Vestea buna despre Internet si despre componenta sa vizibila, World Wide Web-ul, este ca exista miliarde de pagini disponibile, pagini care asteapta sa fie vizitate pentru a oferi informatii despre o miriada de subiecte. Ceea ce este mai putin bun este ca exista milioane de pagini disponibile, cele mai multe dintre ele denumite în functie de dorinta autorului, toate pe servere cu nume criptice sau protejate. Totusi, în momentul în care un utilizator doreste sa acceseze un anumit subiect, acesta utilizează 626e45g ; un motor de cautare pe Internet.
Motoarele de cautare pe Internet sunt site-uri web specializate, create pentru a ajuta oamenii sa gaseasca informatii stocate în alte site-uri. Exista multe diferente în modul în care lucreaza diferitele motoare de cautare, dar acestea executa în general aceleasi trei sarcini de baza:
cauta pe Internet sau "selecteaza" parti din Internet, pe baza cuvintelor importante;
retin un index al cuvintelor pe care le gasesc si a locului acestora;
permit utilizatorilor sa caute cuvinte sau combinatii de cuvinte gasite în acest index.
Motoarele de cautare initiale detineau un index cu câteva sute de mii de pagini si documente, si receptionau si serveau cam doua mii de cereri pe zi. Astazi, un motor de cautare de vârf indexeaza sute de milioane sau chiar miliarde de pagini si raspunde la zeci de milioane de interogari pe zi. În continuare vom vedea modalitatea în care sunt executate aceste sarcini si cum motoarele de cautare de pe Internet alatura date separate pentru ca utilizatorul sa gaseasca ceea ce are nevoie.
Când se vorbeste despre motoare de cautare pe Internet, se vorbeste în general despre motoare de cautare pe World Wide Web. Totusi, înainte ca web-ul sa devina partea proeminenta a Internetului, existau si alt fel de motoare de cautare, care permiteau utilizatorilor sa gaseasca informatii în Internet. Astfel, exista si astazi, dar se utilizeaza foarte putin, programe precum "gopher" sau "Archie", care tineau indexuri de fisiere stocate pe serverele conectate le Internet, reducând în mod semnificativ timpul necesar gasirii programelor sau documentelor. La sfârsitul anilor 1980, utilizarea la maximum a Internetului însemna utilizarea programelor "gopher", "Archie", "Veronica" etc. Astazi cei mai multi utilizatori îsi limiteaza cautarile la serverele web, ftp sau de grupuri de dialog.
Înainte ca un motor de cautare sa poate spuna utilizatorilor unde se gasesc anumite documente, acestea trebuie sa fie mai întâi gasite. Pentru a gasi informatii din miliardele de pagini web, un motor de cautare foloseste o aplicatie speciala, numita "robot de cautare" sau "spider", pentru a construi o lista de cuvinte gasite în paginile web. Procesul prin care un spider îsi construieste lista se numeste "web crawling", iar pentru ca un motor de cautare/spider sa construiasca o lista eficienta de cuvinte, acesta trebuie sa caute printr-o multime de pagini.
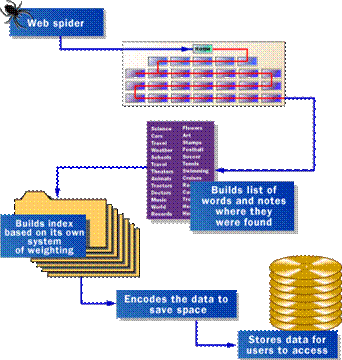
Figura : Un "Spider" obtine continutul unei pagini web si creeaza o lista de cuvinte cheie care permit utilizatorilor sa gaseasca informatiile pe care le doresc.
Un spider îsi începe cautarea prin web pornind de obicei de la o lista cu servere intens utilizate si cu pagini web foarte populare. Spider-ul va începe cu un site popular, indexând cuvintele din pagini si urmând toate legaturile gasite în site-ul respectiv, ajungând în acest fel sa traverseze si sa indexeze partea cea mai utilizata a web-ului.
Google.com a început ca un motor de cautare academic. În lucrarea care descrie modalitatea de construire a acestuia, Sergey Brin si Lawrence Page au exemplificat cât de repede poate sa lucreze un spider. Astfel, sistemul a fost construit pentru a utiliza mai multi spider-i, trei de obicei, fiecare spider putând sa tina deschise 300 de conexiuni catre pagini web la un moment dat. La cea mai ridicata performanta, folosind patru spider-i, sistemul putea cauta în peste 100 pagini pe secunda, generând 600 kilobytes de date în fiecare secunda.
Mentinerea unui sistem rapid însemna de asemenea construirea unui sistem care sa alimenteze spider-ii cu informatii. Astfel, Google.com initial avea un server dedicat pentru a oferi URL-uri spider-ilor. Google avea de asemenea si propriul server DNS, translatarea numelor în adrese fiind semnificativ mai rapida, micsorând în acelasi timp si întârzierile datorate retelelor.
În momentul în care un spider Google vizita o pagina HTML, acesta tinea cont de doua lucruri:
cuvintele gasite în pagina;
pozitia acestor cuvinte în pagina.
Cuvintele gasite în titlu, subtitlu, metatag-uri si alte pozitii de importanta relativa erau notate cu o semnificatie speciala în timpul cautarilor initiate de utilizatori. De asemenea, spider-ul a fost construit pentru a indexa toate cuvintele semnificative din pagina, lasând la o parte cuvintele de legatura.
Alti spider-i folosesc alte procedee pentru indexare, permitând, spre exemplu, spider-ilor sa opereze mai rapid sau sa permita utilizatorilor sa caute mai eficient sau ambele. De exemplu, unii spider-i mentin o lista de cuvinte din titlu, subtitlu si legaturi, împreuna cu cele mai utilizate 100 de cuvinte din pagina si fiecare cuvânt din primele 20 de linii de text. Se pare ca Lycos utilizeaza aceasta modalitate de indexare a continutului paginilor web.
Alte sisteme, precum AltaVista.com, merg în alta directie, indexând toate cuvintele din pagina, inclusiv toate cuvintele de legatura sau "nesemnificative". Aceasta împingere catre completitudine are si alte modalitati de functionare, mai ales prin utilizarea meta-tag-urilor.
Meta-tag-urile permit proprietarului unei pagini sa specifice cuvintele cheie si conceptele sub care va fi indexata pagina respectiva. Acest lucru poate fi folositor în cazul în care cuvintele din pagina pot avea doua sau mai multe semnificatii, meta-tag-urile ghidând motorul de cautare în alegerea celei mai corecte semnificatii pentru cuvintele respective. Exista de asemenea si anumite pericole în utilizarea acestor tag-uri, deoarece un proprietar neatent sau fara scrupule ar putea adauga meta-tag-uri care sa se potriveasca celor mai populare subiecte, fara ca acestea sa aiba nimic cu continutul în sine al paginii. Pentru o protectie împotriva acestei practici, spider-ii coreleaza de obicei continutul paginii cu meta-tag-urile, respingând tag-urile care nu se potrivesc cu cuvintele din pagina.
Toate cele de mai sus presupun faptul ca proprietarul paginii sau site-ului doreste ca pagina/site-ul sa fie inclus în rezultatele activitatii motoarelor de cautare. De multe ori proprietarii nu doresc includerea într-un motor de cautare major sau nu doresc indexarea anumitor pagini dintr-un site. Pentru acest lucru a fost dezvoltat protocolul de excludere al robotilor (robot exclusion protocol). Acest protocol, implementat în sectiunea de meta-tag-uri de la începutul unei pagini web, comunica robotului de cautare sa nu indexeze pagina si/sau sa nu urmareasca nici unul din link-urile din pagina respectiva.
Dupa ce spider-ii au terminat sarcina de gasire a informatiilor în paginile web (trebuie sa notam faptul ca aceasta sarcina nu se termina niciodata - din cauza naturii mereu schimbatoare a web-ului, spider-ii indexeaza pagini în permanenta), motorul de cautare trebuie sa stocheze informatiile adunate într-o modalitate utilizabila. Exista astfel doua componente care fac datele adunate accesibile utilizatorilor:
informatia stocata cu datele;
metoda în care este indexata informatia.
În cel mai simplu caz, un motor de cautare doar va stoca cuvintele si URL-ul unde au fost gasite. În realitate, acest lucru ar face dintr-un motor de cautare unul cu utilizari limitate, deoarece nu ar exista nici o modalitate de a spune daca acel cuvânt a fost utilizat într-un context important sau unul trivial în pagina respectiva, nici daca acel cuvânt a fost utilizat o singura data sau de mai multe ori, sau daca pagina contine legaturi catre alte pagini cu acel cuvânt. Cu alte cuvinte, nu ar fi nici o posibilitate de a construi un clasament care ar încerca sa prezinte cele mai utile pagini la începutul listei de rezultate.
Pentru a crea si afisa cele mai utile rezulte, cele mai multe motoare de cautare stocheaza mult mai multe date decât cuvântul si URL-ul în care a fost gasit. Un motor ar putea stoca numarul de aparitii al cuvântului în pagina, putând de asemenea sa asigneze câte o "greutate" fiecarei intrari, cu valori mai mari atasate cuvintelor care apar catre începutul documentului, în subtitluri, legaturi, meta-tag-uri sau titlul paginii. Fiecare motor de cautare comercial are diferite formule sau modalitati pentru asignarea greutatii pentru cuvintele din index. Acesta este unul din motivele pentru care o cautare dupa acelasi cuvânt în motoare de cautare diferite va produce liste de rezultate diferite, cu paginile prezentate în ordini diferite, chiar daca sunt indexate aceleasi pagini.
Fara a tine cont de combinatia precisa de informatii aditionale stocate de un motor de cautare, datele vor fi stocate în mod codat, pentru a economisi spatiul de stocare. De exemplu, documentul original de prezentare al Google.com utiliza 2 bytes, fiecare din 8 biti, pentru a stoca informatii referitoare la greutate: cuvântul era scris cu litere mari, marimea fontului, pozitia sau alte informatii necesare clasificarii. Fiecare factor putea lua 2 sau 3 biti în cei 2 bytes, având ca rezultat stocarea unui volum mare de informatii într-un spatiu foarte compact.
Dupa ce informatia este compactata/condata, aceasta este gata de indexare. Un index are un singur scop: permite gasirea foarte rapida a informatiei. Exista mai multe modalitati de a construi un index, dar una din cele mai eficiente modalitati este utilizarea unui tabel hash (hash table). Prin hashing, se aplica o formula matematica pentru atasarea unei valori numerice fiecarui cuvânt, formula fiind construita pentru a distribui în mod egal intrarile de-a lungul unui numar predeteminat de diviziuni. Distributia numerica este diferita de distributia cuvintelor din alfabet, aceasta fiind cheia eficientei unui tabel hash.
În limba engleza, de exemplu, exista unele litere cu care încep cele mai multe cuvinte, în timp ce alte litere sunt la începutul a mai putine cuvinte (comparati litera "M" din dictionar cu litera "X"). Aceasta inegalitate înseamna ca gasirea unui cuvânt care începe cu o litera mai "populara" ar putea lua mai mult timp decât gasirea unui cuvânt care începe cu o litera mai putin utilizata la începutul cuvintelor. Prin hashing se elimina aceasta diferenta si se reduce timpul mediu pentru a gasi o intrare. Tot prin hashing se separa cuvintele de indecsii în sine. Tabela hash contine numarul hash împreuna cu un pointer catre datele efective, date care pot fi sortate în orice directie. Combinatia de indexare si stocare eficienta face posibila obtinerea rapida a rezultatelor, chiar daca utilizatorul creeaza o interogare complexa.
Cautarea printr-un index presupune construirea unei interogari de catre utilizator si transmiterea ei catre motorul de cautare. Interogarea poate fi simpla, alcatuita din minim un cuvânt sau mai complexa, necesitând operator booleeni, care permit rafinarea si extinderea cautarii.
Operatorii booleeni cei mai des utilizati sunt urmatorii:
AND - toti termenii separati prin "AND" trebuie sa apara în pagina sau în document. Unele motoare de cautare pot folosi "+" în loc de "AND";
OR - cel putin unul din termenii separati prin "OR" trebuie sa apara în pagina sau document;
NOT - termenul sau termenii care urmeaza dupa "NOT" nu trebuie sa apara în document. Unele motoare de cautare pot folosi "-" în locul cuvîntului "NOT";
FOLLOWED BY - unul din termeni trebuie sa fie urmat în mod direct de catre altul;
NEAR - unul din termeni trebuie sa fie la o distanta specificata în cuvinte de celalalt termen;
Ghilimele - cuvintele dintre ghilimele sunt tratate sub forma de fraza, iar acea fraza trebuie sa fie gasita în interiorul documentului sau paginii;
Cautarile definite prin operatorii booleeni sunt cautari "literale", în care motorul cauta cuvintele sau frazele exact cum sunt introduse. Acest lucru poate fi o problema în cazul cuvintelor cu mai multe întelesuri. În cazul în care utilizatorul este interesat doar în gasirea paginilor care contin doar unul din sensuri, se pot astfel de interogari, dar ar fi mai util ca motorul de cautare sa realizeze acest lucru în mod automat.
Astfel, una din ariile de cercetare în domeniul motoarelor de cautare este cel al "cautarii bazate pe concepte". Unele din aceste cercetari presupun utilizarea analizei statistice în pagini care contin cuvintele sau frazele care sunt cautate, pentru a gasi alte pagini în care utilizatorul ar putea fi interesat.
Alte domenii de cercetare privesc interogarile bazate pe limbaj natural, putând astfel fi introduse interogari la fel ca întrebarile puse oamenilor, fara a mai fi nevoie de operatori booleeni sau structuri de interogari complexe. Cel mai important motor de cautare care foloseste limbajul natural este AskJeeves.com, care parseaza interogarile pentru a gasi cuvintele cheie, pe care le aplica mai apoi indexului de site-uri construit. AskJeeves.com lucreaza cel mai bine cu interogari simple, dar exista o competitie deosebita în acest sens.
În tabelul urmator se poate observa o comparatie între trei motoare de cautare foarte populare.
|
Motor de cautare |
Google |
Yahoo! Search |
|
|
Link-uri pentru ajutor |
|
|
|
|
Marime (marimea variaza de la o zi la alta) |
Peste 8 miliarde pagini. Aproximativ 25% nu sunt indexate pe deplin (nu pot fi cautate cuvinte în interior). Paginile neindexate sunt afisate în cazul în care interogarea se potriveste cu titlul sau cu alte pagini care conduc la ele. |
Peste 3 miliarde de pagini, indexate si interogabile în întregime. |
Pretinde ca are 1 miliard de pagini indexabile si interogabile în întregime si înca 1 miliard indexate partial. |
|
Facilitati si limitari |
Clasificarea rangurilor este facuta cu PageRankT. Limitare la 10 cuvinte pe cautare, excluzînd OR. Indexeaza primii 101 KB din pagini web si 120 KB din documente PDF. |
Prescurtarile permit acces rapid la dictionar, sinonime, patente, trafic, actiuni, enciclopedie etc. |
Rang în functie de Subject-Specific PopularityT. Sugereaza termini în rezultat pentru a-l rafina. Sugereaza pagini cu multe link-uri în rezultate. |
|
Cautare dupa fraza |
Da. Utilizeaza " ". Utilizeaza si cuvinte de oprire în fraza. |
Da. Utilizeaza " ". |
Da. Utilizeaza " ". Utilizeaza si cuvinte de oprire în fraza. |
|
Logica booleana |
Partiala. AND este implicit între cuvine. OR trebuie scris cu litere mari. "-" pentru excludere. Nu permite paranteze sau imbricare. |
Accepta AND, OR, NOT, AND NOT, (), toate scrise cu litere mari. |
Partiala. AND este implicit între cuvine. OR trebuie scris cu litere mari. "-" pentru excludere. Nu permite paranteze sau imbricare. |
|
+Necesita / -Excludere |
- excludere + permite gasirea cuvintelor de oprire (ex: +in) |
- excludere + permite gasirea cuvintelor comune "+in truth" |
- excludere + permite gasirea cuvintelor de oprire (ex: +in) |
|
Sub-cautare |
La sfîrsitul paginii de rezultat exista "Search within results" pentru a introduce mai multi termini |
Adaugare de termeni |
Adaugare de
termeni. |
|
Clasificarea rezultatelor |
Bazata pe popularitatea paginii masurata în legaturi catre ea de la alte pagini: rang înalt daca multe alte pagini se leaga la ea. Este implicat si FuzzyAND[1]. Rang si pe baza paginilor din cache, care pot sa nu fie cele mai recente. |
FuzzyAND automat. |
Bazat pe Subject-Specific PopularityT, legaturi catre o pagina de la pagini înrudite. |
|
Limitarea cîmpurilor |
link: |
link: |
intitle: |
|
Trunchiere |
Nu. Cautare cu
variante de terminatii si sinonime separate prin OR: |
Nu. Cautare cu
variante de terminatii si sinonime separate prin OR: |
Nu. Cautare cu
variante de terminatii si sinonime separate prin OR: |
|
Diferenta litera mare/litera mica |
Nu. |
Nu. |
Nu. |
|
Limba |
Da, în "Advanced Search". |
Da. |
Da. Utilizare cu lang: |
|
Limitare dupa data documentului |
In "Advanced Search" si cu daterange: |
In "Advanced Search" |
In "Advanced Search" |
|
Traducere |
Da. Din/în Engleza din/în limbi majore internationale si chineza,coreana,japoneza |
Da. |
Tabelul : Comparatie între trei motoare de cautare populare.
Meta-motoarele de cautare transmit interogarea tastata de utilizator catre mai multe motoare de cautare în acelasi timp, afisînd catre utilizatori rezultatele tuturor cautarilor, în toate motoarele de cautare. Acest tip de motoare de cautare nu detine propria baza de date cu pagini indexate, transmitînd interogarile catre bazele de date detinute de companiile care detin motoare de cautare.
Totusi, din ce în ce mai putine meta-motoare de cautare permit gasirea de date în cele mai utile baze de date, ele gasindu-si rezultatele din motoare de cautare gratuite sau de dimensiuni mici ca si din directoare (de subiecte) mici si cu un intens caracter comercial.
|
Meta-motoare de cautare |
In ce cauta |
Interogari complexe |
Afisare rezultate |
|
Vivisimo |
Cauta într-un numar de motoare de cautare redus si de o calitate îndoielnica. |
Accepta si translateaza cautarile complexe cu operatori booleeni si limitari de cîmp. |
Rezultatele sunt însotite de subdiviziuni ale subiectului bazat pe cuvintele din rezultate, dînd de obicei temele majore rezultate. |
|
Metacrawler |
Cauta în Google, Yahoo, LookSmart, Teoma, Overture, FindWhat. Include, fara sa mentioneze exemplicit, ranguri cumparate. |
Accepta logica booleana, mai ales în modurile de cautare avansata. |
Permit si vizualizarea separata a rezultatelor fiecarui motor de cautare. |
Tabelul : Meta-motoare de cautare.
Partea vizibila a web-ului este ceea ce se poate obtine în rezultatele motoarelor de cautare sau în directoarele de subiecte. Web-ul invizibil este acea parte din web care nu se poate obtine în rezultatele cautarii precum si alte link-uri continute în aceste tipuri de pagini.
Baze de date : cea mai mare parte a web-ului invizibil este alcatuita din continutul al mii de baze de date specializate care pot fi cautate prin web. Rezultatele cautarii în multe din aceste baze de date sunt transmise catre utilizatorul final sub forma de pagini web care sunt generate doar ca raspuns la interogarea utilizatorului. Asemenea pagini nu sunt stocate nicaieri, fiind mai ieftin si mai rapid de generat în mod dinamic raspunsul fiecarei interogari decât de stocat toate paginile posibile continând toate raspunsurile posibile la întrebarile sau interogarile diversilor utilizatori.
Paginile excluse: exista anumite tipuri de pagini care sunt excluse din rezultatele motoarelor de cautare din cauza politicilor. Nu exista nici un motiv tehnic ca aceste pagini sa nu fie incluse în rezultat, fiind mai mult o chestiune de selectare includerii sau neincluderii în baze de date deja uriase si a caror interogare produce un venit nesemnificativ.
De ce sunt unele pagini invizibile ? Exista doua motive pentru care un motor de cautare nu contine o pagina: 1. motive tehnice care interzic accesul si 2. decizia de a exclude.
Barierele tehnice pot fi împartite în doua categorii:
Este necesara scrierea sau inteligenta. Daca singura modalitate de a accesa o pagina web este de a scrie ceva sau de a selecta o combinatie de optiuni, motoarele de cautare nu pot face acest lucru. Explicatia este ca robotii de cautare traverseaza web-ul pe baza legaturilor dintre pagini; în cazul în care nu exista nici o legatura catre o pagina, robotii nu o pot "vedea". De asemenea, robotii nu pot alege una sau mai multe optiuni înainte de a parcurge o pagina. Paginile generate dinamic pot sa nu fie de asemenea incluse în rezultate, deoarece aceste pagini nu sunt stocate, având continut unic, generat la fiecare cerere.
Necesitatea autentificarii. Toate site-urile care necesita autentificare sunt închise motoarelor de cautare, deoarece robotii ar avea nevoie de ceva necunoscut (username/parola, de exemplu). Exista milioane de astfel de site-uri care necesita autentificare, deoarece continutul acestora nu este gratuit sau au impus altfel de restrictii, de exemplu.
Excluderea intentionata a paginilor. Motoarele de cautare pot sa nu includa în index pagini deoarece formatul acestora sau al documentelor este accesat rar sau nu poate fi indexat în mod corespunzator. Nu exista nici un motiv tehnic pentru a le exclude ci doar o politica a companiei detinatoare a motorului de cautare. Motivul este urmatorul: bazele de date ale motoarelor de cautare si robotii de cautare sunt optimizate pentru a citi HTML. Alte tipuri de limbaje pot contine coduri sau necesitati de formatare incompatibile cu HTML. De asemenea, paginile care contin numai imagini sunt deseori omise, deoarece nu exista text care sa fie inclus în index.
Exista si exceptii de la regula de mai sus. Google.com, de exemplu, poate sa indexeze documentele PDF, DOC, PPT. De asemenea, Google, Altavista si alte motoare de cautare au directoare sau motoare de cautare specializate în indexarea /cautarea imaginilor.
Din cele de mai sus se poate deduce ca este dificil de prezis ce site-uri sau tipuri de site-uri sau parti din site-uri nu fac parte din web-ul invizibil, existând la mijloc câtiva factori:
Ce site-uri îsi replica o parte din continut în pagini statice (hibrid de web vizibil si invizibil);
Ce site-uri îsi replica tot continutul în pagini statice;
Ce site-uri nu îsi replica deloc continutul si trebuie interogate în mod direct (total invizibile);
Politicile motoarelor de cautare se pot schimba în ceea ce priveste includerea/excluderea din index.
|
