Cauzalitate si timp
În sistemele distribuite asincrone nu se dispune de o modalitate de masurare a timpului real. Pentru a cunoaste ordinea relativa în care au loc evenimentele se studiaza relatiile de cauzalitate dintre ele.
Vom considera în continuare sisteme distribuite asincrone de tip MP. Evenimentele vor fi numai de calcul (daca nu se specifica altceva).
Definitie Fie a o executie fixata a sistemului si j j doua evenimente ale sale. Spunem ca j se întâmpla înaintea lui j (happens before) si notam
j a j , daca are loc una din conditiile:
j si j sunt evenimente ale aceluiasi procesor si j apare în a înaintea lui j
j trimite un mesaj m de la procesorul pi la procesorul pj, iar j este evenimentul de primire al mesajului m de la pi (j este primul eveniment de calcul al lui pj care apare în a dupa livrarea lui m).
j un eveniment a.î. j a j si perechea j j satisface conditia 1 sau 2 (cu j în locul lui j
Observatie a este o ordine partiala ireflexiva.
Definitie: Daca a=exec(C, s) este un segment de executie, un amestec cauzal (causal shuffle) al lui s este orice permutare p a lui s care satisface:
"i=![]() , s i=p i (t i
noteaza subsirul lui t care se refera doar
la procesorul pi).
, s i=p i (t i
noteaza subsirul lui t care se refera doar
la procesorul pi).
-Daca un mesaj m este trimis în a în evenimentul j al lui pi, atunci în p j precede livrarea lui m.
Lema 1: Fie a=exec(C, s). Orice ordonare totala a evenimentelor lui s care e consistenta cu relatia a este un amestec cauzal al lui s
Lema 2: Fie a= exec(C, s). Fie p un amestec cauzal al lui s. Atunci a'=exec(C, s) este un segment de executie similar lui a
Pentru a "observa" relatia a dintr-o executie, procesoarele pot adauga un tag numit logical timestamp pentru fiecare eveniment (de calcul). Aceasta asociere trebuie sa fie a.î.
j a j LT(j )<LT(j
Un algoritm de constructie a timestamp-urilor este urmatorul:
Fiecare procesor pi pastreaza o variabila locala întreaga LTi numita ceas logic, initial 0.
Fiecare eveniment de calcul este extins cu o noua operatie care atribuie lui LTi
max (valoarea curenta a lui LTi, valoarea maxima a unui timestamp
primit în acel eveniment)+1.
Fiecare mesaj trimis într-un eveniment, este stampilat cu valoarea noua a lui LTi.
Timestampul unui eveniment este valoarea lui LTi calculata în timpul acelui eveniment. Relatia de ordine între timestampuri este relatia de ordine din N.
Teorema 1: Fie a o executie si j j doua evenimente din a
Daca j a j atunci LT(j )<LT(j
Observatie: Daca LT(j LT(j j a j ). Este însa posibil ca LT(j )<LT(j ) si totusi j a j ). Necauzalitatea nu-i surprinsa deoarece N este total ordonat, iar a este o ordine partiala.
Vom folosi vectori cu componente întregi pentru a surprinde necauzalitatea.
Definitie: Spunem ca j si j sunt concurente (j j în a daca
j a j j a j
Din lemele 1 si 2 rezulta ca daca j j atunci exista a si a similare cu a a.î. j a j si j a j
Consideram urmatorul algoritm:
fiecare procesor pi pastreaza un tablou n-dimensional VCi (ceasul vectorial), cu componente întregi, initial 0.
fiecare eveniment de calcul este extins cu urmatoarele operatii:
VCi [i]:= VCi [i]+1
"j i VCi [j]:=max(VCi [j], cea mai mare componenta j a timestampurilor primite în acest eveniment)
"mesaj trimis este stampilat cu noua valoare a lui VCi.
Observatie:
10.VCj(i) este o "estimare" a lui VCi[i] tinuta de pj (numarul de pasi executat de pi pâna în acest moment).
20.Pentru "pj, în orice configuratie accesibila VCj[i] VCi[i] "i (întrucât numai pi mareste valoarea lui VCi[i]).
Pe multimea vectorilor definim relatia
de ordine partiala v1 v2
"i=![]() v1[i] v2[i]. v1<v2 v1 v2, v1 v2.
v1[i] v2[i]. v1<v2 v1 v2, v1 v2.
Urmarind definitia relatiei a si modul de constructie a ceasurilor vectoriale rezulta:
Teorema 2: Fie a o executie si j j evenimente ale lui a
j a j VC(j )<VC(j
Observatie: Rezulta ca j j VC(j ) si VC(j ) sunt incomparabile (timestampurile vectoriale surprind (captureaza) concurenta).
Defectul major al acestui mecanism este ca se mareste enorm complexitatea de comunicare. Din pacate are loc:
Teorema 3: Daca VC este o functie care asociaza fiecarui eveniment al unei executii oarecare un vector din Rk a.î. concurenta sa fie capturata, atunci k n.
Dem.: Consideram un sistem distribuit cu topologia un graf complet si a executie în care fiecare procesor pi trimite secvential mesaje la toate celelalte, cu exceptia lui pi-1 în ordinea: pi+1, pi+2,., pn-1, p0,., pi-2. Dupa ce toate mesajele au fost primite, fiecare pi primeste secvential mesajele transmise lui în ordine descrescatoare a indicelui transmitatorului, începând cu pi-1: pi-1, pi-2, ., p0,pn-1, ., pi+2 (pi nu primeste mesaj de la pi+1).
Pentru fiecare procesor pi notam cu ai primul eveniment de trimitere si cu bi ultimul eveniment de primire.
Cum în a un procesor trimite toate mesajele sale înainte de a primi unul rezulta ca relatia de cauzalitate este simpla si nu include relatii derivate de tranzitivitate. Cum nu mesaj de la pi+1 la pi si lipsa tranzitivitatii în patternul de trimitere descris de a, obtinem
(*)"i 0 i n-1, ai+1 bi.
Pe de alta parte, "pj pi, primul eveniment de trimitere al lui pi+1 influenteaza cauzal un anumit mesaj de primire al lui pj. Rezulta
(**)"i,j 0 i j n-1 ai+1 abj.
(Pentru j=i+1, ai+1 si bj=bi+1 apar la acelasi procesor, deci ai+1 a bj.
Pentru j i+1, cum j i, pi+1 trimite un mesaj lui pj în executie; ai+1 este sau acest eveniment sau se întâmpla înaintea trimiterii mesajului de la pi+1 lui pj. Primirea de la pi+1 este sau egal cu bj sau se întâmpla înaintea lui bj.)
Fixam i 0 i n-1. Din (*) ai+1 bi. Cum VC captureaza concurenta rezulta
ca VC(ai+1) si VC(bi) sunt incomparabile. Deci, o componenta r a.î. VC[r](bi)<VC[r](ai+1). Notam acest indice cu l(i).
Am definit o functie l: . Daca aratam ca l este injectiva teorema este demonstrata.
Presupunem ca i,j: l(i)=l(j)=r. Din definitia functiei l, rezulta VC[r](bi)<VC[r](ai+1) si VC[r](bj)<VC[r](aj+1). Conform (**),rezulta
ai+1 a bj, deci VC(ai+1) VC(bj). Am obtinut
VC[r](bi)<VC[r](ai+1) VC[r](bj)<VC[r](aj+1)
care contrazice (**) pentru j=i si i=j+1!
Definitia relatiei a pentru sisteme cu memorie partajata
Fie a o executie într-un sistem distribuit cu memoria partajata. Atunci j a j daca:
j si j au aceeasi valoare (se refera la acelasi procesor pi) si j
apare în a înaintea lui j
j si j sunt elemente conflictuale: acceseaza amândoua aceeasi variabila partajata, unul dintre ele este un write si j apare înaintea lui j în a
j un eveniment a.î. j a j si perechea j j satisface conditia 1 sau 2 (cu j în locul lui j ).
Mai departe totul se poate adapta ca si in cazul sistemelor de tip MP.
Taieturi
Într-un sistem distribuit nu exista un observator care sa înregistreze un instantaneu al starii sistemului. Aceasta ar fi necesar pentru rezolvarea unor probleme ca: restaurarea sistemului dupa o cadere, determinarea existentei unui deadlock sau detectarea terminarii.
Se poate obtine un instantaneu aproximativ prin cooperarea procesoarelor. Pentru simplificarea expunerii vom presupune ca fiecare eveniment de calcul primeste cel mult un mesaj (se poate implementa o coada locala a mesajelor sosite si procesând un singur mesaj la fiecare pas).
Fie a o executie fixata. Pentru fiecare procesor se pot numara evenimentele de calcul.
O taietura a executiei este un vector k=(k0, ., kn-1) de întregi pozitivi. Pentru fiecare taietura se poate construi o multime de stari ale procesoarelor: starea procesorului pi este starea sa din a imediat dupa evenimentul de calcul numarul ki din pi.
Taietura k a lui a este consistenta daca pentru "i,j
evenimentul de calcul numarul ki+1 al lui pi în a nu se întâmpla înaintea evenimentului kj al procesorului pj din a (evenimentul numarul kj din a al procesorului pj nu depinde de nici o actiune luata de alt procesor dupa taietura).
Vom presupune ca fiecare canal livreaza mesajele într-o ordine FIFO.
Pentru " taietura k si " executie a o taietura consistenta k1<k.
O taietura consistenta maximala ce precede k este o taietura consistenta k1<k a.î. "k' taietura k1<k'<k, k' nu este consistenta.
Se poate demonstra ca taietura consistenta maximala ce precede k este unica.
Presupunem ca avem un algoritm A ce se executa pe un sistem distribuit asincron de tip MP. La un moment dat " procesor primeste o aceeasi taietura k. Fiecare procesor trebuie sa calculeze componenta sa din taietura maximala ce precede k.
(Nu discutam modul în care se primeste taietura; problema este reala si apare în restaurarea unui sistem distribuit dupa o cadere).
Pentru realizarea acestui task procesoarele pot memora extra-informatie, pot stampila mesajele lui A cu extra-informatii si pot trimite mesaje aditionale.
Descriem o metoda ce necesita suplimentarea mesajelor lui A cu O(n) informatii. Ideea e foarte simpla: fiecare mesaj al lui A este stampilat cu VC. Pentru aceasta:
-fiecare procesor pi are un tablou (nemarginit) storei a.î.storei[l] pastreaza ceasul vectorial VC asociat evenimentelor de calcul numarul l al lui pi.
-atunci când pi primeste intrarea k, începe sa parcurga înapoi storei, începând cu storei[ki] pâna gaseste primul indice l, cu proprietatea ca storei[l]<k.
-raspunsul calculat de pi este l.
În timp ce procesoarele executa un algoritm A, fiecare procesor dintr-o anumita multime S primeste indicatia ca procesoarele trebuie sa înceapa calculul unei taieturi consistente care include starea cel putin a unui procesor din S la momentul în care a primit indicatia de start. (O astfel de taietura se numeste instantaneu distribuit).
Prezentam un algoritm pentru rezolvarea acestei probleme prin trimiterea unor mesaje aditionale numite markere.
Cum problema este obtinerea unui instantaneu pentru executia algoritmului A, primirea mesajelor marker nu trebuie sa influenteze calculul taieturii.
fiecare procesor pi are o variabila locala ansi, initial nedefinita care la sfârsit pastreaza raspunsul (intrarea lui pi în taietura consistenta dorita).
la primirea unui mesaj marker de la un vecin, sau la primirea indicatiei sa înceapa algoritmul, pi executa : daca ansi nu a fost deja setata atunci atribuie lui ansi numarul mesajelor primite de la algoritmul A pâna în acel moment si trimite un mesaj marker tuturor vecinilor (inundare).
Algoritm de determinare a unui instantaneu distribuit
(codul pentru procesorul pi):
Initial, ans= si num=0.
La primirea unui mesaj al algoritmului A:
1: num:=num+1
2: executa actiunile algoritmului A
La primirea unui mesaj marker sau a indicatiei sa ia un instantaneu:
3: if ans= then
4: ans:=num
5: send marker tuturor vecinilor.
Teorema: Algoritmul de mai sus calculeaza un instantaneu distribuit folosind O(m) mesaje aditionale.
Dem.: Fie k raspunsul calculat de algoritm. Fie pf primul procesor care primeste o indicatie de start. Clar, kf va avea valoarea lui numf din momentul primirii indicatiei de start. Presupunem ca pi si pj a.î. evenimentul de calcul kj al lui pj (în algoritmul A) depinde de evenimentul ki+1 al lui pi (în algoritmul A).
Exista un sir de mesaje ale algoritmului A de la pi la pj: m1, m2, ., ml a.î. m1 e trimis de pi lui pi2 dupa taietura din pi, m2 este trimis de pi2 lui pi3 dupa primirea lui m1 s.a.m.d. iar ml este trimis de pil lui pj dupa primirea lui ml-1 si primit de pj înainte de taietura din pj. Exista deci un mesaj mh care e trimis de pih dupa taietura si primit de pih+1 înaintea taieturii. Dar cum pih este trimis dupa taietura pih a trimis deja mesajul marker lui pih+1 înaintea trimiterii lui mh. Cum canalele sunt organizate FIFO si mesajul marker este primit de pih+1 înaintea lui mh si deci mh n-a fost primit înaintea taieturii.
Observatie: Cei doi algoritmi ignora continutul canalelor (stivelor de mesaje). O solutie e sa presupunem ca starile locale ale procesoarelor patreaza ce mesaje au fost primite si trimise. Atunci informatia despre canale se obtine din colectia starilor procesoarelor. Solutia este nepractica datorita volumului de memorie locala necesar.
O alta solutie se obtine dupa cum urmeaza:
Algoritm de determinare a taieturilor maximale consistente: În tabloul store fiecare componenta contine si numarul de mesaje primite de procesor de la vecinii sai pe lânga VC.
Atunci când trebuie calculata o taietura maximala consistenta, fiecare procesor pi parcurge tabloul sau store înainte, începând cu prima componenta, si simuleaza o "reluare" a mesajelor pe care le-ar fi trimis. Procesul se termina cu ultima intrare, l, din storei a.î.VC din storei[l] este k (taietura data). Consideram un vecin pj oarecare al lui pi. În storei[l] se cunoaste numarul x al mesajelor primite de pi de la pj. Când pi a terminat "reluarea" sa, trimite x lui pj. Când pj primeste mesajul de la pi, asteapta pâna când îsi calculeaza propria sa reluare. Atunci pj calculeaza starea canalului de la pj la pi pentru taietura consistenta ca fiind sufixul, începând cu al (x+1)-lea al secventei de mesaje care este generata de "reluare" pe care el le-a trimis lui pi.
Algoritmul de determinare a unui instantaneu distribuit: se modifica a.î. fiecare procesor pi înregistreaza sirul de mesaje primite de la fiecare pj, de la momentul când pi si-a determinat raspunsul ansi pâna în momentul în care pi primeste un mesaj marker de la pj. Se obtine astfel si informatie referitoare la mesajele în tranzit în configuratia care corespunde instantaneului distribuit.
Problema sesiunii
Relatia a captureaza dependentele din interiorul sistemului, dar nu surprinde interactiunea cu mediul înconjurator.
Problema sesiunii pe care o descriem în continuare poate fi usor rezolvata în sisteme sincrone, însa necesita extra-timp considerabil pentru sisteme asincrone, datorita necesitatii comunicarii explicite.
O sesiune este o perioada minima de timp în care fiecare procesor executa o actiune speciala cel putin o data. Problema sesiunii cere ca pentru un s dat sa se garanteze executia a cel putin s sesiuni.
Mai precis:
-fiecare procesor pi are o variabila întreaga SAi.
-în timpul executiei fiecare procesor pi incrementeaza SAi la anumite evenimente de calcul (incrementarea lui SA reprezinta "actiunea speciala" mentionata mai sus).
-orice executie se partitioneaza în sesiuni disjuncte, unde o sesiune este un fragment de executie în care orice procesor îsi incrementeaza variabila SA cel putin o data.
Problema cere sa se construiasca un algoritm care pentru un s dat sa garanteze ca în orice executie admisibila:
-exista cel putin s sesiuni
-nici un procesor nu-si incrementeaza variabila SA de o infinitate de ori (procesoarele se vor opri odata si odata în executia actiunii speciale).
Timpul de executie este timpul pâna la ultima incrementare a lui SA (folosind conventiile standard de la masurarea timpului în sisteme asincrone).
Pentru sistemele sincrone algoritmul este banal: fiecare procesor este lasat sa execute s actiuni speciale. În fiecare runda avem o sesiune si deci timpul este cel mult s.
În sistemele asincrone timpul de rezolvare a problemei depinde de diametrul retelei de comunicatie.
Teorema: Fie A un algoritm pentru problema s-sesiunii într-un sistem distribuit sincron de tip memorie partajata cu reteaua de comunicatie având diametrul D. Atunci CT a lui A este > (s-1) D.
Dem.: Presupunem, prin reducere la absurd, ca exista un algoritm A cu CT ( s-1) D.
Fie a o executie admisibila a lui A care este sincrona (a consta dintr-o serie de runde, fiecare runda continând un eveniment de livrare pentru fiecare mesaj în tranzit, urmat de un pas de calcul al fiecarui procesor).
Fie bd planificarea lui a unde b se termina la sfârsitul rundei continând ultima actiune speciala. Deci d nu are actiuni speciale (iar b consta din cel mult (s-1)D runde, din ipoteza asupra algoritmului A).
Ideea demonstratiei: Vom înlocui b cu un amestec cauzal al lui bd a.î. sa se realizeze mai putin de s sesiuni si totusi procesorul sa nu distinga aceasta situatie de cea originala si deci ele vor opri executia actiunilor speciale prematur. Intuitiv, aceasta se întâmpla întrucât nu-i timp suficient pentru ca informatia referitoare la îndeplinirea sesiunilor sa circule prin toata reteaua.
Lema 1: Fie g un subsir contiguu al lui b constând din cel mult x runde complete (x-întreg pozitiv). Fie C configuratia ce precede imediat primul eveniment al lui g în executia a.Consideram doua procesoare oarecare pi si pj. Daca dist(pi, pj)>x (în reteaua de comunicatie) atunci exista un sir de evenimente g g g numit split(g, j, i) a.î.:
g este pi-free (nu are evenimente referitoare la pi)
g este pj-free
-exec(C,g') este un segment de executie similar lui exec(C, g
Dem.: Fie ji primul eveniment al lui pi în g si jj ultimul eveniment al lui pj în g (Daca g este pi-free g g si g vid; Daca g este pj-free atunci g g si g vid). Aratam ca ji ajj) (nici un eveniment al lui pj în timpul lui g nu depinde de vreun eveniment al lui pi în timpul lui g). Daca ar exista o astfel de dependenta, ar exista un sir de mesaje de la ji la jj în g. Numarul rundelor necesare pentru acest lant ar fi cel putin dist(pi, pj)+1, din constructia lui a (într-o runda nu exista doua evenimente care sa se influenteze cauzal). Dar acest numar de runde este cel putin x+1, contradictie cu alegerea lui g
Fie R restrictia relatiei a la evenimentele din g la care adaugam perechea (jj ji jj trebuie sa apara înaintea lui ji
R este o relatie de ordine pe multimea evenimentelor din g
Fie g' o ordine totala a evenimentelor din g care este consistenta cu R. Cum g' e consistenta cu restrictia ca ji sa apara dupa jj urmeaza ca g g g unde g este pi-free si g este pj-free.
Întrucât g' este un amestec cauzal al lui g rezulta ca exec(C, g') este un fragment de executie similar lui exec(C, g
Partitionam b b bs-1 , în care fiecare bi consta din cel mult D runde (daca n-ar fi posibil, atunci numarul de runde din b ar fi mai mare de (s-1) D, în contradictie cu presupunerea asupra timpului de executie al lui A).
Alegem p0 si p1 a.î. dist(p0, p1)=D.
Consideram b'i= .
.
Lema 2. Fie C0 configuratia initiala a lui a. Atunci exec(C0, b b's-1) este o executie a lui A care e similara lui exec(C0,b
Dem.: Se arata prin inductie dupa i ca exec(C0,b b'i) este o executie a lui A care este similara lui exec(C0, b bi i s-1. În pasul inductiv se aplica lema precedenta.
Rezulta ca a'=exec(C0, b b's-1 d) e o executie admisibila a lui A.
Aratam ca exista prea putine sesiuni în a', contrazicând ipoteza de corectitudine a lui A.
Sesiunea 1 nu se poate termina înaintea primei parti a lui b'1 întrucât p0 nu face nici un pas în prima parte a lui b'1. Sesiunea 2 nu se poate termina înaintea partii a II-a a lui b'2, caci p1 nu face nici un pas dupa terminarea sesiunii 1 pâna în a doua parte a lui b'2. În acest fel obtinem ca sesiunea s-1 nu se poate termina pâna la a doua jumatate a sectiunii b's-1. Dar ultima parte a lui b's-1 nu contine o sesiune completa întrucât sau p0 sau p1 nu apare în ea!
Cum în g nu se executa nici o actiune speciala, toate sesiunile trebuie incluse în exec(C0, b b's-1) si prin urmare a' contine cel mult s-1 sesiuni
Sincronizarea ceasurilor
Pentru studiul complexitatii timp a sistemelor distribuite asincrone s-a introdus notiunea de t-executie (timed execution). Fiecare eveniment are asociat un timp de aparitie (timpul real) care nu este accesibil procesoarelor.
Modele mai puternice ale sistemelor distribuite presupun ca procesoarele au acces la informatia referitoare la timp prin intermediul ceasurilor hard: acestea ofera aproximatii ale timpilor reali.
Modelul formal al sistemelor distribuite cu ceasuri hard:
Într-o t-executie, se asociaza fiecarui procesor pi o functie HCi:R R. Atunci când pi executa un pas de calcul la timpul real t, HCi(t) e disponibil ca intrare în functia de tranzitie a lui pi. Aceasta functie de tranzitie nu poate modifica HCi.
Vom considera ca "i HCi(t)=t+ci (ceasul hard al procesorului pi masoara fara abateri timpul trecut de la un eveniment la altul).
Pentru fiecare t-executie se poate asocia starea initiala si sirul de evenimente (de calcul si de livrare) asociate unui procesor: view(pi). Putem proceda si invers, din cele n view-uri sa construim o executie.
Definitie: view(pi) într-un model cu ceasuri hard consta dintr-o stare initiala a lui pi, un sir de evenimente (de calcul sau de livrare) ce apar în pi si câte o valoare a ceasului hard asociata fiecarui eveniment. sirul valorilor ceasurilor hard este crescator si daca sirul de evenimente este infinit, atunci sirul valorilor ceasurilor hard este nemarginit.
Definitie: t-view(pi) într-un model cu ceasuri hard este un view(pi) împreuna cu o valoare reala asociata fiecarui eveniment. Aceste valori trebuie sa fie consistente cu ceasurile hard satisfacând HCi(t)=t+ci.
O multime de n t-view-uri hi i=![]() pot fi reunite într-o t-exec astfel:
pot fi reunite într-o t-exec astfel:
Configuratia initiala se obtine considerând starile initiale din hi. Se considera apoi un sir de evenimente prin interleavingul evenimentelor din hi, consistent cu timpii reali (daca exista mai multe evenimente la un moment t se respecta ordinea impusa de evenimentele de livrare, daca nu mai exista alt criteriu de ordonare se folosesc indicii procesoarelor). Aplicând acest sir de evenimente starii initiale se obtine o t-executie. Rezultatul este merge(h hn-1 Aceasta este o executie daca t-view-urile sunt "consistente".
Definitie:
: Fie a o t-exec cu
ceasuri hard si fie ![]() un vector real cu n
componente. Definim shift(a
un vector real cu n
componente. Definim shift(a ![]() ) ca fiind merge(h hn-1) unde hi este t-view-ul obtinut adaugând xi la
timpul real asociat cu fiecare eveniment din a i.
) ca fiind merge(h hn-1) unde hi este t-view-ul obtinut adaugând xi la
timpul real asociat cu fiecare eveniment din a i.
Lema: Fie a o t-exec cu ceasuri hard HCi 0 i n-1 si ![]() un vector real .
un vector real .
In shift(a,![]() ):
):
(a)HC'i (ceasul hard asociat lui pi) este HCi-xi 0 i n-1.
(b)"mesaj de la pi la pj are întârzierea d-xi+xj unde d este întârzierea mesajului din a "i,j
Problema sincronizarii ceasurilor
Fiecare procesor are o componenta speciala de stare adji pe care o poate manipula. Ceasul ajustat al lui pi este functie de HCi si variabila adji.
În procesul de sincronizare a ceasurilor, pi modifica valoarea lui adji si deci schimba valoarea ceasului ajustat.Daca ceasurile hard sunt fara abateri, atunci ACi(t)=HCi(t)+adji(t) unde adji(t) este valoarea lui adji în configuratia imediat dinaintea ultimului eveniment a carui aparitie în timp este mai mare decât t. Daca ceasurile hard sunt fara abateri, odata atinsa sincronizarea nu mai este nevoie de nici o actiune ulterioara.
Atingerea e-sincronizarii ceasurilor: În " t-exec admisibila tf timp real a.î. algoritmul se termina la momentul t f si " pi, pj "t tf ACi(t)-ACj(t) e
e se numeste skew.(distorsiune, perturbatie)
Vom presupune ca d,u d u > 0 a.î. în " t-exec admisibila " mesaj are întârzierea în intervalul [d-u,d].
(pi trimite un mesaj m lui pj la momentul real t, atunci trebuie sa apara un eveniment de livrare a lui m urmat de un pas de calcul al lui pj nu mai târziu de t+d si nu mai devreme de t+d-u).
Vom presupune ca reteaua de comunicare este completa (pentru simplificarea expunerii)
Algoritm de sincronizare a ceasurilor pentru n procesoare
(cod pentru pi , 0 i n-1)
la primul pas de calcul:
1: trimite HC tuturor procesoarelor
la primirea mesajului T de la pj :
2: diff[j]:=T +d -u/2-HC
3: if (s-au primit mesaje de la toate procesoarele) then
adj:= media aritmetica a componentelor vectorului diff
Se poate demonstra
Teorema: Algoritmul atinge u(1-1/n)-sincronizarea ceasurilor.
Observatie: S-a dovedit ca orice algoritm care atinge ε-sincronizarea satisface εS u(1-1/n), ceea ce arata ca algoritmul dat este optimal.
Consens tolerant la defectari
1. Sisteme sincrone cu caderi
Cel mai simplu scenariu de procesare distribuita toleranta la defectari: sisteme distribuite sincrone în care procesoarele "cad" , încetând sa opereze.
Vom considera numai sisteme distribuite sincrone cu topologia graf complet. Canalele vor fi considerate ca fiind fara defecte, deci toate mesajele trimise vor fi livrate.
Sistemul se numeste f-rezilient daca numarul maxim de procesoare care se pot defecta este f.
Definitia unui
executii trebuie modificata pentru un sistem f-rezilent. În sistem
exista o multime F cu ![]() , necunoscuta, a procesoarelor defecte.
, necunoscuta, a procesoarelor defecte.
Fiecare runda care contine exact un eveniment de calcul pentru fiecare procesor care nu-i din F si cel mult un eveniment de calcul pentru fiecare eveniment din F.
În plus, daca un procesor din F nu are un eveniment de calcul într-o runda, atunci nu va mai avea în nici o runda care urmeaza. De asemenea se presupune ca într-o runda în care un procesor cade, vor fi livrate doar o submultime arbitrara dintre mesajele pe care le trimite. Daca am avea o cadere curata - toate mesajele trimise sunt livrate sau nici un mesaj nu este livrat- atunci problemele create se rezolva mult mai simplu.
Fiecare procesor pi are o componenta a starii sale xi (intrarea) si o componenta yi (iesirea sau decizia). Initial xi are o valoare dintr-o multime total ordonata iar yi este nedefinit. Orice asignare asupra lui yi este ireversibila. O solutie la problema consensului trebuie sa garanteze:
Terminarea: În " executie admisibila, yi va primi o valoare pentru fiecare procesor nedefect pi.
Agreement: În " executie daca yi si yj au fost asignate atunci yi = yj pentru " procesoare nedefecte pi si pj. (procesoarele nedefecte nu decid pe valori conflictuale)
Validitate: În " executie daca o valoare v a.î. xi = v pt " pi si daca yi este asignat pentru un procesor nedefect pi, atunci yi =v (daca toate procesoarele au aceeasi intrare, atunci singura valoare pe care ele vor decide este intrarea comuna).
Fiec procesor isi mentine o multime a valorilor pe care el le stie ca în sistem. Initial aceasta multime este formata doar din intrarea sa. În fiecare din cele f+1 runde pe care le executa sistemul, fiecare procesor îsi actualiza multimea sa cu multimile primite de la acel procesor si difuzeaza orice noua modificare. În acest moment, procesoarele decid pe valorile minime din multimea fiecaruia.
Algoritm de consens (codul pentru pi)
Initial V= // V contine intratea lui pi
runda k 1 k f+1
send tuturor procesoarelor
receive Sj de la pj 0 j n-1 j i
![]()
if k = f+1 then y:= min(V)
Terminarea este asigurata deorece algoritmul prevede exact f+1 runde, ultima asignând o valoare a lui y.
Validitatea este asigurata, deoarece aceasta valoare este o intrare a unui procesor.
Conditia de agreement este satisfacuta asa cum rezulta din urmatoarea lema.
Lema: În orice executie, la sfârsitul rundei f+1, Vi = Vj, " doua procesoare nedefecte pi si pj.
Demonstratie: Consideram doua proceasoare nedefecte oarecare pi si pj.
Demonstram ca daca x Vi la sfârsitul rundei f+1 atunci x Vj la sfârsitul rundei f+1. Fie r prima runda la care x este adaugat la un Vk pentru un procesor nedefect pk (r =0 daca x era valoarea initiala a lui pk).
Daca r f, în runda r+1 ( f+1), x va fi trimis lui pj care îl adauga la Vj , daca nu era deja prezent.
Presupunem, deci, ca r= f+1 si
ca pk primeste x pentru prima oara în runda f+1.
Exista un sir de f+1 procesoare ![]() a.î.
a.î. ![]() trimite x lui
trimite x lui ![]() în runda 1,
în runda 1, ![]() lui
lui ![]() în runda 2, ......... ,
în runda 2, ......... , ![]() lui
lui![]() în runda f si
în runda f si ![]() lui pk în
runda f+1. Cum fiecare procesor trimite o valoare particulara o
singura data, acestea sunt distincte. Deci avem o multime de f+1
procesoare care va contine sigur unul nedefect, care deci va adauga x
la multimea sa într-o runda f < r contrazicând alegerea lui r.
lui pk în
runda f+1. Cum fiecare procesor trimite o valoare particulara o
singura data, acestea sunt distincte. Deci avem o multime de f+1
procesoare care va contine sigur unul nedefect, care deci va adauga x
la multimea sa într-o runda f < r contrazicând alegerea lui r.
Teorema: Algoritmul precedent rezolva problema consensului în prezenta a f caderi în f+1 runde.
Fie a o executie admisibila a unui algoritm de consens si fie dec(a) decizia unui procesor oarecare nedefect ( care din conditia de agreement este unic definita).
Ideea obtinerii marginii inferioare: daca procesoarele decid prea devreme ele nu pot distinge o executie admisibila în care ele iau decizii diferite.
Vom presupune f n - 2.
Definitie: Doua executii a si a sunt similare
în raport cu pi, notat ![]() ,
,
daca a | pi = a | pi.
Evident, daca ![]() rezulta ca pi
decide pe aceeasi valoare în ambele executii. Din conditiile de
agreement toate procesoarele nedefecte vor decide pe o aceeasi valoare.
rezulta ca pi
decide pe aceeasi valoare în ambele executii. Din conditiile de
agreement toate procesoarele nedefecte vor decide pe o aceeasi valoare.
Deci, ![]() dec(a1) = dec(a
dec(a1) = dec(a
Consideram închiderea tranzitiva a relatiei ~ notata
a a b bk+1 si pi1,..............,pik a.î.
a b ![]() b
b ![]() ,...,
,...,![]() bk+1 a
bk+1 a
Evident, a a dec(a dec (a
Vom presupune ca " procesor nedefect trimite mesaje la toate celelalte în fiecare runda (daca nu-i asa se pot trimite mesaje fictive).
Consideram mai întâi cazul parcticular când f=1.
Lema. Daca n 3, nu exista algoritm care sa rezolve problema consensului în mai putin de doua runde în prezenta unei singure caderi.
Demonstratie:
Presupunem ca un algoritm în care toate procesele nedefecte decid dupa runda 1, pentru multimea intrarilor .
Fie ![]() executia
admisibila a algoritmului în care procesoarele p0 pâna la
pi-1 au valorile initiale 1 si celelalte 0 (0 i n) (în ao procesoarele au toate
intrarile 0 iar an au toate intrarile 1).
executia
admisibila a algoritmului în care procesoarele p0 pâna la
pi-1 au valorile initiale 1 si celelalte 0 (0 i n) (în ao procesoarele au toate
intrarile 0 iar an au toate intrarile 1).
Daca aratam ca ![]() , contradictie.
, contradictie.
Considerând ![]() excutia în care
procesoarele încep cu aceeasi valoare initiala ca si ai, dar care în
runda 1 se "defecteaza" netrimitând mesaje la ultimele j
procesoare:
excutia în care
procesoarele încep cu aceeasi valoare initiala ca si ai, dar care în
runda 1 se "defecteaza" netrimitând mesaje la ultimele j
procesoare: ![]() , 0 j n-1 (excluzându-se eventual pe el însusi).
, 0 j n-1 (excluzându-se eventual pe el însusi).
Evident ![]() . Pentru fiecare 0 j n-2,
cum n > 3, un
procesor nedefect pk diferit de procesorul care primeste mesaj
în
. Pentru fiecare 0 j n-2,
cum n > 3, un
procesor nedefect pk diferit de procesorul care primeste mesaj
în ![]() dar nu în
dar nu în ![]() . Deci
. Deci ![]()
În ![]() pi nu
trimite mesaje. Daca schimbam intrarea lui pi din 0 în 1
rezulta o executie admisibila
pi nu
trimite mesaje. Daca schimbam intrarea lui pi din 0 în 1
rezulta o executie admisibila ![]() . Pentru " procesor pk pi
. Pentru " procesor pk pi ![]() pentru ca am
modificat intrarea unui procesor care nu trimite mesaje.
pentru ca am
modificat intrarea unui procesor care nu trimite mesaje.
Pentru ![]() consideram
consideram ![]() executia
admisibila în care p0,....... pi încep cu 1 restul
cu 0 si în runda 1 pi trimite mesajele sale la primele j cele
mai mici procesoare, excluzându-se pe el însusi daca este cazul. Ca
mai înainte " j 0 j n-2, cum n un procesor nedefect în pk altul decât
procesorul ce primeste mesajul lui pi în
executia
admisibila în care p0,....... pi încep cu 1 restul
cu 0 si în runda 1 pi trimite mesajele sale la primele j cele
mai mici procesoare, excluzându-se pe el însusi daca este cazul. Ca
mai înainte " j 0 j n-2, cum n un procesor nedefect în pk altul decât
procesorul ce primeste mesajul lui pi în ![]() dar nu în
dar nu în ![]() , deci
, deci ![]() . Evident
. Evident ![]() si deci am
demonstrat ca
si deci am
demonstrat ca ![]()
Cazul general.
Presupunem ca exista un algoritm care rezolva problema consensului în cel mult f runde 1 f n-2.
Un pattern al mesajelor specifica pentru fiecare runda si fiecare procesor care din mesajele trimise de el vor fi livrate altui procesor în acea runda. Clar, patternul mesajelor descrie patternul caderilor.
Un procesor este nedefect în runda r a unei executii daca toate mesajele pe care el le-a trimis în runda r sunt livrate.
O executie admisibila este r - failure-free (r-ff) daca nici un procesor nu este defect într-o runda k. În particular, o executie admisibila este failure-free daca este 1-ff.
Fie a o executie admisibila r-ff cu configuratia initiala I si patternul caderilor M si presupunem ca procesorul pi este nedefect în runda r. Notam cu crash (a, pi, v) executia admisibila cu configuratia initiala I si patternul mesajelor M' unde M' este egal cu M cu exceptia faptului ca pi nu va mai transmite nici un mesaj începând cu runda r; dupa runda r este posibil ca pi sa se comporte diferit în cele 2 executii.
Lema. Pentru " r, 1 r f, daca a este r-ff cu cel mult o defectiune în fiecare runda si procesorul pi este nedefect în a, atunci
a crash (a, pi, r).
Demonstratie: Inductie dupa f-r.
r = f. Fie a r-ff executie si presupunem ca pi e nedefect în a. În runda f exista cel putin 3 procesoare nedefecte . (În fiecare runda se defecteaza cel mult un procesor, în runda f nu avem procesoare defecte deci avem cel mult f-1 procesoare defecte iar f n-2).
Procedam ca în
demonstratia precedenta si construim un sir de
executii eliminând câte un mesaj trimis de pi în runda f
(executia ![]() pâna la
pâna la ![]() ). Cum macar doua procesoare în afara lui pi sunt nedefecte în runda f si numai un
procesor are view-urile diferite în
fiecare pereche de executii consecutive, cel putin un procesor
nedefect are acelasi view în fiecare pereche de executii consecutive.
Deci avem
). Cum macar doua procesoare în afara lui pi sunt nedefecte în runda f si numai un
procesor are view-urile diferite în
fiecare pereche de executii consecutive, cel putin un procesor
nedefect are acelasi view în fiecare pereche de executii consecutive.
Deci avem ![]() pentru fiecare din
executiile consecutive. Ultima executie din acest sir este o
executie în care pi nu trimite nici un mesaj în runda f, deci
crash (a,pi
, f) a
pentru fiecare din
executiile consecutive. Ultima executie din acest sir este o
executie în care pi nu trimite nici un mesaj în runda f, deci
crash (a,pi
, f) a
În pasul inductiv, presupunem ca lema are loc pentru runda r+1, 1 r f-1 si demonstram ca are loc pentru r.
Fie a o executie r-ff cu cel mult o defectiune în fiecare runda si presupunem ca pi este nedefect în runda r.
Evident a este si (r+1)-ff cu cel mult o defectiune în fiecare runda si deci aplicând ipoteza inductiva lui pi obtinem crash(a,pi , v+1) a
Fie a o executie care este exact crash(a,pi , r+1) cu exceptia faptului ca pi cade la sfârsitul rundei r dupa ce trimite toate cele n-1 mesaje, în loc sa cada la începutul rundei r+1.
Dar a0![]() crash(a,pi , r+1) pentu " procesor nedefect pj . Se observa
ca a este (r+1)-ff. În plus a are cel mult
o defectiune pe runda întrucât a este r-ff si în runda r în a se adauga o defectiune prin
constructie.
crash(a,pi , r+1) pentu " procesor nedefect pj . Se observa
ca a este (r+1)-ff. În plus a are cel mult
o defectiune pe runda întrucât a este r-ff si în runda r în a se adauga o defectiune prin
constructie.
Eliminam mesajele lui pi din runda r unul câte unul astfel: pentru " j 1 j n-1, fie aj executia cu aceeasi configuratie initiala ca a si acelasi pattern al mesajelor ca a , cu exceptia faptului ca pi nu trimite în runda r mesaje ultimelor j procesoare, cu exceptia sa, daca este necesar (si desigur nu mai trimite mesaje în viitor). Fiecare aj este (r+1)-ff si are cel mult o cadere pe runda.
Daca demonstram ca a aj-1 " j 1 j n-1 obtinem an-1 a si cum an-1 = crash(a,pi , v) lema este demonstrata.
Fie ph procesorul care prin mesajul lui pi din runda r în aj-1 dar nu în aj ( h = n-1-j daca ultimile j procesoare includ pi , altfel h = n-2-j).
Cazul 1. ph defect în a. Cum a este r-ff, ph cade într-o runda k< r si deci cade
si în aj-1 si în aj . Clar aj-1![]() aj pentru un procesor nedefect pl ( pentru ca r<f n-2 si cel
mult o cadere pe runda). (Nici un procesor nu poate spune daca pi trimite lui ph un mesaj în runda
r, pentru ca ph era deja mort).
aj pentru un procesor nedefect pl ( pentru ca r<f n-2 si cel
mult o cadere pe runda). (Nici un procesor nu poate spune daca pi trimite lui ph un mesaj în runda
r, pentru ca ph era deja mort).
Cazul 2. ph nu este defect în a
Cum aj-1 este (r+1)-ff si are cel mult o cadere pe runda, aplicand ipoteza inductiva, rezulta crash(aj-1 , ph , r+1) aj-1
Similar crash (aj , ph , r+1 ) aj . Cum singura diferenta dintre crash(aj-1 , ph , r+1) si crash (aj , ph , r+1 ) este ca mesajul lui pi catre ph din runda r este prezent în prima si nu este prezent în a doua, iar ph nu va trimite mesaje mai departe, rezulta ca crash(aj-1 , ph , r+1) crash (aj , ph , r+1 ).
Teorema: Nu exista algoritm care sa rezolve problema consensului în mai putin de f+1 runde în prezenta a f caderi daca n f+2.
Demonstratie: Presupunem prin reducere la absurd ca un algoritm care rezolva problema în mai putin de f+1 runde.
Consideram o executie admisibila fara caderi în care toate procesoarele au intrarea 0.
Fie ai i n) executia admisibila a algoritmului fara caderi în care procesoarele p0 pâna la pi -1 încep cu 1 si celelalte încep cu 0. Deci a are toate intrarile 0 iar an are toate intrarile 1. Demonstram ca: a a an si cum dec(a ) = 0 (datorita conditiei de validitate) obtinem ca dec(an) = 0 contrazicand conditia de validitate pentru an
ai este fara caderi deci are cel mult o cadere pe runda. Deci ai crash (ai,pi , 1) si ai+1 crash (ai+1,pi , 1). Cum singura diferenta dintre crash (ai,pi , 1) si crash (ai+1,pi , 1) este intrarea lui pi si cum pi nu trimite mesaje
crash (ai,pi , 1) crash (ai+1,pi , 1).
2. Sisteme sincrone cu caderi bizantine
Defectiunile sunt "rautacioase" fata de cele "curate" ale modelului precedent.
Descrierea metaforica a problemei: Mai multe divizii ale armatei Bizantine sunt campate lânga cetatea inamicului. Fiecare divizie este comandata de un general. Generalii comunica între ei doar prin mesageri (care isi îndeplinesc ireprosabil sarcinile). Generalii trebuie sa decida asupra unui plan comun de actiune, adica sa decida daca sa atace sau nu cetatea (agreement) si daca generalii sunt toti unanimi în opinia lor initiala atunci aceasta trebuie sa fie decizia pe care o vor lua.
Problema este ca unii dintre generali pot fi tradatori (doar sunt în armata bizantina !!) si ei pot încerca sa-i împiedice pe generalii loiali sa fie de acord. Pentru aceasta ei trimit mesaje diferite la generali diferiti, retransmit în mod eronat ce-au auzit de la altii sau chiar pot conspira si forma o coalitie.
Modelul formal: Sistem distribuit sincron f - rezilient.
În orice executie o submultime de cel mult f procesoare care se pot defecta (procesoarele defecte, tradatorii). Într-un pas de calcul al unui procesor defect nu se impune nici o restrictie asupra noii stari sau asupra mesajelor transmise (în particular se poate comporta ca în modelul precedent). Sistemul se comporta ca si în lipsa caderilor: la fiecare runda fiecare procesor executa un pas de calcul si orice mesaj transmis în acea runda este livrat pentru urmatoarea runda.
Problema consensului : exact acelasi enunt.
Spre deosebire de modelul precedent, conditia de valabilitate nu este echivalenta cu a cere ca decizia unui procesor oarecare nedefect sa fie intrarea unui anumit procesor.
Lema: Într-un sistem cu 3 procesoare în care unul poate fi bizantin nu exista un algoritm care sa rezolve problema consensului.
Demonstratie: Presupunem ca exista un astfel de algoritm într-un sistem cu 3 procesoare p0, p1 , p2 conectate printr-un graf complet cu trei vârfuri.
Notam cu A, B, C programele locale ale lui p0, p1 , p2 respectiv.
Consideram un inel sincron cu 6 procesoare în care p0 si p3 au programul local A, p1 si p4 au programul local B si p2 si p5 au programul local C.

Desigur, mesajele dintr-un program local vor fi transmise procesorului vecin cu acelasi program cu cel din triunghi. (p0, nu trimite lui p2 ci lui p5 , p3, nu trimite lui p1 ci lui p4 etc. ).
Considerând b o executie particulara a acestui algoritm pe inel, în care p0, p1 , p2 au intrarea 1 iar p3, p4 , p5 au intrarea 0.
Revenim la problema nostra.
Consideram a executia algoritmului în
în care toate procesoarele pornesc cu 1 si procesorul p2 este defect. Mesajele pe care le trimite p2 le consideram ca fiind:
p2 p0 mesajele trimise în b de p5 lui p0
p2 p0 mesajele trimise în b de p2 lui p1
Din conditia de validitate, p0 si p1 vor decide pe 1 în a
Consideram a executia algoritmului în în care toate procesoarele pornesc cu intrarea 0 si procesorul p0 este defect.
Mesajele pe care le trimite p0 le consideram ca fiind:
p0 p1 mesajele trimise în b de p3 lui p4
p0 p2 mesajele trimise în b de p0 lui p5
Din conditia de validitate, p1 si p2 decid pe 0 în a
Consideram a executia algoritmului în care p0 porneste cu intrarea 0, p1 porneste cu intrarea 1, p2 porneste cu intrarea 0 si defect este p1.
Mesajele pe care le trimite p1 le consideram ca fiind:
p1 p2 mesajele trimise în b de p4 p5
p1 p0 mesajele trimise în b de p1 p0
Observam ca :
p0 are acelasi view în a pe care îl are si în b
p0 are acelasi view în b pe care îl are si în a
Deci (inductiv dupa numarul de runde) a ![]() a p0
decide 1 în a
a p0
decide 1 în a
Similar a ![]() a p2 decide 0 în a
a p2 decide 0 în a
Dar acesta contravine conditiei de agreement. Contradictie.
Teorema Într-un sistem cu n procesoare dintre care f sunt bizantine nu exista un algoritm care sa rezolve problema consensului daca n 3f.
Demonstratie. Presupunem, prin reducere la absurd, ca exista un astfel de algoritm.
Partitionam
multimea procesoarelor în P0, P1, P2
fiecare continând cel mult ![]() procesoare.
procesoare.
Consideram un sistem cu trei procesoare . Pentru acest sistem descriem un algoritm de consens care poate tolera o cadere bizantina (contrazicând teorema precedenta).
În algoritm, p0 simuleaza toate procesoarele din P0, p1 pe cele din P1 si p2 pe cele din P2.
Daca unul din
procesoare în sistemul este defect cum ![]() rezulta ca în sistemul simulat cu n procesoare avem
cel mult f procesoare defecte. Algoritmul simulat trebuie sa pastreze
validitatea si conditia de agreement din sistemul simulat si
deci si în sistemul cu 3 procesoare.
rezulta ca în sistemul simulat cu n procesoare avem
cel mult f procesoare defecte. Algoritmul simulat trebuie sa pastreze
validitatea si conditia de agreement din sistemul simulat si
deci si în sistemul cu 3 procesoare.
Prezentam un algoritm care în f +1 runde rezolva problema consensului în ipoteza ca n 3f+1. Totusi, foloseste mesaje de dimensiune exponentiala
Algoritmul are doua etape:
- I se colecteaza informatia prin comunicare între procesoare
- II pe baza informatiei colectate, fiecare procesor ia decizia sa.
Este convenabil sa descriem informatia mentinuta de fiecare procesor cu ajutorul unor arbori etichetati.
Arborele fiecarui procesor are proprietatea ca oricare drum de la radacina la frunze are f+2 noduri (arborele are adâncimea f+1). Fiecare nod este etichetat cu siruri de nume de procesoare astfel:
radacina are eticheta cuvântul vid l
nodul v cu eticheta i1 i2 ...ir (de pe nivelul r+1; aflat la adâncimea r) are ca descendenti câte un nod etichetat i1 i2 ...ir i pentru oricare
i (etichetele au simboluri distincte).
Vom spune ca nodul i1 i2 ...ir-1 i de pe nivelul r corespunde procesorului i.
În runda 1: fiecare procesor trimite valoarea sa tuturor procesoarelor (inclusiv lui însusi; aceasta se simuleaza)
În runda 2: (fiecarui procesor îi sunt livrate mesajele din runda precedenta si procesoarele nedefecte memoreaza valoarea primita de la procesorul pj în nodul etichetat j de pe nivelul 1. Deci fiecare procesor nedefect are completat arborele:

fiecare procesor trimite un mesaj format din nivelul 2 din arborele sau celorlalte procesoare.
În runda 3: (fiecare procesor a luat mesajul primit de la pj si valoarea memorata de pj în nodul i, o memoreaza în nodul ij de pe nivelul 3.
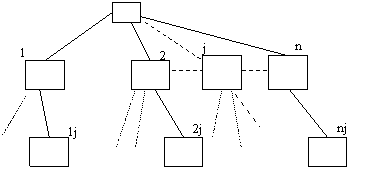
fiecare procesor trimite un mesaj format din nivelul 3 din arborele sau celorlalte procesoare.
În runda r fiecare procesor difuzeaza celorlalte nivelul r din arborele sau.
Cînd un procesor primeste un mesaj de la pj cu valoarea din nodul arborelui lui pj etichetat i1 i2 ...ir-1 = x, el memoreaza valoarea x în nodul
i1 i2 ...ir j din arborele sau.
Intuitiv pi memoreaza în i1 ...ir j valoarea: "pj spune ca pir spune ca
pir-1 spune ca .... ca ![]() spune x".
spune x".
Vom nota aceasta valoare treei (i1, ..., iv, j) omitind indicile i când nu este pericol de confuzie.
Faza I-a contine f+1 runde, când se umple fiecare arbore al procesoarelor.
Urmeaza faza II-a.
Procesorul pi îsi calculeaza decizia sa aplicând fiecarui subarbore o functie recursiva resolve. În arborele lui pi, daca avem un subarbore etichetat p, valoarea determinata de functie o notam resolvei (p). (eventual omitând indicele).
Decizia luata de pi va fi resolvei ( )(aplicarea functiei radacinii arborelui)
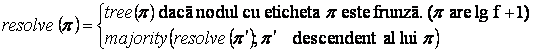
Observatie:
daca în prima faza a algoritmului un nod primeste o valoare nelegitima sau nu primeste o valoare (procesorul care ar fi trebuit sa i-o trimita este defect) nodul memoreaza în nodul corespunzator o valoare default v
daca majority nu exista functia resolve ia valoarea v
Fixam o executie admisibila a algoritmului. Sa reamintim ca daca un nod p din arborele lui pi corespunde lui pj atunci valoarea memorata în tree(p) a fost primita într-un mesaj de la pj.
Lema 1. Pentru orice nod p de forma p'j unde pj este nedefect avem
resolvei (p) = treej (p') , " pi nedefect.
Demonstratie: Inductiv dupa adâncimea lui p în arbore, pornind din frunze.
p frunza: prin definitie resolvei(p) = treei(p), dar treei(p) memoreaza valoarea lui p' pe care pj o trimite lui pi în ultima runda. Cum pj nu este defect acceasta valoare este treej(p
p nod intern. Cum arborele are f +2 nivele radacina are n descendenti si la fiecare nivel numarul descendentilor scade cu 1 p are cel putin n - f descendenti. Cum n 3f+1 gradul lui p este 2f +1. Majority aplicata descendentilor lui p corespunde procesoarelor nedefecte. Fie pk un descendent al lui p (care corespunde procesorului nedefect pk). Din ipoteza inductiva, resolvei(pk) = treek(p), pj nedefect treek(p) = treej (p') adica pj îi spune corect lui pk valoarea pe care pj a memorat-o în p
Deci pi rezolva fiecare copil al lui p corespunzator unui procesor nedefect ca fiind treej(p') si deci resolvei(p) este egala cu valoarea majoritara treej(p
Algoritmul satisface conditia de validitate. Presupunem ca toate procesoarele nedefecte pornesc cu aceasi valoare v initiala. Decizia fiecarui procesor nedefect pi este resolvei(), care este valoarea majoritara din valorile rezolvate pentru descendentii radacina. Pentru fiecare descendent j cu pj nedefect, lema precedenta asigura ca resolvei(j) = treej( ) =v (pj nu este defect). Cum valoarea majoritara corespunde procesoarelor nedefecte pi decide pe v.
Pentru a demonstra conditia de agreement consideram urmatoarea definitie:
Nodul p este comun într-o executie daca toate procesoarele nedefecte calculeaza aceeasi valoare în nodul p
resolvei(p) = resolvej(p " pi, pj nedefecte.
Un subarbore are frontiera comuna daca exista un nod comun pe oricare drum din radacina subarborelui la frunzele sale.
Lema 2. Fie p un nod. Daca subarborele cu radacina în p are frontiera comuna p e comun.
Demonstratie: Inductiv dupa înaltimea lui p
Daca p este frunza, evident. În pasul inductiv,
presupunem ca lema are loc pentru orice nod cu înaltimea k si fie p cu înaltimea k+1. Presupunem ca p nu este comun. Cum subarborele cu radacina în p are frontiera comuna orice subarbore cu radacina în copiii lui p are frontiera comuna, si din ipoteza inductiva fiecare copil al lui p este comun. Deci toate procesoarele rezolva aceeasi valoare pentru toti copii lui p si prin urmare si pentru p (pentru ca se aplica majoritatea ).
Rezulta ca p este comun.
Nodurile de pe fiecare drum de la un copil al radacinei la o frunza corespund la procesoare diferite (f+1), cel putin unul este nedefect si deci este comun conform lemei 1. Deci, lema 2 asigura faptul ca radacina este comuna, adica are loc conditia agreement.
Concluzie
Teorema. Daca n > 3f, exista un algoritm pentru n procesoare care rezolva problema consensului în prezenta a f caderi bizantine în f+1 runde, folosind mesaje de dimensiune exponentiala.
Observatie MC = n2 (f+1) (numarul mesajelor trimise).
Mesajul cel mai lung trimis contine n(n-1)...(n-(f+1)) = q (nf+2) valori.
Daca n > 4f se poate construi un algoritm cu mesaje de dimensiune constanta care rezolva problema în 2(f+1) runde
Algoritmul are f+1 faze, fiecare faza cu 2 runde.
Pentru fiecare faza, fiecare procesor are o decizie preferata (preferinta sa), initial, aceasta fiind valoarea sa.
În prima runda a fiecarei faze toate procesoarele îsi trimit preferinta lor tuturor celorlalte.
Fie ![]() valoarea
majoritara în multimea valorilor primite de un procesor pi
la sfârsitul primei runde din faza k (daca nu exista majoritate
se foloseste o valoare default vT).
valoarea
majoritara în multimea valorilor primite de un procesor pi
la sfârsitul primei runde din faza k (daca nu exista majoritate
se foloseste o valoare default vT).
În a doua runda a
fiecarei faze k, procesorul pk - numit regele fazei -
trimite valoarea sa majoritara ![]()
![]() celorlalte procesoare.
celorlalte procesoare.
Daca un procesor
pi primeste > ![]() copii a lui
copii a lui ![]() (în prima runda a
fazei) atunci el considera preferinta sa pentru faza urmatoare
ca fiind
(în prima runda a
fazei) atunci el considera preferinta sa pentru faza urmatoare
ca fiind ![]() . Altfel, alege drept preferinta sa pentru faza
urmatoare ca fiind cea a regelui
. Altfel, alege drept preferinta sa pentru faza
urmatoare ca fiind cea a regelui ![]() (primita în runda
2-a a fazei).
(primita în runda
2-a a fazei).
Dupa f+1 runde procesorul decide pe preferinta sa
Algoritm polinomial de consens în prezenta caderilor bizantine
Codul
pentru pi ( 0![]() )
)
Initial pref i = x pref j = v " j i
Runda 2k-1 ![]() //
prima runda a fazei k
//
prima runda a fazei k
send < pref i > tuturor procesoarelor
receive < vj > de la pj si asigneaza-l lui pref j j n-1, j i
fie maj valoarea majoritara din pref , ..., pref n-1 (v daca nu
exista)
fie mult multiplicitatea lui maj
Runda 2k, 1 k f+1 // a doua runda a fazei k.
5: if i=k then send <maj> tuturor procesoarelor // regele fazei
receive <king-maj> from pk (v daca nu exista)
if mult > ![]()
then pref [i]: = maj
else pref [i]: = king-maj
10: if k= f+1 then y : = pref [i] // decide
Lema 1. Daca toate procesoarele nedefecte prefera v la începutul fazei k, atunci toate prefera v la sfârsitul fazei k, " k, 1 k f+1.
Demonstratie: Cum toate prefera v la începutul fazei k fiecare precesor primeste cel putin n-f copii ale lui v (inclusiv pe a sa) în prima runda a fazei k. Cum n > 4f n-f > n/2 + f ; deci toate procesoarele prefera v la sfârsitul fazei k.
Din acesta lema rezulta imediat proprietatea de validitate: daca toate procesoarele nedefecte încep cu aceeasi valoare de intrare v atunci ele vor prefera v în toate fazele; deci si în faza f+1 când vor decide pe v.
Conditia de agreement este asigurata de interventia regilor. Cum sunt f+1 faze, macar o faza are un rege nedefect.
Lema 2. Fie g o faza astfel încât regel pg nu este defect. Atunci toate procesoarele nedefecte sfârsesc faza g cu acceasi preferinta.
Demonstratie: Presupunem ca toate procesoarele nedefecte folosesc valoarea majoritara primita de la rege ca preferinta. Cum regele nu este defect, trimite acest mesaj tuturor si deci ele vor avea aceeasi preferinta.
Presupunem ca un
procesor nedefect pi foloseste valoarea majoritara
proprie v ca preferinta. Deci pi primeste mai mult de ![]() mesaje egale cu v în
prima runda a fazei g. În consecinta orice procesor (inclusiv regele pg )
primeste
mesaje egale cu v în
prima runda a fazei g. În consecinta orice procesor (inclusiv regele pg )
primeste ![]() mesaje egale cu v în
prima runda a fazei g si isi va alege valoarea sa
majoritara egala cu v. Deci în faza g+1 toate procesoarele vor avea
acceasi preferinta si lema 1 ne asigura ca vor
decide pe acceasi valoare la sfârsit. Concluzie:
mesaje egale cu v în
prima runda a fazei g si isi va alege valoarea sa
majoritara egala cu v. Deci în faza g+1 toate procesoarele vor avea
acceasi preferinta si lema 1 ne asigura ca vor
decide pe acceasi valoare la sfârsit. Concluzie:
Teorema: Daca n>4f, algoritmul precedent rezolva problema consensului în prezenta a f defectiuni Bizantine în 2(f+1) runde folosind mesaje de dimensiune constanta.
Observatie. In cazul sistemelor distrbuite asincrone, nu se poate rezolva problema consensului, chiar în prezenta unei singure defectuni.
|
