ARHITECTURA MICROPROCESOARELOR: TIPURI DE DATE, MODURI DE ADRESARE, INSTRUCTIUNI
1.1 Istorie a evolutiei microprocesoarelor
Se impune evocarea unor momente semnificative in evolutia microprocesoarelor, evocare care va permite mai buna intelegere a stadiului actual si a tendintelor.
Anterior anului 1971 o serie de firme de renume (General Electric, RCA, Viatron) au contribuit la dezvoltarea microproce- soarelor. Totusi modelul 4004 introdus pe piata de Intel la sfirsitul anului 1971, reprezinta primul microprocesor care a patruns in lumea civila. La scurt timp dupa aceea, in anul 1972, i-au urmat PPS-4 (Rockwell International), proccesor de 4 biti, 8008 (Intel), procesor de 8 biti si IMP-16 (National Semiconductor), procesor de 16 biti.
Motivele ce au stat la baza implemmentarii primelor microprocesoare au fost dictate de cererea importanta de circuite de comanda puternice, care sa fie usor de adaptat la circuitele integrate disponibile in acel moment. Deci, in epoca de inceput, microprocesorul a fost privit ca un dispozitiv electronic programabil care poate inlocui logica cablata (hard-wired logic) utilizata in realizarea controllerelor de periferie, cum sint cele pentru imprimante, terminale inteligente sau calculatoare de buzunar. Domeniul de aplicatie si tehnologia disponibila au impus caracteristicile tehnice ale acestor dispozitive. 8008 opera cu cuvinte de date de 8 biti, cu adrese pe 14 biti (16 Kocteti spatiu de memorie maxima direct adrsabila), cu un set de instructiuni destinat efectuarii unor operatii aritmetice (adunare, scadere) si o stiva implementata hardware in cadrul CPU (Central Processing Unit - unitate centrala de prelucrare), de dimensiuni modeste, care nu permitea executia unor programe complexe.
Dezvoltarea in continuare a tehnologiei a permis cresterea numarului de tranzistoare ce se pot depune pe o arie data a plachetei de siliciu, asa ca proiectantii de microprocesoare au inceput sa isi puna problema utilizarii ariei ramas 919h79j e disponibile ca urmare a progresului tehnologic.
Perioada 1973-1977 este specifica microprocesoarelor cu lungimea cuvintului de date de 8 biti, cu adresele formulate pe 16 biti (spatiul maxim de memorie direct adresabila fiind, deci, de 64 Kocteti). Setul de instructiuni s-a extins pentru a permite manipularea unor date pe 16 biti, fapt ce a permis oferirea de mijloace de evaluare a adreselor. Stiva a fost mutata din unitatea centrala in memorie, avind ca efect cresterea numarului de subrutine imbricate. Domeniile principale de aplicare a microprocesoarelor de 8 biti erau: sisteme cu functionare in timp real (in general) si sisteme destinate conducerii proceselor industriale in particular. Majoritatea programelor erau scrise in limbaj de asamblare, deoarece frecventa mica a ceasului sistemului (2 MHz) si spatiul restrins de adresare reclamau cod compact si eficient. O alta calitate importanta a noilor microprocesoare a constat in posibilitatea folosirii unor periferice specializate utilizate in aritmetica intregilor extinsi si a numerelor reale cu virgula mobila, ceea ce a constituit prima tentativa de introducere a facilitatilor de prelucrare complexa in cadrul arhitecturilor bazate pe microprocesoare. Cu toate acestea procesoarele aritmetice slabe aveau inca viteza mica, iar interfatarea lor cu sistemul de calcul introducea consumuri suplimentare (overhead) atit de mari incit multe dintre avantajele utilizarii lor erau anulate de timpul consumat de citirea/inscrierea datelor si de programarea procesorului slave. Ca exemplu poate fi citat procesorul matematic 8231 (Intel).
Extinderea cu adevarat a tipurilor de date prelucrate de catre microprocesor, pentru a include si numerele cu virgula mobila, a avut loc la inceputul anilor '80, odata cu introducerea unei noi clase de microproccesoare. Astfel de microprocesoare au fost prevazute cu o unitate separata pentru prelucrari in virgula mobila, capabila sa decodifice si sa execute instructiuni cu operanzi in virgula mobila. La noile microprocesoare s-au extins si lungimea cuvintului de date (la 16 biti) si capacitatea maxima de memorie direct adresabila pina la 16 Mocteti. S-au efectuat si alte imbunatatiri, aritmetica numerelor intregi a fost extinsa la operanzi de 32 biti, ceea ce favorizeaza manipularea adreselor, s-au introdus instructiuni de manipulare a sirurilor de lungime variabila de octeti, s-a perfectionat mecanismul CALL/RETURN, cu efecte favorabile asupra implementarii limbajelor de nivel inalt si a programarii recursive. Poate ca cea mai importanta facilitate noua este cea legata de protectia si gestiunea memoriei, fapt ce a presupus o organizare hardware speciala destinata oferirii de suport pentru taskuri specifice sistemului de operare.
Toate aceste noi caracteristici s-au reflectat in noi tipuri de aplicatii, cum sint cele legate de calculatoarele personale, statii de lucru CAD/CAM (Computer Aided Design/Computer Aided Manufacturing) sau sisteme functionind cu divizarea timpului (time-sharing). Intrucit toate aceste noi procesoare dispuneau de memorii mari si operau cu viteze sporite ale ceasului, majoritatea programelor de aplicatii au inceput sa fie scrise in limbaje de nivel inalt: Fortarn, Pascal, C, limbaje aflate deja in uz in sistemele mari de calcul. Limbajul de asamblare s-a mai folosit doar pentru scrierea de subrutine intim legate de particularitatile hardware ale masinii sau pentru realizarea de programe cu performante deosebite.
Urmatorul pas in evolutia microprocesoarelor, concretizat in realizarile acestui moment, a constat in proiectarea unei arhitecturi bazate pe trei unitati majore: unitatea centrala de prelucrare (CPU), unitatea de virgula mobila (FPU-Floating Point Unit) si unitatea de gestiune a memoriei (MMU-Memory Management Unit). CPU are ca scop executarea prelucrarilor de uz general, FPU efectueaza operatii aritmetice cu numere in formatul cu virgula mobila cu precizie extinsa, in timp ce MMU asigura suportul cerut de realizarea unor functii aferente sistemelor de memorie virtuala si ofera un suport hardware pentru protectia obiectelor de memorie impotriva utilizarii necorespunzatoare. Aceste microprocesoare au lungimea cuvintului de date de 32 biti si un spatiu virtual de adresare de pina la 4 Gocteti.
Din succinta trecere in revista de mai sus rezulta ca aria disponibilizata a plachetei de siliciu a circuitului integrat s-a utilizat in doua mari scopuri:
a) oferirea de suport pentru implementarea sistemelor complexe de operare prin introducerea de hardware specializat si instructiuni speciale;
b)executia mai eficienta a programelor scrise in limbaj de nivel inalt prin utilizarea unor moduri de adresare si a unor instructiuni mai complexe.
Desi aceste tendinte nu afecteaza in mod direct dezvoltarea de viitor a microprocesorului, ele evidentiaza doua idei interesante privind arhitectura microprocesoarelor in conditiile utilizarii pe scara din ce in ce mai larga a limbajelor de nivel inalt si ale introducerii microprocesoarelor in domenii ca: statii de lucru pentru aplicatii ingineresti, calculatoare personale puternice, ambele necesitind sisteme de operare complexe. Este motivul pentru care in cele ce urmeaza se vor trata, cu precadere, problemele legate de implementare. Apoi se vor particulariza - pentru cele mai raspindite microprocesoare in prezent - problemele despre care s-a vorbit.
1.2. Dihotomia limbaj de nivel inalt - masina tinta
Intrucit un mare volum din programele destinate microcalculatoarelor este scris prin utilizarea limbajelor de nivel inalt, cel mai bun mod de imbunatatire a performantelor microcalculatoarelor consta in cresterea eficientei de executie pentru astfel de limbaje. In prezent se vorbeste despre o prapastie semantica intre modul in care limbajul de nivel inalt este vazut de catre programator si modul de implementare a acestui limbaj pe masina tinta. Cresterea eficientei de ansamblu de executie a programelor si de realizare a lor intr-o forma fiabila se bazeaza, intr-o mare masura, pe eforturile de realizare de punti de trecere pentru aceasta prapastie.
Pentru a gasi solutii la problema se impune mai intii o examinare amanuntita. Primul pas consta in a compara optica prin care masina este vazuta de catre programatorul in limbaj de nivel inalt si de catre cei ce folosesc limbajul de asamblare. Cele mai importante diferente sint:
a)in limbajele de nivel inalt memoria este privita drept constind dintr-un set de variabile carora li s-au asociat nume, set care nu reflecta relatii de tipul: vecinatatea variabilelor, pozitia lor relativa etc. Masina are memoria organizata ca o matrice liniara cu locatii de dimensiuni egale, fiecarei locatii asociindu-i-se o adresa.
b)limbajele de nivel inalt folosesc structuri de date multidimensionale (de exemplu matrici cu mai multi indici), in timp ce organizarea memoriei unei masini reale poate manipula structuri de date cu o singura dimensiune.
c)in unele limbaje de nivel inalt, programarea structurata necesita o multitudine de apeluri de proceduri care implica si transfer de parametri, alocare dinamica a memoriei cerute suplimentar fata de instructiunile de salt la subrutina si revenire din subrutina, oferite de catre orice procesor.
d)limbajele de nivel inalt fac diferentierea neta intre cod si date, diferentiere inexistenta in memoria masinii reale.
La cele mentionate se mai pot considera si alte caracteristici ale masinii care nu sint luate in considerare de limbajele de nivel inalt: registrele unitatii centrale de prelucrare sau aritmetica binara.
1.3.Clasificari arhitecturale
Considerentele din paragraful precedent pot servi si pentru clasificarea variatelor arhitecturi disponibile in acest moment. Diferentele intre clasele de arhitecturi constau in volumul de prelucrari efectuate prin program si prin intermediul echipamentului la executia unui program scris in limbaj de nivel inalt. In calculatorul convetional, programul sursa este compilat de catre compilator, care translateaza instructiunile programa- torului in instructiuni de nivel inferior, care pot fi executate de catre hardware. Deci, pentru executia programului sint necesare prelucrari atit software cit si hardware. Totusi, unele masini necesita volume importante de translatari din limbajul de nivel inalt in cel apropiat masinii, ca urmare a nivelului foarte scazut al limbajului masina, caz in care un mare volum de prelucrari se efectueaza de catre software. Alte calculatoare, avind functii de nivel inalt implementate in arhitecturi hardware, necesita un proces de compilare mai simplu, deoarece echipamentul este capabil sa execute functii mai apropiate de cele utilizate in limbajul sursa.
In figura 1.1 se indica o posibila clasificare a arhitecturilor [1],[2]. Principalele doua clase sint: arhitecturi cu executie directa si arhitecturi cu executie indirecta.Arhitectura cu executie indirecta se subdivizeaza in arhitectura complexa si redusa, iar arhitectura complexa include arhitectura orientata catre limbaj (language oriented) si arhitectura corelata cu limbajul (language-corresponding). In fine, arhitectura corelata cu limbajul se subdivizeaza in arhitecturi ce necesita translatari prin program si arhitecturi cu translatari prin hardware.
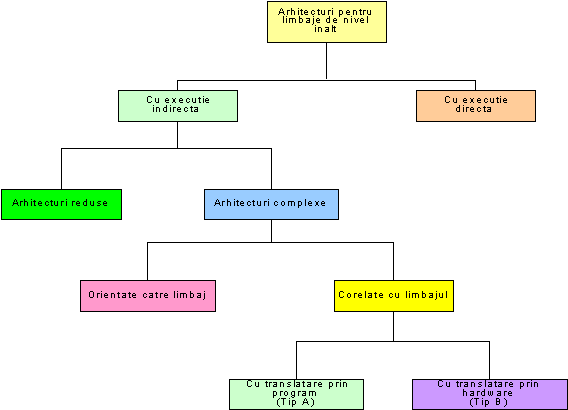
Fig. 1.1 Clasificari arhitecturale din punctul de vedere al executiei programului in limbaje de nivel inalt
1.3.1.Arhitecturi cu executie directa
Calculatoarele din aceasta clasa sint capabile sa execute limbaje de nivel inalt direct, fara nici un fel de translatare. Avantajele majore ale acestei clase constau in: gradul ridicat de interactiune cu programatorul, absenta timpului de compilare si reprezentarea programului cu un singur fisier (doar codul sursa, fara fisier obiect sau executabil). Dezavantajele sint generate de dificultatile de depanare (numarul erorilor sintactice detectate la executie este mic; este necesara verificarea sintactica a tuturor programelor, chiar si a celor corecte; masina nu poate executa decit programe scrise in limbajul propriu). Nu exista exemple de microprocesoare din aceasta categorie.
1.3.2.Arhitecturi reduse
Calculatoarele cu arhitectura redusa sint orientate catre imbunatatirea performantelor la rularea programelor de nivel inalt. Scopul este atins prin implementarea directa in hardware a unui mic numar de instructiuni simple, a caror executie este optimizata. Aria economisita pe placheta de siliciu printr-o astfel de abordare poate fi utilizata pentru construirea unor blocuri menite sa creasca viteza de executie a programului. Principalele dificultati sint solutionate la nivelul compilatoru- lui.
Filozofia de mai sus a avut ca rezuultat realizarea procesoarelor cu set redus de instructiuni (RISC- Reduced Innstruction Set Computers), care au inceput a fi utilizate in aplicatii comerciale (microcalculatoare IBM). In aceeasi clasa pot fi incluse si transputerele, produse ale firmei INMOS, care poseda alte facilitati arhitecturale ce le recomanda pentru utilizarea in realizarea structurilor multiprocesor.
1.3.3. Arhitecturi orientate catre limbaj
Trasatura distinctiva a acestor arhitecturi este data de utilizarea unor moduri speciale de adresare si a unor instructiuni speciale, utilizabile de catre compilator pentru implementarea unor operatii specifice limbajelor de nivel inalt, cum este accesul la structuri complexe de date. Rezultatul se manifesta in simplificarea procesului de compilare. Avantajul potential al acestui mod de abordare consta in posibilitatea de implementare directa in hardware a unor functii specifice limbajelor de nivel inalt. Pe de alta parte, complexitatea crescinda a procesorului poate indeparta rezultatul proiectarii de situatia optima, manifestata printre altele si prin reducerea vitezei de executie a instructiunilor simple.
Aceasta categorie include marea majoritate a procesoarelor disponibile pe piata la ora actuala. Doua din cele mai intens utilizate familii (iAPX 286 si iAPX 432) vor fi studiate in capitole ulterioare.
1.3.4.Arhitecturi corelate cu limbajul
Aceste sisteme ar trebui sa realizeze o corespondenta biunivoca intre limbajul de nivel inalt si codul masina. Ca urmare, compilatorul unui astfel de calculator devine similar cu un asamblor. Diferenta intre tipurile A (translatare software) si B (translatare hardware) din fig. 1.1. se manifesta in mai marea viteza de translatare pentru varianta B si mai redusa complexitate hardware pentru varianta A.
Pentru ambele tipuri avantajele decurg din posibilitatea de depanare a unui program scris direct in limbaj de nivel inalt. Ca performante care cunosc o imbunatatire se mentioneaza fiabilitatea programelor si implemenatrea functiilor complexe. Este limpede ca ambele tipuri de arhitecturi corelate cu limbajul sint puternic orientate catre executia programelor scrise in limbajul pentru care a fost conceputa masina.
Doar putine masini existente functioneaza conform principiilor din aceasta clasa, dar nu exista microprocesoare care sa ofere caracteristicile arhitecturii corelate cu limbajul.
1.3.5. Arhitectura si eficienta de executie
Caracteristicile arhitecturale cu cele mai puternice influente asupra eficientei de executie a programelor scrise in limbaje de nivel inalt sint:
-tipurile de date, deoarece tipurile de date manipulate eficient de catre masina tinta s-ar putea sa fie identice cu tipurile de variabile in limbajul de nivel inalt;
-modurile de adresare, intrucit ele definesc mecanismul de acces la date in masina reala, deci pot fi utilizate eficient pentru a reprezenta structuri complexe de date intr-o memorie cu organizare liniara;
-setul de instructiuni, caci echipamentul poate oferi instructiuni ce realizeaza operatii tipice cerute de executia programului (ca in arhitecturile orientate spre limbaj) sau poate oferi un set de instructiuni mai apropiat de cel optim din punctul de vedere al timpului de executie (ca in cazul masinilor cu arhitectura redusa).
In paragraful urmator se considera un exemplu ilustrativ pentru modul de alocare a memoriei in executia programelor scrise in limbaj de nivel inalt, ca si pentru unele operatii tipice pentru acest gen de programe.
1.4. Alocarea memoriei in limbaje de nivel inalt
Practic toate microprocesoarele contemporane folosesc compila- toare sau, mai bine spus, generatoare de cod care reprezinta declaratiile limbajului de nivel inalt si modalitatile de adresare a memoriei prin instructiuni masina si organizarea memoriei. Descrierea de mai jos se aplica limbajelor structurate si care permit programare recursiva, asa cum sint popularele limbaje Pascal si C, larg acceptate in lumea microprocesoarelor.
Spatiul de memorie ocupat de un program poate fi divizat in doua sectii principale: o sectie read-only (care poate fi citita, dar nu inscrisa), care contine codul si constantele, si o sectie read-write (ce poate fi atit citita cit si inscrisa), in care se stocheaza toate variabilele declarate si auxiliare utilizate de catre program. In general, aceste doua sectii sint alocate in doua zone de memorie (chiar daca aceste zone ar putea fi contigue). La rindul ei, zona de date poate fi subdivizata in zona pentru stiva (stack), unde se aloca variabilele declarate, si zona cu acces aleatoriu (heap - gramada neorganizata), folosita pentru variabilele create dinamic.
Se considera urmatorul program scris in Pascal:
program mem(input, output);
var i,j:integer;
a:array[1,10] of real;
procedure A(x:integer; y:real);
var z,t:real;
procedure B(m:boolean; y:real);
var w:real;
procedure C(var t:real);
var z:real;
begin
.
.
.
end;
procedure D(var v:boolean);
begin
.
.
.
C(w);
.
.
.
end;
begin
.
.
.
D(m);
. .
.
end;
begin
.
.
.
B(true,t);
.
.
.
end;
begin
.
.
.
A(i,a[j]);
.
.
.
end.
Figura 1.2.a. arata sectiunea de memorie dedicata memorarii variabilelor la inceperea executiei. Memoria se reprezinta printr-o matrice liniara de locatii de memorie. Cu blocuri mai late se indica blocuri contigue de memorie, in timp ce blocurile mai inguste reprezinta o locatie, sau un mic numar de locatii cconsiderate ca o singura variabila. Sageata arata ca in originea ei este memorat un indicator (pointer), virful sagetii indicind locatia indicata.
In fig. 1.2. numai zona superioara este alocata pentru a pastra variabilele i,j si a, definite in programul principal. Cind se executa instructiunea care apeleaza procedura A, alocarea memoriei se modifica (Fig. 1.2.b.).

Fig 1.2. Alocarea memoriei la apelarea unei proceduri:
a. inainte de apelare;
b. dupa apelare
Deoarece limbajul Pascal permite programarea recursiva, fiecarei apelari de procedurri trebuie sa i se ofere propria copie de parametri si variabile definite in cadrul procedurii. In felul acesta, apelarea procedurii reduce alocarea unei noi regiuni de memorie, numita cadru (frame), care contine variabilele locale ale lui A, parametrii sai, adresa de revanire si orice alta informatie necesara adresarii variabilelor exterioare lui A, dar vizibile din procedura A. In acest exemplu celelalte variabile sint cele definite in programul principal.
Structura posibila a unui nou cadru alocat in memorie ca urmare a apelarii unei proceduri este indicata in fig. 1.3.

Cimpul de afisare este folosit pentru stocarea informatiilor cerute pentru accesul variabilelor definite in exteriorul procedurii; mai precis, cimpul de afisare contine o lista de indicatori catre cadrele ultimei activari a fiecareia din procedurile care incapsuleaza apelul procedurii in discutie. In consecinta, cadrul procedurii A este compus doar din indicatorul catre variabilele globale, deoarece declararea procedurii A este incapsulata doar in programul principal. Cimpul de afisare al procedurii B este compus din indicatori catre programul principal si procedura A, intrucit procedura B este declarata in interiorul procedurii A, declarata, la rindul ei, in programul principal. Este de notat faptul ca localizarea declararii procedurii, si nu imbricarea activarilor procedurii, este elementul care determina continutul cimpului de afisare.
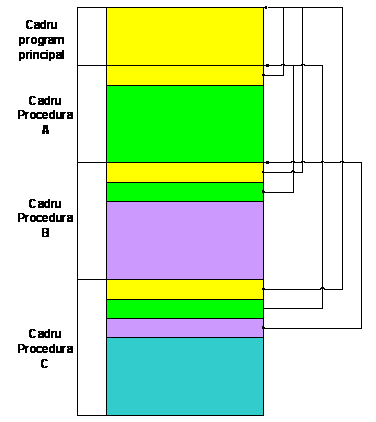
Fig.1.3.Formatul cadrului de memorie alocat unei proceduri definite in nivelul i-1 de imbricare
Procedura A apeleaza procedura B, producind alocarea unui nou cadru pentru B, asa cum se vede in fig. 1.4.a. Apoi procedura B apeleaza procedura D, harta memoriei fiind cea din figura 1.4.b. La rindul ei, procedura D apeleaza procedura C, ceea ce rezulta in alocarea unui nou cadru, noua situatie fiind ilustrata in fig. 1.4.c. Se va remarca identitatea cadrelor pentru D si C, a caror declarare se face la acelasi nivel de imbricare, in timp ce nivelurile lor de imbricare a activarii sint diferite.
Cind o procedura este terminata, cadrul corespunzator este dezalocat (sau eliberat); deci, se efectueaza inversele operatiilor cerute de alocare. Pentru a efectua dealocarea este necesar a pastra adresa de inceput a cadrului de apelare sau dimensiunea cadrului curent. Adresa de inceput a cadrului de apelare, care implementeaza legatura intre cadre, poate fi si ea adaugata la cimpul de afisare al procedurii apelante ori de cite ori procedura apelata este definita la un nivel de imbricare superior celui al procedurii apelante.
In conditiile organizarii memoriei descrise mai sus adresarea variabilelor se efectueaza utilizind doua tipuri de informatii: nivelul de afisare si deplasamentul (offset-ul) variabilei in interiorul cadrului. De exemplu, pe durata existentei procedurii C, accesul la variabila j se face prin adunarea la primul element al cimpului de afisare din cadrul curent a deplasamentului sau in cadrul de afisare al programului principal (fig. 1.5.). Operatii similare se efectueaza pentru a adresa oricare alta variabila (locala sau nu, asa cum este w), dupa cum rezulta din aceeasi figura.
Modurile de adresare utilizate cel mai frecvent de catre un generator de cod avind ca intrare un limbaj de nivel inalt sint cele care calculeaza adresa operandului prin adunarea unei cantitati la continutul unui registru, continut obtinut din incarcarea cu unul din indicatorii de cadru, memorati in cimpul de afisare. Afirmatia poate fi usor verificata, intrucit majoritatea compilatoarelor ofera, suplimentar fata de codul obiect, un fisier in limbaj de asamblare, care reprezinta codul generat. Pe de alta parte, alte moduri de adresare, cum sint cele utilizind adresa completa specificata in chiar codul instructiunii, nu prezinta interes pentru generarea de cod avind ca sursa programe scrise in limbaje de nivel inalt. Intr-un paragraf ulterior se vor analiza, si din acest punct de vedere, modurile de adresare ale microprocesoarelor moderne.
1.5. Tipuri de date
Manipularea datelor reprezinta scopul principal al unui program, asa ca ele joaca un rol important in orice sistem de calcul. Organizarea variabilelor folosite de catre program determina modul in care se face manipularea lor. De aceea, toate limbajele de nivel inalt ofera metode flexibile de definire a structurilor complexe de date, intrucit proiectantii limbajului au inteles ca, in majoritatea cazurilor, programul este aproape complet definit de indata ce s-au proiectat structurile de date ce urmeaza a fi manipulate.
Principial, toate microprocesoarele sint capabile a manipula cu rezonabila eficienta structurile de date definite in limbajele de nivel inalt, dar prapastia semantica despre care s-a vorbit mai inainte conduce la mari deosebiri intre diveresele forme de
Fig. 1.5. Adresarea variabilelor nelocale prin indicatorii de cadru memorati in zona de afisare realizare.
Se spune ca un microprocesor ofera suport pentru un anumit tip de date doar daca este capabil a manipula operanzi apartinind acelui tip. Pentru asigurarea suportului pentru tipuri de date diverse doua caracteristici ale microprocesorului sint - de regula - intrebuintate:
a) instructiuni care executa operatii asupra datelor reprezentate conform formatului asociat tipului considerat;
b) moduri de adresare care permit accesul simplu la operanzi de tipul considerat.
In cele ce urmeaza se va analiza, pe baza acestor doi factori, daca un microprocesor ofera sau nu suport pentru un anumit tip de date.
1.5.1.Lungimea cuvintului
Dimensiunea cuvintului de date este unul dintre factorii majori care influenteaza atit performantele, cit si calitatile functionale ale unui microprocesor. Importanta acestor parametri este demonstrata de faptul ca un criteriu tipic de clasificare a microprocesoarelor se bazeaza pe lungimea cuvintului. Se vorbeste de microprocesor de 8 biti, 16 biti sau 32 biti, numerele 8, 16, 32 referindu-se la lungimea cuvintului de date manipulat.
Desi de o mare importanta, definitia lungimii cuvintului unui microprocesor nu este lipsita de ambiguitate. Doua posibile definitii sint:
a) lungimea cuvintului este data de numarul maxim de biti care pot fi transferati intre CPU si memorie intr-un singur ciclu;
b)lungimea cuvintului este determinata de dimensiunea maxima a operandului care poate fi manipulat de catre unitatea aritmetica-logica (ALU) a CPU.
Prima definitie se refera la traseul extern al datelor fata de microprocesor, in timp ce a doua se refera la traseul intern. La microprocesoarele perioadei de inceput ambele definitii conduceau la acelasi rezultat, data fiind identitatea de dimensiune intre traseul extern si cel intern.
O data cu cresterea dimensiunii operandului manipulat intern de catre ALU, fabricantii de microprocesoare au realizat diferite versiuni ale aceleiasi CPU, cu diferite dimensiuni al magistralei externe. Acest lucru a izvorit din necesitatea de a permite grefarea noilor microprocesoare in sisteme de calcul deja existente, avind memoria si porturile I/O construite pentru magistralele de date mai inguste. In acelasi timp, trebuie mentionat ca toate versiunile au acelasi set de instructiuni, aceleasi moduri de adresare, aceleasi registre interne, aceeasi arhitectura a ALU, acelasi mecanism de intreruperi si capcane (traps). Ca exemplu poate fi citata familia microprocesoarelor Intel care a debutat cu 8086, a continuat cu 8088, sau microprocesoarele 80186, 80286, 80386, 80486.
Adesea, lungimea cuvintului indica, intr-o anumita masura, performanta. Cu cit lungimea este mai mare, cu atit microprocesorul este mai rapid. Dar lucrurile nu sint atit de simple. S-ar putea ca un microprocesor de 32 biti cu magistrala de date de 8 biti (daca ar exista !) sa se comporte mai prost decit un microprocesor de 16 biti cu magistrala de date de 16 biti.
Se justifica, deci, afirmatia ca nu exista o definitie adecvata a lungimii cuvintului, intrucit dimensiunile cuvintului de date transferat pe magistrala externa si a cuvintului de date prelucrat de catre ALU difera. Este mai potrivit a se discuta despre doua dimensiuni de cuvint de date: pentru cel intern si pentru cel extern. Dimensiunea cuvintului de date intern influenteaza viteza de prelucrare a operanzilor instructiunii, in timp ce dimensiunea cuvintului de date extern influenteaza timpul global de acces la memorie pentru extragerea instructiunilor si vehicularea operanzilor.
Cresterea dimensiunii operandului nu este singura consecinta a disponibilitatii unei dimensiuni mai mari a cuvintului, deoarece posibilitatea de a manipula seturi mai mari de biti conduce, de obicei, la introducerea de noi tipuri de instructiuni. Microprocesoarele cu dimensiuni mai mari de cuvint nu sint numai mai rapide decit cele cu cuvinte de dimensiuni mai mici, dar ele tind sa posede un mai bogat repertoriu de tipuri de date, sprijinite cu seturi de instructiuni si moduri de adresare adecvate.
1.5.2. Organizarea memoriei
Toate microprocesoarele au un subsistem al memoriei organizat ca o matrice liniara de elemente de baza de memorare, fiecare din ele asociat cu o anumita adresa. Dimensiunea elementului de baza de memorare este rezultatul coompromisului intre doua cerinte disjuncte:
a) reprezentarea compacta a datelor
b) acces eficient la datele stocate in memorie
1.5.2.1. Adresarea bitilor
Necesitatea unei reprezentari compacte a datelor conduce la selectarea unei dimensiuni mici a elementului de baza de memorare, caci devine posibila ajustarea spatiului de memorie disponibil la dimensiunea formatului datelor, risipindu-se doar un mic volum de memorie. Situatia extrema este cea in care cea mai mica unitate adresabila a memoriei este bitul. Devine posibila stocarea datelor de diferite dimensiuni prin asocierea lor cu siruri contigue, de lungimi variabile, de biti, dimensiunea sirului fiind cea minim necesara pentru reprezentarea datelor. Se ajunge la utilizarea deplina a spatiului de memorie.
Totusi o astfel de organizare a memoriei implica penalizari asupra performantei si costului. Principala problema a adresarii individuale a bitilor consta in necesitatea ca ei sa ajunga la unitatea centrala pe linii fizice diferite, intrucit pozitia unui bit in cadrul cuvintului citit din memorie este data de diferenta dintre adresa sa si adresa emisa de catre CPU. Rezulta necesitatea unor circuite de multiplexare realizate in cadrul modulului de memorie.
Alternativa consta in emularea adresarii la nivel de bit pe o masina care utilizeaza elemente de baza de memorare de dimensiuni mai mari. In acest caz, memoria este adresata la nivel de bloc, iar cimpul cerut de biti este extras de catre CPU cu ajutorul unui mecanism de deplasare - mascare (barrel-shifter) care extrage cimpul necesar intr-un singur ciclu. Probleme serioase apar cind cimpul de biti, desi de dimensiune mica, traverseaza frontiera intre doua cuvinte de memorie (fig. 1.6.).
Fig. 1.6. Date traversind frontiera intre cuvinte in organizarea la nivel de bit
S-a considerat ca dimensiunea blocului citit este egala cu dimensiunea unui cuvint de memorie. Accesul la aceste date necesita doua cicluri de acces la memorie, trebuind citite ambele cuvinte pentru a extrage datele de interes. Desigur, aceleasi probleme se pun in legatura cu inscrierea.
Dezavantajele adresarii la nivel de bit au determinat proiectantii de microprocesoare sa utilizeze elemente de baza de memorie de dimensiuni mai mari. Cresterea eficientei acestui tip de adresare este conferita de similaritatea cu operatia fizica de acces la memorie. Datele si instructiunile sint vehiculate intre memorie si CPU pe un numar finit de linii fizice care transporta numarul de biti transferati (intr-un singur ciclu de acces la memorie). Deci, masinile cu lungime fixa de cuvint constituie o consecinta fireasca a implementarii fizice a transferului de date.
1.5.2.2. Masini cu lungime fixa a cuvintului
La majoritatea procesoarelor contemporane, dimensiunea cuvintului de date externe este de 32 biti. Alegerea ca dimensiune a elementului de baza de memorie a unei astfel de lungimi ar conduce la risipa de memorie cind se stocheaza tipuri de date necesitind un numar mult mai mic de biti (de exemplu: caractere in cod ASCII).
De aceea se accepta ca dimensiunea celei mai mici entitati de memorie adresabila sa fie cuvintul de 8 biti (octetul), iar toate adresele emise de catre CPU sint adrese de octeti. Pentru accesul la date cu dimensiunea mai mare de un octet, CPU emite adresa primului octet, insotita de semnale de comanda indicind dimensiunea datelor, dimensiune care poate merge pina la cea a cuvintului de date extern. In vederea simplificarii circuitelor de interfata numarul posibil de dimensiuni de date este limitat, fiecare dimensiune (in biti) fiind un divizor al lungimii cuvintului de date extern. Pentru microprocesoarele de 32 biti, dimensiunile uzuale pentru date accesibile intr-un singur ciclu de memorie sint:
- date de 32 biti: long word (cuvint lung);
- date de 16 biti: word (cuvint);
- date de 8 biti: byte (octet);
Uneori se utilizeaza termenul de quad word (cuvint cvadruplu) pentru indicarea de date cu dimensiunea de 64 biti, dar un astfel de tip de date nu poate fi citit/inscris intr-un singur ciclu de acces la memorie. De mentionat faptul ca amintita clasificare reflecta filozofia microprocesoarelor de 16 biti, pentru care 32 biti reprezinta un cuvint "lung", dar terminologia este puternic inradacinata in limbajul curent, asa incit va fi folosita in continuare.
Adresarea la nivel de octet si organizarea cu lungime fixa a cuvintului nu pot solutiona problema accesului la date ce traverseaza frontiera unui cuvint. Asa cum rezulta si din fig. 1.7., in astfel astfel de situatie accesul la date se realizeaza in doua cicluri de acces la memorie. Desigur, se pot intrevedea doua solutii ale problemei:
Fig. 1.7. Date traversind frontiera intre cuvinte in organizarea la nivel de octet
a)evitarea alocarii de date de tipul celor din fig. 1.7.
b)tratarea automata a unor astfel de situatii

In primul caz adresa de inceput a activitatii asociate unui cuvint (word) sau cuvint lung (long word) este fortata sa se supuna unor reguli simple:
- orice cuvint incepe la o adresa para;
- orice cuvint lung incepe la o adresa multiplu de 4.
In al doilea caz nu se mai impun restrictii. La aparitia situatiilor de tipul celor din fig. 1.7. microprocesorul efectueaza automat operatiile de acces, insa acestea dureaza dublu.
1.5.3. Biti si cimpuri de biti
Bitul constituie cea mai naturala reprezentare interna a variabilelor booleene, dar, asa cum s-a demonstrat, datorita consumurilor suplimentare asociate unei astfel de reprezentari, astfel de variabile se reprezinta printr-un octet.
Prin cimp de biti se intelege un sir contiguu de biti in memorie, fara ca sa existe vreo interpretare speciala asociata continutului sirului. Masinile care ofera suport pentru acest tip de date dispun de instructiuni: pentru copierea unui cimp de biti intr-o locatie de memorie sau intr-un registru; de aliniere a cimpului la una din frontierele locatiei in care acesta se afla; de extindere, atunci cind este cazul, a semnului valorii asociate cimpului de biti. Astfel de instructiuni, precum si cele ce efectueaza operatiile inverse folosesc la transformarea formatului valorii cimpului de biti intr-un alt tip de date. De exemplu, copiind un cimp de biti intr-un registru, aliniindu-l la dreapta si extinzindu-i bitul de semn se obtine un intreg cu aceeasi valoare ca cea a cimpului de biti. In felul acesta se pot efectua operatii cu valorile stocate in cimpurile de biti, dupa ce s-a facut conversia de format si, apoi, dupa efectuarea operatiei, s-a readus valoarea rezultata la formatul initial.
Cum s-a mentionat, folosirea cimpurilor de biti de lungime variabila permite stocarea compacta a datelor. Se considera urmatoarea definitie in Pascal a unei inregistrari:
item = record
switch : boolean;
workday : (mon, tue, wed, thu, fri);
count : integer;
cod : 0..1024;
end;
Pentru a stoca in memorie un vector de tip item, harta alocarii memoriei (cind nu se folosesc cimpuri de biti) este cea din fig. 1.8.a. Aria hasurata indica spatiul de memorie irosit intr-o
astfel de reprezentare. Utilizarea cimpurilor de biti permite reprezentarea acelorasi date intr-un mod mult mai compact (fig. 1.8.b.). Linia ingrosata indica frontierele inregistrarilor, iar cea punctata - granitele cimpurilor. Desi economia de memorie este importanta avantajul este anulat de cresterea timpului cerut de accesul la inregistrare sau la un cimp al inregistrarii, fapt datorat depasirii de catre un cimp a frontierelor dintre cuvinte.
Fig. 1.8. Alocarea memoriei pentru o matrice de inregistrari
a. normal; b. utilizind cimpuri de biti
Sint necesare mai multe cicluri de acces la memorie in cazul b decit in cazul a. Totusi, cimpurile de biti isi pastreaza utilitatea cind memorarea compacta a informatiei constituie o necesitate.
Cimpurile de biti au aceleasi avantaje si dezavantaje ca si adresarea la nivel de bit, intrucit ele pot fi utilizate pentru emularea adresarii la nivel de bit pe masini cu lungimi fixe de cuvint si memorie structurata pe octeti. Pentru a defini un cimp de biti sint necesare trei informatii:
a) A - adresa octetului;
b) P - offsetul bitului (primul al cimpului);
c) S - lungimea cimpului
Fig. 1.9. indica un exemplu de utilizare. Primii doi parametri localizeaza primul bit al cimpului. Valoarea offsetului difera de la o masina la alta (fiind mare pentru VAX sau Motorola MC68020). De regula, valoarea maxima a lui S este egala cu dimensiunea cuvintului de date intern.
Fig. 1.9. Exemplu de acces la un cimp de biti
1.5.4. Intregi cu semn si fara semn
Pentru reprezentarea in sistemele cu microprocesoare a valorilor intregi se folosesc doua forme:
a)reprezentarea in complement fata de doi: valoarea X stocata prin intermediul unui sir de n biti X0 X1 ... Xn-1 este data de
n-1
X = ( -X0 + Xi2-i) 2n-1
i=1
X ia valori intre -2n-1 si 2n-1-1;
b)reprezentarea binara pura: valoarea X stocata prin intermediul unui sir de biti X0 X1 ... Xn-1 este data de
n-1
X = Xn-1-i 2i.
i=0
Pentru aceasta reprezentare gama de valori ale lui X este cuprinsa intre 0 si 2n-1.
Trebuie remarcat faptul ca reprezentarea in complement fata de doi permite, spre deosebire de cea in forma binara pura, reprezentarea numerelor negative. In mod obisnuit intregii se folosesc pentru contoare, ca indici ai matricelor si ca adrese de memorie, asa ca alegerea modului de reprezentare este determinata de utilizare. De exemplu adresele se reprezinta in forma binara pura.
Practic toate microprocesoarele dispun de instructiuni care opereaza cu intregi in oricare dintre cele doua forme de reprezentare, cu oricare dintre cele trei lungimi despre care s-a vorbit (octet, cuvint, cuvint lung). Unele microprocesoare pot manipula intregi cu lungimea de 64 biti, iar coprocesoarele matematice folosesc intregi reprezentati pe 80 biti (pentru ca lungimea finita de reprezentare a datelor sa afecteze cu o valoare maxima prestabilita precizia rezultatelor).
1.5.5. Caractere
Cele mai importante tipuri de date manipulate de programe sint texte si numere. In consecinta, toate microprocesoarele dispun de o metoda pentru reprezentarea interna a caracterelor. De regula, fiecarui caracter tiparibil i se asociaza un intreg fara semn (numit cod al caracterului). Aceasta conventie permite folosirea instructiunilor destinate intregilor la manipularea si compararea caracterelor. Cel mai raspindit cod de reprezentare a caracterelor este codul ASCII (American Standard Code for Communication Interchange), fiecarui caracter asociindu-i-se un octet.
O structura de date des utilizata este sirul de caractere (string),echivalent cu un vector de octeti. Lungimea sirului poate fi fixa sau variabila ; cind este variabila se impune utilizarea unui caracter special pentru a indica terminarea sirului sau asocierea cu un contor indicind numarul de caractere al sirului.De cele mai multe ori-in conjunctie cu un astfel de contor- lungimea sirului este limitata la 65.535 ( 216-1, deci reprezentarea pe 16 biti a contorului). Unele microprocesoare pot manipula nu numai siruri de caractere (reprezentate prin octeti),ci si siruri de cuvinte de 16 biti (word) sau 32 biti (longword). Operatiile uzuale cu siruri includ compararea si mutarea. In aceeasi situatie intra si folosirea unui sir drept tabela de conversie (table lookup) in operatii legate de conversii de coduri. Pentru adresarea unui sir sint necesare adresa primului caracter (pentru prelucrare ascendenta) sau a ultimului caracter (pentru prelucrare descendenta), precum si numarul de caractere continute de catre sir.
Dimensiunea sirurilor nu permite pastrarea lor in registrele unitatii centrale de prelucrare, asa ca ele sint manipulate in memorie. La unele microprocesoare informatiile de adresare a sirului trebuie pastrate in registre, deoarece executia instructiunilor referitoare la siruri poate necesita mai multe operatii de acces la aceste informatii , de exemplu pentru incrementarea / decrementarea indicatorului elementului curent al sirului si actualizarea contorului de caractere.
1.5.7. Numere in format binar - codificat zecimal
Considerente legate de viteza de calcul impun reprezentarea interna a numerelor in formatul binar si nu in cel zecimal.Pe de alta parte , utilizatorului ii este mai comod sa foloseasca reprezentarea zecimala , asa ca se impune necesitatea conversiei datelor din formatul zecimal in cel binar (la introducerea datelor) si din cel binar in formatul zecimal (la extragerea datelor). Aceste conversii sint consumatoare de timp, asa ca , uneori, se poate accepta efectuarea de operatii cu numere in forma zecimala (atunci cind aceste operatii nu sint de o complexitate deosebita si volumul de date prelucrate nu este prea mare). Reprezentarea zecimala propriu - zisa este imposibila , deoarece baza de numeratie folosita in sistemele de calcul este 2, asa ca se recurge la o reprezentare apropiata de cea zecimala,numita forma BCD (de la binary - coded decimal -numere zecimale in codificare binara).
Codul BCD foloseste grupe de 4 biti pentru reprezentarea valorii individuale a fiecarei cifre zecimale care compune un numar dat.Deci,reprezentarea BCD a unui numar consta intr-un sir de byte-i de 4 biti, fiecare codificind cifra zecimala corespunzatoare pozitiei byte-ului in sir.
|
Packed BCD |
Unpacked BCD |
||||
|
Hi |
Lo |
Continut |
Hi |
Lo |
Continut |
Pentru stocarea in memorie a formatelor BCD se folosesc doua metode: BCD impachetat (packed BCD) si BCD neimpachetat (unpacked BCD) (Fig. 1.10).
----- ----- ----------- ----- ----- -----------
I 1 0 0 1 I 0 0 0 1 I I 0 0 0 0 I 0 0 0 1 I
I 0 1 0 0 I 0 0 0 0 I I 0 0 0 0 I 1 0 0 1 I
I 0 0 1 1 I 1 0 0 0 I I 0 0 0 0 I 0 0 0 0 I
----- ----- ----------- I 0 0 0 0 I 0 1 0 0 I
I 0 0 0 0 I 1 0 0 0 I
I 0 0 0 0 I 0 0 1 1 I
----- ----- -----------
Fig. 1.10. Reprezentarea numarului 384091 in format BCD
a. impachetat; b. neimpachetat.
Formatul BCD impachetat permite memorarea intr-un octet a doua cifre zecimale. Fata de formatul BCD neimpachetat, care foloseste doar cei patru biti mai putin semnificativi ai octetului pentru a memora o singura cifra zecimala (ceilalti biti sint 0), se obtine o reducere la circa jumatate a spatiului de memorie necesar reprezentarii unui numar dat. Pe de alta parte formatul neimpachetat este mai apropiat de reprezentarea zecimala , ceea ce simplifica operatia de conversie a rezultatelor din forma BCD in cea zecimala.
In general microprocesoarele sint prevazute cu instructiuni pentru operatii aritmetice cu cifre zecimale, si nu cu numere zecimale. Pentru operatii aritmetice cu numere zecimale de mai multe cifre se utilizeaza subrutine dedicate. De asemenea , unele coprocesoare matematice ofera functii de prelucrare a numerelor zecimale.
1.5.7. Matrici
Microprocesoarele nu ofera instructiuni pentru manipularea datelor structurate in matrici (arrays) , insa ele poseda unele moduri de adresare create special in scopul inlesnirii prelucrarii acestor structuri de date.
Limbajele de nivel inalt permit programatorului sa defineasca matrici cu mai multi indici (numarul este limitat superior de caracteristicile compilatorului), elementele matricii putind fi de oricare din tipurile de date, standard sau definite de utilizator. Compilatorul reprezinta aceasta structura multidimensionala de date printr-o matrice unidimensionala de octeti stocati in memorie.Reprezentarea presupune folosirea de n octeti pentru fiecare element, n fiind determinat de tipul elementului. Apoi elementele sint aranjate in memorie incepind de la cea mai mica valoare a indicelui si continuind cu elementele indicate de valorile incrementate ale indicelui, pina la cea maxima. In fig. 1.11 este exemplificata alocarea memoriei pentru o matrice de octeti cu dimensiunea 3x3. Primul indice variaza cu viteza mai mare decit cel de al doilea.
Se pot imagina si alte scheme de alocare obtinute din modificarea ordinii de incrementare a indicilor. Consumul de memorie este acelasi, doar ordinea relativa a elementelor in memorie diferind de la o schema de alocare la alta.
In unele limbaje de programare (de exemplu Pascal), indicii unei matrici pot diferi ca tip, desi ei trebuie sa ia valori intr-o multime discreta si finita, fapt ce permite compilatorului asocierea biunivoca de numere naturale 0,1,...,m-1 la elementele multimii in discutie (m este numarul de elemente ale

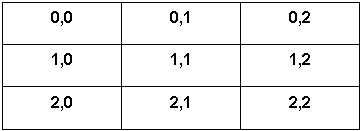
Fig. 1.11 Localizarea in memorie a celor 9 componente ale unei matrici 3x3
acestei multimi).
Alocarea din fig. 1.11 se poate generaliza. Se considera o matrice cu n indici. Adresa a a elementului matricii caracterizat de setul de indici d0,d1,...,dn-1 este data de
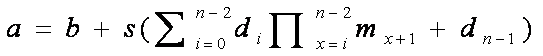
Prin b s-a notata adresa primului octet din zona de memorie alocata matricii.s reprezinta dimensiunea in octet a elementului matricii. mi este numarul de valori posibile ale indicelui i (altfel spus : mi-1 este cea mai mare valoare pe care o poate lua indicele i).
Evaluarea adresei unui element se amplifica in masura considerabila cind se considera o matrice unidimensionala de elemente standard, caci numarul de inmultiri se reduce la una singura, iar unul din factori, dimensiunea in octeti a elementului, este o putere a lui 2 (0,1,2,3,). In consecinta, evaluarea adresei de acces la un element se reduce la o deplasare si o adunare. Unele microprocesoare poseda moduri speciale de adresare care permit efectuarea operatiilor descrise mai sus.
La o prima examinare , evaluarea parantezei din expresia lui a este o operatie complicata , cel putin din punctul de vedere al programarii. Evaluarea se poate face in maniera recursiva :
k0 = 0
ki = ki-1 x mi-1 + di-1 , i = 1,2,...,n
Se poate observa ca valoarea lui kn reprezinta numarul
de elemente precedente celui adresat. Se mai observa ca valoarea maxima a indicelui di-1 este mi-1 - 1. Deci, cunoasterea valorilor ki-1,mi-1,di-1 necesare pasului i al iteratiei permite si testarea validitatii indicelui di-1. In consecinta evaluarea lui ki presupune testarea lui di-1 si apoi evaluarea propriu-zisa, fapt folosit de unele microprocesoare pentru a implementa, intr-o singura instructiune , testarea incadrarii in gama corecta a indicelui si evaluarea lui ki. Prin iteratie se evalueaza numarul de elemente ale matricii care trebuie sarite pentru a se ajunge la elementul dorit. Dupa obtinerea acestui numar se calculeaza adresa prin multiplicarea numarului cu dimensiunea elementului matricii, urmata de adunarea rezultatului cu adresa de inceput a zonei in care este stocata matricea.
1.5.8. Inregistrari
Prin inregistrare (record) se defineste structura de date compusa din variabile heterogene. O variabila a inregistrarii se numeste cimp (field). Un program poate realiza accesul fie la inregistrari, fie la un cimp din cadrul acesteia. In primul caz este convenabil a considera inregistrarea drept un sir de octeti, fapt ce permite mutarea si compararea inregistrarilor cu ajutorul instructiunilor destinate sirurilor. Cind se executa accesul la un cimp, adresa acestuia se obtine adaugind la adresa inregistrarii ce il contine deplasamentul cimpului in cadrul inregistrarii (fig. 1.12).
Fig. 1.12 Acces la un cimp al unei inregistrari Suportul pentru operatii cu inregistrari este oferit de instructiunile destinate sirurilor (pentru operatii cu intreaga inregistrare), si de modurile de adresare utilizind registre baza pentru acces la cimpurile componente ale unei inregistrari.
1.5.9. Comparatie intre microprocesoare
In cele doua tabele care urmeaza sint evidentiate caracteristici privind organizarea memoriei si structuri de date ale unor microprocesoare uzuale. In tabel nu este inclusa structura evoluata iAPX 432 a firmei Intel , dar aceasta, ca si iAPX 286,vor fi discutate in detaliu in capitolele ulterioare.
|
Caracteristica Microprocesorul |
|
iAPX 286 Z 8000 MC 68020 VAX 11 |
|
Unitate minima octet octet octet octet |
|
adresata |
|
Dimensiunea |
|
cuvintului 16 32/16 32/16/8 32 |
|
de date |
|
extern |
|
Dimensiunea |
|
cuvintului 16 32 32 32 |
|
de date |
|
intern |
|
Alinierea |
|
datelor nu da da da |
|
mai lungi de |
|
un octet |
|
Tip de date iAPX 286 Z 8000 MC 68020 VAX 11 |
|
Bit nu da da nu |
|
Cimp de biti nu 1...32 nu 1...32 |
|
Intreg (biti) 8,16 8,16 8,16 8,16,32 |
|
Intreg (complement 32 32,64 32 64 |
|
fata de 2) (64 FPU) |
|
Contor (biti) 8,16 8,16,32,64 8,16,32 8,16,32,64 |
|
Adresa (biti) 16+offset 32 32 32 |
|
Sir (octeti) 1-64k 1-231-1 nu 1-231-1 |
|
Structuri nu nu da da |
|
matrici |
|
ASCII da nu nu nu |
|
BCD neimpachetat da nu da nu |
|
BCD impachetat da da da da |
|
Format virgula FPU FPU FPU da |
|
mobila |
|
Dimensiune format 32,80 32,64,80 32,64,80 32,64 |
|
virgula mobila |
Se poate vedea ca deosebirile sint, in general, minore,aceleasi principii arhitecturale stind la baza tuturor microprocesoarelor atuale.
1.6. Moduri de adresare
Modurile de adresare constituie un instrument principal pentru a reprezenta in memoria masinii imaginea datelor asa cum este aceasta vazuta de programatorul in limbaj de nivel inalt. Ele permit programatorului sa construiasca si sa utilizeze structuri complexe , multidimensionale de date , in timp ce echipamentul poate trata doar matrici lineare cu elemente de dimensiune fixa. Pentru accesul la un element al unei structuri complexe de date trebuie evaluata adresa de memorie corespunzatoare inceputului zonei de memorie in care se pastreaza acel element. De regula, aceasta operatie se efectueaza prin mai multe instructiuni utilizind mai multe moduri de adresare.
Cu cit calculele efectuate in cadrul modului de adresare sint mai complexe , cu atit numarul mediu de instructiuni cerut de accesul la un element al unei structuri complexe de date este mai mic. Avind in vedere ca modurile complexe de adresare lungesc instructiunea ca spatiu ocupat in memorie ,ii maresc timpul de executie si complica arhitectura unitatii de comanda , astfel de instructiuni isi dovedesc utilitatea doar daca sint folosite in mod frecvent.
1.6.1. Elemente de baza privind modurile de adresare.
Marea varietate a modurilor de adresare utilizate de gama de microprocesoare disponibile ofera o caracteristica generala : oricare mod se obtine ca o combinatie intre un numar relativ mic de obiecte (objects) si functii de baza.
Se considera ca un obiect sau o functie sint fundamentale daca, in absenta acelui obiect sau a acelei functii , masina nu este capabila sa emuleze nici un mod de adresare. In consecinta obiectele fundamentale sint constituite din registre si deplasamente (displacement) sau offseturi stocate in instructiune. Functiile fundamentale sint adunarea, deplasarea (shift), adresarea indirecta (indirection). Operatia de deplasare ar putea fi inlocuita de adunari / scaderi, insa timpul care s-ar consuma in acest caz ar fi prea mare , asa incit deplasarea este considerata drept functie fundamentala. Adunarea include si operatiile de incrementare si decrementare , cazuri particulare de adunari.
In continuare obiectele si functiile fundamentale sint considerate cu unele detalii.
Registre. Registrele despre care se vorbeste sint situate in unitatea centrala de prelucrare , in unitatea de aritmetica in virgula mobila (FPU) si in cea de gestiune a memoriei (MMU). In discutarea modurilor de adresare nu se tine cont de unitatea careia un anumit registru apartine. Principalele functii ale registrelor in ceea ce priveste modurile de adresare sint :
- registru operand : continutul registrului este insusi operandul la care se face referire;
- registru adresa : continutul registrului este adresa operandului la care se face referire;
- registru baza : registrul contine o adresa care, pentru obtinerea adresei complete a operandului , se va utiliza in conjunctie cu continutul unui alt registru sau al unui cimp imediat al instructiunii.
Cimp imediat. Cimpul imediat (immediate field) este un anumit cimp,adesea optional , al unei instructiuni , dedicat pastrarii unei informatii ce se va utiliza in determinarea adresei la care se afla operandul in discutie. Cele mai importante utilizari ale cimpului imediat sint :
- operand imediat : continutul cimpului imediat este chiar operandul la care se face referire;
- adresa imediata : continutul cimpului imediat constituie
adresa operandului la care se face referire;
- offset/deplasament : cimpul imediat contine un intreg (in general - cu semn), care se utilizeaza in conjunctie cu continutul unui registru pentru a produce adresa operandului la care se face referire.
Adunarea. Rolul adunarii in adresare este la fel de important ca si in prelucrarea datelor , intrucit toate modurile de adresare , cu exceptia celor mai simple , necesita adunarea a doua sau mai multe valori. Cum s-a mai mentionat , un caz particular al adunarii este incrementarea / decrementarea.
Adresarea indirecta. Adresarea indirecta este o functie al carei argument este dat de rezultatele unor calcule , argument pe care il foloseste pentru a determina - prin adresarea memoriei - operandul la care se face referire. Acest tip de operatie este cel mai frecvent folosit in modurile de adresare , deoarece toate au nevoie de el, cu exceptia acelor moduri de adresare in care operandul se afla in unitatea centrala (intr-un registru al acesteia sau citit implicit o data cu citirea instructiunii).
Modurile complexe de adresare pot folosi de mai multe ori functia de adresare indirecta pentru a obtine adresa finala a operandului.
Deplasarea. Deplasarea se utilizeaza pentru executarea operatiei de indexare. In acest caz indexarea este operatia care produce offsetul unui element din matricea liniara , avind ca baza de plecare indicii elementului. Daca se noteaza cu i indicele (sau indexul) elementului la care se face referire si acceptind ca valoarea cea mai mica a oricarui indice este 0 , offsetul elementului i in cadrul matricii liniare este i * w , unde w este lungimea unui element al matricii. Intr-un caz general, indexarea necesita o inmultire. Cum w are, de regula , valoarea 1,2 sau 4 (exprimata in octeti), inmultirea i * w se face prin deplasarea la stinga a lui i cu un numar de pozitii binare egal cu logaritmul in baza 2 al lui w ( 0, una sau doua pozitii pentru
w = 1,2 sau 4). Deplasarea se face cu mult mai rapid decit inmultirea , ceea ce o recomanda pentru includerea in functiile de baza pentru adresare .
Corelatia mod de adresare - cicluri masina.
Exista o corespondenta intre functiile si obiectele de baza ale modurilor de adresare , pe de o parte , si ciclurile masina necesare adresarii operandului exprimat intr-un anumit mod de adresare , pe de alta parte. In fond , fiecare aplicare a functiei de adresare indirecta produce un ciclu suplimentar de acces la memorie , intrucit rezultatul calculelor anterioare este folosit ca adresa pentru accesul la memorie. Acelasi efect apare si in cazul utilizarii unui cimp imediat, intrucit acesta constituie o componenta a instructiunii, care trebuie citita din memorie. De cele mai multe ori aceste cimpuri sint mai scurte decit lungimea cuvintului de date extern al microprocesorului,asa incit un asemenea cimp este citit in unitatea centrala simultan cu codul operatiei , fara a mai fi necesare cicluri suplimentare de acces la memorie.In general adunarea si deplasarea necesita , fiecare , cite un ciclu al unitatii aritmetice - logice. In unele structuri specializate (barrel-shuffler) adunarea si deplasarea se executa intr-un unic ciclu.
In cele ce urmeaza modurile de adresare se vor descrie prin utilizarea unor relatii algebrice folosind urmatoarele notatii:
g - numele sau numarul unui registru , accesibil programatorului in limbaj de asamblare ;
M(x) - functia de adresare indirecta, aplicata valorii x ;
rezultatul ei este valoarea memorata la adresa x in
memoria principala ;
G(g)-valoarea stocata in registrul g ;
a.sh.b - valoarea rezultata din deplasarea lui a la stinga cu b pozitii binare ;
d - valoarea deplasamentului, memorata intr-un cimp al
instructiunii.
Orice mod de adresare poate fi reprezentat comod in acest fel , fapt ce permite si o comparare concludenta a facilitatilor oferite - in privinta implementarii programelor scrise in limbaje de nivel inalt - de diversele microprocesoare existente
1.6.2. Adresarea directa prin registru
Cel mai simplu mod de adresare este cel care nu necesita aplicarea nici uneia din functiile de baza pentru a obtine valoarea operandului. In aceasta clasa singurul mod de adresare este cel direct prin registru (register operand addressing).
Operandul este stocat in registru , deci nu este necesar un ciclu memorie sau ciclu ALU pentru a-i obtine valoarea. Valoarea operandului este data de G(g). Adresarea directa prin registru reprezinta modul cel mai compact si cel mai rapid de adresare. El este folosit pentru manipularea operanzilor utilizati in mod frecvent in sectiunea curenta a programului , operanzi care sint incarcati in registre in scopul minimizarii timpului de acces.
1.6.3. Adresarea indirecta prin registru
Acest mod de adresare (register indirect addressing) utilizeaza continutul registrului g, specificat in instructiune , pentru a adresa operandul , asa cum se vede in figura 1.13. Valoarea operandului este data de M(G(g)). Intrucit se utilizeaza o operatie de adresare indirecta, extragerea operandului necesita un ciclu suplimentar de memorie.
Adresarea indirecta prin registru este folositoare pentru accesul la elementele structurilor complexe de date , altfel inaccesibile doar cu unicul mod de adresare permis de masina. Calculul adresei, disponibila - in final - in registrul in discutie , necesita o secventa de instructiuni al caror rezultat este adresa elementului solicitat.

Fig 1.13. Adresarea indirecta prin registru 1.6.4. Adresarea cu autoincrementare / autodecrementare.
Acest mod de adresare (autoincrement/decrement addressing), extrem de important, constituie baza modurilor de adresare implementate in oricare calculator. In mod normal , acest mod de adresare este utilizat in conjunctie cu indicatorul de stiva si cu contorul programului.
Adresarea cu autoincrementare / autodecrementare functioneaza intr-un mod similar cu adresarea indirecta prin registru , intrucit registrul g, specificat explicit sau implicit in instructiune , contine adresa operandului. In plus fata de modul precedent , continutul registrului este incrementat / decrementat cu o cantitate determinata de lungimea operandului la care se realizeaza accesul. In general , acest mod de adresare este utilizat pentru intregi , asa ca valoarea incrementului este 1,2,4 sau 8.
Din considerente evidente autoincrementarea continutului registrului este efectuata dupa accesul la operand , iar decrementarea continutului registrului se face inainte de accesul la operand. Decurg de aici doua moduri de adresare : cu postincrementare si cu predecrementare.
In modul de adresare cu postincrementare are loc operatia de adresare indirecta
M(G(g))
urmata de incrementarea cu N :
G(g): = G(g) + N
In modul de adresare cu predecrementare are loc predecrementarea cu N :
G(g) : = G(g) - N
urmata de adresarea indirecta:
M(G (g))
Cele doua moduri de adresare sint reprezentate schematic in fig. 1.14.
Este de mentionat ca modurile de adresare cu postincrementare si predecrementare sint singurele care au efecte secundare , manifestate in modificarea continutului registrului g. Aceasta modificare este de dorit , deoarece ea permite accesul secvential in ordine ascendenta la memoria program (postincrementare) , precum si implementarea comoda a mecanismului de stiva LIFO (last

Fig. 1.14. Adresarea cu autoincrementare/autodecrementare
in - first out), indispensabil pentru buna functionare a sistemului de intrerupere , precum si pentru operarea cu subrutine.
Adresarea cu postincrementare permite si obtinerea modului de adresare numit "adresarea imediata a operandului" , folosita de toate microprocesoarele pentru a introduce constante in sirul de instructiuni. Adresarea imediata a operandului se obtine prin utilizarea adresarii cu postincrementare si specificind contorul programului drept registru de utilizat pentru adresare. Acest mod de adresare permite prelucrarea de instructiuni compuse din mai multe cuvinte.
Statistic s-a constatat ca operanzii imediati pentru limbajele de nivel inalt au diverse lungimi [3]. Pentru a se scurta lungimea medie a instructiunii la o serie de microprocesoare s-a acceptat posibilitatea specificarii mai multor formate pentru operanzii imediati : ( Z 8000, MC 68000). In cazul operanzilor de lungime mica este posibila stocarea lor in acelasi cuvint care contine codul operatiei , deci accesul se face fara consum suplimentar de cicluri de memorie. Se constata ca operanzii imediati sint constante care nu se modifica prin program. Pentru variabile se folosesc alte moduri de adresare.

1.6.5. Adresarea indirecta cu autoincrementare / autodecrementare
Acest mod (autoincrement/autodecrement indirect addressing) se poate obtine prin aplicarea unei adresari indirecte suplimentare
Fig. 1.15 Adresarea indirecta cu postincrementare modului normal de adresare cu autoincrementare /autodecrementare. Fig. 1.15 reprezinta adresarea indirecta cu postincrementare.
Functionarea in modul de adresare indirecta cu postincrementare presupune dubla adresare indirecta
M(M(G(g))),
urmata de postincrementarea cu N a continutului registrului g :
G (g) := G (g) + N
In modul de adresare indirecta cu predecrementare are loc decrementarea cu N a continutului registrului g
G (g) := G (g) - N ,
urmata de o dubla adresare indirecta M ( M ( G (g))).
Ca la orice adresare cu autoincrementare / autodecrementare se manifesta efectul secundar de modificare a continutului registrului g folosit pentru adresare.
In cazul particular in care adresarea indirecta cu postincrementare foloseste ca registru contorul programului se obtine adresarea directa , mod de adresare existent in toate microprocesoarele. La adresarea directa adresa operandului este memorata ca un cimp al instructiunii. Dupa citirea codului instructiunii ( realizata prin modul de adresare cu postincrementare ) contorul programului indica urmatorul cimp al instructiunii. Adresarea indirecta cu postincrementare permite accesul la operand si actualizarea contorului programului. Intrucit microprocesoarele de 8 si 16 biti au lungimea cuvintului de adresa mai mare decit lungimea cuvintului de date , sint necesare mai multe cicluri de acces la memorie pentru citirea adresei operandului.
Adresarea directa specifica adresa operandului ca parte componenta a instructiunii, care se stabileste in momentul compilarii si nu mai poate fi schimbata in timpul executiei programului. Asa cum s-a vazut , limbajele de nivel inalt care folosesc recursivitatea nu pot folosi adresarea directa ca urmare a dinamicii adreselor in procesul de recursivitate. Cu exceptia variabilelor globale , celelalte variabile au adrese alocate in timpul rularii pentru programele recursive , adrese care nu se pot insera in codul instructiunii.
Utilizarea adreselor stocate in codul instructiunii este legata de operatiile de salt sau apeluri de subrutine , deci nu de specificarea de variabile propriu - zise.
1.6.6. Adresarea indirecta bazata si cu deplasament
S-a denumit registru baza registrul al carui continut se aduna cu un obiect manipulat de catre modul de adresare, cu scopul determinarii adresei operandului. Modul de adresare bazat si cu deplasament (base displacement indirect addressing) calculeaza adresa operandului prin insumarea continutului registrului baza specificat cu valoarea unui cimp al instructiunii, numit deplasament ( fig. 1.16):
M ( G(g) + d )
Fig. 1.16. Adresarea indirecta bazata si cu deplasament
Se subliniaza faptul ca obtinerea deplasamentului presupune un ciclu de memorie si incrementarea contorului programului, ceea ce face ca numarul de cicluri de acces la memorie necesare pentru obtinerea operandului sa fie 2. Operatiile efectuate sint adunarea si incrementarea. Si aici trebuie avut in vedere faptul ca lungimea deplasamentului poate fi variabila , ceea ce poate rezulta in necesitatea unui ciclu suplimentar de memorie, sau, dimpotriva, la diminuarea numarului de cicluri de memorie impus de obtinerea operandului.
Adresarea bazata cu deplasament este foarte potrivita pentru executarea programelor scrise in limbaj de nivel inalt , pentru ca ofera un mod natural de adresare a scalarilor. Pentru ilustrare se poate considera exemplul din fig 1.4c
De asemenea , adresarea bazata solutioneaza problema de adresare a variabilelor si a informatiilor de comanda. Sectiunea de cod in limbaj de asamblare destinata implementarii apelarii procedurii specifica un anumit registru , de uz general sau specializat , pentru a indica inceputul noului cadru. Acest registru se numeste indicator al cadrului local (local frame pointer ). In continuare compilatorul poate genera instructiuni de acces la variabilele locale prin utilzarea indicatorului cadrului local drept registru baza. Deplasamentul este dat de suma lungimilor cimpului si variabilelor ce preced variabila adresata. Fig. 1.17 ilustreaza acest mod de adresare, cu referire la exemplul din fig. 1.4c.
Fig. 1.17. Acces la variabilele locale (stinga) si nelocale (dreapta).
Din aceeasi figura 1.17. se vede cum se poate efectua accesul la variabilele nelocale. Mecanismul este similar cu cel al adresarii variabilelor locale, dar indicatorul cadrului in care se afla variabila se obtine din cimpul de afisare. Informatia din cimpul de afisare poate fi considerata ca o variabila locala normala, deci ea poate fi copiata intr-un registru prin evaluarea deplasamentului sau in cadrul curent si folosind modul de adresare bazata cu deplasament , avind indicatorul cadrului local drept registru baza. Informatia din registru ( notata Rg in figura ) reprezinta indicatorul catre cadrul care contine variabila nelocala , iar adresarea variabilei dorite decurge conform mecanismului descris.
Aproape intotdeauna indicatorul cadrului local este pastrat intr-un registru , deoarece el reprezinta informatia-cheie pentru accesul la toate variabilele locale , iar probabilitatea de a le utiliza in cadrul procedurii este mare. Un alt indicator de cadru , si el pastrat , de regula , intr-un registru , este cel indicind spre variabilele globale , la care orice procedura are acces. In fine , un al treilea registru este rezervat pentru stocarea indicatorului catre un eventual cadru situat intre cadrul programului principal si cel al procedurii locale.
Adresarea indirecta bazata si cu deplasament este frecvent utilizata pentru accesul variabilelor atit locale , cit si nelocale , cu conditia ca aceste variabile sa fie scalari. In structurile complexe de date acest mod de adresare furnizeaza doar adresa de inceput a zonei de memorie alocate intregii structuri. Pentru localizarea unui element sint necesare calcule suplimentare.
Situatiile in care contorul programului este folosit drept registru baza sint numite adresari relative, intrucit cimpul din instructiune indica pozitia relativa a operandului in raport cu adresa la care se afla instructiunea. Acest mod de adresare impune utilizarea unui intreg cu semn pentru deplasament , in timp ce in alte moduri deplasamentul este un numar pozitiv. Necesitatea deplasamentului cu semn este mai stringenta pentru instructiunile de salt.
1.6.7. Adresarea dublu indirecta bazata si cu deplasament.
Acest mod de adresare (base displacement indirect indirect addressing) se obtine prin aplicarea unei a doua functii de adresare indirecta rezultatului adresarii indirecte bazate si cu deplasament. El se descrie astfel :
M ( M(G(g)+d)).
In fig.1.18 se poate vedea, schematic , modul de evaluare a adresei operandului in adresarea dubla indirecta bazata si cu deplasament.
Fig. 1.18. Adresarea dublu indirecta bazata si cu deplasament
Modul de adresare descris este utilizabil pentru adresarea variabilelor la care referirea se face prin intermediul unui indicator. Intrucit registrul baza este intotdeauna utilizat pentru a indica adresa de inceput a cadrului , deplasamentul corespunde pozitiei indicatorului variabil in interiorul cadrului. Dubla adresare indirecta este folosita intii pentru a obtine valoarea indicatorului si, apoi, valoarea operandului propriu-zis. In fig. 1.19. se arata utilizarea modului de adresare cu dubla adresare indirecta pentru obtinerea unei variabile din stiva neordonata (heap) prin intermediul variabilei indicator p.
O alta aplicatie tipica a modului de adresare descris mai sus este realizarea accesului la parametrii procedurii transferate prin referire. In astfel de aplicatii in interiorul procedurii se stocheaza nu valoarea ci adresa parametrului. In consecinta , prin adresarea indirecta bazata cu deplasament se obtine doar adresa parametrului , obtinerea valorii lui necesitind o noua adresare indirecta.
Fig. 1.19 Accesul la o variabila cu ajutorul unui indicator p
1.6.8. Adresarea indirecta bazata indexata
Cele mai simple structuri cu care opereaza limbajele de nivel inalt sint matricile liniare de scalari. In general , scalarii se reprezinta prin cimpuri de memorie de 8, 16 sau 32 biti. Calcularea deplasamentului unui element in cadrul matricii liniare se obtine prin deplasarea la stinga a numarului ce reprezinta indicele (indexul) unui element cu 0, 1, sau , respectiv 2 pozitii binare , presupunind ca valoarea initiala a indicelui este 0. Unele compilatoare , cum sint cele pentru limbajul Pascal , permit programatorului sa foloseasca indici care nu sint intregi. Totusi , compilatorul ii converteste intern in intregi , dupa cum aceeasi operatie de conversie are loc si atunci cind indicii sint intregi , dar valoarea initiala nu este 0. In primul caz indicele intreg rezultat este dat de pozitia intr-o multime ordonata a indicelui neintreg ; in cel de al doilea conversia presupune o simpla scadere.
Adresarea indirecta indexata bazata (base indexed indirect addressing) este in masura sa efectueze imediat calculele cerute de indexare, precum si operatia de adunare a deplasamentului cu adresa de baza a structurii de date. Acest mod de adresare necesita doua registre : g1 si g2 . g2 contine indicele elementului in matrice (registru index). Continutul sau este deplasat la stinga cu 0, 1 sau 2 pozitii binare, in functie de tipul operandului manipulat de catre instructiune. Dupa efectuarea operatiei de deplasare , rezultatul este adunat cu continutul registrului g1 , care contine adresa de inceput a matricii ; aceste operatii sint caracterizate de functia
M( G(g1) + G(g2).Sh. N)
si sint reprezentate in fig. 1.20
Fig. 1.20 Adresarea indirecta bazata indexata
Modul de adresare indirecta indexata bazata este folosit pentru accesul la un element al unei matrici unidimensionale de scalari, stocata intr-o zona de memorie a carei adresa de inceput este continuta in registrul baza.
1.6.9. Adresarea indirecta indexata cu postincrementare
Modul de adresare din titlul paragrafului (postincrement indexed indirect addressing) se obtine din modul de adresare indirecta indexata bazata prin adaugarea unei operatii de incrementarea continutului unuia din cele doua registre, operatie efectuata dupa extragerea operandului. Deci, continutul registrului g2 se deplaseaza la stinga cu 0,1 sau 2 pozitii binare ; rezultatul se aduna cu continutul registrului g1, obtinindu-se adresa operandului ; in fine,continutul registrului g1 se incrementeaza cu valoarea N1, egala cu 1,2 sau, respectiv, 4. Fig. 1.21 indica procesul de evaluare , care se desfasoara dupa relatiile
M( G(g1) + G(g2).sh.N),
G(g1) := G(g1) + N
Fig. 1.21 Adresarea indirecta indexata cu postincrementare
1.6.10. Adresarea indirecta indexata cu predecrementare
Acest mod de adresare (postdecrement indexed indirect addressing) este similar cu cel anterior ; deosebirea consta in predecrementarea , in loc de postincrementarea registrului g1 ( fig. 1.22 ) :
G (g1) := G (g1) - N
M (G (g1) + G (g2).sh.N)
Fig. 1.22 Adresarea indirecta indexata cu predecrementare
1.6.11. Adresarea indirecta indexata bazata si cu deplasament
Modul de adresare din titlul paragrafului (base displacement indexed indirect addressing) necesita trei obiecte : un registru baza g1, un deplasament d stocat intr-un cimp al instructiunii si un al doilea registru g2, registru index. Continutul registrului g2 este deplasat la stinga cu N pozitii binare (N = 0,1 sau 2), in functie de tipul operandului manipulat de catre instructiune . La acest rezultat se aduna deplasamentul d si adresa de baza G(g1) continuta de registrul g1 (fig. 1.23).
M ( G(g1) + d + G(g2). sh.N )
Adresarea indirecta indexata bazata si cu deplasament este o metoda mai buna de acces la elementele unei matrici unidimensionale de scalari , atit fata de metoda de adresare indirecta bazata cu deplasament , cit si fata de cea de adresare indirecta indexata bazata. Daca g1 contine indicatorul cadrului local , indicele elementului matricii este continut de g2 , iar d indica deplasamentul in interiorul cadrului al adresei de inceput a zonei de memorie ce contine elementele matricii , modul de adresare indirecta indexata bazata si cu deplasament permite accesul intr-o singura instructiune al oricarui element al matricii locale unidimensionale de scalari. Un exemplu este cel din fig. 1.24.
Fig. 1.23 Adresarea indirecta indexata bazata si cu deplasament
Fig. 1.24. Acces la un element al unei matrici locale utilizind adresarea indirecta indexata bazata si cu deplasament 1.6.12. Adresarea indirecta indexata indirect cu postincrementare
Pentru acest mod de adresare (postincrement indirect indexed indirect addressing) se folosesc doua registre : registrul baza g1 si registrul index g2. Continutul lui g1 permite adresarea si citirea continutului unei locatii de memorie. Acest continut se aduna la rezultatul deplasarii spre stinga cu N2 pozitii binare a continutului registrului g2 ( N2 = 0,1 sau 2). In felul acesta se obtine adresa operandului. In final , continutul registrului g1 este incrementat cu N1 unitati ; valoarea lui N1 depinde de dimensiunea adresei. Evident , nu exista legatura intre N1 si N2.
Cele de mai sus sint ilustrate de fig. 1.25 si sintetizate de relatiile
M ( G(g1) + G(g2).sh.N1 )
G (g1) : = G (g1) + N
Accesul la operand necesita doua cicluri de acces la memorie , o adunare si o deplasare.
Fig. 1.25 Adresarea indirecta indexata indirect cu postincrementare 1.6.13. Adresarea indirecta indexata indirect bazata cu deplasament
Modul de adresare de mai sus (base displacement indirect indexed indirect addressing) necesita trei obiecte : registrul baza g1 , registrul index g2 si deplasamentul d, memorat intr-un cimp al instructiunii. Continutul M (g1) al lui g1 se aduna cu deplasamentul d. Rezulta o adresa a unei zone de memorie , care contine , la rindul sau , o adresa. Aceasta din urma se insumeaza cu continutul G (g2) al registrului g2 , deplasat in prealabil la stinga cu N pozitii binare ( N = 0,1 sau 2 ). Rezultatul constituie adresa operandului la care se face referire :
M ( M ( G(g1) + d ) + G (g2).sh. N )
Figura 1.26 serveste drept ilustrare.
Fig. 1.26 Adresarea indirecta indexata indirect bazata cu deplasament
Un posibil caz de utilizare a acestui mod de adresare este cel in care se cere accesul la un element al unei matrici unidimensionale de scalari , indicat prin intermediul unei variabile. Matricile transferate ca parametri ai procedurii au adresele de inceput stocate in cimpul de parametrii ai cadrului procedurii curente. Accesul la un element se obtine prin incarcarea in g1 a indicatorului cadrului local ; deplasamentul indica pozitia in cadrul curent a inceputului zonei de memorie care contine matricea , iar g2 contine indicele elementului la care se face referire. Pentru exemplificare se poate considera fig. 1.27.
Fig1.27. Adresarea unui vector transferat ca parametru utilizind adresarea indirecta indexata indirect bazata cu deplasament
1.6.14. Adresarea indirecta cu deplasament indirect bazata si cu deplasament
Acest mod de adresare (base displacement indirect displacement indirect addressing) foloseste doua deplasamente d1 si d2 , stocate in doua cimpuri ale instructiunii , si un registru baza g. Continutul G (g) al registrului g se aduna cu deplasamentul d1. Rezulta adresa unei zone de memorie , care contine o adresa. Aceasta din urma se aduna cu d2 pentru a furniza adresa operandului la care se face referire :
M ( M (G(g) + d1 ) + d2 )
Grafic, modul de adresare este prezentat in fig. 1.28.
Fig. 1.28. Adresarea indirecta cu deplasament indirect bazata si cu deplasament
Acest mod de adresare permite accesul intr-o singura instructiune la scalari nelocali. Indicatorul cadrului local este incarcat in g. d1 reprezinta deplasamentul ( in cadrul cimpului de afisare al cadrului curent ) indicatorului spre cadrul in care se afla variabila la care se face referire. In fine , d2 reprezinta deplasamentul in interiorul cadrului a scalarului referit (fig. 1.29). Un alt fel de utilizare permite accesul la un cimp al unei inregistrari locale la care referirea se face cu ajutorul unui indicator. In acest caz d1 este deplasamentul indicatorului in interiorul cadrului, iar d2 este deplasamentul (fata de inceputul zonei ce contine inregistrarea, inceput specificat prin indicatorul obtinut prin M ( G(g) + d1) ) al cimpului la care se face referire.
Fig. 1.29. Accesul la un operand nelocal (stinga) sau la un cimp dintr-o inregistrare (dreapta) cu ajutorul unui indicator
1.6.15. Adresare indirecta indexata cu deplasament indirect bazata si cu deplasament
Modul de adresare numit in titlul paragrafului (base displacement indirect displacement indexed indirect addressing) foloseste patru obiecte : registrul baza g1, registrul index g2 si deplasamentele d1 si d2 , memorate in cimpuri ale instructiunii. Relatia de acces la operand este M ( M ( G(g1) + d1 ) + d2 + G(g2).sh.N )
La continutul G (g1) al registrului g1 se aduna deplasamentul d1, obtinindu-se adresa unei zone de memorie ce contine o adresa. Aceasta din urma se insumeaza cu deplasamentul d2 si cu G(g2).sh.N , continutul G(g2) al registrului g2 deplasat in prealabil spre stinga cu N pozitii binare ( N = 0,1, sau 2). Accesul se realizeaza prin consumul a doua cicluri de memorie si prin efectuarea a 3 adunari si o deplasare. Schematic , adresarea este prezentata in fig. 1.30.
Fig. 1.30. Adresare indirecta indexata cu deplasament indirect bazata si cu deplasament
Modul de adresare descris permite accesul la matrici unidimensionale nelocale de scalari , fapt datorat adaugarii indexarii la modul de adresare indirecta cu deplasament indirect bazata si cu deplasament. In g1 se incarca indicatorul cadrului local. d1 este deplasamentul indicatorului (din cimpul de afisare ) catre cadrul ce contine matricea de interes. d2 da deplasamentul in cadrul de interes al inceputului zonei de memorie ce contine matricea , iar g2 contine indicele elementului la care se face referire. (fig. 1.31)
Fig. 1.31. Acces la un element al unui vector nelocal
1.6.17. Concluzii privind modurile de adresare
Modurile de adresare se pot grupa in trei mari categorii :
a. moduri simple, cum sint cele de adresare cu operandul in registru, indirect prin registru, imediata sau directa;
b. moduri in care procesul de evaluare a adresei presupune adunarea continutului unui registru cu unul sau doua deplasamente, continute in cimpuri ale instructiunii, fiind,eventual, posibila si utilizarea unei functii de indexare;
c. moduri in care procesul de evaluare a adresei necesita adunarea continuturilor unuia sau ale mai multor registre, eventual si cu folosirea unei functii de indexare, urmata de incrementarea, sau precedata de decrementarea continutului unuia din registrele implicate.
In general, toate sistemele de calcul folosesc modurile simple de adresare, care reprezinta modurile de baza de adresare a operanzilor, toate acestea fiind utile pentru executia programelor scrise in limbaj de nivel inalt. Face exceptie modul de adresare directa, folositor doar pentru segmentul de cod.
Modurile de adresare cu registru baza si deplasament sint adecvate pentru programele in limbajele de nivel inalt care permit recursivitatea,care, asa cum s-a aratat mai inainte, necesita alocarea dinamica a variabilelor definite in interiorul procedurilor sau functiilor. Alocarea dinamica nu permite compilatorului sau editorului de legaturi sa insereze in cod adresele variabilelor manipulate. La momentul compilarii singura informatie disponibila despre amplasarea variabilelor este deplasamentul acestor variabile in cadrul zonei de memorie sau cadrului rezervat pentru procedura in care sint definite. De aici decurge utilitatea unui registru baza, care pastreaza adresa de inceput a cadrului, si a modurilor de adresare ce folosesc acest registru si deplasamentul inserat in cod de catre compilator.
Modurile de adresare cu postincrementare/predecrementare sint foarte asemanatoare cu unele moduri de adresare ce folosesc registrul baza, diferenta constind in incrementare/decrementare in locul adunarii cu valoarea deplasamentului. Postincrementarea simpla este folosita de toate microprocesoarele pentru extragerea instructiunilor, ca si pentru modurile de adresare imediata si directa. Autoincrementarea/autodecrementarea sint folosite si in legatura cu stiva, pentru extragerea/introducerea de date in stiva. Nu toate registrele unitatii centrale permit adresarea in autoincrementare/autodecrementare.
Aceleasi operatii de autoincrementare/autodecrementare sint folosite si pentru implementarea operatiilor cu siruri, care necesita incrementarea automata a indicatorului sirului. Modurile complexe bazate pe autoincrementarea registrelor folosesc, de exemplu, pentru manipularea unui bloc de operanzi ale caror adrese sint memorate intr-un sir de locatii contigue. Desi de o mai mare utilitate, modurile de adresare utilizind registre baza conduc la scaderea vitezei de executie drept urmare a ciclurilor suplimentare de memorie cerute de obtinerea valorii deplasamentului. O cale de diminuare a scaderii performantei consta in utilizarea celor mai scurte deplasamente posibile.
1.7.1. Codificarea instructiunilor
Orice program executabil consta dintr-o secventa de instructiuni acceptabile de catre masina. Orice instructiune masina contine doua tipuri de informatie: operatia ce urmeaza a se executa si unde anume se localizeaza - in registre sau memorie - rezultatul operatiei. De regula aceste informatii sint codificate in cimpuri diferite ale instructiunii, asa ca numarul de cimpuri ale unei instructiuni este in general, de trei. O instructiune are structura urmatoare :
a) codul operatiei ce se executa (opcode) ;
b) specificarea modului de adresare pentru operanzii de intrare si pentru rezultat;
c) datele ce se utilizeaza in calculul adresei de catre modurile de adresare specificate.
Instructiunile masina au diferite lungimi, depinzind de numarul de operanzi si modurile de adresare utilizate. Numarul de operanzi ce se specifica trebuie mentinut la o valoare cit de mica pentru a lucra cu instructiuni de dimensiuni mici. Daca operatia efectuata de catre o instructiune necesita n operanzi de intrare pentru a produce un rezultat, este necesara specificarea a n+1 moduri de adresare si a unui numar de pina la n+1 deplasamente.
Un mod uzual de scurtare a lungimii medii a instructiunii este cel in care unul din operanzii de intrare este folosit si ca destinatia rezultatului. Aceasta solutie limiteaza capacitatea de adresare prin fortarea stocarii rezultatului la adresa unuia din operanzii de intrare, dar are ca efect o importanta reducere a consumului de memorie.
Un studiu efectuat asupra limbajului Fortran [4] a indicat ca majoritatea instructiunilor de asignare sint de forma A:=A op B, unde op reprezinta operatia efectuata cu cei doi operanzi A si B. Din aceste motive,toate microprocesoarele,cu exceptia lui VAX 11,
folosesc adresa unuia din operanzii de intrare pentru memorarea rezultatului. VAX 11 are instructiuni cu trei adrese pentru operatii implicind doua intrari.
1.7.2. Ortogonalitate
Modurile de adresare si seturile de instructiuni se numesc ortogonale cind procesorul permite orice combinatie posibila de moduri de adresare si coduri de operatii, cu exceptia acelor combinatii care sint lipsite de sens. Ortogonalitatea este o caracteristica de dorit a instructiunilor, intrucit ea simplifica activitatea generatorului de cod al compilatorului prin evitarea folosirii de restrictii asupra combinatiilor cod al operatiei - mod de adresare. In acelasi timp ortogonalitatea conduce la cresterea lungimii medii a instructiunii. Cresterea este impusa de necesitatea prevederii unor cimpuri de biti de lungime fixa, independenta de modul de adresare, pentru specificarea modului de adresare pentru fiecare operand al instructiunii. Se mai adauga si posibilitatea mai multor operanzi imediati, adrese sau deplasamente in instructiune.
La microprocesoarele de 8 sau 16 biti s-a adoptat conventia ca unul din operanzi sa fie continut de un registru al unitatii centrale, celalalt fiind adresat in orice mod posibil. Solutia are avantajul ca adresa operandului din registru se specifica simplu, prin numarul registrului respectiv. De asemenea, numarul de operanzi imediati, adrese sau deplasamente intr-o instructiune se reduce la unu.
Se mai pot da si alte solutii: numai un subset de instructiuni (de exemplu cele folosite pentru transferul datelor) poate utiliza toate modurile de adresare, in timp ce restul instructiunilor folosesc numai combinatii permise.
Desi ortogonalitatea este o caracteristica dezirabila, seturile de instructiuni ale microprocesoarelor existente se abat - in masura mai mica sau mai mare - de la cerintele ei, fapt ce conduce la cod mai compact, dar si la mai mari dificultati de realizare a compilatoarelor cu optimizare.
1.7.3. Operatii speciale
In cele ce urmeaza se discuta acele instructiuni care faciliteaza implementarea de operatii tipice programelor scrise in limbaje de nivel inalt. Desi aceste instructiuni nu sint singurii factori care contribuie la eficienta de rulare a programelor, ele se refera la un set de operatii caracteristice programelor scrise in limbaje de nivel inalt si care se regasesc in alte tipuri de programe.
1.7.3.1. Apeluri de proceduri
Intr-un paragraf anterior s-a ilustrat mecanismul de apelare a procedurii intr-un limbaj permitind programarea recursiva. In cadrul acestui mecanism se disting mai multe faze:
- alocarea de memorie pentru noul cadru;
- construirea noului cimp de afisare prin copierea valorilor corespunzatoare din cadrul programului sau procedurii chematoare si adaugarea unui nou indicator ( daca procedura apelata este definita in interiorul celei chematoare ;
- saltul la subrutina ;
-salvarea in zona dedicata a contextului, adica a continutu- rilor acelor registre care sint utilizate de catre procedura apelata.
Din operatiile listate mai sus doar saltul la subrutina se afla in setul de instructiuni al oricarui microprocesor, chiar si al celor din epoca de inceput. Microprocesoarele recent elaborate sint prevazute cu instructiuni suplimentare, care sa ofere suport pentru toate fazele de apelare a procedurii. In tabelul de mai jos sint indicate facilitatile oferite de unele tipuri de procesoare in privinta apelarii de proceduri.
|
Operatia iAPX 286 Z 8000 MC 68020 VAX 11 |
|
JSR ENTER CALL ENTER JSR ENTER CALL |
|
Alocarea X X X |
|
cadrului |
|
Salt de X X X X |
|
subrutina |
|
Crearea |
|
zonei de X X X X |
|
afisare |
|
Salvare X |
|
registre |
X marcheaza facilitatile oferite de un anumit procesor.
1.7.3.2 Referirea elementelor matricilor
Metodele de alocare si acces la elementele unei matrici multidimensionale au fost prezentate intr-un paragraf anterior, in care s-a indicat si un algoritm iterativ pentru evaluarea in n pasi adresa unui element al unei matrici cu n dimensiuni, calcul necesitind valorile indicilor elementului referit. In cele ce urmeaza sint prezentate unele elemente legate de testarea incadrarii in limitele impuse a valorii unui indice al elementului matricii. Daca asemenea teste se pot face cu consumuri mici de resurse, in special timp, ele sint de recomandat, deoarece au ca efect cresterea fiabilitatii programelor prin eliminarea operatiilor de acces la elemente inexistente.
S-a indicat posibilitatea transformarii de catre compilator a unui set de n indici intr-un numar k cuprins intre 0 si M-1, unde M este produsul numerelor de valori ale fiecaruia din cei n indici. Microprocesoarele moderne permit testarea valorii k prin compararea sa cu M-1, iar unele din acestea testeaza si semnul lui k (cele doua limite, 0 si M-1, sint parametri ai instructiunii de testare). In aceasta a doua categorie intra procesoarele Z8000 si VAX 11. In plus iAPX 286 face, in aceeasi instructiune, atit evaluarea lui m, cit si testarea incadrarii sale sub limita superioara.
|
