REPREZENTAREA INTERNA A FISIERELOR
Dupa cum s-a mentionat in capitolul al doilea, orice fisier intr-un sistem UNIX are asociat un inod unic. Inodul contine informatiile necesare unui proces pentru a putea accesa un fisier, cum ar fi:
proprietarul fisierului
drepturile de acces
dimensiunea fisierului
amplasarea datelor fisierului in cadrul sistemului de fisiere.
Un fisier este specificat printr-un sir de caractere (nume de cale) care identifica in mod unic acel fisier. Sistemul pune la dispozitie un set bine definit de apeluri sistem prin care procesele pot accesa fisierele folosind inodurile lor (determinate pe baza numelui de cale).
Acest capitol descrie structura interna a fisierelor in sistemul UNIX, iar capitolul urmator se va descrie interfata apelurilor sistem cu fisierele.
Algoritmii ce vor fi descrisi pe parcursul acestui capitol sunt:
iget - returneaza un inod specificat dupa in prealabil îl aduce in memorie (prin intermediul buffer-ului cache), daca este nevoie;
iput - elibereaza inodul;
bmap - seteaza parametrii nucleului pentru accesarea unui fisier;
namei - converteste un nume de cale de nivel utilizator la un inod, utilizând algoritmii iget, iput si bmap;
alloc, free - aloca, respectiv elibereaza blocuri disc pentru fisiere;
ialloc, ifree - aloca, respectiv elibereaza inoduri pentru fisiere.
Dupa cum se arata si in figura 4.1, acesti algoritmi ocupa nivelul de deasupra algoritmilor buffer-ului cache care au fost prezentati in capitolul anterior.
4.1 Inoduri
Definitie
Inodurile exista intr-o forma statica pe disc, iar pentru a le prelucra, nucleul le citeste intr-un inode in-core in memoria interna pentru a le manipula. Inodurile din memorie sunt numite in-core inoduri.
Inodurile disc contin urmatoarele câmpuri:
Identificatorul proprietarului fisierului. Proprietatea asupra unui fisier este impartita intre un proprietar individual si un "grup" al proprietarului si defineste setul de utilizatori care au drepturi de acces la fisier. Superutilizatorul are drepturi de acces la toate fisierele din sistem.
Tipul fisierului. Fisierele pot fi de tip regulat, director, speciale (caracter sau bloc), sau pipe (FIFO).
Permisiunile de acces la fisier. Pentru protectie, sistemul împarte utilizatorii unui fisier in trei clase: proprietarul, grupul proprietarului fisierului si alti utilizatori. Fiecare clasa are drepturi de acces pentru citirea, scrierea si executia unui fisier, iar acestea pot fi setate individual. Întrucât un director nu poate fi executat, permisiunea de executie confera dreptul de a cauta in el un nume de fisier.
Timpii de acces la fisier. Contin timpul la care fisierul a fost modificat ultima data, timpul când a fost accesat ultima oara, respectiv timpul când inodul a fost modificat ultima oara.
Numarul de legaturi ale fisierului. Reprezinta numarul de nume pe care fisierul le are in cadrul ierarhiei de directoare. Capitolul 5 va prezenta detaliat legarea fisierelor.
Tabela de cuprins. Contine adresele disc unde pot fi regasite datele fisierului. Desi utilizatorii trateaza datele din fisier ca un sir logic de octeti, nucleul salveaza datele in blocuri disc discontinue. Inodul identifica blocurile de pe disc care contin datele fisierului.
Dimensiunea fisierului. Adresarea datelor dintr-un fisier se face prin precizarea deplasamentului fata de începutul fisierului. Dimensiunea fisierului este cu o unitate mai mare decât cel mai mare deplasament de date din fisier. De exemplu, daca un utilizator creeaza un fisier si scrie numai un octet de date la deplasamentul 1000, atunci dimensiunea fisierului este de 1001 octeti.
Numele caii (cailor) prin care se acceseaza un fisier nu se afla in inodul fisierului, ci in directorul 535f512f (directoarele) in care rezidã fisierul.
Figura 4.2 prezinta inodul disc al unui fisier obisnuit, al carui proprietar este "mjb" si care contine 6030 octeti. Sistemul ii permite lui "mjb" sa citeasca, sa scrie sau sa execute fisierul. Membrii grupului "os" si toti ceilalti utilizatori pot sa citeasca sau sa execute fisierul, dar nu pot sa scrie in el. Ultimul moment când cineva a citit fisierul a fost 22 oct. 1994, la 10:30. Pe 23 oct 1984, la 1:30, inodul a fost modificat ultima oara, dar nu si datele din fisier. Informatiile de mai sus sunt pastrate codificat in inod.
Dupa cum se observa, se face distinctie intre scrierea continutului unui inod pe disc si scrierea continutului fisierului pe disc. Continutul unui fisier se schimba numai când se scrie in el. Continutul unui inod se schimba când se schimba continutul fisierului, sau când se schimba proprietarul, permisiunile, legaturile. Schimbarea continutului unui fisier implica automat modificarea continutului inodului, dar modificarea inodului nu implica modificarea continutului fisierului.
proprietar mjb
grup os
fisier de tip obisnuit
permisiuni rwxr-xr-x
accesat oct 23 1994 1:45 PM
modificat oct 22 1994 10:30 AM
inod oct 23 1994 1:30 PM
dimensiune 6030 bytes
adrese disc
Figura 4.2 Exemplu de inod disc
Copia din memoria interna a unui INCORE inod contine câmpurile unui inod disc plus urmatoarele:
Starea inodului din memoria interna, indica daca:
inodul este blocat,
un proces asteapta deblocarea inodului,
reprezentarea din memoria interna a inodului difera de copia de pe disc ca rezultat al modificarii datelor din inod,
reprezentarea din memoria interna a fisierului difera de copia de pe disc ca urmare a modificarii datelor in fisier,
fisierul este un punct de montare (mount point),
Numarul de dispozitiv logic al sistemului de fisiere care contine fisierul.
Numarul inodului. Deoarece inodurile sunt stocate pe disc intr-un sir, nucleul identifica numarul inodului disc prin pozitia sa in lista. Inodul disc nu are nevoie de acest câmp.
Pointeri catre alte inoduri din memoria interna. Nucleul inlantuieste inodurile din memorie in structuri de tip liste hash si o lista de inoduri libere, similare celor descrise pentru buffere in capitolul anterior. Inodurile se pot gasi simultan si intr-o lista hash si in lista de inoduri libere. O lista hash este identificata dupa numarul de dispozitiv logic al inodului si dupa numarul inodului. Nucleul poate contine in memoria interna cel mult o copie a unui inod disc.
Contorul de referinta, indica numarul de instante active ale fisierului (de câte ori a fost deschis).
Multe câmpuri ale inodului din memoria interna sunt analoage celor din antetele buffere-lor . Astfel gestiunea inodurilor este similara cu cea a buffere-lor. Blocarea inodului se realizeaza pentru a nu permite mai multor procese sa acceseze acelasi inod. Daca procesele vor sa acceseze un inod care este blocat, ii seteaza un semnalizator care indica faptul ca trebuie trezite când inodul va fi deblocat. Nucleul seteaza alti semnalizatori, pentru a indica diferenta dintre inodul disc si copia sa din memoria interna. Actualizarea inodului sau a fisierului pe disc conform copiei din memorie se face dupa examinarea in prealabil a acestor semnalizatoare.
Cea mai mare diferenta dintre un inod din memoria interna si un antet de buffer o constituie contorul de referinta (prezent la inodul din memoria interna) care contorizeaza instantele active ale unui fisier. Un inod este activ când un proces îl aloca (la deschiderea unui fisier). Inodul este in lista inodurilor libere numai daca contorul sau de referinta este 0, ceea ce inseamna ca nucleul îl poate realoca unui alt inod disc. Lista inodurilor libere se constituie astfel, ca un cache al inodurilor inactive. Daca un proces încearca sa acceseze un fisier al carui inod nu este prezent in memoria interna, nucleul realoca un inod din lista inodurilor libere pentru a fi utilizat. Spre deosebire de inoduri, un buffer nu are contor de referinta si este in lista buffere-lor libere daca si numai daca este deblocat.
Accesarea inodurilor
Nucleul identifica un anumit inod dupa sistemul de fisiere din care face parte si numarul inodului si aloca inoduri in memoria interna la cererea algoritmilor de nivel inalt.Algoritmul iget aloca o copie in memoria interna pentru un inod (vezi figura 4.3), si este similar cu algoritmul getblk pentru gasirea unui bloc disc in bufferul cache. Nucleul asociaza numarului dispozitivului si numarului inodului o lista hash in care se va face cautarea inodului. Daca nucleul nu gaseste inodul, el aloca unul din lista fisierelor libere si-l blocheaza. Apoi pregateste citirea copiei disc in inodul alocat.
algoritm iget
intrare: numar inod din sistemul de fisiere
iesire: inod blocat
/* executie speciala în cazul în care este punct de montare
(Capitolul 5) */
if (inodul este în lista inodurilor libere )
sterge inodul din lista inodurilor libere ;
incrementeaza contorul de referinta al inodului;
return (inod);
}
/* inodul nu este în cache-ul de inoduri (listele hash) */
if (nu este nici un inod în lista inodurilor libere )
return (eroare);
sterge noul inod din lista inodurilor libere ;
reseteaza numarul inodului si sistemul de fisiere;
sterge inodul din vechea lista hash, plaseaza-l în cea
nouå;
citeste inodul de pe disc (algoritm bread);
initializeaza inodul (de exemplu, contorul=1);
return (inod);
}
Figura 4.3. Algoritmul pentru alocarea inodurilor din memoria
internã
Pe baza numarului inodului si a numarului dispozitivului logic (cunoscute), nucleul calculeaza blocul logic de pe disc care contine inodul tinând seama de numarul de inoduri continute intr-un bloc disc.
Calculul se face dupa formula:
numar bloc=s(numar inod-1)/numar inoduri din bloct+blocul de start al listei de inoduri ;
unde operatia de impartire returneaza partea întreaga a rezultatului. De exemplu, presupunând ca blocul 2 este blocul de început al listei de inoduri si ca sunt 8 inoduri in bloc, atunci inodul numarul 8 este in blocul disc numarul 2, iar inodul 9 este in blocul disc numarul 3.
Când nucleul cunoaste numarul dispozitivului si numarul blocului disc, el citeste blocul utilizând algoritmul bread, si utilizeaza urmatoarea formula pentru a calcula deplasamentul inodului in bloc:
deplasament=s(numar inod -1) modulo (numar de inoduri din bloc)t*dimensiunea inodului disc ;
De exemplu, daca fiecare inod disc ocupa 64 octeti si sunt 8 inoduri intr-un bloc disc, atunci inodul numarul 8 începe de la deplasamentul 448 din blocul disc. Nucleul scoate inodul din lista inodurilor libere, îl plaseaza in lista hash corespunzatoare si seteaza contorul de referinta pe 1. Apoi copiaza din inodul disc in cel din memorie tipul fisierului, câmpurile de proprietate, permisiunile de acces, numarul de legaturi, dimensiunea fisierului si tabela de cuprins, si returneaza inodul blocat.
Nucleul manipuleaza semnalizatorul de blocare si contorul de referinta independent. Blocarea se realizeaza in timpul executiei unui apel sistem pentru a împiedica accesarea inodului de catre alte procese pe durata cât este utilizat.
Nucleul deblocheaza inodul la încheierea apelurilor sistem, el nefiind niciodata blocat intre apelurile sistem. In acest fel se permite proceselor accesul simultan la fisiere. Nucleul incrementeaza contorul de referinta pentru fiecare referinta activa la fisier. El decrementeaza contorul de referinta numai daca referinta devine inactiva (când un proces închide fisierul). Contorul de referinta ramâne setat intre apelurile sistem multiple, împiedicând nucleul sa realoce un inod activ. Astfel, nucleul poate bloca si debloca un inod alocat independent de valoarea contorului de referinta. Daca in cazul buffer-ului cache termenii deblocat si eliberat aveau aceeasi semnificatie, la inoduri ei au semnificatie aparte. Termenul eliberat (precum si cel ce desemneaza starea opusa, alocat) este asociat contorului de referinta, iar deblocat (cât si blocat) semnalizatorului de blocare.
Revenind la algoritmul iget, daca nucleul încearca sa obtina un inod din lista inodurilor libere , iar aceasta este goala, el raporteaza o eroare. Modalitatea de actiune a nucleului in cazul alocarii buffere-lor este diferita, procesele punându-se in asteptare pana când buffere-le devin libere.
Aceasta diferenta in abordarea problemei (de alocare a unei resurse) este datorata faptului ca procesele au control asupra alocarii inodurilor la nivel utilizator (prin intermediul apelurilor sistem open si close), nucleul neputând garanta când un inod devine disponibil . Astfel, un proces care se pune in asteptare pâna la eliberarea unui inod s-ar putea sa nu se mai trezeasca niciodata si de aceea nucleul întoarce eroare. In schimb, procesele nu au un astfel de control asupra buffere-lor. Deoarece un proces nu poate tine un buffer blocat intre apelurile sistem, nucleul poate garanta ca un buffer va deveni curând liber. Acesta constituie motivul pentru care procesele se pun in asteptare pâna la eliberarea unui buffer.
Paragrafele precedente au tratat cazul in care nucleul a alocat un inod care nu a fost in cache (listele hash). Daca inodul este in cache, un proces (A) îl gaseste in lista sa hash si verifica daca este blocat de un alt proces (B). Daca inodul este blocat, procesul A se pune in asteptare, setând un bit de semnalizare al inodului din memoria interna pentru a arata ca asteapta deblocarea inodului. Când procesul B deblocheaza inodul, el trezeste toate procesele ce asteptau acest eveniment, (inclusiv A). Când A reuseste sa acceseze inodul, îl blocheaza pentru ca alte procese sa nu-l poata aloca.
Daca contorul de referinta a fost înainte 0, inodul apare de asemenea in lista inodurilor libere, si întrucât nu va mai fi liber, nucleul îl scoate de acolo. Nucleul incrementeaza contorul referinta al inodului si returneaza inodul blocat.
Recapitulând, algoritmul iget este utilizat de catre apelurile sistem, când un proces acceseaza pentru prima data un fisier. Algoritmul returneaza o structura de inod blocat având contorul de referinta incrementat cu o unitate. Inodul din memoria interna contine informatii actualizate despre starea fisierului. Nucleul deblocheaza inodul înainte de revenirea dintr-un apel sistem astfel încât si alte procese sa poata accesa inodul.
Eliberarea inodurilor
algoritm iput /* elibereaza un inod */
intrari: pointer la un inod din memorie
iesiri: niciuna
if (fisierul a fost accesat sau inodul modificat sau fisierul
modificat)
actualizeaza continutul inodului disc;
pune inodul în FLI;
}
deblocheaza inodul;
Figura 4.4. Algoritmul pentru eliberarea unui inod din memorie
Când nucleul elibereaza un inod (algoritmul iput din figura 4.4), el ii decrementeaza contorul de referinta. Daca contorul ajunge la 0, nucleul scrie inodul pe disc daca copia din memorie difera de cea de pe disc. Ele difera in cazul in care au fost modificate datele din fisier, timpul de acces la fisier, proprietarul sau permisiunile de acces. Nucleul plaseaza inodul in lista inodurilor libere pentru a putea fi realocat unui alt fisier. In cazul in care numarul de legaturi ale fisierului devine 0 (fisierul este sters), nucleul va elibera toate blocurile disc asociate fisierului.
4.2 Structura unui fisier
Dupa cum s-a mentionat anterior, inodul are o tabela de cuprins prin care localizeaza datele fisierului pe disc. Întrucât fiecare bloc de pe disc este adresabil prin numar, tabela de cuprins contine un set de numere de blocuri disc. Daca datele unui fisier ar fi stocate intr-o sectiune contigua pe disc (fisierul ocupa o secventa liniara de blocuri disc), atunci memorarea adresei blocului de start si dimensiunea fisierului ar fi suficiente pentru a accesa toate datele din fisier. Insa, o astfel de strategie de alocare nu permite o dinamica a marimii fisierului in sistemul de fisiere fara riscul fragmentarii spatiului liber de memorare de pe disc. In plus, nucleul trebuie sa aloce si sa rezerve spatiu contiguu in sistemul de fisiere înainte de a permite efectuarea operatiunilor de marire a dimensiunii fisierului.
De exemplu, sa presupunem ca un utilizator creeaza trei fisiere A, B si C, fiecare ocupând câte 10 blocuri disc si ca sistemul aloca spatiu contiguu pentru cele trei fisiere.

Figura 4. 5. Alocarea de fisiere in blocuri contigue si fragmentarea
spatiului liber
Daca dupa aceea utilizatorul doreste sa adauge 5 blocuri de date la fisierul din mijloc ,B, nucleul trebuie sa copieze fisierul B intr-un spatiu din sistemul de fisiere care permite stocarea a 15 blocuri.
O astfel de metoda care presupune costuri de executie ridicate, nu ar permite, in cazul de fata, utilizarea blocurilor disc ocupate anterior de datele fisierului B pentru a stoca fisiere ce necesita mai mult de 10 blocuri(figura 4.5.). Nucleul poate minimiza fragmentarea spatiului de memorare prin executarea periodica a unui set de proceduri destinate compactarii spatiului disponibil, insa aceasta operatie ar diminueaza din puterea de procesare.
Pentru o mai mare flexibilitate, nucleul aloca unui fisier câte un bloc la un moment dat, si elimina necesitatea pastrarii contigue a datelor fisierului, permitând ca acestea sa fie memorate peste tot in sistemul de fisiere. Dar aceasta schema de alocare complica sarcina localizarii datelor. Tabela de cuprins poate stoca o lista a numerelor de blocuri ce contin datele apartinând fisierului, dar calculele arata ca gestiunea unei liste liniare a blocurilor disc ale unui fisier in inod este dificila. Daca un bloc logic contine 1 ko, atunci un fisier de dimensiune 10 ko va avea nevoie de un index de 10 numere de bloc. Aceasta ar presupune fie variatia dimensiunii inodului in conformitate cu dimensiunea fisierului, fie necesitatea plasarii unei limite inferioare relative pentru dimensiunea fisierului.
Tabela de cuprins a blocurilor disc arata conform reprezentarii din figura 4.6, si asigura posibilitatea de a avea fisiere de dimensiuni mari.
UNIX system V are 13 intrari in tabela de cuprins a inodului. Intrarile marcate "direct" contin numere de blocuri disc care contin date din fisier. Intrarea marcata "simpla indirectare" refera un bloc ce contine o lista de numere de blocuri directe. Pentru a accesa date prin intermediul blocului de indirectare, nucleul trebuie sa-l citeasca, sa gaseasca intrarea corespunzatoare blocului direct in care se gasesc datele solicitate, si dupa aceea sa citeasca blocul direct. Blocul corespunzator intrarii marcate "dubla indirectare" contine o lista de numere de blocuri de indirectare, iar blocul corespunzator intrarii "tripla indirectare" contine o lista de numere de blocuri de dubla indirectare.
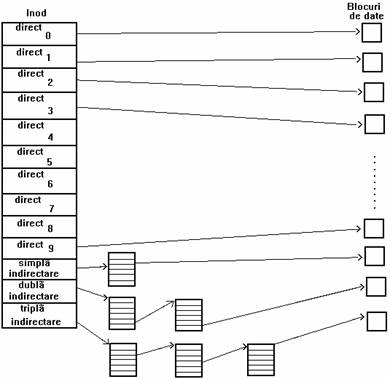
Figura 4. 6. Blocuri directe si de indirectare ale unui nod
In principiu metoda poate fi extinsa la structuri cu mai multe nivele de indirectare, insa structura prezentata este suficienta in practica. De exemplu, presupunând ca un bloc logic din sistemul de fisiere ocupa 1ko si ca un numar de bloc este adresabil pe 32 de biti, un bloc poate contine pâna la 256 numere de bloc. Dimensiunea maxima a unui fisier poate depasi 16 Go prin utilizarea tuturor celor 13 intrari, dupa cum arata si calculul din figura 4.7.
Întrucât câmpul din inod in care se pastreaza dimensiunea fisierului este are 32 biti, dimensiunea unui fisier este limitata practic la 4 Go (232).
10 blocuri directe a câte 1ko fiecare ___________ 10 ko
1 bloc indirect de 256 blocuri directe ___________ 256 ko
1 bloc dublu de 256 blocuri indirecte___________ 64 Mo
1 bloc triplu de 256 blocuri duble ______________ 16 Go
Figura 4.7. Capacitatea unui fisier - blocuri de 1ko
Procesele acceseaza datele unui fisier specificând deplasamentul. Daca utilizatorul vede fisierul ca pe un sir de octeti, nucleul îl vede ca un sir de blocuri, realizând in acest sens si o conversie. Fisierul începe de la blocul logic 0 si continua pâna la un numar de bloc logic corespunzator dimensiunii fisierului.
algoritm bmap
intrari: (1) inod
(2) deplasamentul
iesiri: (1) numarul blocului în sistemul de fisiere
(2) deplasamentul din bloc
(3) numar de octeti din bloc transferati prin operatii de I/O
(4) numarul blocului citit în avans
Figura 4.8. Obtinerea numarului blocului din sistemul de fisiere pe
baza deplasamentului
Nucleul acceseaza inodul si converteste numarul de bloc logic in numarul de bloc disc. Figura 4.8 prezinta algoritmul bmap care determina blocul fizic de disc corespunzator deplasamentului in fisier.
Consideram ca un fisier are blocurile dispuse conform figurii 4.9 si ca un bloc disc contine 1ko(1024octeti). Daca un proces intentioneaza sa acceseze octetul cu deplasamentul 9000, nucleul calculeaza ca octetul este in blocul direct 8 al fisierului (numarând de la 0). Apoi acceseaza (conform tabelei de cuprins a inodului) blocul cu numarul 367, iar octetul 808 din acesta reprezinta octetul 9000 din fisier.
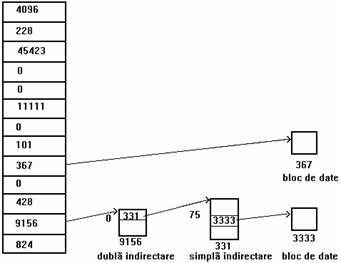
Figura 4. 9. Inodul si dispunerea blocurilor unui fisier
Daca un proces intentioneaza sa acceseze octetul cu deplasamentul 350 000 al unui fisier, el trebuie sa acceseze un bloc de dubla indirectare (conform figurii, numarul 9156). Deoarece un bloc de indirectare poate contine cel mult 256 numere de bloc, primul octet accesat prin blocul de dubla indirectare este octetul 272 384 (256 ko+10 ko) al fisierului. Astfel, octetul numarul 350 000 din fisier este octetul cu numarul 77 616 in blocul de dubla indirectata. Întrucât fiecare bloc de simpla indirectare acceseaza 256 ko, octetul numarul 350 000 trebuie sã fie in blocul de simpla indirectare cu numarul 331, corespunzator intrarii 0 in blocul de dubla indirectare. Deoarece fiecare bloc direct corespunzator unui bloc de simpla indirectare contine 1 ko, octetul numarul 77 616 al blocului de simpla indirectare este in blocul direct 75 al blocului de simplã indirectare, care are numarul 3333. In final, se determina ca octetul cu numarul 350 000 in fisier este octetul cu numarul 816 in blocul 3333.
Examinând mai atent figura, mai multe intrari de blocuri din inod sunt 0, ceea ce înseamna ca intrarile blocurilor logice nu contin date. Aceasta se întâmpla daca nici un proces nu a scris date in fisier la deplasamentul corespunzator acelor blocuri, si din acest motiv numerele de bloc ramân la valoarea lor initiala, 0. Pentru aceste blocuri nu se aloca spatiu pe disc. Procesele pot realiza o astfel de dispunere a blocurilor unui fisier utilizând apelurile sistem lseek si write (descrise in capitolul urmator).
Conversia unui deplasament de valoare mare, de exemplu unul care implica o tripla indirectare, este o procedura dificila care poate cere nucleului sa acceseze pe lânga inod si blocul de date cautat, inca trei blocuri disc. Chiar daca nucleul gaseste blocurile in buffer-ul cache, operatia este totusi consumatoare (de timp si resurse), deoarece nucleul trebuie sa faca multiple cereri de acces la buffere care pot fi blocate, trebuind in acest caz sa astepte deblocarea lor. In practica, eficienta algoritmului depinde de modul de utilizare a sistemului si de frecventa cu care utilizatorii acceseaza fisiere de dimensiuni mici sau mari. S-a observat ca majoritatea fisierelor intr-un sistem UNIX contin mai putin de 10 ko, si o parte însemnata dintre acestea chiar mai putin de 1 ko. Pentru ca cei 10 ko ai unui fisier sunt stocati in blocuri directe, majoritatea datele din fisier pot fi accesate printr-un singur acces la disc. In ciuda faptului ca accesarea fisierelor mari este o operatiune costisitoare, accesul la fisiere de dimensiuni obisnuite este rapid.
Accesul la sistemul de fisiere este cu atât mai rapid cu cât nucleul acceseaza mai multe date de pe disc in decursul unei operatii, altfel spus, cu cât dimensiunea blocurilor disc este mai mare. Folosirea blocurilor de dimensiuni mari (4 ko, 8 ko) aduce pe lânga avantajul cresterii vitezei, si un dezavantaj: cresterea fragmentarii blocurilor (mari portiuni de spatiu de pe disc nu pot fi utilizate). De exemplu, daca dimensiunea blocului logic este de 8 o, atunci un fisier de dimensiune 12 o va folosi complet un bloc si unul pe jumatate. Cei 4 ko ramasi se irosesc, deoarece nu pot fi folositi ca spatiu de stocare.
Implemetarea Berkeley BSD 4.2 remediaza situatia prezentata anterior prin introducerea blocurilor fragment ce contin ultimele date (care nu completeaza un bloc) din diferite fisiere. Aceste blocuri au tot dimensiunea de 4 ko sau 8 ko, dar sunt organizate ca o succesiune antet-date, unde antetul pastreaza informatii referitoare la fisierul caruia ii apartine fragmentul de date care-l urmeaza. Pentru a identifica blocul fragment care-i pastreaza partea finalã, fisierul pastreaza in ultima intrare adresa acestui bloc. Aceasta solutie va introduce o încetineala la accesul ultimului fragment.
4.3 Directoare
Directoarele sunt fisiere care dau sistemului de fisiere o structura ierarhica. Ele joaca un rol important in conversia numelui unui fisier intr-un numar de inod. Un director este un fisier ale carui date sunt o secventa de intrari, fiecare fiind alcatuita dint-un un numar de inod si numele fisierului continut in director. Un nume de cale este un sir de caractere terminat cu caracterul 'i 0', ale carui componente sunt separate prin caracterul '/'. Fiecare componenta, exceptie facând ultima, trebuie sa fie nume de director.
System V restrictioneaza dimensiunea maxima a unei componente la 14 caractere. Dimensiunea unei intrari in director este astfel de 16 octeti - 2 pentru numarul inodului, iar restul de 14 pentru numele fisierului continut in director.
Figura 4.10 descrie structura directorului "/etc". Orice director contine fisierele numite "." ºi "..", ale caror numere de inod sunt cel al directorului curent, respectiv al directorului parinte. Numarul de inod al fisierului "." din "/etc" este plasat la deplasamentul 0 in fisier, si are valoarea 83. Numarul inodului pentru ".." este plasat la deplasamentul 16, si are valoarea 2. O intrare in director este neocupata daca numarul de nod este 0. De exemplu, intrarea de la deplasamentul 224 este neocupata, si a continut o intrare pentru fisierul numit "crash". La initializarea sistemului de fisiere (folosind programul mkfs) numerele inodurilor fisierelor "." ºi ".." ale directorului radacina primesc valoarea inodului radacina al sistemului de fisiere. Nucleul stocheaza datele pentru un director la fel cum le stocheaza pentru un fisier obisnuit, utilizând structura de inod si nivelele de blocuri directe si blocuri indirecte.
|
Deplasamentul in director |
Numarul inodului (2 octeti) |
Numele fisierului |
|
init fsck clri motd mount mknod passwd umount checklist fsdblb config getty crash mkfs Inittab |
Figura 4. 10. Structura directorului "/etc"
Procesele pot citi directoarele in acelasi mod in care citesc fisierele obisnuite, dar nucleul isi rezervã dreptul exclusiv de a scrie un director, asigurându-i astfel o structura corecta. Permisiunile de acces la un director au urmatoarele semnificatii:
Cea de citire permite unui proces sa citeasca un director.
Cea de scriere permite unui proces sa modifice continutul unui director. Se pot crea intrari noi in director sau se pot sterge din cele vechi (folosind apelurile sistem creat, mknod, link si unlink).
Cea de executie permite unui proces sa caute un nume de fisier in director.
4.4 Translatarea nume fisier-inod
Accesul initial la un fisier se face precizând numele caii sale (vezi apelurile sistem open, chdir si link). Deoarece nucleul opereaza intern cu inoduri (si nu cu numele caii), pentru a accesa un fisier converteste numele caii sale in inod. Algoritmul namei analizeaza numele caii componenta cu componenta, convertind fiecare componenta pe baza numelui ei si a directorului in care se executa cautarea, si returneaza eventual inodul corespunzator numelui caii dat ca intrare (vezi figura 4.11).
Fiecare proces are asociat un directorul curent, iar zona sa u area contine un pointer catre inodul directorului curent. Directorul curent al primului proces din sistem (procesul 0) este directorul radacina. Directorul curent al oricarui alt proces este directorul curent al procesului parinte din momentul crearii. Procesele schimba directorul lor curent folosind apelul sistem chdir. Cautarea începe din directorul curent daca primul caracter din cale nu este "/", altfel va începe din directorul radacina. In ambele situatii nucleul gaseste usor inodul din care începe cautarea, deoarece directorul curent se regaseste in zona u area a procesului, iar inodul radacinii sistemului este memorata intr-o variabila globala.
Algoritmul namei utilizeaza inoduri intermediare in analiza unui nume de cale, numite inoduri de lucru (working inode). Primul inod de lucru, este cel din care se începe cautarea. Pe durata fiecarui ciclu din namei, nucleul se asigura ca inodul de lucru este al unui director. Altfel, sistemul ar încalca asertiunea ca fisierele care nu sunt directoare pot fi doar noduri frunza in arborele de fisiere. Procesul trebuie sa aiba si permisiunea de a cauta in director (permisiunea de citire nu este suficienta). Pentru aceasta identificatorul utilizator (UID) al procesului trebuie sa se potriveasca cu identificatorul proprietarului sau grupului (GID) fisierului, sau fisierul trebuie sa permita tuturor utilizatorilor cautarea. Astfel cautarea esueaza.
algoritm namei /* converteste nume cale într-un inod */
intrare: nume cale
iesire: inod blocat
else /* componenta nu este în director */
return (nici un inod);
}
return (inodul de lucru); }
Figura 4.11. Conversia nume cale-inod
Nucleul executa o cautare secventiala in fisierul director asociat inodului de lucru, încercând sa determine o potrivire intre componenta curenta a numelui caii si numele unei intrari in director. Pe baza deplasamentului (începând cu 0) in fisierul director se determina blocul disc corespunzator (folosind algoritmul bmap) pe care-l citeste (folosind algoritmul bread ). Tratând continutul blocului ca o secventa de intrari in director, nucleul cauta o intrare care se potriveste cu componenta curenta din numele caii. Daca gaseste o potrivire, el înregistreaza numarul inodului din intrarea respectiva, elibereaza blocul (algoritm brelse) si vechiul inod de lucru (algoritm iput), si aloca un inod componentei pentru care s-a realizat potrivirea (algoritm iget'). Acest inod devine noul inod de lucru. Daca nucleul nu determina nici o potrivire, elibereaza blocul si ajusteaza deplasamentul cu numarul de octeti corespunzator unui bloc, determina numarul blocului disc corespunzator noului deplasament (algoritm bmap) si citeste urmatorul bloc. Nucleul repeta procedura pâna gaseste o potrivire intre componenta din numele caii si un nume de intrare in director sau pâna ajunge la sfârsitul directorului.
Sa presupunem, de exemplu, ca un proces vrea sa deschida fisierul "/etc/passwd". Când nucleul începe analiza numelui caii, intâlneste caracterul '/' si obtine inodul radacina al sistemului. Dupa ce inodul radacina devine inod de lucru, nucleul receptioneaza sirul "etc". In continuare se verifica daca inodul curent ("/") este al unui director si daca procesul are permisiunile necesare de a cauta in el. Dupa aceea nucleu acceseaza datele din directorul radacina bloc cu bloc, pâna localizeaza o intrare pentru "etc". Gasind intrarea, nucleul elibereaza inodul pentru radacina (algoritm iput) si aloca un inod corespunzator numarului inodului intrarii gasite (algoritm iget). Dupa ce se asigura ca "etc" este un director si ca are permisiunile necesare de cautare, nucleul cauta in "etc" bloc cu bloc o intrare pentru fisierul "passwd". Dupa cum reiese din figura 4.10, a noua intrare in director este cea cautata ("passwd"). Când o gaseste, nucleul elibereaza inodul pentru "etc", aloca un inod pentru "passwd" si, dupa ce constata ca nu mai sunt componente neanalizate, returneaza acest inod.
4.5 Superblocul
Pâna in punctul de fata al acestui capitol s-a descris structura unui fisier, presupunându-se ca inodul si blocurile disc folosite de un fisier au fost deja alocate. In urmatoarele subcapitole se va prezenta modul in care nucleul aloca inoduri si blocuri disc. Pentru a intelege mai bine algoritmii respectivi, se va analiza in continuare structura superblocului.
Superblocul contine urmatoarele câmpuri:
dimensiunea sistemului de fisiere;
numarul blocurilor libere in sistemul de fisiere;
o lista a blocurilor libere disponibile in sistemul de fisiere;
indexul urmatorului bloc liber din lista blocurilor libere;
dimensiunea listei de inoduri;
numarul de inoduri libere in sistemul de fisiere;
o lista cu inoduri libere in sistemul de fisiere;
indexul urmatorului inod liber din lista inodurilor libere;
câmpuri de blocare pentru lista inodurilor libere si lista blocurilor libere;
un bit de semnalizare care indica daca superblocul a fost modificat
Periodic, nucleul scrie pe disc superblocul in cazul in care au survenit modificari.
4.6 Alocarea unui inod la un fisier nou
Nucleul utilizeazã algoritmul iget pentru a aloca un inod cunoscut (al carui sistem de fisiere si numar de inod a fost determinat anterior). In algoritmul namei, nucleul determina numarul inodului pentru care are loc potrivirea unei componente din numele caii cu numele unei intrari din director. Un alt algoritm, ialloc asigneaza (aloca) un inod disc unui fisier nou creat.
Asa cum s-a mentionat in capitolul 2, sistemul de fisiere contine o lista de inoduri. Un inod este liber daca câmpul tip are valoarea 0. Când un proces are nevoie de un inod nou, nucleul ar putea teoretic sa caute un inod liber in lista de inoduri. Insa o astfel de cautare este neeconomica, necesitând cel putin o operatiune de citire (posibil de pe disc) pentru fiecare inod. Pentru imbunatatirea performantei, superblocul sistemului de fisiere contine o zona in care pastreaza numerele de inoduri libere din sistemul de fisiere.
In figura 4.12 se prezinta algoritmul ialloc pentru asignarea de noi inoduri. Pentru a evita conditiile de concurenta, nucleul verifica mai întâi daca alte procese nu au blocat accesul la lista de inoduri libere din superbloc. Daca lista cu numere de inoduri din superbloc nu este goala, nucleul asigneaza urmatorul numar de inod, aloca un inod liber in memoria interna pentru inodul disc asignat folosind algoritmul iget (citind inodul de pe disc daca este necesar), copiaza inodul disc in inodul din memoria interna, initializeaza câmpurile inodului si returneaza inodul blocat. Actualizeaza inodul disc pentru a arata ca acum este folosit: o valoare diferitã de zero a câmpului din inod ce contine tipul fisierului indica faptul ca inodul disc este asignat.
algoritm ialloc /* asigneaza un inod */
intrare: sistemul de fisiere
iesire: inod blocat
if (lista de inoduri din superbloc este goala)
/* lista inodurilor din superbloc nu este goala */
obtine un numar de inod din lista de inoduri din superbloc;
obtine inod (algoritm iget);
if (inodul nu este liber nici acum) /* a fost alocat altui fisier !!! */
/* inodul este liber */
initializeaza inodul;
scrie inodul pe disc;
decrementeaza contorul inodurilor libere din sistemul de fisiere;
return (inod);
}
}
Figura 4.12. Algoritmul pentru alocarea de inoduri noi
Daca lista inodurilor libere din superbloc este goala, nucleul citeste bloc cu bloc lista de inoduri de pe disc si umple lista din superbloc cu numere de inoduri libere, memorând totodata cel mai mare numar de inod gasit. Acesta, numit si inod memorat, este ultimul salvat in superbloc. Când nucleul va cauta din nou inoduri libere pe disc, va utiliza ca punct de plecare inodul memorat. In acest fel se elimina timpul ce s-ar pierde cu citirea blocurilor disc ce nu contin inoduri libere. Dupa completarea unui nou set de numere de inoduri libere, nucleul reia algoritmul de alocare a inodurilor. La fiecare asignare a unui inod disc, nucleul decrementeaza contorul cu numarul inodurilor libere aflat in superbloc.
In continuare se prezinta modul in care se manipuleaza lista de inoduri libere din superbloc la asignarea unui inod liber. Daca lista arata ca primul sir al figurii 4.13 (a) atunci când nucleul aloca un inod, el decrementeaza indexul pentru urmatorul numar valid de inod la 18 si utilizeaza numarul de inod 48. Daca lista arata ca primul sir al figurii 4.13 (b), nucleul va observa ca sirul este gol si cauta pe disc inoduri libere începând de la numarul de inod 470, care este inodul memorat. Când nucleul completeaza lista libera din superbloc, el memoreaza ultimul inod ca punct de start pentru urmatoarea cautare pe disc. Nucleul asigneaza apoi un inod care tocmai a fost luat de pe disc (471 in figurã).
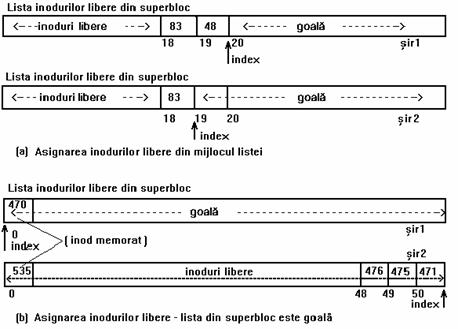
Figura 4.13. Doua siruri de numere de inoduri libere
Algoritmul pentru eliberarea inodurilor este mult mai simplu. Dupa incrementarea numarului total de inoduri disponibile in sistemul de fisiere, nucleul verifica daca superblocul este blocat. Daca este, pentru a evita conditiile de concurenta algoritmul se încheie imediat. Numarul inodului nu este depus in superbloc, insa poate fi gasit pe disc si este disponibil pentru reasignare.
algoritm ifree /* eliberare inod */
intrare: numar inod din sistemul de fisiere
iesire: niciuna
else
return;
pune numarul inodului în lista inodurilor libere;
Figura 4.14. Algoritmul pentru eliberarea inodurilor
Daca lista nu este blocata, nucleul verifica daca mai este spatiu in lista de inoduri, si daca este, plaseaza numarul de inod in lista dupa care algoritmul se încheie. Daca lista este plina, se compara numarul inodului eliberat cu cel al inodului memorat. Daca este mai mic, devine noul inod memorat. Vechiul inod memorat nu este pierdut, deoarece nucleul îl poate gasi la urmatoarea cautare in lista de inoduri de pe disc. Ideal ar fi sa nu existe inoduri libere ale caror numere sunt mai mici decât numarul inodului memorat, dar in realitate sunt posibile si astfel de situatii.
Sã considerãm, de exemplu, douã cazuri in care poate avea loc eliberarea inodurilor. Daca lista inodurilor libere din superbloc nu este plina, vezi figura 4.13 (a), nucleul plaseaza in lista numarul inodului si incrementeaza indexul la urmatorul inod liber. Daca lista de inoduri libere este plina, vezi figura 4.15 (a), nucleul compara numarul inodului eliberat (499) cu numarul inodului memorat (535), ai întrucât este mai mic, acesta devine noul inod memorat. Daca nucleul elibereaza apoi inodul 601 (vezi figura 4.15 (c) ), continutul listei de inoduri libere din superbloc nu va fi schimbat. Ulterior, dupa ce va consuma inodurile din lista liberã, nucleul va cauta inoduri libere pe disc începând cu numarul 499 si va regasi ainodurile 535 si 601.
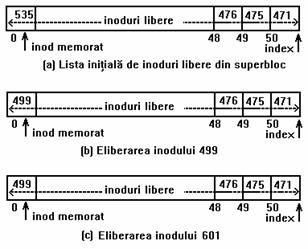
Figura 4.15. Plasarea numerelor de inoduri libere in superbloc
In paragraful anterior s-au descris situatiile simple ale algoritmilor. In cele ce urmeaza consideram cazul in care nucleul asigneaza un inod nou, iar apoi aloca o copie in memoria interna pentru acesta. In algoritmul ialloc se arata ca nucleul ar putea gasi inodul deja asignat. Desi rar, urmatorul scenariu prezinta un astfel de caz (vezi figurile 4.16 si 4.17). Se considera trei procese (A, B si C) si se presupune ca nucleul, actionând in numele procesului A, asigneaza inodul I, dar adoarme înainte de a copia inodul in memoria interna. Algoritmii iget (apelat de ialloc) si bread (apelat de iget) ofera mari sanse procesului A de a adormi. Cât timp procesul A este adormit, sa presupunem ca B încearca sa aloce un nou inod, dar descopera ca lista inodurilor libere din superbloc este goala. Procesul B începe cautarea de inoduri libere pe disc si sa presupunem ca isi începe cautarea de la un numar de inod mai mic decât al inodului pe care A îl asigneaza. Este posibil ca B sa gaseasca inodul I liber pe disc, deoarece A este inca adormit, si nucleul nu stie ca inodul I urmeaza sa fie asignat. Procesul B, fara a realiza pericolul, încheie cautarea pe disc si umple lista inodurilor libere din superbloc (I este printre elemente), dupa care asigneaza un inod si dispare din scenariu. Când A se trezeste, el încheie asignarea inodului I. Sa presupunem acum ca procesul C va solicita ulterior un inod liber si va primi inodul I. Când se creeaza copia din memoria interna pentru inod, el va gasi câmpul corespunzator tipului fisierului setat (diferit de 0), ceea ce arata ca inodul a fost deja asignat. Nucleul verifica aceasta conditie si daca inodul a fost deja alocat, încearca sa asigneze unul nou. Actualizarea inodului pe disc imediat dupa asignarea sa in ialloc, micsoreaza posibilitatea de aparitie a conditiilor de concurenta, deoarece câmpul tip fisier arata ca inodul este utilizat.
Pentru a preveni alte conditii de concurenta, lista de inoduri din superbloc va fi blocata pe durata citirii unui nou set de inoduri de pe disc. Daca lista din superbloc nu ar fi blocata, sa presupunem cazul in care ea este goala si un proces solicita un inod.
procesul A procesul B procesul C

Asigneaza inodul I din : :
superbloc : :
Doarme in timpul : :
citirii inodului (a) : :
: Încearca sa asigneze :
: un inod din super- bloc :
: Superblocul este gol (b) :
: Cauta inoduri libere pe disc, :
: pune inodul I in superbloc (c) :
Inodul I este utilizat in : :
memoria internã : :
: Încheie cautarea, :
: asigneaza un alt inod (d) :
: : Asigneaza inodul I din : : superbloc
: : Inodul I este utilizat ! : : Asigneaza un alt inod (c)
Timp
Figura 4.16. Conditii de concurenta ce au loc la asignarea inodurilor
Procesul încerca sa completeze lista cu inoduri de pe disc, iar pe durata operatiilor de I/O se va pune in asteptare. Daca un alt proces încearca si el sa asigneze un inod nou si gaseste lista goala, va executa ceea ce a executat si cel anterior. Aceasta dubla umplere a listei (de fapt o umplere si o rescriere) are ca efect folosirea ineficienta a resurselor, si constituie totodata o premisa importanta pentru cresterea conditiilor de concurenta de tipul celor descrise anterior. Similar, daca procesul elibereaza un inod si nu verifica daca lista este blocata, s-ar putea rescrie numere de inoduri aduse deja in lista libera aduse de un proces care executa popularea listei cu inoduri de pe disc.
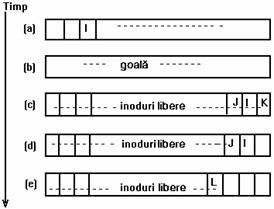
Figura 4.17. Conditii de concurenta ce au loc la asignarea inodurilor
Aceasta situatie ar genera conditii de concurenta de tipul celor descrise anterior mult mai frecvente. Desi nucleul rezolva satisfacator aceste conditii de concurenta, performantele sistemului au de suferit.
4.7 Alocarea blocurilor de date
Când un proces scrie date intr-un fisier nucleul trebuie sa aloce blocuri disc din sistemul de fisiere (folosite ca blocuri directe de date sau ca blocuri de indirectare). Superblocul sistemului de fisiere contine o lista in care sunt pastrate numerele de blocuri disc libere din sistemul de fisiere. Programul utilitar mkfs (make file system) organizeaza blocurile de date ale sistemului de fisiere intr-o lista inlantuita, fiecare element fiind un bloc disc care contine o lista de numere de blocuri disc libere, si o intrare din aceasta lista reprezinta numarul urmatorului bloc din lista inlantuita. Figura 4.18 prezinta un exemplu de lista inlantuita, unde primul bloc este lista libera din superbloc, iar celalalte blocuri din lista inlantuita contin numere de blocuri libere.
Când nucleul intentioneaza sa aloce un bloc dintr-un sistem de fisiere (algoritmul alloc, figura 4.19), aloca urmatorul bloc disponibil din lista aflata in superbloc. Odata alocat, blocul nu poate fi realocat pâna când el nu devine liber. Daca blocul alocat este ultimul bloc disponibil din superbloc, nucleul îl trateaza ca un pointer la un bloc care contine o alta lista de blocuri libere.
El citeste blocul, completeaza lista din superbloc cu noua lista de numere de blocuri, si apoi permite utilizarea blocului (care a fost tratat ca pointer). El aloca un buffer pentru bloc si sterge datele din buffer (le pune pe 0). Blocul disc a fost asignat si nucleul are acum la dispozitie un buffer cu care lucreaza. Daca sistemul de fisiere nu contine blocuri libere, procesul apelator receptioneaza o eroare.
Daca un proces scrie mai multe date intr-un fisier, el cere repetat sistemului blocuri pentru a stoca datele, insa nucleul i le aloca bloc cu bloc (nu se aloca mai multe blocuri deoadata). Programul mkfs încearca sa organizeze lista inlantuita initiala cu numere de blocuri libere, astfel încât numerele de blocuri distribuite unui fisier sa fie unul lânga celalalt. Aceasta duce la marirea performantelor sistemului deoarece se reduce timpul de cautare pe disc si perioada in care un proces asteapta citirea unui fisier secvential.
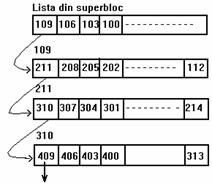
Figura 4.18. Lista inlantuita a numerelor blocurilor disc libere
Figura 4.18 prezinta numere de blocuri dispuse intr-un tipar obisnuit, bazat probabil pe viteza de rotatie a discului. Din pacate, ordinea numerelor de blocuri libere din lista inlantuita se abate foarte mult de la acest mod de dispunere pe masura ce procesele scriu si sterg fisiere, deoarece numerele de blocuri intra si parasesc aleator lista libera. Nucleul nu sorteaza numerele de blocuri in lista liberã.
Algoritmul free pentru eliberarea unui bloc este invers celui de alocare a unui bloc. Daca lista din superbloc nu este plina, numarul blocului eliberat este plasat in lista. Daca lista este plina, blocul eliberat devine bloc de legatura, adica nucleul scrie lista din superbloc in blocul eliberat si scrie blocul pe disc. Apoi, plaseaza numarul blocului nou eliberat in lista din superbloc, acesta fiind singurul element al listei.
algoritm alloc /* alocarea unui bloc din sistemul de fisiere */
intrare: numarul sistemului de fisiere
iesire: buffer pentru noul bloc
scoate un bloc din lista libera din superbloc;
if (s-a scos ultimul bloc)
obtine buffer pentru blocul scos din superbloc(algoritm getblk );
continutul bufferului este pus pe zero;
decrementeaza contorul total al blocurilor libere;
marcheaza faptul ca superblocul a fost modificat;
return buffer; }
Figura 4.19. Algoritmul pentru alocarea blocurilor disc
In exemplul din figura 4.20 se prezinta o secventa de operatii alloc si free asupra listei libere din superbloc care initial contine un singur numar (vezi figura 4.20 (a)). Nucleul elibereaza blocul numarul 949 si plaseaza numarul acestuia in lista libera (vezi figura 4.20 (b)). Dupa aceea, se solicitã douã blocuri. Nucleul asigneaza întâi blocul numarul 949 (vezi figura 4.20 (c)), dupa care aloca si scoate blocul numarul 109 din lista libera. Deoarece lista libera din superbloc este acum goala, nucleul copiaza in lista din superbloc continutului blocului 109, urmatorul element din lista inlantuita (vezi figura 4.20 (d)), iar urmatorul bloc de legatura devine blocul 211.
Algoritmii pentru asignarea si eliberarea inodurilor si blocurilor disc sunt similari, nucleul utilizând superblocul ca un cache pentru indici de resurse libere (numere de blocuri si numere de inoduri).

Figura 4.20. Cereri si eliberari de blocuri disc
Nucleul pastreaza o listã inlantuita cu numere de blocuri in care va putea fi regasit numarul oricarui bloc liber din sistemul de fisiere. O astfel de lista nu se pastreaza si pentru inodurile libere.
Motivele acestei tratari diferentiate sunt :
Pentru a determina daca un nod este liber nucleul verifica daca câmpul tip fisier este 0. In cazul blocurilor, el nu poate determina daca un bloc este liber doar printr-o simpla inspectare. Astfel, este necesara o metoda externa pentru identificarea blocurilor libere, iar implementarile obisnuite utilizeaza o listã inlantuita.
Blocurile disc se preteaza la folosirea in structuri de tip lista inlantuita. Un bloc disc poate cuprinde cu usurinta liste mari cu numere de blocuri libere. In schimb, inodurile nu au loc suficient pentru pastrarea unui numar mare de numere de inoduri libere.
Utilizatorii consuma mult mai multe blocuri disc decât inoduri, astfel ca performantele legate de cautarea blocurilor disc libere au un rol important in stabilirea performantelor generale ale sistemului.
4.8 Alte tipuri de fisiere
Sistemul UNIX permite folosirea altor doua tipuri de fisiere: fisierul pipe si fisierul special.
Un fisier pipe (uneori numit fifo) se deosebeste de unul obisnuit prin faptul ca datele sale sunt tranzitorii: odata ce datele sunt citite din pipe, ele nu mai pot fi citite din nou. Stocarea datelor intr-un pipe se face ca la fisierele obisnuite, cu deosebirea ca se utilizeaza numai blocuri directe.
Celalalt tip de fisiere din sistemul UNIX îl constituie fisierele speciale (bloc si caracter). Acest tip este caracteristic dispozitivelor, si de aceea inodurile fisierelor nu refera niciodata date. In schimb, inodul contine doua numere: major, care indica tipul dispozitivului (de exemplu, terminalul sau discul) si minor, care reprezinta numarul unitatii dispozitivului.
|
