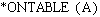Restrictii

CUPRINS
Definirea problemei satisfacerii restrictiilor
Instante ale problemei satisfacerii restrictiilor
Satisfacerea restrictiilor ca problemã de cãutare în spatiul stãrilor
Cadrul logic al problemei satisfacerii restrictiilor
Reprezentarea problemei ca demonstrare a teoremelor în calculul cu predicate
Reprezentarea problemei ca demonstrare a teoremelor în calculul propozitional
Reprezentarea problemei în limbajele logice
Utilizarea satisfacerii restrictiilor în interpretarea desenelor
Problema etichetãrii desenelor
Determinarea restrictiilor de etichetare a desenelor
Metode de rezolvare a problemei satisfacerii restrictiilor
Îmbunãtãtirea performantelor algoritmilor de satisfacere a restrictiilor
Utilizarea euristicilor generale în rezolvarea problemei satisfacerii restrictiilor
Tehnici de modificare a spatiului de cãutare
Propagarea localã a restrictiilor
Satisfacerea restrictiilor fãrã backtracking
Tehnici prospective de îmbunãtãtire a performantelor cãutãrii
Algoritmul de backtracking cu predictie completã
Algoritmul de backtracking cu predictie partialã
Algoritmul de backtracking cu verificare predictivã
Tehnici retrospective de îmbunãtãtire a performantelor cãutãrii
Algoritmul de backtracking cu salt
Algoritmul de backtracking cu marcare
Algoritmul de backtracking cu multime conflictualã
Problema satisfacerii partiale a restrictiilor
Determinarea solutiei utilizînd algoritmul "branch and bound"
Determinarea solutiei utilizînd algoritmul de backtracking cu salt
Formalizarea rationamentului despre actiuni
Sistemul General Problem Solver
Planificare liniarã în sistemul STRIPS
Functionarea sistemului STRIPS
Planificare neliniarã în sistemul TWEAK
Modelul formal al planificãrii
Reguli de inferentã utilizate în învãtare
Clasificarea tipurilor de învãtare
Învãtarea bazatã pe explicatii
Tipuri de învãtare bazatã pe explicatii
Învãtare prin operationalizare
Învãtare utilizînd macrooperatorii
Învãtarea prin generalizare explicatã
Generalizarea bazatã pe explicatii
Achizitia schemelor explicative
Învãtarea euristicilor de control
Capitolul 4
restrictiilor Problema satisfacerii
Multe probleme de inteligentã artificialã pot fi formulate ca probleme de satisfacere a restrictiilor. Utilizarea unor algoritmi de cãutare sistematicã cu revenire, numiti algoritmi de backtracking, reprezintã o abordare ineficientã a acestor probleme întrucît acesti algoritmi conduc la o complexitate temporalã exponentialã. Plecînd de la schema de cãutare cu revenire în spatiul stãrilor, s-au propus douã modalitãti de bazã pentru îmbunãtãtirea performantelor cãutãrii: modificarea spatiului solutiilor pentru simplificarea cãutãrii, si utilizarea unor euristici pentru ghidarea procesului de cãutare.
Una dintre primele aplicatii ale problemei satisfacerii restrictiilor a fost întelegerea desenelor [Clowes,1971;Montanari,1974;Waltz,1975]. Algoritmul propus de Waltz pentru identificarea laturilor mutual restrictionate ale diagramei unei figuri tridimensionale are performante timp surprinzãtor de bune. Aceasta a dus la dezvoltarea unor algoritmi eficienti pentru cazuri particulare ale problemei, de cãtre Mackworth si Freuder [1985], si a unor algoritmi care, desi complex computationali, cresc performantele rezolvãrii [Mackworth,1977;Haralick, Eliot,1980;Dechter,1989].
Prezentarea problemei
Problema satisfacerii restrictiilor se poate formula, în cazul cel mai general, astfel: fiind date o multime de variabile, un domeniu de valori potentiale pentru fiecare variabilã si o multime de restrictii care specificã combinatiile de valori acceptabile ale variabilelor, se cere sã se gãseascã o atribuire de valori pentru fiecare variabilã astfel încît aceste valori sã satisfacã toate restrictiile. Aceastã atribuire de valori reprezintã solutia problemei.
Dacã domeniile de valori ale variabilelor sînt finite, atunci problema enuntatã devine problema satisfacerii restrictiilor finite. Domeniile de valori ale variabilelor pot fi însã si infinite, iar restrictiile, în loc sã fie specificate ca multimi de valori acceptabile, pot fi specificate sub forma unor multimi de intervale acceptabile [Hyvonen,1992]. În prezentarea ce urmeazã, toate consideratiile se vor face pentru cazul finit al problemei satisfacerii restrictiilor.
4.1.1 Definirea problemei satisfacerii restrictiilor
Fie ![]() o multime de variabile
cu valori într-o multime de domenii finite
o multime de variabile
cu valori într-o multime de domenii finite ![]() si
si ![]() o multime de restrictii,
fiecare indicînd valorile mutual compatibile pentru un subset de variabile. Astfel
o multime de restrictii,
fiecare indicînd valorile mutual compatibile pentru un subset de variabile. Astfel
![]() indicã valorile
compatibile ale variabilelor
indicã valorile
compatibile ale variabilelor ![]() . Problema satisfacerii restrictiilor cere sã se gãseascã o
atribuire de valori variabilelor,
. Problema satisfacerii restrictiilor cere sã se gãseascã o
atribuire de valori variabilelor, ![]() cu
cu ![]() , astfel încît toate restrictiile sã fie satisfãcute. Fiecare
astfel de atribuire diferitã reprezintã o solutie a problemei. În strînsã
legaturã cu definitia formalã a problemei satisfacerii restrictiilor se aflã,
dupã cum se va vedea în continuare, notiunile de grad al problemei si aritate a
problemei satisfacerii restrictiilor.
, astfel încît toate restrictiile sã fie satisfãcute. Fiecare
astfel de atribuire diferitã reprezintã o solutie a problemei. În strînsã
legaturã cu definitia formalã a problemei satisfacerii restrictiilor se aflã,
dupã cum se va vedea în continuare, notiunile de grad al problemei si aritate a
problemei satisfacerii restrictiilor.
Definitie. Gradul unei variabile este cardinalitatea domeniului ei de valori, aritatea unei restrictii este numãrul de variabile specificate de restrictie, gradul problemei este gradul maxim al variabilelor problemei, iar aritatea problemei este aritatea maximã a restrictiilor ei.
Exemplu. Fie o problemã de satisfacere a restrictiilor
pentru care multimea de variabile este ![]() , domeniile de valori ale variabilelor au cardinalitatea
, domeniile de valori ale variabilelor au cardinalitatea ![]() ,
, ![]() ,
, ![]() si multimea de restrictii
este
si multimea de restrictii
este ![]() cu
cu ![]() ,
, ![]() ,
, ![]() . În acest caz gradul variabilelor este
. În acest caz gradul variabilelor este ![]() ,
, ![]() ,
, ![]() , aritatea restrictiilor este
, aritatea restrictiilor este ![]() ,
, ![]() ,
,![]() , gradul problemei este 5 si aritatea problemei este 3.
, gradul problemei este 5 si aritatea problemei este 3.
Observatie. Existã o relatie directã între gradul si aritatea unei probleme. Ori de cîte ori o problemã este reformulatã cu o aritate mai micã, gradul ei creste.
4.1.2 Instante ale problemei satisfacerii restrictiilor
Problema satisfacerii restrictiilor, formulatã în sectiunea anterioarã, prezintã mai multe instante care se deosebesc prin urmãtoarele cerinte: se cere gãsirea unei solutii sau a tuturor solutiilor problemei; se cere cea mai bunã solutie; se cere sã se determine numãrul de solutii; intereseazã dacã existã o solutie sau o solutie partialã a problemei.
O solutie partialã a problemei satisfacerii restrictiilor reprezintã gãsirea unei atribuiri de valori variabilelor pentru a satisface o submultime de restrictii ale problemei. În cadrul acestei instante, cunoscutã sub numele de problema satisfacerii partiale a restrictiilor, apar douã valori interesante:
Rsuf, numãrul minim de restrictii ce trebuie satisfãcut, si
Rnec, numãrul de restrictii dupã care se poate considera cã s-a gãsit o solutie acceptabilã si nu se mai continuã cãutarea.
Ideea de bazã a problemei satisfacerii partiale a restrictiilor este relaxarea conditiilor impuse pentru a permite si alte atribuiri de valori variabilelor. Problema satisfacerii partiale a restrictiilor apare în urmãtoarele cazuri:
problema propusã spre rezolvare este suprarestrictionatã si nu admite solutii
problema este prea dificilã pentru a fi rezolvatã integral si se doreste gãsirea unei solutii "suficient de bune"
se cautã cea mai bunã solutie care poate fi obtinutã, în termenii unor resurse limitate.
Problema satisfacerii
totale a restrictiilor, a cãrei definitie a fost prezentatã în sectiunea
anterioarã, este un caz particular al celei partiale pentru care ![]() , unde R este numãrul total de restrictii.
, unde R este numãrul total de restrictii.
Revenind la instantele problemei satisfacerii restrictiilor, în general, aflarea numãrului sau existentei solutiilor necesitã generarea unei solutii, iar gãsirea celei mai bune solutii se reduce la gãsirea unei solutii sau a tuturor solutiilor utilizînd un criteriu de optim.
Instante ale problemei satisfacerii restrictiilor apar în multe domenii ale inteligentei artificiale, cum ar fi etichetarea si interpretarea imaginilor, izomorfismul grafurilor, colorarea grafurilor si realizabilitatea booleanã. Analiza circuitelor electrice si proiectarea sistemelor de revizuire a încrederii de tipul sistemelor de mentinere a consistentei datelor (Capitolul 5) conduc, de asemenea, la instante ale problemei satisfacerii restrictiilor.
Cele mai multe studii ale algoritmilor de rezolvare au fost
fãcute pentru problema satisfacerii restrictiilor de aritate doi, restrictii
numite si restrictii binare. Majoritatea problemelor de satisfacere a restrictiilor,
cazul finit, pot fi reformulate ca probleme cu restrictii binare. În acest caz
problema poate fi reprezentatã printr-un graf orientat si etichetat, numit graf de restrictii. În acest graf
fiecare nod reprezintã o variabilã, iar fiecare arc orientat specificã o
restrictie binarã Rij între
variabila Xi, asociatã nodului
i, si variabila Xj, asociatã
nodului j. În plus ![]() oricare ar fi Xi si Xj
variabile ale problemei. Între douã noduri neconectate în graf existã restrictia universalã, aceea care
implicã acceptarea tuturor combinatiilor de valori posibile între cele douã
variabile.
oricare ar fi Xi si Xj
variabile ale problemei. Între douã noduri neconectate în graf existã restrictia universalã, aceea care
implicã acceptarea tuturor combinatiilor de valori posibile între cele douã
variabile.
Exemplu. Se presupune existenta unui robot constient de restrictiile modei, robot ce trebuie sã se îmbrace într-o dimineatã. Robotul are la dispozitie o garderobã minimalã formatã din: pantofi (escarpeni si pantofi de tenis), cãmãsi (verde si albã) si pantaloni (bleu, gri si jeans). Robotului i s-au specificat urmãtoarele reguli ale modei:
1. Pantofii de tenis se pot purta numai cu jeans.
2. Escarpenii se pot purta numai cu pantalonii gri si cu cãmasa albã.
3. Cãmasa albã se poate îmbrãca fie cu jeans, fie cu pantalonii bleu.
4. Cãmasa verde se poate îmbrãca numai cu pantalonii gri.
Se poate îmbrãca robotul si cum?
Graful de restrictii pentru problema de mai sus este prezentat în Figura 4.1.

Figura 4.1 Problema îmbrãcãrii robotului
Problema robotului este o problemã de satisfacere a restrictiilor binare, în care existã trei variabile: Pantofi, Pantaloni, Cãmãsi, cu domeniile de valori DPf, DPt, respectiv DC. Aritatea problemei este evident 2 (restrictii binare), iar gradul problemei este 3. Aceastã instantã a problemei satisfacerii restrictiilor cere sã se determine dacã existã solutie si care este aceastã solutie, în cazul în care ea existã. Cititorul este îndemnat sã încerce gãsirea unei solutii pe cale informalã.
4.1.3 Satisfacerea restrictiilor ca problemã de cãutare în spatiul stãrilor
Problema satisfacerii restrictiilor este, în cazul general, o problemã grea, deci NP-completã, exponentialã în raport cu numãrul de variabile ale problemei. Aceastã problemã poate fi privitã si ca o problemã de cãutare în spatiul multimilor de restrictii. Starea initialã a procesului de cãutare contine restrictiile identificate în descrierea initialã a problemei. Starea finalã este o stare care a fost restrictionatã "suficient" pentru a rezolva problema.
Fiind o problemã de cãutare, rezolvarea problemei
satisfacerii restrictiilor poate fi fãcutã aplicînd una din tehnicile de
cãutare a solutiei în spatiul stãrilor [Nilsson,1980;Barr,1982;
Deoarece problema satisfacerii restrictiilor este o problemã NP-completã, este evident cã nu s-a gãsit încã un algoritm eficient de rezolvare pentru cazul general. Studiile efectuate au dus însã la urmãtoarele rezultate:
(a) Identificarea unor subclase de probleme de satisfacere a restrictiilor care pot fi rezolvate în timp polinomial. Considerarea caracteristicilor particulare ale problemei poate duce la eliminarea completã a procesului de cãutare în rezolvarea problemei, asa cum se va arãta în Sectiunile 4.3 si 4.5.
(b) Îmbunãtãtirea timpului de executie, chiar dacã complexitatea temporalã rãmîne în continuare exponentialã. Procesul de cãutare cu revenire poate deveni mai eficient dacã se utilizeazã variante îmbunãtãtite ale algoritmului de backtracking, variante ce vor fi prezentate în Sectiunile 4.6 si 4.7.
În realitate problema satisfacerii restrictiilor prezintã o
caracteristicã suplimentarã fatã de problemele generale de cãutare. Propagarea
restrictiilor de la o variabilã la alta poate reduce semnificativ spatiul de
cãutare. În plus, în functie de caracteristicile fiecãrei probleme, multimea de
restrictii poate fi extinsã cu restrictii suplimentare. Se considerã exemplul
urmãtoarei criptograme ![]() în care se cere sã se
asocieze consistent cifre literelor, astfel încît relatia matematicã între
numerele rezultate sã fie îndeplinitã. Multimea initialã de restrictii este
definitã astfel: fiecare cifrã corespunde unei singure litere si suma cifrelor
trebuie sã satisfacã relatia. Aceastã multime initialã de restrictii poate fi
extinsã prin includerea restrictiilor inferate din regulile aritmeticii. De
exemplu, din criptograma specificatã
în care se cere sã se
asocieze consistent cifre literelor, astfel încît relatia matematicã între
numerele rezultate sã fie îndeplinitã. Multimea initialã de restrictii este
definitã astfel: fiecare cifrã corespunde unei singure litere si suma cifrelor
trebuie sã satisfacã relatia. Aceastã multime initialã de restrictii poate fi
extinsã prin includerea restrictiilor inferate din regulile aritmeticii. De
exemplu, din criptograma specificatã
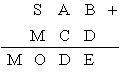
se poate deduce cã ![]() si
si ![]() sau
sau ![]() , deoarece
, deoarece ![]() , unde T reprezintã transportul de la cifra curentã la cifra
mai semnificativã. În continuare dacã
, unde T reprezintã transportul de la cifra curentã la cifra
mai semnificativã. În continuare dacã ![]() atunci
atunci ![]() , deci
, deci ![]() si cum transportul T
este 0 sau 1 se deduce restrictia
si cum transportul T
este 0 sau 1 se deduce restrictia ![]() sau
sau ![]() . Continuînd propagarea restrictiilor în acest mod, multimea
initialã de restrictii este semnificativ extinsã, deci spatiul de cãutare este
redus. Dupã ce toate restrictiile au fost propagate, se intrã într-un proces de
cãutare pentru gãsirea unei solutii.
. Continuînd propagarea restrictiilor în acest mod, multimea
initialã de restrictii este semnificativ extinsã, deci spatiul de cãutare este
redus. Dupã ce toate restrictiile au fost propagate, se intrã într-un proces de
cãutare pentru gãsirea unei solutii.
Asa cum se observã si din exemplul precedent, gãsirea unei solutii pentru o problemã de satisfacere a restrictiilor constã, în general, dintr-un ciclu format din doi pasi de bazã:
1. propagarea restrictiilor în scopul reducerii numãrului posibil de valori ale variabilelor
2. dacã nu s-a gãsit solutia se executã un proces de cãutare a valorilor pentru variabilelor care nu au încã atribuite valori unice.
În cazul unei anumite clase de probleme, i.e. cazul (a) de mai sus, executia pasului întîi este suficientã pentru a gãsi solutia, deci cãutarea nu mai este necesarã. Acesta este, de exemplu, cazul problemei etichetãrii consistente a desenelor utilizînd algoritmul de "filtrare" al lui Waltz. Deoarece etichetarea consistentã a desenelor a fost una din primele probleme de satisfacere a restrictiilor, problemele de tipul (a) se mai numesc si probleme de etichetare consistentã.
4.2 Cadrul logic al problemei satisfacerii restrictiilor
Este important de remarcat posibilitatea de abordare a problemei satisfacerii restrictiilor din perspectiva logicii simbolice, utilizînd proprietãtile si algoritmii specifici acesteia. Pentru o prezentare mai detaliatã a acestei perspective se poate consulta Mackworth [1992]. Consideratiile ce urmeazã se referã la cazul finit al problemei satisfacerii restrictiilor.
Fie urmãtoarea problemã, cunoscutã sub numele de problema steagului canadian. Se propune desenul prezentat în Figura 4.2 pentru steagul canadian si se cere sã se coloreze acest steag numai cu douã culori, rosu si alb, astfel încît fiecare regiune sã fie coloratã diferit fatã de regiunile învecinate iar frunza de artar sã fie rosie.

Figura 4.2 Problema steagului canadian
Problema este foarte simplã, solutia este evidentã, dar va servi, în continuare, ca suport al prezentãrii ideilor.
4.2.1 Reprezentarea problemei ca demonstrare a teoremelor în calculul cu predicate
1-Rezolvarea problemei satisfacerii restrictiilor poate
fi formulatã ca o demonstrare de teoreme, în formã restrinsã, în calculul cu
predicate de ordinul I. Astfel, axiomele sînt reprezentate de multimea restrictiilor
![]() , unde cij
sînt constante din domeniile de valori ale variabilelor problemei, elementele
multimii Restrictii fiind deci atomi de bazã. Concluzia, numitã în continuare
Scop, este
, unde cij
sînt constante din domeniile de valori ale variabilelor problemei, elementele
multimii Restrictii fiind deci atomi de bazã. Concluzia, numitã în continuare
Scop, este
![]()
unde ![]() este notatia
folositã pentru:
este notatia
folositã pentru:
![]() ...
...![]() ...
...
![]() .
.
În aceste conditii, problema satisfacerii restrictilor este
decidabilã. Acest lucru se poate demonstra prin construirea unei proceduri de
decizie. Universul Herbrand al setului de clauze ![]() este
este ![]() . Deoarece nu existã simboluri functionale, universul
Herbrand al setului de clauze este finit.
. Deoarece nu existã simboluri functionale, universul
Herbrand al setului de clauze este finit.
Algoritm: Decidabilitatea problemei satisfacerii restrictiilor
1. ![]()
2. pentru fiecare ![]() executã
executã
2.1 dacã
![]()
atunci ![]()
3. întoarce rezultat
sfîrsit.
În algoritmul de mai sus, Hn
este multimea constantã de nivel n din universul Herbrand, iar implicatia ![]() este adevãratã dacã si
numai dacã toti atomii din
este adevãratã dacã si
numai dacã toti atomii din ![]() apartin multimii de
restrictii. Acest algoritm se terminã întotdeauna si întoarce valoarea adevãrat dacã si numai
dacã multimea restrictiilor implicã concluzia Scop si fals în caz contrar.
Numãrul de predicate evaluate de acest algoritm este
apartin multimii de
restrictii. Acest algoritm se terminã întotdeauna si întoarce valoarea adevãrat dacã si numai
dacã multimea restrictiilor implicã concluzia Scop si fals în caz contrar.
Numãrul de predicate evaluate de acest algoritm este ![]() , unde
, unde ![]() reprezintã numãrul de
atomi din
reprezintã numãrul de
atomi din ![]() .
.
Pentru problema steagului canadian multimea restrictiilor, utilizînd notatiile: a si r pentru culorile alb si rosu; Stg, Dr, Ctr si Frunza pentru regiunile din stînga, dreapta, centru si respectiv frunza steagului si Neeg pentru neegalitatea a douã elemente, este
![]() ,
,
iar scopul este
![]()
![]()
![]() .
.
Universul Herbrand al multimii de clauze este ![]() , multimea constantã de nivel patru a universului Herbrand
fiind
, multimea constantã de nivel patru a universului Herbrand
fiind ![]() . Aplicînd algoritmul de decizie, rãspunsul pentru acest caz
este adevãrat cu instanta
. Aplicînd algoritmul de decizie, rãspunsul pentru acest caz
este adevãrat cu instanta ![]() .
.
Pentru a alege reprezentarea logicã cea mai potrivitã asociatã unei probleme, trebuie ales sistemul cu cele mai simple capacitãti descriptive capabil sã reprezinte problema. Asa cum se observã în Figura 4.3, problema satisfacerii restrictiilor cazul finit poate fi reprezentatã logic utilizînd logica propozitiilor, deci un sistem logic mai simplu decît cel al calculului cu predicate de ordinul I.

Figura 4.3 Relatia între anumite sisteme logice si sisteme de rezolvare a problemelor
4.2.2 Reprezentarea problemei ca demonstrare a teoremelor în calculul propozitional
Algoritmul de decizie prezentat în sectiunea anterioarã
poate fi interpretat ca implementarea unei demonstrãri de teoreme în calculul
propozitional. Dacã Scop este o teoremã, atunci ![]() este o formulã
inconsistentã. Problema satisfacerii restrictiilor are o solutie dacã si numai
dacã multimea
este o formulã
inconsistentã. Problema satisfacerii restrictiilor are o solutie dacã si numai
dacã multimea ![]() este falsã în orice
interpretare peste universul Herbrand.
este falsã în orice
interpretare peste universul Herbrand.
Deoarece nu existã cuantificatori universali în Scop, rezultã cã nu existã cuantificatori existentiali în ~Scop, deci nu existã functii Skolemn, ceea ce face ca universul Herbrand sã fie finit. Acest rezultat permite înlocuirea clauzei Scop cu multimea instantelor sale de bazã. Pentru cazul problemei steagului canadian multimea instantelor de bazã ale clauzei Scop este
![]()
![]()
![]() ....,
....,
![]() ...,
...,
![]() .
.
Se obtine o multime de clauze formatã dintr-o submultime de
clauze pozitive care rezultã din multimea de restrictii, si o submultime de
clauze negative care rezultã din concluzie. Se observã cã setul de clauze este
o multime de clauze Horn si este nerealizabil dacã si numai dacã problema
satisfacerii restrictiilor are solutie. Deoarece setul de clauze este Horn,
problema are complexitatea timp proportionalã cu dimensiunea formulei, dar
fiind ![]() clauze negative în
formulã, complexitatea timp este exponentialã în raport cu numãrul de
variabile, n. Acest rezultat este în concordantã cu afirmatia fãcutã la
începutul capitolului conform cãreia problema satisfacerii restrictiilor este o
problemã NP-completã.
clauze negative în
formulã, complexitatea timp este exponentialã în raport cu numãrul de
variabile, n. Acest rezultat este în concordantã cu afirmatia fãcutã la
începutul capitolului conform cãreia problema satisfacerii restrictiilor este o
problemã NP-completã.
Pentru demonstrarea teoremei Scop prin respingere rezolutivã se poate aplica strategia rezolutiei unitare, care este completã pentru clauze Horn în calculul propozitional. Asa cum s-a arãtat în Capitolul 3, problema este decidabilã.
4.2.3 Reprezentarea problemei în limbajele logice
Cel mai rãspîndit limbaj de programare logicã este limbajul Prolog [Clocksin,Mellish,1981]. Problema satisfacerii restrictiilor poate fi reprezentatã sub forma unui program Prolog, odatã ce s-a arãtat modul în care ea poate fi exprimatã ca formalism logic. În cazul problemei steagului canadian, reprezentarea Prolog a problemei este urmãtoarea:
stg(r). ctr(r). neeg(a,r).
stg(a). ctr(a). neeg(r,a).
dr(r). frunza(r).
dr(a).
?- stg(X), dr(Y), ctr(Z), frunza(U), neeg(X, Y), neeg(Y, Z), neeg(Y, U).
Solutia scopului Prolog indicat este
X = r, Y = r, U = r, Z = a
si reprezintã solutia problemei steagului canadian.
Pentru probleme complexe, o astfel de rezolvare, care utilizeazã numai strategia de backtracking a limbajului Prolog, poate fi foarte ineficientã. De aceea s-au dezvoltat diverse limbaje logice de satisfacere a restrictiilor, numite limbaje de programare logicã restrictivã. Pornind de la modelul Prolog, ideea de bazã a acestor limbaje este utilizarea satisfacerii restrictiilor în locul unificãrii, ca operatie de bazã a limbajului, realizarea consistentei locale prin propagarea restrictiilor si utilizarea strategiei de control "branch and bound", pe lîngã algoritmul de backtracking pentru problemele de optimizare. Exemple de astfel de limbaje sînt CHIP [Dincbas,s.a.,1990], CLP(R), cc(FD) [Hentenryck,1992] si altele.
4.3 Utilizarea satisfacerii restrictiilor în interpretarea desenelor
În sfera inteligentei artificiale intrã si robotica, ramurã a inteligentei artificiale care se ocupã de interfatarea rationamentului abstract cu lumea realã prin intermediul unor dispozitive de tip senzor si a unor motoare. În general un robot receptioneazã stimuli de la o serie de dispozitive (microfoane, camere video, sonare, etc.) si produce miscãri ale componentelor sale sau sunete.
Vizualizarea cu ajutorul calculatorului este un subdomeniu al roboticii care se ocupã de interpretarea informatiei vizuale. În general, un modul de vizualizare are douã componente: o componentã de nivel scãzut, ce determinã în imaginea primitã de la o camerã video linii, suprafete si texturi, si o componentã de nivel înalt, care va construi din elementele recunoscute de prima un model tridimensional al obiectelor prezente în imagine. În sectiunile urmãtoare vor fi prezentate elemente ale componentei de nivel înalt a vizualizãrii.
4.3.1 Problema etichetãrii desenelor
Problema etichetãrii desenelor poate fi enuntatã în urmãtorul mod: avînd ca elemente de intrare lista liniilor (muchiilor) si a vîrfurilor unor obiecte tridimensionale, determinate prin preprocesarea unei imagini, se cere sã se identifice obiectele din imagine. De exemplu, fiind date cele nouã linii ale desenului din Figura 4.4, care este modalitatea prin care ele sînt interpretate ca reprezentînd un obiect tridimensional, i.e. un paralelipiped si nu un hexagon cu trei linii în interior.
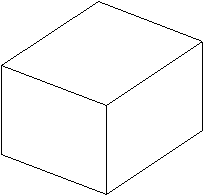
Figura 4.4 Desen - imagine reprezentatã prin linii si vîrfuri
Se pune problema întelegerii unui desen format din linii ce reprezintã obiecte cu fete plane. Aceasta revine la a determina care sînt liniile extreme ce separã obiectele, deci a determina ce obiecte si ce contururi de obiecte se gãsesc în imagine. Aparent, numãrul de combinatii posibile poate fi enorm, dar, în realitate acest numãr se reduce datoritã restrictiilor naturale existente în lumea obiectelor fizice. Aceste restrictii naturale pot fi utilizate pentru a limita interpretãrile posibile ale unui desen format din linii [Clowes,1971;Montanari,1974;Waltz,1975].
Waltz [1975] a propus un algoritm pentru etichetarea consistentã a desenelor formate din linii. Acesta este un algoritm de satisfacere a restrictiilor în care partea de cãutare este eliminatã. Algoritmul produce o etichetare consistentã a desenului numai pe baza restrictiilor naturale existente într-un astfel de desen.
Desi algoritmul lui Waltz poate fi extins pentru a acoperi si alte tipuri de obiecte, în discutia urmãtoare se vor considera numai desene ce reprezintã poliedre (obiecte tridimensionale solide ale cãror suprafete sînt plane si mãrginite de linii drepte) avînd numai vîrfuri triedre, adicã vîrfuri în care se întîlnesc exact trei plane. De exemplu, în Figura 4.5, obiectele (a) si (b) sînt obiecte triedrale, în timp ce obiectele (c) si (d) nu sînt triedrale, vîrfurile vizibile în care se întîlnesc mai mult de trei plane fiind marcate cu litera A.
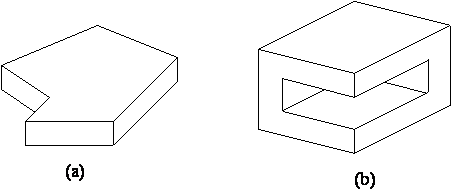
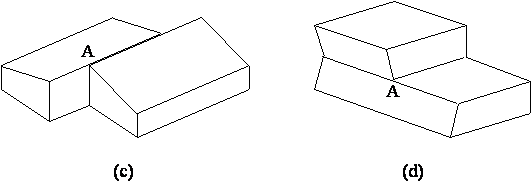
Figura 4.5 Tipuri de poliedre
O linie a unui desen ce respectã conditiile impuse mai sus poate fi linie convexã, linie concavã sau linie extremã. O linie convexã separã douã fete vizibile ale unui poliedru avînd proprietatea cã o linie care le uneste rãmîne în interiorul poliedrului. O linie concavã separã douã fete a douã poliedre avînd proprietatea cã o linie între cele douã fete ar trece prin spatiul extern obiectelor. O linie extremã exprimã aceeasi situatie fizicã ca si linia convexã, dar în acest caz desenul este orientat astfel încît numai una din cele douã fete ale poliedrului este vizibilã, deci o astfel de linie marcheazã frontiera dintre poliedru si fondul pe care acesta se aflã.
Pentru figuri mai complicate, trebuie considerate si alte tipuri de linii, de exemplu cele de demarcatie între fete distincte dar coplanare sau linii ce despart umbrele obiectelor de obiecte. Algoritmul lui Waltz poate fi usor extins pentru a lucra cu mai multe tipuri de linii, dar în continuare prezentarea va trata numai cazul desenelor în care apar cele trei tipuri de linii descrise anterior: convexe, concave si extreme.
Se considerã urmãtoarea conventie de etichetare a liniilor: + pentru linii convexe, pentru linii concave si sau pentru linii extreme. Directia de plasare a sãgetii, sau , pe liniile extreme depinde de pozitia fetei obiectului si a fondului fatã de linie. Dacã fata este la dreapta liniei si în jos atunci sãgeata se plaseazã , iar dacã fata obiectului este la dreapta liniei si în sus, plasarea sãgetii va fi . Altfel spus, parcurgînd linia în sensul dat de sãgeatã, poliedrul se va afla la dreapta liniei iar fondul desenului se va afla la stînga liniei. Deci, pentru liniile extreme, conventia de etichetare se poate stabili parcurgînd conturul format din aceste linii si mentinînd tot timpul obiectul la dreapta. Directia de mers este directia sãgetilor cu care se face etichetarea.

Figura 4.6 Conventia de etichetare a liniilor desenelor
Exemplu. Figura 4.7 prezintã etichetarea a douã paralelipipede utilizînd conventiile specificate. Vîrfurile A si A' sînt vîrfurile cele mai apropiate de privitor ale celor douã paralelipipede. Liniile care pornesc din A si A' sînt toate convexe. Liniile G'D' si D'F' sînt linii concave indicînd frontiera dintre cele douã paralelipipede care se aflã în contact. Restul liniilor sînt linii extreme indicînd faptul cã nu existã conexiune fizicã între cele douã paralelipipede, de exemplu B'E' si E'C', si între paralelipipedul P si fondul desenului, de exemplu BE si EC, dar existã alte laturi ale paralelipipedelor care nu pot fi vãzute.

Figura 4.7 Un exemplu de etichetare a liniilor unui desen
Observatie. Dacã în desenul din exemplul anterior, liniile G'D' si D'F' ar fi fost etichetate ca linii extreme, semnificatia desenului ar fi fost cu totul alta. În acest caz cele douã paralelipipede nu ar fi fost în contact, ele fiind deci "suspendate" în aer.
Odatã ce s-a reusit etichetarea desenului, se pot recunoaste
obiectele individuale si pozitiile lor relative. Considerînd cele patru
etichete posibile pentru linii (+, , si ), pentru un desen continînd N
linii existã ![]() posibilitãti de
etichetare a desenului. Trebuie deci
gãsit un rãspuns la întrebarea "Cum se poate gãsi etichetarea
corectã?". Pentru a realiza acest deziderat, trebuie tinut cont de faptul
cã fiecare linie are la capetele ei un vîrf. Pentru cazul figurilor triedrale,
existã numai patru tipuri de vîrfuri posibile: L, Furculitã, Sãgeatã si T,
prezentate în Figura 4.8.
posibilitãti de
etichetare a desenului. Trebuie deci
gãsit un rãspuns la întrebarea "Cum se poate gãsi etichetarea
corectã?". Pentru a realiza acest deziderat, trebuie tinut cont de faptul
cã fiecare linie are la capetele ei un vîrf. Pentru cazul figurilor triedrale,
existã numai patru tipuri de vîrfuri posibile: L, Furculitã, Sãgeatã si T,
prezentate în Figura 4.8.
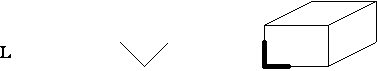
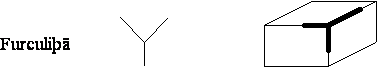
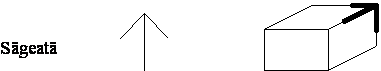
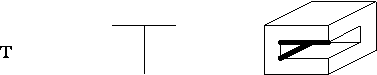
Figura 4.8 Cele patru tipuri de vîrfuri ale figurilor triedrale
Rotatia unui vîrf este nesemnificativã; de asemenea, nu conteazã nici dimensiunea unghiurilor, cu exceptia cazului în care trebuie fãcutã distinctia între unghiuri ascutite (<90o) si obtuze (>90o), pentru a distinge între vîrfuri de tip Furculitã si Sãgeatã.
4.3.2 Determinarea restrictiilor de etichetare a desenelor
Dacã se reuseste impunerea unui numãr limitat de etichetãri pentru fiecare tip de vîrf posibil, atunci aceste restrictii vor impune restrictii liniilor ce leagã aceste vîrfuri si se va reduce numãrul posibil de etichetãri ale desenului. Pentru a stabili restrictiile de etichetare a vîrfurilor, se considerã numãrul maxim de combinatii de linii pentru fiecare tip de vîrf:
Vîrful de tip L leagã 2 linii, deci are maximum 16 etichetãri posibile
Vîrfurile de tip T, Furculitã si Sãgeatã leagã 3 linii, deci au maximum 64 etichetãri posibile fiecare.
Existã deci un numãr maxim de 208 posibile etichetãri pentru un vîrf triedral. Care dintre acestea sînt efectiv permise de restrictiile lumii fizice? Pentru a putea rãspunde la aceastã întrebare se considerã cele trei plane care formeazã un vîrf triedru. Aceste plane împart spatiul tridimensional în opt pãrti (opt octanti), deoarece fiecare plan împarte spatiul în douã si nici unul din plane nu este identic sau paralel cu celãlalt. Obiectele de tip triedru pot fi diferite din punct de vedere al octantilor pe care îi ocupã si din punct de vedere al pozitiei din care sînt privite. Fiecare vîrf ce poate apare într-un obiect triedral corespunde unei pozitii a obiectului ce ocupã diversi octanti si unui octant liber din care se priveste vîrful.
Pentru a determina toate posibilitãtile reale de etichetare a vîrfurilor, trebuie sã se ia în considerare cum pot fi asezate obiectele în octanti si cum se pot vedea vîrfurile pentru aceste pozitii. Cei opt octanti formati de un vîrf triedru sînt reprezentati în Figura 4.9 (a). Figura 4.9 (b) prezintã un obiect care ocupã unul din cei opt octanti formati prin intersectia planelor corespunzãtoare vîrfului A.
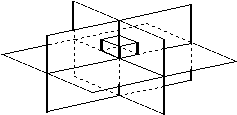 (a)
(a)
 (b)
(b)
Figura 4.9 Un poliedru care ocupã un octant
Dacã în Figura 4.9 (b) se priveste vîrful A din ceilalti sapte octanti liberi, directiile de privire fiind marcate prin sãgeti numerotate, se obtin urmãtoarele etichetãri posibile pentru vîrful A:
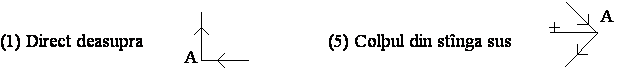
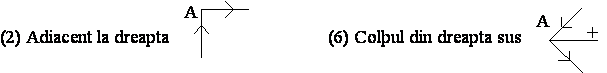
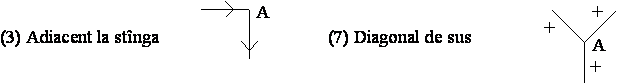
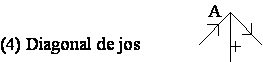
Dacã se considerã aceste sapte etichetãri si se eliminã rotatiile si variatiile unghiulare, se constatã cã rãmîn numai trei etichetãri distincte:

Dacã se continuã acest proces pentru obiecte ce ocupã doi octanti, trei octanti s.a.m.d. pînã la sapte octanti (nu pot exista vîrfuri dacã toti cei opt octanti sînt ocupati) atunci, dupã eliminarea etichetãrilor echivalente prin rotiri si variatii de unghiuri, se obtin numai 18 etichetãri fizice posibile pentru vîrfuri triedrale [Clowes,1971], prezentate în Figura 4.10.
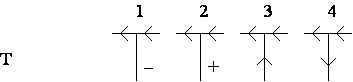
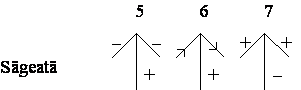

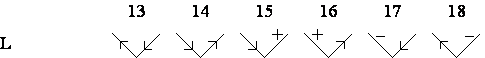
Figura 4.10 Cele 18 etichetãri posibile ale vîrfurilor triedrale
Din cele 208 de etichetãri posibile, numai 18 sînt fizic posibile. S-a gãsit deci o multime de restrictii destul de severe. Acelasi proces se poate aplica si pentru figuri ce contin si alte tipuri de linii sau vîrfuri ce nu sînt triedre. S-a descoperit cã raportul între numãrul de etichetãri fizic posibile si cel teoretic posibile în acest caz este chiar mai mic de 18/208.
În urma acestei analize s-a stabilit o multime de restrictii care vor fi folosite de algoritmul de etichetare a liniilor unui desen. Aceste restrictii sînt statice, deoarece regulile fizice pe care se bazeazã nu se schimbã niciodatã si nu trebuie sã fie reprezentate explicit ca stare a problemei. Restrictiile statice, determinate de restrictiile lumii fizice, pot fi codificate direct în algoritm. Cealaltã clasã de restrictii, restrictiile dinamice, reprezintã restrictiile de etichetare a vîrfurilor pentru fiecare desen în parte. Acestea vor fi reprezentate si prelucrate explicit de algoritm. Pornind de la restrictiile lumii fizice, descrise anterior, Waltz [1975] a propus un algoritm pentru rezolvarea problemei etichetãrii desenelor, algoritm care nu necesitã cãutare.
Waltz a proiectat un proces de filtrare care eliminã interpretãrile inconsistente în timpul analizei desenului si a observat experimental cã efortul necesar realizãrii procesului de filtrare este aproape liniar în raport cu dimensiunea desenului (numãrul de vîrfuri). Argumente euristice bazate pe semantica domeniului justificau informal aceastã comportare liniarã. Ulterior, Mackworth si Freuder [1985] au demonstrat formal cã orice proces de filtrare a desenelor de tipul celui propus de Waltz poate fi realizat în timp de complexitate liniarã. În plus, ei au identificat o întreagã subclasã de probleme de satisfacere a restrictiilor care admit rezolvãri în timp liniar, deci nu necesitã cãutare. Aceste probleme vor fi discutate în Sectiunea 4.5.
Ideea algoritmului lui Waltz este urmãtoarea: pentru a eticheta liniile din desen se selecteazã un vîrf si toate etichetãrile lui posibile, apoi se trece la un vîrf adiacent, cu toate etichetãrile lui posibile. Linia ce uneste cele douã vîrfuri trebuie, în final, sã fie etichetatã cu o singurã etichetã constistentã cu cele douã etichetãri ale vîrfurilor. Deci din multimile de etichetãri posibile ale celor douã vîrfuri se eliminã acele posibilitãti care fac ca linia ce le uneste sã nu aibã o etichetã unicã. Procesul se repetã pentru alte vîrfuri si restrictiile se propagã înapoi la vîrfurile deja selectate, deci setul de etichetãri posibile pentru acestea va fi redus si mai mult.
Exemplu. În Figura 4.11, vîrfurile 2, 4 si 6 sînt de tip Sãgeatã. Etichetarea începe cu liniile extreme si din cauza vîrfurilor 2, 4 si 6 etichetarea liniilor interioare va fi +, +, +. De fapt etichetarea vîrfului 7 se poate face numai pe baza vîrfului 2, deoarece acesta impune o linie + si singurul vîrf de tip Furculitã cu + este cel care are toate trei liniile etichetate cu +.

Figura 4.11 Un exemplu simplu al procesului de etichetare
În continuare se prezintã algoritmul de etichetare a desenelor care realizeazã procesul descris anterior. În algoritm, s-a notat cu NV numãrul vîrfurilor din desenul de etichetat, si cu LEV lista etichetãrilor posibile pentru un nod V, aceastã listã fiind specificã tipului nodului V, conform celor arãtate în sectiunea anterioarã. În cadrul algoritmului este folositã notiunea de etichetãri consistente conform cu definitia urmãtoare. Etichetarea unui vîrf, formatã din etichetele celor douã sau trei linii care îl determinã, este numitã în algoritm etichetã a vîrfului, iar listele de etichetãri ale vîrfului, liste de etichete, pentru simplificarea exprimãrii.
Definitie. Douã etichetãri apartinînd listelor de
etichetãri atasate la douã vîrfuri adiacente V si A, ![]() si
si ![]() , sînt consistente
dacã linia care leagã vîrful V de vîrful A are o etichetã un 444j91e icã determinatã de
etichetãrile EV si EA.
, sînt consistente
dacã linia care leagã vîrful V de vîrful A are o etichetã un 444j91e icã determinatã de
etichetãrile EV si EA.
Algoritm: Etichetarea desenelor
1. Identificã si eticheteazã liniile de contur exterior ale desenului
2. Numeroteazã vîrfurile desenului
2.1. Alege un vîrf V de pe o linie de contur si numeroteazã-l V
2.2. ![]()
2.3. cît timp mai sînt vîrfuri nenumerotate pe conturul exterior executã
2.3.1. Alege un vîrf nenumerotat de pe conturul exterior si numeroteazã-l Vi
2.3.2. ![]()
2.4. cît timp mai sînt vîrfuri nenumerotate în desen executã
2.4.1. Alege un vîrf deja numerotat Vk
2.4.2. Alege un vîrf nenumerotat, adiacent lui Vk, si numeroteazã-l Vi
2.4.3. ![]()
3. pentru ![]() pînã la NV executã
pînã la NV executã
3.1. ![]()
3.2. Marcheazã V ca vîrf vizitat
3.3. Asociazã lui V lista etichetelor LEV corespunzãtoare tipului de vîrf
3.4. pentru fiecare vîrf A adiacent cu V si deja vizitat executã
3.4.1. Eliminã din LEV etichetele care nu sînt consistente cu cel putin o etichetã din LEA
3.5. ![]()
sfîrsit.
![]()
pentru fiecare vîrf vizitat A, adiacent cu V executã
1. Eliminã din LEA etichetele ce nu sînt consistente cu cel putin o etichetã din LEV
2. dacã s-a eliminat cel putin o etichetã din LEA
atunci ![]()
sfîrsit.
Observatii:
În pasul 1 al algoritmului liniile conturului exterior sînt gãsite urmãrind un traseu astfel încît nici un vîrf sã nu rãmînã în exteriorul traseului, pornind dintr-un vîrf al conturului exterior. Etichetarea acestor linii se face respectînd conventiile enuntate în Sectiunea 4.3.1.
În pasul 2 numerotarea vîrfurilor apartinînd conturului exterior al desenului va corespunde ordinii în care acestea au fost vizitate în timpul procesului de etichetare de la pasul 1. Din aceastã cauzã pasul 1 si pasii 2.12.3 pot fi executati simultan.
Alegerea unui vîrf de pe conturul exterior, ca vîrf de plecare în propagarea restrictiilor, la pasul 2.1, se explicã prin faptul cã liniile conturului exterior, fiind deja etichetate la pasul 1, vor impune restrictii mai puternice asupra vîrfurilor mentionate.
În pasul 3.4 al algoritmului, asa cum se poate vedea, sînt satisfãcute restrictiile locale, în timp ce în pasul 3.5, prin apelul subprogramului Propagã, se realizeazã propagarea restrictiilor.
Acest algoritm va gãsi întotdeauna o etichetare unicã corectã si consistentã, dacã o astfel de etichetare existã. Dacã desenul este ambiguu, la terminarea algoritmului va exista cel putin un vîrf V avînd mai mult de o etichetã în lista de etichete atasate LEV. Un desen este ambiguu dacã în el apar si alte tipuri de linii si vîrfuri decît cele luate în consideratie în Sectiunea 4.3.1 sau dacã reprezintã o figurã imposibilã. Algoritmul lui Waltz se extinde usor si pentru cazul în care desenul include si alte tipuri de linii, provenite fie din figuri ce nu sînt triedrale, fie din desene cu umbre ale obiectelor. De fapt, programul scris de Waltz include si aceste cazuri. În plus, cu cît numãrul de tipuri de linii admise în desen este mai mare, cu atît raportul între numãrul de restrictii fizic posibile si numãrul de restrictii teoretic posibile este mai mic.
În cazul desenelor inerent ambigui, cum ar fi cel din Figura 4.12, algoritmul nu poate determina o etichetare consistentã deoarece aceasta nu existã.
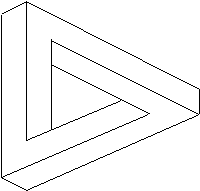
Figura 4.12 Desenul unei figuri imposibile, propus de R. Penrose
Procesul de filtrare prezentat în algoritmul lui Waltz poate fi executat în timp liniar pentru orice desen, complexitatea lui fiind O(n) si O(d), unde n este numãrul de vîrfuri si d este numãrul de etichetãri posibile ale vîrfurilor.
4.4 Metode de rezolvare a problemei satisfacerii restrictiilor
Problema etichetãrii desenelor, prezentatã în sectiunea anterioarã, reprezintã o instantã a unei subclase de probleme de satisfacere a restrictiilor care nu necesitã cãutare. Pentru cazul unei probleme generale de satisfacere a restrictiilor se pot pune urmãtoarele douã întrebari: "Cum se poate identifica dacã problema admite o rezolvare în timp liniar?" si "Cum se pot îmbunãtãti performantele procesului de cãutare în cazul în care problema necesitã un timp exponential de rezolvare?".
4.4.1 Metoda de bazã: backtracking
În cazul general, problema satisfacerii restrictiilor
este o problemã de cãutare în spatiul stãrilor. Strategia preferentialã de
rezolvare a acestei probleme este strategia de backtracking [Nilsson,1980;
Se prezintã în continuare douã variante ale algoritmului de
backtracking. Prima variantã, nerecursivã, este o adaptare a algoritmului
general de cãutare în adîncime care utilizeazã listele FRONTIERA si TERITORIU
pentru a memora nodurile explorate, respectiv expandate [
Algoritm: Backtracking nerecursiv
1. Creazã lista ![]() /*
Si este starea initialã */
/*
Si este starea initialã */
2. dacã ![]()
atunci întoarce INSUCCES /* nu existã solutie /*
3. Fie S prima stare din FRONTIERA
4. dacã toate stãrile succesoare ale lui S au fost deja generate
atunci
4.1. Eliminã S din FRONTIERA
4.2. repetã de la 2
5. altfel
5.1. Genereazã S', noua stare succesoare a lui S
5.2. Introduce S' la începutul listei FRONTIERA
5.3. Stabileste legãtura ![]()
5.4. Marcheazã în S faptul cã starea succesoare S' a fost generatã
5.5. dacã S' este stare finalã
atunci
5.5.1. Afiseazã calea spre solutie urmãrind
legãturile ![]()
5.5.2. întoarce SUCCES /* s-a gãsit o solutie */
5.6. repetã de la 2
sfîrsit.
Observatii:
Algoritmul de backtracking realizeazã o economie de spatiu considerabilã fatã de cel al cãutãrii în adîncime, deoarece memoreazã numai un singur succesor al stãrii curente. Acest avantaj este contracarat de imposibilitatea algoritmului de backtracking de a utiliza informatii euristice pentru evaluarea celor mai promitãtoare stãri urmãtoare.
În algoritmul prezentat nu s-a introdus o adîncime maximã de cãutare, deci s-a presupus spatiul de cãutare arbore finit.
Algoritmul prezentat gãseste o singurã solutie. El poate fi usor modificat pentru a determina toate solutiile.
O a doua variantã a algoritmului de backtracking, prezentatã în continuare, este o solutie recursivã si ea va sta la baza algoritmilor cu eficientã crescutã care vor fi prezentati în sectiunile urmãtoare. În algoritmul recursiv, orientat pe rezolvarea problemei satisfacerii restrictiilor, se folosesc urmãtoarele notatii:
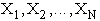 sînt variabilele problemei, N fiind numãrul de variabile ale
problemei,
sînt variabilele problemei, N fiind numãrul de variabile ale
problemei,
U este un întreg care reprezintã indicele variabilei curent selectate pentru a i se atribui o valoare,
F este un vector indexat dupã indicii variabilelor, în care sînt memorate selectiile de valori fãcute de la prima variabilã si pînã la variabila curentã; F[U] este deci valoarea atribuitã variabilei curente XU.

Algoritm: Backtracking recursiv
BKT ![]()
pentru fiecare valoare V a lui XU executã
1. ![]()
2. dacã Verificã ![]() = adevãrat
= adevãrat
atunci
2.1. dacã
![]()
atunci BKT ![]()
2.2. altfel
2.2.1. Afiseazã valorile din vectorul F /* F reprezintã solutia problemei */
2.2.2. întrerupe ciclul
sfîrsit.
Verificã ![]()
1. ![]()
2. ![]()
3. cît timp ![]() executã
executã
3.1. ![]()
3.2. ![]()
3.3. dacã
![]()
atunci întrerupe ciclul
4. întoarce test
sfîrsit.
În continuare se prezintã o implementare în limbajul Lisp a
strategiei de backtracking. Spre deosebire de algoritmul prezentat, structurile
de date utilizate nu sînt vectoriale, ci de tip listã, conform specificului
limbajului, iar functia BKT are trei parametri. Parametrul suplimentar Cale memoreazã o listã de perechi cu
punct ![]() , perechi ce reprezintã atribuirile fãcute pînã în momentul
apelului functiei. Initial acest parametru este nil, el completîndu-se treptat
cu o solutie a problemei. Parametrul Variabile
memoreazã lista variabilelor rãmase neinstantiate pînã în momentul apelului
functiei BKT. Primul element al acestei liste reprezintã variabila curentã a
procesului de backtracking. Parametrul Valori
memoreazã lista domeniilor de valori ale variabilelor neinstantiate. Primul
element al acestei liste este domeniul de valori al variabilei curente.
Predicatul Verifica-p este
codificarea Lisp a subprogramului Verificã. Verifica-p
utilizeazã predicatul exista-relatie-p,
corespunzãtor functiei Relatie din algoritm, si specific fiecãrei probleme
particulare, pentru verificarea compatibilitãtii atribuirilor de valori pentru
douã variabile. Variabilele speciale *VERIFICARI*
si *EXPANDARI* memoreazã numãrul de
teste de consistentã si de expandãri necesare pentru o anumitã solutie. Aceste
variabile sînt utile pentru a putea evalua performantele diverselor variante de
algoritmi de backtracking. Variabila specialã *SOLUTII* memoreazã solutiile unei probleme, fiecare solutie fiind
memoratã împreunã cu parametrii ei de calitate *VERIFICARI* si *EXPANDARI*.
Aici apare o altã diferentã fatã de algoritmul prezentat, în algoritm
determinîndu-se doar prima solutie a problemei. *VARIABILE* si *VALORI*
sînt douã variabile speciale care memoreazã lista de variabile si pe cea a
domeniilor de valori ale variabilelor specifice unei anumite probleme.
, perechi ce reprezintã atribuirile fãcute pînã în momentul
apelului functiei. Initial acest parametru este nil, el completîndu-se treptat
cu o solutie a problemei. Parametrul Variabile
memoreazã lista variabilelor rãmase neinstantiate pînã în momentul apelului
functiei BKT. Primul element al acestei liste reprezintã variabila curentã a
procesului de backtracking. Parametrul Valori
memoreazã lista domeniilor de valori ale variabilelor neinstantiate. Primul
element al acestei liste este domeniul de valori al variabilei curente.
Predicatul Verifica-p este
codificarea Lisp a subprogramului Verificã. Verifica-p
utilizeazã predicatul exista-relatie-p,
corespunzãtor functiei Relatie din algoritm, si specific fiecãrei probleme
particulare, pentru verificarea compatibilitãtii atribuirilor de valori pentru
douã variabile. Variabilele speciale *VERIFICARI*
si *EXPANDARI* memoreazã numãrul de
teste de consistentã si de expandãri necesare pentru o anumitã solutie. Aceste
variabile sînt utile pentru a putea evalua performantele diverselor variante de
algoritmi de backtracking. Variabila specialã *SOLUTII* memoreazã solutiile unei probleme, fiecare solutie fiind
memoratã împreunã cu parametrii ei de calitate *VERIFICARI* si *EXPANDARI*.
Aici apare o altã diferentã fatã de algoritmul prezentat, în algoritm
determinîndu-se doar prima solutie a problemei. *VARIABILE* si *VALORI*
sînt douã variabile speciale care memoreazã lista de variabile si pe cea a
domeniilor de valori ale variabilelor specifice unei anumite probleme.
(defparameter *EXPANDARI* 0)
(defparameter *VERIFICARI* 0
(defparameter *SOLUTII* nil)
(defun BKT (Cale Variabile Valori)
(let (Caleaux)
(dolist (Val (car Valori))
(when (Verifica-p (setf Caleaux (cons (cons (first Variabile) Val) Cale)))
(if (cdr Variabile)
(progn
(incf *EXPANDARI*)
(BKT Caleaux (rest Variabile) (rest Valori)))
(push (cons (cons *EXPANDARI* *VERIFICARI*) Caleaux) *SOLUTII*))))))
(defun Verifica-p (Cale)
"Verifica compatibilitatea primei asignari din Cale cu restul asignarilor.
Intoarce t dacã prima asignare este compatibila cu restul asignarilor din Cale
sau nil in caz contrar."
(let ((var (caar Cale))
(val (cdar Cale)))
(every #'(lambda (pereche)
(incf *VERIFICARI*)
(exista-relatie-p var val (first pereche) (rest pereche)))
(rest Cale))))
Solutiile unei probleme specifice se obtin prin apelul
(BKT nil *VARIABILE* *VALORI*)
Vizualizarea solutiilor si a parametrilor de calitate a acestora fiind posibilã prin apelul
(dolist (solutie (reverse *SOLUTII*))
(format t "~&Solutia: ~A Expandari: ~A Verificari: ~A"
(rest solutie)(caar solutie) (cdar solutie)))
4.4.2 Îmbunãtãtirea performantelor algoritmilor de satisfacere a restrictiilor
Principala metodã de rezolvare a problemei satisfacerii
restrictiilor este, asa cum s-a spus, algoritmul de backtracking. Utilizînd un
astfel de algoritm complexitatea timp este ![]() , iar complexitatea spatiu este
, iar complexitatea spatiu este ![]() . Algoritmul de backtracking este ineficient din mai multe
motive, printre care:
. Algoritmul de backtracking este ineficient din mai multe
motive, printre care:
Are o privire localã asupra rezolvãrii problemei, prin aceasta întelegînd
faptul cã dacã variabila X
are o valoare incompatibilã cu valoarea atribuitã variabilei ![]() , toate valorile pentru variabilele
, toate valorile pentru variabilele ![]() sînt totusi
verificate.
sînt totusi
verificate.
Utilizeazã un spatiu de memorie restrîns dar, datoritã acestui
lucru, nu memoreazã actiuni anterioare, ci le reexecutã dacã ajunge din nou la
executarea acestor actiuni. De exemplu, dacã prima valoare din domeniul
variabilei Xi este
incompatibilã cu prima valoare din domeniul variabilei ![]() , testul de incompatibilitate va fi efectuat prima oarã
pentru prima atribuire de valoare lui Xj,
dar si dupã fiecare revenire la o variabilã anterioarã lui Xi, si avans pînã la Xi, si apoi la Xj. Dacã astfel de incompatibilitãti sînt tinute
minte, este posibil sã se evite reefectuarea testelor cu rezultat cunoscut.
, testul de incompatibilitate va fi efectuat prima oarã
pentru prima atribuire de valoare lui Xj,
dar si dupã fiecare revenire la o variabilã anterioarã lui Xi, si avans pînã la Xi, si apoi la Xj. Dacã astfel de incompatibilitãti sînt tinute
minte, este posibil sã se evite reefectuarea testelor cu rezultat cunoscut.
Existã mai multe posibilitãti de îmbunãtãtire a performantelor algoritmului de backtracking utilizat în rezolvarea problemei satisfacerii restrictiilor, care duc la reducerea spatiului de cãutare dar, de multe ori, algoritmii rezultati folosesc mai multã memorie. Totusi, acesti algoritmi folosesc mai putinã memorie decît strategiile de cãutare în lãtime sau în adîncime. O clasificare a metodelor de îmbunãtãtire a performantelor algoritmilor de cãutare este prezentatã în continuare. De cele mai multe ori, aceste metode nu modificã complexitatea timp exponentialã a algoritmului, dar realizeazã cresterea eficientei procesului de cãutare.
Existã trei modalitãti de bazã pentru cresterea performantelor algoritmilor de rezolvare a problemei satisfacerii restrictiilor [Meseguer,1989].
(1) Algoritmi care modificã spatiul de cãutare prin eliminarea unor regiuni ce nu contin solutii. Acesti algoritmi pot fi împãrtiti, la rîndul lor, în douã categorii, prezentate mai jos.
(a) Algoritmi care modificã spatiul de cãutare înainte de a începe procesul de cãutare, numiti si algoritmi de îmbunãtãtire a consistentei reprezentãrii. Acesti algoritmi pot fi clasificati astfel:
Algoritmi care realizeazã consistenta localã a arcelor sau a cãilor în graful de restrictii
Algoritmi de cãutare fãrã backtracking, pentru o anumitã clasã de probleme care admite astfel de rezolvãri
Algoritmi de cãutare cu backtracking limitat
(b) Algoritmi care modificã spatiul de cãutare în timpul procesului de cãutare, numiti si algoritmi hibrizi deoarece modificarea spatiului de cãutare si cãutarea se executã în acelasi timp. Acesti algoritmi îmbunãtãtesc performantele rezolvãrii prin reducerea numãrului de teste. Algoritmii hibrizi pot fi clasificati astfel:
Tehnici prospective. La selectarea unei valori pentru o variabilã se verificã consistenta domeniilor de valori ale variabilelelor neconsiderate încã.
- Algoritmul de cãutare cu predictie completã
- Algoritmul de cãutare cu predictie partialã
- Algoritmul de cãutare cu verificare predictivã
Tehnici retrospective. La selectarea unei valori pentru o variabilã se verificã consistenta cu domeniile de valori ale variabilelor deja selectate.
- Algoritmul de backtracking cu salt
- Algoritmul de backtracking cu marcare
- Algoritmul de backtracking cu multime conflictualã
(2) Utilizarea euristicilor. Se stabilesc euristici generale, independente de problemã, care ghideazã cãutarea si ajutã la reducerea efortului de cãutare de cele mai multe ori. Acele euristici pot fi euristici de bazã, euristici teoretice sau euristici bazate pe retele.
(3) Utilizarea structurii unei probleme particulare pentru gãsirea unui algoritm eficient. În acest caz este vorba de fapt tot de utilizarea euristicilor, dar a euristicilor specifice problemei. Exemple de astfel de probleme sînt algoritmul de filtrare al lui Waltz prezentat în Sectiunea 4.3 si problema cãsãtoriilor stabile (Sectiunea 4.10).
Clasificarea de mai sus este departe de a fi exhaustivã si, în plus, diverse metode pot fi combinate. De exemplu, euristicile generale pot fi utilizate în una din tehnicile prospective sau retrospective. Modalitatea (2) de crestere a performantelor este prezentatã în sectiunea urmãtoare, iar cazurile (1a) si (1b) vor fi prezentate în Sectiunea 4.5 si respectiv sectiunile 4.6 si 4.7.
4.4.3 Utilizarea euristicilor generale în rezolvarea problemei satisfacerii restrictiilor
Utilizarea euristicilor în rezolvarea problemei satisfacerii restrictiilor se realizeazã prin considerarea urmãtoarelor ordonãri: ordonarea variabilelor în vederea atribuirii, ordonarea valorilor în vederea atribuirii, ordonarea testelor variabilelor anterioare si selectia variabilelor anterioare în backtracking. O combinatie adecvatã a acestor patru criterii permite implementarea unor euristici simple, cu un cost computational scãzut. Anumite criterii euristice dintre cele prezentate în continuare formeazã si ideea de plecare a anumitor tehnici prospective si retrospective.
Existã douã criterii de bazã pentru ghidarea cãutãrii. Dacã se cere gãsirea tuturor solutiilor problemei, se foloseste criteriul primei blocãri, în care sînt încercate întîi cele mai probabile cãi care ar putea conduce la insucces. Deoarece în cazul determinãrii tuturor solutiilor, tot spatiul de cãutare trebuie sã fie parcurs, detectarea cît mai devreme a cãilor care nu duc la solutie prezintã avantajul reducerii spatiului de cãutare. Dacã se cere gãsirea unei singure solutii, este bun criteriul cãii promitãtoare, i.e. criteriul invers. Se încearcã întîi cãile cele mai promitãtoare pentru gãsirea unei solutii.
În functie de criteriile prezentate anterior, se pot defini urmãtoarele euristici:
(1) Ordonarea variabilelor
Aceastã euristicã se bazeazã pe alegerea unei ordonãri a variabilelor astfel încît variabilele legate prin restrictii explicite sã fie consecutive. Acest criteriu încearcã sã evite, pe cît posibil, atribuiri de valori între variabile legate prin restrictii implicite. Restrictiile explicite sînt cele specificate de multimea de restrictii definitã în problemã. Ele se numesc asa pentru a le deosebi de restrictiile implicite, care apar ca efect lateral al celor explicite în procesul de inspectare a spatiului de cãutare.
Dacã se cer toate solutiile, variabilele care apar într-un numãr mic de restrictii si au domenii de valori cu cardinalitate micã, sînt preferate, deci asezate la început în ordonare. Dacã se cere numai o solutie, criteriul opus celui enuntat mai sus este cel adecvat. În acest caz, se încearcã mai întîi atribuiri de valori pentru variabilele cu domenii de valori cu cardinalitate mare si legate printr-un numãr mare de restrictii.
(2) Ordonarea valorilor
Aceastã euristicã tine cont de faptul cã nu toate valorile din domeniul variabilelor apar în toate restrictiile. Dacã se cer toate solutiile, pentru o variabilã fixatã se alege ca primã valoare de atribuit variabilei cea mai restrictionatã valoare, i.e. cea care permite cele mai putine atribuiri. Dacã se cere gãsirea unei singure solutii, se utilizeazã criteriul contrar.
(3) Ordonarea testelor
În tehnicile retrospective, dupã atribuirea unei valori unei variabile, se testeazã valoarea variabilei curente cu toate valorile atribuite variabilelor deja considerate. O euristicã utilã este aceea de a începe cu variabila precedentã cea mai restrictionatã. În tehnicile prospective, se va începe testarea cu variabilele care au domeniile de valori cele mai restrînse (cu cardinalitate micã).
(4) Ordonarea procesului de backtracking
Aceasta este euristica utilizatã de algoritmul de backtracking cu salt si de algoritmul de backtracking condus de dependente ce va fi prezentat în Capitolul 5. În acesti algoritmi, euristica generalã utilizatã impune ca revenirea sã se facã la variabila care a generat inconsistente pe un anumit nivel si nu la variabila imediat anterioarã. O altã euristicã posibilã este executarea revenirii la variabilele legate prin restrictii explicite de variabila curentã care a produs blocarea. Se presupune cã dacã se face întoarcerea în cãutare la o variabilã legatã prin restrictii explicite, se va gãsi mai repede o instantiere compatibilã pentru aceastã variabilã. Deci revenirea se face la variabile anterioare care au restrictii nesatisfãcute cu variabila curentã.
4.5 Tehnici de modificare a spatiului de cãutare
Una din metodele de îmbunãtãtire a performantelor algoritmului de backtracking pentru satisfacerea restrictiilor este eliminarea valorilor inconsistente din domeniile de valori ale variabilelor, înaintea începerii procesului de cãutare. Eliminarea partialã sau totalã a valorilor inconsistente modificã reprezentarea, deci domeniile de valori, si are drept consecintã importantã reducerea spatiului de cãutare. Procesul de eliminare a valorilor inconsistente ale variabilelor se poate realiza prin diverse forme de propagare a restrictiilor care vor fi discutate în continuare. În plus, prin recunoasterea anumitor proprietãti ale grafului de restrictii asociat problemei se pot identifica anumite subclase de probleme pentru care, dupã eliminarea valorilor inconsistente si fixarea unei ordonãri a variabilelor, procesul de cãutare nu mai este necesar. Aceste subclase de probleme vor fi prezentate în Sectiunea 4.5.3. Propagarea restrictiilor într-o formã sau alta este, evident, utilã atît timp cît complexitatea algoritmului de propagare rãmîne polinomialã, deci net eficientã fatã de cea a algoritmului de cãutare.
4.5.1 Propagarea restrictiilor
Restrictiile între douã variabile pot fi explicite si
implicite. Restrictiile explicite sînt date de multimea de restrictii ![]() dar cele implicite nu
apar nicãieri, ele fiind efecte laterale ale restrictiilor explicite. Dacã o
valoare asociatã unei variabile violeazã o restrictie implicitã, aceastã
incompatibilitate va fi detectatã mult mai tîrziu, dupã intrarea în actiune a
multimii de restrictii explicite ce determinã aceastã restrictie implicitã.
dar cele implicite nu
apar nicãieri, ele fiind efecte laterale ale restrictiilor explicite. Dacã o
valoare asociatã unei variabile violeazã o restrictie implicitã, aceastã
incompatibilitate va fi detectatã mult mai tîrziu, dupã intrarea în actiune a
multimii de restrictii explicite ce determinã aceastã restrictie implicitã.
Exemplu. Fie graful de restrictii prezentat în Figura
4.13 (a) si domeniile de valori ale variabilelor ![]() .
.

Figura 4.13 Transformarea restrictiilor implicite în restrictii explicite
Restrictiile R
si R interactioneazã si, ca
rezultat al acestei interactiuni, domeniul variabilei X se restrînge la . Acest rezultat
este propagat de restrictiile R
si R si domeniul variabilei
X se restrînge la , iar
domeniul variabilei X la .
Fatã de formularea initialã a problemei, restrictiile R si R
s-au schimbat si, în plus, a apãrut o nouã restrictie R , deci o nouã legãturã în graf între
nodurile corespunzãtoare variabilelor X
si X , ce erau initial legate
prin restrictia universalã. Noul graf
de restrictii obtinut prin modificarea reprezentãrii este prezentat în Figura
4.13(b). Domeniile de valori ale variabilelor, dupã explicitarea restrictiilor
implicite, sînt ![]() ,
, ![]() si
si ![]() .
.
Pentru a face explicite restrictiile implicite este nevoie de un astfel de proces de propagare a restrictiilor. Un graf în care toate restrictiile au fost propagate, deci fãcute explicite, se numeste graf minim de restrictii si este echivalent cu graful original, în sensul cã orice solutie a grafului initial de restrictii este solutie si pentru graful minim de restrictii.
Determinarea grafului minim de restrictii se numeste problema centralã. Aceastã problemã este la rîndul ei NP-completã, iar algoritmii de rezolvare a ei sînt de complexitate exponentialã. Ca atare, problema centralã nu prezintã un interes deosebit. Totusi, o versiune mai slabã a problemei, propagarea localã a restrictiilor, poate fi de mare interes.
4.5.2 Propagarea localã a restrictiilor
Se considerã un graf de restrictii orientat în care restrictiile între perechi de variabile sînt reprezentate prin douã arce orientate între nodurile corespunzãtoare celor douã variabile, fiecare arc fiind etichetat cu valorile ordonate acceptate de restrictie. În Figura 4.14 se prezintã exemplul unui graf de restrictii orientat, cu douã noduri si o restrictie. Evident, orice graf de restrictii poate fi reformulat ca un graf de restrictii ordonat prin transformarea legãturilor între noduri în arce (orientate) simetrice.

Figura 4.14 Graf orientat pentru reprezentarea unei restrictii
Într-un graf de restrictii orientat se definesc notiunile de
arc-consistentã si cale-consistentã [Montanari,1974;Mackworth,1977]. Se noteazã
cu ![]() asertiunea
"Combinatia de valori x si y pentru variabilele Xi si Xj
este permisã de restrictia explicitã Rij".
asertiunea
"Combinatia de valori x si y pentru variabilele Xi si Xj
este permisã de restrictia explicitã Rij".
Definitie. Un arc ![]() într-un graf de
restrictii orientat se numeste arc-consistent
dacã si numai dacã pentru orice valoare
într-un graf de
restrictii orientat se numeste arc-consistent
dacã si numai dacã pentru orice valoare ![]() , domeniul variabilei Xi,
existã o valoare
, domeniul variabilei Xi,
existã o valoare ![]() , domeniul variabilei Xj,
astfel încît
, domeniul variabilei Xj,
astfel încît ![]() .
.
Altfel spus, fiind datã perechea de variabile Xi, Xj, pentru fiecare valoare a variabilei Xi existã o valoare a variabilei Xj astfel încît restrictia Rij este satisfãcutã. Arc-consistenta se poate realiza prin testarea valorilor perechilor de variabile legate prin restrictii explicite. Realizarea arc-consistentei poate implica eliminarea anumitor valori din anumite domenii ale variabilelor, astfel încît graful rezultat sã fie arc-consistent; acest graf rezultat reprezintã aceeasi multime de solutii a problemei.
Definitie. Un graf de restrictii orientat este arc-consistent dacã toate arcele lui sînt arc-consistente.
Considerînd din nou exemplul robotului constient de restrictiile
modei, din Sectiunea 4.1.2, dacã se aplicã un algoritm de arc-consistentã, se
obtin urmãtoarele rezultate. Pantofii de tenis pot fi eliminati din DPf, domeniul de valori al variabilei
Pantofi, deoarece nu sînt consistenti cu nici o valoare din domeniul variabilei
Cãmãsi. Cãmasa verde poate fi eliminatã din DC,
domeniul de valori al variabilei Cãmãsi, deoarece nu este consistentã cu nici o
valoare din domeniul variabilei Pantofi, iar pantalonii bleu pot fi eliminati
din DPt, domeniul de valori al
variabilei Pantaloni, din acelasi motiv. Deoarece pantalonii de jeans pot fi
purtati cu pantofii de tenis, dar acestia au fost eliminati, atunci pot fi eliminati
si pantalonii de jeans din DPt.
Deci în acest moment ![]() ,
, ![]() si
si ![]() . Dar pentru cãmasa albã nu existã nici o restrictie care sã
permitã pantalonii gri, deci cãmasa albã se eliminã din DC. Rezultã
. Dar pentru cãmasa albã nu existã nici o restrictie care sã
permitã pantalonii gri, deci cãmasa albã se eliminã din DC. Rezultã ![]() , deci problema nu are solutie. Prin realizarea arc-consistentei
în acest caz a dispãrut necesitatea unui proces ulterior de cãutare.
, deci problema nu are solutie. Prin realizarea arc-consistentei
în acest caz a dispãrut necesitatea unui proces ulterior de cãutare.
Acest lucru nu se întîmplã pentru orice problemã, dar, de cele mai multe ori, realizarea arc-consistentei reduce domeniile de valori ale variabilelor, deci reduce spatiul de cãutare.
Definitie. O cale de lungime m prin nodurile ![]() ale unui graf de
restrictii orientat se numeste cale-consistentã
dacã pentru orice valoare
ale unui graf de
restrictii orientat se numeste cale-consistentã
dacã pentru orice valoare ![]() , domeniul de valori al variabilei i , si
, domeniul de valori al variabilei i , si ![]() astfel încît
astfel încît ![]() , existã o secventã de valori
, existã o secventã de valori ![]() astfel încît
astfel încît ![]() si
si ![]() si ...
si ... ![]() .
.
Observatie. ![]() poate fi si restrictia universalã, deci cea care permite
toate multimile de valori posibile.
poate fi si restrictia universalã, deci cea care permite
toate multimile de valori posibile.
Definitie. Un graf de restrictii orientat este cale-consistent dacã orice cale din graf este cale-consistentã.
Cu alte cuvinte, valorile permise de un arc între nodul Xi si nodul Xj trebuie sã fie permise si de o cale, diferitã de arcul XiXj, între nodul Xi si nodul Xj, ce poate include si restrictia universalã. Pentru realizarea cale-consistentei anumite perechi de valori care erau initial permise sînt eliminate, deci se adaugã restrictii suplimentare. În particular, dacã restrictia universalã era permisã între douã variabile si este restrictionatã de realizarea cale-consistentei, noi restrictii explicite vor fi generate, vor apare noi legãturi în graf si graful se va modifica.
Montanari [1974] si Mackworth [1977] au propus algoritmi
polinomiali pentru a realiza arc-consistenta si cale-consistenta unui graf de
restrictii. Complexitatea timp a algoritmului de realizare a arc-consistentei,
numit AC-3, este ![]() iar cea spatialã este
iar cea spatialã este ![]() , unde N este numãrul de variabile, a este cardinalitatea
maximã a domeniilor de valori ale variabilelor, iar e este numãrul de restrictii.
S-a gãsit chiar si un algoritm de complexitate temporalã
, unde N este numãrul de variabile, a este cardinalitatea
maximã a domeniilor de valori ale variabilelor, iar e este numãrul de restrictii.
S-a gãsit chiar si un algoritm de complexitate temporalã ![]() numit AC-4
[Mohr,Henderson,1986]. Pentru algoritmul de realizare a cale-consistentei,
numit PC-4, complexitatea timp este
numit AC-4
[Mohr,Henderson,1986]. Pentru algoritmul de realizare a cale-consistentei,
numit PC-4, complexitatea timp este ![]() [Mohr,
[Mohr,
Algoritm: AC-3: Realizarea arc-consistentei pentru un graf de restrictii.
1. Creeazã o
coadã ![]()
2. cît timp Q nu este vidã executã
2.1. Eliminã din Q un arc ![]()
2.2. Verificã![]()
2.3. dacã subprogramul Verificã a fãcut schimbãri în domeniile variabilelor
atunci ![]()
sfîrsit.
Verificã ![]()
pentru fiecare ![]() executã
executã
1. dacã nu existã nici o valoare ![]() astfel încît
astfel încît ![]()
atunci eliminã x din Dj
sfîrsit.
Arc-consistenta si cale-consistenta efectueazã propagarea localã a restrictiilor. Acesti algoritmi eliminã anumite valori din domeniul de definitie al variabilelor, valori care nu vor apare niciodatã în solutie. Pentru a rezolva o problemã, chiar dacã graful ei de restrictii este arc-consistent sau cale-consistent, tot avem nevoie, în cazul general, de un algoritm de cãutare, deoarece restrictiile nu s-au propagat global si tot pot apare situatii de insucces.
Generalizînd, o multime de k variabile este k-consistentã dacã pentru orice submultime
de ![]() variabile, cu valori
ce satisfac toate restrictiile pentru cele
variabile, cu valori
ce satisfac toate restrictiile pentru cele ![]() variabile, este
posibil sã se gãseascã o valoare pentru variabila de ordin k, astfel încît
restrictiile între cele k variabile sã fie satisfãcute. Pentru valorile
variabile, este
posibil sã se gãseascã o valoare pentru variabila de ordin k, astfel încît
restrictiile între cele k variabile sã fie satisfãcute. Pentru valorile ![]() si
si ![]() se obtin cazurile
particulare de arc-consistentã si cale-consistentã.
se obtin cazurile
particulare de arc-consistentã si cale-consistentã.
4.5.3 Satisfacerea restrictiilor fãrã backtracking
Existã probleme de satisfacere a restrictiilor care pot fi rezolvate fãrã cãutare cu reveniri. Fiecare pas fãcut de algoritmul de cãutare reprezintã un pas corect spre solutie. De fapt, procesul de cãutare nu este un proces neinformat si deci nu este nevoie de backtracking. Pentru aceastã categorie de probleme complexitatea timp a algoritmului de rezolvare este polinomialã.
În continuare se prezintã o caracterizare a acestor tipuri de probleme, prin corelarea conectivitãtii grafului de restrictii cu nivelul de consistentã localã.
Definitie. Un graf de restrictii ordonat este un graf de restrictii împreunã cu o ordonare a nodurilor asociate variabilelor problemei, ordonare ce reprezintã ordinea de selectare a variabilelor în algoritmul de backtracking.
Definitie. Intr-un graf de restrictii ordonat, lãtimea unui nod este egalã cu numãrul de arce care leagã acel nod de nodurile anterioare lui în ordonare.
Definitie. Intr-un graf de restrictii ordonat, lãtimea unei ordonãri a nodurilor este lãtimea maximã a nodurilor.
Definitie. Lãtimea unui graf de restrictii este valoarea minimã a lãtimilor de ordonare a nodurilor, pentru toate posibilitãtile de ordonare a nodurilor. Altfel spus,
![]()
Exemplu. Fie graful de restrictii din Figura 4.15 (a) si cele 6 ordonãri posibile ale variabilelor (Figura 4.15 (b)) într-un proces de cãutare a solutiei, ordonãri determinate de secventa de variabile considerate în cãutare. De pildã, pentru primul caz din Figura 4.15 (b) procesul de backtracking considerã variabilele în ordinea B, A, C. În aceastã primã ordonare, lãtimea nodului C este egalã cu doi, iar în cea de a doua ordonare lãtimea aceluiasi nod este este egalã cu unu. Considerînd toate cele sase ordonãri posibile se deduce lãtimea grafului de restrictii egalã cu unu.


Figura 4.15 Posibile ordonãri ale variabilelor într-un graf de restrictii
Freuder [1982] a gãsit un algoritm eficient, de complexitate
polinomialã ![]() , pentru a determina atît lãtimea grafului de restrictii cît si
o ordonare corespunzãtoare acestei lãtimi. Tot el a enuntat si demonstrat
urmãtoarele teoreme.
, pentru a determina atît lãtimea grafului de restrictii cît si
o ordonare corespunzãtoare acestei lãtimi. Tot el a enuntat si demonstrat
urmãtoarele teoreme.
Teoremã. Dacã un graf de restrictii arc-consistent are lãtimea egalã cu unu (i.e. este un arbore), atunci problema asociatã grafului admite o solutie fãrã backtracking.
Teoremã. Dacã un graf de restrictii cale-consistent are lãtimea egalã cu doi, atunci problema asociatã grafului admite o solutie fãrã backtracking.
Din prima teoremã rezultã cã problemele de satisfacere a
restrictiilor al cãror graf de restrictii este arbore pot fi rezolvate întîi prin
realizarea arc-consistentei si apoi prin instantierea variabilelor în orice
ordine de lãtime egalã cu unu. Testarea grafului de restrictii pentru a
vedea dacã este un arbore se realizeazã
în urmãtorul mod. Se construieste arborele de acoperire al grafului
[Sedgewick,1990] si se determinã dacã arborele de acoperire a inclus toate
arcele grafului de restrictii. Constructia arborelui de acoperire al grafului
de restrictii se poate face pe baza unui algoritm de complexitate polinomialã ![]() . Pentru un arbore, gãsirea unei ordonãri de lãtime egalã cu
unu se face prin enumerarea în preordine, i.e. rãdãcinã-stînga-dreapta, a
nodurilor. Enumerarea în inordine, i.e. stînga-rãdãcinã-dreapta, si postordine,
i.e. stînga-dreapta-rãdãcinã, produc ordonãri de lãtime mai mare decît doi.
. Pentru un arbore, gãsirea unei ordonãri de lãtime egalã cu
unu se face prin enumerarea în preordine, i.e. rãdãcinã-stînga-dreapta, a
nodurilor. Enumerarea în inordine, i.e. stînga-rãdãcinã-dreapta, si postordine,
i.e. stînga-dreapta-rãdãcinã, produc ordonãri de lãtime mai mare decît doi.
Deoarece instantierea variabilelor fãrã backtracking
necesitã ![]() pasi, si pentru arbori
pasi, si pentru arbori
![]() , întreaga problemã poate fi rezolvatã într-un timp
, întreaga problemã poate fi rezolvatã într-un timp ![]() , deoarece instantierea variabilelor necesitã
, deoarece instantierea variabilelor necesitã ![]() , realizarea arc-consistentei necesitã
, realizarea arc-consistentei necesitã ![]() , iar verificarea faptului cã graful de restrictii este
arbore necesitã
, iar verificarea faptului cã graful de restrictii este
arbore necesitã ![]() pasi. Se reaminteste
cã N este numãrul de variabile, a este cardinalitatea maximã a domeniilor de
valori ale variabilelor si e este numãrul de restrictii.
pasi. Se reaminteste
cã N este numãrul de variabile, a este cardinalitatea maximã a domeniilor de
valori ale variabilelor si e este numãrul de restrictii.
Pentru un graf de lãtime egalã cu doi, algoritmul de cale-consistentã poate adãuga arce în graf, deci lãtimea grafului poate creste, devenind mai mare ca doi. Aceasta se întîmplã în cazul în care algoritmul eliminã perechi de valori posibile pentru variabile care nu sînt legate în mod direct în graf, i.e. variabile legate initial prin restrictia universalã. Dacã graful de restrictii îndeplineste de la început premisele celei de-a doua teoreme a lui Freuder, atunci concluzia acesteia este adevãratã.
Dechter si Pearl [1987] au propus douã definitii mai slabe ale notiunilor de arc-consistentã si cale-consistentã, definitii care sînt, de asemenea, suficiente pentru a garanta gãsirea solutiei fãrã backtracking, dar au urmãtoarele avantaje fatã de cele ale lui Montanari si Mackworth:
pot fi realizate mai eficient
adaugã mult mai putine arce suplimentare la realizarea cale-consistentei, crescînd astfel sansele ca lãtimea grafului sã rãmînã egalã cu doi.
Realizarea arc-consistentei complete este mai mult decît
este nevoie pentru a obtine solutii fãrã backtracking. De exemplu, dacã în
graful de restrictii din Figura 4.16 ordonarea variabilelor este ![]() , nu se cîstigã nimic dacã se face arcul
, nu se cîstigã nimic dacã se face arcul ![]() consistent. Pentru a
asigura o atribuire de valori variabilelor fãrã backtracking, trebuie numai sã
se asigure faptul cã pentru orice valoare atribuitã variabilei X , existã cel putin o valoare consistentã
în domeniul D al variabilei X . Acest lucru poate fi realizat fãcînd
numai arcul
consistent. Pentru a
asigura o atribuire de valori variabilelor fãrã backtracking, trebuie numai sã
se asigure faptul cã pentru orice valoare atribuitã variabilei X , existã cel putin o valoare consistentã
în domeniul D al variabilei X . Acest lucru poate fi realizat fãcînd
numai arcul ![]() consistent, fãrã sã
mai intereseze dacã arcul
consistent, fãrã sã
mai intereseze dacã arcul ![]() este sau nu
consistent.
este sau nu
consistent.

Figura 4.16 Graf de restrictii ordonat ce demonstreazã suficienta
conditiei de ![]()
Se observã deci cã arc-consistenta este necesarã numai într-o singurã directie, în directia în care algoritmul de backtracking selecteazã variabilele pentru instantiere.
Definitie. Fiind datã o ordonare d a variabilelor unui graf de restrictii R, graful R este d-arc-consistent dacã toate arcele avînd directia d sînt arc-consistente.
Teoremã. Fie un graf de restrictii R, avînd ordonarea variabilelor d cu lãtimea egalã cu unu. Dacã R este d-arc-consistent atunci cãutarea dupã directia d este fãrã backtracking.
Algoritmul urmãtor realizeazã d-arc-consistenta unui graf de restrictii. El este o adaptare a algoritmului AC-3 pentru cazul unui graf de restrictii cu ordonarea variabilelor.
Algoritm: Realizarea
d-arc-consistentei unui graf de restrictii cu ordonarea variabilelor ![]()
pentru ![]() pînã la 1 executã
pînã la 1 executã
1. pentru fiecare arc ![]() cu
cu ![]() executã
executã
1.1. Verificã![]()
sfîrsit.
Acest algoritm are complexitatea timp ![]() . În algoritm, subprogramul Verificã este cel prezentat în
sectiunea anterioarã. Algoritmul realizeazã într-adevãr d-arc-consistenta unui
graf de restrictii. Dupã executia lui, orice arc
. În algoritm, subprogramul Verificã este cel prezentat în
sectiunea anterioarã. Algoritmul realizeazã într-adevãr d-arc-consistenta unui
graf de restrictii. Dupã executia lui, orice arc ![]() cu
cu ![]() , în ordonarea variabilelor d, este arc-consistent. Algoritmul verificã fiecare arc d-orientat
o singurã datã. Rãmîne sã se demonstreze cã prin prelucrarea arcelor urmãtoare
nu se violeazã consistenta unui arc deja vizitat. Fie
, în ordonarea variabilelor d, este arc-consistent. Algoritmul verificã fiecare arc d-orientat
o singurã datã. Rãmîne sã se demonstreze cã prin prelucrarea arcelor urmãtoare
nu se violeazã consistenta unui arc deja vizitat. Fie ![]() cu
cu ![]() arcul prelucrat de
Verificã
arcul prelucrat de
Verificã ![]() . Pentru a distruge consistenta arcului
. Pentru a distruge consistenta arcului ![]() , anumite valori din domeniul variabilei Xi ar trebui eliminate la continuarea
procesului. Dar, în functie de ordinea de apel al subprogramului Verificã,
numai variabile cu indici mai mici vor avea domeniile actualizate. Deci, odatã
ce un arc orientat este fãcut arc-consistent, consistenta lui nu va fi violatã.
, anumite valori din domeniul variabilei Xi ar trebui eliminate la continuarea
procesului. Dar, în functie de ordinea de apel al subprogramului Verificã,
numai variabile cu indici mai mici vor avea domeniile actualizate. Deci, odatã
ce un arc orientat este fãcut arc-consistent, consistenta lui nu va fi violatã.
O problemã de satisfacere a restrictiilor avînd graful de
restrictii de tip arbore poate fi rezolvatã în ![]() pasi si acest rezultat
este optimal. Justificarea acestei afirmatii este urmãtoarea: odatã ce se cunoaste
faptul cã graful de restrictii este arbore (
pasi si acest rezultat
este optimal. Justificarea acestei afirmatii este urmãtoarea: odatã ce se cunoaste
faptul cã graful de restrictii este arbore (![]() ), gãsirea unei ordonãri de lãtime egalã cu unu necesitã O(N)
pasi. Realizarea d-arc-consistentei, cu algoritmul de mai sus, necesitã
), gãsirea unei ordonãri de lãtime egalã cu unu necesitã O(N)
pasi. Realizarea d-arc-consistentei, cu algoritmul de mai sus, necesitã ![]() pasi. Solutia fãrã
backtracking a arborelui rezultat este gãsitã în
pasi. Solutia fãrã
backtracking a arborelui rezultat este gãsitã în ![]() pasi. Deci,
pasi. Deci, ![]() .
.
Observatie.
Dacã se aplicã algoritmul pe ordonarea d,
apoi pe ordonarea inversã, pentru arbori, se obtine arc-consistenta. Deci,
pentru arbori, se poate obtine arc-consistenta într-un timp ![]() .
.
Definitie. Intr-un graf de restrictii R, fiind datã o
ordonare a grafului ![]() , graful R este d-cale-consistent
dacã pentru orice pereche de valori
, graful R este d-cale-consistent
dacã pentru orice pereche de valori ![]() astfel încît
astfel încît ![]() , atunci pentru orice
, atunci pentru orice ![]() existã
existã ![]() astfel încît
astfel încît ![]() si
si ![]() .
.
Teoremã. Fie un graf de restrictii R cu ordonarea d si lãtimea acestei ordonãri egalã cu doi. Dacã R este d-arc-consistent si d-cale-consistent, atunci cãutarea dupã directia d este fãrã backtracking.
Algoritmul de realizare a d-cale-consistentei este prezentat
în continuare. Pentru ca un algoritm sã realizeze d-cale-consistenta, trebuie
sã facã atît schimbãri în multimea de restrictii, cît si schimbãri în graf,
i.e. adãugare de noi arce. Pentru descrierea algoritmului se foloseste o
matrice de reprezentare a restrictiilor. Fiecare restrictie între douã
variabile Xi si Xj este reprezentatã printr-o matrice
binarã de dimensiune ![]() cu valori 1 pentru
combinatii de valori permise si valori 0 pentru combinatii interzise. De
exemplu, pentru graful de restrictii din Figura 4.17, restrictia
cu valori 1 pentru
combinatii de valori permise si valori 0 pentru combinatii interzise. De
exemplu, pentru graful de restrictii din Figura 4.17, restrictia ![]() are forma matricialã
indicatã în figurã. Pentru fiecare variabilã Xi
se considerã si matricea unitarã Rii,
asa cum se vede tot în Figura 4.17. Elementele matricii Rii definesc multimea de valori permise
ale variabilei Xi, fiind 1 pe
diagonala principalã si 0 în rest.
are forma matricialã
indicatã în figurã. Pentru fiecare variabilã Xi
se considerã si matricea unitarã Rii,
asa cum se vede tot în Figura 4.17. Elementele matricii Rii definesc multimea de valori permise
ale variabilei Xi, fiind 1 pe
diagonala principalã si 0 în rest.
Se defineste intersectia a douã restrictii ca o
restrictie care permite numai perechile de valori ce apar în ambele restrictii.
Intersectia a douã restrictii se noteazã cu &. Compunerea a douã restrictii, R
si R , între variabilele X si X
si respectiv X si X , determinã o nouã restrictie R definitã astfel: ![]() dacã existã
dacã existã ![]() astfel încît
astfel încît ![]() si
si ![]() . În notatia cu matrice, compunerea a douã restrictii se
poate obtine fãcînd produsul de matrice
. În notatia cu matrice, compunerea a douã restrictii se
poate obtine fãcînd produsul de matrice ![]() si înlocuind în
matricea rezultat valorile pozitive cu 1.
si înlocuind în
matricea rezultat valorile pozitive cu 1.

Figura 4.17 Reprezentarea matricialã a restrictiilor
În algoritmul urmãtor se considerã graful de restrictii ![]() , se utilizeazã reprezentarea cu matrice a restrictiilor si
ordonarea
, se utilizeazã reprezentarea cu matrice a restrictiilor si
ordonarea ![]() . V este multimea nodurilor din graf
. V este multimea nodurilor din graf ![]() , iar E este multimea arcelor
, iar E este multimea arcelor ![]() etichetate cu
matricele de restrictii Rij.
etichetate cu
matricele de restrictii Rij.
Algoritm: Realizarea d-cale-consistentei unui graf de restrictii cu variabile ordonate
1. ![]()
2. pentru ![]() pînã la 1 executã
pînã la 1 executã
2.1. pentru
fiecare pereche ![]() cu
cu ![]() si
si ![]() executã
executã
/*Xi legat la Xk */
2.1.1. ![]()
2.2. pentru
fiecare triplet ![]() cu
cu ![]() si
si ![]() si
si ![]() executã
executã
2.2.1. ![]()
2.2.2. ![]()
sfîrsit.
În algoritmul de mai sus, pasul 2.1 realizeazã
d-arc-consistenta si este echivalent cu subprogramul Verificã![]() prezentat în Sectiunea 4.5.2. Pasul 2.2 actualizeazã restrictiile
între perechi de variabile prin intermediul unei a treia variabile ce se aflã
mai sus în ordonarea d. Dacã Xi si Xj, cu
prezentat în Sectiunea 4.5.2. Pasul 2.2 actualizeazã restrictiile
între perechi de variabile prin intermediul unei a treia variabile ce se aflã
mai sus în ordonarea d. Dacã Xi si Xj, cu ![]() , nu sînt legate de Xk,
atunci relatia între Xi si Xj nu este afectatã de Xk. Dacã o variabilã Xi, cu
, nu sînt legate de Xk,
atunci relatia între Xi si Xj nu este afectatã de Xk. Dacã o variabilã Xi, cu ![]() , este legatã cu variabila Xk,
efectul variabilei Xk asupra
restrictiei
, este legatã cu variabila Xk,
efectul variabilei Xk asupra
restrictiei ![]() va fi calculat în
pasul 2.1 al algoritmului. Singura datã cînd o variabilã Xk afecteazã restrictiile între perechi de
variabile anterioare, este în situatia în care Xk este legatã cu amîndouã variabilele din pereche. Numai
în acest caz se poate adãuga un nou arc în graf. Complexitatea algoritmului
este
va fi calculat în
pasul 2.1 al algoritmului. Singura datã cînd o variabilã Xk afecteazã restrictiile între perechi de
variabile anterioare, este în situatia în care Xk este legatã cu amîndouã variabilele din pereche. Numai
în acest caz se poate adãuga un nou arc în graf. Complexitatea algoritmului
este ![]() [Dechter,
[Dechter,
4.6 Tehnici prospective de îmbunãtãtire a performantelor cãutãrii
Tehnicile prospective se bazeazã pe ideea conform cãreia fiecare pas spre solutie trebuie ales astfel încît sã nu ducã la blocare. De fiecare datã cînd se atribuie o valoare variabilei curente, toate variabilele sînt verificate pentru a depista eventuale conditii de blocare. Anumite valori ale variabilelor neinstantiate încã pot fi eliminate deoarece nu vor putea sã facã parte din solutie niciodatã.
În continuare se vor prezenta trei algoritmi predictivi de rezolvare a problemei satisfacerii restrictiilor: algoritmul de predictie completã, de predictie partialã si de verificare predictivã. Cei trei algoritmi sînt o combinatie de cãutare neinformatã cu realizarea unor grade diferite de k-consistentã.
În prezentarea algoritmilor se fac urmãtoarele conventii:
(1) variabilele vor fi numerotate si numerotarea lor va reprezenta ordinea de instantiere
(2) la un anumit moment dat în procesul de cãutare cu backtracking, variabilele deja instantiate se numesc variabile anterioare, variabila ce se instantiazã pe nivelul curent se numeste variabilã curentã, iar variabilele neinstantiate încã se numesc variabile viitoare.
4.6.1 Algoritmul de backtracking cu predictie completã
Acest algoritm garanteazã, la orice nivel în arborele de cãutare, îndeplinirea urmãtoarelor conditii:
fiecare variabilã viitoare are cel putin o valoare compatibilã cu valorile variabilelor anterioare si cu a celei curente, si
fiecare variabilã viitoare are cel putin o valoare compatibilã cu orice altã variabilã viitoare.
Pentru realizarea acestor conditii se executã urmãtoarele operatii:
(a) Pentru fiecare variabilã viitoare se verificã dacã valoarea variabilei curente este compatibilã cu cel putin o valoare din domeniul variabilei viitoare. Valorile variabilelor viitoare incompatibile cu valoarea atribuitã variabilei curente sînt eliminate din domeniile variabilelor viitoare. În acest fel, domeniile variabilelor viitoare contin numai valori compatibile cu valorile variabilelor anterioare si la atribuirea unei valori variabilei curente este necesar sã se testeze numai consistenta acestei valori cu domeniile variabilelor viitoare.
(b) Pentru fiecare variabilã viitoare se verificã dacã existã cel putin o valoare compatibilã cu orice altã variabilã viitoare si valorile incompatibile sînt eliminate.
Algoritmul de backtracking cu predictie completã împiedicã
procesul de cãutare în spatiul stãrilor sã execute repetat avans si revenire
între variabilele Xv si Xu, cu ![]() , numai pentru a descoperi ulterior cã valorile variabilelor
, numai pentru a descoperi ulterior cã valorile variabilelor ![]() au determinat
incompatibilitatea între toate valorile unei variabile Xw, cu
au determinat
incompatibilitatea între toate valorile unei variabile Xw, cu ![]() , si anumite variabile anterioare, curente sau viitoare.
, si anumite variabile anterioare, curente sau viitoare.
Observatie. Algoritmul construieste solutia mentinînd un
nivel de k-consistentã între cele ![]() variabile anterioare si
variabila curentã si un nivel de 2-consistentã între variabilele viitoare.
variabile anterioare si
variabila curentã si un nivel de 2-consistentã între variabilele viitoare.
În descrierea algoritmului se folosesc urmãtoarele notatii:
U este o valoare întreagã ce reprezintã indicele variabilei
curente; initial ![]() .
.
N este numãrul de variabile din problemã.
F este un vector indexat dupã variabile, F[U] fiind valoarea atribuitã variabilei XU.
T este o matrice în care fiecare linie T[U] reprezintã lista valorilor posibile pentru variabila XU. Initial matricea contine toate valorile din domeniile variabilelor problemei; aceastã tabelã, indexatã dupã variabile, indicã, pentru fiecare nivel al arborelui de cãutare, ce valori mai sînt încã posibil de atribuit variabilei curente si variabilelor viitoare. Pentru variabilele anterioare informatia din tabelã este neinteresantã.
TNOU este o matrice similarã cu T, dar care memoreazã noile valori posibile pentru variabila curentã si variabilele viitoare la fiecare apel recursiv.
![]() , unde L si
L sînt valorile atribuite
variabilelor cu indici U si U .
, unde L si
L sînt valorile atribuite
variabilelor cu indici U si U .
Acest algoritm utilizeazã un numãr de locatii de memorie egal cu pãtratul numãrului variabilelor înmultit cu numãrul maxim de valori din domeniile de valori ale variabilelor, pentru a memora matricile T si TNOU, deoarece pot numãrul de nivele de recursivitate este cel mult egal cu numãrul variabilelor.
Subprogramul Verificã_Înainte verificã pentru fiecare pereche viitoare variabilã-valoare dacã este consistentã cu valoarea prezentã F[U] pentru variabila curentã XU si copiazã tabela T în tabela TNOU de pe nivelul urmãtor, eliminînd din T valorile variabilelor viitoare incompatibile cu valoarea F[U] atribuitã variabilei XU. Subprogramul întoarce ca valoare tabela TNOU sau o valoare specialã LINIE_VIDÃ, dacã o variabila viitoare nu are nici o valoare compatibilã cu F[U]. Subprogramul Verificã_Viitoare verificã pentru fiecare pereche variabilã-valoare din tabela TNOU dacã este consistentã cu cel putin o valoare a fiecãrei variabile viitoare si eliminã valorile ce nu sînt consistente. Subprogramul actualizeazã de asemenea indicatorul LINIE_VIDÃ, în aceleasi conditii ca si subprogramul Verificã_Înainte. Dacã indicatorul LINIE_VIDÃ este activ, urmãtorul nivel în cãutare este ignorat si se încearcã o nouã selectie.
Algoritm: Backtracking cu predictie completã
Predictie ![]()
pentru fiecare element L din T[U] executã
1. ![]()
2. dacã ![]()
atunci /* verificã consistenta atribuirii */
2.1. ![]()
2.2. dacã
![]()
atunci ![]()
2.3. dacã
![]()
atunci Predictie ![]()
3. altfel afiseazã atribuirile din F
sfîrsit.
Verificã_Înainte ![]()
1. ![]()
2. pentru ![]() pînã la N executã
pînã la N executã
2.1. pentru fiecare element L2 din T[U2] executã
2.1.1. dacã
![]()
atunci introduce L2 în TNOU[U2]
2.2. dacã TNOU[U2] este vidã
atunci întoarce LINIE_VIDÃ /* la gãsirea unei incompatibilitãti între valoarea F[U] atribuitã variabilei curente XU, si o variabilã viitoare, se va încerca o altã atribuire pentru XU, în Predictie */
3. întoarce TNOU
sfîrsit.
Verificã_Viitoare ![]()
dacã ![]() /*
mai sînt variabile viitoare*/
/*
mai sînt variabile viitoare*/
atunci
1. pentru ![]() pînã la N executã
pînã la N executã
1.1. pentru fiecare element L1 din TNOU[U1] executã
1.1.1. pentru
![]() pînã la N,
pînã la N, ![]() executã
executã
i. pentru fiecare element L2 din TNOU[U2] executã
- dacã
![]()
atunci întrerupe ciclul /* dupã variabila L2 */
/* s-a gãsit o valoare a variabilei U2 consistentã cu valoarea L1 a variabilei U1 */
ii. dacã nu s-a gãsit o valoare consistentã pentru U2
atunci
Eliminã L1 din TNOU[U1]
întrerupe ciclul /* dupã variabila U2 */
/* variabila U2 nu are nici o valoare consistentã cu valoarea L1 a variabilei U1 */
1.2. dacã TNOU[U1] este vidã
atunci întoarce LINIE_VIDÃ
2. întoarce TNOU
întoarce TNOU /* în acest caz TNOU este nemodificat */
sfîrsit.
Acest algoritm, desi face toate testele între valorile variabilelor viitoare, nu memoreazã aceste teste. Din aceastã cauzã, algoritmul nu este suficient de performant. Urmãtorul algoritm, cu predictie partialã, care face mai putine teste, se comportã mai bine din punct de vedere al performantelor.
4.6.2 Algoritmul de backtracking cu predictie partialã
Algoritmul de backtracking cu predictie partialã face aproximativ jumãtate din testele de consistentã ale algoritmului de predictie completã în timp ce verificã valorile variabilelor viitoare cu valorile altor variabile viitoare. Fiecare pereche variabilã-valoare este verificatã numai cu variabilele din propriul ei viitor, în loc sã fie testatã fatã de toate variabilele viitoare. Aceastã metodã va elimina din domeniul de valori al variabilelor mai putine valori decît algoritmul de predictie totalã, dar va face mai putine teste de consistentã în toate cazurile.
Observatie. Algoritmul de predictie partialã este echivalent cu algoritmul de predictie completã în care nivelul de 2-consistentã între valorile variabilelor viitoare este înlocuit cu d-arc-consistenta.
Algoritmul de backtracking cu predictie partialã se obtine din algoritmul de backtracking cu predictie completã dacã în subprogramul Verificã_Viitoare se fac urmãtoarele modificãri: se înlocuieste pasul 1 cu
1'. pentru ![]() pînã la
pînã la ![]() executã
executã
si pasul 1.1.1 cu
1.1.1'. pentru
![]() pînã la N executã
pînã la N executã
Verificarea valorilor perechilor de variabile viitoare nu descoperã inconsistente suficient de des pentru a justifica numãrul mare de teste necesare. În plus, rezultatele acestor teste nu pot fi memorate eficient. Un algoritm de predictie care verificã valorile variabilelor viitoare numai cu variabila prezentã si cu variabilele anterioare poate avea performante mai bune, deoarece testele efectuate pot fi memorate.
4.6.3 Algoritmul de backtracking cu verificare predictivã
Acest algoritm este similar cu cel de predictie, cu exceptia faptului cã valorile variabilelor viitoare nu mai sînt verificate cu variabilele viitoare, iar verificãrile valorilor variabilelor viitoare cu variabilele anterioare sînt tinute minte în verificãrile fãcute la nivele anterioare ale arborelui de cãutare.
Verificarea predictivã începe dintr-o stare în care nici o variabilã viitoare nu are vreo valoare inconsistentã cu o pereche anterioarã variabilã-valoare. Aceastã premisã este sigur adevãratã la rãdãcina arborelui de cãutare, cînd nu existã variabile anterioare. Se selecteazã o valoare pentru prima variabilã. Aceastã valoare este consistentã cu variabilele anterioare deoarece acestea nu existã încã. Verificarea predictivã încearcã sã provoace o blocare cît mai repede posibil, cãutînd dacã existã o variabilã viitoare ce nu are nici o valoare consistentã cu perechea curentã variabilã-valoare.
Dacã orice variabilã viitoare are o valoare consistentã cu perechea curentã variabilã-valoare, atunci se poate trece la urmãtorul nivel în arborele de cãutare, într-o stare avînd aceleasi proprietãti cu starea initialã. Dacã existã o variabilã viitoare ce nu are nici o valoare consistentã cu perechea curentã variabilã-valoare, atunci cãutarea rãmîne la acelasi nivel în arbore si continuã selectînd urmãtoarea valoare din domeniul variabilei curente. Dacã nu mai existã astfel de valori, atunci se executã revenirea la variabila anterioarã.
Algoritmul de verificiare predictivã se obtine din algoritmul de backtracking cu predictie completã, prin eliminarea apelului Verificã_Viitoare (U, TNOU) în subprogramul Predictie.
Observatie. Toate cele trei variante de tehnici predictive pot fi îmbunãtãtite prin introducerea euristicii prin care se alege ca variabilã urmãtoare variabila cu cele mai putine valori rãmase în domeniul de valori. Acest lucru este echivalent cu o reordonare dinamicã a variabilelor la fiecare avans în cãutare. Experimental, s-a dovedit cã introducerea acestei euristici furnizeazã rezultate foarte bune.
4.6.4 Solutii de implementare
În cele ce urmeazã va fi prezentatã o solutie de implementare a algoritmului de backtracking cu predictie completã. Spre deosebire de algoritmul prezentat în Sectiunea 4.6.1, programul foloseste structuri de date de tip listã care faciliteazã implementarea în Lisp. Structurile utilizate sînt asemãnãtoare cu cele prezentate în Sectiunea 4.4.1. Astfel, vectorul de variabile F este reprezentat prin lista *VARIABILE*, iar solutia este construitã în variabila *SOLUTII*. Matricea de valori ale domeniilor variabilelor, T, este reprezentatã prin lista de liste *VALORI*, iar valorile compatibile rezultate în urma verificãrilor, deci TNOU, sînt calculate în variabila ValoriNoi. Valoarea de incompatibilitate LINIE_VIDÃ este înlocuitã cu rezultatul nil întors de functiile Verifica-Inainte si Verifica-Viitoare, în caz de blocare.
(defparameter *EXPANDARI* 0)
(defparameter *VERIFICARI* 0)
(defparameter *SOLUTII* nil)
(defun Predictie (Cale Variabile Valori)
(dolist (Val (car Valori))
(if (cdr Variabile)
(let ((ValoriNoi (Verifica-Inainte Variabile Val Valori)))
(when ValoriNoi
(when (cddr Variabile)
(setf ValoriNoi (catch 'break (Verifica-Viitoare Variabile ValoriNoi))))
(when ValoriNoi
(incf *EXPANDARI*)
(Predictie (cons (cons (first Variabile) Val) Cale) (rest Variabile) ValoriNoi))))
(push (cons (cons *EXPANDARI* *VERIFICARI*)
(cons (cons (first Variabile) Val) Cale))
*SOLUTII*))))
(defun Verifica-Inainte (Variabile Val Valori)
(do ((Variabile2 (rest Variabile) (rest Variabile2))
(Domenii2 (rest Valori) (rest Domenii2))
(DomeniuNou nil nil)
ValoriNoi)
((null Variabile2) (reverse ValoriNoi))
(dolist (Val2 (first Domenii2))
(incf *VERIFICARI*)
(when (exista-relatie-p (first Variabile) Val (first Variabile2) Val2)
(push Val2 DomeniuNou)))
(unless DomeniuNou (return))
(push DomeniuNou ValoriNoi)))
(defun Verifica-Viitoare (Variabile Valori)
(do* ((Variabile1 (rest Variabile) (rest Variabile1))
(Domenii1 Valori (rest Domenii1))
(Domeniu1 (first Domenii1) (first Domenii1))
ValoriNoi)
((null Variabile1) (reverse ValoriNoi))
(dolist (Val1 Domeniu1 (when (null Domeniu1) (throw 'break nil)))
(do* ((Variabile2 (rest Variabile) (rest Variabile2))
(Domenii2 Valori (rest Domenii2))
(Domeniu2 (first Domenii2) (first Domenii2)))
((or (null Variabile2) (unless (equal (first Variabile2) (first Variabile1))
(dolist (Val2 Domeniu2 (pop Domeniu1))
(incf *VERIFICARI*)
(when (exista-relatie-p (first Variabile1) Val1
(first Variabile2) Val2)
(return))))))))
(push Domeniu1 ValoriNoi)))
În continuare se prezintã modul în care se poate rezolva problema îmbrãcãrii robotului, prezentatã în Sectiunea 4.1.2, utilizînd functiile definite. Se defineste predicatul exista-relatie-p care verificã compatibilitatea atribuirilor de valori pentru douã variabile. Pentru aceasta se utilizeazã variabila specialã *RESTRICTII*, care memoreazã restrictiile problemei sub forma unei liste de perechi cu punct între perechi variabilã-valoare. Functia tipareste-solutie tipãreste lista de asociatii variabilã-valoare primitã ca parametru.
(defun exista-relatie-p (var1 val1 var2 val2)
"Verifica existenta unei relatii ((var1.val1).(var2.val2)) sau ((var2.val2).(var1.val1))
in lista *RELATII*. Intoarce t in caz afirmativ, nil in caz contrar."
(let ((aux1 (cons var1 val1))
(aux2 (cons var2 val2)))
(some #'(lambda (pereche)
(or (and (equal (first pereche) aux1)
(equal (rest pereche) aux2))
(and (equal (first pereche) aux2)
(equal (rest pereche) aux1))))
*RESTRICTII*)))
(defun tipareste-solutie (solutie)
(dolist (pereche solutie)
(format t "~&variabila: ~A valoare: ~A" (first pereche) (rest pereche))))
Variabilele speciale *VARIABILE*,*VALORI* si *RESTRICTII* se definesc astfel:
(defparameter *VARIABILE* '(Pantofi Pantaloni Camasi))
(defparameter *VALORI* '((Escarpeni Tenisi) (Jeans Bleu Gris) (Verde Alba)))
(defparameter *RESTRICTII*
`(,(cons '(Pantofi . Escarpeni) '(Pantaloni . Gris))
,(cons '(Pantofi . Tenisi) '(Pantaloni . Jeans))
,(cons '(Pantofi . Escarpeni) '(Camasi . Verde))
,(cons '(Pantofi . Tenisi) '(Camasi . Alba))
,(cons '(Pantaloni . Gris) '(Camasi . Verde))
,(cons '(Pantaloni . Jeans) '(Camasi . Alba))
,(cons '(Pantaloni . Bleu) '(Camasi . Alba))))
Dupã cum se observã, în implementare apare o restrictie suplimentarã, între Pantofii de tenis si Cãmasa albã, restrictie care nu se regãseste în descrierea initialã problemei. Aceastã pereche suplimentarã a fost introdusã pentru ca problema sã admitã solutie. Solutiile problemei pot fi obtinute utilizînd secventa de apeluri:
(Predictie nil *VARIABILE* *VALORI*)
(dolist (solutie (reverse *SOLUTII*))
(tipareste-solutie solutie)
(format t "~&Expandari: ~A Verificari: ~A" (caar solutie) (cdar solutie)))
4.7 Tehnici retrospective de îmbunãtãtire a performantelor cãutãrii
Tehnicile retrospective memoreazã perechi variabilã-valoare care s-au detectat a fi inconsistente cu perechi variabilã-valoare prezente sau anterioare. Perechile memorate sînt obtinute numai pe baza testãrii perechii curente variabilã-valoare cu perechi variabilã-valoare anterioare si nu cu cele viitoare, cum se întîmplã în cazul tehnicilor prospective.
Fiecare test executat de o tehnicã retrospectivã în timp ce
inspecteazã calea de la Xi la ![]() , va fi deja executat de un algoritm prospectiv în momentul
în care Xj era variabilã
curentã; bineînteles, în acest moment, algoritmul prospectiv ar fi testat si
toate variabilele de dupã Xi.
Tehnicile retrospective prezentate în urmãtoarele sectiuni fac mai putine teste
de consistentã, dar plãtesc pretul parcurgerii unui arbore de cãutare mai mare.
, va fi deja executat de un algoritm prospectiv în momentul
în care Xj era variabilã
curentã; bineînteles, în acest moment, algoritmul prospectiv ar fi testat si
toate variabilele de dupã Xi.
Tehnicile retrospective prezentate în urmãtoarele sectiuni fac mai putine teste
de consistentã, dar plãtesc pretul parcurgerii unui arbore de cãutare mai mare.
4.7.1 Algoritmul de backtracking cu salt
Ideea care stã la baza acestui algoritm este urmãtoarea: la întîlnirea unei blocãri, se identificã atribuirea de valori care a generat blocarea si revenirea în cãutre se face la nivelul de blocare si nu la nivelul imediat anterior. Algoritmul detecteazã nivelul cel mai adînc din arborele de cãutare care a generat blocarea, adicã acel nivel pentru care toate valorile variabilei curente sînt incompatibile, iar revenirea se face pînã la acel nivel.
Pentru a ilustra functionarea algoritmului de backtracking cu salt, se considerã exemplul robotului constient de restrictiile modei (Sectiunea 4.1.2) la care se adaugã o pereche suplimentarã de valori complementare între variabilele Pantaloni si Cãmãsi: cãmasa verde se poate îmbrãca cu pantalonii jeans. Graful de restrictii asociat este prezentat în Figura 4.18 (a). Considerînd ordinea variabilelor Pantofi, Pantaloni, Cãmãsi, ce se va întîmpla dacã se încearcã atribuirea unei valori variabilei Cãmãsi pe calea pantofi de tenis, jeans a arborelui de cãutare? Ambele valori ale variabilei Cãmãsi, verde si albã, desi compatibile cu jeans, se dovedesc incompatibile datoritã pantofilor de tenis. În algoritmul de backtracking cronologic, cãutarea ar reveni la nivelul variabilei Pantaloni încercînd celelalte douã valori bleu si gri. Acest lucru este inutil deoarece inconsistenta a fost generatã de atribuirea fãcutã variabilei Pantofi. Concluzia care se desprinde este aceea cã revenirea trebuie sã se facã la nivelul variabilei care a produs inconsistenta, în acest caz la nivelul variabilei Pantofi. Cum pentru Pantofi nu mai existã nici o altã valoare posibilã, algoritmul se opreste fãrã a gãsi solutii pentru acest exemplu. Arborele de cãutare generat de acest algoritm este prezentat în Figura 4.18 (b). Sãgetile numerotate indicã nivelele de revenire (salt) din backtracking. Se observã eliminarea unei portiuni din arborele de cãutare datoritã saltului la nivelul variabilei care a produs inconsistenta.

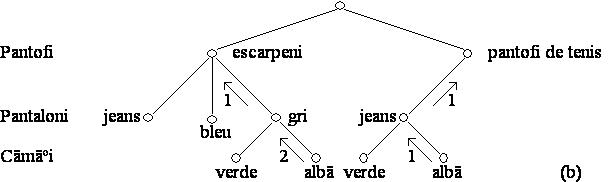
Figura 4.18 Problema robotului si arborele de cãutare al
algoritmului
de backtracking cu salt
Algoritmul care urmeazã utilizeazã variabilele U, N, F si
functia ![]() descrise la tehnicile
prospective. În plus, se utilizeazã vectorul NivelVec, cu dimensiunea egalã cu
gradul maxim al problemei, care memoreazã nivelele de blocare asociate fiecãrei
valori pentru variabila de pe nivelul curent. Procedura de bazã
BacktrackingCuSalt contine un parametru suplimentar Nivel care, la iesirea din
procedurã, va indica nivelul de blocare pentru atribuirile nivelului curent.
Vectorul NivelVec este variabilã localã procedurii BacktrackingCuSalt. Functia
Verificã, asemãnãtoare cu cea prezentatã la algoritmul de backtracking simplu
(Sectiunea 4.4.1), contine de asemenea un parametru suplimentar Nivel, care
indicã nivelul de blocare a unei perechi variabilã valoare. Se observã cã functia
Verificã testeazã compatibilitatea unei atribuiri curente începînd de la
nivelul cel mai adînc (mai depãrtat de rãdãcinã) spre nivelul cel mai scãzut al
arborelui de cãutare generat de algoritm. În acest fel algoritmul de
backtracking cu salt detecteazã cel mai adînc nivel din arbore care a generat
blocarea.
descrise la tehnicile
prospective. În plus, se utilizeazã vectorul NivelVec, cu dimensiunea egalã cu
gradul maxim al problemei, care memoreazã nivelele de blocare asociate fiecãrei
valori pentru variabila de pe nivelul curent. Procedura de bazã
BacktrackingCuSalt contine un parametru suplimentar Nivel care, la iesirea din
procedurã, va indica nivelul de blocare pentru atribuirile nivelului curent.
Vectorul NivelVec este variabilã localã procedurii BacktrackingCuSalt. Functia
Verificã, asemãnãtoare cu cea prezentatã la algoritmul de backtracking simplu
(Sectiunea 4.4.1), contine de asemenea un parametru suplimentar Nivel, care
indicã nivelul de blocare a unei perechi variabilã valoare. Se observã cã functia
Verificã testeazã compatibilitatea unei atribuiri curente începînd de la
nivelul cel mai adînc (mai depãrtat de rãdãcinã) spre nivelul cel mai scãzut al
arborelui de cãutare generat de algoritm. În acest fel algoritmul de
backtracking cu salt detecteazã cel mai adînc nivel din arbore care a generat
blocarea.
Algoritm: Backtracking cu salt
BacktrackingCuSalt![]()
1. ![]() ,
, ![]()
2. pentru fiecare valoare V a lui XU executã
2.1. ![]()
2.2. ![]()
2.3. dacã ![]()
atunci
2.3.1. dacã
![]()
atunci
i. BacktrackingCuSalt(U+1,F,Nivel1)
ii. dacã Nivel1<U
atunci întrerupe executia procedurii
iii. altfel
![]()
2.3.2. altfel afiseazã valorile vectorului F /* F reprezintã solutia problemei */
2.4. altfel
![]()
2.5. ![]()
3. dacã ![]() si
si
toate elementele din NivelVec sînt egale
atunci ![]()
4. altfel ![]()
sfîrsit.
Verificã ![]()
1. ![]()
2. ![]()
3. cît timp ![]() executã
executã
3.1. ![]()
3.2. dacã
![]()
atunci întrerupe ciclul
3.3. ![]()
4. ![]()
5. întoarce test
sfîrsit.
4.7.2 Algoritmul de backtracking cu marcare
Algoritmul de backtracking cu marcare eliminã executia unor teste de consistentã care au fost deja fãcute, nu au reusit, si dacã sînt repetate vor esua din nou. Sînt eliminate, de asemenea, si testele care au fost deja fãcute, au reusit si ar reusi din nou dacã s-ar reface.
Pentru a explica acest proces, se tine cont de faptul cã în arborele de cãutare se face avans, apoi revenire, iar avans, etc. Se considerã variabila curentã XU. Fie XV variabila de nivel cel mai scãzut (cel mai aproape de rãdãcinã în arborele de cãutare) la care s-a ajuns cu procesul de backtracking, deci si-a schimbat valoarea de la ultima vizitare a lui XU. Algoritmul de backtracking cu marcare va memora variabila XV.
Dacã ![]() , atunci
algoritmul de backtracking cu marcare procedeazã similar algoritmului de
backtracking simplu. Dacã
, atunci
algoritmul de backtracking cu marcare procedeazã similar algoritmului de
backtracking simplu. Dacã ![]() , atunci toate valorile variabilei XU au fost deja testate cu valorile
variabilelor
, atunci toate valorile variabilei XU au fost deja testate cu valorile
variabilelor ![]() , deci orice valoare a variabilei XU trebuie testatã numai cu valorile
variabilelor
, deci orice valoare a variabilei XU trebuie testatã numai cu valorile
variabilelor ![]() , acestea fiind variabilele ale cãror valori s-au schimbat de
la ultima vizitare a variabilei XU.
, acestea fiind variabilele ale cãror valori s-au schimbat de
la ultima vizitare a variabilei XU.

Figura 4.19 O portiune a spatiului de cãutare în algoritmul de
backtracking cu marcare
Deoarece algoritmul de backtracking cu marcare memoreazã, de
la ultima vizitã a variabilei XU,
ce valori ale lui XU au fost
compatibile cu valorile variabilelor ![]() , segmentul A al arborelui de cãutare prezentat în Figura
4.19 nu mai trebuie reverificat. Se verificã numai segmentul B, deci se
testeazã valorile variabilelor
, segmentul A al arborelui de cãutare prezentat în Figura
4.19 nu mai trebuie reverificat. Se verificã numai segmentul B, deci se
testeazã valorile variabilelor ![]() .
.
Algoritmul prezentat în continuare mentine semnificatia variabilelor U si F folosite în algoritmii tehnicilor prospective. În plus, se folosesc douã structuri de date suplimentare:
Matricea Marc, de dimensiune ![]() , unde N este numãrul de variabile, iar V este numãrul de
valori ale variabilelor. Matricea Marc este indexatã pe linii dupã numãrul
variabilelor, considerat în functie de ordinea de instantiere, si pe coloane
dupã valorile fiecãrei variabile. Astfel indicii elementului
, unde N este numãrul de variabile, iar V este numãrul de
valori ale variabilelor. Matricea Marc este indexatã pe linii dupã numãrul
variabilelor, considerat în functie de ordinea de instantiere, si pe coloane
dupã valorile fiecãrei variabile. Astfel indicii elementului ![]() indicã variabila XU si valoarea l din domeniul de definitie
al acesteia. Elementul
indicã variabila XU si valoarea l din domeniul de definitie
al acesteia. Elementul ![]() indicã nivelul cel mai
scãzut, i.e. cel mai apropiat de rãdãcinã, la care un test de consistentã a esuat
atunci cînd perechea
indicã nivelul cel mai
scãzut, i.e. cel mai apropiat de rãdãcinã, la care un test de consistentã a esuat
atunci cînd perechea ![]() , de pe nivelul curent a fost testatã cu perechi
variabilã-valoare de pe nivele anterioare.
, de pe nivelul curent a fost testatã cu perechi
variabilã-valoare de pe nivele anterioare.
Vectorul Nivel, de dimensiune N, unde ![]() indicã cel mai scãzut
nivel în arborele de cãutare la care a apãrut o modificare de valoare pentru o
variabilã, de la ultima atribuire a unei valori unui element al matricii Marc.
indicã cel mai scãzut
nivel în arborele de cãutare la care a apãrut o modificare de valoare pentru o
variabilã, de la ultima atribuire a unei valori unui element al matricii Marc.
În timpul procesului de cãutare apar 2 cazuri:
(1) ![]() , deci perechea
, deci perechea ![]() a fost deja testatã cu
perechile variabilã-valoare de deasupra nivelului
a fost deja testatã cu
perechile variabilã-valoare de deasupra nivelului ![]() si testul va esua
oricum la nivelul
si testul va esua
oricum la nivelul ![]() , deci aceste teste nu mai trebuie repetate.
, deci aceste teste nu mai trebuie repetate.
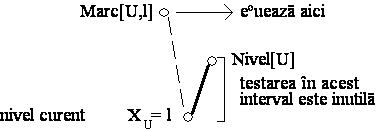
(2) ![]() , deci toate testele perechii
, deci toate testele perechii ![]() au reusit pe portiunea
au reusit pe portiunea
![]() . În continuare numai testele de la nivelul
. În continuare numai testele de la nivelul ![]() si cele de sub
si cele de sub ![]() pînã la nivelul
variabilei XU trebuie
executate.
pînã la nivelul
variabilei XU trebuie
executate.
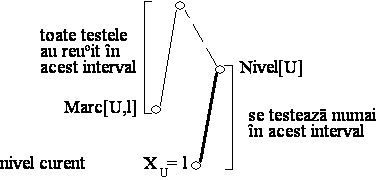
În intervalul
figurat cu linie întreruptã din schema de mai sus, nu se executã teste de
consistentã, deoarece acestea au reusit înainte de a se face revenire si în
timpul revenirii nimic nu s-a schimbat pînã la ![]() .
.
Înaintea apelului subprogramului BacktrackingCuMarcare,
toate elementele vectorului Nivel si ale matricii Marc sînt initializate cu
valoarea 1, iar subprogramul este apelat cu parametrul ![]() . Deoarece structurile Nivel si Marc sînt utilizate la toate
nivelele în recursivitate, spatiul de memorie necesar acestui algoritm este
aproximativ egal cu numãrul de variabile înmultit cu numãrul de valori ale
variabilelor.
. Deoarece structurile Nivel si Marc sînt utilizate la toate
nivelele în recursivitate, spatiul de memorie necesar acestui algoritm este
aproximativ egal cu numãrul de variabile înmultit cu numãrul de valori ale
variabilelor.
Algoritm: Backtracking cu marcare
BacktrackingCuMarcare![]()
1. pentru fiecare valoare V a lui XU executã
1.1. ![]()
1.2. dacã
![]()
atunci
1.2.1. ![]()
1.2.2. ![]()
1.2.3. cît
timp ![]() executã /*
gãseste cel mai scãzut nivel
de blocare */
executã /*
gãseste cel mai scãzut nivel
de blocare */
i. ![]()
ii. dacã
![]()
atunci întrerupe ciclul /* cît timp */
iii.
![]()
1.2.4. ![]() /*marcheazã
valoarea de blocare pe nivelul
cel mai scãzut în arbore */
/*marcheazã
valoarea de blocare pe nivelul
cel mai scãzut în arbore */
1.2.5. dacã
![]()
atunci
i. dacã
![]()
atunci
BacktrackingCuMarcare![]()
ii. altfel afiseazã atribuirea din F
2. ![]() /*
nivelul anterior va fi schimbat */
/*
nivelul anterior va fi schimbat */
3. pentru ![]() pînã la numãrul de variabile executã
pînã la numãrul de variabile executã
3.1. ![]()
sfîrsit.
Teste experimentale pentru problema celor N regine ![]() au demonstrat cã, în
toate cazurile, algoritmul de backtracking simplu este mai putin eficient.
Dintre ceilalti algoritmi, algoritmul de backtracking cu marcare si cel cu
verificare predictivã s-au dovedit a fi cele mai eficiente solutii. Eficienta a
fost mãsuratã în functie de:
au demonstrat cã, în
toate cazurile, algoritmul de backtracking simplu este mai putin eficient.
Dintre ceilalti algoritmi, algoritmul de backtracking cu marcare si cel cu
verificare predictivã s-au dovedit a fi cele mai eficiente solutii. Eficienta a
fost mãsuratã în functie de:
numãrul de teste de consistentã
numãrul de noduri generate în arborele de cãutare
numãrul de accese la structurile de date
În general acestia sînt indicatori standard de apreciere a eficientei algoritmului de rezolvare a problemei satisfacerii restrictiilor. Solutiile de implementare prezentate au folosit variabilele *EXPANDARI* si *VERIFICARI* pentru calculul si mentinerea primilor doi indicatori.
4.7.3 Algoritmul de backtracking cu multime conflictualã
Ideea de bazã a algoritmului de backtracking cu multime conflictualã este o combinatie a celor douã strategii retrospective anterioare. Într-o situatie de blocare, se identificã variabilele care au generat aceastã situatie cu un dublu scop:
pentru a fi considerate în procesul de cãutare cu reveniri, ca în orice algoritm de backtracking
pentru a se memora perechea de atribuiri incompatibile variabilã-valoare în vederea evitãrii ei la o viitoare resatisfacere a restrictiei.
Algoritmul de backtracking cu multime conflictualã realizeazã o transformare partialã a restrictiilor implicite în restrictii explicite prin detectarea unor perechi de atribuiri inconsistente variabilã-valoare si memorarea acestora. Acest algoritm se mai numeste si algoritm de backtracking cu învãtare în timpul cãutãrii.
Una dintre formele de învãtare automatã este memorarea informatiei obtinute pe parcursul rezolvãrii unei probleme, informatie care poate fi ulterior utilizatã fie la rezolvarea aceleiasi instante a problemei, fie la rezolvarea altor instante ale problemei. Metodele de învãtare în timpul rezolvãrii unei probleme se numesc metode de învãtare bazatã pe explicatii si vor fi discutate pe larg în Capitolul 7. Aceste metode identificã în timpul cãutãrii cea mai generalã descriere a unei multimi de conditii care permite executia anumitor actiuni si care poate fi învãtatã pe parcursul rezolvãrii. În contextul rezolvãrii problemei satisfacerii restrictiilor, procesul transformãrii restrictiilor implicite în restrictii explicite poate fi vãzut ca o formã de învãtare bazatã pe explicatii. Acest proces poate fi executat independent de procesul de cãutare prin backtracking, asa cum s-a arãtat în Sectiunea 4.5, dar eficienta procesului poate deveni efectivã dacã este încorporat în algoritmul de cãutare, asa cum se prezintã în continuare.
Definitie. Fie starea curentã reprezentatã de multimea
atribuirilor curente variabilã-valoare ![]() realizate pînã la un
moment dat în cãutare. Se spune cã multimea S este în conflict cu variabila Xi
sau, pe scurt, S este o multime
conflictualã dacã starea curentã este o situatie de blocare, i.e. multimea
S nu mai poate fi extinsã cu nici o atribuire consistentã pentru variabila
urmãtoare Xi.
realizate pînã la un
moment dat în cãutare. Se spune cã multimea S este în conflict cu variabila Xi
sau, pe scurt, S este o multime
conflictualã dacã starea curentã este o situatie de blocare, i.e. multimea
S nu mai poate fi extinsã cu nici o atribuire consistentã pentru variabila
urmãtoare Xi.
Observatie. Dacã problema ar fi inclus restrictii explicite, acestea ar fi împiedicat atribuirile din S si blocarea curentã ar fi fost evitatã.
Din multimea conflictualã, însã, algoritmul de cãutare poate sã învete ceva. În anumite cazuri se memoreazã întreaga multime conflictualã pentru a putea rãspunde la întrebãri viitoare care referã aceeasi multime initialã de conflicte. De cele mai multe ori însã, nu este necesarã memorarea acestei multimi deoarece, în strategia de backtracking, aceastã stare nu va mai apare niciodatã. Dar dacã multimea S contine una sau mai multe submultimi ce sînt, de asemenea, în conflict cu variabila Xi, atunci memorarea acestei informatii sub forma unor restrictii noi, explicite, poate fi utilã, deoarece stãri viitoare pot contine aceste submultimi conflictuale si pot fi astfel evitate.
Dacã o multime conflictualã contine cel putin o submultime conflictualã, memorarea celei mai mici submultimi conflictuale ca o restrictie este suficientã pentru a împiedica aparitia celorlalte submultimi conflictuale. Scopul algoritmului de backtracking cu multime conflictualã este acela de a identifica submultimi conflictuale cît mai mici ale multimii conflictuale S, deoarece submultimile conflictuale mici vor apare mai devreme în procesul de cãutare.
Definitie. O multime conflictualã M se numeste multime
conflictualã minimalã, dacã multimea
conflictualã M nu are nici o submultime conflictualã, i.e. ![]() , M nu este
multime conflictualã.
, M nu este
multime conflictualã.
Multimile conflictuale minimale pot fi privite ca multimile
de instantieri de variabile care au generat conflictul, i.e. situatia de
blocare. Descoperirea si memorarea unei submultimi conflictuale minimale, sau
numai a uneia conflictuale, poate duce la cresterea performantelor algoritmului
de backtracking. Primul pas în descoperirea unei submultimi conflictuale ![]() , unde S este o multime conflictualã cu variabila Xi, este acela de a elimina din S toate
valorile care sînt irelevante pentru variabila Xi.
, unde S este o multime conflictualã cu variabila Xi, este acela de a elimina din S toate
valorile care sînt irelevante pentru variabila Xi.
Definitie. O pereche variabilã-valoare ![]() este irelevantã pentru variabila Xi, dacã este consistentã cu toate
valorile variabilei Xi.
Perechile irelevante pot fi eliminate dintr-o multime conflictualã S deoarece
nu pot face parte din multimea conflictualã minimalã.
este irelevantã pentru variabila Xi, dacã este consistentã cu toate
valorile variabilei Xi.
Perechile irelevante pot fi eliminate dintr-o multime conflictualã S deoarece
nu pot face parte din multimea conflictualã minimalã.
Procesul de memorare a restrictiilor generate prin
eliminarea din S a perechilor irelevante pentru o variabilã Xi, se numeste învãtare de suprafatã. Învãtarea de suprafatã este completã dacã toate perechile irelevante
sînt eliminate din S. Multimea conflictualã rezultatã se noteazã ![]() .
.
Graful de restrictii al problemei oferã o modalitate usoarã
de identificare a perechilor irelevante. În acest graf perechile irelevante
sînt perechile ![]() pentru care variabila
Xk nu este legatã cu variabila Xi
din
pentru care variabila
Xk nu este legatã cu variabila Xi
din ![]() . Aceastã conditie nu eliminã toate perechile irelevante,
deoarece si o variabilã legatã cu variabila Xi
în graf poate fi irelevantã. Deci multimea calculatã cu ajutorul conditiei de
mai sus include multimea
. Aceastã conditie nu eliminã toate perechile irelevante,
deoarece si o variabilã legatã cu variabila Xi
în graf poate fi irelevantã. Deci multimea calculatã cu ajutorul conditiei de
mai sus include multimea ![]() .
.
Exemplu. Fie graful de
restrictii din Figura 4.20, ordonarea variabilelor ![]() si un algoritm de
backtracking care a ajuns în starea curentã
si un algoritm de
backtracking care a ajuns în starea curentã
![]()
Aceastã stare nu mai poate fi extinsã cu nici o valoare
pentru variabila X , deci S
este o multime în conflict cu variabila X .
Dacã ![]() , atunci restrictia R
este violatã, dacã
, atunci restrictia R
este violatã, dacã ![]() , restrictia R
este violatã. Se observã cã
, restrictia R
este violatã. Se observã cã ![]() si
si ![]() sînt perechi
irelevante pentru variabila X ,
deoarece nu existã nici o restrictie explicitã între variabilele X si X
sau între variabilele X si X . Rezultã multimea
sînt perechi
irelevante pentru variabila X ,
deoarece nu existã nici o restrictie explicitã între variabilele X si X
sau între variabilele X si X . Rezultã multimea ![]() ca fiind
ca fiind ![]() . Aceastã multime poate fi memoratã prin eliminarea perechii
. Aceastã multime poate fi memoratã prin eliminarea perechii ![]() din multimea de
restrictii R . În aceastã
situatie, restrictia R
devine . Multimea conflictualã nu este minimalã deoarece
din multimea de
restrictii R . În aceastã
situatie, restrictia R
devine . Multimea conflictualã nu este minimalã deoarece ![]() este în conflict cu
variabila X . De fapt, ar fi
suficient sã se memoreze numai aceastã informatie, eliminînd valoarea b din
domeniul variabilei X .
este în conflict cu
variabila X . De fapt, ar fi
suficient sã se memoreze numai aceastã informatie, eliminînd valoarea b din
domeniul variabilei X .
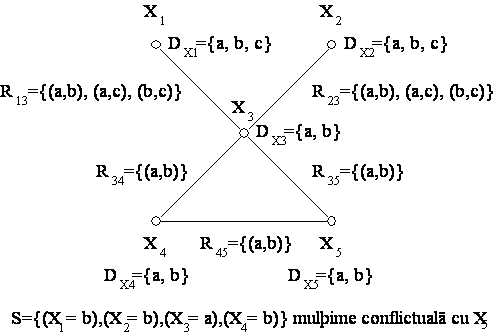
Figura 4.20 Graf de restrictii si multime conflictualã
Procesul de identificare si memorare numai a multimilor conflictuale minimale se numeste învãtare de adîncime. Descoperirea tuturor multimilor conflictuale minimale se numeste învãtare de adîncime completã.
Deducerea multimilor conflictuale minimale este un proces
exponential în raport cu cardinalitatea multimii de conflicte, deci învãtarea
de adîncime completã poate induce necesitãti de timp si spatiu suplimentare
care vor depãsi avantajele de eficientã aduse de aceastã metodã. Dacã c este
cardinalitatea multimii ![]() si se considerã cazul
defavorabil în care toate submultimile lui
si se considerã cazul
defavorabil în care toate submultimile lui ![]() avînd
avînd ![]() elemente sînt în
conflict cu Xi, numãrul de multimi
conflictuale minimale este de ordinul 2c,
ceea ce înseamnã complexitate timp si spatiu exponentialã la fiecare blocare.
Chiar dacã din punct de vedere al timpului, procesul de învãtare poate fi
eficient pentru anumite grafuri de restrictii, el este costisitor din punct de
vedere al spatiului de cãutare.
elemente sînt în
conflict cu Xi, numãrul de multimi
conflictuale minimale este de ordinul 2c,
ceea ce înseamnã complexitate timp si spatiu exponentialã la fiecare blocare.
Chiar dacã din punct de vedere al timpului, procesul de învãtare poate fi
eficient pentru anumite grafuri de restrictii, el este costisitor din punct de
vedere al spatiului de cãutare.
În plus, nu este sigur cã adãugarea restrictiilor
suplimentare reduce necesar calculele efectuate de algoritmul de backtracking.
Desi, în principiu, prezenta unui numãr mare de restrictii va reduce spatiul de
cãutare, cresterea numãrului de restrictii creste costul generãrii spatiului de
cãutare deoarece trebuie sã se testeze un numãr mai mare de restrictii la
fiecare instantiere de variabilã. Din aceastã cauzã, algoritmul de backtracking
cu multime conflictualã foloseste euristica memorãrii multimilor care referã un
numãr mic de variabile, de obicei una sau douã. Controlul aritãtii multimilor
conflictuale este aplicabil atît la învãtarea de suprafatã cît si la cea de
adîncime. De exemplu, dacã se decide memorarea numai a multimilor conflictuale
cu o variabilã, implementarea poate realiza acest lucru prin eliminarea valorii
variabilei din domeniul ei de valori. Învãtarea de suprafatã de ordinul doi va
memora multimea conflictualã ![]() ca o restrictie numai
dacã multimea
ca o restrictie numai
dacã multimea ![]() are maximum douã variabile.
Învãtarea de adîncime de ordinul doi va identifica si memora ca restrictii
numai multimile conflictuale minimale de una sau douã variabile.
are maximum douã variabile.
Învãtarea de adîncime de ordinul doi va identifica si memora ca restrictii
numai multimile conflictuale minimale de una sau douã variabile.
Observatii:
Schemele de învãtare de ordinul întîi sînt echivalente cu realizarea unei arc-consistente partiale, deoarece numai arcele gãsite în procesul de cãutare sînt fãcute consistente. Schemele de învãtare de ordinul doi sînt echivalente cu realizarea unui proces de arc-consistentã partialã si cale-consistentã partialã.
Asa cum s-a vãzut, tehnicile prezentate sînt centrate pe douã idei fundamentale: detectarea si schimbarea deciziilor care au cauzat o situatie de blocare cu ignorarea deciziilor irelevante si înregistrarea motivelor blocãrii, astfel încît aceleasi conflicte sã nu mai aparã din nou pe parcursul cãutãrii. Ambele idei sînt încorporate într-un alt algoritm de satisfacere a restrictiilor care a fost extins la rezolvãri generale a problemelor: algoritmul de backtracking condus de dependente. Prezentarea acestui algoritm si utilizarea lui în sistemele de mentinere a consistentei datelor se va face în Capitolul 5.
4.8 Problema satisfacerii partiale a restrictiilor
Prezentarea initialã a problemei satisfacerii restrictiilor a discutat o instantã a problemei, numitã problema satisfacerii partiale a restrictiilor. În continuare se vor prezenta doi algoritmi pentru rezolvarea acestei instante a problemei satisfacerii restrictiilor.
În cazul unei probleme de satisfacere a restrictiilor, o blocare apare în momentul în care se detecteazã o inconsistentã între o pereche de variabile instantiate. În cazul problemei satisfacerii partiale a restrictiilor, nu apare blocare atît timp cît nu s-au acumulat suficiente inconsistente pentru a se atinge numãrul maxim de inconsistente admis. În acest caz, se pune problema gãsirii unui algoritm de determinare a unei solutii maximale, i.e. o solutie care satisface un numãr cît mai mare de restrictii. Acestã solutie poate fi aceea care satisface toate restrictiile, în cazul în care o astfel de solutie existã si limitarea resurselor permite gãsirea acestei solutii, sau solutia care satisface cele mai multe restrictii posibile, tot în conditiile existentei unor resurse date, eventual limitate.
4.8.1 Determinarea solutiei utilizînd algoritmul "branch and bound"
Primul algoritm prezentat este o extindere a algoritmului
de backtracking simplu pentru problema satisfacerii partiale a restrictiilor.
Ideea de bazã a algoritmului este combinarea schemei de backtracking pentru
gãsirea tuturor solutiilor cu o strategie de cãutare informatã de tip
"branch and bound" [
Functia de evaluare utilizatã de strategia "branch and bound" este, în acest caz, numãrul de restrictii violate, altfel spus numãrul de inconsistente detectate. Valoarea acestei functii reprezintã distanta unei anumite instantieri (partialã sau completã) a variabilelor fatã de solutia perfectã, i.e. solutia care satisface toate restrictiile. Aceastã functie va fi notatã în continuare cu d.
În timpul cãutãrii se foloseste o variabilã NI care
memoreazã numãrul de inconsistente gãsite în "cea mai bunã solutie"
depistatã pînã la un moment dat. Valoarea NI reprezintã o limitã necesarã, în sensul cã, pentru a obtine un rezultat mai bun,
este necesarã gãsirea unei solutii cu mai putine inconsistente. Limita necesarã
NI poate fi stabilitã initial pe baza cunostintelor specifice problemei: se stie,
de exemplu, cã existã o solutie care violeazã mai putin de NI restrictii sau,
alt exemplu, existã cerinta a priori ca solutia sã nu violeze mai mult de ![]() restrictii. În timpul
cãutãrii, în cazul în care se gãseste o solutie care violeazã un numãr de
restrictii NI',
restrictii. În timpul
cãutãrii, în cazul în care se gãseste o solutie care violeazã un numãr de
restrictii NI', ![]() , valoarea NI este inlocuitã cu NI'. Din acest motiv, în
cazul în care nu existã informatie a priori despre valoarea limitei necesare,
se poate considera la începutul algoritmului limita necesarã
"infinitã" (foarte mare), iar algoritmul va determina cea mai micã
valoare posibilã pentru limita necesarã NI.
, valoarea NI este inlocuitã cu NI'. Din acest motiv, în
cazul în care nu existã informatie a priori despre valoarea limitei necesare,
se poate considera la începutul algoritmului limita necesarã
"infinitã" (foarte mare), iar algoritmul va determina cea mai micã
valoare posibilã pentru limita necesarã NI.
Considerînd din nou exemplul robotului constient de restrictiile
modei (Sectiunea 4.1.2), în Figura 4.21 se prezintã arborele de cãutare
determinat de strategia "branch and bound" pentru rezolvarea acestei
probleme. În figurã, d reprezintã distanta fatã de solutie, NI este limita
necesarã iar t.c. reprezintã numãrul de teste de consistentã efectuate de la
începutul cãutãrii pînã într-un anumit nod al arborelui. Pe prima ramurã de
cãutare, escarpeni-jeans-verde, se determinã valoarea limitei necesare ![]() , iar pe ramura escarpeni-jeans-albã, valoarea
, iar pe ramura escarpeni-jeans-albã, valoarea ![]() . Se retine aceastã ultimã valoare. Pe a treia ramurã de
cãutare se recunoaste faptul cã orice solutie partialã care implicã
atribuirile Pantofi-escarpeni si
Pantaloni-bleu, nu se poate extinde la o solutie cu o valoare inferioarã pentru
limita necesarã NI, deoarece functia de evaluare are deja valoarea
. Se retine aceastã ultimã valoare. Pe a treia ramurã de
cãutare se recunoaste faptul cã orice solutie partialã care implicã
atribuirile Pantofi-escarpeni si
Pantaloni-bleu, nu se poate extinde la o solutie cu o valoare inferioarã pentru
limita necesarã NI, deoarece functia de evaluare are deja valoarea ![]() , asa cã se abandoneazã cãutarea de-a lungul acestei cãi.
Astfel de cãi au fost marcate în Figura 4.21 prin atasarea simbolului * nodului
de la care expandarea cãii înceteazã.
, asa cã se abandoneazã cãutarea de-a lungul acestei cãi.
Astfel de cãi au fost marcate în Figura 4.21 prin atasarea simbolului * nodului
de la care expandarea cãii înceteazã.
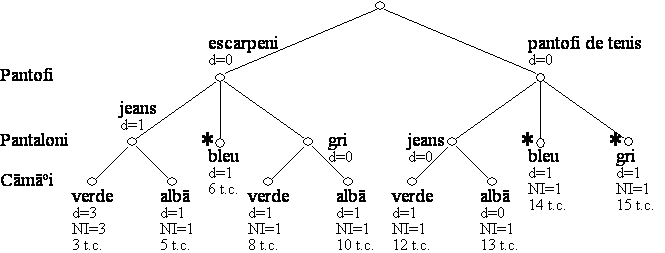
Figura 4.21 Arborele de cãutare generat de algoritmul
"branch and bound"
pentru problema robotului
Algoritmul poate fi extins prin includerea unei valori noi,
numitã limita suficientã si notatã cu
![]() . De exemplu, dacã se stie a priori cã o problemã de
satisfacere a restrictiilor nu admite o solutie perfectã, se poate alege
valoarea limitã suficientã
. De exemplu, dacã se stie a priori cã o problemã de
satisfacere a restrictiilor nu admite o solutie perfectã, se poate alege
valoarea limitã suficientã ![]() . Cu cît valoarea limitei suficiente este mai mare, cu atît
mai simplu este de rezolvat problema. În cazul în care nu existã cunostinte a
priori despre S sau se testeazã dacã existã solutie perfectã, se alege valoarea
limitei suficiente
. Cu cît valoarea limitei suficiente este mai mare, cu atît
mai simplu este de rezolvat problema. În cazul în care nu existã cunostinte a
priori despre S sau se testeazã dacã existã solutie perfectã, se alege valoarea
limitei suficiente ![]() .
.
Algoritmul "branch and bound" este potrivit si în cazul existentei unor resurse limitate, de exemplu timp, deoarece poate produce o primã solutie acceptabilã într-un interval limitat de timp si poate încerca ulterior o rafinare a acestei solutii, prezentînd deci o comportare de tipul "cel mai bun gãsit pînã în prezent".
Determinarea unei solutii partiale utilizînd strategia
"branch and bound" se bazeazã pe functia PBKT![]() care întoarce ca valoare starea procesului de cãutare;
parametrii functiei au urmãtoarea semnificatie:
care întoarce ca valoare starea procesului de cãutare;
parametrii functiei au urmãtoarea semnificatie:
Cale memoreazã calea de cãutare, sub forma unei liste de instantieri variabilã-valoare realizate pînã la un anumit moment.
Distanta reprezintã numãrul de restrictii violate, pînã la un anumit moment, de instantierile realizate pînã în acel moment.
Variabile reprezintã lista variabilelor ce nu au fost încã instantiate.
Valori memoreazã lista valorilor care nu au fost încã încercate ca extensie a cãii curente, pentru variabila curentã. Se considerã ca variabilã curentã primul element din lista Variabile.
Functia poate întoarce douã valori, care indicã starea procesului de cãutare:
GATA care semnalizeazã gãsirea solutiei si întreruperea procesului de cãutare, si
CONTINUÃ care semnalizeazã faptul cã nu s-a gãsit încã solutia si este necesarã continuarea cãutãrii.
În algoritm, functia PBKT este apelatã recursiv pentru
extensia cãii curente prin instantierea variabilei urmãtoare, sub forma PBKT![]() , unde Rest(Variabile) este lista variabilelor neinstantiate
din care a fost înlãturat primul element (variabila curentã) iar ValoriNoi
reprezintã domeniul de valori al variabilei de pe nivelul urmãtor. Functia PBKT
este, de asemenea, apelatã si pentru încercarea unei noi instantieri pe acelasi
nivel, sub forma PBKT
, unde Rest(Variabile) este lista variabilelor neinstantiate
din care a fost înlãturat primul element (variabila curentã) iar ValoriNoi
reprezintã domeniul de valori al variabilei de pe nivelul urmãtor. Functia PBKT
este, de asemenea, apelatã si pentru încercarea unei noi instantieri pe acelasi
nivel, sub forma PBKT![]() .
.
Algoritmul utilizeazã urmãtoarele variabile globale:
CeaMaiBunã, care memoreazã cea mai bunã solutie gãsitã pînã la un moment dat,
NI, care memoreazã limita necesarã si reprezintã numãrul de inconsistente gãsite în cea mai bunã solutie pînã la un moment dat în cãutare si
S, care memoreazã limita suficientã,
celelalte variabile fiind locale functiei PBKT.
Algoritmul este o tehnicã retrospectivã, deci dupã instantierea unei variabile, valoarea ei este testatã cu valorile atribuite variabilelor anterioare. Distanta fatã de solutia perfectã este comparatã cu valoarea NI dupã fiecare esec de verificare a restrictiilor.
Algoritm: Satisfacerea partialã a restrictiilor utilizînd strategia "branch and bound"
PBKT (Cale, Distanta, Variabile, Valori)
1. dacã ![]() /*
toate variabilele au atribuite valori */
/*
toate variabilele au atribuite valori */
atunci
1.1. ![]()
1.2. ![]()
1.3. dacã
![]()
atunci întoarce GATA /* solutia este suficient de bunã */
1.4. altfel întoarce CONTINUÃ
2. altfel
2.1. dacã
![]() /*
s-a încercat extinderea cãii de cãutare cu
toate valorile */
/*
s-a încercat extinderea cãii de cãutare cu
toate valorile */
atunci întoarce CONTINUÃ /* se revine la variabila anterioarã */
2.2. altfel
2.2.1. dacã
![]()
atunci întoarce CONTINUÃ /* se revine la variabila anterioarã pentru a încerca gãsirea unei solutii mai bune */
2.2.2. altfel /* se încearcã extinderea cãii curente */
i. ![]()
ii. ![]()
iii. ![]()
iv. ![]()
v. cît
timp ![]() si
si ![]() executã
executã
- Considerã prima pereche ![]() din Cale1
din Cale1
- dacã
![]()
atunci
![]()
- ![]()
vi. dacã
![]() si
si
PBKT![]()
![]()
/* ValoriNoi - domeniul de valori asociat primei variabile din Rest(Variabile) */
atunci întoarce GATA /* s-a gãsit o solutie satisfãcãtoare */
vi. altfel
întoarce PBKT![]()
/* se încearcã gãsirea unei solutii mai bune cu o nouã valoare pentru variabila curentã */
sfîrsit.
În algoritmul prezentat, s-a ales o variantã de cãutare "branch and bound" care functioneazã pe o schemã de cãutare în adîncime, deoarece aceastã paradigmã este mai apropiatã de algoritmul de backtracking. În plus, cãutarea în adîncime este potrivitã pentru a produce cea mai bunã solutie pînã la un moment dat. Timpul cel mai defavorabil al aceastui algoritm este exponential în raport cu numãrul de variabile si valori, dar nu este mai costisitor decît cel al algoritmului de backtracking simplu pentru gãsirea unei solutii perfecte.
4.8.2 Determinarea solutiei utilizînd algoritmul de backtracking cu salt
Algoritmul de backtracking cu salt pentru rezolvarea problemei satisfacerii restrictiilor memoreazã nivelul din arborele de cãutare pentru care toate valorile unei variabile au dus la blocare si, la revenire, face saltul la acel nivel. În cazul în care acest nivel este nivelul anterior, atunci se procedeazã ca în algoritmul de backtracking simplu.
În algoritmul de backtracking cu salt pentru rezolvarea
problemei satisfacerii partiale a restrictiilor, blocarea nu apare la gãsirea
unei inconsistente, ci numai atunci cînd s-a acumulat un numãr de inconsistente
egal cu valoarea predefinitã NI. De exemplu, dacã cãutarea a ajuns la a ![]() variabilã din secventã,
X , si verificarea consistentei
unei valori din domeniul ei de valori cu valoarea atribuitã variabilei X determinã cresterea distantei la
valoarea NI, adîncimea de blocare a variabilei X este 5.
variabilã din secventã,
X , si verificarea consistentei
unei valori din domeniul ei de valori cu valoarea atribuitã variabilei X determinã cresterea distantei la
valoarea NI, adîncimea de blocare a variabilei X este 5.
Revenind la exemplul robotului constient de restrictiile modei, exemplu deja învãtat pe dinafarã de cititorul constiincios, arborele de cãutare generat de algoritmul de backtracking cu salt pentru satisfacerea partialã a restrictiilor este cel prezentat în Figura 4.22. Se observã cã algoritmul detecteazã nivelul de blocare pantofi de tenis pentru variabila Cãmãsi cu valorile verde si albã. În consecintã, se face saltul la nivelul variabilei Pantofi si nu se mai considerã celelalte douã valori posibile pentru variabila Pantaloni, respectiv bleu si gri. Sãgetile numerotate din figurã indicã nivelele de salt întoarse de functia PBJ, ce va fi prezentatã în continuare.
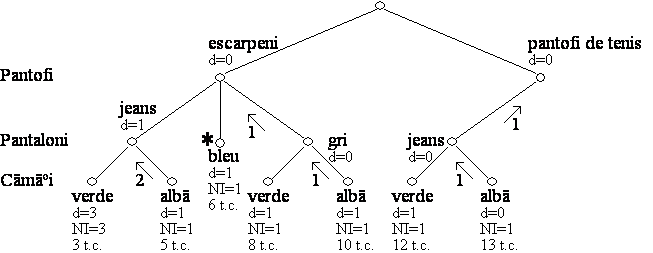
Figura 4.22 Arborele de cãutare generat de algoritmul de
backtracking cu salt
pentru problema robotului
În afara diferentei mentionate anterior, existã o a doua diferentã semnificativã între algoritmul de backtracking cu salt pentru rezolvarea problemei satisfacerii restrictiilor si cel pentru rezolvarea problemei satisfacerii partiale a restrictiilor. În cazul acestei ultime probleme, nu se poate sãri întotdeauna la cel mai adînc nivel de blocare. Dacã una din valorile de pe nivelele inferioare nivelului de blocare a fost inconsistentã, i.e. a necesitat o crestere a distantei, se poate sãri înapoi numai pînã la nivelul L al valorii inconsistente celei mai adînci, acesta fiind nivelul cel mai de jos în arbore unde a fost admisã o valoare inconsistentã. Acest lucru este necesar deoarece valori alternative de pe nivelul L ar putea implica mai putine inconsistente, fãcînd distanta sã creascã mai putin, iar cãutarea ar putea continua de la nivelul L, fãrã sã ajungã la distanta limitã NI în acelasi punct.
Ca un exemplu al acestui fenomen, se modificã problema
robotului astfel încît sã existe alte valori testate anterior care au dat o
limitã necesarã ![]() . Se considerã ordinea variabilelor: Pantaloni, Cãmãsi,
Pantofi, asa cum se vede în Figura 4.23. Fiecare domeniu este verificat de la
stînga la dreapta si o linie verticalã apare la dreapta valorilor curent
considerate. Inconsistentele sînt indicate de liniile ce unesc nodurile.
Cãutarea s-a blocat cînd a ajuns la variabila numãrul trei, deoarece numãrul de
inconsitente a devenit egal cu valoarea limitã NI, cu adîncimea de blocare
egalã cu X , nivelul
variabilei 1. În cazul problemei satisfacerii restrictiilor, cãutarea ar sãri
la nivelul variabilei X
(Pantaloni) si urmãtoarea valoare ar fi selectatã; în cazul problemei
satisfacerii partiale a restrictiilor, urmãtoarea valoare asociatã variabilei X (Cãmãsi), albã, este compatibilã cu
valoarea variabilei X
(Pantaloni), bleu, deci nu existã nici o inconsistentã între variabilele X si X
(Pantaloni si Cãmãsi). Prin revenirea la nivelul variabilei X , se poate alege o valoare care lasã
distanta egalã cu valoarea 0. În plus, valoarea escarpeni pentru variabila X este compatibilã cu valoarea albã a
variabilei X , dar nu cu
valoarea bleu a variabilei X ,
deci este posibilã gãsirea unei solutii cu pantaloni bleu si cãmasa albã avînd
distanta egalã cu 1.
. Se considerã ordinea variabilelor: Pantaloni, Cãmãsi,
Pantofi, asa cum se vede în Figura 4.23. Fiecare domeniu este verificat de la
stînga la dreapta si o linie verticalã apare la dreapta valorilor curent
considerate. Inconsistentele sînt indicate de liniile ce unesc nodurile.
Cãutarea s-a blocat cînd a ajuns la variabila numãrul trei, deoarece numãrul de
inconsitente a devenit egal cu valoarea limitã NI, cu adîncimea de blocare
egalã cu X , nivelul
variabilei 1. În cazul problemei satisfacerii restrictiilor, cãutarea ar sãri
la nivelul variabilei X
(Pantaloni) si urmãtoarea valoare ar fi selectatã; în cazul problemei
satisfacerii partiale a restrictiilor, urmãtoarea valoare asociatã variabilei X (Cãmãsi), albã, este compatibilã cu
valoarea variabilei X
(Pantaloni), bleu, deci nu existã nici o inconsistentã între variabilele X si X
(Pantaloni si Cãmãsi). Prin revenirea la nivelul variabilei X , se poate alege o valoare care lasã
distanta egalã cu valoarea 0. În plus, valoarea escarpeni pentru variabila X este compatibilã cu valoarea albã a
variabilei X , dar nu cu
valoarea bleu a variabilei X ,
deci este posibilã gãsirea unei solutii cu pantaloni bleu si cãmasa albã avînd
distanta egalã cu 1.
Deoarece distanta limitã NI a fost stabilitã la valoarea 2, solutia gãsitã este acceptabilã. Totusi, ar fi putut fi ignoratã dacã s-ar fi procedat ca în cazul algoritmului de backtracking cu salt pentru problema satisfacerii complete a restrictiilor.

Figura 4.23 Backtracking cu salt la nivelul ultimei selectii inconsistente
Pentru a surprinde acest caz, algoritmul trebuie sã memoreze cel mai adînc nivel L asociat unei inconsistente, notat în continuare cu AdInconsist, în plus fatã de memorarea adîncimii de blocare. Subprogramul PBJ(Cale, Distanta, Variabile, Valori, Adîncime, AdSalt, AdInconsist) rezolvã problema satisfacerii partiale a restrictiilor prin backtracking cu salt pornind de la o schemã generalã asemãnãtoare cu cea folositã de subprogramul PBKT. Functia PBJ întoarce fie o valoare specialã, GATA, avînd semnificatia gãsirii unei solutii acceptabile, fie adîncimea de salt (i.e. nivelul unde se revine din backtracking). AdInconsist este transmis ca parametru al subprogramului si este actualizat la valoarea Adîncime, adîncimea curentã a procesului de cãutare, dacã apare o blocare pe nivelul curent.
Algoritm: Satisfacerea partialã a restrictiilor utilizînd strategia backtracking cu salt
PBJ (Cale, Distanta, Variabile, Valori, Adîncime, AdSalt, AdInconsist)
1. dacã ![]()
atunci
1.1. ![]()
1.2. ![]()
1.3. dacã
![]()
atunci întoarce GATA
1.4. altfel întoarce ![]()
2. altfel
2.1. dacã
![]() sau
sau ![]()
atunci întoarce AdSalt /* poate duce la salt */
2.2. altfel /* încearcã extinderea cãii */
2.2.1. ![]()
2.2.2. ![]()
2.2.3. ![]()
2.2.4. ![]()
2.2.5.
cît timp ![]() si
si ![]() executã
executã
i. Considerã prima pereche ![]() din Cale1
din Cale1
ii. dacã
![]()
atunci
- ![]()
- ![]()
iii. ![]()
2.2.6. dacã
![]()
atunci ![]() /* nu
a apãrut blocare */
/* nu
a apãrut blocare */
2.2.7. dacã
![]()
atunci ![]()
![]()
2.2.8. altfel ![]()
![]()
2.2.9. dacã
(![]() sau
sau ![]() ) si
) si ![]()
atunci întoarce NivelBloc2
2.2.10.altfel întoarce ![]()
![]()
sfîrsit.
Observatii:
Dacã problema admite o solutie care violeazã un numãr de restrictii
egal sau mai mic cu limita suficientã S, atunci algoritmul se opreste de îndatã
ce gãseste aceastã solutie. În cazul exemplului cu robotul, dacã se porneste cu
limita suficientã ![]() , solutia gãsitã va fi
, solutia gãsitã va fi ![]() .
.
Dacã nu existã nici o solutie cu distanta inferioarã limitei
suficiente, atunci algoritmul inspecteazã toate cãile de cãutare care au o
distantã inferioarã sau egalã cu cea mai bunã distantã gãsitã pînã la un moment
dat, în speranta gãsirii unei solutii cu o distantã mai micã. În exemplul
robotului, dacã se porneste cu limita suficientã ![]() , solutia gãsitã va fi
, solutia gãsitã va fi ![]() .
.
Cele douã observatii anterioare sînt valabile atît pentru algoritmul de backtracking cu salt cît si pentru algoritmul "branch and bound". În cazul algoritmului de backtracking cu salt, avantajul este evident acela al reducerii numãrului de teste de consistentã efectuate, deci obtinerea unui timp de rezolvare mai bun.
4.8.3 Solutii de implementare
În aceastã sectiune se prezintã solutiile de implementare ale celor doi algoritmi de backtracking pentru rezolvarea problemei satisfacerii partiale a restrictiilor: algoritmul "branch and bound" si algoritmul de backtracking cu salt.
În solutiile prezentate, semnificatia variabilelor speciale *EXPANDARI* si *VERIFICARI*, si a parametrilor Cale si Variabile ai functiilor PBKT si PBJ a rãmas nemodificatã fatã de cea prezentatã în Sectiunea 4.4.1. Spre deosebire de acestea, parametrul Valori si-a schimbat semnificatia. În implementarea din Sectiunea 4.4.1, parametrul Valori memora lista domeniilor de valori ale variabilelor neinstantiate. De aceastã datã, Valori memoreazã domeniul de valori neexplorat al variabilei curente. Pentru a nu adãuga noi parametri functiilor, întregul domeniu de valori al unei variabile este memorat ca valoare a proprietãtii Domeniu a simbolului asociat respectivei variabile. Din aceastã cauzã, la avansul pe un nivel mai adînc al arborelui de cãutare, corespunzãtor variabilei ValoriNoi din algoritmii prezentati, se va folosi valoarea proprietãtii Domeniu a variabilei urmãtoare, iar rãmînerea pe acelasi nivel în arborele de cãutare va reprezenta explorarea restului domeniului de valori al variabilei curente Valori. Nivelul fiecãrei variabile va fi memorat ca valoare a proprietãtii Nivel, atasatã simbolului asociat respectivei variabile.
Fatã de programele prezentate anterior, care determinau toate solutiile unei probleme si le memorau în variabila specialã *SOLUTII*, programele corespunzãtoare algoritmilor de backtracking pentru rezolvarea problemei satisfacerii partiale a restrictiilor determinã numai cea mai bunã solutie gãsitã pînã la un moment al cãutãrii. Aceastã solutie este memoratã în variabila specialã *CEA-MAI-BUNA*. Variabilele speciale *NI* si *S* corespund limitei necesare si, respectiv, limitei suficiente din algoritmii prezentati. Valorile GATA si CONTINUÃ utilizate în algoritmi pentru a indica starea procesului de cãutare vor fi codificate prin simbolii Lisp t si respectiv nil.
;; Satisfacerea partiala a restrictiilor utilizind strategia "branch and bound"
(defun PBKT (Cale Distanta Variabile Valori)
(if (null Variabile)
(progn
(setf *CEA-MAI-BUNA* Cale ;; memoreaza cea mai buna solutie
*NI* Distanta) ;; si calitatea ei
(<= *NI* *S*))
(if (null Valori) nil ;; CONTINUA
(if (>= Distanta *NI*)
nil
(let ((Var (first Variabile))
(Val (first Valori))
(DistNoua Distanta))
(do* ((Cale1 Cale (rest Cale1))
(pereche (first Cale1) (first Cale1)))
((or (null Cale1) ;; s-a terminat verificarea
(>= DistNoua *NI*))) ;; sau a aparut o blocare
(incf *VERIFICARI*)
(unless (exista-relatie-p Var Val (first pereche) (rest pereche))
(incf DistNoua)))
(if (and (<= DistNoua *NI*)
(incf *EXPANDARI*)
(PBKT (cons (cons Var Val) Cale)
DistNoua (rest Variabile)
(get (cadr Variabile) 'Domeniu)))
t
(PBKT Cale Distanta Variabile (rest Valori))))))))
;; Satisfacerea partiala a restrictiilor utilizind strategia backtracking cu salt
(defun PBJ (Cale Distanta Variabile Valori Adincime AdSalt AdInconsist)
(if (null Variabile)
(progn
(setf *CEA-MAI-BUNA* Cale ;; memoreaza cea mai buna solutie
*NI* Distanta) ;; si calitatea ei
(if (<= *NI* *S*)
t ;; GATA
(1- Adincime))) ;; nivelul de revenire
(if (or (null Valori) (>= Distanta *NI*))
AdSalt ;; nivelul de revenire
(let ((Var (first Variabile)) ;; incearca extinderea solutiei
(Val (first Valori))
(DistNoua Distanta)
NivelBlocare1
NivelBlocare2)
(do* ((Cale1 Cale (rest Cale1))
(pereche (first Cale1) (first Cale1)))
((or (null Cale1) ;; s-a terminat verificarea
(>= DistNoua *NI*))) ;; sau a aparut o blocare
(incf *VERIFICARI*)
(unless (exista-relatie-p Var Val (first pereche) (rest pereche))
(incf DistNoua) ;; marcheaza inconsistenta
(setf NivelBlocare1 ;; si adincimea variabilei
(get (first pereche) 'Nivel)))) ;; care a produs-o
(when (< DistNoua *NI*) ;; nu s-a blocat
(setf NivelBlocare1 Adincime))
(if (= DistNoua Distanta) ;; au aparut inconsistente?
(progn
(incf *EXPANDARI*)
(setf NivelBlocare2
(PBJ (append Cale (list (cons Var Val)))
DistNoua
(rest Variabile) (get (cadr Variabile) 'Domeniu)
(1+ Adincime) 0 AdInconsist)))
(progn
(incf *EXPANDARI*)
(setf NivelBlocare2
(PBJ (append Cale (list (cons Var Val)))
DistNoua
(rest Variabile) (get (cadr Variabile) 'Domeniu)
(1+ Adincime) 0 Adincime))))
(if (or (not (numberp NivelBlocare2)) ;; solutie acceptabila
(and (< DistNoua *NI*)
(< NivelBlocare2 Adincime))) ;; se face salt
NivelBlocare2
(PBJ Cale
Distanta
Variabile (rest Valori)
Adincime (max NivelBlocare1 AdSalt AdInconsist) AdInconsist)))))))
Initializarea procesului de cãutare se realizeazã prin secventa:
(defparameter *CEA-MAI-BUNA* nil)
(defparameter *NI* *MOST-POSITIVE-FIXNUM*)
(defparameter *S* calitate)
(defparameter *EXPANDARI* 0)
(defparameter *VERIFICARI* 0)
unde *MOST-POSITIVE-FIXNUM* este o constantã Lisp avînd valoarea celui mai mare întreg reprezentabil, iar calitate este limita suficientã pe care utilizatorul doreste sã o utilizeze.
Pentru rezolvarea problemei robotului se pot utiliza predicatul exista-relatie-p si functia tipareste-solutie definite în Sectiunea 4.6.4, iar reprezentarea problemei se obtine prin secventa:
(defparameter *VARIABILE* '(Pantofi Pantaloni Camasi))
(setf (get (first *VARIABILE*) 'Domeniu) '(Escarpeni Pantofi-de-tenis)
(get (second *VARIABILE*) 'Domeniu) '(Jeans Bleu Gri)
(get (third *VARIABILE*) 'Domeniu) '(Verde Alba)
(get (first *VARIABILE*) 'Nivel) 0
(get (second *VARIABILE*) 'NIVEL) 1
(get (third *VARIABILE*) 'Nivel) 2)
(defparameter *RESTRICTII*
`(,(cons '(Pantofi . Escarpeni) '(Pantaloni . Gri))
,(cons '(Pantofi . Pantofi-de-tenis) '(Pantaloni . Jeans))
,(cons '(Pantofi . Escarpeni) '(Camasi . Alba))
,(cons '(Pantaloni . Gri) '(Camasi . Verde))
,(cons '(Pantaloni . Jeans) '(Camasi . Alba))
,(cons '(Pantaloni . Bleu) '(Camasi . Alba))))
Tipãrirea solutiei problemei se face prin apelurile:
(PBKT nil 0 *VARIABILE* (get (car *VARIABILE*) 'Domeniu))
sau
(PBJ nil 0 *VARIABILE* (get (car *VARIABILE*) 'Domeniu) 0 0 0)
si
(format t "~&Cea mai buna solutie (N=~D) :" *NI*)
(tipareste-solutie *CEA-MAI-BUNA*))
4.9 Exercitii si probleme
1. Trei actori, Radu, Sergiu si Tatiana, apar într-un spectacol alcãtuit din mai multe acte. În fiecare act apar unul, doi sau toti trei actorii. Distributia din fiecare douã acte consecutive trebuie sã continã cel putin un actor comun, dar nu poate avea toti actorii în comun. Presupunîndu-se cã actorii din distributia unui act rãmîn pe scenã pe întreaga duratã a actului, se cere:
1. Sã se indice toate distributiile posibile pentru douã acte consecutive
2. Dacã Sergiu apare în actele I si IV, care din urmãtoarele asertiuni sînt adevãrate:
(A) Sergiu apare în fiecare din primele patru acte.
(B) Radu apare o singurã datã în primele patru acte.
(C) Tatiana apare atît în actul II cît si în actul III.
(D) Radu, Sergiu si Tatiana apar împreunã în actul V.
(E) Distributia actului V este identicã cu cea a actului III.
3. Dacã Radu este distribuit în actul I si apoi nu mai apare în urmãtoarele patru acte, care dintre urmãtoarele afirmatii este adevãratã pentru distributiile din cel putin douã din primele cinci acte
(A) Sergiu apare singur.
(B) Tatiana apare singurã.
(C) Sergiu si Tatiana apar împreunã.
2. Un agricultor planteazã cinci tipuri diferite de legume: fasole, porumb, napi, mazãre si dovlecei. În fiecare an, agricultorul planteazã trei tipuri de legume respectînd urmãtoarele restrictii:
(1) Dacã agricultorul planteazã porumb într-un an, trebuie sã planteze si fasole în acel an.
(2) Dacã agricultorul planteazã napi într-un an, nu mai trebuie sã-i planteze si anul urmãtor.
(3) În fiecare an agricultorul planteazã cel mult un soi din legumele plantate în anul precedent.
Se cere:
(a) Dacã agricultorul planteazã fasole, porumb si napi în primul an, ce va planta în cel de-al treilea an?
(b) Indicati combinatiile posibile de legume plantate în doi ani consecutivi. Care din urmãtoarele combinatii se aflã printre cele posibile?
(A) fasole, porumb, napi; porumb, mazãre, dovlecei
(B) fasole, porumb, mazãre; fasole, porumb, dovlecei
(C) fasole, mazãre, dovlecei; fasole, porumb, napi
(D) porumb, mazãre, dovlecei; fasole, napi, mazãre
3. Sã se scrie un program care sã implementeze algoritmul de etichetare a desenelor prezentat în Sectiunea 4.3.
4. Se considerã o problemã definitã prin urmãtoarele restrictii:
(a) Restrictiile determinate de optiunile studentilor pentru anumite cursuri
Mihai, Prolog
Mihai, Matematicã
Vlad, Artã
Vlad, Prolog
Anda, C
Anda, Lisp
Anda, Pascal
(b) Restrictiile determinate de desfãsurarea cursurilor în anumite zile ale sãptãmînii
Prolog, Luni ; Prolog, Vineri
Matematicã, Marti ; Matematicã, Vineri
C, Joi ; C, Vineri
Lisp, Marti
Pascal, Joi ; Pascal, Sîmbãtã
(c) Restrictiile determinate de locul de desfãsurare al cursurilor
Luni, Clasa1
Marti, Clasa1
Joi, Clasa1 ; Joi, Clasa3
Vineri, Clasa2
Sîmbãtã, Clasa2
Se cere:
(1) Sã se reprezinte graful de restrictii asociat scopului "Ce studenti pot urma douã cursuri diferite în douã zile diferite?"
.
(2) Sã se reprezinte graful de restrictii asociat scopului "Ce studenti pot urma care cursuri, în ce zile si în ce clase?".
(3) Sã se utilizeze un limbaj de programare logic, de exemplu Prolog, pentru reprezentarea acestei probleme si sã se exprime în limbaj cele douã scopuri enuntate anterior.
5. Se considerã urmãtoarea problemã, numitã problema cãsãtoriilor stabile. N bãrbati si N femei îsi exprimã preferintele, în ordine, pentru cei N indivizi de sex opus. Problema constã în gãsirea unei multimi de cãsãtorii stabile. O multime de cãsãtorii este instabilã dacã existã cel putin douã persoane necãsãtorite între ele care se preferã reciproc fatã de sotii lor. Altfel spus, fiecare din cele douã persoane si-a exprimat o preferintã mai mare fatã de cealaltã persoanã decît fatã de sotul, respectiv sotia lui actualã. Se cere:
(1) Sã se
reprezinte graful de restrictii asociat unei instante a problemei, de exemplu ![]() , specificînd variabilele, domeniile lor de valori si restrictiile.
, specificînd variabilele, domeniile lor de valori si restrictiile.
(2) Sã se scrie un program pentru gãsirea unei solutii a acestei probleme utilizînd un algoritm eficient.
(3) Sã se scrie un subprogram care verificã dacã o multime generatã de cãsãtorii este stabilã.
(4) Sã se scrie un program pentru determinarea tuturor solutiilor acestei probleme, utilizînd unul din algoritmii de backtracking prezentati.
6. Se considerã urmãtoarea problemã, cunoscutã sub numele de problema zebrei. Existã cinci case, de culori diferite, locuite de persoane avînd nationalitãti diferite si care cresc animale diferite, fumeazã tigãri diferite si beau bãuturi diferite. Se cunoaste cã:
1. Englezul locuieste în casa rosie.
2. Spaniolul are un cãtel.
3. Cafeaua se bea în casa verde.
4. Ucraineanul bea ceai.
5. Casa verde este imediat la dreapta casei ocru.
6. Fumãtorul de Old Gold creste melci.
7. În casa galbenã se fumeazã Kools.
8. În casa din mijloc se bea lapte.
9. Norvegianul trãieste în prima casã din stînga.
10. Fumãtorul de Chesterfield locuieste imediat lîngã cel care creste vulpea.
11. În casa de lîngã cea în care se creste calul se fumeazã Kools.
12. Fumãtorul de Lucky Strike bea suc de portocale.
13. Japonezul fumeazã Parliament.
14. Norvegianul trãieste imediat lîngã casa albastrã.
Se cere:
(1) Sã se reprezinte graful de restrictii binare al acestei probleme.
(2) Sã se exprime restrictiile 5, 8, 9 si 11 si sã se indice dacã aceste restrictii sînt unare sau binare.
(3) Sã se afle cine creste zebra si cine bea apã. Pentru aceasta se va folosi un limbaj de programare logic, de exemplu Prolog, si se vor exprima restrictiile direct în limbaj. Se vor stabili douã scopuri care sã rãspundã la cele douã întrebãri formulate.
7. Se considerã o problemã de satisfacere a restrictiilor definitã în urmãtorul mod:
existã cinci variabile X1, X2, X3, X4 si X5
domeniile de valori ale variabilelor sînt ![]() ,
, ![]() ,
, ![]() ,
, ![]() si
si ![]()
restrictiile sînt specificate de urmãtoarele multimi
X1 X3
X2 X3
X3 X4
X3 X5
X4 X5
Se cere:
1. Sã se deseneze graful de restrictii asociat problemei.
2. Sã se aplice algoritmul de d-arc-consistentã si sã se deseneze noul graf astfel rezultat.
3. Sã se construiascã arborii de cãutare ai solutiei cu indicarea variabilelor conflictuale de fiecare datã cînd apare o blocare, atît înainte cît si dupã aplicarea algoritmului de d-arc-consistentã.
8. Sã se scrie un program pentru implementarea algoritmului de realizare a d-arc-consistentei unui graf de restrictii, algoritm prezentat în Sectiunea 4.5. Se considerã ca date de intrare N, numãrul de variabile ale problemei, domeniile de valori ale variabilelor si restrictiile binare dintre variabile. Cele N variabile ale problemei sînt ordonate si reprezentate prin numere întregi. Programul trebuie sã afiseze noile domenii de valori ale variabilelor.
9.
Sã se scrie un algoritm care determinã dacã un graf de restrictii dat este d-arc-consistent. Sã se discute care este efectul aplicãrii algoritmului de realizare a d-arc-consistentei pe un graf de restrictii care nu are proprietatea de d-arc-consistentã.
10.
Sã se scrie un program pentru rezolvarea problemei celor opt regine utilizînd:
un algoritm de backtracking cu predictie completã,
un algoritm de backtracking cu predictie partialã,
un algoritm de backtracking cu verificare predictivã.
În fiecare caz se va include o componentã de numãrare a testelor de consistentã efectuate si se vor compara rezultatele obtinute.
11.
Sã se scrie un program pentru rezolvarea problemei generale a criptogramei prezentatã în Sectiunea 4.1.3, utilizînd:
un algoritm de backtracking simplu,
un algoritm de backtracking cu marcare.
12. Sã se scrie un algoritm de backtracking pentru o problemã a cãrei solutie este reprezentatã prin grafuri SI/SAU. Sã se implementeze acest algoritm pentru a rezolva problema urmãtoare. Existã 12 monede, identice ca formã, dintre care 11 au aceeasi greutate si una are o greutate diferitã (este mai usoarã sau mai grea decît celelalte). Utilizînd o balantã cu douã talere egale sã se gãseascã moneda de greutate diferitã printr-un numãr minim de cîntãriri.
13. Sã se scrie un algoritm pentru rezolvarea problemei satisfacerii partiale a restrictiilor utilizînd metoda de backtracking cu marcare.
4.10 Rezolvãri
4. (1) Graful de restrictii asociat scopului "Ce studenti pot urma douã cursuri diferite în douã zile diferite?"
este prezentat în Figura 4.24.
Figura 4.24 Graful de restrictii asociat primului scop al problemei cursurilor
(2) Graful de restrictii asociat scopului "Ce studenti pot urma care cursuri, în ce zile si în ce clase?" este prezentat în Figura 4.25.
Figura 4.25 Graful de restrictii asociat celui de-al doilea scop al problemei cursurilor
(3) Programul Prolog pentru rezolvarea problemei este:
%% Baza de fapte
%% optiune(Student,Curs) specifica restrictiile determinate de optiunile studentilor
%% pentru cursuri
optiune(mihai, prolog). optiune(mihai, matematica).
optiune(vlad, arta). optiune(vlad, prolog).
optiune(anda, c). optiune(anda, lisp).
optiune(anda, pascal).
%% desfasurare(Curs,Zi) specifica restrictiile determinate de desfasurarea cursurilor
%% în anumite zile ale saptaminii
desfasurare(prolog, luni). desfasurare(prolog, vineri).
desfasurare(matematica, marti). desfasurare(matematica, vineri).
desfasurare(c, joi). desfasurare(c, vineri).
desfasurare(lisp, marti). desfasurare(pascal, joi).
desfasurare(pascal, simbata).
%% sala(Zi,Clasa) specifica restrictiile determinate de locul de desfasurare al cursurilor
sala(luni, clasa1). sala(marti, clasa1).
sala(joi, clasa1). sala(joi, clasa3).
sala(vineri, clasa2
). sala(simbata, clasa2).
%% scopuri
?- optiune(Student,Curs1), optiune(Student,Curs2),
desfasurare(Curs1,Zi1), desfasurare(Curs2,Zi2),
not(Curs1=Curs2), not(Zi1=Zi2).
?- optiune(Student,Curs), desfasurare(Curs,Zi), sala(Zi,Clasa).
5. (2) Problema admite o solutie fãrã cãutare, algoritmul urmãtor gãsînd o multime de cãsãtorii stabile. În algoritm LB reprezintã lista bãrbatilor nelogoditi, LF pe cea a femeilor nelogodite, iar LFi reprezintã lista ordonatã a preferintelor bãrbatului Bi.
Algoritm: Determinarea unei multimi de cãsãtorii stabile
CãsãtoriiStabile(LB, LF)
1. repetã
1.1. ![]()
1.2. Alege urmãtoarea femeie preferatã ![]()
1.3. Eliminã Fj din LFi
1.4. dacã Fj nu este logoditã
atunci
1.3.1. Logodeste Bi cu Fj
1.3.2. Eliminã Fj din LF
1.3.3. Eliminã Bi din LB
1.5. altfel
1.5.1. ![]()
1.4.2. dacã Fj preferã pe Bi lui Bj
atunci
i. Rupe logodna Fj - Bj
ii. Logodeste Fj cu Bi
iii. Eliminã Bi din LB
iv. Introduce Bj în LB
pînã cînd ![]()
sfîrsit.
Pentru algoritmul prezentat complexitatea timp este liniarã. Ordinea bãrbatilor si a femeilor în listele initiale LB si LF este lipsitã de importantã. Asa cum este scris, algoritmul "favorizeazã" preferintele bãrbatilor. Algoritmul poate fi scris în mod similar pentru a favoriza preferintele femeilor, între solutiile obtinute de cele douã variante putînd apare diferente.
Programul
Lisp, prezentat în continuare, implementeazã algoritmul prezentat mai sus.
Variabilele speciale *LB* si *LF* memoreazã listele bãrbatilor nelogoditi si
ale femeilor nelogodite considerate drept exemplu. Variabila LL din functia casatorii-stabile memoreazã logodnele
stabilite pînã la un moment dat, iar în final va reprezenta solutia problemei,
deci multimea de cãsãtorii stabile. Fiecare logodnã este reprezentatã printr-o
pereche cu punct ![]() . Listele de preferinte ale bãrbatilor si femeilor sînt
memorate ca valori ale proprietãtii Preferinte
a simbolurilor asociate bãrbatilor si femeilor.
. Listele de preferinte ale bãrbatilor si femeilor sînt
memorate ca valori ale proprietãtii Preferinte
a simbolurilor asociate bãrbatilor si femeilor.
(defun stabileste-preferinte (persoana lista-preferinte)
"Stabileste lista preferintelor pentru o persoana si intoarce persoana."
(setf (get persoana 'Preferinte) lista-preferinte)
persoana)
(defparameter *LB*
`(,(stabileste-preferinte 'Adrian '(Carmen Tatiana Elena Rodica Sanda))
,(stabileste-preferinte 'Bogdan '(Elena Carmen Rodica Sanda Tatiana))
,(stabileste-preferinte 'Cristi '(Carmen Rodica Tatiana Sanda Elena))
,(stabileste-preferinte 'David '(Elena Rodica Carmen Sanda Tatiana))
,(stabileste-preferinte 'Florin '(Tatiana Rodica Carmen Elena Sanda)))
"Lista barbatilor nelogoditi.")
(defparameter *LF*
`(,(stabileste-preferinte 'Elena '(Florin Adrian David Bogdan Cristi))
,(stabileste-preferinte 'Carmen '(David Florin Bogdan Adrian Cristi))
,(stabileste-preferinte 'Rodica '(Adrian David Bogdan Cristi Florin))
,(stabileste-preferinte 'Sanda '(Cristi Bogdan David Adrian Florin))
,(stabileste-preferinte 'Tatiana '(David Bogdan Cristi Florin Adrian)))
"Lista femeilor nelogodite.")
(defun logodeste (barbat femeie lista-logodne)
"Introduce o noua logodna in lista de logodne.
Intoarce noua lista a logodnelor."
(cons (cons barbat femeie) lista-logodne))
(defun rupe-logodna (barbat femeie lista-logodne)
"Elimina o logodna din lista de logodne."
(delete (cons barbat femeie) lista-logodne :test #'equal))
(defun casatorii-stabile (LB LF)
"Stabileste un set de casatorii stabile intre barbatii din
lista LB si femeile din lista LF. Intoarce lista casatoriilor."
(do ((Bi (first LB) (first LB))
LL Bj Fj)
((null LB) LL)
(setf Fj (pop (get Bi 'Preferinte))) ;; extrage prima preferinta a lui Bi
(if (member Fj LF :test #'eq)
(progn ;;Fj este nelogodita
(setf LL (logodeste Bi Fj LL))
(setf LF (delete Fj LF :test #'eq))
(pop LB))
(progn ;; Fj este logodita si
(setf Bj (first (rassoc Fj LL))) ;; Bj este logodnicul actual al lui Fj
(when (member Bj ;; Bj se afla dupã Bi in lista de
(member Bi ;; preferinte a lui Fj ?
(get Fj 'Preferinte)
:test #'eq)
:test #'eq)
(setf LL (rupe-logodna Bj Fj LL))
(setf LL (logodeste Bi Fj LL))
(pop LB)
(push Bj LB))))))
(3) Algoritmul de complexitate liniarã prezentat mai sus, gãseste o singurã solutie. Pentru generarea tuturor solutiilor problemei trebuie utilizat un algoritm general de satisfacere a restrictiilor.
6. (1) Se folosesc 25 de variabile împãrtite în 5 grupe, astfel:
1. rosu, albastru, galben, verde, ocru
2. norvegian, ucrainean, englez, spaniol, japonez
3. cafea, ceai, apã, lapte, suc de portocale
4. zebrã, cãtel, cal, vulpe, melci
5. Old Gold, Parliament, Kools, Lucky Strike, Chesterfield
Fiecare
variabilã are domeniul de valori ![]() , atribuirea unei valori variabilei reprezentînd asocierea
unui numãr de casã caracteristicii
reprezentate de variabilã. De exemplu,
, atribuirea unei valori variabilei reprezentînd asocierea
unui numãr de casã caracteristicii
reprezentate de variabilã. De exemplu, ![]() (initial) iar
(initial) iar ![]() indicã atribuirea
valorii 2 variabilei rosu si semnificã faptul cã a doua casã este rosie.
indicã atribuirea
valorii 2 variabilei rosu si semnificã faptul cã a doua casã este rosie.
Restrictiile
problemei pot fi astfel exprimate ca restrictii binare. De exemplu,
"Spaniolul are un cãtel" descrie o restrictie între variabilele spaniol si cãtel ce permite numai valorile ![]() . Aceastã restrictie are urmãtoarea semnificatie: dacã
spaniolul stã în prima casã, deci
. Aceastã restrictie are urmãtoarea semnificatie: dacã
spaniolul stã în prima casã, deci ![]() , atunci si cãtelul este în prima casã, deci
, atunci si cãtelul este în prima casã, deci ![]() , de unde apare restrictia (1,1), si analog pentru celelalte
restrictii. Astfel, fiecare conditie din problemã se traduce printr-o restrictie.
În plus, existã o restrictie între fiecare pereche de variabile din aceeasi
grupã, care împiedicã atribuirea de valori egale unor astfel de variabile.
, de unde apare restrictia (1,1), si analog pentru celelalte
restrictii. Astfel, fiecare conditie din problemã se traduce printr-o restrictie.
În plus, existã o restrictie între fiecare pereche de variabile din aceeasi
grupã, care împiedicã atribuirea de valori egale unor astfel de variabile.
Graful de restrictii este prezentat în Figura 4.26. În figurã, restrictiile între variabilele aceleiasi grupe au fost omise.

Figura 4.26 Graful de restrictii al problemei zebrei
(2) Conditia 5 va fi reprezentatã sub forma unei
restrictii binare între variabilele verde si ocru, restrictie care permite
numai valorile ![]() .
.
Conditia
8 va fi reprezentatã printr-o restrictie unarã care determinã domeniul de
valori al variabilei lapte sã continã numai valoarea 3 (![]() ).
).
Conditia
9 va fi reprezentatã tot printr-o restrictie unarã, domeniul de valori al
variabilei norvegian devenind ![]() .
.
Conditia 11 va fi reprezentatã sub forma unei restrictii binare între variabilele Kools si cal, restrictie care permite numai valorile indicate mai jos.
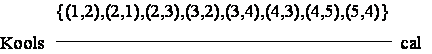
8. Functia d-arc-cons realizeazã d-arc-consistenta unui graf de restrictii. Graful este specificat prin lista ordonatã a variabilelor problemei, deci prin lista nodurilor grafului. Fiecare variabilã va memora ca valoare a proprietãtilor Nivel si Vecini pozitia variabilei în ordonare si, respectiv, variabilele cu care este legatã în graful de restrictii. Domeniul de valori al fiecãrei variabile va fi memorat ca valoare a proprietãtii Domeniu, atasatã simbolului asociat variabilei în reprezentarea problemei. Functia verifica este implementarea în Lisp a subprogramului descris în Sectiunea 4.5.2.
(defun verifica (Xj Xi)
(dolist (x (get Xj 'Domeniu))
(unless (some #'(lambda (y)
(exista-relatie-p Xi y Xj x))
(get Xi 'Domeniu))
(setf (get Xj 'Domeniu) (delete x (get Xj 'Domeniu) :test #'eq)))))
(defun d-arc-cons (Variabile)
(dolist (Xi Variabile)
(let ((i (get Xi 'Nivel)))
(do* ((vecini (get Xi 'Vecini) (rest vecini))
(Xj (first vecini) (first vecini))
(j (get Xj 'Nivel) (get Xj 'Nivel)))
((or (null vecini) (>= j i)))
(verifica Xj Xi)))))
Ordonarea variabilelor unei probleme particulare poate fi realizatã prin apelul:
(sort *VARIABILE* #'(lambda (Xi Xj) (< (get Xi 'Nivel) (get Xj 'Nivel))))
unde *VARIABILE* este o variabilã specialã, care memoreazã lista de variabile ale unei probleme particulare.
Capitolul 6
Logica actiunii si planificare automatã
Un aspect important al rationamentului de bun simt si al problemelor de planificare automatã este capacitatea de a reprezenta actiuni si de a rationa despre aceste actiuni, deci de a rationa despre schimbãri. Planificarea automatã, care implicã utilizarea actiunilor, reprezintã un domeniu intens investigat al inteligentei artificiale. Cele mai multe probleme de planificare se referã la domenii complexe, pentru care reprezentarea si prelucrarea descrierii complete a stãrilor problemei de rezolvat poate deveni foarte costisitoare. Din aceastã cauzã, de multe ori este nevoie sã se adopte o strategie de reprezentare partialã a universului problemei cît si o strategie de descompunere a problemei în subprobleme.
Rationamentul despre actiuni implicã rezolvarea celor trei probleme ale rationamentului de bun simt, mentionate în capitolul anterior: problema cadrului, problema calificãrii si problema ramificãrii. Se considerã cazul unui robot care trebuie sã execute actiunile de mutare a obiectelor dintr-o camerã. Dacã robotul mutã masa din centrul camerei lîngã fereastrã, un sistem de planificare automatã trebuie sã fie capabil sã deducã faptul cã nici covorul si nici dulapul nu si-au schimbat pozitia, chiar dacã acest lucru nu s-a spus explicit . Aceasta este problema cadrului, deci a identificãrii si inferãrii tuturor faptelor care nu s-au schimbat ca efect al executãrii unei actiuni sau a trecerii timpului. Dacã robotul trebuie sã execute actiunea de mutare a bibliotecii din camerã, el ar putea sã nu reuseascã deoarece biblioteca este prea grea, sau pentru cã ea este ancoratã în podea, sau din cauzã cã se dãrîmã casa, etc. Înregistrarea tuturor preconditiilor necesare executãrii unei actiuni este de multe ori imposibilã, aceasta fiind problema cadrului. Dacã robotul mutã dulapul dintr-un loc în altul al camerei, floarea de pe dulap va fi mutatã odatã cu dulapul, anumite portiuni de covor vor fi acoperite, s-ar putea ca fereastra sã fie blocatã, etc. Aceasta este problema ramificãrii, deoarece este imposibil sã se înregistreze toate consecintele unei actiuni. Astfel, reprezentarea completã si explicitã a tuturor stãrilor universului unei probleme de executare a actiunilor în lumea realã este foarte diferitã, de fapt imposibilã pentru situatii complexe. Tot datoritã complexitãtii problemelor de planificare, de multe ori este indicat sã se foloseascã paradigma de rezolvare a problemelor prin descompunere în subprobleme [Pearl,1988].
Tehnicile de rezolvare a problemelor prin descompunerea problemei în subprobleme sînt viabile numai în cazul problemelor pentru care subproblemele componente nu interactioneazã între ele, deci sînt independente. Altfel spus, rezolvarea unei subprobleme nu depinde de rezolvarea altor subprobleme si nici nu este afectatã de rezolvarea subproblemelor ulterioare ei. Din pãcate, pentru numeroase probleme nu existã o descompunere în subprobleme care sã satisfacã conditia anterior enuntatã, problemele rezultate din descompunere fiind interdependente. Din multimea problemelor interdependente, Herbert Simon identificã problemele aproape independente ca fiind o multime de subprobleme, provenite din descompunerea unei probleme, între care existã numai o interactiune redusã. Aceastã caracteristicã simplificã, într-o oarecare mãsurã, problema generãrii automate a planurilor, dar si în acest caz trebuie sã se tinã seama de interactiunile existente.
Din punct de vedere al întelesului obisnuit, planificarea implicã stabilirea unei secvente de actiuni pentru atingerea unui anumit scop. În cazul rezolvãrii unei probleme de planificare cu ajutorul calculatorului, distinctia între plan si actiune este mai putin evidentã, deoarece planul propus pentru a realiza un anumit scop nu este, de cele mai multe ori, aplicat pe mãsura dezvoltãrii sale. Chiar dacã problema implicã actiuni irevocabile în lumea realã, programul de planificare poate simula planul, ceea ce permite utilizarea unei strategii tentative. Succesul acestei abordãri se bazeazã pe presupunerea cã lumea realã este predictibilã. Din nefericire, acest lucru nu este întotdeauna adevãrat, deci procesul de simulare nu poate considera toate alternativele posibile.
Un aspect important al problemelor de planificare este tocmai acela cã lumea realã nu este întotdeauna predictibilã. Un plan bine alcãtuit pentru atingerea unui scop în anumite conditii poate sã nu mai functioneze la aparitia unor conditii reale diferite. Modificarea neasteptatã a contextului poate sã invalideze tot planul sau numai o parte din el. O problemã importantã este aceea a refacerii planului, pãstrînd totodatã acele pãrti din plan care rãmîn în continuare valide. Acest aspect constituie un argument în plus în favoarea necesitãtii descompunerii problemelor în subprobleme. Pe lîngã reducerea complexitãtii reprezentãrii si a procesului de rezolvare a problemelor, descompunerea problemelor în subprobleme reduce si complexitatea operatiilor de revizuire dinamicã a planului, operatii necesare pe parcursul executãrii unui plan într-o lume imprevizibilã. Operatiile de revizuire a planului se executã mai usor în cazul unor probleme independente sau aproape independente.
Asa cum se deduce si din aspectele prezentate anterior, problemele de planificare si rationament despre actiuni necesitã un proces de cãutare. De cele mai multe ori cãutarea este condusã de scopuri, deci se face pornind de la starea scop si determinînd secventele de operatori care fac trecerea de la starea initialã la starea finalã. În scopul facilitãrii operatiilor de revizuire a planului, este util sã se asocieze fiecãrei actiuni executate în cadrul unui plan motivul care a determinat aparitia actiunii în cadrul planului. Astfel, dacã într-o nouã situatie o anumitã actiune nu mai este necesarã sau valabilã, utilizînd o strategie de backtacking condus de dependente, se pot determina restul actiunilor din plan dependente de actiunea în cauzã, deci se pot identifica astfel actiunile care trebuie reconsiderate.
Metodele de generare automatã a planurilor pot fi împãrtite în douã categorii: metode de planificare liniarã si metode de planificare neliniarã. În cazul planificãrii liniare, o secventã de scopuri este rezolvatã prin satisfacerea fiecãrui subscop, pe rînd. Un plan generat de o astfel de metodã contine o secventã de actiuni care duce la satisfacerea primului subscop, apoi secventa de actiuni necesarã satisfacerii celui de-al doilea subscop, si asa mai departe.
Aceastã metodã nu poate fi utilizatã pentru rezolvarea problemelor de planificare în care subproblemele interactioneazã, asa cum se va prezenta în Sectiunile 6.3 si 6.4. În acest caz, trebuie utilizatã o metodã de planificarea neliniarã care genereazã planuri prin considerarea simultanã a mai multor subprobleme obtinute din descompunerea problemei initiale. Planul este întîi incomplet specificat si rafinat ulterior considerînd interactiunile existente. O astfel de metodã se numeste planificare neliniarã deoarece planul nu este compus dintr-o secventã liniarã de subplanuri complete. Planificarea neliniarã implementeazã o paradigmã de rezolvare a problemelor cunoscutã în inteligenta artificialã sub numele de strategia deciziilor amînate. Aceastã abordare este utilã si în cazul necesitãtii revizuirii dinamice a planului.
Primele sisteme de planificare automatã au fost: sistemul GPS [Newell,Simon,1963] si sistemul STRIPS [Fikes,Nilsson,1971], ce vor fi prezentate în Sectiunea 6.2 si, respectiv, Sectiunea 6.3. Sistemul de planificare liniarã STRIPS a fost primul program care a dat o rezolvare problemei cadrului, la nivelul implementãrii.
Sistemul de planificare independent de domeniu HACKER [Sussman,1975] a fost primul program care a considerat aspecte de planificare neliniarã si a încercat sã dea o rezolvare anomaliei lui Sussman (anomalia lui Sussman este prezentatã în Sectiunea 6.3). Primul sistem de planificare neliniarã a fost NOAH [Sacerdoti,1975] care a inclus o îmbunãtãtire a modalitãtilor de reprezentare a planurilor, un set extins de operatori de modificare a planului si care a oferit o rezolvare consistentã anomaliei lui Sussman.
Un sistem de planificare neliniarã de referintã este sistemul MOLGEN [Stefik,1981a,b], destinat planificãrii experientelor de geneticã molecularã. Sistemul MOLGEN este primul program care a utilizat propagarea restrictiilor ca o tehnicã centralã în planificare si care a introdus conceptul de planificare ierarhicã. Sistemul TWEAK [Chapman,1987], care va fi prezentat în Sectiunea 6.4, este un sistem recent de planificare neliniarã care utilizeazã de asemenea propagarea restrictiilor si, în plus, oferã o formalizare si o analizã a eficientei computationale a planificãrii automate.
Formalizarea rationamentului despre actiuni
S-au propus diverse modele de formalizare logicã a rationamentului despre actiuni. În continuare, se prezintã pe scurt un model monoton si doua modele nemonotone ale actiunilor. Cititorul trebuie sã remarce faptul cã rationamentul despre actiuni este de tip nemonoton, implicã cele trei probleme discutate anterior, deci oricare din abordãrile formale nemonotone prezentate în Capitolul 5 pot constitui punctul de plecare al formalizãrii actiunilor.
Abordarea monotonã
Prima propunere de formalizare a rationamentului despre actiuni a fost fãcutã de McCarthy [McCarthy,Hayes,1969]. În aceastã abordare, existã axiome explicite care indicã toate faptele ce rãmîn valabile dupã executarea fiecãrei actiuni. Aceste axiome sînt de douã tipuri: axiome ale actiunilor care indicã faptele care se schimbã ca efect al unei actiuni, si axiome ale cadrului care indicã faptele neafectate de executarea fiecãrei actiuni.
De exemplu, fie operatia de mutare a unui obiect executatã de un robot. Dacã obiectul x care se mutã si obiectul l peste care se va pune x sînt libere, mutarea obiectului x peste l va avea ca rezultat faptul cã x este deasupra lui l. Formal, acest lucru se exprimã astfel:
![]()
unde notatia ps
semnificã faptul cã propozitia p este adevãratã în situatia (sau la momentul de
timp) s, iar expresia ![]() se referã la situatia
(sau timpul) în care actiunea a fost
executatã.
se referã la situatia
(sau timpul) în care actiunea a fost
executatã.
Pe lîngã axiomele de acest tip, care descriu actiuni, trebuie enuntate si axiome care descriu faptele ce nu se schimbã în urma executãrii unei actiuni, deci axiomele cadrului. De exemplu, o axiomã a cadrului poate enunta faptul, prin mutarea obiectului x peste l, pozitia celorlalte obiecte nu se modifica, astfel:
![]()
Similar, trebuie adãugate axiome ale cadrului care indicã faptul cã mutarea unui obiect nu afecteazã forma sau culoarea obiectelor existente:
![]()
![]()
Abordarea monotonã pune douã mari probleme. Prima problemã este de ordin epistemologic si constã în indicarea explicitã a tuturor axiomelor cadrului. Acest lucru poate deveni foarte dificil, mai ales dacã axiomele cadrului sînt complexe. A doua problemã este complexitatea computationalã implicatã de determinarea faptelor care rãmîn adevãrate dupã executarea unei actiuni. Dacã baza de cunostinte contine un numãr mare de fapte, numãrul de deductii necesare pentru demonstrarea acestor fapte poate deveni prohibitiv de mare.
Abordarea logicii implicite
O abordare nemonotonã a descrierii actiunilor permite reprezentarea schimbãrilor prin axiome explicite care indicã ce fapte se modificã si adãugarea unei singure axiome de rationament implicit care spune cã toate celelalte fapte nu se modificã. Folosind logica implicitã a lui Reiter [1980], o formalizare posibilã este:
![]()
Aceastã axiomã exprimã faptul cã dacã propozitia p este adevãratã în situatia (la momentul de timp) s si p este în continuare consistentã dupã executarea actiunii a, se poate infera cã p este adevãratã dupã actiunea a. Deci, atît timp cît actiunea a nu a produs o consecintã care sã infirme p, propozitia p poate fi consideratã adevãratã.
Abordarea implicitã nu prezintã dificultãtile epistemologice ale celei monotone, dar ridicã în continuare problema complexitãtii computationale. Pentru a determina faptele adevãrate dupã executarea unei actiuni, axioma cadrului descrisã mai sus trebuie aplicatã pentru fiecare fapt de interes.
Abordarea lumilor posibile
Modelul lumilor posibile poate fi utilizat în formalizarea rationamentului despre actiuni, asa cum aratã Ginsberg si Smith [1988]. În aceastã abordare, rezultatul unei actiuni reprezintã lumea nouã cea mai apropiatã de lumea curentã, în care rezultatele actiunii sînt consistente. De exemplu, dacã un robot mutã dulapul dintr-un loc în altul al camerei, rezultatul acestei actiuni este cea mai apropiatã lume de cea curentã, în care dulapul este în noua pozitie. În aceastã lume nouã, dulapul nu va mai fi în vechea pozitie, tot ce se aflã în dulap si deasupra lui va fi în noua pozitie si, în plus, fereastra sau tabloul din camerã pot fi blocate de dulap.
În formalizarea actiunilor prin lumi posibile, se identificã o serie de fapte si axiome care se numesc restrictii ale domeniului sau propozitii protejate, si despre care se stie cã nu pot fi modificate de nici o actiune. Se defineste o lume partialã ca fiind orice colectie consistentã de fapte si axiome care descrie domeniul problemei, o parte din elementele acestei lumi fiind specificate ca protejate.
Se presupune cã lumea partialã S descrie situatia curentã si
cã se doreste adãugarea multimii de fapte C la aceastã lume. În modelul general
al lumilor posibile, adãugarea de fapte la o lume curentã nu revine la
considerarea multimii ![]() deoarece C poate fi
inconsistentã cu S. Pentru a rezolva aceastã problemã, se considerã submultimi
ale multimii
deoarece C poate fi
inconsistentã cu S. Pentru a rezolva aceastã problemã, se considerã submultimi
ale multimii ![]() . În aceste submultimi existã restrictiile domeniului care nu
pot fi eliminate. Un exemplu de astfel de elemente protejate este axioma
. În aceste submultimi existã restrictiile domeniului care nu
pot fi eliminate. Un exemplu de astfel de elemente protejate este axioma ![]() care indicã faptul cã
un obiect poate fi într-un singur loc la un anumit moment.
care indicã faptul cã
un obiect poate fi într-un singur loc la un anumit moment.
Definitie. Fiind datã o multime
de formule logice S, o multime de elemente protejate (restrictii ale
domeniului) ![]() si o multime de
formule suplimentare C, o lume potentialã
pentru C în S se defineste ca fiind orice submultime
si o multime de
formule suplimentare C, o lume potentialã
pentru C în S se defineste ca fiind orice submultime ![]() astfel încît:
astfel încît:
(1) ![]() . T contine formulele din C care trebuie explicit adãugate
pentru a construi noua lume.
. T contine formulele din C care trebuie explicit adãugate
pentru a construi noua lume.
(2) ![]() . Orice element protejat din S este pãstrat în noua lume.
. Orice element protejat din S este pãstrat în noua lume.
(3) T este consistentã.
Se observã cã "apropierea" unei lumi potentiale
pentru C în S de lumea initialã S este reflectatã de cardinalitatea multimii T.
Astfel, dacã T si T sînt lumi potentiale pentru C în S, si ![]() , T este
cel putin la fel de aproape de S ca si T .
Aceastã observatie conduce la definitia notiunii de cea mai apropiatã lume
potentialã sau a lumii posibile pentru C în S.
, T este
cel putin la fel de aproape de S ca si T .
Aceastã observatie conduce la definitia notiunii de cea mai apropiatã lume
potentialã sau a lumii posibile pentru C în S.
Definitie. Fie o multime de formule logice S, o multime
de elemente protejate ![]() si o multime de
formule suplimentare C. O lume posibilã
pentru C în S se defineste ca fiind multimea
si o multime de
formule suplimentare C. O lume posibilã
pentru C în S se defineste ca fiind multimea ![]() astfel încît:
astfel încît:
(1) ![]() ,
,
(2) ![]() ,
,
(3) T este consistentã,
(4) T este maximalã din punct de vedere al restrictiilor (1)(3).
Se noteazã cu L(C,S) multimea de lumi posibile pentru C în S.
Plecînd de la aceste notiuni, Ginsberg si Smith formalizeazã
actiunile dupã cum urmeazã. Fie o descriere a universului initial al problemei
S, împreunã cu o multime de actiuni A. Fiecare actiune ![]() este definitã printr-o
multime de preconditii p(a) si o multime de consecinte C(a). Preconditiile
trebuie sã fie adevãrate pentru a putea executa actiunea si rezultatul actiunii
este adãugarea faptelor din C(a) la descrierea lumii curente. Dacã p(a) ar
specifica toate preconditiile necesare actiunii, deci ar fi completã, ar
dispare problema calificãrii. Dacã C(a) ar fi completã, ar dispare problema
ramificãrii.
este definitã printr-o
multime de preconditii p(a) si o multime de consecinte C(a). Preconditiile
trebuie sã fie adevãrate pentru a putea executa actiunea si rezultatul actiunii
este adãugarea faptelor din C(a) la descrierea lumii curente. Dacã p(a) ar
specifica toate preconditiile necesare actiunii, deci ar fi completã, ar
dispare problema calificãrii. Dacã C(a) ar fi completã, ar dispare problema
ramificãrii.
Fiind datã descrierea lumii S si o actiune a, se doreste
definirea rezultatului actiunii a ca fiind lumea nouã obtinutã prin adãugarea
consecintelor actiunii la lumea curentã. Dificultatea constã în faptul cã lumea
rezultatã poate fi inconsistentã. Se defineste rezultatul unei actiuni a, executatã în lumea S, cu consecintele
C(a), ca fiind intersectia tuturor lumilor posibile pentru C(a) în S, si se
noteazã aceastã multime cu ![]() . Dacã
. Dacã ![]() , atunci se considerã cã
, atunci se considerã cã ![]() . Definitia efectului unei actiuni în termenii modelului
lumilor posibile se poate extinde la definitia rezultatului unei secvente de actiuni
. Definitia efectului unei actiuni în termenii modelului
lumilor posibile se poate extinde la definitia rezultatului unei secvente de actiuni ![]() .
.
![]()
![]()
Autorii formalismului descris propun algoritmi pentru generarea lumilor posibile si pentru selectia celei mai apropiate lumi posibile. Din nefericire, selectia celei mai apropiate lumi posibile nu poate fi fãcutã întotdeauna deoarece sînt cazuri în care nu existã o relatie de incluziune între lumile posibile generate. Constructia formalã propusã nu poate selecta o lume între astfel de lumi si trebuie sã se recurgã la cunostinte specifice domeniului pentru a lua o decizie. În sectiunile care urmeazã se vor prezenta solutii computationale ale rationamentului despre actiuni care încearcã sã rezolve eficient o parte din problemele apãrute în modelele formale.
Sistemul General Problem Solver
Unul dintre primele sisteme de planificare propuse a fost sistemul General Problem Solver, pe scurt GPS, dezvoltat la sfîrsitul anilor '50 de Alan Newell si Herbert Simon [1963]. Strategia de rezolvare a problemelor utilizatã în GPS este analiza bazatã pe modalitãti. Ideea de bazã a acestei strategii, enuntatã întîia oarã de Aristotel, este urmãtoarea: la rezolvarea unei anumite probleme, se presupune scopul atins, i.e. problema rezolvatã, si se analizeazã cum, prin aceasta întelegîndu-se prin ce mijloace, se poate realiza acest deziderat. Dacã se constatã cã existã mai multe mijloace de realizare, se va considera acel mijloc care rezolvã problema cel mai usor si în acelasi timp cel mai bine. Dacã, dimpotrivã, se constatã cã existã un singur mijloc de rezolvare a problemei, se considerã acel mijloc, si analiza se concentreazã asupra modalitãtilor de realizare a acestuia. Cu alte cuvinte, problema initialã s-a descompus (transformat) într-o nouã problemã. Procesul de descompunere continuã pînã cînd problema rezultatã în urma unei descompuneri nu mai poate fi redusã printr-o nouã descompunere, fie datoritã faptului cã este suficient de simplã pentru a nu mai constitui o problemã, fie datoritã inexistentei unor mijloace de reducere. În acest din urmã caz, rezolvarea problemei esueazã. Aristotel a conjecturat cã acesta este chiar modelul de analizã aplicat de oameni în subconstient.
Newell si Simon au descris acest mod de analizã folosind notiunea de eliminare a diferentelor. Ei au identificat problema cu multimea diferentelor existente între starea scop si starea initialã a problemei si rezolvarea problemei cu reducerea acestor diferente pînã la eliminarea lor, efectuînd pentru aceasta numai transformãri (actiuni) posibile în universul problemei. Transformãrile sînt asociate cu o multime de preconditii care trebuie sã fie îndeplinite într-o stare pentru a putea aplica transformarea în starea respectivã. Ca efect al transformãrii, starea problemei se modificã în conformitate cu o multime de efecte asociate transformãrii. Asocierea unei transformãri cu preconditiile si efectele sale formeazã un operator. Operatorii sînt specificati de cãtre proiectantul problemei.
În viziunea celor doi autori, rezolvarea unei probleme utilizînd analiza bazatã pe modalitãti constã în detectarea repetatã a diferentelor între starea curentã si starea scop, apoi selectarea unui operator care poate fi aplicat pentru a reduce aceastã diferentã. În cazul în care operatorul nu poate fi aplicat în starea curentã, se creazã subscopul prin care trebuie sã se ajungã din starea curentã în starea în care operatorul selectat poate fi aplicat. Dar este posibil ca operatorul selectat, desi a redus o parte din diferentele dintre starea curentã si starea scop, sã nu producã chiar starea scop doritã. Apare în acest fel un nou subscop, acela de a ajunge din starea produsã de operator în starea scop. Dacã operatorul este bine ales, rezolvarea celor douã subprobleme, corespunzatoare celor douã scopuri, poate fi mai usoarã decît rezolvarea problemei initiale. Deci, o problemã poate fi rezolvatã fie aplicînd direct un operator adecvat, fie rezolvînd mai întîi subproblemele ridicate de îndeplinirea preconditiilor operatorului adecvat si executînd apoi actiunea asociatã lui.
Procesul de analizã bazatã pe modalitãti poate fi aplicat împreunã cu criterii euristice care fac ca strategia sã se concentreze mai întîi pe eliminarea diferentelor mai importante dintre starea scop si starea curentã. Pentru aceasta se pot asocia nivele de prioritate diferentelor, diferentele cu prioritate mai mare fiind considerate pentru a fi eliminate mai întîi.
Asa cum s-a aratat, operatorii de eliminare a diferentelor sînt operatori de transformare a unei stãri într-o altã stare si includ preconditiile pe care trebuie sã le satisfacã o stare pentru ca un operator sã fie aplicabil în acea stare. O dezvoltare ulterioarã a sistemelor de planificare a abandonat ideea reprezentãrii integrale a stãrii, formulînd operatorii de eliminare a diferentelor sub forma unor reguli în care partea stîngã specificã preconditiile operatorului, iar partea dreaptã indicã efectul aplicãrii operatorului asupra stãrii curente numai în termenii modificãrii acesteia. Aceastã dezvoltare va fi prezentatã în Sectiunea 6.3. Motivele acestei evolutii în reprezentarea operatorilor au fost prezentate la începutul acestui capitol.
Sistemul GPS foloseste o structurã de date suplimentarã,
numitã tabela de diferente, pentru a
indexa operatorii dupã diferentele care pot fi reduse prin aplicarea lor. Se
considerã în continuare exemplul robotului Robo care foloseste analiza bazatã
pe modalitãti pentru a dezvolta un plan de cãlãtorie între localitãtile Paris si
Bucuresti. Existã mai multe posibilitãti de a cãlãtori între cele douã orase si
Robo trebuie sã selecteze o posibilitate. Operatorii pe care Robo îi are la
dispozitie sînt: ![]() ,
, ![]() ,
, ![]() ,
, ![]() si
si ![]() , cu preconditiile si efectele specificate în continuare.
, cu preconditiile si efectele specificate în continuare.
Operator Preconditii Efect
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Tabela de diferente asociatã problemei este prezentatã în Figura 6.1.
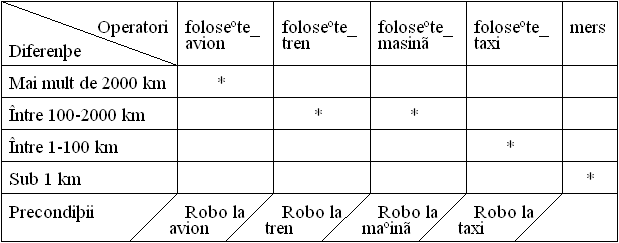
Figura 6.1 Tabela de diferente pentru problema planului de cãlãtorie
Pentru a ajunge de la Paris la Bucuresti, distanta initialã este mai mare de 2000 km, deci operatorul selectat este foloseste_avion. Pentru a folosi avionul, Robo trebuie sã fie la avion. Distanta dintre Robo si Orly, presupunînd cã Robo se aflã în centrul Parisului, este între 1-100 km, deci Robo la avion este un subscop ce poate fi atins dacã se aplicã operatorul de reducere a distantei foloseste_taxi. Pentru a folosi taxiul, Robo trebuie sã fie la taxi, si cum cea mai apropiatã statie de taxiuri este la o distantã mai micã de 1 km, Robo poate merge. Acest subscop nu necesitã nici o conditie initialã, deci acest subscop poate fi realizat imediat. Acelasi rationament se poate aplica si în cazul ajungerii la Otopeni, deci pentru starea rezultatã prin aplicarea operatorului selectat initial, si pentru a reduce diferentele si a ajunge în centrul Bucurestiului. Procesul descris poate fi reprezentat, în linii generale, de urmãtorul algoritm:
Algoritm: Analizã bazatã pe modalitãti
MEA ![]()
1. dacã ![]()
atunci
1.1. ![]()
1.2. întoarce SUCCES
2. Selecteazã cea mai importantã diferentã D între Stare si Scop
3. ![]()
4. repetã
4.1. dacã nu mai existã nici un operator neaplicat diferentei D
atunci ![]()
4.2. altfel
4.2.1. Selecteazã un operator potrivit O pentru a reduce diferenta D
4.2.2. Genereazã descrierile a douã stãri O_START si O_REZULTAT
4.2.3. dacã MEA
![]() si
si
MEA
![]()
atunci
i. ![]()
ii. repetã de la 1
pînã ![]()
5. întoarce INSUCCES
sfîrsit.
Observatii:
O-START este o stare în care preconditiile operatorului O sînt satisfãcute, iar O-REZULTAT este starea care rezultã din aplicarea operatorului O stãrii O-START.
Ordinea de selectie a diferentelor poate afecta drastic performantele rezolvãrii problemei. Dacã diferentele semnificative nu sînt selectate înaintea celor nesemnificative, se poate investi un efort considerabil pentru realizarea unor subscopuri care s-ar fi realizat deja prin atingerea scopului principal.
Acest mod de abordare a problemelor nu este potrivit pentru rezolvarea problemelor complexe deoarece, pe de o parte, eliminarea unei diferente poate influenta planul stabilit pentru eliminarea altei diferente si, pe de altã parte, tabela de diferente poate avea dimensiuni considerabile în cazul aplicatiilor complexe.
6.3 Planificare liniarã în sistemul STRIPS
Sistemul GPS, desi abandonat de multe vreme, a avut un rol important în dezvoltarea ulterioarã a sistemelor de planificare automatã. Unul dintre sistemele care a evoluat din sistemul GPS, sistemul STRIPS (STanford Research Institute Problem Solver) [Fikes,Nilsson,1971] încearcã sã rezolve o parte din limitãrile existente în GPS.
6.3.1 Functionarea sistemului STRIPS
Reprezentarea actiunilor si construirea planului în sistemul STRIPS [Fikes,Nilsson,1971] pleacã de la presupunerea cã domeniul problemei de rezolvat nu se schimbã semnificativ prin executarea unei actiuni. Din acest motiv, în sistemul STRIPS se reprezintã un model unic al universului problemei, care este permanent actualizat pentru a reflecta rezultatul actiunilor executate. Starea curentã a universului problemei este descrisã printr-o multime de formule bine formate în logica cu predicate de ordinul I. În plus se pot indica axiome specifice domeniului. Actiunile sînt descrise în sistem prin operatori de plan care nu mai specificã integral starea curentã în care un operator poate fi aplicat, si starea rezultatã prin aplicarea operatorului. Descrierea unei actiuni se face specificînd conditiile în care aceastã actiune poate fi efectuatã si schimbãrile survenite în starea problemei ca urmare a executãrii actiunii. Schimbãrile generate de efectuarea actiunii pot fi vãzute ca fiind formate din douã multimi: o multime de formule ce descriu noua stare a problemei, formule care devin adevãrate în urma executãrii actiunii, si o multime de formule care devin false în urma executãrii actiunii. În consecintã, fiecare operator este definit de urmãtoarele elemente:
Actiune care reprezintã actiunea asociatã operatorului.
Lista Preconditiilor ce contine formulele care trebuie sã fie adevãrate într-o stare a problemei pentru ca operatorul sã poatã fi aplicat, notatã în continuare cu LP.
Lista Adãugãrilor ce contine formulele care vor deveni adevãrate dupã aplicarea operatorului, notatã în continuare cu LA.
Lista Eliminãrilor ce contine formulele care vor deveni false dupã aplicarea operatorului, notatã în continuare cu LE.
Se observã cã sistemul STRIPS a preluat de la predecesorul sau ideea de a atasa unei actiuni o multime de preconditii. Acest fapt a fost posibil datoritã pãstrãrii analizei bazate pe modalitãti ca strategie de rezolvare a problemelor. Dar, în loc de a reprezenta rezultatul actiunii prin descrierea integralã a noii stãri, sistemul STRIPS reprezintã numai modificãrile aduse de actiune stãrii curente. Acest lucru permite, pe de o parte, simplificarea descrierii si, pe de altã parte, rezolvarea problemei cadrului. Orice predicat (element al stãrii curente) care nu apare explicit în Lista Adãugãrilor sau în Lista Eliminãrilor unei actiuni, este automat considerat ca fiind nemodificat de executarea acelei actiuni.
Se considerã urmãtorul exemplu în lumea blocurilor, considerat un exemplu clasic în inteligenta artificialã. Existã o suprafatã planã, numitã masã, pe care pot fi plasate cuburi si un numãr de astfel de cuburi, de aceeasi dimensiune, asezate pe masã. Problema cere sã se genereze un plan de transformare a unei configuratii initiale date într-o configuratie finalã, stiind cã existã urmãtoarele conditii:
(1) cuburile pot fi asezate unul peste celalalt cu ajutorul bratului unui robot care este folosit pentru a muta cuburile;
(2) bratul robotului nu poate tine decît un singur bloc la un moment dat.
Actiunile care pot fi executate de bratul robotului sînt:
![]() reprezintã actiunea de apucare a blocului A aflat deasupra
blocului B. Pentru a executa actiunea, bratul robotului trebuie sã fie liber si
deasupra blocului A nu trebuie sã se afle alte blocuri.
reprezintã actiunea de apucare a blocului A aflat deasupra
blocului B. Pentru a executa actiunea, bratul robotului trebuie sã fie liber si
deasupra blocului A nu trebuie sã se afle alte blocuri.
![]() reprezintã actiunea de plasare a blocului A deasupra
blocului B. Pentru a executa actiunea, bratul robotului trebuie deja sã tinã
blocul A iar deasupra blocului B nu trebuie sã se afle alte blocuri.
reprezintã actiunea de plasare a blocului A deasupra
blocului B. Pentru a executa actiunea, bratul robotului trebuie deja sã tinã
blocul A iar deasupra blocului B nu trebuie sã se afle alte blocuri.
![]() reprezintã actiunea de apucare a blocului A asezat pe masã. Pentru a executa actiunea, bratul
robotului trebuie sã fie liber, blocul A trebuie sã fie asezat pe masã si
deasupra blocului A nu trebuie sã se gãseascã alte blocuri.
reprezintã actiunea de apucare a blocului A asezat pe masã. Pentru a executa actiunea, bratul
robotului trebuie sã fie liber, blocul A trebuie sã fie asezat pe masã si
deasupra blocului A nu trebuie sã se gãseascã alte blocuri.
![]() reprezintã actiunea de asezare a blocului A pe masã. Pentru
a executa actiunea, bratul robotului trebuie sã tinã blocul A.
reprezintã actiunea de asezare a blocului A pe masã. Pentru
a executa actiunea, bratul robotului trebuie sã tinã blocul A.
Pentru a specifica conditiile în care un operator se poate executa cît si rezultatul executãrii acestei actiuni, se definesc urmãtoarele predicate:
![]() este adevãrat dacã blocul A se aflã peste blocul B.
este adevãrat dacã blocul A se aflã peste blocul B.
![]() este adevãrat dacã blocul A este asezat pe masã.
este adevãrat dacã blocul A este asezat pe masã.
![]() este adevãrat dacã nu existã nici un bloc asezat deasupra
blocului A.
este adevãrat dacã nu existã nici un bloc asezat deasupra
blocului A.
![]() este adevãrat dacã bratul robotului tine blocul A.
este adevãrat dacã bratul robotului tine blocul A.
ARMEMPTY este adevãrat dacã bratul robotului este liber.
În plus, se specificã axiomele domeniului, deci asertiuni logice adevãrate în aceastã lume a blocurilor, cum ar fi:
![]()
![]()
![]()
Cititorul este îndemnat sã indice o exprimare în limbaj natural a acestor asertiuni. Axiomele domeniului, care nu se modificã prin executarea actiunilor, sînt indicate de proiectant.
Pentru exemplul prezentat, lista operatorilor din sistemul STRIPS este urmãtoarea:
![]() LP:
LP: ![]()
LE: CLEAR(y)HOLD(x)
LA: ON(x,y)ARMEMPTY
![]() LP:
LP: ![]()
LE: ![]()
LA: ![]()
PICKUP(x) LP: ![]()
LE: ![]()
LA: ![]()
PUTDOWN (x) LP: ![]()
LE: ![]()
LA: ![]()
Se observã cã, pentru actiuni simple, Lista Preconditiilor
este de multe ori identicã cu Lista Eliminãrilor, însã preconditiile nu sînt
eliminate întotdeauna. De exemplu, pentru ca bratul robotului sã tinã un bloc (![]() ), blocul nu trebuie sã aibã un alt bloc deasupra lui. Dupã
ce bratul robotului apucã blocul, acesta continuã sã nu aibã nici un alt bloc
deasupra lui.
), blocul nu trebuie sã aibã un alt bloc deasupra lui. Dupã
ce bratul robotului apucã blocul, acesta continuã sã nu aibã nici un alt bloc
deasupra lui.
În Figura 6.2 se prezintã schematic, pentru o instantã a problemei specificatã anterior, tranzitia din starea initialã Si în starea finalã Sf, prin starea intermediarã S în care blocul B este liber si se aflã pe masã, iar blocul A este tinut de bratul robotului. În figurã sînt reprezentate si descrierile celor trei stãri si actiunile efectuate pentru a trece dintr-o stare în alta.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
ARMEMPTY
Figura 6.2 Reprezentarea stãrilor si actiunilor în lumea blocurilor
Sinteza planului în sistemul STRIPS se face în urmãtorul mod: se considerã descrierea stãrii finale, se inspecteazã asertiunile din starea finalã care nu existã în starea initialã si se selecteazã operatorii (actiunile) ale cãror Liste de Adãugãri contin asertiunile de interes din starea finalã. Pentru a putea aplica un astfel de operator, formulele din Lista Preconditiilor operatorului trebuie sã fie adevãrate în starea curentã. Sistemul verificã validitatea preconditiilor cu ajutorul unui demonstrator de teoreme, utilizînd faptele din starea curentã si axiomele domeniului. Preconditiile care nu sînt îndeplinite devin, la rîndul lor, asertiuni care trebuie satisfãcute pentru a putea aplica operatorii. Dacã toate preconditiile sînt adevãrate, operatorul poate fi aplicat. Înaintea aplicãrii operatorului, variabilele acestuia sînt instantiate, dacã este cazul, folosind substitutiile efectuate în timpul demonstrãrii preconditiilor operatorului. Aplicarea unui operator eliminã din starea curentã formulele care identificã cu o formulã din Lista Eliminãrilor si adaugã formulele din Lista Adãugãrilor, obtinînd astfel o nouã stare. Procesul continuã în acest fel pînã la gãsirea unei secvente de operatori care pot transforma descrierea stãrii initiale în descrierea stãrii finale. Aceastã secventã de operatori (actiuni) constituie planul sintetizat de sistemul STRIPS.
Un astfel de proces de rezolvare a problemei implicã,
evident, un proces de cãutare. Realizarea preconditiilor unei operatii stabileste
lista de scopuri care trebuie îndeplinite iar un anumit scop poate fi
îndeplinit în mai multe moduri. Deoarece pot exista cãi de cãutare care conduc la esec, apare necesitatea unei
cãutãri cu reveniri. Revenirea la o stare anterioarã, dintr-o stare curentã obtinutã
pe baza modificãrilor din Lista Adãugãrilor si Lista Eliminãrilor, se face prin
adãugarea la starea curentã a elementelor din Lista Eliminãrilor si eliminarea
din starea curentã a elementelor din Lista Adãugãrilor. Pentru ca acest lucru
sã fie posibil, este necesar sã se memoreze actiunea (operatorul) aplicatã si
obiectele asupra cãreia s-a aplicat aceastã actiune pentru fiecare stare obtinutã
pe parcursul cãutãrii. În exemplul din Figura 6.2, pentru a reveni din starea
finalã Sf în starea initialã Si, trebuie întîi eliminate efectele actiunii
![]() , apoi efectele actiunii
, apoi efectele actiunii ![]() . Cresterea eficientei procesului de revenire poate fi
realizatã prin adãugarea unui sistem de mentinere a consistentei datelor.
Diverse versiuni de planificatoare care au evoluat din sistemul STRIPS au
folosit aceastã facilitate.
. Cresterea eficientei procesului de revenire poate fi
realizatã prin adãugarea unui sistem de mentinere a consistentei datelor.
Diverse versiuni de planificatoare care au evoluat din sistemul STRIPS au
folosit aceastã facilitate.
Utilizarea tehnicii prezentate poate pune mai multe probleme. Prima problemã este aceea a aparitiei unui ciclu în satisfacerea scopurilor. De exemplu, pentru satisfacerea scopului SC este necesarã realizarea preconditiei SC , pentru satisfacerea scopului SC este necesarã realizarea preconditiei SC , iar pentru realizarea scopului SC este necesarã realizarea preconditiei SC . În termenii unui proces de cãutare, aceastã situatie este echivalentã cu generarea unui spatiu de cãutare de tip graf, cu cicluri.
A doua problemã care poate apare
este problema generatã de interactiunea între scopuri. Dacã se doreste
realizarea unei liste de scopuri ![]() si, dupã realizarea
scopurilor S si S , la realizarea scopului S se produce invalidarea scopului S , sistemul nu va putea sã satisfacã
conjunctia de scopuri
si, dupã realizarea
scopurilor S si S , la realizarea scopului S se produce invalidarea scopului S , sistemul nu va putea sã satisfacã
conjunctia de scopuri ![]() . În acest caz, se spune cã existã o interactiune a
scopurilor S si S pe calea
. În acest caz, se spune cã existã o interactiune a
scopurilor S si S pe calea ![]() . Existã diverse posibilitãti de a trata aceastã problemã.
Fie, dacã este posibil, se reordoneazã scopurile astfel încît interactiunea sã
nu mai aparã, fie se încearcã gãsirea unei alte solutii în speranta cã, pentru
noile planuri, scopul S nu va
mai fi invalidat, fie se încearcã satisfacerea scopului S , în conditiile în care se stie cã
scopurile S si S sînt satisfãcute. În anumite situatii,
nici una din aceste variante nu este realizabilã. În plus, dacã programul functioneazã
în timp real, un scop care a fost satisfãcut nu mai poate fi resatisfãcut sau,
pentru alte cazuri, efectul actiunilor efectuate nu mai poate fi anulat. Un
plan ce contine o actiune de tipul "dinamiteazã usa" nu mai poate fi
modificat dacã usa a fost efectiv aruncatã în aer. Alternativ, dacã într-o
secventã de scopuri
. Existã diverse posibilitãti de a trata aceastã problemã.
Fie, dacã este posibil, se reordoneazã scopurile astfel încît interactiunea sã
nu mai aparã, fie se încearcã gãsirea unei alte solutii în speranta cã, pentru
noile planuri, scopul S nu va
mai fi invalidat, fie se încearcã satisfacerea scopului S , în conditiile în care se stie cã
scopurile S si S sînt satisfãcute. În anumite situatii,
nici una din aceste variante nu este realizabilã. În plus, dacã programul functioneazã
în timp real, un scop care a fost satisfãcut nu mai poate fi resatisfãcut sau,
pentru alte cazuri, efectul actiunilor efectuate nu mai poate fi anulat. Un
plan ce contine o actiune de tipul "dinamiteazã usa" nu mai poate fi
modificat dacã usa a fost efectiv aruncatã în aer. Alternativ, dacã într-o
secventã de scopuri
S : Intrã în casã.
S : Mentine integritatea usii.
scopul S poate fi satisfãcut alternativ prin satisfacerea fie a subscopului S , fie a lui S :
S : Descuie usa.
S : Dinamiteazã usa.
dacã subscopul S esueazã si se executã subscopul S , atunci scopul S nu mai poate fi satisfãcut.
O solutie partialã a problemelor enuntate a fost propusã în sistemul STRIPS prin utilizarea unei stive de scopuri si operatori. Aceastã stivã poate fi asimilatã cu lista de tip FRONTIERA folositã în tehnicile de cãutare. Programul foloseste urmãtoarele structuri de date:
lista operatorilor, fiecare operator avînd asociate cele trei liste: de preconditii, adãugãri si eliminãri;
descrierea stãrii curente a universului problemei;
stiva de scopuri si operatori propusi pentru satisfacerea acestor scopuri;
lista scopurilor nesatisfãcute pe calea curentã.
Se considerã din nou exemplul lumii blocurilor si urmãtoarea instantã a problemei de planificare în aceastã lume: se cere gãsirea unui plan de actiuni pentru a ajunge din starea initialã Si în starea finalã Sf, descrierile acestor stãri fiind indicate în Figura 6.3, iar operatorii posibili fiind cei specificati anterior.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
ARMEMPTY
Figura 6.3 O problemã de planificare în lumea blocurilor
În continuare, se va utiliza prescurtarea OTAD pentru conjunctia de scopuri ONTABLE(A)ONTABLE(D), deoarece aceste scopuri ale stãrii finale sînt deja îndeplinite în starea initialã. În functie de ordinea de satisfacere a scopurilor, din starea initialã se pot crea douã stive de scopuri:
Stiva 1 Stiva 2
![]()
![]()
![]()
![]()
![]()
![]()
Se presupune cã se începe cu investigarea alternativei Stiva 1 (alternativa Stiva 2 va gãsi mai repede solutia, dar nu pune în evidentã problemele mentionate anterior). Sistemul STRIPS va executa pasii urmãtori.
1. Se încearcã satisfacerea
scopului ![]() . Operatorul potrivit este
. Operatorul potrivit este ![]() . Acest operator înlocuieste scopul
. Acest operator înlocuieste scopul ![]() în stivã, deoarece
dacã se aplicã acest operator, rezultatul lui va fi sigur
în stivã, deoarece
dacã se aplicã acest operator, rezultatul lui va fi sigur ![]() , deci satisfacerea scopului dorit. Continutul stivei devine:
, deci satisfacerea scopului dorit. Continutul stivei devine:
![]() /*
pentru realizarea scopului
/*
pentru realizarea scopului ![]() */
*/
![]()
![]()
2. Pentru a putea aplica
operatorul ![]() trebuie îndeplinite
preconditiile lui, acestea devenind la rîndul lor scopuri si întroducîndu-se în
stivã:
trebuie îndeplinite
preconditiile lui, acestea devenind la rîndul lor scopuri si întroducîndu-se în
stivã:
![]() /*
preconditiile operatorului
/*
preconditiile operatorului ![]() */
*/
![]()
![]()
![]()
![]()
![]()
Ordinea de introducere
a scopurilor în stivã este importantã. Se pot aplica diverse euristici pentru a
ordona aceste scopuri. În cazul de fatã, a fost aplicatã euristica conform
cãreia, pentru a putea executa alte actiuni, robotul trebuie sã aibã bratul
liber, deci este bine ca scopul ![]() sã fie lãsat ultimul.
sã fie lãsat ultimul.
3. Se verificã scopul ![]() . Acest scop nu este satisfãcut în starea Si datoritã axiomei
. Acest scop nu este satisfãcut în starea Si datoritã axiomei
![]()
Se încearcã
satisfacerea scopului prin aplicarea operatorului ![]() , care va înlocui scopul
, care va înlocui scopul ![]() în stivã. Stiva
rezultatã este:
în stivã. Stiva
rezultatã este:
![]()
![]()
ARMEMPTY
![]()
![]()
![]()
![]()
![]()
![]()
![]()
4. Scopul
![]() este satisfãcut de
starea initialã si se eliminã din stivã. La fel scopurile
este satisfãcut de
starea initialã si se eliminã din stivã. La fel scopurile ![]() si ARMEMPTY. Se face
reverificarea preconditiilor pentru operatia
si ARMEMPTY. Se face
reverificarea preconditiilor pentru operatia ![]() , pentru a evita situatia în care satisfacerea unui scop ar
fi invalidat un alt scop. Conjunctia de scopuri
, pentru a evita situatia în care satisfacerea unui scop ar
fi invalidat un alt scop. Conjunctia de scopuri ![]() este satisfãcutã, deci
se eliminã din stivã. În aceste conditii se poate aplica operatorul
este satisfãcutã, deci
se eliminã din stivã. În aceste conditii se poate aplica operatorul ![]() si se modificã starea
curentã Si, obtinîndu-se noua
stare S si planul indicat în
continuare.
si se modificã starea
curentã Si, obtinîndu-se noua
stare S si planul indicat în
continuare.
![]()
![]()
Stiva devine:
![]()
![]()
![]()
![]()
![]()
Pentru a putea realiza ![]() , se pot aplica doi operatori:
, se pot aplica doi operatori: ![]() si
si ![]() , deci existã douã ramuri alternative ale arborelui de
cãutare. Dacã s-ar urmãri alternativa
, deci existã douã ramuri alternative ale arborelui de
cãutare. Dacã s-ar urmãri alternativa ![]() atunci rezultatul ar
fi:
atunci rezultatul ar
fi:
![]()
![]()
![]()
![]()
![]()
ARMEMPTY
![]()
![]() /*
satisface
/*
satisface ![]() */
*/
![]()
![]()
![]()
![]()
Se observã cã apare o
satisfacere circularã a scopurilor, în acest caz a scopului ![]() , deci aceastã cale trebuie abandonatã.
, deci aceastã cale trebuie abandonatã.
6. Se alege deci prima alternativã, iar stiva devine:
![]()
![]()
ARMEMPTY
![]()
![]() /*
satisface
/*
satisface ![]() */
*/
![]()
![]()
![]()
![]() .
.
7. În starea S , scopurile ![]() si
si ![]() sînt adevãrate dar
ARMEMPTY nu este adevãrat datoritã axiomei
sînt adevãrate dar
ARMEMPTY nu este adevãrat datoritã axiomei
![]()
Pentru a satisface
scopul ARMEMPTY, existã doi operatori posibili: ![]() si
si ![]() . Aplicînd o euristicã de alegere, de exemplu euristica
distantei fatã de scopul initial, se va alege
. Aplicînd o euristicã de alegere, de exemplu euristica
distantei fatã de scopul initial, se va alege ![]() . Se pot alege si alte instantieri pentru x si y, dar
preconditia
. Se pot alege si alte instantieri pentru x si y, dar
preconditia ![]() a scopului
a scopului ![]() este satisfãcutã numai
pentru
este satisfãcutã numai
pentru ![]() , iar instanta
, iar instanta ![]() este cea mai aproape
de scopul initial. Stiva devine:
este cea mai aproape
de scopul initial. Stiva devine:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Preconditiile
operatorului ![]() sînt îndeplinite în
starea S , deci operatorul
poate fi aplicat si se face tranzitia în starea S .
sînt îndeplinite în
starea S , deci operatorul
poate fi aplicat si se face tranzitia în starea S .
![]()
![]()
Procesul continuã si se descoperã starea finalã S si planul care conduce în aceastã stare:
![]()
![]()
Ce se întîmplã însã în cazul în care se aplicã aceastã metodã pentru rezolvarea urmãtoarei probleme, cunoscutã si sub numele de "anomalia lui Sussman" [Sussman,1975]. Fie o altã instantã a problemei de planificare în lumea blocurilor, descrisã anterior, în care starea initialã si starea finalã sînt cele prezentate în Figura 6.4.

![]()
![]()
![]()
![]()
![]()
ARMEMPTY
Figura 6.4 Anomalia lui Sussman
Se considerã în continuare functionarea sistemului STRIPS pentru aceastã problemã. Considerarea scopurilor de satisfãcut pentru ajungerea în starea finalã poate genera urmãtoarele douã stive:
Stiva 1 Stiva 2
![]()
![]()
![]()
![]()
![]()
![]()
Pornind cu ordonarea scopurilor din Stiva 1, se genereazã
secventa de operatori ![]() care determinã tranzitia
din starea initialã Si în
starea Sk:
care determinã tranzitia
din starea initialã Si în
starea Sk:

![]()
![]()
În starea Sk,
scopul ![]() este realizat, scopul
este eliminat din stivã si se trece la îndeplinirea scopului
este realizat, scopul
este eliminat din stivã si se trece la îndeplinirea scopului ![]() . Pentru satisfacerea acestui scop, trebuie ca blocul A sã
fie mutat pe masã, pentru a putea realiza mutarea blocului B peste blocul C. În
momentul în care s-a realizat scopul
. Pentru satisfacerea acestui scop, trebuie ca blocul A sã
fie mutat pe masã, pentru a putea realiza mutarea blocului B peste blocul C. În
momentul în care s-a realizat scopul ![]() , s-au mai aplicat în plus operatorii
, s-au mai aplicat în plus operatorii ![]() care au determinat
tranzitia din starea Sk în
starea St:
care au determinat
tranzitia din starea Sk în
starea St:

![]()
![]()
Deoarece scopul ![]() este satisfãcut în
starea St, se eliminã acest scop din stivã; în stivã rãmîne conjunctia
de scopuri
este satisfãcut în
starea St, se eliminã acest scop din stivã; în stivã rãmîne conjunctia
de scopuri ![]() care nu este
satisfãcutã, desi scopul
care nu este
satisfãcutã, desi scopul ![]() fusese initial
satisfãcut. Scopul
fusese initial
satisfãcut. Scopul ![]() a fost invalidat
datoritã realizãrii scopului
a fost invalidat
datoritã realizãrii scopului ![]() . Diferenta între starea curentã si starea scop este acum
. Diferenta între starea curentã si starea scop este acum ![]() . Acest scop este adãugat în stivã si satisfãcut, prin
aplicarea a încã doi operatori, care
determinã tranzitia din starea St
în starea Sf:
. Acest scop este adãugat în stivã si satisfãcut, prin
aplicarea a încã doi operatori, care
determinã tranzitia din starea St
în starea Sf:
![]()
![]()
În acest moment, scopul compus este din nou verificat, si de aceastã datã este satisfãcut. Planul complet care a fost sintetizat este:
![]()
![]()
Desi acest plan va realiza scopul propus, el nu este deosebit de eficient. O situatie similarã apare si în cazul în care se porneste din varianta Stiva 2. Metoda utilizatã în sistemul STRIPS nu este capabilã sã gãseascã o solutie eficientã pentru aceastã problemã. Dificultatea este generatã de faptul cã nu existã nici o combinatie de planuri care, rezolvînd separat cele douã subscopuri, sã rezolve si conjunctia celor douã subscopuri.
Pentru a genera un plan eficient existã douã abordãri posibile. Prima abordare este aceea de a prelua planul existent si de a-l îmbunãtãti, de exemplu prin eliminarea operatiilor care executã o actiune pentru ca apoi sã o anuleze imediat. Pornind de la acest criteriu se pot elimina operatorii 4 si 5 ai planului, apoi, aplicînd acelasi criteriu pe planul rezultat, se eliminã operatorii 3 si 6. Deci planul îmbunãtãtit va fi format numai din operatorii 1, 2, 7, 8, 9, 10. Aceastã abordare poate fi deosebit de dificilã pentru probleme complexe, în care operatorii care interfereazã sînt separati prin secvente lungi de operatori. În plus, în procesul de construire a planului s-a pierdut deja o mare parte de timp pentru descoperirea acestor operatori nenecesari, si care au fost ulterior eliminati.
O altã posibilitate este utilizarea unei metode de planificare neliniarã. Metoda prezentatã în aceastã sectiune este o metodã de planificare liniarã, în care programul încearcã satisfacerea scopurilor la rînd, unul dupã altul, deci liniar. Pentru eliminarea anomaliei lui Sussman este necesar ca programul sã ia în considerare, simultan, mai multe scopuri care interactioneazã, deci sã execute o planificare neliniarã. O astfel de abordare se va prezenta în Sectiunea 6.4.
6.3.2 Solutii de implementare
În aceastã sectiune se prezintã un algoritm de functionare a sistemului STRIPS, împreunã cu implementarea sa în limbajul Lisp. Algoritmul utilizeazã urmãtoarele structuri de date:
Variabila S care memoreazã descrierea stãrii curente a universului problemei;
Stiva care memoreazã stiva de scopuri satisfãcute pe calea curentã de cãutare;
Scopuri care pãstreazã lista scopurilor nesatisfãcute pe calea curentã;
Structura Operator avînd cîmpurile Actiune, Preconditii, ListaAdãugãri si ListaEliminãri.
Algoritm: Planificare liniarã în STRIPS
SatisfacereScopuri (Scopuri, S, Stiva)
1. pentru fiecare ![]() executã
executã
1.1. ![]()
1.2. dacã
![]()
atunci întoarce INSUCCES
2. dacã toate scopurile din Scopuri sînt satisfãcute în starea StareNouã
atunci întoarce StareNouã
3. altfel întoarce INSUCCES
sfîrsit.
RealizeazãScop (Scop S, Stiva)
1. dacã Scop este marcat satisfãcut în starea S
atunci întoarce S
2. dacã ![]()
atunci întoarce INSUCCES
3. ![]()
4. pentru fiecare
operator ![]() executã
executã
4.1. ![]()
4.2. dacã
![]()
atunci
4.2.1. Marcheazã scopul Scop satisfãcut în starea S
4.2.2. întoarce StareNoua
5. întoarce INSUCCES
sfîrsit.
AplicãOperator (Operator, Stare, Stiva)
1. ![]()
2. dacã ![]()
atunci
2.1. executã
![]()
2.2. ![]()
2.3. întoarce
![]()
3. altfel întoarce INSUCCES
sfîrsit.
Observatii:
În algoritm, referirea cîmpurilor structurii unui operator se face cu ajutorul operatorului ..
În pasul 3 al subprogramului RealizeazãScop operatorii din multimea OperatoriValizi sînt acei operatori care pot satisface scopul Scop, deci care contin Scop în cimpul ListaAdãugãri.
Implementarea în limbajul Lisp a algoritmului prezentat anterior este descrisã în continuare. Variabila specialã *OPERATORI* memoreazã operatorii de rezolvare a problemei, fiecare operator fiind o structurã Lisp avînd cîmpurile actiune, preconditii, lista-adaugari si lista-eliminari. Actiunea fiecãrui operator este reprezentatã de o listã cu douã elemente, primul dintre acestea fiind atomul Lisp EXECUTA, al doilea fiind actiunea asociatã operatorului. Valoarea variabilei *OPERATORI* este stabilitã prin apelul functiei utilizeaza cu parametrul lista de operatori specifici unei anumite probleme. Functia satisfacere-scopuri satisface fiecare scop din lista de scopuri primitã ca parametru, asigurîndu-se cã dupã satisfacerea tuturor scopurilor acestea sînt în continuare satisfãcute. Functia realizeaza-scop este cea care satisface un scop într-o stare a problemei. O stare S a problemei este reprezentatã printr-o listã formatã din atomi Lisp, atomi ai cãror nume descriu în limbaj natural trãsãturile stãrii S, si actiunile operatorilor executati pînã la ajungerea în starea S. Un scop este reprezentat printr-un atom Lisp si este satisfãcut într-o stare a problemei dacã el se aflã inclus în starea problemei sau dacã existã un operator potrivit prin aplicarea cãruia scopul este inclus în starea problemei, i.e. scopul se aflã inclus în lista de adãugãri a operatorului. Functia aplica-operator întoarce o nouã stare a problemei dacã operatorul primit ca parametru este aplicabil, i.e. toate preconditiile sale sînt satisfãcute. Noua stare a problemei este obtinutã din precedenta stare modificatã în conformitate cu lista de eliminãri si lista de adãugãri ale operatorului în care se adaugã actiunea operatorului. Predicatul potrivit-p verificã dacã un operator este potrivit pentru satisfacerea unui scop, verificînd dacã scopul se aflã în lista de adãugãri a operatorului. Functiile extrage, sterge si subsetp sînt functii auxiliare si se regãsesc în majoritatea implementãrilor limbajului Lisp. Functia extrage primeste ca parametri un element, o secventã si o functie de test si întoarce lista elementelor din secventã care sînt similare elementului, potrivit testului efectuat cu functia de test, fãrã a altera secventa. Functia sterge primeste ca parametri o functie de test si o listã si întoarce lista din care au fost îndepãrtate toate elementele pentru care rezultatul testului efectuat cu functia de test a fost adevãrat. Predicatul subsetp primeste douã secvente si verificã dacã elementele primului parametru se regãsesc, în totalitate, printre elementele celui de-al doilea parametru.
(defvar *OPERATORI* nil
(defstruct operator
(actiune nil) (preconditii nil) (lista-adaugari nil) (lista-eliminari nil))
(defun strips (stare scopuri &optional (*OPERATORI* *OPERATORI*))
(sterge #'atom (satisfacere-scopuri (cons '(START) stare) scopuri nil)))
(defun satisfacere-scopuri (stare scopuri stiva-scopuri)
(let ((stare-curenta stare))
(when
(and (every #'(lambda (scop)
(setf stare-curenta (realizeaza-scop stare-curenta scop stiva-scopuri)))
scopuri)
(subsetp scopuri stare-curenta :test #'equal))
stare-curenta)))
(defun realizeaza-scop (stare scop stiva-scopuri)
(cond ((member scop stare :test #'equal) stare)
((member scop stiva-scopuri :test #'equal) nil)
(t (some #'(lambda (operator)
(aplica-operator stare scop operator stiva-scopuri))
(extrage scop *OPERATORI* #'potrivit-p)))))
(defun aplica-operator (stare scop operator stiva-scopuri)
(let ((stare2 (satisfacere-scopuri stare
(operator-preconditii operator)
(cons scop stiva-scopuri))))
(when stare2
(append (sterge #'(lambda (x)
(member x (operator-lista-eliminari operator) :test #'equal))
stare2)
(list (operator-actiune operator))
(operator-lista-adaugari operator)))))
(defun potrivit-p (scop operator)
(member scop (operator-lista-adaugari operator) :test #'equal))
(defun utilizeaza (lista-operatori)
(length (setf *OPERATORI* lista-operatori)))
(defun extrage (element secventa functie-test)
(delete nil (mapcar #'(lambda (i) (when (funcall functie-test element) i)) secventa)))
(defun sterge (functie-test lista)
(delete nil (mapcar #'(lambda (elem) (unless (funcall functie-test elem) elem)) lista)))
(defun subsetp (subset set &rest args)
(every #'(lambda (element) (apply #'member element set args)) subset))
În continuare vor fi prezentati operatorii de rezolvare a unei probleme clasice, problema maimutei si a bananei, prezentatã în Sectiunea 5.5.1, cu urmãtoarea ipotezã simplificatoare: în camerã existã un singur cub si o singurã bananã. Pozitia maimutei în interiorul camerei este specificatã prin atomii Lisp la-usa, sub-banana, pe-podea, pe-cub, linga-banana si in-camera. Pozitia cubului în interiorul camerei este specificatã prin atomii cub-la-usa si cub-sub-banana, iar starea maimutei este descrisã prin atomii are-minge, are-banana, miini-libere, maimuta-flaminda si maimuta-satula. Starea problemei la un moment dat este definitã prin pozitia maimutei, pozitia cubului si starea maimutei. Actiunile pe care maimuta le poate realiza sînt: urca-pe-cub, impinge-cub-de-la-usa-sub-banana, merge-la-usa, merge-de-la-usa-sub-banana, apuca-banana, arunca-minge si maninca-banana.
(defparameter *operatori-maimuta*
`(,(make-operator
:actiune '(executa urca-pe-cub)
:preconditii '(cub-sub-banana sub-banana pe-podea)
:lista-adaugari '(linga-banana pe-cub)
:lista-eliminari '(sub-banana pe-podea))
,(make-operator
:actiune '(executa impinge-cub-de-la-usa-sub-banana)
:preconditii '(cub-la-usa la-usa)
:lista-adaugari '(cub-sub-banana sub-banana)
:lista-eliminari '(cub-la-usa la-usa))
,(make-operator
:actiune '(executa merge-la-usa)
:preconditii '(in-camera pe-podea)
:lista-adaugari '(la-usa)
:lista-eliminari nil)
,(make-operator
:actiune '(executa merge-de-la-usa-sub-banana)
:preconditii '(la-usa pe-podea)
:lista-adaugari '(sub-banana)
:lista-eliminari '(la-usa))
,(make-operator
:actiune '(executa apuca-banana)
:preconditii '(la-banana miini-libere)
:lista-adaugari '(are-banana)
:lista-eliminari '(miini-libere))
,(make-operator
:actiune '(executa arunca-minge)
:preconditii '(are-minge)
:lista-adaugari '(miini-libere)
:lista-eliminari '(are-minge))
,(make-operator
:actiune '(executa maninca-banana)
:preconditii '(are-banana)
:lista-adaugari '(miini-libere maimuta-satula)
:lista-eliminari '(are-banana maimuta-flaminda))))
Stabilirea contextului si rezolvarea problemei particulare se realizeazã prin apelurile:
(utilizeaza *operatori-maimuta*)
(strips '(in-camera pe-podea are-minge maimuta-flaminda cub-la-usa)
'(maimuta-satula))
6.4 Planificare neliniarã în sistemul TWEAK
Exemplul lui Sussman prezentat în sectiunea anterioarã a pus în evidentã faptul cã satisfacerea conjunctiilor de scopuri care interactioneazã poate crea dificultãti în sinteza planului. Pentru anumite probleme, nu se poate garanta existenta unei ordonãri conjunctiei de scopuri, în care planurile pentru realizarea unor scopuri sã nu interfereze cu planurile pentru realizarea celorlalte scopuri. Un plan eficient pentru rezolvarea problemei din exemplul lui Sussman ar putea fi urmãtorul:
(1) Începe lucrul pentru
satisfacerea scopului ![]() prin eliberarea
blocului A si asezarea blocului C pe masã.
prin eliberarea
blocului A si asezarea blocului C pe masã.
(2) Realizeazã scopul ![]() prin asezarea blocului
B peste blocul C.
prin asezarea blocului
B peste blocul C.
(3) Realizeazã restul
operatiilor pentru satisfacerea scopului ![]() prin asezarea blocului
A peste blocul B.
prin asezarea blocului
A peste blocul B.
Un astfel de plan nu poate fi sintetizat printr-o metodã de planificare liniarã, cum ar fi cea utilizatã în sistemul STRIPS. În schimb, el poate fi realizat printr-o metodã de planificare neliniarã. Primul sistem de planificare neliniarã a fost sistemul NOAH [Sacerdoti,1974]. Ideea importantã a acestui sistem este aceea cã un plan, în timp ce este construit, nu trebuie sã specifice complet ordinea de executare a operatiilor. Cu alte cuvinte, un plan specificã numai o ordine partialã a operatiilor lui, cel putin pînã în momentul în care planul este complet.
Sistemul de planificare neliniarã TWEAK [Chapman, 1987], este un sistem de planificare independent de domeniu care foloseste ca tehnicã centralã a planificãrii neliniare, înregistrarea restrictiilor. Utilizarea restrictiilor în rezolvarea problemelor de planificare a fost introdusã pentru prima oarã de sistemul MOLGEN [Stefik,1981a,b].
Înregistrarea restrictiilor este procesul de definire a unui obiect, un plan în acest caz, prin specificarea incrementalã a descrierilor partiale (restrictiilor) pe care obiectul trebuie sã le satisfacã. Alternativ, înregistrarea restrictiilor poate fi vãzutã ca o strategie de cãutare în care se eliminã succesiv portiuni din spatiul de cãutare prin adãugarea unor restrictii. Restrictiile exclud stãri si cãi de cãutare din acest spatiu, pînã ce, în final, toate alternativele rãmase sînt satisfãcãtoare. Avantajul tehnicii de înregistrare a restrictiilor constã în faptul cã proprietãtile obiectului cãutat, i.e. ale planului, nu trebuie alese pînã în momentul în care nu existã un motiv pentru alegerea acestora. Aceastã reducere a selectiilor arbitrare determinã de multe ori o reducere a numãrului de reveniri necesare în procesul de cãutare. Înregistrarea restrictiilor utilizatã în sistemul TWEAK este o paradigmã a strategiei deciziilor amînate de rezolvare a problemelor.
Sistemul TWEAK este primul sistem de planificare automatã care prezintã o definire formalã a planului si a corectitudinii unui plan. Autorul sistemului construieste o formalizare matematicã a principiilor planificãrii neliniare. În acelasi timp, sistemul este implementat într-o variantã functionalã. Din punct de vedere conceptual, sistemul TWEAK este construit din trei nivele:
nivelul de reprezentare a planului;
nivelul de modificare a planului pentru a obtine un plan care realizeazã scopul problemei;
structura de control generalã.
În continuare se vor prezenta elementele constructive si functionarea sistemului TWEAK, iar în final se vor descrie aspectele de bazã ale formalizãrii planificãrii neliniare si limitãrile sistemului.
6.4.1 Reprezentarea planului
Un plan dezvoltat de sistemul TWEAK este alcãtuit dintr-o secventã de pasi de plan (operatori, actiuni). Un pas de plan este reprezentat prin actiunea care trebuie executatã, o multime finitã de preconditii (echivalentã cu lista preconditiilor din sistemul STRIPS) si o multime finitã de postconditii. Analog sistemului STRIPS, multimea efectelor unei actiuni, deci postconditiile, este alcãtuitã din Lista Adãugãrilor si Lista Eliminãrilor. Preconditiile reprezintã asertiuni despre starea curentã a problemei care trebuie sã fie adevãrate pentru ca actiunea sã poatã fi executatã. Postconditiile reprezintã asertiunile validate si invalidate ca efect al executãrii pasului de plan. Preconditiile si postconditiile sînt exprimate prin formule atomice în logica cu predicate de ordinul I, negate sau nu, care acceptã ca argumente constante si variabile. Simbolurile functionale, operatorii si cuantificatorii sînt interzise în preconditii si postconditii. Postconditiile corespunzãtoare asertiunilor validate de o actiune sînt reprezentate prin formule atomice nenegate, iar cele corespunzãtoare asertiunilor invalidate de o actiune, prin formule negate. Se observã cã puterea de reprezentare a sistemului TWEAK este echivalentã cu cea a sistemului STRIPS. În ambele cazuri, aceste restrictii restrîng capacitãtile generale de modelare a universului problemei, asa cum se va discuta în Sectiunea 6.4.3.
Considerînd lumea blocurilor si operatorii de plan definiti în Sectiunea 6.3.1, o reprezentare a doi dintre acesti operatori este urmãtoarea, reprezentarea celorlalti operatori obtinîndu-se analog.
Actiune: ![]()
Preconditii: ![]()
Postconditii: ![]()
Actiune: PICKUP(x)
Preconditii: ![]()
Postconditii: ![]()
În timpul activitãtii de planificare, starea problemei este reprezentatã printr-o multime de formule, considerate conjunctiv, de tipul celor descrise anterior. Pe mãsurã ce se executã pasi de plan, starea problemei se modificã. Reprezentarea este similarã cu cea din sistemul STRIPS. Un plan are asociate o stare initialã, i.e. starea problemei în momentul începerii executãrii planului, si o stare finalã, i.e. starea problemei la terminarea executãrii planului. Asemãnãtor, pentru fiecare pas al planului se definesc starea de intrare, respectiv starea de iesire, ca fiind multimile de formule adevãrate la începerea, respectiv la terminarea executãrii pasului de plan. Chapman, autorul sistemului TWEAK, numeste stãrile din sistem situatii.
Sistemul TWEAK a preluat si îmbunãtãtit ideea sistemului
NOAH de a dezvolta planuri în care ordinea de executare a operatorilor nu este
specificatã complet. Pe parcursul procesului de rezolvare a problemei, sistemul
TWEAK dezvoltã un plan incomplet. Un
plan incomplet este o descriere partialã a unui plan capabil sã rezolve
problema propusã. Informal, în fiecare moment, sistemul TWEAK are la dispozitie
o multime utilã de pasi de plan, dar nu are o idee clarã asupra modului în care
va trebui sã ordoneze în final aceastã multime de actiuni pentru a executa
planul. În cele ce urmeazã, planurile vor fi reprezentate prin multimi de pasi
de plan, considerînd deci cã ordinea pasilor nu este stabilitã, de exemplu ![]()
Planul partial poate fi completat, deci transformat într-un plan complet, în diferite moduri, prin adãugarea de restrictii în planul partial. Din aceastã cauzã, un plan incomplet reprezintã o clasã de planuri complete. Procesul de planificare constã, de fapt, în adãugarea de noi restrictii planurilor incomplete si se terminã în momentul în care se obtine un plan (complet sau incomplet) care rezolvã problema propusã.
În sistemul TWEAK, planurile pot fi incomplete datoritã:
specificãrii incomplete a ordinii (temporale) de executare a pasilor de plan, sau
specificãrii incomplete a pasilor de plan.
Generarea unui plan complet dintr-unul incomplet se poate face prin adãugarea a douã tipuri de restrictii:
restrictii temporale care specificã ordinea de executare a pasilor de plan;
restrictii de codesemnare care specificã complet pasii planului.
O restrictie temporalã este reprezentatã de conditionarea
executãrii unui pas de plan înaintea altui pas de plan. Din aceastã cauzã, o
multime de restrictii temporale reprezintã o ordonare partialã a pasilor unui
plan. O completare a unei multimi de
restrictii temporale R, referitoare la o multime de pasi de plan P, este orice
ordonare totalã T a multimii P astfel încît ![]() implicã
implicã ![]() oricare ar fi p si p
pasi de plan. Cu alte cuvinte, orice ordonare în planul incomplet rãmîne
valabilã si în planul complet.
oricare ar fi p si p
pasi de plan. Cu alte cuvinte, orice ordonare în planul incomplet rãmîne
valabilã si în planul complet.
Un plan complet reprezintã o ordonare totalã a unei multimi finite de pasi de plan. Relatia de ordine este ordonarea temporalã, iar pasii de plan sînt reprezentati de actiunile asociate lor. Realizarea planului corespunde executãrii actiunilor asociate pasilor planului în ordinea stabilitã de plan.
Restrictia de codesemnare este o relatie de echivalentã între variabilele si constantele din formule. Într-un plan complet, toate variabilele care apar în preconditii si postconditii trebuie sã codesemneze (i.e. sã fie legate) cu o anumitã constantã. În momentul executãrii actiunilor asociate pasilor de plan, constanta care codesemneazã cu o variabilã care apare într-un pas de plan va substitui acea variabilã.
Restrictiile de codesemnare impun codesemnarea sau noncodesemnarea elementelor formulelor. Este evident cã douã constante diferite nu pot codesemna. Douã formule codesemneazã dacã ambele contin acelasi nume de preconditie sau postconditie (predicat), sînt în forma negatã sau normalã si elementele lor componente codesemneazã. Codesemnarea formulelor este similarã unificãrii formulelor atomice din logica cu predicate de ordinul I.
Adãugarea unei restrictii la un plan incomplet poate conduce la distrugerea tuturor extinderilor complete ale planului incomplet. În acest caz, multimea de restrictii este inconsistentã si nu mai reprezintã un plan incomplet valid, sistemul fiind obligat sã execute un proces de revenire pentru a alege o altã restrictie pentru a fi adãugatã planului incomplet.
6.4.2 Sinteza planului
Scopul sistemului TWEAK este acela de a construi un plan pentru o problemã datã. Planul sintetizat trebuie sã continã actiunile prin care se ajunge din starea initialã în starea finalã, deci trebuie sã valideze toate formulele din starea finalã a problemei. Initial se porneste cu un plan vid, deci un plan care nu contine nici un pas. Pe mãsurã ce procesul de planificare avanseazã, se alege cîte un scop (formulã) care trebuie satisfãcut si se adaugã pasii de plan, incomplet specificati atît ca instantieri cît si ca ordine temporalã, care formeazã un plan incomplet. Satisfacerea fiecãrui scop determinã rafinarea treptatã a planului incomplet pe baza operatiilor de modificare a planului. Planul care rezolvã problema poate fi atît complet, cît si incomplet, caz în care orice instantã a planului incomplet poate produce solutia.
În sistemul TWEAK existã cinci operatii de modificare a planului:
(1) adãugarea de pasi este operatia prin care se creazã noi pasi care se adaugã la plan;
(2) promovarea este operatia de stabilire a unei ordonãri (temporale) între doi pasi de plan;
(3) legarea simplã este operatia de atribuire de valori variabilelor pentru a valida preconditiile unui pas de plan;
(4) separarea este operatia de împiedicare a atribuirii anumitor valori unei variabile;
(5) eliminarea destructivitãtii este operatia de introducere a unui pas S3 (un pas deja existent în plan sau un pas nou) între pasii S1 si S2, în scopul de a adãuga un fapt invalidat de pasul S1 si necesar în pasul S2.
Operatia de separare este contrariul operatiei de legare simplã si este folositã pentru a împiedica legarea a douã variabile sau unificarea a douã formule. Operatia de separare este folositã tot ca o modalitate de eliminare a destructivitãtii. Pentru a ilustra acest fapt se presupune existenta planului P în care pasul C precede pasul C , si, în plus, pasul C ar putea invalida o preconditie a pasului C2. Se spune cã "ar putea invalida" deoarece pasul C poate contine variabile. Separarea permite specificarea restrictiei prin care douã formule nu trebuie sã se instantieze în acelasi fel în planul final eliminînd astfel posibilitatea de invalidare a unor formule.
În continuare se va prezenta functionarea sistemului TWEAK pentru rezolvarea problemei anomaliei lui Sussman, cu starea initialã si starea finalã descrise în Figura 6.5 si cu operatorii (actiunile) descrisi în Sectiunea 6.3.1. În cele ce urmeazã, se presupune cã sistemul este capabil sã selecteze de fiecare datã pasii de plan ce conduc spre solutie. În realitate, sistemul va face un proces de cãutare cu reveniri pentru a alege alternativa corectã de completare a planului. Se va discuta ulterior strategia de selectie utilizatã.

![]()
![]()
![]()
![]()
![]()
ARMEMPTY
Figura 6.5 Anomalia lui Sussman
Se doreste realizarea stãrii scop ![]() . Procesul de planificare începe cu un plan vid. Conform
principiului analizei bazatã pe modalitãti, pentru realizarea stãrii scop se
aleg doi pasi de plan care contin în lista postconditiilor cîte unul din cele
douã scopuri, în forma directã. În continuare, fiecare operator este
reprezentat cu lista preconditiilor indicatã deasupra operatorului si lista
postconditiilor dedesubt. Asertiunile invalidate sînt marcate cu simbolul ~ în
fatã. O preconditie nesatisfãcutã în starea curentã este marcatã cu simbolul *.
Pentru satisfacerea celor douã asertiuni din starea finalã, se pot aplica pasii
de plan indicati mai jos si planul se modificã prin adãugarea acestor doi pasi.
. Procesul de planificare începe cu un plan vid. Conform
principiului analizei bazatã pe modalitãti, pentru realizarea stãrii scop se
aleg doi pasi de plan care contin în lista postconditiilor cîte unul din cele
douã scopuri, în forma directã. În continuare, fiecare operator este
reprezentat cu lista preconditiilor indicatã deasupra operatorului si lista
postconditiilor dedesubt. Asertiunile invalidate sînt marcate cu simbolul ~ în
fatã. O preconditie nesatisfãcutã în starea curentã este marcatã cu simbolul *.
Pentru satisfacerea celor douã asertiuni din starea finalã, se pot aplica pasii
de plan indicati mai jos si planul se modificã prin adãugarea acestor doi pasi.
![]()
![]()
![]()
![]()
----- ----- -------- ----- ----- --------
![]()
----- ----- -------- ----- ----- --------
ARMEMPTY ARMEMPTY
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Planul se modificã în continuare
prin introducerea de noi operatori care sã ducã la satisfacerea preconditiilor
celor doi pasi de plan. Euristica de introducere a noilor pasi de plan pentru
satisfacerea preconditiilor corespunde, de asemenea, operatiei de modificare a
planului adãugare de pasi. Deoarece ![]() si
si ![]() sînt scopuri
satisfãcute în starea initialã, scopurile care trebuie satisfãcute, prin
modificarea planului, sînt
sînt scopuri
satisfãcute în starea initialã, scopurile care trebuie satisfãcute, prin
modificarea planului, sînt ![]() si
si ![]() . Urmãtorii pasi sînt adãugati planului incomplet:
. Urmãtorii pasi sînt adãugati planului incomplet:
![]()
![]()
![]()
![]()
*ARMEMPTY *ARMEMPTY
----- ----- -------- ----- ----- ----
![]()
![]()
----- ----- -------- ----- ----- ----
![]()
![]()
~ARMEMPTY ![]()
![]()
![]()
În acest moment planul incomplet contine multimea neordonatã de pasi:
![]()
Dacã un pas de plan PICKUP ar urma
pasului STACK în planul final, scopurile ![]() si
si ![]() ar trebui satisfãcute
în alt mod, si nu ar mai putea fi satisfãcute de pasul PICKUP. Aceastã problemã
se rezolvã prin introducerea unor restrictii temporale de ordonare a pasilor
planului, de forma
ar trebui satisfãcute
în alt mod, si nu ar mai putea fi satisfãcute de pasul PICKUP. Aceastã problemã
se rezolvã prin introducerea unor restrictii temporale de ordonare a pasilor
planului, de forma ![]() , si avînd semnificatia deja cunoscutã: pasul de plan P trebuie sã preceadã pasul de plan P în planul final. Restrictiile temporale
sînt:
, si avînd semnificatia deja cunoscutã: pasul de plan P trebuie sã preceadã pasul de plan P în planul final. Restrictiile temporale
sînt:
![]()
![]()
Euristica de ordonare a pasilor utilizatã corespunde operatiei de modificare a planului promovare.
Acum, planul incomplet contine
patru pasi partial ordonati si patru preconditii nesatisfãcute. Formula ![]() este nesatisfãcutã
deoarece blocul A nu este liber în starea initialã. Formula
este nesatisfãcutã
deoarece blocul A nu este liber în starea initialã. Formula ![]() este nesatisfãcutã
deoarece, desi blocul B este liber în starea initialã, existã pasul de plan
este nesatisfãcutã
deoarece, desi blocul B este liber în starea initialã, existã pasul de plan ![]() , avînd postconditia
, avînd postconditia ![]() , si acest pas s-ar putea sã preceadã pasul de plan care are
formula
, si acest pas s-ar putea sã preceadã pasul de plan care are
formula ![]() ca preconditie, deci
pasul de plan
ca preconditie, deci
pasul de plan ![]() . Pentru ca acest lucru sã nu se întîmple, se introduce o
altã restrictie de ordonare:
. Pentru ca acest lucru sã nu se întîmple, se introduce o
altã restrictie de ordonare:
![]()
Rãmîn în continuare
nesatisfãcute scopurile ARMEMPTY (pentru ambii operatori PICKUP) si ![]() . Desi în starea initialã preconditia ARMEMPTY este
satisfãcutã, fiecare operatie PICKUP are ca efect ~ARMEMPTY. Fiecare operatie
PICKUP executatã poate duce la imposibilitatea executãrii celeilalte operatii
PICKUP. Se utilizeazã ordonarea pentru a realiza cel putin un pas PICKUP:
. Desi în starea initialã preconditia ARMEMPTY este
satisfãcutã, fiecare operatie PICKUP are ca efect ~ARMEMPTY. Fiecare operatie
PICKUP executatã poate duce la imposibilitatea executãrii celeilalte operatii
PICKUP. Se utilizeazã ordonarea pentru a realiza cel putin un pas PICKUP:
![]()
Deoarece în starea initialã bratul
robotului este liber si nici un pas de plan care precede pasul ![]() nu invalideazã scopul
ARMEMPTY, preconditiile pasului
nu invalideazã scopul
ARMEMPTY, preconditiile pasului ![]() sînt satisfãcute.
Pentru realizarea preconditiei ARMEMPTY a pasului
sînt satisfãcute.
Pentru realizarea preconditiei ARMEMPTY a pasului ![]() se foloseste o a treia
euristicã corespunzatoare operatiei de modificare a planului eliminarea destructivitãtii.
se foloseste o a treia
euristicã corespunzatoare operatiei de modificare a planului eliminarea destructivitãtii.
Pasul ![]() are ca efect infirmarea scopul ARMEMPTY, adicã ~ARMEMPTY,
dar dacã se poate introduce un alt pas de plan între pasii
are ca efect infirmarea scopul ARMEMPTY, adicã ~ARMEMPTY,
dar dacã se poate introduce un alt pas de plan între pasii ![]() si
si ![]() , pas care va revalida scopul ARMEMPTY, afirmîndu-l, atunci
preconditia pasului
, pas care va revalida scopul ARMEMPTY, afirmîndu-l, atunci
preconditia pasului ![]() va fi satisfãcutã.
Acest lucru poate fi realizat cu ajutorul pasului care se restrictioneazã
temporal astfel:
va fi satisfãcutã.
Acest lucru poate fi realizat cu ajutorul pasului care se restrictioneazã
temporal astfel:
![]()
Se observã cã s-a întîlnit o situatie
în care pasul ![]() distruge preconditiile
pasului
distruge preconditiile
pasului ![]() , iar pasul eliminã aceste
distrugeri. În acest moment, singura preconditie care mai rãmîne de îndeplinit
este
, iar pasul eliminã aceste
distrugeri. În acest moment, singura preconditie care mai rãmîne de îndeplinit
este ![]() . Pentru satisfacerea acestei conditii se adaugã un nou pas
de plan:
. Pentru satisfacerea acestei conditii se adaugã un nou pas
de plan:
![]()
![]()
*ARMEMPTY
----- ----- ------------
![]()
----- ----- ------------
~ARMEMPTY
![]()
![]()
![]()
restrictiile temporale si planul devenind:
![]()
![]()
![]()
S-a introdus variabila x deorece
singura postconditie care intereseazã este ![]() si nu conteazã care
din blocuri este deasupra blocului A. Restrictiile de ordonare permit
specificarea incompletã a planurilor din punct de vedere al ordinii pasilor,
iar variabilele permit specificarea incompletã a planurilor prin instantierea
partialã a pasilor (operatorilor).
si nu conteazã care
din blocuri este deasupra blocului A. Restrictiile de ordonare permit
specificarea incompletã a planurilor din punct de vedere al ordinii pasilor,
iar variabilele permit specificarea incompletã a planurilor prin instantierea
partialã a pasilor (operatorilor).
Dupã introducerea pasului ![]() , existã trei preconditii nesatisfãcute. Prima,
, existã trei preconditii nesatisfãcute. Prima, ![]() , poate fi satisfãcutã prin restrictia de instantiere a lui x
la C, deci printr-o restrictie de codesemnare. Aceasta corespunde operatiei de
modificare a planului numitã legare
simplã. În acest moment preconditiile devin
, poate fi satisfãcutã prin restrictia de instantiere a lui x
la C, deci printr-o restrictie de codesemnare. Aceasta corespunde operatiei de
modificare a planului numitã legare
simplã. În acest moment preconditiile devin ![]() ,
, ![]() si ARMEMPTY. Preconditiile
si ARMEMPTY. Preconditiile
![]() si ARMEMPTY pot fi
invalidate de pasi din plan, dar acest lucru este împiedicat prin operatii de
modificare a planului de tip promovare:
si ARMEMPTY pot fi
invalidate de pasi din plan, dar acest lucru este împiedicat prin operatii de
modificare a planului de tip promovare:
![]()
![]()
![]()
Dar pasul ![]() necesitã îndeplinirea
preconditiei ARMEMPTY care este invalidatã de noul pas adãugat
necesitã îndeplinirea
preconditiei ARMEMPTY care este invalidatã de noul pas adãugat ![]() . Rezolvarea acestei probleme se realizeazã prin adãugarea
unui nou pas de eliminare a destructivitãtii:
. Rezolvarea acestei probleme se realizeazã prin adãugarea
unui nou pas de eliminare a destructivitãtii:
![]()
----- ----- ---------
![]()
----- ----- ----------
![]()
![]()
ARMEMPTY
si a ordonãrii:
![]() .
.
Deci s-au pus în evidentã douã
modalitãti de eliminare a destructivitãtii: una în care se foloseste un pas
deja existent al planului, pasul  , si alta în care este necesarã introducerea unui nou pas,
pasul
, si alta în care este necesarã introducerea unui nou pas,
pasul ![]() . Din fericire, preconditiile pasului PUTDOWN sînt toate satisfãcute;
preconditiile tuturor pasilor din plan sînt satisfãcute, deci se obtine planul
complet:
. Din fericire, preconditiile pasului PUTDOWN sînt toate satisfãcute;
preconditiile tuturor pasilor din plan sînt satisfãcute, deci se obtine planul
complet:
![]() 1. UNSTACK (C,A)
1. UNSTACK (C,A)
2. PUTDOWN (C)
3. PICKUP (B)
4. STACK (B,C)
5. PICKUP (A)
6. STACK (A,B) }
Se observã cã metoda de planificare neliniarã din sistemul TWEAK a generat un plan eficient pentru rezolvarea problemei anomaliei lui Sussman, deci pentru o problemã în care satisfacerea subscopurilor interactioneazã.
6.4.3 Structura de control
Algoritmul de satisfacere a unui scop în sistemul TWEAK este urmãtorul:
Algoritm: Planificare neliniarã în TWEAK
1. Initializeazã
![]()
2. Initializeazã S cu multimea formulelor care definesc starea scop
3. cît timp ![]() executã
executã
3.1. Alege si eliminã o formulã F din S
3.2. dacã F nu este satisfãcutã în starea curentã
atunci
3.2.1. Alege o operatie de modificare a planului
3.2.2. Aplicã operatia si adaugã efectul ei în Plan
3.3. Verificã pentru toti pasii din Plan satisfacerea preconditiilor
3.4. pentru fiecare preconditie nesatisfãcutã a unui pas din Plan executã
Adaugã preconditia la S
4. Genereazã ordinea totalã a elmentelor din Plan pe baza relatiilor de ordine individuale
5. dacã planul Plan este partial
atunci
5.1. Instantiazã variabilele planului
5.2. Transformã arbitrar ordinea partialã în ordine totalã
sfîrsit.
Algoritmul prezentat este evident nedeterminist. Caracterul nedeterminist este dat de pasii 3.1. si 3.2. Alegerea unui scop (formulã) ce trebuie satisfãcut în pasul 3.1. si alegerea unei operatii de modificare a planului implicã un proces de cãutare. De aceea, structura de control a sistemului TWEAK este o cãutare în spatiul cãilor generate de procedura de satisfacere a scopului. Strategia de cãutare utilizatã în TWEAK este cãutarea în lãtime cu utilizarea mecanismului de backtracking condus de dependente. La selectia operatiilor de modificare a planului se preferã adãugarea unei restrictii fatã de adãugarea unui pas de plan. Acest lucru este justificat prin faptul cã adãugarea de pasi conduce la generarea de noi preconditii, iar pasul adãugat poate distruge scopuri anterior îndeplinite. Din nefericire, aceste probleme sînt inevitabile si pot duce la cicluri infinite.
6.4.4 Modelul formal al planificãrii
În Sectiunea 6.4.1 s-a descris modalitatea de reprezentare a planului si restrictiile temporale si de codesemnare care pot fi utilizate pentru rafinarea planurilor incomplete. Plecînd de la aceste elemente, se prezintã în continuare modelul riguros al activitãtii de planificare automatã a sistemului TWEAK. Se reaminteste cã stãrile problemei sînt numite situatii în acest sistem.
O formulã este adevãratã într-o situatie dacã codesemneazã
cu o formulã care face parte din situatia respectivã. Deci formula F este
adevãratã în situatia S dacã existã ![]() astfel încît F si G
codesemneazã. Un pas de plan afirmã o
formulã în situatia sa de iesire dacã formula codesemneazã cu o postconditie a
pasului. Un pas de plan infirmã o
formulã în situatia sa de iesire dacã afirmã negarea acelei formule.
astfel încît F si G
codesemneazã. Un pas de plan afirmã o
formulã în situatia sa de iesire dacã formula codesemneazã cu o postconditie a
pasului. Un pas de plan infirmã o
formulã în situatia sa de iesire dacã afirmã negarea acelei formule.
Un pas de plan poate fi executat numai dacã toate preconditiile sale sînt adevãrate în situatia sa de intrare. În acest caz, situatia de iesire a pasului de plan este situatia de intrare din care se sterg formulele infirmate de cãtre pasul de plan si se adaugã formulele afirmate de pasul de plan. Ordinea de efectuare a operatiilor de stergere si adãugare este importantã.
Exemplu. Dacã formula R era adevãratã în situatia de intrare a pasului de plan P si acesta afirmã formula ~R, atunci situatia de iesire a pasului P nu trebuie sã continã nici formula R si nici formula ~R deoarece situatiile de intrare si de iesire ale pasilor trebuie sã reprezinte multimi consistente de formule.
În timpul planificãrii,
incompletitudinea planului introduce incertitudini cu privire la semnificatia
planului. De exemplu, dacã x este variabilã, nu se poate spune dacã formula ![]() este adevãratã sau
falsã într-o anumitã situatie, decît în cazul în care x codesemneazã cu o
constantã. Din acest motiv, se introduce un criteriu formal cu ajutorul cãruia
se poate decide dacã o formulã este necesar
adevãratã într-o anumitã situatie: criteriul adevãrului modal. Pentru a
introduce criteriul adevãrului modal este necesarã prezentarea cîtorva notiuni
pregãtitoare.
este adevãratã sau
falsã într-o anumitã situatie, decît în cazul în care x codesemneazã cu o
constantã. Din acest motiv, se introduce un criteriu formal cu ajutorul cãruia
se poate decide dacã o formulã este necesar
adevãratã într-o anumitã situatie: criteriul adevãrului modal. Pentru a
introduce criteriul adevãrului modal este necesarã prezentarea cîtorva notiuni
pregãtitoare.
O formulã F, i.e. o proprietate a stãrii curente, este necesar adevãratã într-un plan incomplet dacã F este adevãratã în toate planurile complete obtinute din planul incomplet. O formulã F este posibil adevãratã dacã F este adevãratã pentru cel putin un plan complet al planului incomplet.
Avînd în vedere definitiile date notiunilor de necesar si respectiv posibil, douã formule dintr-un plan incomplet codesemneazã necesar dacã codesemneazã în toate completãrile planului, i.e. indiferent de restrictiile adãugate planului incomplet. Douã formule care codesemneazã posibil pot fi constrînse sã codesemneze necesar prin adãugarea de restrictii care sã conducã la codesemnarea elementelor componente. Douã formule care nu codesemneazã posibil pot fi constrînse sã nu codesemneze necesar prin adãugarea unei restrictii de noncodesemnare a douã elemente de acelasi rang din formule.
Exemplu. Formulele ![]() si
si ![]() pot fi constrînse sã
codesemneze necesar prin adãugarea restrictiei de codesemnare asupra
variabilelor x si y. În acelasi mod, douã formule pot fi constrînse sã nu
codesemneze necesar prin adãugarea restrictiei de noncodesemnare asupra
variabilelor x si y.
pot fi constrînse sã
codesemneze necesar prin adãugarea restrictiei de codesemnare asupra
variabilelor x si y. În acelasi mod, douã formule pot fi constrînse sã nu
codesemneze necesar prin adãugarea restrictiei de noncodesemnare asupra
variabilelor x si y.
Din cele arãtate anterior se poate concluziona cã o formulã este necesar adevãratã într-o situatie S dacã este necesar afirmatã în situatia S. Odatã ce o formulã a fost afirmatã într-o situatie, formula rãmîne adevãratã pînã la infirmarea sa.
Criteriul adevãrului modal permite stabilirea caracterului de adevãr al unei formule din preconditiile sau postconditiile unui pas de plan, într-o situatie (stare) datã. Criteriul are douã cazuri, corespunzãtoare modalitãtilor necesar si posibil: criteriul adevãrului necesar si criteriul adevãrului posibil.
Criteriul adevãrului necesar
O formulã F este necesar adevãratã într-o situatie S dacã si numai dacã se îndeplinesc urmãtoarele douã conditii:
(a) existã o situatie T egalã cu/sau necesar anterioarã lui S în care F este necesar afirmatã (adãugatã);
(b) pentru fiecare pas C posibil de executat înaintea lui S si pentru fiecare formulã Q care poate codesemna cu F pe care C o infirmã, existã un pas W necesar între C si S care afirmã R, R fiind o formulã pentru care R si F codesemneazã ori de cîte ori F si Q codesemneazã.
Criteriul adevãrului posibil
O formulã F este posibil adevãratã într-o situatie S dacã si numai dacã se îndeplinesc urmãtoarele douã conditii:
(a) existã o situatie T egalã cu/sau posibil anterioarã lui S în care F este posibil afirmatã (adãugatã);
(b) pentru fiecare pas C necesar de executat înaintea lui S si pentru fiecare formulã Q care poate codesemna cu F pe care C o infirmã, existã un pas W posibil între C si S care afirmã R, R fiind o formulã pentru care R si F codesemneazã ori de cîte ori F si Q codesemneazã.
Situatiile T, necesar anterioare situatiei S, care afirmã necesar formula F se numesc situatii de stabilire. Pasii C, posibil înaintea situatiei S, se numesc pasi de infirmare, iar pasii de tipul W care invalideazã pasii ce altfel ar deveni pasi de distrugere se numesc pasi de eliminare a infirmãrii. Se observã introducerea cuantificãrii existentiale si universale a situatiilor si a pasilor de plan în criteriul adevãrului modal.
Informal, criteriul adevãrului modal spune cã formula F este necesar adevãratã dacã F a fost afirmatã (adãugatã) fie în situatia initialã, fie de un pas anterior si cã nu existã nici un pas anterior destructiv pentru care sã nu existe un pas de eliminare a destructivitãtii. În Figura 6.6 se prezintã schematic ideea criteriului adevãrului necesar. Liniile continue indicã relatiile temporale necesare, iar liniile punctate relatiile temporale posibile. Pãtratul format din linii punctate indicã un pas de infirmare, iar pãtratul format din puncte indicã pasul care eliminã consecintele pasului de infirmare.

Figura 6.6 Diagrama de reprezentare a criteriului adevãrului necesar
Prin definitie, un scop în sistemul TWEAK este o formulã care trebuie sã fie adevãratã într-o anumitã situatie. Sistemul urmãreste sinteza unui plan care rezolvã în mod necesar problema, deci îndeplineste scopul. În final, acest plan poate fi chiar incomplet, caz în care orice plan complet derivat poate fi ales pentru a fi executat. În concluzie, pentru o problemã definitã printr-o situatie initialã si o situatie finalã, un plan are ca scopuri formulele din situatia finalã a problemei, care trebuie sã fie adevãrate în situatia finalã a planului, si preconditiile fiecãrui pas al planului care trebuie sã fie adevãrate în situatiile de intrare ale respectivilor pasi.
Procesul de planificare constã în alegerea repetatã a unui scop si dezvoltarea pasilor de plan necesari satisfacerii lui. Procedura de îndeplinire a unui scop în TWEAK este o procedurã de interpretare nedeterministã a criteriului adevãrului modal. Criteriul adevãrului modal specificã toate metodele de obtinere a unei formule necesar adevãratã într-un plan incomplet. Planificatorul va alege una din aceste metode si va modifica corespunzãtor planul prin adãugarea de restrictii temporale si de codesemnare. Deoarece multimea formulelor afirmate într-o situatie S nu poate fi schimbatã, pentru a face o formulã F necesar adevãratã în acea situatie, planificatorul va forta codesemnarea formulei F cu una din formulele afirmate în S. Existã douã modalitãti de a instantia în mod nedeterminist o situatie cuantificatã existential:
prin alegerea unei situatii existente în plan;
prin adãugarea unui nou pas de plan si stabilirea situatiei sale de iesire ca valoare a variabilei cuantificate existential.
Una din aceste douã modalitãti va fi aleasã în mod nedeterminist. Operatorii logici prezenti în criteriul adevãrului modal sînt interpretati procedural în urmãtorul mod:
cuantificatorul universal peste o multime este interpretat ca iteratie peste multimea respectivã;
cuantificatorul existential peste o multime este interpretat ca o alegere nedeterministã din multimea respectivã;
disjunctia este interpretatã ca o alegere nedeterministã;
conjunctia este interpretatã ca o multime de elemente care trebuie sã fie toate adevãrate.
Folosind notatiile si / pentru reprezentarea restrictiilor
de codesemnare si, respectiv, noncodesemnare, < si pentru restrictiile
temporale, ![]() si pentru reprezentarea criteriilor
de necesar si respectiv posibil, criteriul adevãrului modal se rescrie în
urmãtorul mod:
si pentru reprezentarea criteriilor
de necesar si respectiv posibil, criteriul adevãrului modal se rescrie în
urmãtorul mod:
T ![]() T S
T S ![]() este_afirmatã(F,T)
este_afirmatã(F,T)
S ![]() S C
S C
Q ![]() ~este_afirmatã(F,T)
~este_afirmatã(F,T)
![]() Q / F
Q / F
W ![]() C < W
C < W
![]() W < S
W < S
R afirmã(W,R) F Q F R
Planificarea neliniarã, bazîndu-se pe planuri incomplet specificate, ridicã probleme din punct de vedere al stabilirii adevãrului formulelor din preconditiile si postconditiile pasilor de plan. Modelul formal propus defineste aceste notiuni si permite demonstrarea corectitudinii planurilor sintetizate de sistemul TWEAK.
Relatia dintre cele cinci operatii
de modificare a planului si criteriul adevãrului modal este prezentatã în
Figura 6.6. În figurã este reprezentat un arbore de derivare a criteriului pe
baza cãruia se vede cum se foloseste criteriul adevãrului modal pentru a
verifica dacã formula F este necesar adevãratã în situatia S. ![]() reprezintã faptul cã
pasul (sau situatia) C
precede în mod necesar pasul (sau situatia) C ,
iar
reprezintã faptul cã
pasul (sau situatia) C
precede în mod necesar pasul (sau situatia) C ,
iar ![]() reprezintã faptul cã
formulele F si Q codesemneazã.
reprezintã faptul cã
formulele F si Q codesemneazã.
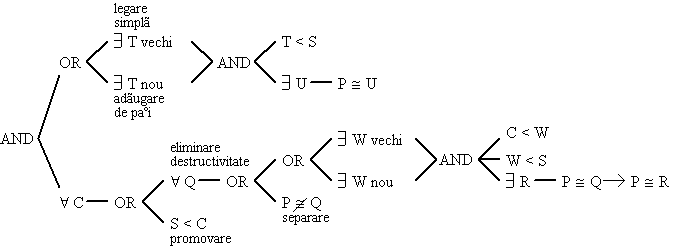
Figura 6.6 Relatia criteriului adevãrului modal cu operatiile
de modificare a planului
Figura 6.6 ilustreazã structura procedurii nedeterministe. În figurã este reprezentat un arbore de derivare a criteriului adevãrului modal modificat corespunzator interpretãrii procedurale a operatorilor logici. În figurã simbolul OR are semnificatia "alege una din alternativele urmãtoare", AND semnificã "executã toate alternativele urmãtoare", are semnificatia "alege un/o", iar semnificã "aplicã alternativa urmãtoare tuturor". Nodurile frunzã ale arborelui reprezintã restrictiile care trebuie adãugate planului. U reprezintã formulele necesar adevãrate în situatia T, Q si R reprezintã postconditiile pasului C si, respectiv, W.
Adãugarea de pasi planului implicã alegerea pasului de adãugat. Fiecare pas de plan trebuie sã reprezinte o actiune posibilã în universul problemei. Pentru a îndeplini un scop F prin adãugarea unui pas de plan, pasul adãugat trebuie sã afirme o formulã care codesemneazã posibil cu F. În concluzie, operatia de modificare a planului adãugare de pasi se realizeazã prin alegerea unui pas care afirmã posibil scopul de satisfãcut din multimea pasilor posibili ai problemei.
Autorul sistemului TWEAK a demonstrat cã cele cinci operatii de modificare a planului sînt suficiente pentru a rezolva orice problemã de planificare neliniarã care admite solutie si care satisface conditiile impuse de sistem. Aceste conditii sînt:
nu sînt permise efecte laterale directe si indirecte ale pasilor de plan,
nu este permis ca efectul actiunilor sã depindã de situatia în care acestea se aplicã, si
toate efectele unei actiuni trebuie explicit reprezentate de postconditiile actiunii.
Aceastã concluzie este exprimatã de urmãtoarea teoremã:
Teoremã. Corectitudinea/completitudinea sistemului TWEAK. Dacã pentru o problemã datã, programul TWEAK se terminã si gãseste solutii, atunci planul sintetizat rezolvã într-adevãr problema. Dacã programul TWEAK se opreste semnalînd insucces sau intrã în buclã infinitã, nu existã solutie pentru acea problemã.
Se observã cã cea de a treia conditie eludeazã problema ramificãrii. Conditiile impuse limiteazã sever puterea de reprezentare a universului problemei în sistemul TWEAK dar constituie suportul formalizãrii activitãtii de planificare si a validitãtii teoremei enuntate. În plus, autorul sistemului enuntã si demonstreazã urmãtoarea teoremã.
Teoremã. Orice masinã Turing cu banda ei de intrare asociatã poate fi codificatã ca o problemã de planificare în reprezentarea sistemului TWEAK. În consecintã problemele de planificare neliniarã sînt nedecidabile.
6.4 Exercitii si probleme
1. Se considerã problema dezvoltãrii un plan de cãlãtorie între localitãtile Paris si Bucuresti prezentatã în Sectiunea 6.2. Sã se exprime sub forma unei multimi de operatori STRIPS tabela de diferente din Figura 6.1.
2. Ce strategie de cãutare foloseste implementarea sistemului STRIPS prezentatã în Sectiunea 6.3.2. Justificati rãspunsul.
3. Se considerã problema curãteniei într-o bucãtãrie. Trebuie curãtate bufetele, frigiderul, chiuveta si pardoseala. Operatiile de curãtare implicã printre altele urmãtoarele aspecte:
curãtarea frigiderului murdãreste pardoseala
pentru a curãta pardoseala, aceasta trebuie mai întîi mãturatã si apoi spãlatã
înainte de a spãla pardoseala, gunoiul trebuie dus afarã
curãtarea frigiderului genereazã gunoi si murdãreste bufetele
spãlatul bufetelor si al pardoselii murdãreste chiuveta
Se cere:
1. Sã se proiecteze o multime de operatori cu ajutorul cãrora sistemul STRIPS poate rezolva problema curãteniei într-o bucãtãrie. Sã se scrie descrierea unei stãri initiale în care totul este murdar în bucãtãrie si descrierea unei stãri finale în care totul este curat.
2. Sã se arate cum ar rezolva sistemul STRIPS aceastã problemã.
4. Se considerã labirintul prezentat în Figura 6.8. Sã se scrie o functie Lisp care genereazã operatorii STRIPS pentru gãsirea unei cãi între douã puncte ale labirintului. Sã se scrie o functie Lisp care gãseste calea între douã puncte ale labirintului.

Figura 6.8 Un exemplu de labirint
5. Sã se scrie o functie Lisp care genereazã operatorii STRIPS de rezolvare a unei probleme de planificare în lumea blocurilor. Sã se modifice programul prezentat în Sectiunea 6.3.2 pentru a putea rezolva o problemã de planificare în lumea blocurilor.
6. Sã se proiecteze un algoritm de functionare a sistemului STRIPS care inspecteazã lista L a scopurilor rãmase de satisfãcut la un moment dat, astfel încît sistemul sã nu se blocheze dacã prin satisfacerea scopului curent cu operatorul O se eliminã toate posibilitãtile de satisfacere a unui scop din lista L. În caz de blocare algoritmul trebuie sã considere un alt operator, dacã existã, pentru satisfacerea scopului curent. Sã se modifice programul prezentat în Sectiunea 6.3.2 pentru a implementa acest nou algoritm.
7. Sã se proiecteze un algoritm de functionare a sistemului STRIPS care memoreazã atît scopurile rãmase de satisfãcut pe calea curentã de cãutare cît si scopurile care odatã satisfãcute nu mai pot fi infirmate. Un scop este infirmat prin aplicarea unui operator care contine scopul în lista de eliminãri. Sã se modifice programul prezentat în Sectiunea 6.3.2 pentru a implementa algoritmul proiectat.
8. Utilizati functiile de unificare prezentate în Sectiunea 3.4.3 pentru a scrie o variantã a programului STRIPS care permite existenta variabilelor în structura operatorilor de rezolvare a problemei.
6.6 Rezolvãri
4. Se considerã structura labirintului din Figura 6.9. Se defineste functia constructor-pereche care construieste perechea de operatori STRIPS pentru deplasarea între douã pozitii adiacente. Functia constructor construieste operatorul de deplasare între douã pozitii cu ajutorul constructorului standard al structurii operator. Cîmpurile preconditii, lista de adãugãri si lista de eliminãri ale operatorilor vor contine liste de forma (la <pozitie>) unde <pozitie> reprezintã o pozitie validã a labirintului, i.e. un numãr cuprins între 1 si 25.

Figura 6.9 Structura unui labirint
(defun constructor-pereche (pereche)
(list (constructor (first pereche) (second pereche))
(constructor (second pereche) (first pereche))))
(defun constructor (de-la la)
(make-operator :actiune `(executa (muta de la ,de-la la ,la))
:preconditii `((la ,de-la))
:lista-adaugari `((la ,la))
:lista-eliminari `((la ,de-la))))
Operatorii de rezolvare a unei probleme de navigare în labirintul prezentat în Figura 6.8 se obtin prin apelul:
(defparameter *operatori-labirint*
(mappend #'constructor-pereche
'((1 2) (2 3) (3 4) (4 9) (9 14) (9 8) (8 7) (7 12) (12 13)
(12 11) (11 6) (11 16) (16 17) (17 22) (21 22) (22 23)
(23 18) (23 24) (24 19) (19 20) (20 15) (15 10) (10 5) (20 25))))
Functia gaseste-cale genereazã succesiunea de pozitii care trebuie parcurse pentru a ajunge din starea de-la în starea la. Pentru aceasta foloseste o variantã putin modificatã a functiei strips prezentatã în Sectiunea 6.3.2. Functiile filtreaza si destinatie sînt douã functii auxiliare care realizeazã filtrarea elementelor unei secvente cu ajutorul unei functii de test si respectiv extragerea cîmpului destinatie din actiunea unui operator.
(defun gaseste-cale (de-la la)
(let ((cale (strips `((la ,de-la)) `((la ,la)))))
(when cale
(cons de-la (mapcar #'destinatie (remove '(start) cale :test #'equal))))))
(defun strips (stare scopuri &optional (*OPERATORI* *OPERATORI*))
(filtreaza #'executa-p (satisfacere-scopuri (cons '(start) stare) scopuri nil)))
(defun filtreaza (test-fn secventa)
(delete nil (mapcar #'(lambda (elem) (when (funcall test-fn elem) elem)) secventa)))
(defun destinatie (actiune)
(first (last (second actiune))))
5. Functia constructor primeste o listã de blocuri si construieste operatorii de lucru în lumea blocurilor pentru o problemã care contine blocurile specificate si masa. Functia operator-mutare construieste operatorul de mutare a blocului a aflat deasupra blocului b pe blocul c. Functia satisfacere scopuri este redefinitã astfel încît sã ia în consideratie mai multe ordonãri posibile ale scopurilor, ordonãri furnizate de functia ordonari. În varianta prezentatã functia ordonari realizeazã numai douã ordonãri, cea directã si cea inversã, însã prin rescrierea functiei se pot genera toate ordonãrile de scopuri posibile cu penalizãrile de timp corespunzatoare. Functia operatori-potriviti întoarce lista sortatã a operatorilor care pot satisface un scop într-o anumitã stare. Sortarea se face în ordine crescatoare a numãrului de preconditii nesatisfãcute. Celelalte functii au aceasi semnificatie cu a functiilor definite în Sectiunea 6.3.2.
(defun constructor (blocuri)
(let (operatori)
(dolist (a blocuri)
(dolist (b blocuri)
(unless (equal a b)
(dolist (c blocuri)
(unless (or (equal c a) (equal c b))
(push (operator-mutare a b c) operatori)))
(push (operator-mutare a 'masa b) operatori)
(push (operator-mutare a b 'masa) operatori))))
operatori))
(defun operator-mutare (a b c)
(make-operator :actiune `(executa (muta ,a de pe ,b pe ,c))
:preconditii `((liber ,a) (liber ,c) (,a pe ,b))
:lista-adaugari (mutare a b c)
:lista-eliminari (mutare a c b)))
(defun mutare (a b c)
(if (eq b 'masa) `((,a pe ,c)) `((,a pe ,c) (liber ,b))))
(defun satisfacere-scopuri (stare scopuri stiva)
(some #'(lambda (scopuri) (satisfacere stare scopuri stiva))
(ordonari scopuri)))
(defun satisfacere (stare scopuri stiva)
(let ((stare-curenta stare))
(when (and (every #'(lambda (g)
(setf stare-curenta (realizare-scop stare-curenta g stiva)))
scopuri)
(subsetp scopuri stare-curenta :test #'equal))
stare-curenta)))
(defun realizare-scop (stare scop stiva)
(cond ((member scop stare :test #'equal) stare)
((member scop stiva :test #'equal) nil)
(t (some #'(lambda (op) (aplica-operator stare scop op stiva))
(operatori-potriviti scop stare)))))
(defun operatori-potriviti (scop stare)
(sort (extrage scop *OPERATORI* #'potrivit-p)
#'<
:key #'(lambda (op)
(length (filtreaza #'(lambda (preconditie)
(not (member preconditie stare :test #'equal)))
(operator-preconditii op))))))
(defun ordonari (lista)
(if (> (length lista) 1) (list lista (reverse lista)) (list lista)))
Secventa de apeluri din continuare furnizeazã solutia problemei anomaliei lui Susmann prezentatã în Sectiunea 6.3.1.
(utilizeaza (constructor '(a b c)))
(strips '((c pe a) (a pe masa) (b pe masa) (liber c) (liber b) (liber masa))
'((c pe masa) (b pe c) (a pe b)))
Capitolul 7
Rationament inductiv si învãtare automatã
Una dintre caracteristicile esentiale ale inteligentei umane este capacitatea de a învãta. Învãtarea automatã este domeniul cel mai provocator al inteligentei artificiale si, în acelasi timp, cel mai rezistent încercãrilor de automatizare completã. S-au dat multe definitii ale procesului de învãtare, una dintre cele mai adecvate definitii din punct de vedere al inteligentei artificiale fiind cea a lui Herbert Simon: "Orice schimbare într-un sistem, care permite sistemului îmbunãtãtirea performantelor în rezolvarea ulterioarã a aceleiasi probleme sau a unei probleme similare, reprezintã un proces de învãtare".
La baza procesului de învãtare stau o serie de forme inferentiale nevalide cum ar fi: inductia, abductia sau analogia. O metodã de învãtare poate folosi una sau mai multe astfel de forme de inferentã cît si forme de inferentã validã, cum ar fi deductia.
Capitolul de fatã se ocupã de prezentarea unei metode de învãtare automatã numitã învãtare bazatã pe explicatii. Aceastã formã de învãtare, intens investigatã în ultimul timp de cercetãtorii domeniului, este o metodã de învãtare analiticã în care sistemul învatã pe baza unui singur exemplu semnificativ pe care îl explicã în termenii cunostintelor generale ale domeniului problemei. Pentru a situa învãtarea bazatã pe explicatii în contextul general al metodelor de învãtare în inteligenta artificialã, prima sectiune a acestui capitol prezintã o clasificare a acestor metode.
7.1 Metode de învãtare
Existã douã motive principale pentru care este interesant sã se studieze procesul si metodele de învãtare. Primul motiv, de ordin epistemologic, este acela de a întelege un comportament inteligent esential uman. Al doilea motiv, de ordin pragmatic si fundamental pentru cercetãrile de inteligentã artificialã, este acela de a putea crea programe care sã-si construiascã singure baza de cunostinte si care, eventual, sã poatã sintetiza alte componente de program. În acest fel, se poate elimina una din marile limitãri de eficientã ale dezvoltãrii sistemelor de inteligentã artificialã, si anume procesul de achizitie a cunostintelor.
7.1.1 Reguli de inferentã utilizate în învãtare
Regulile de inferentã valide (deductive), de tipul celor prezentate în Capitolul 3, reprezintã inferente care garanteazã adevãrul formulei inferate dacã formulele asupra cãrora se aplicã regula sînt adevãrate. În procesul de învãtare se folosesc însã, preponderent, reguli de inferentã nevalide (nedeductive), care nu garanteazã validitatea formulei obtinute prin aplicarea lor. Cu toate acestea, inferentele nedeductive pot fi aplicate cu succes în numeroase cazuri pentru rezolvarea problemelor care includ componente de învãtare. În continuare sînt prezentate cele mai importante reguli de inferentã nevalide.
Inferenta inductivã se bazeazã pe ideea cã o proprietate adevãratã pentru o submultime de obiecte dintr-o clasã este adevãratã pentru toate obiectele din acea clasã. Inferenta inductivã are forma:
![]()
De exemplu, dupã ce se constatã cã cele mai multe lebede sînt albe, se poate infera prin inductie cã toate lebedele sînt albe, desi existã si lebede negre, cum ar fi unele dintre cele care cresc în Australia.
Inferenta inductivã se poate generaliza la sintetizarea unei întregi reguli de deductie pe baza exemplelor, astfel:
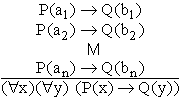
Inferenta abductivã se bazeazã pe utilizarea cunostintelor cauzale pentru a explica sau a justifica o concluzie, posibil invalidã. Inferenta abductivã are urmãtoarea formã:
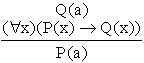
De exemplu, din formulele ![]() si
si ![]() se poate infera abductiv
cã iarba este udã deoarece a plouat peste ea. Cu toate acestea, abductia nu
poate fi aplicatã consistent în oricare caz. De exemplu, din formulele
se poate infera abductiv
cã iarba este udã deoarece a plouat peste ea. Cu toate acestea, abductia nu
poate fi aplicatã consistent în oricare caz. De exemplu, din formulele ![]() si
si ![]() , unde cea de a doua formulã exprimã faptul cã toti pacientii
internati în pavilionul 5 au gripã, nu se poate infera cã Maria are gripã
deoarece este internatã acolo. Acest lucru se întîmplã deoarece inferenta
abductivã poate fi aplicatã pentru a genera explicatii numai atunci cînd
implicatia
, unde cea de a doua formulã exprimã faptul cã toti pacientii
internati în pavilionul 5 au gripã, nu se poate infera cã Maria are gripã
deoarece este internatã acolo. Acest lucru se întîmplã deoarece inferenta
abductivã poate fi aplicatã pentru a genera explicatii numai atunci cînd
implicatia ![]() indicã o relatie
cauzalã.
indicã o relatie
cauzalã.
Inferenta analogicã este o formã de inferentã bazatã pe experientã si se bazeazã pe ideea conform cãreia situatii sau entitãti care tind sã fie asemãnãtoare sub anumite aspecte sînt asemãnãtoare în general. Inferenta analogicã este de fapt o combinatie a celorlalte forme de inferentã: abductive, deductive si inductive. Inferenta analogicã are forma:
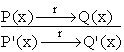
7.1.2 Clasificarea tipurilor de învãtare
Plecînd de la definitia învãtãrii datã de H. Simon, se poate construi un model general al procesului de învãtare, care permite si clasificarea principalelor tipuri de învãtare automatã. Clasificarea prezentatã în aceastã sectiune se bazeazã pe cea propusã de Feigenbaum si are ca scop situarea si reliefarea locului învãtãrii bazate pe explicatii în contextul general al învãtãrii automate.
Un sistem de învãtare automatã poate fi vãzut ca fiind format din cinci componente principale, asa cum se prezintã în Figura 7.1. Modul de functionare al unui sisem de învãtare automatã este descris, pe scurt, în continuare. Mediul oferã stimuli sau informatie elementului de învãtare care foloseste aceastã informatie pentru a îmbunãtãti cunostintele (explicite) din baza de cunostinte. Aceste cunostinte sînt utilizate de elementul de prelucrare în rezolvarea problemei. Elementul de prelucrare este de fapt motorul de inferentã al sistemului si formeazã împreunã cu baza de cunostinte componenta de rezolvare a problemelor. Calitatea rezolvãrii problemei este analizatã de componenta de evaluare a prelucrãrii (componenta criticã) si rezultatele acestei analize sînt transmise elementului de învãtare. Infomatia sintetizatã în procesul de rezolvare a problemei poate servi ca reactie inversã pentru elementul de învãtare. Mediul, baza de cunostinte si elementul de prelucrare determinã natura problemei particulare de învãtare si functiile particulare pe care elementul de învãtare trebuie sã le realizeze. În figurã, sãgetile indicã directia predominantã a fluxului informational într-un sistemul de învãtare automatã.
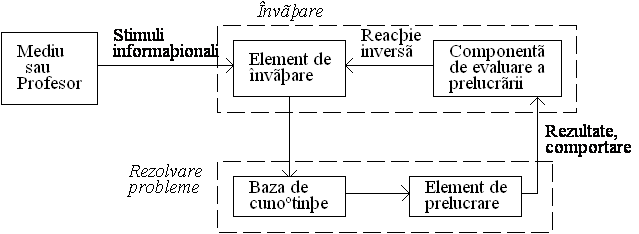
Figura 7.1 Modelul conceptual al unui sistem de învãtare automatã
Mediul influenteazã procesul de învãtare prin nivelul si calitatea informatiei oferite. Nivelul informatiei se referã la gradul de generalitate al acesteia. Rolul principal al elementului de învãtare este acela de a reduce diferenta dintre nivelul informatiei transmise de mediu si nivelul informatiei utilizate de elementul de prelucrare în rezolvarea problemei. Dacã nivelul informatiei oferite de mediu elementului de învãtare este abstract, acesta trebuie sã detalieze informatia astfel încît elementul de prelucrare sã o poatã utiliza în rezolvarea unei probleme particulare. Dacã elementului de învãtare îi sînt oferite informatii specifice despre o problemã particularã, el trebuie sã generalizeze aceastã informatie pentru a ghida elementul de prelucrare în rezolvarea unei clase mai largi de probleme. În timpul procesului de învãtare, elementul de învãtare formeazã ipoteze asupra modului în care trebuie redusã diferenta. Pentru a valida aceste ipoteze, el trebuie sã primeascã o reactie pe baza cãreia sã evalueze ipotezele formulate. În functie de diferenta între nivelul informatiei oferite de mediu si cel al informatiei din baza de cunostinte, se pot identifica cele patru tipuri de învãtare prezentate în continuare.
Învãtarea prin memorare este caracterizatã de faptul cã nivelul informatiei oferite de mediu coincide cu nivelul informatiei utilizate de elementul de prelucrare, deci al problemei de rezolvat. În acest tip de învãtare elementul de învãtare nu trebuie sã formuleze ipoteze, ci doar sã memoreze informatia pentru a o utiliza ulterior. Un exemplu de sistem de învãtare prin memorare este programul de jucat sah al lui Samuel [1967], care îsi îmbunãtãteste performantele în jocul de sah prin memorarea fiecãrei pozitii evaluate si a mutãrii considerate. Pozitiile anterior memorate sînt utilizate pentru cresterea vitezei si a numãrului de mutãri investigate în avans.
Învãtarea prin instruire este caracterizatã de nivelul abstract, general, al informatiei oferite de mediu, elementului de învãtare revenindu-i sarcina de a formula ipoteze asupra detaliilor care lipsesc în rezolvarea problemei. Prin formularea ipotezelor, elementul de învãtare transformã informatia primitã într-o formã utilizabilã de elementul de prelucrare. Aceastã transformare, care presupune întelegerea si interpretarea cunostintelor de nivel ridicat si corelarea lor cu informatiile existente deja în sistem, se numeste operationalizare. Exemple de astfel de sisteme sînt: programele de jucat cupe FOO si BAR [Mostow,1983], si programul TEIRESIAS care învatã reguli de tipul celor existente în sistemul expert medical MYCIN. De exemplu, sistemul FOO trebuie sã operationalizeze indicatii strategice de tipul "Evitã sã acumulezi puncte" în strategii specifice de tipul "Joacã o carte mai micã decît orice carte jucatã pînã în acest moment".
Învãtarea prin inductie (din exemple) este caracterizatã prin nivelul scãzut al informatiei oferite de mediu. În acest tip de învãtare, elementul de învãtare trebuie sã formuleze ipoteze de generalizare a exemplelor în reguli de nivel mai ridicat, reguli care pot fi aplicate în ghidarea elementului de prelucrare în rezolvarea unei clase mai largi de probleme. De exemplu, un program care învatã conceptul de pereche într-un joc de cãrti trebuie sã sintetizeze din douã exemple de tipul:
4 - 4 5 7
7 6 - 6 9
conceptul de descriere a unei perechi: douã cãrti de acelasi rang, indiferent de culoare si de valoarea celorlalte cãrti. Învãtarea prin inductie include mai multe instante ale învãtãrii, cum ar fi învãtarea conceptelor unice, învãtarea conceptelor multiple, învãtarea secventelor de operatori aplicati în timpul rezolvãrii problemelor. Învãtarea bazatã pe explicatii este tot o formã de învãtare din exemple, dar care include si componente de învãtare prin instruire, respectiv operationalizare.
Învãtarea
prin analogie este caracterizatã prin faptul cã informatia oferitã de mediu
este relevantã numai pentru probleme similare. Elementul de învãtare trebuie sã
descopere analogia si sã formuleze ipoteze despre reguli similare
aplicabile problemei curente. Învãtarea
prin analogie, putin studiatã pînã în prezent, ridicã probleme conceptuale
deosebite, de exemplu: ce este analogia, cum sînt recunoscute analogiile, cum
se transferã cunostintele relevante, etc. Se considerã exemplul unui sistem de
învãtare prin analogie confruntat cu o problemã de hidraulicã care cere sã se
calculeze debitul printr-o conductã de iesire QC, aflatã la jonctiunea (de tip Y) a douã conducte de
intrare QA si QB. Baza de cunostinte a sistemului nu contine
cunostinte de hidraulicã dar contine cunostinte de electrotehnicã. În procesul
de învãtare prin analogie se indicã sistemului faptul cã "debitul este
analog curentului electric". Aceastã analogie sugereazã cã se pot folosi
anumite cunostinte despre curentul electric pentru a genera (învãta) reguli
utile în rezolvarea problemei debitului. În particular, sistemul poate folosi
ca punct de plecare în rezolvarea problemei de hidraulicã, prima lege a lui
Kirchhoff care statueazã cã pentru o jonctiune electricã de tip Y, intensitatea
curentului de iesire printr-o ramurã IC
este egalã cu suma intensitãtilor curentilor IA
si IB de intrare în jonctiune
(nod). Prin analogie, sistemul poate
învãta o regulã de calcul a debitului prin conducta de iesire: ![]() .
.
Structura si functiile elementului de prelucrare depind de complexitatea tipului problemei de rezolvat: clasificare sau predictie pe baza unui singur concept, sinteza conceptelor multiple, planificare prin sinteza unor secvente de actiuni. O componentã importantã care influenteazã elementul de prelucrare este componenta de evaluare a prelucrãrii deoarece elementul de prelucrare trebuie sã aibã o posibilitate de a valida sau corecta ipotezele fãcute. Anumite sisteme de învãtare au cunostinte separate pentru evaluare, în timp ce alte sisteme asteaptã de la mediu sau profesor un standard de evaluare pentru a valida ipoteza curentã. De exemplu, în sistemele de învãtare din exemple standardul de evaluare, oferit de profesor, este clasificarea corectã a fiecãrei noi instante a problemei.
7.2 Învãtarea bazatã pe explicatii
Sistemele de învãtare inductivã se bazeazã pe abstractizarea caracteristicilor comune ale exemplelor, instante pozitive sau instante negative ale unui concept, pentru a sintetiza descrierea generalã a unui concept. În ultimul timp, cercetãrile în domeniul învãtãrii din exemple s-au orientat si spre metode analitice, conform cãrora instantele unui concept reprezintã mai mult decît o multime independentã de caracteristici. Una dintre aceste metode analitice, intens investigatã recent, este învãtarea bazatã pe explicatii. Învãtarea bazatã pe explicatii este o formã a învãtãrii din exemple în care sistemul învatã un concept general pornind de la o singurã instantã a conceptului. Generalizarea conceptului pe baza exemplului se face utilizînd o cantitate semnificativã de cunostinte despre domeniul problemei de rezolvat.
Metoda învãtãrii bazate pe explicatii poate generaliza, pornind de la un singur exemplu, prin analiza motivelor pentru care exemplul este o instantã a conceptului. Explicatia identificã caracteristicile relevante ale exemplului, care constituie conditii suficiente pentru descrierea conceptului, apoi aceastã explicatie este transformatã în reguli operationale de recunoastere a conceptului. Puterea acestei metode izvorãste din utilizarea teoriei domeniului pentru a ghida procesul de cãutare [Minton,s.a.,1989].
Abordarea traditionalã a învãtãrii inductive, cunoscutã si sub numele de învãtare empiricã sau învãtare bazatã pe similitudini, necesitã investigarea a numeroase exemple ale unui concept pentru a determina caracteristicile lor comune. Cercetãtorii care au studiat aceastã perspectivã a învãtãrii au presupus cã sistemul poate învãta din exemple, fãrã a se baza pe o cantitate semnificativã de cunostinte ale domeniului. Abordarea alternativã a învãtãrii bazate pe explicatii generalizeazã exemplul unic, utilizînd cunostinte extinse despre domeniu. Din acest motiv, învãtarea bazatã pe explicatii este analiticã si intensivã din punct de vedere al utilizãrii cunostintelor, în timp ce metodele inductive sînt slabe în raport cu exploatarea cunostintelor.
7.2.1 Tipuri de învãtare bazatã pe explicatii
Învãtarea bazatã pe explicatii a fost identificatã ca metodã distinctã de învãtare abia la începutul anilor '80 de DeJong si Mitchell, DeJong [1981] fiind cel care a dat numele metodei. Dezvoltarea metodei a început însã înaintea acestei perioade prin programele de învãtare analiticã: STRIPS [Fikes,Nilson,1972], HACKER [Sussman,1975] si programul de jucat poker al lui Waterman [1970], programe care îsi îmbunãtãtesc comportarea pe baza experientei acumulate în rezolvarea problemelor.
Notiunea de învãtare bazatã pe explicatii a fost utilizatã pentru a caracteriza diverse abordãri ale învãtãrii. Cu toate acestea, cele mai multe abordãri pot fi întelese în termenii unei proceduri care contine douã etape de bazã. În prima etapã se construieste o explicatie a functionãrii sau a caracteristicilor exemplului dat, în termenii cunostintelor domeniului. Aceastã explicatie trebuie sã surprindã principiile generale exprimate de exemplu. Cea de a doua etapã constã în analiza explicatiei si a exemplului în scopul construirii conceptului general sau a regulii generale. Caracteristicile si restrictiile exemplului sînt generalizate cît mai mult posibil, atît timp cît acestea rãmîn consistente cu explicatia. Generalizarea va include si alte exemple (necunoscute) care pot fi întelese utilizînd aceeasi explicatie si care au aceleasi principii sau caracteristici. În concluzie, metoda utilizeazã cunostintele domeniului problemei pentru a determina ce caracteristici si restrictii ale unui exemplu pot fi generalizate, generalizarea fiind justificatã.
Desi învãtarea bazatã pe explicatii este privitã, preponderent, ca o metodã de realizare a generalizãrii, ea poate fi vãzutã si din alte puncte de vedere. Astfel, învãtarea bazatã pe explicatii poate fi consideratã din patru perspective [Ellman,1989]: generalizare explicatã, grupare, operationalizare si analogie justificatã. Aceste patru perspective permit clasificarea diverselor sisteme care utilizeazã metoda.
Generalizarea explicatã este abordarea care urmãreste îndeaproape cele douã etape ale procedurii de învãtare bazatã pe explicatii. Sistemele GENESIS [DeJong,1983;Mooney,DeJong, 1985] si LEX-II [Mitchell,s.a.,1983] sînt exemple de programe care realizeazã generalizare explicatã si vor fi prezentate în Sectiunea 7.3. Tot în aceeasi sectiune se prezintã o abordare unitarã a generalizãrii explicate si a învãtãrii bazate pe explicatii, datoratã lui Mitchell, Keller si Kedar-Cabelli [1986].
Învãtarea prin grupare este o metodã de învãtare în timpul rezolvãrii problemelor în care o secventã liniarã sau arborescentã de operatori, capabilã sã transforme o stare initialã într-o stare finalã a problemei, este "compilatã" într-un singur operator care are acelasi efect ca întreaga secventã. Componenta de învãtare din sistemul STRIPS [Fikes,Nilson,1972], prezentatã în Sectiunea 7.2.3, si sistemul SOAR [Laird,s.a.,1987] sînt exemple de programe care utilizeazã învãtarea prin grupare.
Învãtarea prin operationalizare, care poate fi consideratã atît o formã a învãtãrii prin instruire cît si învãtare bazatã pe explicatii, constã într-un proces de transformare a unei reguli neoperationale, sau a unui concept neoperational, într-o regulã operationalã, respectiv concept operational. Conceptele sau regulile sînt considerate a fi operationale în raport cu baza de cunostinte a sistemului, dacã sînt exprimate în termenii actiunilor si faptelor cunoscute de sistem. Sistemul FOO [Mostow,1983] este un exemplu de program care realizeazã operationalizarea si va fi prezentat pe scurt în sectiunea urmãtoare.
Învãtarea prin analogie justificatã constã în gãsirea unei proceduri de rationament analogic pe baza exemplelor. Fiind datã o bazã de cunostinte BC, un exemplu X si un exemplu analog Y, trebuie gãsitã o caracteristicã C astfel încît, dacã C(X) este adevãratã, se poate infera si C(Y) adevãratã. Cea mai semnificativã abordare a metodei este analogia derivationalã [Carbonell,1983] în care se utilizeazã derivarea conceptului din exemplu pentru a ghida rationamentul analogic într-o manierã similarã cu cea în care explicatia este folositã pentru a ghida generalizarea.
7.2.2 Învãtare prin operationalizare
Tremenul de operationalizare poate fi definit ca procesul de traducere a unei expresii neoperationale într-una operationalã, din punct de vedere al informatiei continute în baza de cunostinte a unui program. Programul FOO [Mostow,1983], cu succesorul sãu BAR, dezvoltate de Mostow, au fost construite în intentia de a operationaliza sfaturile în jocul de cupe. Pe scurt, jocul de cupe contine urmãtoarele reguli: fiecare jucãtor are 13 cãrti; la fiecare levatã trebuie jucatã o carte de aceeasi culoare cu cea jucatã de primul jucãtor; jucãtorul care a jucat cartea cea mai mare pentru o culoare cîstigã levata; fiecare carte de cupã reprezintã un punct si jocul este cîstigat de jucãtorul care acumuleazã un numãr minim de puncte.
Pentru a explica metoda de învãtare utilizatã de programul FOO, se considerã exemplul sfatului "Evitã sã acumulezi puncte". Acest sfat este considerat neoperational deoarece nu este exprimat în termenii actiunilor pe care le poate executa un jucãtor; regulile jocului nu permit unui jucãtor sã refuze cîstigarea unei levate numai datoritã faptului cã aceasta contine puncte. Un alt exemplu de sfat neoperational este "Nu ataca o carte de o culoare inexistentã la un alt jucãtor"; acest sfat este neoperational deoarece necesitã cunoasterea continutului cãrtilor nejucate ale celorlalti jucãtori, lucru de asemenea interzis de regulile jocului.
Un student care doreste sã învete acest joc si sã operationalizeze sfatul "Evitã sã acumulezi puncte" poate proceda dupã cum urmeazã, privind exemplul unui joc si cãrtile unui jucãtor, considerat profesor. Atacantul levatei curente a jucat 8, iar profesorul, care este al doilea jucãtor, are în acest moment urmãtoarele cãrti:
J 7 Q 7 4 2 A 10 J 9
Profesorul poate juca una din cele patru cãrti de cupã si el alege 7. Studentul poate explica alegerea profesorului prin urmãtorul rationament:
Levata contine cupe. Cîstigãtorul levatei va acumula puncte nedorite. De aceea este bine sã se joace o carte care nu cîstigã levata.
Jucarea unei cãrti mari va minimiza sansele de a cîstiga levatele ulterioare.
Profesorul a ales 7 deoarece este cea mai mare carte de cupã care garanteazã pierderea levatei.
Dupã explicarea exemplului, studentul poate sã realizeze cã aceeasi linie de rationament poate fi aplicatã si altor situatii. Explicatia poate fi generalizatã pentru orice secventã de cãrti de cupã. Generalizînd explicatia prin eliminarea faptelor nerelevante, studentul poate sintetiza regula "Într-o levatã care contine cupe, joacã cea mai mare carte de cupã care garanteazã pierderea levatei". Utilizînd aceastã regulã, studentul poate alege cartea care trebuie jucatã într-o nouã levatã. Se observã cã modul de învãtare aplicat de student este asemãnãtor procedurii cu douã etape din învãtarea bazatã pe explicatii. Ca rezultat, se obtine o regulã operationalã a sfatului "Evitã sã acumulezi puncte".
Programul FOO aplicã aceeasi metodã de învãtare. Pentru a transforma un sfat într-o regulã operationalã, programul foloseste diverse tipuri de cunostinte. O parte a bazei de cunostinte contine o multime de reguli de transformare a problemei, independente de domeniu. Fiecare regulã are o componentã actiune (partea dreaptã a regulii) care specificã cum trebuie rescrisã o expresie ce reprezintã un sfat, si o componentã care indicã conditiile de aplicare a regulii (partea stîngã a regulii). Exemple de astfel de reguli sînt:
Explicitarea definitiei
conceptului. Dacã F este un concept definit ca ![]() atunci înlocuieste
expresia
atunci înlocuieste
expresia ![]() cu rezultatul substitutiei
lui
cu rezultatul substitutiei
lui ![]() cu
cu ![]() pentru orice aparitie
din e.
pentru orice aparitie
din e.
Aproximarea 1 a unui
predicat. Fiind datã o expresie ce contine ![]() , unde P este un predicat, înlocuieste
, unde P este un predicat, înlocuieste ![]() cu expresia
cu expresia ![]() .
.
Aproximarea 2 a unui
predicat. Fiind datã o expresie ce contine ![]() , unde P este un predicat, înlocuieste
, unde P este un predicat, înlocuieste ![]() cu expresia
cu expresia ![]() , unde
, unde ![]() este adevãratã, cu
exceptia cazului în care se stie cã
este adevãratã, cu
exceptia cazului în care se stie cã ![]() este falsã.
este falsã.
Regulile de transformare sînt aplicate sfatului initial, acesta fiind transformat progresiv într-o formã care satisface conditia de a fi operationalã. Baza de cunostinte contine, de asemenea, definitii de concepte specifice domeniului, de exemplu:
point-cards = (lambda ( ) (set-of C (cards) (has-points C)))
avoid = (lambda (E S) (achieve (not (during S E))))
trick = (lambda ( ) (scenario (each P (players) (play-card P)) (take-trick (trick-winner))))
De exemplu, sfatul "Evitã sã acumulezi puncte" este reprezentat initial prin expresia:
(avoid (take-points me) (trick))
care poate fi interpretatã astfel: evitã o situatie în care jucãtorul acumuleazã puncte în timpul levatei curente. Pentru a traduce aceastã expresie, programul FOO utilizeazã regula de explicitare a definitiei conceptului si definitiile conceptelor avoid si trick. Apoi programul aplicã diverse transformãri si obtine expresia intermediarã:
(achieve (not (and (= (trick-winner me) (trick-has-points)))))
Aceastã expresie are urmãtoarea semnificatie: "Încearcã sã nu cîstigi o levatã care contine cãrti ce au asociate puncte". Transformînd în continuare expresia, sistemul obtine forma finalã, operationalã a expresiei:
(achieve (=> (and (in-suit-led (card-of me))
(possible (trick-has-points)))
(low (card-of me))))
Expresia are semnificatia: "Joacã o carte micã de culoarea jucatã într-o levatã care poate contine cãrti cu puncte".
Programele FOO si BAR diferã prin strategia de control utilizatã la alegerea regulilor de transformare a sfaturilor. Programul FOO lasã utilizatorul sã aleagã regulile de transformare adecvate, în timp ce programul BAR aplicã strategia analizei bazate pe modalitãti pentru a determina secventa de reguli de aplicat, dar necesitã din cînd în cînd interventia utilizatorului.
7.2.3 Învãtare utilizînd macrooperatorii
Sistemul de planificare automatã STRIPS [Fikes,Nilsson,1971], prezentat în Sectiunea 6.3, este cel mai important precursor al metodei de învãtare bazatã pe explicatii. În sistemul STRIPS, dupã rezolvarea unei probleme, componenta de învãtare preia planul sintetizat si îl memoreazã sub forma unui macrooperator. Un macrooperator specificã o secventã de operatori care poate fi vãzutã ca un singur operator generalizat. Preconditiile macrooperatorului sînt reprezentate de starea initialã a problemei, iar postconditiile lui reprezintã starea scop satisfãcutã prin executarea planului, deci prin rezolvarea problemei. La întîlnirea unei noi probleme de planificare pentru care apare necesitatea realizãrii unui scop sau subscop similar cu cel îndeplinit de macrooperator se poate aplica direct macrooperatorul sintetizat, pentru care lista preconditiilor este satisfãcutã. Se evitã asttfel reluarea procesului de cãutare pentru satisfacerea scopului sau subscopului. În acest fel, sistemul STRIPS include o componentã de învãtare în timpul rezolvãrii problemelor.
Se considerã sistemul STRIPS, cu specificatiile de functionare si multimea de operatori prezentati în Sectiunea 6.3, si problema de planificare definitã în Figura 7.2.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
ARMEMPTY
Figura 7.2 Problemã de planificare utilizatã în sinteza unui macrooperator
Planul sintetizat de sistemul STRIPS pentru rezolvarea acestei probleme este:
![]()
Dupã rezolvare, pe baza planului Plan, componenta de învãtare a sistemului construieste macrooperatorul:
MACROOP1 LP: ![]()
![]()
LE: ![]()
LA: ![]()
Acest macrooperator nu este însã deosebit de util, deoarece este putin probabil ca sistemul sã întîlneascã exact aceeasi stare initialã si stare finalã, pentru care sã poatã aplica macrooperatorul sintetizat. Din acest motiv sistemul generalizeazã macrooperatorul prin înlocuirea constantelor cu variabile. Pentru exemplul anterior, macrooperatorul generalizat este format din operatorii:
![]()
unde x , x si x sînt variabile. Macrooperatorul generalizat poate fi descris astfel
MACROGEN1 LP: ![]()
![]()
LE: ![]()
LA: ![]()
Generalizarea prin înlocuirea
constantelor cu variabile poate duce însã la suprageneralizare. Desi în cele
mai multe cazuri generalizarea se face prin înlocuirea constantelor cu
variabile, existã cazuri în care anumite constante nu trebuie sã fie înlocuite
cu variabile, ci trebuie sã rãmînã constante în macrooperator. Pentru a ilustra
aceastã situatie, se considerã rezolvarea problemei anterioare, în conditiile
în care se adaugã operatorul specific ![]() care aseazã un bloc
oarecare x deasupra blocului B. Acest operator se defineste astfel:
care aseazã un bloc
oarecare x deasupra blocului B. Acest operator se defineste astfel:
![]() LP:
LP: ![]()
LE: ![]()
LA: ![]()
În aceste conditii, sistemul sintetizeazã, de exemplu, planul
![]()
Generalizînd acest plan, planul generalizat si macrooperatorul obtinut sînt:
![]()
MACROGEN2 LP: ![]()
![]()
LE: ![]()
LA: ![]()
Cum se comportã sistemul care are la dispozitie acest macrooperator în cazul în care trebuie sã rezolve problema descrisã în Figura 7.3?
Macrooperatorul MACROGEN2,
memorat anterior, pare foarte potrivit pentru a rezolva aceastã problemã, cu
instantierile ![]() ,
, ![]() ,
, ![]() . Deoarece preconditiile lui sînt satisfãcute, se construieste
planul
. Deoarece preconditiile lui sînt satisfãcute, se construieste
planul
![]()
![]()
![]()
![]()
![]()
![]()
![]()
ARMEMPTY ![]()
![]()
![]()
![]()
![]()
![]()
![]()
Figura 7.3 Problemã pentru care nu se poate aplica
macrooperatorul MACROGEN2
Dar acest plan nu se poate executa. Primii trei pasi sînt
posibili, dar ![]() nu poate fi executat,
deoarece
nu poate fi executat,
deoarece ![]() este o preconditie a
operatorului STACKONB care nu este îndeplinitã. Chiar dacã blocul B ar fi liber
si planul s-ar putea executa, efectul lui nu este cel dorit. Aceastã comportare
apare datoritã faptului cã postconditiile macrooperatorului au fost suprageneralizate.
Operatorul MACROGEN2 este capabil sã aseze blocuri numai peste blocul B, deci
transformarea constantei B în variabila x
a condus la o suprageneralizare.
este o preconditie a
operatorului STACKONB care nu este îndeplinitã. Chiar dacã blocul B ar fi liber
si planul s-ar putea executa, efectul lui nu este cel dorit. Aceastã comportare
apare datoritã faptului cã postconditiile macrooperatorului au fost suprageneralizate.
Operatorul MACROGEN2 este capabil sã aseze blocuri numai peste blocul B, deci
transformarea constantei B în variabila x
a condus la o suprageneralizare.
În realitate, procedura de generalizare a macrooperatorilor sintetizati de sistemul STRIPS este mai complicatã decît simpla înlocuire a constantelor cu variabile. Sistemul trebuie sã analizeze utilitatea fiecãrui pas de plan generalizat si sã verifice preconditiile operatorilor generalizati de componenta de învãtare [Ellman,1989].
Dupã sintetizarea unui plan de satisfacere a scopului dat, sistemul STRIPS construieste o structurã de date numitã tabela triunghiularã. Tabela triunghiularã descrie structura planului într-un format adecvat procedurii de generalizare, i.e. de învãtare. Aceastã tabelã este utilã deoarece aratã dependenta preconditiilor operatorilor de efectul altor operatori si de faptele existente în starea initialã. Formulele marcate cu simbolul * într-o astfel de tabelã indicã o astfel de dependentã. Procedura de construire a acestei tabele pentru o secventã de operatori P, de lungime N, este cea descrisã în continuare, tabela triunghiularã fiind notatã TABT.
Algoritm: Construirea tabelei triunghiulare în sistemul STRIPS
1. Numeroteazã
liniile tabelei de la 1 la ![]() si coloanele tabelei
de la 0 la N
si coloanele tabelei
de la 0 la N
2. pentru ![]() pînã la N executã
pînã la N executã
![]()
3. pentru ![]() pînã la N executã
pînã la N executã
Plaseazã
în ![]() toate faptele din
starea initialã care sînt adevãrate înaintea aplicãrii operatorului i
toate faptele din
starea initialã care sînt adevãrate înaintea aplicãrii operatorului i
4. Plaseazã în ![]() faptele din starea initialã
care rãmîn adevãrate în starea finalã
faptele din starea initialã
care rãmîn adevãrate în starea finalã
5. pentru ![]() pînã la
pînã la ![]() executã
executã
pentru ![]() pînã la N executã
pînã la N executã
Plaseazã
în ![]() faptele adãugate de
operatorul
faptele adãugate de
operatorul ![]() care sînt adevãrate înaintea
aplicãrii operatorului
care sînt adevãrate înaintea
aplicãrii operatorului ![]()
6. pentru ![]() pînã la N executã
pînã la N executã
Plaseazã în ![]() faptele adãugate de
operatorul
faptele adãugate de
operatorul ![]() care rãmîn adevãrate în starea finalã
care rãmîn adevãrate în starea finalã
7. pentru ![]() pînã la N executã
pînã la N executã
Marcheazã cu *
fiecare fapt din linia i a tabelei TABT care a fost utilizat în demonstrarea preconditiilor
operatorului ![]()
sfîrsit.
Pentru problema de planificare
descrisã în Figura 7.4 (a), tabela triunghiularã construitã de sistem este cea
din Figura 7.4 (b). Faptul ![]() din
din ![]() , marcat cu *, indicã dependenta preconditiilor operatorului
, marcat cu *, indicã dependenta preconditiilor operatorului ![]() de faptele adãugate de
operatorul
de faptele adãugate de
operatorul ![]() . Faptul
. Faptul ![]() din
din ![]() , marcat cu *, indicã dependenta preconditiilor operatorului
, marcat cu *, indicã dependenta preconditiilor operatorului ![]() de faptele din starea
initialã.
de faptele din starea
initialã.
![]()
![]()
![]()
![]()
ARMEMPTY
![]()
![]()
![]()
Figura 7.4 (a) Planul pentru care se construieste tabela triunghiularã
|
| |||
|
| |||
|
1 |
|
1. | |
|
| |||
|
*ARMEMPTY | |||
|
| |||
|
2 |
|
|
2. |
|
| |||
|
|
|
||
|
3 |
|
ARMEMPTY |
|
|
0 |
1 |
2 |
Figura 7.4 (b) Tabela triunghiularã asociatã unui plan
Existã douã criterii utilizate în generalizarea planului reprezentat printr-o tabelã triunghiularã. Primul criteriu implicã mentinerea dependentelor între operatori. Operatorul i va adãuga un fapt în tabela generalizatã care va permite aplicarea operatorului j, dacã si numai dacã existã aceeasi dependentã între operatorii i si j în tabela originalã. Cel de al doilea criteriu cere ca preconditiile operatorilor din tabela generalizatã sã poatã fi dovedite ca adevãrate folosind aceleasi demonstratii de verificare a preconditiilor din planul original. Algoritmul de generalizare a planului folosit în sistemul STRIPS este prezentat în continuare.
Algoritm: Generalizarea planului în sistemul STRIPS
1. Generalizeazã tabela triunghiularã
1.1. Înlocuieste fiecare constantã distinctã din coloana 0 a tabelei TABT cu o variabilã distinctã
1.2. pentru
![]() pînã la N executã
pînã la N executã
Înlocuieste fiecare formulã din coloana i a tabelei TABT cu formula (neinstantiatã) corespunzãtoare din lista adãugãrilor operatorului i
1.3. Redenumeste variabilele astfel încît formulele obtinute prin aplicarea operatorilor distincti sã continã variabile cu nume diferite
2. Executã din nou validarea preconditiilor utilizînd demonstratii similare cu cele ale planului original
2.1. Fiecare nouã validare a unei preconditii se va face pe baza formulelor generalizate marcate cu *
2.2. Fiecare nouã demonstratie considerã aceleasi perechi de formule în rezolutie si aceleasi perechi de literali în unificare
2.3. Substitutiile generate în timpul unificãrii sînt aplicate întregii tabele
sfîrsit.
Algoritmul de generalizare a planului foloseste atît tabela triunghiularã cît si demonstratiile preconditiilor operatorilor fãcute în timpul sintezei planului initial. Pasul 1 al algoritmului înlocuieste constantele cu variabile, putînd duce la suprageneralizare. Pasul 2 restrictioneazã tabela generalizatã în functie de cele douã criterii mentionate anterior, eliminînd astfel anomalii de genul celei prezentate în Figura 7.3. Aplicarea acestui algoritm pentru tabela triunghiularã din Figura 7.4 (b) va genera tabela generalizatã din Figura 7.5. Exemple suplimentare de aplicare a algoritmului sînt date în Sectiunea 7.4.
|
| |||
|
| |||
|
1 |
|
1. | |
|
| |||
|
*ARMEMPTY | |||
|
| |||
|
2 |
|
|
2. |
|
| |||
|
|
|
||
|
3 |
|
ARMEMPTY |
|
|
0 |
1 |
2 |
Figura 7.5 Tabela triunghiularã generalizatã
Dupã ce s-a obtinut tabela generalizatã a unui plan, se
poate construi macrooperatorul corespunzãtor, avînd ca preconditii starea initialã
a problemei date. Lista eliminãrilor acestui macrooperator se obtine fãcînd
diferenta între continutul celulelor ![]() si
si ![]() din tabela
generalizatã, iar lista adãugãrilor se obtine prin cumularea continutului
celulelor
din tabela
generalizatã, iar lista adãugãrilor se obtine prin cumularea continutului
celulelor ![]() ,
, ![]() . Sistemul mentine tabela triunghiularã asociatã unui macrooperator,
memorînd astfel faptul cã acest operator nu poate fi executat printr-un singur
pas de plan. Avantajul evident al utilizãrii macrooperatorilor este reducerea
spatiului de cãutare al rezolvãrii problemei de planificare.
. Sistemul mentine tabela triunghiularã asociatã unui macrooperator,
memorînd astfel faptul cã acest operator nu poate fi executat printr-un singur
pas de plan. Avantajul evident al utilizãrii macrooperatorilor este reducerea
spatiului de cãutare al rezolvãrii problemei de planificare.
Folosirea macrooperatorilor poate fi utilã si în cazul în care se rezolvã o problemã de planificare neliniarã. Un macrooperator poate contine operatori care, luati în parte, pot duce la distrugerea unor scopuri anterior îndeplinite, dar tot acelasi macrooperator poate contine alti operatori ce eliminã distrugerile. Vãzut din punct de vedere global macrooperatorul nu afecteazã scopurile anterior satisfãcute.
Se considerã, de exemplu, problema mozaicului de 9 piese. Dupã asezarea primelor patru piese în pozitiile finale, asezarea celei de a cincea piese nu se poate face fãrã a distruge temporar asezarea primelor patru. Dacã în timpul cãutãrii algoritmul foloseste o euristicã bazatã pe distanta pînã la scop, alegerea unui operator care modificã asezãrile finale va fi evaluatã ca mai putin interesantã. Existenta unui macrooperator care aseazã cea de a cincea piesã la locul ei, nemodificînd pozitiile primelor patru, va implica alegerea preferentialã a acestui macrooperator de cãtre functia euristicã de evaluare. Aceeasi situatie se întîlneste si în rezolvarea problemei cubului lui Rubik.
Din punct de vedere al perspectivei învãtãrii bazate pe explicatii, sinteza si memorarea unui macrooperator (plan) pentru realizarea unui scop explicã de ce scopul respectiv poate fi satisfãcut. Conceptul general care este învãtat este clasa situatiilor în care postconditiile macrooperatorului pot fi satisfãcute. Formarea macrooperatorilor determinã conditiile suficiente, sub forma preconditiilor macrooperatorului, pentru care o situatie datã (instantã) face parte din aceastã clasã. Astfel, spre deosebire de tehnicile inductive, sistemul STRIPS învatã dintr-un singur exemplu.
7.3 Învãtarea prin generalizare explicatã
Aceasta sectiune începe prin prezentarea unei scheme generale de învãtare prin generalizare explicatã, care pune în evidentã caracteristicile esentiale ale metodei. Apoi sînt prezentate douã sisteme care folosesc aceastã abordare, sistemul GENESIS [DeJong,1983;Mooney,Dejong,1985] si sistemul LEX-II [Mitchell,1983].
7.3.1 Generalizarea bazatã pe explicatii
Mitchell, Keller si Kedar-Cabelli [1986] prezintã o abordare unitarã a învãtãrii bazate pe explicatii, abordare numitã generalizare bazatã pe explicatii, cu prescurtarea din limba englezã EBG. Formalismul generalizãrii bazate pe explicatii încearcã sã sintetizeze elementele esentiale ale celor mai multe sisteme de învãtare bazatã pe explicatii, într-o formã potrivitã aplicãrii în orice domeniu. Mitchell descrie acest formalism ca "o metodã independentã de domeniu ... pentru utilizarea cunostintelor specifice domeniului în ghidarea generalizãrii". În aceastã abordare, explicatiile sînt identificate cu demonstratiile scopurilor de rezolvat, ceea ce stabileste un înteles precis al termenului explicatie. Formalismul este format din douã pãrti: problema EBG si metoda EBG. Problema EBG este definitã în termenii a patru parametri necesari sistemului de învãtare, parametri descrisi în continuare.
Conceptul scop este o definitie care descrie conceptul ce se învatã si care reprezintã scopul sistemului de învãtare. Se presupune cã aceastã definitie nu satisface criteriul de operationalitate, deci nu poate fi utilizatã pentru a recunoaste instante ale conceptului.
Exemplul de învãtare este un exemplu al conceptului scop care se învatã, i.e. o instantã a acestui concept.
Teoria domeniului este o multime de reguli si fapte care descriu domeniul exemplului si al conceptului de învãtat.
Criteriul de operationalitate indicã ce fel de descrieri ale conceptului sînt considerate operationale, deci în ce formã trebuie exprimat conceptul învãtat.
În formalismul lui Mitchell, conceptul scop este reprezentat ca o formulã în logica cu predicate de ordinul I, formulã care poate contine atît variabile legate cît si variabile libere. Criteriul de operationalitate este exprimat sub forma unei multimi de predicate observabile sau usor de evaluat, care apartin teoriei domeniului sau care sînt predicate generale. Descrierea unui concept este consideratã operationalã dacã si numai dacã este în întregime exprimatã în termenii predicatelor acestei multimi. Exemplul de învãtare este descris în termeni operationali, i.e. folosind predicate din multimea criteriului de operationalitate. Regulile si faptele din teoria domeniului sînt folosite pentru a explica de ce exemplul de învãtare este o instantã a conceptului scop. Teoria domeniului este reprezentatã printr-o multime de clauze Horn.
Sistemul de învãtare trebuie sã reformuleze conceptul scop în termenii unei noi descrieri care satisface urmãtoarele conditii:
este o generalizare a exemplului de învãtare;
este o conditie suficientã pentru caracterizarea conceptului scop;
satisface criteriul de operationalitate.
Reexprimarea descrierii conceptului scop în termenii criteriului de operationalitate va face conceptul operational din punctul de vedere al recunoasterii instantelor scopului. Noua descriere a conceptului nu este necesar identicã cu conceptul scop, ci poate fi o specializare a conceptului scop si/sau o generalizare a exemplului de învãtare. Pentru a crea o astfel de descriere, sistemul de învãtare aplicã metoda EBG care, similar procedurii generale de învãtare bazatã pe explicatii, contine douã etape:
(1) Explicare. În aceastã etapã sistemul foloseste teoria domeniului pentru a construi o explicatie, sub forma unui arbore de deductie care aratã cum satisface exemplul de învãtare definitia conceptului scop. Aceastã explicatie trebuie construitã astfel încît fiecare ramurã a structurii explicative sã se termine cu o expresie din multimea criteriului de operationalitate. Explicatia demonstreazã faptul cã exemplul de învãtare este într-adevãr o instantã a conceptului scop.
(2) Generalizare. Aceastã etapã se realizeazã prin regresia conceptului scop prin structura explicativã pentru obtinerea unei descrieri operationale a conceptului la nivelul frunzelor arborelui de explicare. În acest fel, se determinã multimea conditiilor suficiente pentru care explicatia este valabilã, conditii exprimate în termenii criteriului de operationalitate.
Procedura de generalizare propusã, numitã regresia modificatã a scopului, este o versiune a tehnicii de regresie propusã de Nilson [1980] si îndeplineste conceptual acelasi rol ca generalizarea planului în sistemul STRIPS sau generalizarea explicatiilor în sistemul GENESIS. Procedura regresiei modificate a scopului identificã conceptul scop cu rãdãcina arborelui de deductie, înlocuind constantele cu variabile, si continuã identificarea la nivelele urmãtoare ale arborelui, pãstrînd substitutiile efectuate.
Fie exemplul definirii conceptului scop ![]() , care indicã o pereche de obiecte
, care indicã o pereche de obiecte ![]() astfel încît x poate
fi asezat în conditii de sigurantã peste y. În acest caz, problema se defineste
astfel:
astfel încît x poate
fi asezat în conditii de sigurantã peste y. În acest caz, problema se defineste
astfel:
Conceptul scop
![]()
Exemplul de învãtare
![]()
![]()
![]()
![]()
![]()
![]()
![]() .
.
Teoria domeniului
![]()
![]()
![]()
Criteriul de operationalitate
Predicate
specifice domeniului: ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Predicate
generale: ![]() ,
, ![]() care sînt adevãrate
dacã
care sînt adevãrate
dacã ![]() , respectiv
, respectiv ![]() .
.
Pentru a aplica metoda generalizãrii bazatã pe explicatii, sistemul trebuie sã construiascã întîi explicatia care justificã (demonstreazã) faptul cã exemplul de învãtare sastisface conceptul scop. Pentru aceasta, sistemul trebuie sã demonstreze conceptul scop în termenii teoriei domeniului si ai specificatiilor exemplului, construind un arbore de deductie care sã satisfacã criteriul de operationalitate la nivelul frunzelor. Acest arbore este prezentat în Figura 7.6.

Figura 7.6 Arbore de explicare a exemplului în termenii conceptului scop
Conceptul scop ![]() este apoi supus
procesului de regresie în structura explicativã, începînd de la rãdãcina
arborelui. Procedeul de regresie este rezumat în Figura 7.7 în care expresiile
subliniate sînt rezultatul pasilor de regresie executati. În acest fel, se obtine
prin generalizare urmãtoarea descriere operationalã a conceptului scop:
este apoi supus
procesului de regresie în structura explicativã, începînd de la rãdãcina
arborelui. Procedeul de regresie este rezumat în Figura 7.7 în care expresiile
subliniate sînt rezultatul pasilor de regresie executati. În acest fel, se obtine
prin generalizare urmãtoarea descriere operationalã a conceptului scop:
![]()
Figura 7.7 Generalizare prin regresia scopului în structura explicativã
Aceastã descriere specificã faptul cã x poate fi asezat în conditii de sigurantã peste y, dacã y este masã si dacã produsul dintre volumul si densitatea lui x este mai mic ca 500 sau, altfel spus, orice obiect mai usor de 500 poate fi asezat pe masã. Aceastã descriere satisface criteriul de operationalitate si este justificatã de explicatie.
Se pot pune urmãtoarele douã probleme. În primul rînd, în ce mãsurã poate fi consideratã aceastã metodã un proces de învãtare, din moment ce algoritmul se bazeazã pe o definitie a conceptului. Avînd în vedere defintia învãtãrii datã de Herbert Simon, conform cãreia învãtarea este îmbunãtãtirea capacitãtii de rezolvare a problemelor, aceastã metodã poate fi consideratã o metodã de învatare. Definitia conceptului primitã de sistem este neoperationalã, ceea ce înseamnã cã este complex computationalã, dacã nu imposibil de aplicat pentru recunoasterea instantelor conceptului. Generalizarea bazatã pe explicatii este vãzutã ca o operationalizare a definitiei conceptului, adicã transformarea acestei definitii într-o formã ce poate fi utilizatã eficient în recunoastere.
În al doilea rînd se pune problema rolului jucat de exemplul de învãtare. În principiu, fiind datã o teorie completã a domeniului, definitia conceptului ar putea fi operationalizatã fãrã a folosi exemplul. Cu toate acestea, exemplul are douã roluri. Primul este acela de a ghida cãutarea pentru gãsirea definitiei operationale, reducînd astfel spatiul de cãutare. Dacã algoritmul s-ar aplica fãrã a utiliza exemplul de învãtare, cea de a doua etapã devine inutilã deoarece nu mai este nevoie sã se generalizeze caracteristicile particulare apãrute în explicatie datoritã exemplului de învãtare. În aceste conditii însã, spatiul de cãutare parcurs poate fi mult mai mare. Al doilea rol al exemplului de învãtare este acela de a impune conditiile suficiente ale descrierii conceptului, în mãsura în care exemplul de învãtare este reprezentativ pentru concept.
Pentru a ilustra aceste idei, se considerã implementarea algoritmului de generalizare bazatã pe explicatii, în limbajul Prolog. Alegerea limbajului Prolog s-a fãcut deoarece caracterul logic si facilitãtile de unificare din limbaj permit exprimarea usoarã atît a problemei EBG, cît si a metodei EBG. Implementarea Prolog, în loc sã construiascã întîi structura explicativã si sã realizeze ulterior generalizarea, construieste simultan atît arborele de deductie al exemplului de învãtat cît si arborele de deductie generalizat. Deductia unui predicat operational este imediatã, predicatul fiind o frunzã a arborelui. Deductia unui predicat neoperational se face pe baza regulii ce îl referã în concluzie, iar deductia unei conjunctii de scopuri se face pe baza deductiei fiecãrui scop în parte. Se propun în continuare douã versiuni ale implementãrii în limbajul Prolog a algoritmului de generalizare bazatã pe explicatii [Harmelen,1988]. Prima versiune este urmãtoarea:
gbe (Frunza, FrGen, FrGen) :-
operational (Frunza), !,
call (Frunza).
gbe ((Scop1, Scop2), (Scop1Gen, Scop2Gen), (Frunze1, Frunze2)) :-
gbe (Scop1, Scop1Gen, Frunze1),
gbe (Scop2, Scop2Gen, Frunze2).
gbe (Scop, ScopGen, Frunze) :-
clause (ScopGen, ClauzaGen),
copiere ((ScopGen :- ClauzaGen), (Scop :- Clauza)),
gbe (Clauza, ClauzaGen, Frunze).
Predicatul Prolog ![]() sintetizeazã în
argumentul Reformulare, pe baza exemplului dat în Exemplu, o descriere operationalã
a conceptului (neoperational) Concept. Efectul predicatului este instantierea
argumentului Reformulare la o listã de predicate operationale care formeazã
frunzele arborelui de deductie a conceptului scop. Predicatul copiere ajutã la construirea arborelui
de deductie generalizat, prin crearea unei copii a primului argument, i.e.
regula
sintetizeazã în
argumentul Reformulare, pe baza exemplului dat în Exemplu, o descriere operationalã
a conceptului (neoperational) Concept. Efectul predicatului este instantierea
argumentului Reformulare la o listã de predicate operationale care formeazã
frunzele arborelui de deductie a conceptului scop. Predicatul copiere ajutã la construirea arborelui
de deductie generalizat, prin crearea unei copii a primului argument, i.e.
regula ![]() , în cel de al doilea argument
, în cel de al doilea argument ![]() .
.
Considerînd exemplul precedent, specificarea problemei în limbajul Prolog se face astfel:
%% Conceptul scop
sigur_peste(X, Y) :- mai_usor(X, Y).
%% Exemplu de invatare
peste(cub1, masa1).
volum(cub1, 10).
isa(cub1, cub).
isa(masa1, masa).
culoare(cub1, rosie).
culoare(masa1, alba).
densitate(cub1, 10).
%% Teoria domeniului
mai_usor(X, Y) :-
greutate(X, W1),
greutate(Y, W2),
mai_mic(W1, W2).
greutate(X, 500) :- isa(X, masa).
greutate(X, Y) :-
volum(X, V),
densitate(X, D),
inm(V, D, Y).
%% Criteriul de operationalitate
operational (Scop) :-
member (Scop, [inm(_,_,_), mai_mic(_,_), peste(_,_), volum(_,_), isa(_,_), culoare(_,_), densitate (_,_)]).
Rezolvarea problemei de învãtare se face prin urmãtorul apel al scopului gbe:
?- gbe (sigur_peste (cub1, masa1), sigur_peste (X, Y), Reformulare)
Reformulare = (volum (X, VX), densitate (X, DX),
inm (VX, DX, MX), isa (Y, masa), mai_mic (MX, 500))
reformularea indicînd faptul cã orice obiect mai usor de 500 poate fi asezat în conditii de sigurantã pe masã.
Cea de a doua variantã de implementare nu mai ia în
considerare exemplul de învãtare si operationalizarea conceptului se face numai
pe baza teoriei domeniului. Predicatul ![]() care implementeazã
aceastã variantã este definit dupã cum urmeazã.
care implementeazã
aceastã variantã este definit dupã cum urmeazã.
gbe1 (Frunza, Frunza) :-
operational (Frunza), !, call (Frunza).
gbe1 ((Scop1Gen, Scop2Gen), (Frunze1, Frunze2)) :-
gbe1 (Scop1Gen, Frunze1),
gbe1 (Scop2Gen, Frunze2).
gbe1 (ScopGen, Frunze) :-
clause (ScopGen, Clauza),
gbe1 (Clauza, Frunze).
Predicatul gbe1 contine numai douã argumente: conceptul scop si reformularea conceptului în termeni operationali. Spre deosebire de predicatul gbe, care construia douã versiuni ale arborelui de deductie, una specificã si alta generalizatã, cu ajutorul predicatului copiere, predicatul gbe1 construieste numai arborele de deductie generalizat, deci nu mai are nevoie de apelul predicatului copiere. Acest comportament se datoreazã faptului cã învãtarea nu se mai face ghidatã de exemplu. Existã si o altã diferentã a predicatului gbe1 fatã de gbe. Predicatul gbe1 include în reformularea conceptului unificãrile cu predicatele operationale, restrictionînd astfel reformularea conceptului scop. Predicatul gbe nu include aceste unificãri în multimea rezultantã de frunze, deci în reformulare. Aceastã diferentã poate fi eliminatã, în sensul cã predicatul gbe1 poate fi modificat astfel încît sã nu includã unificãrile cu predicatele operationale. Efectul dorit este realizat prin înlocuirea primei clauze a predicatului gbe1 cu clauza:
gbe1 (Frunza, Frunza) :-
operational (Frunza), !,
not not call (Frunza).
În aceste conditii, învãtarea conceptului se poate face prin urmãtorul apel al predicatului gbe1, care va avea solutiile indicate în continuare.
?- gbe1 (sigur_peste (X, Y), Reformulare)
Reformulare = (volum (X, VX), densitate (X, DX),
inm (VX, DX, MX), isa (Y, masa), mai_mic (MX, 500))
Reformulare = (isa (X, masa), volum (Y, VY), densitate (Y, DY),
inm (VY, DY, MY), mai_mic (500, MY))
cu semnificatia cã o masã poate fi asezatã în conditii de sigurantã peste orice obiect cu greutatea mai mare de 500.
Reformulare = (volum (X, VX), densitate (X, DX),
inm (VX, DX, MX), volum (Y, VY), densitate (Y, DY),
inm (VY, DY, MY), mai_mic (MX, MY))
cu semnificatia cã orice obiect poate fi asezat în conditii de sigurantã peste orice alt obiect, dacã este mai usor decît obiectul peste care este asezat.
De fapt existã patru reformulãri posibile ale conceptului scop, dintre care una, corespunzãtoare asezãrii a douã mese una peste alta, este eliminatã datoritã faptului cã ambele mese au aceeasi greutate, 500. Se observã cã cele patru reformulãri sintetizate de predicatul gbe1 reprezintã de fapt cele patru multimi de frunze ale celor patru arbori de derivare posibili pentru conceptul scop. În predicatul gbe, cãutarea este ghidatã de exemplul de învãtare, ceea ce determinã sinteza unei singure reformulãri a conceptului în termeni operationali.
7.3.2 Achizitia schemelor explicative
Unul din principalele eforturi fãcute în investigarea învãtãrii bazate pe explicatii sub forma generalizãrii explicate este sistemul GENESIS [DeJong,1983;Mooney,DeJong,1985] de întelegere a povestirilor exprimate în limbaj natural. Sistemul analizeazã o povestire care descrie personaje si planuri de actiune ale acestora în vederea realizãrii anumitor scopuri. Analiza are rolul de a construi scheme de descriere a unor planuri generale, scheme care sînt utilizate în întelegerea unor povestiri similare.
Procesul de întelegere si analizã a planului în sistemul GENESIS se face pe baza cunostintelor despre domeniul discursului, cunostinte care se referã la scopurile tipice ale actiunilor umane si la motivatiile acestora. Reprezentarea cunostintelor se face pe baza schemelor, un model combinat de cunostinte structurate si scenarii [Rich,Knight,1991; Florea,1993], organizate într-o structurã ierarhicã. Schemele descriu actiuni, stãri si obiecte. Actiunile sînt reprezentate într-o formã similarã formei operatorilor din sistemul STRIPS. Structura de control a sistemului foloseste o combinatie a mecanismelor de control specifice scenariilor cu acelea caracteristice rezolvãrii problemelor de planificare. Metodele specifice scenariilor instantiazã schemele generale în urma identificãrii cu obiectele si actiunile povestirii, iar metodele specifice planificãrii conduc cãutarea în spatiul planurilor posibile pentru gãsirea planurilor care justificã scopurile personajelor din povestire.
Fie urmãtoarea povestire despre producerea unei rãpiri: "Florin este tatãl Mariei si Florin este bogat. Radu se împrieteneste cu Maria. Maria poartã pantaloni. Radu îndreaptã un pistol spre Maria si o obligã sã se urce în masina lui. Apoi o încuie în camera lui de hotel. Radu telefoneazã lui Florin si îi spune cã Radu o are pe Maria captivã. Radu îi spune lui Florin cã dacã Florin îi plãteste 10.000.000 lei la Cluj, atunci Radu o elibereazã pe Maria. Florin dã banii lui Radu si Radu o elibereazã pe Maria".
Utilizînd acest unic exemplu si cunostintele din baza de cunostinte, sistemul GENESIS generalizeazã exemplul construind o schemã care descrie un plan general al rãpirilor în scopul obtinerii unei rãscumpãrãri. Schema contine numai acele elemente ale povestirii care sînt necesare îndeplinirii planului, eliminînd detaliile nesemnificative. De exemplu, schema necesitã ca victima sã fie o rudã apropiatã a unei persoane bogate pentru a putea obtine rãscumpãrarea, dar nu necesitã existenta informatiei despre pantalonii purtati de victimã si nici faptul cã banii trebuie sã fie plãtiti la Cluj, deoarece aceste elemente nu sînt esentiale în realizarea planului.
Pentru a generaliza povestirea, sistemul GENESIS construieste o explicatie cauzalã completã a evenimentelor descrise. Desi povestirea istoriseste o secventã de evenimente, nu se indicã legãturile cauzale între aceste evenimente. Sistemul trebuie sã infere toate aceste legãturi cauzale. În timpul construirii explicatiei, se fac diverse tipuri de inferente care instantiazã schemele generale existente în baza de cunostinte. De exemplu, se inferã faptul cã apelul telefonic este o preconditie a întelegerii între Radu si Florin. De asemenea, sistemul inferã cã personajele povestirii au anumite scopuri si anumite prioritãti ale scopurilor, cum ar fi faptul cã Florin doreste sã o recapete pe Maria mai mult decît doreste sã pãstreze cei 10.000.000 lei. În plus, sistemul deduce cã anumite actiuni ale povestirii sînt componente ale unui plan mai cuprinzãtor. De exemplu, "Radu îndreaptã un pistol spre Maria" este o parte a unui plan de amenintare care, la rîndul sãu, este o parte a unui plan de capturare. Explicatia construitã de sistem trebuie sã fie completã, în sensul cã toate actele volitive trebuie sã fie motivate de scopurile umane existente în sistem. Fiecare actiune trebuie sã motiveze realizarea unui scop sau sã fie o parte a unui plan care conduce la îndeplinirea unui scop.
Procesul de generalizare din sistemul GENESIS trebuie sã construiascã o schemã pentru mai multe posibile povestiri. În acest scop, sistemul analizeazã explicatia povestirii pentru a determina aspectele relevante si, respectiv, nerelevante ale planului . Generalizarea eliminã detaliile povestirii atît timp cît explicatia succesului planului rãmîne validã. Dacã explicatia rãmîne validã, planul generalizat va fi de asemenea îndeplinit cu succes. Din aceastã cauzã, abordarea din sistemul GENESIS poate fi consideratã o învãtare prin generalizare explicatã.
Primul pas al procedurii de generalizare eliminã din schemã portiunile retelei de dependente conceptuale care nu fac parte din explicatia povestirii. În particular sînt eliminate actiunile si asertiunile care nu sînt legate prin relatii de tipul "component" sau "motivatie" de structura planului care justificã scopul principal. Aceste asertiuni sînt eliminate deoarece nu contribuie la succesul planului. De exemplu, nodul asociat asertiunii "Maria poartã pantaloni" este eliminat din acest motiv. Al doilea pas al procedurii de generalizare eliminã actiunile care reprezintã instante nominale ale planurilor complexe. Astfel, actiunile de îndreptare a pistolului spre Maria si de amenintare sînt eliminate, deoarece fac parte din planul compus de capturare. Cel de al treilea pas al procedurii de generalizare se face pe baza ierarhiei de obiecte din sistem, în particular pe baza relatiilor de tip ISA. Toate inferentele de tipul "Schema A este o instantã a schemei B", deci A ISA B, sînt eliminate (prin eliminarea schemei A si a legãturii spre schema B). De exemplu, dacã obiectul tatã este legat printr-o relatie ISA de obiectul pãrinte, nodul asociat tatãlui si legãtura spre pãrinte sînt eliminate. Aceastã eliminare este consistentã deoarece schema asociatã scopului prioritar "Florin doreste sã o recapete pe Maria mai mult decît doreste sã pãstreze cei 10.000.000 lei" a fost construitã pe baza instantierii unei reguli de inferentã generale în care relatia dintre victimã si plãtitor este o relatie de rudenie apropiatã si nu neapãrat aceea de fiicã-tatã.
Rezultatele procesului de învãtare din sistemul GENESIS pot fi evaluate în termenii capacitãtii sistemului de a rãspunde la întrebãri. Utilizînd schema învãtatã, sistemul GENESIS poate întelege si rãspunde la întrebãri despre alte povestiri cu rãpiri, cum ar fi povestirea: "Tudor este sotul Anei. Tudor cîstigã 5.000.000 lei la LOTO. Dan o încuie pe Ana în subsolul casei sale si telefoneazã lui Tudor. Dan primeste 5.000.000 lei si o elibereazã pe Ana". Aceastã povestire nu ar fi putut fi înteleasã dacã sistemul nu ar fi sintetizat anterior, prin învãtare, schema generalã a rãpirilor. Trebuie observat cã cea de a doua povestire nu specificã explicit lucruri ca: cum a reusit Dan sã o încuie pe Ana, de ce primeste Dan bani de la Tudor si în ce conditii Dan o elibereazã pe Ana. Fãrã o schemã cauzalã generalã obtinutã anterior, inferentele posibil de executat pentru întelegerea celei de a doua povestiri ar fi fost explozive combinational.
7.3.3 Învãtarea euristicilor de control
Prezentarea acestei abordãri a învãtãrii prin generalizare explicatã se va face pe baza discutãrii sistemului LEX-II [Mitchell,1982;Mitchell,1983]. LEX-II este un sistem de învãtare a euristicilor de control în domeniul integrãrii simbolice automate. El a fost construit ca o extensie a sistemului LEX-I care utiliza o metodã de învãtare inductivã, deci slabã, pentru învãtarea conceptelor din exemple multiple. Sistemul LEX-II a combinat algoritmul de învãtare din sistemul LEX-I, similar cu algoritmul de eliminare a candidatilor propus de Mitchell [1977], cu metoda învãtãrii bazate pe explicatii care generalizeazã pe baza unui singur exemplu sau tip de exemplu. Scopul sistemului este acela de a învãta euristici care îmbunãtãtesc eficienta procesului de rezolvare a problemelor de integrare simbolicã.
Sistemul LEX-II este format din patru componente de bazã: generatorul de probleme, componenta de rezolvare a problemelor, componenta criticã si componenta de generalizare, prezentate în Figura 7.8. Se observã similitudinea arhitecturii sistemului cu cea a unui sistem general de învãtare (Sectiunea 7.1.2).
Figura 7.8 Arhitectura sistemului LEX-II
Componenta de rezolvare a problemelor are la dispozitie o multime de operatori de reducere a problemei în subprobleme (aproximativ 40), numiti si reguli de descriere. Exemple de astfel de reguli de rescriere sînt:
OP1. ![]() /* f(x) este
orice functie realã */
/* f(x) este
orice functie realã */
OP2. ![]() /*
r este orice numãr real */
/*
r este orice numãr real */
OP3. ![]()
OP4. ![]()
OP5. ![]()
OP6. ![]() /*
integrare prin pãrti */
/*
integrare prin pãrti */
Fiecare operator are o conditie care specificã clasa de
stãri a problemei pentru care operatorul poate fi aplicat, deci pentru care
operatorul este valid, si stãrile care pot rezulta prin aplicarea acestui
operator. De exemplu, înainte de a putea aplica operatorul OP6, forma generalã
a integrantului trebuie sã fie produsul a douã functii reale, i.e. sã fie de
forma ![]() . Aplicarea operatorului OP6 poate conduce la obtinerea a
douã stãri, fiecare stare corespunzînd unei instantieri diferite a variabilelor
u cu
. Aplicarea operatorului OP6 poate conduce la obtinerea a
douã stãri, fiecare stare corespunzînd unei instantieri diferite a variabilelor
u cu ![]() si dv cu
si dv cu ![]() sau invers.
sau invers.
Regulile de aplicare a operatorilor în sistemul LEX-II sînt de forma:
dacã sablonul de integrat este P
atunci aplicã OPm cu instantierea B
De exemplu, o regulã de rescriere tipicã pentru operatorul OP6 ar fi:
R6.1: dacã sablonul de integrat este ![]()
atunci
aplicã OP6 cu instantierea ![]() si
si ![]()
Regulile de rescriere reprezintã euristici generale de aplicare a operatorilor. Învãtarea în sistemul LEX-II constã în rafinarea regulilor de rescriere existente sau crearea unor reguli noi în scopul cresterii specificitãtii de aplicare a acestora, si deci al reducerii spatiului de cãutare. Astfel, modulul de învãtare trebuie sã gãseascã conditii mai restrictive de aplicare a operatorilor. Pentru fiecare operator, sistemul încearcã sã învete un concept care descrie multimea de stãri în care operatorul poate fi "util" aplicat. Stãrile în care un operator poate fi util aplicat sînt de obicei o submultime a stãrilor în care operatorul poate fi valid aplicat.
Procesul de învãtare începe în momentul în care generatorul de probleme selecteazã si genereazã probleme de integrare pentru a fi rezolvate de componenta de rezolvare a problemelor. Componenta de rezolvare a problemelor încearcã sã rezolve problemele propuse de generator, prin metoda reducerii problemei la subprobleme, folosind regulile si operatorii sistemului. Se considerã cã sistemul a gãsit o solutie atunci cînd produce o expresie care nu contine integrale, expresiile care nu contin integrale reprezentînd probleme elementare. Componenta de rezolvare produce o solutie a problemei si o urmã completã a procesului de cãutare, reprezentatã sub forma unui arbore ªI/SAU, asa cum se prezintã în Figura 7.9.
![]()

![]()
![]()
![]()
![]()
![]()
Figura 7.9 Parte a arborelui ªI/SAU generat de componenta de rezolvare
Alegerea unei descompuneri (reguli) sau alta poate duce fie la solutia optimã, din punct de vedere al numãrului de reguli generate, fie la o solutie mai putin bunã fie, chiar, la cãi de cãutare care se blocheazã prin generarea de probleme neelementare care nu mai pot fi descompuse.
Urma completã a procesului de cãutare a solutiei este transmisã componentei critice care eticheteazã aplicarea operatorilor din arbore ca fiind "utilã" sau "neutilã". Aplicarea unui operator de-a lungul cãii spre solutie este consideratã utilã, în timp ce aplicarea unui operator pe o altã cale de cãutare este consideratã neutilã. Aceastã clasificare genereazã o multime de instante pozitive si negative ale aplicãrii fiecãrui operator. Aceste exemple sînt folosite de componenta de generalizare pentru a învãta conditii mai restrictive de aplicare a operatorilor.
În sistemul LEX-I instantele clasificate ale aplicãrii operatorilor sînt prelucrate utilizînd algoritmul de eliminare a candidatilor pentru învãtarea conceptelor din exemple, algoritm propus de Mitchell [1977]. Acest algoritm cautã într-un spatiu al versiunilor care contine o multime initialã de descrieri candidate ale conceptului de învãtat. Descrierile candidatilor sînt legate prin relatii de generalizare si specializare care definesc o latice. Generalizarea se face pe baza exemplelor pozitive, iar specializarea pe baza celor negative. Componenta de generalizare a sistemului LEX-I generalizeazã si specializeazã pe baza unui arbore taxonomic de descrieri. O parte din acest arbore este prezentatã în Figura 7.10. Astfel, dacã o regulã se aplicã pentru mai multe functii trigonometrice, de exemplu sin si cos, regula poate fi generalizatã specificînd functia trig.

Figura 7.10 Un segment din arborele de generalizare
Descrierile candidatilor sînt reprezentate prin conditiile de aplicare ale operatorilor. Fiecare operator are asociat, în spatiul versiunilor o multime de descrieri euristice caracteristice. Aceastã multime este reprezentatã sub forma a douã descrieri limitã: o descriere G care specificã cele mai generale conditii de aplicare a operatorului si o descriere S care specificã conditiile particulare de aplicare a operatorului. În timp ce sistemul învatã, descrierea S este generalizatã astfel încît sã includã toate exemplele pozitive prezentate de componenta criticã, în timp ce descrierea G este specializatã pentru a exclude exemplele negative. Dacã componenta de generalizare considerã un numãr suficient de exemple, descrierile S si G devin identice si se considerã cã sistemul a învãtat o euristicã corectã.
Pentru a exemplifica acest
proces, se considerã rafinarea descrierilor euristice ale operatorului OP6. Se
presupune cã generatorul de probleme a generat urmãtoarele douã probleme: ![]() si
si ![]() . În spatiul versiunilor, descrierile G si S asociate
operatorului OP6 au forma prezentatã în Figura 7.11.
. În spatiul versiunilor, descrierile G si S asociate
operatorului OP6 au forma prezentatã în Figura 7.11.
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
Figura 7.11 Spatiul versiunilor cu limitele G si S
Functiile ![]() si
si ![]() sînt orice functii
reale de o variabilã x, iar descrierea S este initializatã cu prima problemã de
rezolvat. Pentru prima problemã, componenta de rezolvare alege operatorul OP6
ca operator valid aplicabil. Pentru acest operator sînt posibile douã instantieri
diferite:
sînt orice functii
reale de o variabilã x, iar descrierea S este initializatã cu prima problemã de
rezolvat. Pentru prima problemã, componenta de rezolvare alege operatorul OP6
ca operator valid aplicabil. Pentru acest operator sînt posibile douã instantieri
diferite:
(a) ![]()
![]()
(b) ![]()
![]()
Dacã se foloseste instantierea (a), aplicarea operatorului
OP6 produce expresia ![]() care poate fi redusã
în continuare, folosind operatorii OP2, OP4 si alti operatori, la solutia
corectã
care poate fi redusã
în continuare, folosind operatorii OP2, OP4 si alti operatori, la solutia
corectã ![]() . Pentru aceastã legare, componenta criticã va considera
aceastã instantã ca un exemplu pozitiv.
. Pentru aceastã legare, componenta criticã va considera
aceastã instantã ca un exemplu pozitiv.
Dacã se foloseste instantierea
(b), aplicarea operatorului OP6 produce expresia mai complexã ![]() . În acest caz, componenta criticã va considera aceastã
instantã ca un exemplu negativ. Exemplul negativ va fi folosit pentru a
specializa descrierea G la
. În acest caz, componenta criticã va considera aceastã
instantã ca un exemplu negativ. Exemplul negativ va fi folosit pentru a
specializa descrierea G la ![]() sau la
sau la ![]() , cu legãrile corespunzãtoare:
, cu legãrile corespunzãtoare:
(a) ![]()
![]()
(b) ![]()
![]()
ambele legãri excluzînd exemplul negativ.
Semnificatia acestei
specializãri este: se foloseste operatorul OP6 fie atunci cînd u este o functie
polinomialã, fie atunci cînd dv este o functie transcendentã. Dupã gãsirea solutiei
si pentru ![]() , componenta criticã considerã instantierea
, componenta criticã considerã instantierea ![]() ,
, ![]() tot ca un exemplu
pozitiv. Dar acest exemplu nu este inclus în spatiul conceptului. În consecintã,
descrierea S trebuie generalizatã pentru a include si aceastã instantã.
Generalizarea se face prin cãutarea în arborele taxonomic a functiei ce include
atît sin(x) cît si cos(x). Aceastã generalizare produce descrierea:
tot ca un exemplu
pozitiv. Dar acest exemplu nu este inclus în spatiul conceptului. În consecintã,
descrierea S trebuie generalizatã pentru a include si aceastã instantã.
Generalizarea se face prin cãutarea în arborele taxonomic a functiei ce include
atît sin(x) cît si cos(x). Aceastã generalizare produce descrierea:
G ![]()
S ![]()
Prin rezolvãri repetate ale problemelor de acest tip, sistemul LEX-I poate crea si rafina regulile euristice ale operatorilor.
Sistemul LEX-II a fost dezvoltat din sistemul LEX-I prin introducerea unor cunostinte suplimentare în modulul de învãtare (componenta criticã si componenta de generalizare) care sã creascã eficienta procesului de rafinare a regulilor euristice. În particular, sistemul LEX-II posedã o descriere a scopului procesului de învãtare. Sitemul contine reguli care oferã o definitie abstractã a instantelor pozitive ale unui predicat, InstPoz, descrise în continuare.
![]()
![]()
![]()
![]()
Aceste reguli oferã definitii
pentru o întreagã colectie de concepte, fiecare concept avînd asociat un
operator. De exemplu, dacã regulile sînt instantiate prin legarea variabilei op
la operatorul OP6, ele definesc conceptul care include toate stãrile ce
satisfac predicatul ![]() . Parafrazînd aceste reguli, o stare s este o instantã
pozitivã a operatorului op, dacã starea s nu este deja rezolvatã si dacã
aplicarea operatorului op stãrii s conduce la o stare care este fie rezolvatã,
fie rezolvabilã prin aplicãri ulterioare ale altor operatori.
. Parafrazînd aceste reguli, o stare s este o instantã
pozitivã a operatorului op, dacã starea s nu este deja rezolvatã si dacã
aplicarea operatorului op stãrii s conduce la o stare care este fie rezolvatã,
fie rezolvabilã prin aplicãri ulterioare ale altor operatori.
Organizarea modulului de învãtare din sistemul LEX-II este prezentatã în Figura 7.12. Sistemul prelucreazã exemplele pozitive si negative în mod diferit. Exemplele pozitive sînt transmise unei proceduri de învãtare bazatã pe explicatii. Procedura generalizeazã instante pozitive unice prin utilizarea regulilor ce definesc predicatul InstPoz. Instantele pozitive generalizate sînt prezentate algoritmului de eliminare a candidatilor. Instantele negative sînt prezentate direct acestui algoritm, la fel ca în sistemul LEX-I.

Figura 7.12 Organizarea modulului de învãtare în sistemul LEX-II
Procedura de învãtare prin generalizare explicatã primeste
ca date de intrare o pereche ![]() , unde OP este operatorul aplicat în starea S si etichetat ca
instantã pozitivã de componenta criticã. Procedura de învãtare bazatã pe
explicatii trebuie sã gãseascã o generalizare a stãrii S, care sã reprezinte o
multime de stãri pentru care operatorul OP este util. Învãtarea se face
utilizînd o procedurã în doi pasi, similarã cu cea din sistemul GENESIS:
sistemul explicã întîi de ce exemplul este o instantã pozitivã apoi generalizeazã
exemplul analizînd aceastã explicatie. În primul pas al procedurii se construieste
o explicatie, sub forma unui arbore ªI/SAU, care aratã de ce perechea
, unde OP este operatorul aplicat în starea S si etichetat ca
instantã pozitivã de componenta criticã. Procedura de învãtare bazatã pe
explicatii trebuie sã gãseascã o generalizare a stãrii S, care sã reprezinte o
multime de stãri pentru care operatorul OP este util. Învãtarea se face
utilizînd o procedurã în doi pasi, similarã cu cea din sistemul GENESIS:
sistemul explicã întîi de ce exemplul este o instantã pozitivã apoi generalizeazã
exemplul analizînd aceastã explicatie. În primul pas al procedurii se construieste
o explicatie, sub forma unui arbore ªI/SAU, care aratã de ce perechea ![]() satisface definitia
predicatului InstPoz. În cel de al doilea pas se analizeazã explicatia pentru a
obtine o multime de conditii suficiente pentru ca orice stare s sã satisfacã
predicatul
satisface definitia
predicatului InstPoz. În cel de al doilea pas se analizeazã explicatia pentru a
obtine o multime de conditii suficiente pentru ca orice stare s sã satisfacã
predicatul ![]() astfel:
astfel:
se modificã constanta S într-o variabilã cuantificatã universal s;
se extrage o multime de conditii care satisfac arborele ªI/SAU ce reprezintã explicatia;
se traduc aceste conditii într-o formã generalizatã prin exprimarea conditiilor în termenii restrictiilor stãrilor din arborele solutie si propagarea acestor restrictii prin arborele solutie pentru a obtine restrictiile echivalente referitoare la starea s.
Se observã cã procedura de învãtare din sistemul LEX-II, la fel ca si cea din sistemul GENESIS, urmãreste aceleasi douã etape ale procedurii de învãtare prin generalizare explicatã, procedurã prezentatã în Sectiunea 7.3.1. Cititorul îsi poate da seama în acest moment de meritele abordãrii unitare propuse de Mitchell, Keller si Kedar-Cabelli.
7.4 Exercitii si probleme
1. Se considerã sistemul STRIPS si problema de planificare descrisã în Figura 7.2.
(a) Sã se construiascã tabela de diferente generatã de sistem dupã sinteza planului de rezolvare a acestei probleme (Sectiunea 7.2.3).
(b) Sã se aplice algoritmul de învãtare a macrooperatorilor si sã se indice tabela de diferente generalizatã construitã de sistem pe baza tabelei de la punctul (a).
2. Se considerã urmãtorii operatori în sistemul STRIPS, unde Robot este o constantã, iar u, c , c si b sînt variabile:
![]() LP:
LP: ![]()
LE: ![]()
LA: ![]()
![]() LP:
LP: ![]()
![]()
LE: ![]()
LA: ![]()
axioma
domeniului ![]() si stãrile initialã si
finalã ale unei probleme de planificare:
si stãrile initialã si
finalã ale unei probleme de planificare:
Si: ![]() Sf:
Sf: ![]()
![]()
![]()
![]()
![]()
![]()
(a) Sã se construiascã planul de rezolvare a acestei probleme si tabela de diferente asociatã.
(b) Sã se aplice algoritmul de învãtare a macrooperatorilor si sã se construiascã tabela de diferente generalizatã.
3. Se considerã urmãtoarea descriere a conceptului scop CEAªCÃ(x):
Concept scop
![]()
Exemplul de învãtare
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Teoria domeniului
![]()
![]()
![]()
![]()
![]()
Criteriul de operationalitate
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]()
Sã
se aplice procedura de generalizare bazatã pe explicatii pentru operationalizarea
conceptului ![]() si sã se descrie
regresia modificatã a scopului în acest caz.
si sã se descrie
regresia modificatã a scopului în acest caz.
7.5 Rezolvãri
1. (a) Planul care rezolvã problema indicatã este:
![]()
Tabela de diferente asociatã acestui plan este prezentatã în continuare.
|
| |||||
|
*ARMEMPTY |
1. | ||||
|
| |||||
|
| |||||
|
|
|
2. | |||
|
|
| ||||
|
| |||||
|
| |||||
|
|
|
|
3. | ||
|
|
*ARMEMPTY | ||||
|
| |||||
|
| |||||
|
|
|
|
|
4. |
|
|
| |||||
|
| |||||
|
|
|
|
|||
|
|
ARMEMPTY |
||||
|
0 |
1 |
2 |
3 |
4 |
În cazul în care
anumite preconditii ale operatorilor se demonstreazã si pe baza unor axiome ale
domeniului, aceste axiome se introduc de asemenea în tabela de diferente,
urmînd regulile de introducere specificate pentru fapte. De exemplu, dacã
formula ![]() nu apare în starea initialã,
dar existã o axiomã pe baza cãreia se deduce cã un bloc este liber dacã nu
existã nici un bloc deasupra lui, atunci aceastã axiomã trebuie introdusã în
tabela de diferente în locul preconditiei
nu apare în starea initialã,
dar existã o axiomã pe baza cãreia se deduce cã un bloc este liber dacã nu
existã nici un bloc deasupra lui, atunci aceastã axiomã trebuie introdusã în
tabela de diferente în locul preconditiei ![]() .
.
|