Structura proceselor
In capitolul 2 au fost formulate caracteristicile de nivel înalt ale proceselor. Acest capitol prezinta idei mai concrete, definind contextul procesului si aratând cum nucleul identifica si localizeaza un proces. Sectiunea 7.1 defineste modelul starilor procesului pentru sistemul UNIX si setul tranzitiilor de stare. Nucleul contine o tabela de procese care are câte o intrare care descrie starea fiecarui proces activ in sistem. Zona u area contine informatii suplimentare care controleaza functionarea procesului. Intrarea din tabela de procese si u area sunt parti ale contextului procesului. Aspectul contextului procesului care il diferentiaza vizibil de contextul altui proces este, desigur, spatiul sau de adrese. Sectiunea 7.2 descrie principiile de gestionare a memoriei pentru procese si pentru nucleu si modul de cooperare al sistemului de operare cu hardware-ul pentru a face translatarea adreselor de memorie virtuala. Sectiunea 7.3 examineaza componentele contextului unui proces, iar in finalul capitolului sunt descrisi algoritmii de nivel scazut care manipuleaza contextul unui proces. Sectiunea 7.4 arata cum nucleul salveaza contextul unui proces pe timpul unei intreruperi, unui apel sistem sau unei schimbari de context si cum ulterior reia executia procesului suspendat. Sectiunea 7.5 ofera diversi algoritmi, folositi de apelurile sistem descrise in capitolul urmator, care manipuleaza spatiul de adrese al unui proces. In sfârsit, sectiunea 7.6 prezinta algoritmii pentru punerea unui proces in asteptare si pentru trezirea acestuia.
7.1 Starile si tranzitiile proceselor
Asa cum s-a aratat in capitolul 2, timpul de viata al unui proces poate fi conceptual divizat intr-un set de stari care descriu procesul. Urmatoarea lista contine setul complet de stari ale procesului:
Procesul este in executie in modul utilizator.
Procesul este in executie in modul nucleu.
Procesul nu este in executie dar este gata pentru executie indata ce
nucleul il planifica.
Procesul este in asteptare si se gaseste in memoria principala.
Procesul este gata de executie, dar incarcatorul( procesul 0) trebuie
sa incarce procesul in memoria principala inainte ca nucleul sa-l
poata planifica pentru executie. Capitolul 12 va reanaliza aceasta
stare intr-un sistem cu paginare.
Procesul este in asteptare si incarcatorul a transferat procesul la un
dispozitiv de memorare secundar facând loc pentru alte procese in
memoria principala.
Procesul se întoarce din modul nucleu in modul utilizator, dar
nucleul il intrerupe si face o comutare de context pentru a planifica
alt proces. Diferenta intre aceasta stare si starea 3 ("gata de
executie") va fi descrisa ulterior.
Procesul este de curând creat si se afla intr-o stare de tranzitie;
procesul exista dar nu este gata de executie si nici in asteptare.
Aceasta este o stare de inceput pentru toate procesele, cu exceptia
procesului 0.
Procesul a executat apelul sistem exit si este in starea zombie.
Procesul nu va mai exista mult, dar el lasa o inregistrare ce
contine codul de iesire si câteva statistici de timp pentru a fi
folosite de procesul parinte. Starea zombie reprezinta o stare
finala a procesului.
Figura 7.1 contine diagrama completa a tranzitiilor de stare ale unui proces. Se considera un proces tipic care strabate complet modelul tranzitiilor de stare. Evenimentele descrise sunt artificiale intrucât proceselor nu li se intâmpla intotdeauna asa, dar ele ilustreaza diferitele tranzitii de stare. Procesul intra in starea "creare proces " când procesul parinte executa apelul sistem fork si trece eventual intr-o stare in care este gata de executie (3 sau 5). Pentru simplificare, presupunem ca procesul intra in starea "gata de executie in memorie". Planificatorul de procese va alege eventual procesul pentru executie si va intra in starea "executie in mod nucleu", unde partea sa de apel sistem fork este încheiata.
Când procesul termina de executat apelul sistem, el poate trece in starea "executie in mod utilizator". Dupa o perioada de timp, ceasul sistem poate întrerupe procesorul si procesul intra iar in starea "executie in mod nucleu". Când rutina de tratare a intreruperii de ceas termina de tratat intreruperea de ceas, nucleul poate decide sa planifice un alt proces pentru executie, astfel primul proces intra in starea "intrerupt" si celalalt se va executa. Starea "intrerupt" este intr-adevar aceeasi ca si starea "gata de executie in memorie" (linia punctata din figura ce uneste cele doua stari subliniaza echivalenta lor), dar ele sunt descrise separat pentru a accentua ca procesul care se executa in modul nucleu poate fi intrerupt numai când este pe punctul de a se intoarce la modul utilizator. Ulterior, nucleul poate schimba un proces din starea "întrerupt" daca este necesar.
In cele din urma, planificatorul va alege procesul pentru executie si acesta se va intoarce la starea "executie in modul utilizator". Când un proces executa un apel sistem, el paraseste starea "executie in modul utilizator" si intra in starea "executie in modul nucleu". Presupunem ca apelul sistem necesita o operatie de I/O de pe disc si procesul trebuie sa astepte pentru ca aceasta sa se termine. El intra in starea "asteptare in memorie", punându-se singur in asteptare pâna când este anuntat ca operatia I O s-a terminat. Ulterior când operatia I/O se termina, hardware-ul întrerupe UCP si rutina de tratare a întreruperii trezeste procesul, determinând trecerea lui in starea "gata de executie in memorie".
Presupunem ca sistemul executa mai multe procese care nu au loc simultan in memoria principala si programul incarcator evacueaza procesul pentru a face loc altui proces care este in starea "gata de executie pe disc". Când este evacuat din memoria principala procesul intra in starea "gata de executie pe disc". In cele din urma incarcatorul alege procesul care este cel mai potrivit sa se încarce in memoria principala si acesta reintra in starea "gata de executie in memorie". Planificatorul va alege eventual procesul pentru executie si acesta va intra in starea "executie in modul nucleu" si isi va continua executia. Când un proces se termina, el invoca apelul sistem exit, astfel trece in starea "executie in modul nucleu" si in final in starea "zombie".
Procesul are controlul asupra câtorva tranzitii de stare la nivelul utilizator. In primul rând, procesul poate crea alte procese. Totusi, starea din care intra procesul din starea "creare proces" ( "gata de executie in memorie" sau "gata de executie pe disc") depinde de nucleu: procesul nu are controlul asupra acestor tranzitii de stare. In al doilea rând, un proces poate face apeluri sistem pentru trecerea din starea "executie in modul utilizator" in starea "executie in modul nucleu" si intra in nucleu la dorinta sa. Totusi, procesul nu are controlul asupra momentului când va reveni in nucleu; evenimentele pot dicta ca acesta sa nu se mai întoarca niciodata dar procesul poate intra in starea "zombie" (vezi sectiunea 8.2 la semnale). In sfârsit procesul se poate termina la cererea sa, dar cum s-a precizat înainte, evenimentele externe pot dicta terminarea unui proces fara invocarea explicita a apelului sistem exit. Toate celelalte tranzitii de stare urmaresc un model rigid codificat in nucleu, reactionând la evenimente in mod previzibil conform regulilor formulate
in acest capitol si urmatoarele.
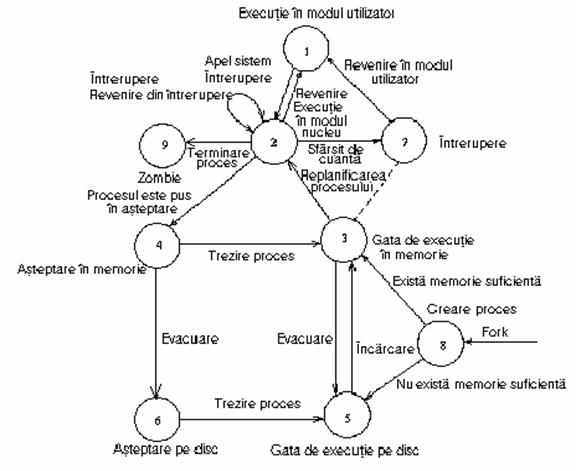
Figura 7.1 Diagrama tranzitiei de stare a procesului
Doua structuri de date ale nucleului descriu starea unui proces: intrarea in tabela de procese si u area. Tabela de procese contine câmpuri care trebuie sa fie întotdeauna accesibile nucleului, dar u area contine câmpuri care trebuie sa fie accesibile numai la executia procesului. Deci nucleul aloca spatiu pentru u area numai când creeaza un proces: el nu are nevoie de structuri u area pentru intrarile din tabela de procese care nu sunt asignate unor procese.
Câmpurile din tabela de procese sunt urmatoarele:
Câmpul de stare care identifica starea procesului.
Intrarea in tabela de procese contine câmpuri care permit nucleului sa localizeze procesul si zona sa u area in memoria principala sau pe un dispozitiv extern. Nucleul foloseste informatia pentru a face o comutare de context, când acesta trece din starea gata de executie in memorie in starea executie in modul nucleu sau din starea întrerupt in starea executie in modul utilizator. In plus, el foloseste informatia când incarca (pagineaza) procese in si din memoria principala (intre cele doua stari "in memorie" si cele doua stari "pe disc ". Intrarea in tabela de procese contine deasemenea un câmp care da marimea procesului, astfel incât nucleul stie cât spatiu trebuie sa aloce procesului.
Mai multi identificatori ai utilizatorului (utilizator ID sau UID) determina diferite drepturi pentru proces. De exemplu, câmpurile utilizator ID descriu seturile de procese care pot transmite semnale altor procese asa cum va fi explicat in capitolul urmator.
Identificatorii procesului (proces ID sau PID) specifica relatia dintre procese. Aceste câmpuri ID sunt setate când procesul intra in starea creare proces in urma apelului sistem fork.
Intrarea in tabela de procese contine un descriptor de evenimente când procesul este in starea "asteptare ". Acest capitol ii va examina folosirea in algoritmii pentru sleep si wake-up.
Parametri de planificare permit nucleului sa determine ordinea in care procesele trec in starile executie in modul nucleu si in starea executie in modul utilizator.
Câmpul semnal retine semnalele trimise unui proces dar care nu sunt inca tratate (sectiunea 8.2).
Diferite contoare de timp dau timpul de executie al procesului si utilizarea resurselor nucleului, timpi folositi pentru contabilizarea procesului si pentru calcularea prioritatii de planificare a procesului. Câmpul contor de timp setat de utilizator este folosit pentru a transmite un semnal de alarma unui proces (sectiunea 9.3).
U area contine urmatoarele câmpuri ce caracterizeaza starile procesului:
Un pointer spre tabela de procese identifica intrarea ce corespunde zonei u area.
Identificatorii de utilizator real si efectiv determina diferite privilegii permise procesului cum ar fi drepturile de acces la fisier (vezi sectiunea 8.6).
Câmpurile contor de timp inregistreaza timpul pe care procesul (si descendentii lui) il consuma in executie in modul utilizator si in modul nucleu.
O zona de reactie la semnale indica cum doreste procesul sa reactioneze la semnale.
Câmpul de control al terminalului indica terminalul de intrare asociat procesului, daca exista.
Un câmp de eroare inregistreaza erorile intâlnite in timpul apelului sistem.
Un câmp valoare de revenire contine rezultatul apelurilor sistem.
Parametrii I/O descriu cantitatea de date transferate, adresa zonei de date sursa (tinta) din spatiul utilizatorului, deplasamentul in fisier si altele.
Directorul curent si radacina curenta descriu sistemul de fisiere in care se afla procesul.
Tabela descriptorilor de fisiere utilizator înregistreaza fisierele pe care procesul le-a deschis.
Câmpurile de limitare restrictioneaza marimea procesului si dimensiunea unui fisier pe care îl poate scrie.
Câmpul permisiunilor de acces mascheaza permisiunile de acces stabilite pentru fisierele create de proces.
Aceasta sectiune a descris tranzitiile de stare ale proceselor la un nivel logic. Fiecare stare are caracteristici fizice gestionate de nucleu, in special spatiul de adrese virtuale al procesului.
7.2 Organizarea memoriei sistemului
Se stie ca memoria fizica a masinii este adresabila începând de la octetul cu deplasamentul 0 si mergând pâna la un deplasament egal cu cantitatea de memorie a masinii. Asa cum s-a aratat in capitolul 2, procesele in sistemul UNIX sunt formate din trei sectiuni logice: text, date si stiva (memoria partajata va fi considerata ca parte a sectiunii de date, in scopul simplificarii acestei discutii). Sectiunea de text contine un set de instructiuni executate de masina; adresele din sectiunea de text includ adresele codului in cazul instructiunilor de ramificare sau apel de subrutine), adresele de date (pentru accesul la variabilele de date globale) sau adresele de stiva (pentru accesul la structurile de date locale ale subrutinelor). Daca masina ar trata adresele generate ca locatii in memoria fizica ar fi imposibil ca doua procese sa se execute concomitent, daca setul lor de adrese s-ar suprapune. Compilatorul poate genera adrese care sa nu se suprapuna intre programe, dar aceasta procedura nu este practica pentru calculatoarele de uz general deoarece cantitatea de memorie a masinii este finita si setul tuturor programelor ce pot fi compilate este infinit. Chiar daca compilatorul încearca euristic sa evite suprapunerea adreselor generate, implementarea nu va fi flexibila.
De aceea compilatorul genereaza adrese pentru un spatiu virtual de adrese cu un domeniu de adrese, iar unitatea de gestiune a memoriei masinii translateaza adresele virtuale generate de compilator in adrese de locatii in memoria fizica. Compilatorul nu trebuie sa stie unde va încarca mai târziu nucleul in memorie programul pentru executie. De fapt, câteva copii ale programului pot exista concomitent in memorie.
Toate se vor executa folosind aceleasi adrese virtuale, dar vor referi diferite adrese fizice. Subsistemele nucleului si hardware-ul ce coopereaza la translatarea adresei virtuale in adresa fizica formeaza sistemul de gestiune a memoriei.
7.2.1 Regiunile
La System V nucleul împarte spatiul virtual de adrese al procesului in regiuni logice. O regiune este o zona contigua a spatiului virtual de adrese al procesului care poate fi tratata ca un obiect distinct si poate fi partajata sau protejata. Astfel textul, datele si stiva, de obicei formeaza regiuni separate ale procesului. Mai multe procese pot folosi in comun aceeasi regiune. De exemplu, mai multe procese pot executa acelasi program si este normal ca ele sa partajeze o copie a regiunii de text. La fel, câteva procese pot coopera la folosirea in comun a regiunii de memorie partajata. Nucleul contine o tabela a regiunilor si aloca câte o intrare din tabela pentru fiecare regiune activa in sistem. Sectiunea 7.5 va descrie amanuntit câmpurile tabelei de regiuni si operatiile cu regiuni, dar pentru inceput consideram ca tabela de regiuni contine informatii pentru a determina unde este localizat continutul ei in memoria fizica. Fiecare proces contine o tabela privata de regiuni per proces (per process region table), numita pe scurt pregion. Intrarile acesteia pot exista in tabela de procese, u area sau intr-o zona de memorie alocata separat depinzând de implementare, dar, pentru simplificare, consideram ca ele sunt o parte tabelei de procese. Fiecare intrare a tabelei private de regiuni pointeaza catre o intrare a tabelei globale de regiuni si contine adresa virtuala de start a regiunii in proces. Regiunile partajate pot avea adrese virtuale diferite in fiecare proces. Intrarea tabelei private de regiuni mai contine câmpul permisiunilor ce indica tipul de acces permis procesului: numai citire, citire-scriere sau citire-executie. Tabela privata de regiuni si structura regiunii sunt analoage cu tabela fisierelor si structura inodului din sistemul de fisiere. Mai multe procese pot accesa in comun parti ale spatiului lor de adrese printr-o regiune la fel cum pot accesa un fisier printr-un inod; fiecare proces acceseaza regiunea printr-o intrare proprie in tabela privata de regiuni la fel cum acceseaza inodul printr-o intrare proprie in tabela descriptorilor de fisiere a utilizatorului si in tabela de fisiere din nucleu.
Figura 7.2 prezinta doua procese A si B, indicând regiunile, tabelele private de regiuni si adresele virtuale unde sunt legate. Procesele impart regiunea de text "a" la adrese virtuale de 8K respectiv 4K.
Daca procesul A citeste locatia de memorie de la adresa 8K si procesul B citeste locatia de memorie de la adresa 4K, ele citesc aceeasi locatie de memorie in regiunea "a". Regiunile de date si de stiva ale celor doua procese sunt private.
Conceptul de regiune este independent de politicile de gestiune a memoriei implementate de sistemul de operare. Politica de gestiune a memoriei se refera la actiunile nucleului ce asigura impartirea corecta a memoriei principale de catre procese. De exemplu, doua politici de gestiune a memoriei considerate in capitolele 10 si 11 sunt: swapping-ul si paginarea la cerere. Conceptul de regiune este deasemenea independent de implementarea gestiunii memoriei:daca memoria este impartita in pagini sau segmente. Pentru fundamentarea descrierii algoritmilor de paginare la cerere din capitolul 12, discutia de aici considera arhitectura memoriei bazata pe pagini, dar nu si ca politica de gestiune a memoriei este bazata pe algoritmii de paginare la cerere.
Figura 7.2 Procese si regiuni
7.2.2 Pagini si tabele de pagini
Aceasta sectiune defineste modelul memoriei care va fi folosit in lucrare, dar el nu este specific sistemului UNIX. In arhitectura de gestiune a memoriei bazata pe pagini, hardware-ul de gestiune a memoriei imparte memoria fizica intr-un set de blocuri de dimensiuni egale numite pagini. Marimea fizica a paginilor este cuprinsa intre 512 octeti si 4Ko si este definita de hardware. Fiecare locatie adresabila din memorie este continuta intr-o pagina si, in consecinta, fiecare locatie de memorie poate fi adresata de perechea:
(numarul paginii, deplasaent in pagina).
De exemplu, daca masina are 232 octeti de memorie fizica si dimensiunea paginii de 1Ko, masina poate avea 222 pagini de memorie fizica; fiecare 32 de biti de adresa pot fi tratati ca o pereche formatã din 22 de biti ai numarului de pagina si 10 biti ai deplasamentului in pagina (Figura 7.3).
Când nucleul atribuie paginile fizice de memorie unei regiuni, nu trebuie sa atribuie pagini contigue sau intr-o anumita ordine. Scopul paginarii memoriei este de a asigura o mai buna flexibilitate in atribuirea memoriei fizice, analog cu atribuirea blocurilor disc ale fisierelor intr-un sistem de fisiere. Asa cum nucleul atribuie blocurile unui fisier pentru a creste flexibilitatea si pentru a reduce cantitatea de spatiu nefolosit datorita fragmentarii blocurilor, la fel el atribuie paginile de memorie unei regiuni.

Figura 7.3 Memoria fizica adresata ca pagini
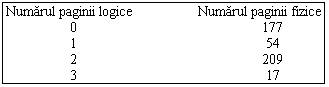
Figura 7.4 Harta de corespondenta intre numerele logice de pagina
si cele fizice
Nucleul coreleaza adresele virtuale ale regiunii cu adresele fizice ale masinii cu ajutorul unei tabele ce cuprinde numerele de pagini logice din regiune si numerele de pagini fizice corespunzatoare ca in figura 7.4. Deoarece o regiune este o zona contigua de adrese virtuale in program, numarul de pagina logica este un index intr-o matrice cu numere de pagini fizice. Intrarea in tabela de regiuni contine un pointer spre tabela numerelor de pagini fizice numita tabela de pagini. Intrarea in tabela de pagini poate deci contine informatii ce depind de masina cum ar fi bitii permisiunilor care permit citirea sau scrierea unei pagini. Nucleul pastreaza tabelele de pagini in memorie si le acceseaza ca pe toate celelalte structuri de date ale nucleului.
Figura 7.5 prezinta un exemplu de mapare a unui proces in memoria fizica. Sa presupunem ca marimea unei pagini este de 1Ko, si ca procesul vrea sa acceseze adresa de memorie virtuala 68,432.
Intrarea din tabela privata de regiuni arata ca adresa virtuala este la inceputul regiunii de stiva la adresa virtuala 64K (65,536 in zecimal), considerând ca directia de crestere a stivei este de la adrese mici catre adrese mari. Prin scadere adresa 68,432 este la deplasamentul 2896 in regiune. Stiind ca fiecare pagina are 1Ko, adresa este continuta la deplasamentul 848 in pagina 2 (numarând de la 0) a regiuni, localizata la adresa fizica 986Ko. Sectiunea 7.5.5 (incarcarea regiunii) descrie semnificatia intrarii in tabela de pagini marcata ca fiind goala.
Masinile moderne folosesc diferiti registri hardware si fac operatii de tip cache pentru a mari viteza de translatie a adreselor , deoarece accesarea memoriei si calculul adreselor ar fi prea consumatoare de timp. Ori de câte ori reia executia procesului, nucleul informeaza hardware-ul de gestiune a memoriei unde rezida tabelele de pagini si memoria fizica a procesului prin incarcarea registrilor corespunzatori.

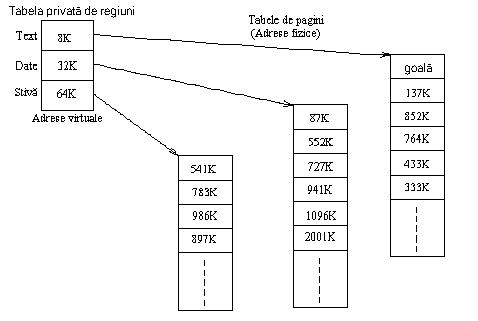
Figura 7.5 Translatarea adreselor virtuale in adrese fizice
Intrucât astfel de operatii sunt dependente de masina si variaza de la o implementare la alta, nu vor fi luate in discutie.In continuare folosim un model simplu de memorie pentru intelegerea gestiunii memoriei. Memoria este organizata in pagini de 1Ko, accesate prin tabelele de pagina asa cum au fost descrise mai inainte.
Sistemul contine un set de registri tripli de gestiune a memoriei, astfel incât primul registru din triplet contine adresa tabelei de pagina in memoria fizica, al doilea registru contine prima adresa virtuala mapata prin triplet, iar al treilea registru contine informatii de control cum ar fi numarul de pagini din tabela de pagini si permisiunile de acces ale paginii (numai citire, citire-scriere). Acest model corespunde modelului de regiune, descris mai sus. Când nucleul pregateste un proces pentru executie, el incarca setul de registri tripli de gestiune a memoriei care corespund datelor memorate in intrarile tabelei private de regiuni.
Daca un proces adreseaza locatii de memorie din afara spatiului sau virtual de adrese, hardware-ul produce o exceptie. De exemplu, daca marimea regiunii text din figura 7.5 este de 16Ko si procesul acceseaza adresa virtuala de 26K, hardware-ul va produce o exceptie pe care o trateaza sistemul de operare. In mod similar, daca un proces incearca sa acceseze memoria fara permisiuni corespunzatoare, cum ar fi scrierea la o adresa in regiunea sa de text protejata la scriere, hardware-ul va produce o exceptie. In ambele exemple, procesul s-ar termina normal; capitolul urmator va furniza mai multe detalii.
7.2.3 Organizarea nucleului
Desi nucleul se executa in contextul unui proces, translatarea memoriei virtuale asociata nucleului este independenta de toate procesele. Codul si datele pentru nucleu rezida permanent in sistem, si toate procesele îl partajeaza. Când sistemul este pus la lucru (la încarcare), el încarca codul nucleului in memorie si seteaza tabelele necesare si registrii pentru maparea adreselor lui virtuale in adrese fizice de memorie. Tabelele de pagini ale nucleului sunt analoage cu tabelele de pagini asociate fiecarui proces, iar mecanismele folosite la maparea adreselor virtuale ale nucleului sunt similare cu cele folosite pentru adresele utilizator. La multe masini, spatiul virtual de adrese al procesului este impartit in câteva clase, cum ar fi sistem si utilizator, iar fiecare clasa are o tabela proprie de pagini. Când executia este in modul nucleu, sistemul permite accesul la adresele nucleului, dar interzice un astfel de acces când executia este in modul utilizator. Astfel, când se trece din modul utilizator in modul nucleu ca rezultat a unei întreruperi sau al unui apel sistem, sistemul de operare coopereaza cu hardware-ul pentru a permite nucleului referirea adresei, iar când se revine in modul utilizator, sistemul de operare si hardware-ul interzic aceste referiri. Alte masini schimba translatarea adresei virtuale prin încarcarea registrilor speciali când se executa in modul nucleu.
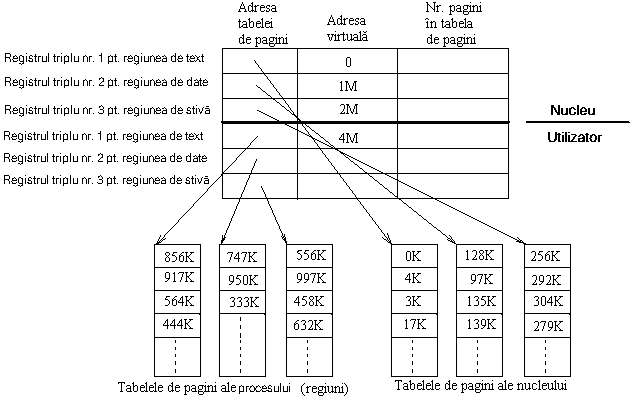
Figura 7.6 Trecerea din modul utilizator in modul nucleu
Figura 7.6 prezinta un exemplu de adrese virtuale ale nucleului si ale unui proces, unde gama adreselor virtuale ale nucleului este de la 0 la 4M 1 si gama adreselor virtuale ale utilizatorului de la 4M in sus. Exista doua seturi de tripleti de gestiune a memoriei, unul pentru adresele nucleului si altul pentru adresele utilizatorului, si fiecare triplet pointeaza spre o tabela de pagini ce contine numerele de pagini fizice corespunzatoare adreselor de pagini virtuale. Sistemul permite referirea de adrese prin intermediul registrilor tripli ai nucleului numai in modul nucleu; deci, comutarea intre modul nucleu si modul utilizator necesita numai ca sistemul sa permita sau nu referirea adresei prin intermediul registrilor tripli ai nucleului.
Unele sisteme încarca nucleul in memorie astfel încât multe adrese virtuale ale nucleului sunt identice cu adresele fizice si maparea memoriei virtuale in memorie fizica a acestor adrese este functia identica. Totusi, tratarea zonei u area necesita maparea adresei virtuale in adresa fizica in nucleu.
7.2.4 U area
Fiecare proces are o zona u area proprie, totusi nucleul o acceseaza ca si cum numai o singura zona u area ar fi in sistem, aceea a procesului care ruleaza. Nucleul schimba harta de translatare a adreselor virtuale in functie de procesul care se executa pentru a accesa zona u area corespunzatoare. Când compileaza sistemul de operare, incarcatorul atribuie variabilei u, numele zonei u area, o adresa virtuala. Valoarea adresei virtuale a zonei u area este cunoscuta si de alte parti ale nucleului, in particular, de modulul care face schimbarea de context (sectiunea 7.4.3). Nucleul cunoaste unde in tabelele de gestiune a memoriei este facuta translaterea adresei virtuale pentru zona u area, si el poate schimba dinamic adresa mapata a zonei u area cu alta adresa fizica. Doua adrese fizice reprezinta zonele u area a doua procese, dar nucleul le acceseaza prin aceeasi adresa virtuala.

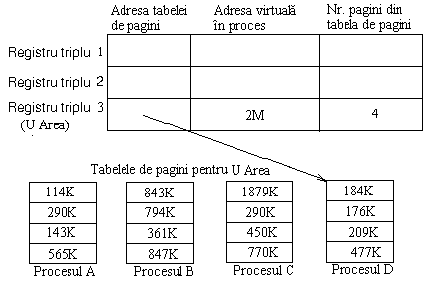
Figura 7.7 Harta de memorie a zonei u area din nucleu
Procesul poate accesa zona sa u area sa când se executa in modul nucleu dar nu atunci când se executa in modul utilizator. Pentru ca nucleul poate accesa doar o zona u area la un moment dat de timp prin adresa sa virtuala, u area defineste partial contextul procesului ce ruleaza in sistem. Când nucleul planifica un proces pentru executie, el gaseste zona u area corespunzatoare in memorie si o face accesibila prin intermediul adresei sale virtuale.
De exemplu, sa presupunem ca zona u area are 4K si se afla in nucleu la adresa virtuala 2M. Figura 7.7 prezinta un exemplu de organizare a memoriei, unde primele doua triplete de registri refera zonele de text si de date ale nucleului (adresele si pointerii nu sunt aratate), si al treilea triplet refera zona u area pentru procesul D.
Daca nucleul doreste sa acceseze zona u area a procesului A, el copiaza informatia corespunzatoare din tabela de pagina pentru zona u area in al treilea registru triplu. In orice moment, al treilea registru triplu al nucleului refera zona u area a procesului care ruleaza in mod curent, dar nucleul poate referi zona u area a altui proces suprascriind intrarile pentru adresa zona u area din tabela de pagini cu noua adresa. Intrarile registrilor tripli 1 si 2 nu pot fi schimbate, deoarece toate procesele partajeaza zonele de text si de date ale nucleului.
7.3 Contextul procesului
Contextul procesului reprezinta continutul spatiului sau de adrese (al utilizatorului), continutul registrilor hardware si structurile de date ale nucleului care au legatura cu procesul. Formal, contextul procesului este format din contextul de nivel utilizator (user-level context), contextul registru (register context), si contextul de nivel sistem (system-level context). Contextul de nivel utilizator cuprinde zonele de text, date, stiva utilizator si memorie partajata care ocupa spatiul virtual de adrese al procesului. Parti ale spatiului virtual de adrese al procesului care nu rezida permanent in memoria principala datorita politicii de swapping sau paginare constituie inca o parte a contextului de nivel utilizator.
Contextul registru cuprinde urmatoarele componente.
Numaratorul de program specifica adresa instructiunii urmatoare pe care o va executa UCP; aceasta este o adresa virtuala in nucleu sau in spatiul de memorie al utilizatorului.
Registrul de stare al procesorului (PS) specifica starea hardware a masinii pe care ruleaza procesul. De exemplu, registrul de stare contine subcâmpurile care indica rezultatul ultimelor calcule care pot fi zero, pozitive sau negative, sau daca s-a produs o depasire si bitul de transport este setat, si altele. Alte subcâmpuri importante care se gasesc de obicei in registrul de stare sunt cele care indica nivelul de executie curenta a precesului (pentru intreruperi) si modul de executie curent precum si cel mai recent (cum ar fi nucleu sau utilizator). Subcâmpurile care dau modul de executie curent determina daca procesul poate executa instructiuni privilegiate si daca poate accesa spatiul de adrese al nucleului.
Pointerul stivei contine adresa curenta a urmatoarei intrari in stiva nucleu sau in stiva utilizator, determinata de modul de executie. Arthitectura masinii dicteaza daca pointerul stivei pointeaza catre urmatoarea intrare libera din stiva sau catre ultima intrare folosita.
In mod similar, masina dicteaza directia de crestere a stivei spre adresele numerice mai mari sau mai mici, dar aceste probleme nu fac obiectul acestei discutii.
Registrii generali contin date generate de proces in timpul executiei. Pentru a simplifica in continuare discutia, sa diferentiem doi registri generali, registrul 0 si 1, folositi aditional pentru transmiterea informatiilor intre proces si nucleu.
Contextul de nivel sistem al procesului are o "parte statica" (primele trei articole ale listei urmatoare) si o "parte dinamica" (ultimele doua componente). Procesul are o parte statica a contextului de nivel sistem pe toata durata existentei sale, dar poate avea un numar variabil de parti dinamice. Partea dinamica a contextului de nivel sistem trebuie sa fie vazuta ca o stiva de cadre context pe care nucleul le introduce si le extrage la aparitia diferitelor evenimente. Contextul de nivel sistem contine urmatoarele componente.
Intrarea procesului in tabela de procese defineste starea procesului descrisa in sectiunea 7.1, si contine informatii de control care sunt permanent accesibile nucleului.
Zona u area a procesorului contine informatii de control care trebuie sa fie accesate numai in contextul procesului. Parametri de control generali cum ar fi prioritatea procesului sunt stocati in tabela de procese pentru ca ei trebuie sa fie accesati in afara contextului procesului.
Intrarile tabelei private de regiuni, tabelele de regiuni si tabelele de pagini, definesc maparea adreselor virtuale in adrese fizice si deci definesc regiunile de text, date si stiva precum si alte regiuni ale procesului. Daca unele procese partajeaza regiuni comune, regiunile sunt considerate parti ale contextului fiecarui proces, pentru ca fiecare proces manipuleaza regiunile independent. O parte a procesului de gestiune a memoriei indica acele zone ale spatiului de adrese virtuale al procesului care nu sunt rezidente in memorie.
Stiva nucleului contine cadrele de stiva ale procedurilor nucleului când un proces se executa in modul nucleu. Desi procesele executa un cod nucleu identic, ele au copii proprii ale stivei nucleului ce specifica apelurile proprii ale functiilor nucleului. De exemplu, un proces poate invoca apelul sistem creat si apoi trece in asteptare pâna când nucleul ii asigneaza un nou inod, iar alt proces poate invoca apelul sistem read si trece in asteptare pâna când se va face transferul de date de pe disc in memorie. Ambele procese executa functii nucleu, dar ele au stive separate ce contin propriile secvente de apeluri de functii. Nucleul trebuie sa fie capabil sa refaca continutul stivei nucleu pentru reluarea executiei procesului in modul nucleu.
Implementarile de sistem plaseaza de obicei stiva nucleului in zona u area a procesului, dar aceasta este logic independenta si poate exista in zone de memorie alocate independent. Stiva nucleu este goala când procesul se executa in modul utilizator.
Partea dinamica a contextului de nivel sistem a procesului contine un set de cadre, vizualizate ca o stiva LIFO (last-in-first-out). Fiecare cadru al contextului de nivel sistem contine informatiile necesare pentru refacerea cadrului precedent, incluzând contextul registru al nivelului precedent.
Nucleul introduce un cadru context in stiva când apare o întrerupere, când procesul executa un apel sistem, sau când procesul face o schimbare de context. Nucleul scoate un cadru context din stiva când revine din tratarea unei întreruperi, când procesul revine la modul utilizator dupa ce nucleul a executat complet un apel sistem, sau când procesul face o schimbare de context. Astfel schimbarea de context determina introducerea si scoaterea unui cadru context de nivel sistem: nucleul introduce un cadrul context al vechiului proces si scoate cadrul context al noului proces. Intrarea in tabela de procese memoreaza informatiile necesare pentru refacerea cadrului context curent.
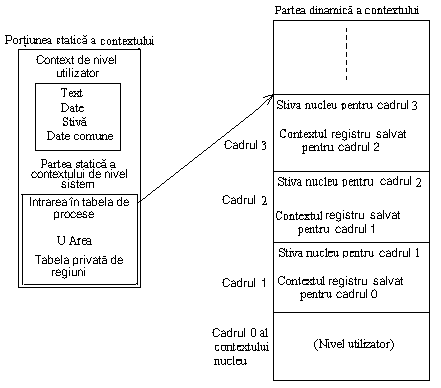
Figura 7.8 Componentele contextului unui proces
Figura 7.8 descrie componentele ce alcatuiesc contextul unui proces. In partea stânga a figurii este prezentata partea statica a procesului.
Aceasta contine contextul de nivel utilizator, care contine zona de text a procesului (instructiunile), zona de date, zona de stiva si zona de memorie partajata (daca exista), si partea statica a contextului de nivel sistem, care contine intrarea in tabela proceselor, zona u area, si intrarile tabelei private de regiuni(informatii de mapare a adreselor virtuale ale contextului de nivel utilizator).
Partea dreapta a figurii prezinta partea dinamica a contextului. Aceasta contine câteva cadre de stiva, iar in fiecare cadru este salvat contextul registru al cadrului anterior si stiva nucleu a aceluiasi cadru. Cadrul 0 al contextului de nivel sistem este o copie a contextului de nivel utilizator; cresterea stivei se face aici in spatiul de adresa al utilizatorului, si stiva nucleu este nula. Sageata pointeaza de la partea statica a contextului de nivel sistem catre cadrul din vârful partii dinamice a contextului reprezentând informatii logice stocate in intrarea din tabela de procese pentru a da posibilitatea nucleului sa refaca cadrul context curent al procesului.
Un proces ruleaza in cadrul contextului sau curent. Numarul de cadre context este limitat de numarul de nivele de întrerupere suportat de masina. De exemplu, daca o masina suporta diferite nivele de întrerupere pentru întreruperile software, terminale, discuri, toate celelalte periferice, si ceas, ea suporta 5 nivele de întrerupere, si deci, procesul poate contine maxim 7 cadre context: câte unul pentru fiecare nivel de întrerupere, unul pentru apelurile sistem, si unul pentru nivelul utilizator.
Aceste 7 nivele sunt suficiente sa cuprinda toate cadrurile context chiar daca întreruperile apar in "cea mai rea" secventa posibila, pentru ca o întrerupere a nivelului dat este blocata (datorita faptului ca UCP o amâna) in timp ce nucleul satisface întreruperile acelui nivel sau ale unui nivel superior.
Desi nucleul se executa permanent in contextul unui proces, functia logica pe care o executa nu este in mod necesar legata de proces. De exemplu, daca un driver de disc întrerupe masina pentru ca returneaza date, el întrerupe rularea procesului iar nucleul executa rutina de tratare a întreruperii intr-un nou cadru context de nivel sistem al procesului aflat in executie, chiar daca datele apartin unui alt proces. Rutinele de tratare întreruperilor in general nu acceseaza sau modifica partile statice ale contextului procesului, atât timp cât aceste parti nu au legatura cu întreruperea.
7.4 Salvarea contextului unui proces
Asa cum am observat in sectiunea precedenta nucleul salveaza contextul unui proces ori de câte ori el introduce in stiva un nou cadru context de nivel sistem. In particular, aceasta se întâmpla când sistemul receptioneaza o întrerupere, când executa un apel sistem, sau când nucleul face o schimbare de context. Aceasta sectiune prezinta detaliile fiecarei situatii.
7.4.1 Întreruperi si exceptii
Sistemul raspunde de tratarea întreruperilor, indiferent daca ele sunt întreruperi hardware (cum ar fi de la ceas sau de la dispozitivele periferice), întreruperi programabile (executia instructiunilor proiectate pentru a genera"intreruperi software"), sau exceptii (cum ar fi erori de pagina). Daca UCP lucreaza la un nivel de executie procesor mai scazut decât nivelul întreruperii, el accepta întreruperea înaintea decodificarii instructiunii urmatoare si ridica nivelul de executie al procesorului, astfel încât nici o alta întrerupere a acelui nivel (sau mai scazut) nu se poate produce cât timp trateaza întreruperea curenta pastrând integritatea structurilor de date ale nucleului (vezi sectiunea 2.2.2). Nucleul trateaza întreruperea cu urmatoarea secventa de operatii
1. Salveaza contextul registru curent al procesului in executie si creeaza (introduce in stiva) un nou cadru context.
2. Determina "sursa" sau cauza intreruperii, identifica tipul intreruperii (de ceas sau de disc) si numarul unitatii care a produs intreruperea, daca este cazul(cum ar fi driverul de disc). Când sistemul receptioneaza o intrerupere, aceasta primeste un numar de la masina pe care il foloseste ca deplasament intr-o tabela, numita de obicei vector de intrerupere. Continutul vectorului de intrerupere variaza de la o masina la alta, dar de obicei contine adresa rutinei de tratare a intreruperii corespunzatoare sursei de intrerupere si calea de gasire a parametrilor pentru rutina. De exemplu, luam in considerare tabela rutinelor de tratare a intreruperilor din figura 7.9. Daca un terminal intrerupe sistemul, nucleul primeste intreruperea numarul 2 de la hardware si invoca rutina de tratare a intreruperii de terminal .

Figura 7.9 Exemplu de vector de intrerupere
3. Nucleul invoca rutina de tratare a intreruperii. Stiva nucleu pentru noul cadru context este din punct de vedere logic distincta de stiva nucleu pentru cadrul context anterior. Unele implementari folosesc stiva nucleu a procesului aflat in executie pentru stocarea cadrelor de stiva ale rutinelor de tratare a intreruperilor, si alte implementari folosesc o stiva de intreruperi globala pentru stocarea acestor cadre ceea ce garanteaza reluarea executiei procesului curent fara schimbare de context.
4. Dupa terminarea executiei rutinei de tratare a intreruperii se reia executia proceslui curent. Nucleul executa o secventa de instructiuni specifice masinii si reface context registrul si stiva nucleu a cadrului context anterior asa cum erau in momentul aparitiei intreruperii si apoi reia executia cadrului restaurat. Comportamentul procesului poate fi afectat de rutina de tratare a intreruperii, pentru ca aceasta poate altera structurile globale de date ale nucleului si trezirea proceselor aflate in stare de asteptare. De obicei, totusi, procesul isi continua executia ca si cum intreruperea nu ar fi aparut niciodata.
algoritmul inthand /* tratarea întreruperilor */
intrare: niciuna
iesire niciuna
Figura 7.10 Algoritmul pentru tratarea întreruperilor
Figura 7.10 prezinta modul in care nucleul trateaza o întrerupere. Unele masini executa o parte a secventei de operatii prin intermediul hardware-ului sau a unor microinstructiuni pentru a obtine performante mai bune decât daca toate operatiile s-ar executa prin intermediul instructiunilor software.

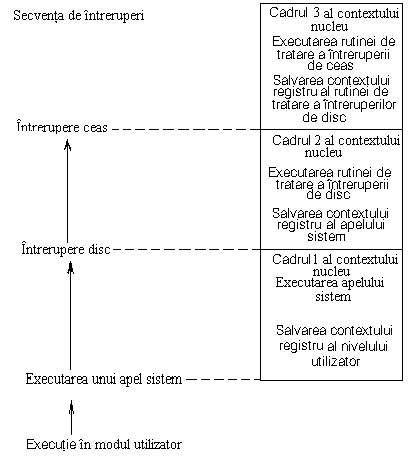
Figura 7.11 Exemple de intreruperi
Figura 7.11 prezinta un exemplu in care un proces face un apel sistem si receptioneaza o intrerupere de disc in timpul executiei apelului sistem. In timpul executiei rutinei de tratare a intreruperii de disc, sistemul receptioneaza o intrerupere de ceas si executa rutina de tratare a intreruperii de ceas. In momentul când sistemul receptioneaza o intrerupere (sau face un apel sistem), el creaza un nou cadru context si salveaza contextul registru al cadrului anterior.
7.4.2 Interfata de apel sistem
Interfata de apel sistem a nucleului a fost descrisa in capitolul precedent ca un apel normal de functie. Evident, ca secventa de apelare uzuala nu poate schimba modul de executie al procesului de la modul utilizator la modul nucleu. Compilatorul C foloseste o biblioteca de functii predefinite (biblioteca C) care contine denumirile apelurilor sistem, astfel rezolvând referirile apelului sistem in programul utilizator de biblioteca.
Functiile de biblioteca invoca o instructiune care schimba modul de executie al procesului in modul nucleu si determina nucleul sa inceapa executia codului pentru apelurile sistem.Aceasta instructiune este numita "trap "si este vazuta ca o exceptie. Rutinele de biblioteca sunt executate in modul utilizator, dar interfata de apel sistem este un caz special de rutina de tratare a intreruperii. Functiile de biblioteca transmit nucleului un numar unic pentru fiecare apelul sistem intr-un mod dependent de masina - ca parametru pentru instructiunea trap, intr-un registru particular, sau prin stiva - si astfel nucleul determina apelul sistem invocat de utilizator.
algoritmul syscall /* algoritmul pentru invocarea unui apel sistem */
intrare: numarul apelului sistem
iesire rezultatul apelului sistem
else
încarca registri 0 si 1 cu valorile de revenire din apelul sistem;
Figura 7.12 Algoritmul pentru apelul sistem
La tratarea instructiunii trap, nucleul cauta numarul apelului sistem intr-un tabel pentru a gasi adresa corespunzatoare rutinei nucleu care este punctul de intrare pentru apelul sistem si pentru a gasi numarul parametrilor pe care îl necesita apelul sistem (Figura 7.12.).
Nucleul calculeaza adresa (utilizazator) a primului parametru al apelului sistem prin adaugarea (sau scaderea, depinzând de directia de crestere a stivei) unui deplasament la pointerul stivei utilizator, corespunzator numarului de parametrii ai apelului sistem. In final el copiaza parametrii utilizator in zona u area, si apeleaza rutina sistem corespunzatoare.
Dupa executia codului apelului sistem, nucleul verifica daca a existat vreo eroare. Daca da, el încarca numarul de eroare in registrul 0 si seteaza bitul transport din registrul de stare al procesului. Daca nu apar erori la executia apelului sistem, nucleul sterge bitul transport din registrul de stare al procesului si copiaza valorile de revenire din apelul sistem in locatiile registrilor 0 si 1. Când nucleul revine in modul utilizator dupa executia unei instructiuni trap, el se întoarce la instructiunile de biblioteca de dupa aceasta. Biblioteca interpreteaza valorile de revenire din apelul sistem si întoarce o valoare catre programul utilizator.
De exemplu, sa consideram programul din prima parte a figurii 7.13 care creeaza un fisier cu permisiuni de citire si scriere pentru toti utilizatorii (0666). In partea a doua a figurii este prezentat codul masina pentru programul de mai sus compilat si dezasamblat pe un sistem Motorola 68000. Compilatorul genereaza cod pentru a introduce cei doi parametrii in stiva utilizator, unde primul parametru introdus este dat de permisiunile de acces, iar al doilea parametru este variabila nume. Apoi procesul apeleaza functia de biblioteca pentru apelul sistem creat (adresa 7a) de la adresa 64. Adresa de revenire din apelul sistem este 6a, iar procesul introduce acest numar in stiva. Functia de biblioteca pentru apelul creat muta constanta 8 in registrul 0 si executa o instructiune trap care determina ca procesul sa fie schimbat din modul utilizator in modul nucleu si sa trateze apelul sistem. Nucleul recunoaste ca utilizatorul executa un apel sistem si recupereaza numarul 8 din registrul 0, pentru a determina ca apelul sistem este apelul creat si ca acesta are nevoie de doi parametri. Ulterior copiaza parametrii din spatiul utilizator in u area. Rutinele nucleului care are nevoie de parametri, ii pot gasi in locatii predictabile in u area. Când nucleul termina executarea codului pentru apelul sistem creat, el se întoarce la rutina de tratare a apelului sistem, verifica daca câmpul eroare din zona u area este setat (însemnând ca a fost o eroare oarecare in apelul sistem); daca da rutina de tratare seteaza bitul transport in registrul de stare al procesului, plaseaza codul de eroare in registrul 0 si se termina. Daca nu este nici o eroare, nucleul plaseaza codul de revenire al sistemului in registrii 0 si 1.
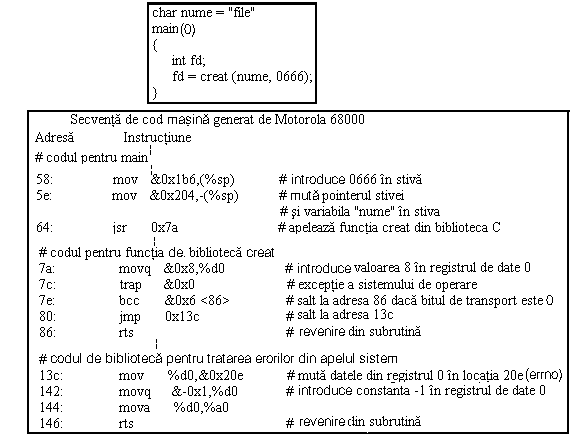
Figura 7.13. Apelul sistem creat si codul generat pentru
Motorola 68000.
Când revine din rutina de tratare a apelului sistem in modul utilizator, biblioteca C verifica bitul transport din registrul de stare al procesului, la adresa 7e. Daca este setat, procesul sare la adresa 13c, ia un cod de eroare din registrul 0 si îl plaseaza in variabila globala errno, la adresa 20e, pune valoarea -1 in registrul 0 si revine la urmatoarea instructiune de dupa apelul sistem la adresa 64. Codul de revenire al functiei este -1, si semnifica o eroare in apelul sistem. Daca atunci când revine din modul nucleu in modul utilizator bitul transport este 0, procesul sare de la adresa 7e la adresa 86 si se întoarce la apelant (adresa 64): registrul 0 contine o valoare de revenire din apelul sistem.
7.4.3 Schimbarea contextului
Referitor la diagrama de stari a unui proces din Figura 7.1. s-a aratat ca nucleul permite o schimbare a contextului doar in patru situatii: când un proces se pune singur in asteptare, când acesta se termina, când revine dintr-un apel sistem in modul utilizator dar nu este procesul cel mai potrivit pentru executie, sau când acesta revine in modul utilizator dupa ce nucleul termina tratarea unei întreruperi dar nu este cel mai potrivit proces pentru executie. Nucleul asigura integritatea si consistenta structurilor de date interne prin interzicerea schimbarilor de context arbitrare, asa cum s-a explicat in capitolul 2. Acesta se asigura ca starea structurilor sale de date este consistenta înainte de a realiza schimbarea contextului: daca toate actualizarile au fost facute, daca toate listele sunt inlantuite corect, daca anumite structuri de date sunt blocate pentru a împiedica accesarea lor de catre alte procese, daca nu exista structuri de date ramase blocate când nu este necesar, si altele. De exemplu, daca nucleul aloca un buffer, citeste un bloc dintr-un fisier si se pune in asteptare, pâna la terminarea operatiilor de I O cu discul, el tine buffer-ul blocat, astfel încât alte procese sa nu-l poata accesa. Dar daca un proces executa apelul sistem link, nucleul elibereaza primul inod blocat înainte de a bloca cel de-al doilea inod pentru a preveni situatiile de concurenta.
Nucleul trebuie sa execute o schimbare a contextului la terminarea apelului sistem exit, deoarece nu mai are nimic de facut. In mod similar nucleul permite o schimbare de context când un proces se pune in asteptare deoarece poate trece o perioada considerabila de timp pâna când procesul va fi trezit, si alte procese pot fi executate intre timp. Nucleul permite o schimbare de context când un proces nu este cel mai potrivit pentru a fi rulat, pentru a permite planificarea proceselor adecvate: daca un proces termina un apel sistem sau revine dintr-o întrerupere si exista un alt proces cu prioritate mai mare care asteapta sa ruleze, ar fi incorect sa mentinem in asteptare procesul cu prioritate mai mare.
Procedura pentru schimbarea contextului este similara cu procedura de tratare a întreruperilor si a apelurilor sistem, exceptând faptul ca nucleul reface cadrul context al altui proces si nu cadrul context anterior al aceluiasi proces. Ratiunea schimbarii de context este neinteresanta. Similar, alegerea urmatorului proces care va fi planificat, este o decizie tactica ce nu afecteaza mecanismul schimbarii de context.
Decide daca trebuie sa faca o schimbare de context si daca
aceasta este permisa.
Salveaza contextul "vechiului" proces.
Gaseste "cel mai bun" proces pentru a-l planifica pentru
executie.
Reface contextul acestuia.
Figura 7.14. Pasii pentru o schimbare de context.
Codul de implementare a schimbarii de context in sistemele UNIX este de obicei cel mai dificil de inteles la sistemul de operare, deoarece se creeaza impresia ca din unele apeluri de functii nu se mai revine in anumite situatii, si ca nu sunt materializate nicaieri in altele. Aceasta deoarece nucleul in multe implementari, salveaza contextul intr-un punct al procesului curent, dar continua sa execute schimbarea de context si algoritmii de planificare in contextul vechiului proces. Când el mai târziu reface contextul procesului, reia executia in conformitate cu contextul salvat anterior. Pentru a diferenta cazul in care nucleul reface contextul noului proces de cazul in care el continua executia in vechiul context dupa ce l-a salvat, valorile de revenire a functiilor critice variaza, sau numaratorul de program poate fi setat artificial.
Figura 7.15. prezinta un scenariu care face o schimbare de context. Functia salvare-context salveaza informatii despre contextul procesului in executie si întoarce valoarea 1. Printre altele nucleul salveaza valoarea numaratorului de program curent si valoarea 0, pentru a fi folosite mai târziu ca valori de revenire din functie. Nucleul continua sa se execute in contextul vechiului proces (A), alegând un alt proces (B) pentru a executa si apelând functia reface context pentru a reface noul context (al lui B).
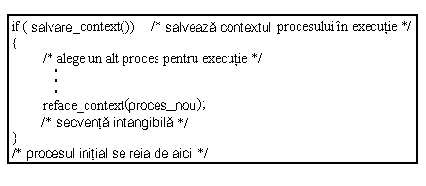
Figura 7.15. Pseudocod pentru schimbarea contextului.
Dupa ce noul context este refacut, sistemul executa procesul B; vechiul proces (A) nu se mai executa dar isi paraseste contextul salvat anterior. Mai târziu, nucleul va alege din nou procesul A pentru executie (exceptând cazul apelului exit) când un alt proces face o schimbare de context, asa cum a fost descris. Când contextul procesului A este restaurat, nucleul va seta numaratorul de program la valoarea salvata anterior pentru procesul A in functia salvare-context, si va pune deasemenea valoarea 0, salvata pentru valoarea de revenire din functie in registrul 0. Nucleul reia executia procesului A din interiorul functiei salvare-context chiar daca a executat codul de deasupra apelului "reface-context" apelat înaintea schimbarii de context.
La sfârsit, procesul A revine din functia salvare-context cu valoarea 0 (in registrul 0) si reia executia de la comentariul "procesul initial se reia de aici".
7.4.4 Salvarea contextului la întoarcerile fortate
Situatiile apar când nucleul trebuie sa iasa fortat din secventa curenta de executie si sa paraseasca imediat un context salvat anterior. Sectiunile urmatoare legate de asteptare si semnale descriu împrejurarile când un proces trebuie sa-si schimbe brusc contextul; aceasta sectiune explica mecanismul de executare a contextului anterior. Algoritmul de salvare a contextului se numeste setjmp si algoritmul de refacere a contextului este longjmp. Metoda este identica cu cea descrisa pentru functia salvare-context in sectiunea anterioara, cu exceptia faptului ca salvare-context adauga un nou cadru context, pe când setjmp memoreaza contextul salvat in u area si continua si execute vechiul strat context. Când nucleul doreste sa reia vechiul context salvat cu setjmp, el apeleaza longjmp, restaurând contextul din zona u area si returnând 1 pentru setjmp.
7.5 Manipularea spatiului de adrese al unui proces
In continuare acest capitol descrie cum schimba nucleul contextul intre procese si cum sunt depuse si scoase din stiva cadrele context, privind cadrul context de nivel utilizator ca un obiect static care nu poate fi schimbat pe timpul refacerii contextului procesului.
Totusi, diferite apeluri sistem manipuleaza spatiul de adrese virtuale al procesului, cum se va vedea in capitolul urmator, prin intermediul unor operatii bine definite asupra regiunilor. Aceasta sectiune descrie structura de date a regiunii si operatiile cu regiuni; urmatorul capitol se ocupa de apelurile sistem care folosesc operatiile cu regiuni.
Intrarea in tabela de regiuni contine informatiile necesare pentru a descrie o regiune. In detaliu ea contine urmatoarele câmpuri:
pointer catre inodul fisierului al carui continut a fost încarcat
initial in regiune,
tipul regiunii (text, memorie partajata, date private sau stiva),
marimea regiunii,
localizarea regiunii in memoria fizica,
starea regiunii care poate fi o combinatie de
blocata
in asteptarea rezolvarii cererii
in încarcare
valida, încarcata in memorie
contorul de referinta, da numarul de procese care refera
regiunea.
Operatiunile de manipulare a regiunilor sunt: blocare regiune, deblocarea unei regiuni, alocarea unei regiuni, atasarea unei regiuni la spatiul de memorie al unui proces, schimbarea dimensiunii unei regiuni, încarcarea unei regiuni dintr-un fisier in spatiul de memorie al unui proces, eliberarea unei regiuni, detasarea unei regiuni din spatiul de memorie al unui proces, duplicarea continutului unei regiuni. De exemplu, apelul sistem exec care suprascrie spatiul de adrese al utilizatorului cu continutul unui fisier executabil, detaseaza vechile regiuni, le elibereaza daca nu sunt partajate, aloca regiuni noi, le ataseaza si le încarca cu continutul fisierului.
In continuare sunt descrise in detaliu operatiunile cu regiuni, presupunând modelul de gestiune a memoriei descris mai devreme (tabele de pagini si seturile de registrii tripli) si existenta algoritmilor pentru alocarea tabelelor de pagini si a paginilor de memorie fizica (Capitolul 12).
7.5.1 Blocarea si deblocarea unei regiuni
Nucleul contine operatiile de blocare si deblocare a unei regiuni, independent de operatiile de alocare si eliberare a regiunii, asa cum sistemul de fisiere contine operatii de blocare-deblocare si alocare-eliberare pentru inoduri (algoritmii iget si iput). Astfel nucleul poate bloca si aloca o regiune si mai târziu o poate debloca fara sa o elibereze. Similar daca el vrea sa manipuleze o regiune alocata, o poate bloca pentru a preveni accesarea ei de catre alte procese si ulterior o deblocheaza.
7.5.2 Alocarea unei regiuni
Nucleul aloca o regiune noua (algoritmul allocreg, Figura 7.16) pe durata apelurilor sistem fork, exec si shmget (memorie partajata). Nucleul contine o tabela de regiuni ale carei intrari apar fie intr-o lista inlantuita de intrari libere fie intr-o lista inlantuita de intrari active. Atunci când aloca o intrare din tabela de regiuni nucleul elimina prima intrare disponibila din lista celor libere, o plaseaza in lista celor active, blocheaza regiunea si ii marcheaza tipul (partajata sau privata). Cu câteva exceptii fiecare proces este asociat cu un fisier executabil ca urmare a unui apel exec anterior, si functia allocreg stabileste ca valoarea câmpului inode din intrarea in tabela de regiuni sa pointeze catre inodul fisierului executabil. Inodul indica nucleului regiunea astfel incât alte procese o pot partaja daca este nevoie. Nucleul incrementeaza contorul de referinta a inodului pentru a evita ca alte procese sa elimine din memorie continutul inodului atunci când il elibereaza. Functia allocreg returneaza o regiune alocata si blocata.
algoritmul allocreg /* aloca o regiune */
intrare: (1) pointer catre inod
(2) tipul regiunii
iesire: regiune blocata
Figura 7.16. Algoritm pentru alocarea unei regiuni
7.5.3 Atasarea unei regiuni unui proces
Nucleul ataseaza o regiune in timpul apelurilor sistem fork, exec si shmat, pentru a o conecta la spatiul de adrese al unui proces (cu algoritmul attachreg, Figura 7.17.). Regiunea poate fi o regiune proaspat alocata sau o regiune existenta pe care procesul o va partaja cu alte procese. Nucleul aloca o intrare libera in tabela privata de regiuni ( pregion ), seteaza câmpul tip la text, date, memorie partajata sau activa si înregistreaza adresa virtuala la care va fi plasata regiunea in spatiul de adrese al procesului. Procesul nu trebuie sa depaseasca limitele impuse de sistem pentru cea mai mare adresa virtuala, iar adresele virtuale ale noii regiuni nu trebuie sa se suprapuna cu adresele unor regiuni existente. De exemplu, daca sistemul restrictioneaza cea mai mare adresa virtuala la 8 Mo, ar fi ilegal sa se ataseze o regiune cu dimensiunea de 1 Mo la adresa virtualã 7,5 Mo. Daca este legal sa se ataseze o regiune, nucleul incrementeaza câmpul dimensiune din intrarea in tabela de procese in functie de dimensiunea regiunii si incrementeaza contorul de referinta al regiunii.
algoritmul attachreg /* ataseaza o regiune unui proces */
intrare: (1) pointer catre regiunea ce trebuie atasata
(2) procesul la care trebuie atasata regiunea
(3) adresa virtuala în proces unde va fi atasata regiunea
(4) tipul regiunii
iesire: intrare în tabela privata de regiuni
Figura 7.17. Algoritm pentru atasarea unei regiuni.
In continuare algoritmul attachreg initializeaza un nou set de registrii tripli pentru gestiunea memoriei procesului: daca regiunea nu este deja atasata altui proces nucleul aloca tabele de pagini pentru aceasta intr-un apel ulterior al functiei growreg (sectiunea urmatoare); in caz contrar va folosi tabelele de pagina existente. In final attachreg returneaza un pointer catre intrarea in tabela privata de regiuni pentru noua regiune atasata. De exemplu sa presupunem ca nucleul doreste sa ataseze o regiune existenta (partajata) de text cu dimensiunea de 7 Ko la adresa virtuala 0 a unui proces (Figura 7.18): el va aloca un nou registru triplu de gestiune a memoriei si il va initializa cu adresa tabelei de pagina a regiunii, adresa virtuala 0 si cu dimensiunea tabelei de pagini ( 9 intrari).
7.5.4 Schimbarea dimensiunii unei regiuni
Un proces isi poate mari sau micsora spatiul adreselor virtuale prin intermediul apelului sistem sbrk. Similar stiva unui proces creste automat (adica procesul nu apeleaza explicit nici un apel sistem) in functie de numarul de apeluri de proceduri. Intern nucleul invoca algoritmul growreg pentru schimbarea dimensiunii unei regiuni (Figura 7.19). Atunci când o regiune se mareste, nucleul verifica daca adresele virtuale ale regiunii marite nu se suprapun cu cele ale altei regiuni si daca cresterea regiunii nu va face ca dimensiunea procesului sa devina mai mare decât spatiul de adrese virtuale permis. Nucleul nu apeleaza niciodata algoritmul growreg pentru a mari dimensiunea unei regiuni partajate care este deja atasata mai multor procese, de aceea nu va trebui sa va faceti probleme pentru faptul ca marirea dimensiunii unei regiuni ar produce marirea dimensiunii altor procese peste dimensiunile permise.

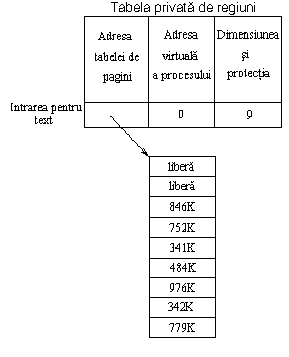
Figura 7.18. Un exemplu de atasare a unei regiuni de text existenta.
Cele doua cazuri in care nucleul foloseste growreg pentru o regiune existenta sunt sbrk pentru regiunea de date a unui proces si cresterea automata a stivei utilizator. Amândoua regiunile sunt private. Regiunile de text si de memorie partajata nu pot fi marite dupa ce au fost initializate. Aceste cazuri vor fi clarificate in capitolul urmator.
Nucleul aloca acum tabele de pagini (sau extinde tabelele de pagini existente) pentru marirea regiunii si aloca memorie fizica pe sistemele care nu accepta paginare la cerere. La alocarea memoriei fizice nucleul verifica daca aceasta memorie este disponibila inainte de apelarea functiei growreg; daca nu mai este memorie disponibila va apela la alte masuri necesare pentru marirea dimensiunii unei regiuni. Daca procesul micsoreaza regiunea nucleul va elibera pur si simplu memoria asignata regiunii.
algoritmul growreg /* schimba marimea unei regiuni */
intrare (1) pointer catre intrarea în tabela privata de regiuni
(2) marimea cu care se schimba dimensiunea regiunii (poate fi
pozitiva sau negativa)
iesirea:niciuna
}
else /* dimensiunea regiunii descreste */
face o (alta) initializare a tabelelor auxiliare, daca este necesar;
seteaza câmpul dimensiune din tabela de procese;
Figura 7.19 Algoritmul growreg pentru schimbarea dimensiunii
unei regiuni
In ambele cazuri el va ajusta dimensiunea procesului si dimensiunea regiunii si va reinitializa intrarea in tabela privata de regiuni si registrii tripli de gestiune a memoriei in conformitate cu noua mapare.
De exemplu, presupunem ca regiunea de stiva a unui proces începe la adresa virtuala 128K si contine de obicei 6Ko, si nucleul doreste sa extinda dimensiunea regiunii cu 1Ko (1 pagina).
Daca marimea procesului este acceptabila si adresele virtuale de la 134K la 135K -1 nu apartin altei regiuni atasate procesului, nucleul extinde dimensiunea regiunii. El extinde tabela de pagini, aloca o pagina de memorie, si initializeaza o noua intrare in tabela de pagini. Figura 7.20 ilustreaza acest caz.
7.5.5 Încarcarea unei regiuni
Intr-un sistem care suporta paginare la cerere, nucleul poate "mapa" un fisier in spatiul de adrese al procesului in timpul apelului sistem exec, aranjând sa citeasca paginile fizice individual mai târziu la cerere, asa cum va fi explicat in capitolul 12. Daca nucleul nu suporta paginarea la cerere, el trebuie sa copieze fisierul executabil in memorie, încarcând regiunile procesului la adresele virtuale specificate in fisierul executabil. Nucleul poate atasa o regiune la o adresa virtuala diferita fata de unde el încarca continutul fisierului, creând un spatiu liber in tabela de pagini (revezi Figura 7.18).
De exemplu, aceasta trasatura este folosita pentru a produce erori de memorie când programele utilizator acceseaza adresa 0 ilegal. Programele cu variabile pointer folosesc uneori acesti pointeri fara sa verifice valoarea lor este 0 si, din acest motiv folosirea lor este ilegala.
Prin protejarea paginii care contine adresa 0, procesele care gresesc accesând pagina cu adresa 0 produc o eroare si se termina fortat, permitand programatorilor sa descopere aceste greseli mari repede.

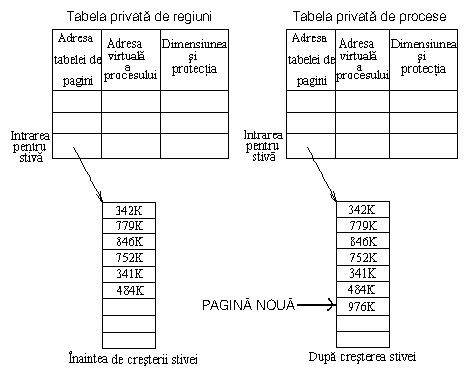
Figura 7.20 Cresterea regiunii de stiva cu 1Ko
La încarcarea unui fisier intr-o regiune, algoritmul loadreg (Figura 7.21) calculeaza spatiul liber dintre adresa virtuala la care este atasata regiunea la procesul si adresa virtuala de început a datelor din regiune si extinde regiunea in conformitate cu cantitatea de memorie de care are nevoie regiunea. Apoi pune regiunea in starea "in încarcare" si citeste datele regiunii in memorie din fisier, folosind o varianta interna a algoritmului apelului sistem read.
Daca nucleul a încarcat o regiune text care poate fi partajata de mai multe procese, este posibil ca alt proces sa poata gasi regiunea si sa încerce sa o utilizeze înainte ca ea sa fie complet încarcata, deoarece primul proces poate fi in asteptare cât timp este citit fisierul.
Pentru a evita problema, nucleul verifica un indicator de stare al regiunii pentru a vedea daca regiunea este complet încarcata si, daca regiunea nu este încarcata, procesul asteapta. La sfârsitul algoritmului loadreg, nucleul reactiveaza procesele care asteapta ca regiunea sa se încarce si schimba starea regiunii in valida si in memorie.
algoritmul loadreg /* încarca o portiune dintr-un fisier într-o regiune */
intrare: pointer catre intrarea în tabela privata de regiuni
(2) adresa virtuala a regiunii de încarcat
(3) pointerul catre inodul fisierului ce trebuie încarcat în regiune
(4) deplasamentul în fisier pentru începutul regiunii
(5) contorul de octeti pentru cantitatea de date încarcat
iesire: niciuna
Figura 7.21 Algoritmul loadreg
De exemplu, presupunem ca nucleul doreste sa incarce un text de dimensiunea 7Ko intr-o regiune care este atasata la adresa virtuala 0 a unui proces dar vrea sa lase un spatiu liber de 1Ko la inceputul regiunii (Figura 7.21). Din acest moment, nucleul va aloca o intrare in tabela de regiuni si va atasa regiunea la adresa 0 folosind algoritmii allocreg si attachreg. Acum nucleul apeleaza loadreg, care apeleaza growreg de doua ori - prima data pentru a lasa un spatiu liber de 1Ko de la inceputul regiunii, si a doua oara, la alocarea spatiului pentru continutul regiunii - si growreg aloca o tabela de pagini pentru regiune. Nucleul seteaza câmpurile in u area pentru a citi fisierul: el citeste 7Ko din fisier de la un deplasament specificat (furnizat ca parametru) la adresa virtuala 1Ko a procesului.

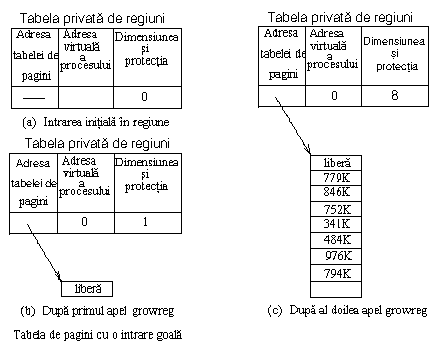
Figura 7.22 Încarcarea unei regiuni text
7.5.6 Eliberarea unei regiuni
Când o regiune nu mai este atasata la un proces, nucleul o poate elibera si o repune in lista regiunilor libere (Figura 7.23). Daca regiunea este asociata cu un inod, nucleul elibereaza inodul folosind algoritmul iput, in acord cu incrementarea contorului de referinta al inodului in allocreg. Nucleul elibereaza resursele fizice asociate cu regiunea, cum ar fi tabelele de pagini si paginile de memorie. De exemplu, presupunem ca nucleul doreste sa elibereze regiunea de stiva din figura 7.20. Presupunând ca, contorul regiunii este 0, el elibereaza 7 pagini din memoria fizica si tabela de pagini.
algoritmul freereg /* elibereaza o regiune alocata */
intrare: pointer la regiune (blocata)
iesire: niciuna
if (regiunea a avut un inod asociat)
elibereaza inodul (algoritmul iput)
elibereaza memoria fizica asociata regiunii
elibereaza tabelele auxiliare asociate regiunii;
sterge câmpurile regiunii;
pune regiunea în lista regiunilor libere;
deblocheaza regiunea;
Figura 7.23 Algoritmul pentru eliberarea regiunilor
algoritmul detachreg /* detaseaza o regiune de la un proces */
intrare: pointer catre intrarea din tabela privata de regiuni
iesire niciuna
}
Figura 7.24 Algoritmul pentru detasarea regiunilor
7.5.7 Detasarea unei regiuni de la un proces
Nucleul detaseaza regiunile in apelurile sistem exec, exit, si shmdt (detaseaza memoria partajata). El actualizeaza intrarea din tabela privata de regiuni si rupe legatura cu memoria fizica prin invalidarea registrului triplu de gestiune a memoriei asociat (algoritmul detachreg , Figura 7.24). Mecanismul de translatare a adresei astfel invalidate se aplica procesului, nu regiunii (ca in algoritmul freereg). Nucleul decrementeaza contorul de referinta al regiunii si câmpul dimensiune din intrarea in tabela de procese in conformitate cu dimensiunea regiunii. Daca contorul de referinte al regiunii ajunge la 0 si daca nu este nici un motiv sa se pastreze regiunea (regiunea nu este o regiune de memorie partajata sau o regiune text cu bitul "sticky " activ, asa cum se va vedea in sectiunea 8.5), nucleul elibereaza regiunea folosind algoritmul freereg. El elibereaza regiunea si inodul blocat, care a fost blocat pentru a preveni conditiile de concurenta asa cum se va prezenta in sectunea 8.5 dar pastreaza regiunea si resursele alocate.

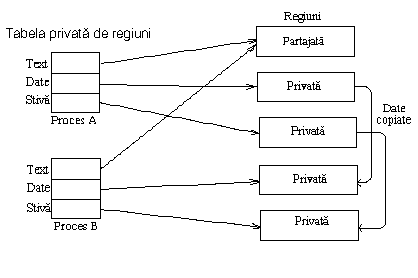
Figura 7.25 Duplicarea unei regiuni
algoritmul dupreg /* duplica o regiune existenta */
intrare: pointer catre intrarea în tabela de procese
iesire pointer catre o regiune blocata identica cu regiunea de duplicat
Figura 7.26 Algoritmul pentru duplicarea unei regiuni
7.5.8 Duplicarea regiunii
Apelul sistem fork cere ca nucleul sa dubleze regiunile unui proces. Daca o regiune este partajata (text partajat sau memorie partajata), totusi, nucleul nu are nevoie de o copie fizica a regiunii; in schimb, el incrementeaza contorul de referinta al regiunii, permitând proceselor parinte si fiu sa foloseasca in comun regiunea. Daca regiunea nu este partajata iar nucleul trebuie sa copie fizic regiunea, el aloca o noua intrare in tabela de regiuni, o tabela de pagini si memorie fizica pentru regiune. In figura 7.25 de exemplu, procesul A creeaza procesul B si isi duplica regiunile. Regiunea de text a procesului A este partajata, deci procesul B o poate folosi in comun cu procesul A. Dar regiunile de date si de stiva ale procesului A sunt private, deci procesul B le duplica prin copierea continutului lor in noi regiuni alocate. Chiar pentru regiuni private, copierea fizica a regiuni nu este mereu necesara. Figura 7.26 prezinta algoritmul pentru dupreg.
7.6 Starea de asteptare (sleep)
Pâna in prezent acest capitol a acoperit toate functiile de nivel scazut care sunt executate pentru tranzitiile la si de la starea executie in modul nucleu exceptând functiile care muta un proces intr-o stare de asteptare. Vom încheia cu prezentarea algoritmilor sleep, care schimba starea procesului din executie in modul nucleu in asteptare in memorie (sleep), si wakeup, care schimba starea procesului din starea de asteptare in starea gata de executie in memorie sau pe disc.
Când un proces se pune in asteptare, el face de obicei aceasta in timpul unui apel sistem: procesul intra in nucleu (cadrul context 1) când executa o exceptie a sistemului de operare (trap) si se pune in asteptare pâna când resursele devin disponibile. Când procesul se pune in asteptare el face o comutare de context, introduce cadrul context curent in stiva si executa in cadrul 2 al contextului nucleu (Figura 7.27). Procesele deci trec in asteptare când întâlnesc o eroare de pagina ca rezultat al accesarii adreselor virtuale care nu sunt fizic încarcate; ele asteapta cât timp nucleul citeste continutul paginilor.
Evenimente de asteptare si adrese de asteptare
Reamintim ca procesele asteapta un eveniment, ceea ce înseamna ca ele sunt in asteptare pâna când evenimentul are loc, dupa care sunt trezite si intra in starea gata de executie (in memorie sau pe disc). Desi sistemul foloseste notiunea abstracta de asteptare pe un eveniment, implementarea mapeaza de fapt setul de evenimente intr-un set de adrese virtuale. Adresele care reprezinta evenimentele sunt codate in nucleu, si semnificatia lor este ca nucleul asteapta pentru a-l mapa intr-o adresa particulara.
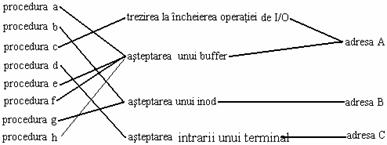
Figura 7.28 Asteptarea procesului pe evenimente si maparea
evenimentelor in adrese
Abstractizarea notiunii de eveniment nu distruge si numarul de procese care asteapta evenimentul. Ca urmare apar doua anomalii. Prima, când apare un eveniment sunt trezite toate procesele care asteptau acel eveniment si acestea in starea gata de executie. Nucleul va planifica pentru executie un singur proces iar celelalte se vor pune din nou in asteptare.
A doua anomalie in implementare este ca, mai multe evenimente se pot mapa intr-o singura adresa ceea ce determina ca unele procese sa astepte eliberarea resurselor de catre altele. Ar fi mai eficient daca evenimentele ar fi mapate câte unul la o adresa. Totusi, uneori, s-ar putea face ca nucleul sa fie mai usor de inteles daca maparea ar fi unu la unu.
algoritmul sleep
intrare: (1) adresa de asteptare
(2) prioritatea
iesire: 1 daca procesul se trezeste ca rezultat al unui semnal interceptat de proces,
executa algoritmul longjmp daca procesul se trezeste ca rezultat a
/* aici procesul aflat în asteptare este întreruptibil de semnale */
if (nu sunt semnale catre proces)
}
scoate procesul din coada hash de asteptare, daca este acolo;
schimba nivelul de prioritate al procesorului la acela la care era când
procesul a intrat în starea de asteptare;
if (prioritatea procesului permite interceptarea semnalelor)
return (1)
executa algoritmul longjmp; }
Figura 7.29 Algoritmul de asteptare
Algoritmii pentru sleep si wake-up
Figura 7.29 prezinta algoritmul sleep. Nucleul mai întâi creste nivelul de executie al procesorului pentru a bloca toate întreruperile astfel încât sa nu poata fi oprit când manipuleaza cozile de asteptare, si când salveaza vechiul nivel de executie al procesorului astfel încât sa poata fi refacut când procesul se va activa mai târziu. El marcheaza starea procesului asteptare, salveaza adresa de asteptare si prioritatea in tabela de procese, si-l pune in asteptare intr-o coada hash de procese. Intr-un caz mai simplu (asteptarea nu poate fi întrerupta), procesul face o comutare de context si asteptarea se face in siguranta. Când un proces in asteptare este trezit, nucleul îl programeaza mai târziu sa se execute: procesul revine din comutarea de context in algoritmul sleep, restaureaza nivelul de executie al procesului la valoarea avuta înaintea intrarii procesului in algoritm si se termina.
La trezirea proceselor care erau in asteptare, nucleul executa algoritmul wakeup (Figura 7.30), in timpul unui apel sistem obisnuit sau când se trateaza o întrerupere. De exemplu, algoritmul iput elibereaza un inod blocat si trezeste toate procesele care asteptau deblocarea acestuia pentru a deveni libere. Similar, tratarea întreruperii de disc activeaza un proces care asteapta terminarea I/O. Nucleul ridica nivelul de executie al procesorului in algoritmul makeup pentru a bloca tratarea întreruperilor. Apoi pentru fiecare proces care asteapta nucleul marcheaza câmpul de stare al procesului "gata de executie", scoate procesul din lista inlantuita a proceselor in asteptare punându-l intr-o lista inlantuita a proceselor pregatite pentru planificare, si sterge câmpul din tabela de procese care a marcat adresa de asteptare a procesului.
algoritmul wakeup /* trezirea unui proces în ateptare */
intrare: adresa de asteptare
iesire: niciuna
reface nivelul de executie al procesorului la nivelul initial
Figura 7.30 Algoritmul pentru trezirea proceselor
Daca procesul trezit nu este încarcat in memorie, nucleul trezeste procesul incarcator pentru a încarca procesul in memorie (presupunem ca sistemul nu suporta paginarea la cerere); altfel, daca procesul trezit este mai potrivit pentru executie decât procesul aflat in executie, nucleul seteaza indicatorul de planificare executa algoritmul de planificare la revenirea in modul utilizator. In sfârsit, nucleul reface nivelul de executie al procesorului. Procesele asteapta frecvent un eveniment care este "sigur" sa se întâmple, cum ar fi când asteapta o resursa blocata (inoduri sau buffere) sau când asteapta terminarea I/O de pe disc. Procesul este sigur ca se trezeste pentru ca utilizarea unei astfel de resurse este planuita sa fie temporara.
Totusi un proces poate astepta câteodata un eveniment care nu este sigur ca se întâmpla, si daca este asa, el trebuie sa existe o modalitate de recapatare a controlului in vederea continuarii executiei. Pentru astfel de cazuri nucleul "întrerupe" asteptarea procesului imediat trimitând un semnal. Urmatorul capitol explica semnalele in detaliu; pentru acum, presupunem ca nucleul poate trezi(selectiv) un proces in asteptare ca rezultat al transmiterii unui semnal. Pentru a distinge tipul starilor de asteptare, nucleul seteaza prioritatea procesului in asteptare când intra in starea de asteptare, pe baza prioritatii de asteptare. El invoca algoritmul sleep cu o valoare a prioritatii, bazata pe cunoasterea faptului ca evenimentul de asteptare este sigur sau nu. Daca prioritatea este deasupra unei valori de prag, procesul nu se va trezi prematur la receptionarea unui semnal, ci va astepta pâna când evenimentul este gata sa se petreaca. Dar daca valoarea prioritatii este sub valoarea de prag, procesul va fi trezit la receptionarea semnalului. Când procesul este trezit ca rezultat al unui semnal, nucleul poate executa un longjmp depinzând de motivul pentru care procesul a trecut in asteptare. Nucleul face un longjm pentru a restabili un context salvat anterior daca nu are nici o cale sa termine apelul sistem pe care îl executa. De exemplu un apel sistem citire de la terminal este întrerupt pentru ca utilizatorul a oprit terminalul, citirea nu se termina dar se revine cu un mesaj de eroare. Aceasta este valabila pentru toate apelurile sistem care pot fi întrerupte in timp ce asteapta.
Procesul n-ar continua normal dupa trezire pentru ca evenimentul nu s-a produs. Nucleul salveaza contextul procesului la începutul celor mai multe apeluri sistem utilizând apelul setjmp, anticipând ca mai târziu va avea nevoie de un apel longjmp. Acestea sunt ocaziile când nucleul doreste ca procesul sa fie trezit la receptionarea unui semnal fara sa execute un apel longjmp.
|
