Motoare de cãutare
La mijlocul anului 1999 se estima cã Internetul conþine aproximativ 800 de milioane de pagini cu informaþii accesibile publicului larg. Numãrul paginilor a crescut în ultimii ani exponenþial ºi se estimeazã triplarea numãrului lor în urmãtorii doi ani.
Cãutarea pe Internet poate fi privitã ca o cãutare într-un catalog imens, unde cãrþile ºi revistele nu sunt grupate în nici o ordine, fãrã nici o referire într-un catalog central.
Majoritatea motoarelor de cãutare oferã douã tipuri de cãutãri: de bazã (basic) ºi avansat (advanced). În modul de cãutare de bazã cãutarea se relizeazã foarte simplu; se introduce cuvântul cheie dupã care se doreºte sã se facã cãutarea ºi, eventual, se pot alege unele din opþiunile oferite de motorul de cãutare respectiv, cãutarea putând deveni chiar complexã.
Cãutarea avansatã diferã de la un motor de cãutare la altul, dar aproape toate oferã posibilitatea de cãutare dupã mai multe cuvinte, de conferire a unei prioritãþi mai mari unui cuvânt decât altuia ºi excluderea cuvintelor care pot afecta rezultatul cãutãrii. Multe motoare de cãutare aplicã automat operatorul boolean AND în cazul cãutãrii dupã mai multe cuvinte cheie.
Unele motoare de cãutare oferã posibilitatea de cãutare în nume proprii, în fraze, de cãutare a cuvintelor care apar la o anumitã apropiere de alþi termeni daþi. De asemenea, unele motoare de cãutare permit specificarea locului în care sã se facã cãutarea, de exemplu în URL sau titlul paginii web indexate, sau precizarea modului în care sã aparã rezultatele.
Aproape toate motoarele de cãutare permit cãutarea folosind operatorii booleeni (AND, OR, NOT) ºi aºa numiþii operatori de apropiere (NEAR, FOLLOWED BY).
În momentul formãrii paginii rezultat sunt afiºate toate paginile pe care motorul de cãutare considerã cã existã cuvintele cheie cãutate. În unele situaþii rezultatul cãutãrii poate stârni confuzia pentru un utilizator. Acest lucru se întâmplã pentru cã motoarele de cãutare nu au ajuns, încã, la punctul în care oamenii ºi calculatoarele se înteleg destul de bine pentru a comunica corect. Deci, dacã cuvântul cheie dupã care se efectueazã cãutarea este unul comun, cu înþelesuri multiple, este foarte posibil ca în rezultatul cãutãrii sã aparã paginii fãrã relevanþã pentru utilizator.
Cãutarea în fiºiere text este utilã în cazul în care utilizatorii executã cãutãri doar în anumite fiºiere predefinite. Un server Web bine fãcut include posibilitatea de cãutare a informaþiilor dupã cuvinte cheie pe tot serverul, inclusiv în fiºiere text ºi HTML.
Documentarea farã pãrãsirea propriului birou pare o idee excepþionalã, însã, adesea, se întâmplã sã ne irosim timpul urmãrind URL-uri inutile. Din acest motiv trebuie sã gândim o strategie dupã care sã efectuam cãutarea. Un lucru util ar fi sã ne gândim la vechi cataloage sau chiar la cataloagel 414f56e e actuale existente pe computer, unde cãutarea se efectueazã dupã autor, titlu sau subiect.
Pe marile motoare de cãutare existã o structurare pe domenii, cum ar fi: artã, afaceri ºi economie, calculatoare ºi Internet, educaþie, divertisment, guvern, sãnãtate, ºtiri, recreaþie, stiinþã, culturã, etc. Fiecare din aceste domenii este împãrþit în subdomenii ºi aºa mai departe.
Deci, dacã ºtiþi foarte bine ce cãutaþi atunci ar fi mai bine sã începeþi cu domeniul potrivit decât sã folosiþi motorul de cãutare. Este foarte probabil ca domeniul sã nu ofere atâtea pagini rezultat ca ºi cãutarea folosind motorul de cãutare, însã toate rezultatele oferite sunt la subiect.
De obicei, motoarele de cãutare posedã cuvinte cheie proprii, care permit cãutarea în indecºii lor pentru gãsirea informaþiilor de care aveþi nevoie.
Aproape în toate motoarele de cãutare structura de domenii descrisã anterior a fost pusã în strânsã legãturã cu motorul de cãutare, interacþionând în diferite moduri.
Clasificarea motoarelor de cautare
Motoarele de cãutare existente pot fi împarþite în douã mari categorii: motoare de cãutare (propriu-zise) ºi directoare de domenii.
Motoare de cãutare propriu-zise
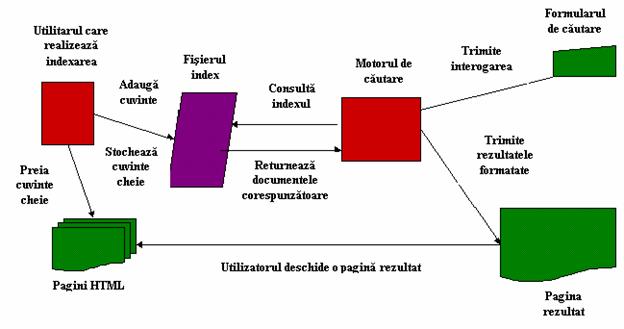
Motoarele de cautare permit cãutarea dupã cuvinte cheie în bazele lor de date, create, de obicei, în mod automat de cãtre roboþi de indexare "paianjen". Bazându-se pe anumite criterii de cãutare stabilite de utilizator sau de cãtre motorul de cãutare, acesta returneazã documente web din bazele sale de date care corespund cuvintelor de cãutare introduse de utilizator. Este foarte important de reþinut faptul cã în momentul în care folosiþi un motor de cãutare nu faceþi o cãutare "live" pe Internet, ci efectuaþi o cãutare într-o bazã de date care a fost actualizatã înaintea cãutãrii.
![]()


Fig.
11 Cãutarea folosind un motor de cãutare
Deºi majoritatea motoarelor de cãutare îndeplinesc aceeaºi sarcinã, ele urmeazã drumuri diferite pentru a-ºi atinge scopul, ceea ce duce la oferirea de rezultate diferite de la un motor de cãutare la altul. La motoarele de cãutare diferã, de asemenea, viteza de cãutare, design-ul interfeþei de cãutare ºi modul în care sunt afiºate rezultatele.
Creºterea continuã a numarului motoarelor de cãutare a condus la dezvoltarea utilitarelor de cautare "meta", adesea referite ca motoare de cãutare multi-thread. Aceste permit utilizatorilor cãutãri multiple, în diferite baze de date, folosind aceeaºi interfaþã de cãutare. Deºi nu oferã acelaºi nivel de control asupra interfeþie de cãutare ºi nici acelaºi control logic ca ºi motoarele de cãutare individuale, majoritate motoarelor de cãutare multi-thread sunt foarte rapide. Mai nou, capacitãþile motoarelor de cãutare multi-thread au fost îmbunãtãþite prin adãugarea posibilitãþilor de sortare a rezultatului dupã site, dupã tipul resursei, dupã domeniu, posibilitatea selectãrii motoarelor de cãutare care sã fie folosite ºi posibilitatea de modificare a rezultatelor. Aceste modificãri aduse au crescut mult eficacitatea ºi utilitatea motoarelor de cãutare multi-thread.
O categorie aparte a motoarelor de cãutare sunt motoarele de cãutare dupã domenii specifice. Aceste nu încearcã indexarea în întregime a Internetului. În schimb, ele îºi concentrezã efortul pe cãutarea paginilor dintr-un domeniu bine stabilit, dupã tipul resursei sau dupã zona geograficã. Deoarece aceste motoare de cãutare urmãresc acoperirea cât mai în profunzime a unui anumit subiect, decât acoperirea a cât mai multe documente. Din acest motiv, unele documente pe care le potem gãsi pe aceste motoare de cãutare dupã domenii specifice nu le vom gãsi în nici una din baze de date ale marilor motoare de cãutare.
Directoare de tematici
Directoarele de tematici sunt indecºi de domenii (subiecte) organizate ierarhic, care permit unui utilizator sã le consulte pentru a gãsi informaþia de care are nevoie. Ele pot include un motor de cãutare pentru consultarea propriilor baze de date.
Directoarele de tematici tind sã fie mai mici decât majoritatea motoarelor de cautare, deci, ºi lista rezultatelor tinde sã fie mai micã.
Între motoarele de cãutare ºi directoarele de tematici existã unele diferenþe. De exemplu, motoarele de cãutare indexeazã toate paginile de pe o paginã web datã, pe când un director de tematici oferã doar un link cãtre pagina principalã. O altã mare diferenþã ar fi accea cã, având în vedere cã directoarele de tematici sunt întreþinute de cãtre om, posibilitatea oferirii unui rezultat în afara contextului este mult mai redus.
Pregãtirea unui site pentru cãutare
Utlilitarele de cãutare pe site necesitã spaþiu destul de mare pe disc (fiºierele index ocupã, de obicei, destl de mult spaþiu) ºi putere destul de mare de procesare. De asemenea, fiºierele index trebuie actualizate periodic pentru a furniza date actuale. Utilitarele de cãutare permit programarea actualizãrii fiºierelor index.
 Rezultatul cãutãrii conþine, de obicei,
titlul paginii ºi ceva text, cum ar fi primele linii ale paginii sau un rezumat
al paginii cu pricina. Ordinea în care sunt afiºate paginile depinde de
algoritmul propriu al motorului de cãutare.
Rezultatul cãutãrii conþine, de obicei,
titlul paginii ºi ceva text, cum ar fi primele linii ale paginii sau un rezumat
al paginii cu pricina. Ordinea în care sunt afiºate paginile depinde de
algoritmul propriu al motorului de cãutare.
Fig.
12 Modul de funcþionare al motoarelor de cãutare
Majoritatea motoarelor de cãutare cautã într-un fiºier index creat de un utilitar care indexeazã documentele publicate pe server.
Pentru a trimite o cerere de cãutare majoritatea sistemelor conþin un formular de cãutare. Vizitatorul site-ului introduce cuvintele cheie într-un text-box ºi poate selecta alte opþiuni specifice existente în formularul de cãutare. Când este apãsat butonul de cãutare, serverul transferã cererea motorului de cãutare.
Tipuri de motoare de cãutare
Programe CGI (Common Gateway Interface)
Standardul CGI permite unui server Web sã comunice cu programe externe. CGI-urile pot fi scrise în C, Perl sau Java, în funcþie de serverul de Web sau de platformã. Multe CGI-uri sunt portabile de pe UNIX pe Windows sau Mac ºi invers, în funcþie de limbajul în care au fost scrise ºi de bibliotecile pe care le folosesc.
Script-uri PERL
PERL este un limbaj pentru realizarea scrip-urilor ºi, spre deosebire de C sau Pascal, în urma compilãrii lor nu rezultã fiºiere obiect. PERL are propria sintaxã ºi propriile biblioteci de funcþii ºi comunicã cu serverul folosind standardul CGI. Script-urile PERL ruleazã pe aproape toate platformele ºi pe aproape toate serverele Web.
Forþa limbajului PERL constã în posibilitatea efectuãrii unor prelucrãri rapide asupra textului ºi a manipulãrii ºirurilor de caractere.
Applet-uri Java ºi Java Servlets
Applet-urile Java sunt programe Java care ruleazã în cadrul browser-ului Web, folosind JVM (Java Virtual Machine). A stabili când ºi unde trebuie folosite applet-urile Java într-o paginã Web nu este o sarcinã prea uºoarã. Înainte de a umple o paginã cu applet-uri, trebuie determinat dacã acestea sunt absolut necesare sau dacã aduc vreo îmbunãtãþire paginii respective. În cazul în care ele nu fac decât sã creascã timpul de încãrcare, este preferabil sã nu fie fololsite.
Java Servlets sunt aplicaþii scrise în Java utilizând Java Servlet API. Multe servere Web schimbã date cu aplicaþii Java care folosesc aceastã interfaþã, asemãnãtor cu sistemul CGI.
Java Servlets sunt module Java care ruleazã într-o aplicaþie server. Java Servlets nu sunt "legate" de un anumit protocol, dar sunt cel mai des folosite cu HTTP, fiind folosit uneori termenul de "HTTP Servlets".
Spre deosebire de CGI-uri, Servlet-urile au câteva avantaje, cum ar fi:
a) Un Servlet nu ruleazã într-un proces separat. Acest lucru eliminã necesitatea creãrii unui proces nou pentru fiecare cerere.
b) Un Servlet rãmâne rezident în memorie dupã terminarea cererii, spre deosebire de un CGI care trebuie încãrcat pentru fiecare cerere.
c) Este folositã o singurã instanþã pentru a rezolva cererile.
d) Un Servlet nu poate fi rulat decât de Servlet Engine, care permite folosirea în siguranþã a servlet-urilor cu potenþial distructiv.
Utilitare de indexare
Utilitarul de indexare repezintã aplicaþia care consultã textul documentelor publicate pe un server ºi le stocheazã într-un fiºier numit de obicei index sau catalog (de cãtre Microsoft), fiºire formatat în aºa fel încât sã uºureze cãutarea.
Aceste aplicaþii trebuie sã poatã salva fiºierele index într-una anume director, de unde motorul de cãutare sã-l poatã consulta.
Utilitare de indexare locale
Utilitarele de indexare locale indexeazã fiºiere pornind de la structura de directoare a hard-disk-ului, de obicei pornind din directorul rãdãcinã. Majoritatea utilitarelor de acest gen permit indexarea fiºielelor dupã nume, tip, extensie, locaþie etc.
Utilitarele de indexare pot verifica dacã un fiºier a fost modificat ºi deci pot adãuga la index informaþii doar din acele fiºiere care au fost modificate sau din fiºierele nou create. Acele utilitare de indexare care sunt în strânsã legãturã cu sistemul de operare vor fi anunþate de modificãrile apãrute în directoarele specificate pentru indexare ºi vor adãuga aceste noi intrãri la index.
Utilitarele de indexare se dovedesc a fi bune la eliminarea paginilor duplicat, astfel încât la o cãutare nu apar mai multe copii ale aceleiaºi pagini.
Utilitarele de indexare locale vor prelua documentul exact cum este el pe hard-disk. Acestea nu vor include date dinamice din CGI-uri, SSI-uri (Server-Side Includes), ASP-uri (Active Server Pages) ºi altele, care pot constitui o mare parte a site-ului. Acest lucru poate constitui un avantaj dacã aceste elemente sunt repetitive, cum ar fi barele de navigare, sau un dezavantaj în cazul în care elementele dinamice reprezintã conþinutul unei pagini
La indexare trebuie avut în vedere ºi aspectul securitãþii, adicã trebuie verificat dacã în interiorul directoarelor supuse indexãrii nu existã ºi fiºiere care nu ar trebui sã fie accesibile. În cazul în care existã, atunci ele pot fi accesate printr-o singurã cãutare.
Roboþi "paianjen" de indexare
Roboþii "paianjen" de indexare localizeazã fiºierele pe care le vor indexa în mod similar roboþilor de pe motoarele de cãutare. Utilizatorul trebuie sã furnizeze o paginã de pornire, iar aceste utilitare de indexare vor stoca toate cuvintele existente în aceastã ºi apoi vor urmãri toate link-urile existente în pagina curentã îndexându-le ºi pe acestea ºi apoi urmãrind link-urile existenet aici º.a.m.d. Deoarece folosesc HTTP, roboþii de indexare pot fi mai lenþi decât utilitarele de indexare locale. Din pãcate, roboþii "paianjen" de cãutare pot scãpa paginile spre care nu indicã nici un link. Orice robot de indexare poate întâmpina probleme, la fel ca ºi roboþii de indexare a marilor motoare de cãutare, cu paginile cu mai multe frame-uri.
Pentru actualizarea indexului, unii roboþi de indexare vor cere serverului informaþii despre starea paginilor care au fost indexate. Pentru aceasta se cere header-ul HTTP printr-o cerere HEAD (de obicei pentru un fiºier HTML se executã o cerere GET). Serverul poate rãspunde la cererea HEAD returnând informaþii despre paginã direct din cache, fãrã a fi nevoie sã deschidã ºi sã citeascã tot fiºierul, ºi astfel interacþiunea cu serverul va fi mult mai eficientã. Apoi, robotul de indexare comparã data modificãrii din header cu data la care indexul a fost ultima datã actualizat. Dacã pagina nu a fost modificatã atunci nu se impunde actualizarea indexului. Dacã, însã, a fost modificatã sau este nouã atunci robotul executã o cerere GET pentru toatã pagina ºi stocheazã fiecare cuvânt în fiºierul index.
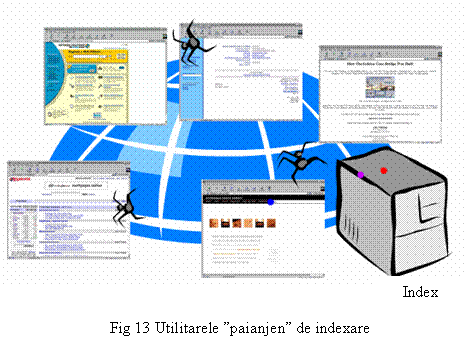
Roboþii de indexare trebuie sã conþinã o porþiune de cod care sã identifice paginile duplicat, duplicari datorate mirroring-ului, greºeli în numele fiºierelor, de exemplu "./" în loc de "../", ºi aºa mai departe.
Webmaster-ii pot controla directoarele pe care roboþii le vor indexa prin editarea fiºierului robots.txt, fiºier consultat de aproape toþi roboþii de indexare a marilor motoare de cãutare.
La consultarea documentelor publicate pe server, roboþii de indexare lasã "urme" în fiºierele jurnal ale serverului la fel ca o persoanã obiºnuitã. Deci, un administrator poate sã-ºi dea seama ce a reuºit ºi ce nu a reuºit sã indexeze un robot. De asemenea, se poate determina numãrul de cereri pe care le fac roboþii de indexare pentru a realiza o contorizare realã a numãrului de accesãri a site-ului.
Roboþii de indexare pot fi identificaþi prin mai multe metode. De exemplu, aceºtia pot fi identificaþi dupã numele host-ului, care încorporeazã o parte din numele motorului de cãutare sau din numele companiei, cum ar fi spidey.webcrawler.com. Însã, o metodã mai bunã de depistare ar fi dupã numele lor. Fiecare robot al marilor motoare de cãutare are un nume bine cunoscut, cum ar fi Mozilla robotul lui Netscape, Scooter al lui Altavista, Slurp al lui HotBot.
Tag-urile Meta
Existã mai multe tag-uri Meta, dar cele mai importante pentru roboþii de indexare ai marilor motoare de cãutare sunt description (descriere), keywords (cuvinte cheie) ºi robots.
Tag-ul description furnizeazã un sumar al paginii pe care l-ar realiza, oricum, motorul de cãutare. Tag-ul keywords furnizeazã cuvintele cheie cu care va fi asociat site-ul în indexul motorului de cãutare. Tag-ul robots permite specificarea paginilor care sã fie sau nu indexate. Pentru a specifica pagina care nu trebuie indexatã aceasta trebuie sã conþinã ºi urmãtoarele linii:
<HEAD>
<TITLE>Aceastã paginã nu trebuie indexatã</TITLE>
<META NAME="ROBOTS" CONTENT="NOINDEX">
</HEAD>.
Cãutarea în baze de date simple
Deºi multe dintre informaþiile unei companii sunt pãstrate centralizat, unele dintre ele, cum ar fi o listã a produselor puse la dispoziþie de firma respectivã, o listã a birourilor regionale, anumite informaþii despre angajaþi, ar trebui facute publice. Toate aceste informaþii ar putea fi pãstrate într-o bazã de date relaþionalã, dar este suficientã pãstrarea datelor într-un banal fiºier text. Scopul este acela de a furniza informaþii rapind ºi de a evita complicaþiile care apar folosind bazele de date relaþionale. Dacã anumite informaþii existã deja în diferite baze de date proprietare, trebuie fãcut un export într-un fiºier text, aproape toate bazele de date permiþând un astfel de lucru.
Aceastã metodã de cãutare permite selectarea bazei de date (fiºierului text) în care sã se facã cãutarea. De exemplu, dacã se doreºte cãutarea numãrului de telefon a unui anume angajat al unei companii care are filiale în Cluj-Napoca, Bucureºti ºi Timiºoara atunci reþinem trei fiºiere cu numerele de telefon ale angajaþilor (CJphone.txt, Bphone.txt ºi TMphone.txt). Alegerea bazei de date în care sã se facã cãutarea prin douã metode: printr-un link corespunzãtor sau printr-o formã aflatã în pagina web.
Dacã se opteazã pentru folosirea link-urilor atunci în textul sursã al paginii web trebuie inserate urmãtoarele linii:
<A HREF="/database/CJphone.txt">Biroul Cluj-Napoca</A>
<A HREF="/database/Bphone.txt"> Biroul Bucureºti<A>
<A HREF="/database/TMphone.txt"> Biroul Timiºoara</A>.
În cea de-a douã situaþie prezentatã se poate folosi un grup de butoane radio ºi deci în textul sursã al paginii web trebuie sã aparã:
<INPUT TYPE="RADIO" NAME="DATABASE" VALUE="/ database/CJphone.txt" CHECKED> Biroul Cluj-Napoca <BR>
<INPUT TYPE="RADIO" NAME="DATABASE" VALUE="/database/Bphone.txt"> Biroul Bucureºti<BR>
<INPUT TYPE="RADIO" NAME="DATABASE" VALUE="/database/TMphone.txt"> Biroul Timiºoara <P>
Sub sistemele UNIX, cãutarea se poate face foarte uºor folosind comanda grep. Aceasta comandã permite atât cãutare simplã cât ºi cãutare multiplã (în mai multe fiºiere din acelaºi director sau din directoare diferite).
Cãutarea pe tot serverul de Web
Soluþia cãutãrii pe tot serverul este similarã oricãrei cãutãri în bazele de date. Se foloseºte un index în care se reþine un rezumat al datelor existente pe server. În mod similar cum datele sunt adãugate în bazele de date, tot aºa se adaugã informaþii în fiºierul index. De exemplu, se poate concepe un program care sã actualizeze informaþiile din fiºierul index noaptea sau cât mai des posibil.
Cãutarea folosind ICE
O soluþie de indexare ºi cãutare Web o reprezintã ICE, scris în PERL, lucru care îi permite sã ruleze sub UNIX, Windows ºi MacOS.
ICE permite efectuarea urmãtoarele operaþii:
cãutare dupã cuvinte cheie folosind operatorii booleeni AND ºi OR;
cãutare case-sensitive sau case-insensitive;
afiºare HTML a rezultatelor obþinute;
- posibilitatea de a cãuta cuvinte similare din punct de vedere ortografic într-un dicþionar existent;
posibilitatea de a cãuta cuvinte ºi teme asemãnãtoare într-un lexicon;
posibilitatea de a limita cãutarea la un anumit director.
Nucleul lui ICE este format dintr-un program PERL care citeºte fiecare fiºier de pe serverul de Web ºi construieºte fiºierul index în format text. Programul care construieºte indexul, în distribuþia standard ice-idx.pl, are o metodã simplã de funcþionare. Administratorul sistemului specificã locaþiile fiºierelor text ºi HTML care trebuie indexate. Când este rulat ice-idex.pl, acesta citeºte fiecare fiºier din directoarele specificate ºi stocheazã informaþia într-un fiºiere index, cu numele predefinit index.idx. cuvintele din fiecare fiºier sunt ordonate alfabetic ºi contorizate pentru a putea fi folosite atunci când se executã o cãutare.
Formatul fiºierului index returnat de ICE este urmãtorul:
@nume_fiºier
@titlu
cuvânt1 contor1
cuvânt2 contor2
cuvânt3 contor3
@nume_fiºier
@titlu
cuvânt1 contor1
Programul ice-idx.pl se ruleazã noaptea sau la un interval bine stabilit de timp astfel încât rezultatele furnizate de o cãutare sã fie bazate pe date actualizate. În mod normal, ICE indexeazã întregul conþinut al directoarelor specificate, dar poate fi configurat astfel încât sã indexeze doar fiºierele noi sau cele modificate de la ultima actualizare.
Pentru a reduce dimensiunea fiºierului index, ICE ignorã tag-urile din fiºierele HTML ºi cuvintele care se repetã.
Motorul de cãutare este alcãtuit din programul ice.pl. Acesta citeºte fiºierul index creat anterior, îl parcurge secvenþial ºi furnizeazã numele fiºierului în care apare cheia dupa care s-a efectuat cãutarea.
Cãutarea folosind WAIS
WAIS (Wide Area Information Server) este un alt software folosit pentru serverle de Web care ruleazã sub Windows NT.
WAIS este alcãtuit din trei componente de bazã:
WAISSERV - un intermediar pentru protocoale ºi un motor de cãutare;
WAISINDEX - utilitarul de indexare;
WAISLOOK - utilitarul de cãutare.
Motorul de cãutare WAIS implementeazã operaþii de cãutare cu operatori booleeni ºi fiºiere asemãnãtoare.
Modul de operare al lui WAIS este asemãnãtor cu cel al lui ICE, adicã implicã crearea fiºierelor index ºi actualizarea acestora.
Programul WAISINDEX poate fi folosit pentru a crea indecºi care pot fi folosiþi doar în interiorul site-ului sau, dacã WAISINDEX este folosit cu opþiunea -export care permite înregistrarea datelor la baza de date "cea mare", se pot crea indecºi care pot fi consultaþi de cãtre public. Pentru înregistrare trebuie trimis fiºierul index.src creat a o anumitã adresã de e-mail.
Criterii de selectare a rezultatelor unei cãutãri
Unul dintre primele locuri unde se realizeazã cãutarea este în numele domeniului. Spre exemplu, dacã se încearcã cãutarea dupã cuvintele cheie "road maps", atunci aceste sunt puse împreunã pentru a se determina dacã nu se poate forma numele unui domeniu existent. De exemplu, https://www.roadmaps.com ar fi potrivirea perfectã, iar https://www.watermaps.com ar fi aproape perfectã (deoarece conþine unul dintre cuvintele cheie dupã care s-a realizat cãutarea) ºi vor cãpãta o prioritate mai mare la cãutare. Din acest motiv se recomandã folosirea cel puþin al unui cuvânt cheie în numele domeniului.
Selectarea rezultatelor unei cãutãri se face respectând urmãtoarele criterii:
a) Dacã cuvintele cheie nu se aflã în numele domeniului atunci se verificã dacã vreun cuvânt cheie nu se alfã undeva în URL, aºa cum am exemplificat mai sus (https://www.eatermaps.com).
b) Dacã nici unul dintre cuvintele cheie nu se aflã în URL atunci se cautã în titlul paginii. De exemplu, dacã în codul sursã al paginii apare <TITLE>Road maps </TITLE> atunci un link spre pagina respectivã va fi inclus în pagina rezultat.
c) Altfel, se verificã HEAD-ul (cuvintele din partea de sus a textului sursã).
d) Altfel, se verificã asemãnãrile dintre cuvintele cheie ºi contextul în care apare pagina web.
e) În cele din urmã se face compararea cuvintelor cheie cu tag-urile Meta. Însã, unele motoare de cãutare atribuie o prioritate mai mare verificãrii tag-urilor Meta decât contextului.
Se recomandã folosirea tag-ului TITLE în cadrul textului sursã al paginii web. Acesta poate fi format din cel mult 40 de caractere, cuprinzând atât literele cât ºi spaþiile. Deoarece spaþiul alocat titlului este relativ redus se recomandã evitarea folosirii cuvintelor de genul: "and", "the", "a", "or", "web", "internet", "an", "is", "www". De exemplu, în cazul motorului de cãutare Altavista, dacã cadrul tag-ul TITLE nu se regãseºte nici unul dintre cuvintele cheie dupã care se face cãutarea atunci existã ºanse mari ca pagina sã nu aparã în rezultatul cãutãrii
De asemenea, nu se recomandã utilizarea în numele domeniilor a urmãtoarelor caractere: "!", "@", "#", "&", "_", "~". Multe motoare de cãutare "urãsc" semnele de punctuaþie, în special "~". Spre exemplu, "-" (dash) a fost acceptat de mult ca delimitator de cuvinte în cazul numelor de domenii.
Motoarele de cãutare nu agreazã subdirectoarele. Deci, nu se recomandã folosirea subdirectoarelor pentru specificare unei paginii. Unele motoare de cãutare "obiºnuiesc" sã nu caute mai adânc de unul sau douã directoare. De exemplu, dacã adresa paginii web este: www.jaguar.com/transportation/cars/sports/jaguars/convertibles/xj6.html atunci este foarte probabil ca pagina sã nu aparã niciodatã listatã într-o paginã rezultat.
Unele motoare de cãutare se uitã sã vadã care sunt ultimele lucruri care apar în codul sursã. De aceea, este recomandatã trecerea URL-ului la sfârºitul codului sursã.
Indiferent de motorul de cãutare folosit, stabilirea unei strategii de cãutare este foarte importantã pentru obþinerea rezultatului de care avem nevoie.
O strategi simplã poate consta din urmãtorii paºi:
a) formularea întrebãrii ºi a scopului acesteia;
b) determinarea conceptelor importante din întrebare;
c) determinarea cuvintelor cheie care descriu aceste concepte;
d) considerarea sinonimelor ºi variaþiilor care pot apãrea;
e) pregãtirea logicii de cãutare.
O strategie de cãutare bine pusã la punct este foarte importantã, mai ales în cadrul unei baze de date aºa de mari cum este World Wide Web. Datoritã creºterii numãrului paginilor publicate pe Internet creºte ºi numãrul paginilor fãrã relevanþã care sunt furnizate ca ºi rezultat al cãutãrii.
|
