2.5.1.1. The verbal model
The library of a university holds books and lends them to registered readers. Readers borrow books from the library and return them after a period of time. A book may have title, authors, publishing house, publishing year, language, translators, nb of pages, price, etc. Authors write books; publishing houses publish books at a publishing year; translators translate books. Authors and translators may have name, profession, nationality. Publishing houses may have name, address. A reader may have name, address, phone_nb, etc. There are three types of readers: students, professors and others.
There are several restrictions imposed on readers regarding the maximum number of borrowed books and the maximum period of time the borrowed book may be held by the reader.
A student may borrow up to 3 books, a professor up to 5 books and other readers just one book at the time. Students may hold the book for maximum 7 days, a professor for maximum 14 days and other readers for maximum 7 days. If the book is not returned in due time, the reader is penalized by not being allowed for a period to borrow books. The forbidden period is established as follows:
For students: If the delay time is between 8 and 14 days, the forbidden period will be 14 days starting with the return date; between 15 and 30 days is 30 days and over 30 days is 90 days
For professors: If the delay time is between 15 and 30 days, the forbidden period will be 30 days starting with the return date; between 30 and 60 days is 60 days and over 60 days is 90 days
For others: If the delay time is between 8 and 14 days, the forbidden period will be 30 days starting with the return date; between 15 and 30 days is 60 days and over 30 days is 90 days.
If readers doesn't return books in maximum 120 days, they will be noticed (a note will be sent to their address in order to remind them about borrowed books and the delay period).
The reader may lose the book. In this case, the reader is restricted from borrowing for 120 days and he must pay 10 times the price of the book. If the price is not paid within the 120 days, then the reader is excluded.
Conceptual modeling
We have a lot of information in the above domain description: words that depict objects and actions that happen in the observed area. In the modeling process we have to identify objects, their attributes and their relationships.
The objects are subjects and objects of the sentences. Subjects are active objects that carry on the action and the objects that support it are passive objects.
The attributes are words depicting properties of the objects that could be directly associated with a value (name, title, price). In the verbal model, the attributes are introduced with the verb to have (the book has title, price, publishing year, etc).
The relationships between objects are structural and functional. The structural relationships are concerned with groups of objects (complex objects) and classes of objects (similar objects). Structural relation 18418r173s ships are described by verbal constructs of the verb to be (to be made of, to be part of, to be like, to be a kind of)
The functional relationships are determined by the objects roles in the domain activities. They are basically action verbs (library lend books; readers borrow books), the sentences' predicates.
In the attempt to identify objects and relationships, we relay on nouns and verbs; so we have to draw a list of nouns and a list of verbs and then use it as a basis of a semantic network with nouns as nodes (only one node for each noun) and verbs as arcs (one arc for each verb considered a predicate of a simple sentence).

 The nouns
list The verbs
list
The nouns
list The verbs
list
Library

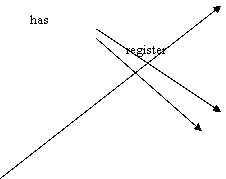
![]()
restrict

write penalize
![]()
![]()
![]()

has
![]()
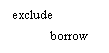

![]()
![]()

![]()
![]()
Title
![]()
![]()
![]()
![]()
year![]()


![]()
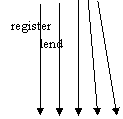
Fig.2.22. The semantic network of the library domain
In the scheme above we have placed the main objects and their relationships according to the sentences of the verbal model. Every object being represented only once, we could easily see which objects are interacting. Any object could be active or passive, according to the sense of the arrow. The attributes are nodes pointed by arcs based on the verb to have. These nodes does not have arcs starting from them unless a value is associated with the attribute (the library phone number is 2222333; the forbidden period is 14 days; the allowed period has the value 7 days). The attribute nodes are the extremities of the semantic network. However, if an extremity node cannot be associated directly with a value, that node is not an attribute, it is an object and we have to look for its attributes. This is the case of library and university whose attributes are not explicitly present in the verbal model, but we may add them directly in the semantic network, providing the evidence.
The attribute nodes are sometimes shared by more objects in the semantic diagram (name, address are shared by library, university, readers, authors, translators and publishing houses). That makes them to belong to a class (persons) and we may add attributes to differentiate them in subclasses (fiscal code for legal persons like university and publishing houses; gender, age for natural persons like readers, authors and translators). We may invent abstract objects to bear common attributes and then indicate them as classes for the initial objects that shared the same attributes. We'll do that if objects with common attributes perform the same functions (like readers as a class for students, professors, others). Otherwise, we'll rather qualify common attributes to indicate the object they belong to (reader's name, library's name, author's name).
Some objects may be parts of other objects (like the library, which is part of the university, or like chapters that are parts of a book). The group-part relationship may be used for decomposing extremity nodes that cannot be associated directly with simple attributes (for instance, if we want to associate the address with a value we'll find that we have to express a composed value "Bucharest, Piata Romana, 6" or "Piata Romana, 6, Bucharest". We may consider City_name, Street_name, House_Number as distinct attributes of library but we may consider them also as parts of the address which is no longer an attribute of the library but a component.
2.5.1.2. The Entity-Relationship conceptual model
Looking at the semantic network we'll identify some standard subnetworks:
Objects & attributes (& values) the Object-Attribute-Value triplets
(nodes and their surroundings linked with to have arcs; the extremities of the semantic network)
Class subnetworks (trees of nodes linked with to be like/ to be a kind of arcs)
Group subnetworks (trees of nodes linked through to be part of / to be made of
The rest of the semantic network including all the nodes linked with functional verbs
These subnetworks are transformed in the entity -relationship conceptual model according to the following rules:
Every node with its surroundings linked with "to have" arcs will be an entity.

Every functional arc will be a relationship between the entities representing the nodes the arc linked in the semantic network. At this point we may add information we weren't able to show in the semantic network: actions attributes (parameters describing mainly the time, the place of the action and other related features)

According to the entity-relationship conceptual model we have to establish the cardinalities of each relationship: how many items of one entity are related to one item of the other entity (at least, at most). Taking for instance the arc borrows between the nodes Readers and Books.
How many books could borrow 1 reader? At least 0, at most N
How many readers could borrow 1 book? At least 0, at most N

Or the arc register between Library and Books
How many books could register 1 library? At least 0, at most N
How many libraries could register 1 book? At least 1, at most 1
There is only one library in our domain and each physical book could not be unregistered nor registered twice or more.

To simplify, the at most cardinality is important. The at least cardinality if 0 express the fact that some items in that entity may not be related at all to any item in the other entity.
The "at most" cardinalities may be one to one (1 to 1), 1 to many (1 to M) and many to many (M to N).
This information is not evident from the semantic network. The entity relationship model is more accurate regarding the actions: we may express action parameters and cardinalities but we lose instead some important information: who's doing and who's supporting the action. The sense of the arcs of the semantic network is not represented anymore in the entity-relationship model.
Objects in a class could be compressed at the root of the class_tree in a single object having all the attributes of each subclass level and an extra attribute to identify each subclass
Readers are students, professors and others
Readers will have an extra attribute to mark the reader type (S for students, P for professors, O for others) and will incorporate all the attributes for students (faculty and year), professors (chair, faculty is common with students), none for others. This attributes may not have values for all the objects (student readers don't have chair, professors readers don't have year and others don't have any).

This could be done if all the readers are doing the same actions (the root is related with functional arcs with other nodes). If not the case, the objects in the class_tree will be compressed at the leaf-level, by copying common attributes of upper classes in each final object and for each class level, an identifier.
For the class persons, we'll have two subclasses: legal (library and Publishing_houses) and natural (readers, writers, translators). We have no identifiable actions at the root (person) or at intermediate legal/natural person level (in our verbal model), but we have a lot of actions at the "leaves" level, so we'll keep each one as an entity with its own attributes (if any) together with the inherited attributes via the branches and the root of the class_tree. For each path from the root to the final object we could keep extra attributes to designate the flattened class level by default values (person_type: L for legal, N for natural).


For decomposition trees (a book is made of volumes and each volume is made of chapters, we'll take every node as an entity but for each node we'll indicate the path from the root by using extra attributes to indicate the object it is part of (book title for each volume, volume nb and book for each chapter).
CHAPTERS Book_title Volume_nb Chapter_title


![]()
![]()
![]()
READERS'ADDRESS Reader_name City Street Number
![]() Or for reader's address:
Or for reader's address:
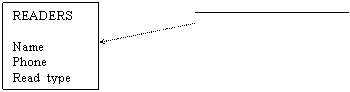

Fig. 2.23. The Entity-Relationship conceptual model of the library domain
Provided the fact that we model the activity of only one library, the entity Library is not very important, its actions of registering, restricting, noticing and excluding readers and registering, holding and lending books could be seen as actions of corresponding objects readers and books, one of them already specified in the model: library lends books to readers is equivalent to readers borrow books. So, we'll replace the library's actions with abstract objects: registrations, restrictions, penalties and suspensions and the relation with the readers and the books will be expressed through the passive verb support, unless no verb more appropriate is available.

TRANSLATORS Name Address Nationality AUTHORS Name Address Nationality
![]()
![]() Fig.2.24. The E-R model revised
Fig.2.24. The E-R model revised
If we analyze the abstract entities introduced we observe that some of them are attribute-less entities (registrations, exclusions, warnings) so we can eliminate them from the model and the attributes of the relationships of 1 to many (like registration date, and excluding date) may migrate in the related entities. The attributes of the M to N relationships may not migrate so the empty entity Warnings must be preserved in the model.
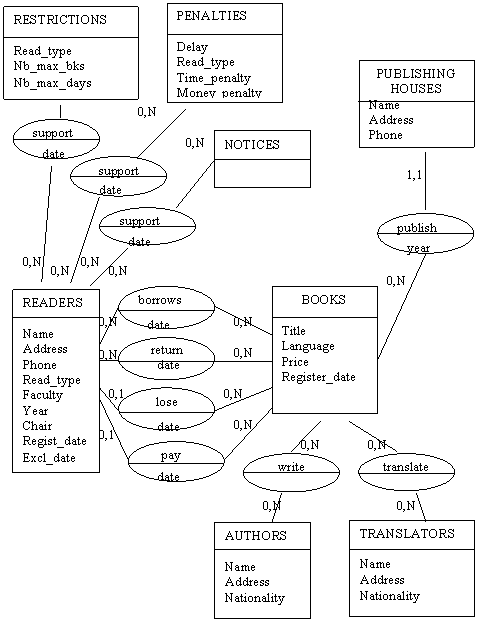
Fig. 2.25. The E-R model revised more
2.5.1.4. The relational model
The Entity-relationship conceptual model is going to be transformed in a logical model suited to be implemented by a Data Base Management System. At this point we have to choose among the three main logical data models: the hierarchical, the network and the relational.
The data models differ in the way they implement the relationships. Network and hierarchical data models use physical relationships (pointers) while relational data models implement relationships by means of common attributes. Since the attributes are names (words), the relationship is said to be logical. Logical relationships are immaterial, virtual, established only at processing time but without the user awareness.
The relational data model is obtained from the E-R conceptual model following the mapping rules:
Entity - table
Attributes - columns in the table
The only type of relationship that could be mapped directly in the relational model is the 1 to M relationship. The entity in the 1 part of the relationship will have a field that uniquely identifies each element of the entity, that field is called an identifier, a primary key. In the entity of the M part is inserted the identifier of the 1 part entity, that field is common to both tables. The expression of the logical relationship, is:
foreign key = primary key
The M to N relationship is mapped in the relational model by means of an additional table that split the M to N relationship in two 1 to M relationships. The additional table will be used to household the common fields (foreign keys) matching the primary keys of the initial related entities.
If there are attributes of the relationships, they migrate in the M part table if the relationship is 1 to M or will stay in the additional table that embody the M to N relationship.
For instance, a 1 to M relationship:


For an M to N relationship, take for instance


We establish for each entity an identifier, we may choose an existing one (Name or Title) or, to be more sure of its uniqueness, we invent a new attribute, an artificial code, usually a number. Then we map each entity in a table, each 1 to M relationship in an additional field in the M part table matching the identifier of the 1 part table and also, attributes of the 1 to M relationship goes in the M part table. As for the M to N relationships, we invent an additional table with new fields matching the identifiers of the former related tables and fields for the relationship attributes.
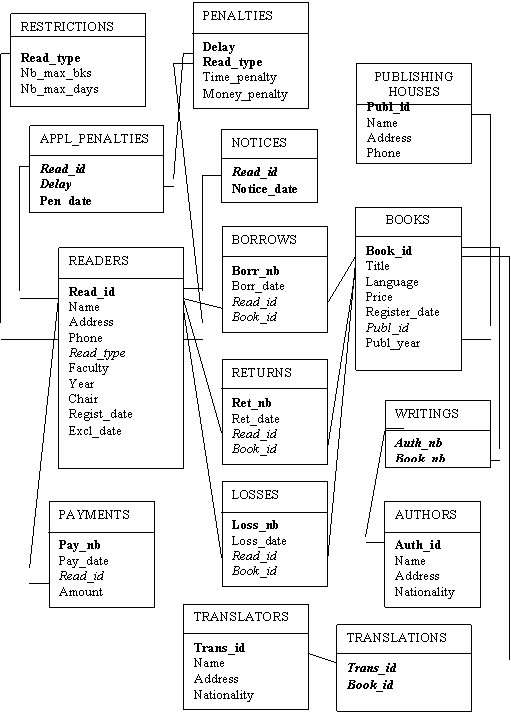
![]()
Fig. 2.26. The relational data model
We put the relational model in the shorthand description:
READERS(Read_id,Name, Address, Phone, Read_type, Faculty, Year, Chair,
Regist_date, Excl_date
BOOKS(Book_id,Title,Language,Price,Register_date,Publ_id,Publ_year
AUTHORS(Auth_id,Name,Address,Nationality)
TRANSLATORS (Trans_id,Name,Address,Nationality)
PUBLISHING_HOUSES (Publ_id,Name,Address,Phone)
RESTRICTIONS (Read_type,Nb_max_bks,Nb_max_days)
PENALTIES(Delay,Read_type Time_penalty,Money_penalty)
BORROWS(Borr_nb Borr_date,Read_id,Book_id)
RETURNS(Ret_nb Ret_date,Read_id,Book_id)
LOSSES(Loss_nb,Loss_date,Read_id,Book_id)
PAYMENTS(Pay_nb Pay_date,Read_id,Amount)
WRITINGS(Auth_nb,Book_nb)
TRANSLATIONS(Trans_nb,Book_nb)
NOTICES(Read_id,Notice_date
APPL_PENALTIES(Read_id,Delay,Pen_date)
2.5.1.5. Normalization
Now we have to check each table for meeting the normal forms rules.
First normal form: All the attributes must depend in a 1:1 relationship on the primary key
Second normal form: For tables with composed keys, all the attributes must depend on the whole primary key.
Third normal form: If an attribute depends also on a nonkey attribute, that attribute must be a candidate key.
Giving the fact that the relational model was derived by means of successive mappings of different conceptual models from the verbal model mapped into a semantic network which in its turn was mapped into the Entity-Relationship model which was finally mapped into the relational model, most of the tables must be in the third normal form already. However, if the verbal model was incomplete, some anomalies may appear, so the model must be checked anyway.
All the tables have primary keys and all the nonkey attributes depends in a 1:1 relationship on the primary key largely because they were related in the semantic network with the arcs "to have" and were supposed not to have multiple values. In such an eventuality, the attribute must be moved in another table with a foreign key to refer to the initial table. In such a case could be the attribute Phone from Readers (a reader could have more phone numbers)
![]()
READERS(Read_id,Name, Address, Phone, Read_type, Faculty, Year, Chair,
Regist_date, Excl_date
In this case we'll invent a new table
READ_PHONES (Auto_id, Read_id,Phone
And the Readers table becomes:
READERS(Read_id,Name, Address, Read_type, Faculty, Year, Chair,
Regist_date, Excl_date
The second normal form must be checked for tables with multiple fields keys which turn to be only PENALTIES, the others tables (WRITINGS, TRANSLATIONS and APPLY_PENALTIES) having no other attributes but key components.
PENALTIES(Delay,Read_type Time_penalty,Money_penalty)
![]()
The Time_penalty depends on both the delay and the read_type in 1:1 relationship (For a given combination of delay and read_type we have only one value for the Time_penalty)
The Money_penalty does not depends on Delay at all, nor on Read_type; it is a penalty percent to be applied on the lost book's price to compute the amount to be paid by the loser; it is a fixed value for any combination of values of Delay and Read_type (10 times the book's price). Being a fixed value, the second normal form is respected anyway, but the table will have a lot of repetitive groups which is forbidden by the first Codd's rule (every cell must be single valued), so the money penalty must be taken away from the table and used directly in computing formula or put aside in a table with one record with a single field. The new table cannot be related to the rest of the database because no primary key could be added to it to be referred from another table as a foreign key.
The same discussion on the repetitive groups issue, when considering the possible values of Delay, we observe that for values between 8 and 14, for a given reader type we have the same value for the Time Penalty. So the problem here is that we have a lot of values for keys and few values for the rest of the fields. Moreover, the Delay field must have all the possible delays, starting with 1 day up to ... let's say 365days for each Read_type. We can change that by replacing the field delay with two fields: Min_delay and Max_delay but in this case we'll lose the relationship with the table Appl_penalties where the foreign key is Delay.

PENALTIES(MinDelay,MaxDelay,Read_type Time_penalty)
The table Penalties could be explicitly related when needed by means of a Cartesian product and a select condition:
SELECT *
FROM APPL_PENALTIES, PENALTIES
WHERE [Delay] Between [MinDelay] and [MaxDelay];
Note that, in this case, the table Penalties no longer belongs to the database according to the definition (a collection of related files).
Again, the conditions and values for Time penalties, as the Money penalties, could be embedded in computing formulas and new fields will be added to Appl_penalties table to store the new computed values.

APPL_PENALTIES(Read_id,Delay,Pen_date,Time_penalty, Value_penalty)
The Value penalty still does not depend on Delay, only on Read_id and Pen_date, so the APPL _PENALTIES table must be sliced in two tables APPL_TIME_PEN, APPL_MONEY_PEN
APPL_TIME_PEN(Read_id,Delay,Pen_date,Time_penalty)
![]()
![]()
![]()
![]() APPL_MONEY_PEN(Read_id,Pen_date,Value_penalty)
APPL_MONEY_PEN(Read_id,Pen_date,Value_penalty)
![]()
![]()
For the third normal form, we have to check each attribute whether it depends or not on nonkey attributes. Such a possible dependence could appear between Phone and Address in Readers table and Publishing Houses Table. The phone depends largely on the address. So, it would be better to put the Phone together with the Address in a new table Fortunately we already proposed this for making room for more phone numbers, if needed.
As we proceed with normal form checking, we see that our database is sliced in more and more smaller tables. We have to compromise at a certain "slicing" level and impose some restrictions on data values. Otherwise, in extremis, we'll have more key attributes and foreign keys than useful data in our database.
|
