1)Prelucrarea paralela,def:Prelucrarea paralela repr o forma eficienta a prelucrarii informatiei care accentueaza evenimentele concurente in procesul de calcul.Concurenta implica parallelism,simultaneitate si pipe-line.Datele repr numere sau simboluri.Acestea sunt considerate necorelate intre ele si nu au o anumita semnif sau structura precizata.
Informatia reprez o colectie de date corelate intre ele printr-o relatie sau struct sintactica. Prin urmare,inf reprez un subspatiu al spatiului datelor.
Cunostintele constituie corelatii de informatie la care se adauga un inteles semantic.
Inteligenta reprez corelatii de cunostinte.Tipuri de prelucrari:a)dc prelucrarea nu e organizata,prelucram date;b)dc prelucrarea interpreteaza/coreleaza date,prel informatie;c) dc corelam informatii,prelucram cunostinte;d)dc legam cunostintele intre ele si obt alte cunostinte,prel inteligenta.
Din pct de vedere al S O:a)prelucrarea secventiala(pe loturi/batch):se executa pe rand cate un proces;SO e responsabil de asigurarea tuturor conditiilor neces executiei unui proces si de lansarea sa in executie.b)prel prin multiprogramare:exista un paralelism intre operatiile real in SC;de obicei se suprapun op interne in procesor cu op de I/O pt ca concurenta e pe bus-ul extern.c)prelucr prin impartirea timpului:creeaza impresia ca mai multe procese se executa simultan;de fapt procesorul exec niste procese,alocandu-le fiecaruia niste intervale de timp de executie.d)multiprocesarea:pp existenta a mai mult de un procesor in SC.Paralelismul poate fi atins si prin modificari arhitecturale la nivelul procesorului.Prel paralela e strans legata de prel distribuita.Distinctia dintre prel paralela sic ea distribuita devine tot mai mica pe masura ce tehnologia comunicatiilor de date se dezvolta.Studiul sistemele de calc,din pct de vedere al prel paralele,pp:
-proiectarea si aplicabilitatea calculatoarelor cu prel paralela;
-analiza si proiectarea sist de operare;
-analiza cerintelor de programare si proiectarea de algoritmi;
-analiza limitarilor performantelor in calc cu struct paralela.
2)Mecanisme hardware de prel paralela in sist uniproc:Din pct de vedere hardware se evidentiaza metode ce constau in multiplicarea resurselor si metode de suprapunere in timp a activitatii diferitelor blocuri hardware.Exista urm categ de mecanisme de prel paralela:
a)Multiplicarea unit functionale:majoritatea unit functionale, la nivelul procesorului sunt realiz multiplicat.Procesoarele "clasice" au o singura unitate aritmetica si logica(ALU). Prin urmare unit ALU nu effect decat o singura operatie la un moment dat.In unele procesoare exist 2 unit ALU,care pot lucra in paralel.Avantaj:dc reusim sa util mai multe unit simultan creste vit de prelucr.Dezavantaje:e necesar un bloc de control;tb prevazute cai suplimentare pt "alimentarea" cu operanzi a acest unit suplimentare.
b)Paralelism si pipe-line in CPU:organizam prelucrarile dupa princip unei benzi de asamblare.Impartim o op in op mai mici situate in blocuri conectate in cascada=>creste viteza de prel.Dezav:nr de blocuri de prel nu poate fi marit oricum de mult;prel e dependenta de tipul de instructiuni de la intrare;
c)Suprapunerea op CPU cu op I/O:Utilizarea unor controlere I/O separate permite efectuarea in paralel a op interne ale CPU cu op de transfer de date oe canale I/O.Exemple de controlere I/O sunt:controlere DMA-care permit transferul direct de date memorie-memorie,bazat pe principiul cererii de magistrala,procesoare specializate I/O.
d)Utilizarea unui sist de mem ierarhizata:Un sist de calcul cu mem organizata ierarhizat poate echilibra diferentele de viteza intre componentele sist.
Registrele CPU sunt direct adresabile de catre unitatea ALU.Me 757c25h m cache reprez un tampon intre mem principala si CPU.Mem principala reprez un tampon intre mem virtuala si CPU.CPU are capacitate de stocare mica,dar viteza e mare (cost mare).Spre baza piram scade viteza,dar creste capacitatea de stocare si invers.
e)Echilibrarea vitezelor de prelucrare:Vit de prel e def ca un nr de operatii effect in unit de timp.In cazul CPU ea e data de durata ciclului de instructiune tp.
CPU:Bp=1/tp;Bpu =R/Tp ;Bpu< Bp;unde R nr de rezultate;Tp=timpul tot necesar si Bpu vit de prelucrare de utilizare.
![]() MEM:Bm=W/T;Bmu=Bm/√M
;Bmu<Bm;unde W repr nr de cuv transferate
;T unit de timp;M nr module de mem.
MEM:Bm=W/T;Bmu=Bm/√M
;Bmu<Bm;unde W repr nr de cuv transferate
;T unit de timp;M nr module de mem.
DISP I/O:Bd=1/td;td-timp mediu de acces la disp de I/O
Bm>Bmu>Bp>Bpu>Bd;Ec care ne spune dc sist de calcul e echilibrat si optim config,darn u prea e indepl niciodata e:Bp+Bd=Bm;Ec care ne spune dc SC e doar echilibrat,dar nu si optim config:Bpu+Bd=Bmu.Ec care se indeplineste: Bpu+Bd<=Bmu
3)Mecanisme software de prel paralela in sist uniprocesor:
a)Multiprogramarea:in acelasi interv de timp pot exista mai multe programe active in
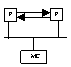
muliprogr e princip cererii si acceptarii de magistrala.Obs:exista posib sa se suprapuna op
de I/O ale unui procesor cu op de I/O al altui procesor,dc sist e prevazut cu un controler DMA pe mai multe canale sau cu mai multe controlere DMA. Tb tinut seama si de disponibilitatea intrarii pt fiecare procesor in parte.P1-pp ca e procesor;P2-DMA;BR-bus request BG-bus grant;MC-mem comuna
b)Diviziunea in timp:reprez impartirea timpului de executie al CPUintre toate procesele sist.Procesorul va executa procesele in mod alternativ.Ne trebuie un instrum pt a masura timpul=>introducem un ceas de timp real care va genera intreruperi periodice(T perioad).
Viteza va creste mai mult ca la multiprogramare.Obs:in cazul multiprogr procesele isi termina faza de calcul;In cazul div in timp procesele nu isi termina faza de calcul,inainte sa se execute alt proces;procesele pot fi astfel intercalate incat sa se castige timp de executie in raport cu multiprogramarea;apare suprap intre op de I/O si op CPU,respect intre diferite op I/O.
4)Principiul realizarii calculatoarelor pipe-line:Executia unei instructiuni pp 4 faze majore:incarcarea instructiunii,decodarea instr,incarcarea operanzilor si executia propriu-zisa.In procesoarele non pipe-line aceste faza se desf secvential, iar in procesoarele pipe-line se desf cu parallelism temporal.
Arhitectura unui SC pipe-line:
RS/RV=register scalare/vectoriale;
S1,2,3=stagii de prelucrare;M=mem;UC=unit de comanda;
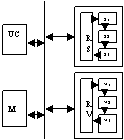 Cond esentiala pt pipe-line:alimentarea cu operanzi in
permanenta.Proiectarea calc pipe-line include:secventarea sarcinilor,
prevenirea conflictelor de acces,controlul congestiei, controlul salturilor in
program.
Cond esentiala pt pipe-line:alimentarea cu operanzi in
permanenta.Proiectarea calc pipe-line include:secventarea sarcinilor,
prevenirea conflictelor de acces,controlul congestiei, controlul salturilor in
program.
Exista 2 struct pipe-line:una pt date scalare si una pt date vectoriale.Faza de incarcare a operanzilor e impartita in 2 subfaze independente,corespunz operarii cu scalari si cu vectori.Faza de executie se desf in 2 procese distincte ,asociate scalarilor sau vectorilor.
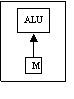
5)Principiul real calculate matriceale:Exista 2 unitati functionale distincte:o unitate de control si sincronizare a elem de procesare si o unitate de prelucrare matriceala.Fiecare element de prelucrare (PE) reprez un elem pasiv fara posibilitatea de a decodifica instruct.Elem de prelucrare sunt conectate printr-o retea de interconectare, dupa diverse topologii de interconectare.Incarcarea instruct si decodarea lor, pt unitatea de prel matriceala, e efectuata de unitatea de control ,prin intermediul unei retele de interconectare intre PE.Fiecare elem PE e alc dintr-o unit ALU si mem locala.
 Structura:
Structura:
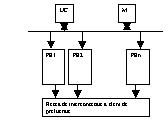
Pt o sesiune de lucru specifica,unitatea de control stabileste functia ALU pt fiecare PE, dupa care transfera operanzi din exterior catre mem locale ale PE si rezultatele de la un PE la alt PE.Programarea procesoarelor matriceale e mult mai dificila decat cea a calc pipe-line,nu exista limbaj de program pt o astfel de structura si duplicarea elem functionale la nivelul HW.
6)Principiul real sist multiprocessor:Sistemul e alc din mai multe procesoare ce impart resurse commune(mem),dar poseda si resurse proprii.Procesoarele funct independent ,dar treb sa comunice intre ele.Structura de interconectare intre procesoare si intre procesoare si resursele comune determina organizarea sist multiprocessor.Exista 3 mari categorii de interconectari:
-impartirea unui bus comun;
-util unei retele de interconectare totala;
-util de mem multiport.
Sist multiprocesor pot fi centralizate sau distribuite.Sist centralizate contin toate procesoarele in acelasi sist de calcul,spre deoseb de sist distribuite in care procesoarele pot fi fizic plasate in subsisteme diferite.Pt sist distribuite e necesara o retea de comunicatie intre procesoare rapida, adaptabila si fiabila.Nr de procesoare treb sa fie limitat.
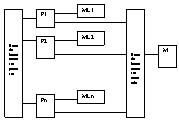
7)Tipuri de arhitecturi ale sist de calcul:Sist de calcul se pot clasifica, d p d v arhitectural,astfel:
a)dupa multiplicarea sirului de instructiuni si date:
-un singur sir de instructiuni-un singur sir de date (SISD) ;
-un singur sir de instructiuni-sir multiplu de date (SIMD);
-sir multiplu de instructiuni-un singur sir de date (MISD);
-sir multiplu de instructiuni-sir multiplu de date(MIMD);
SISD:
SIMD: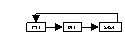
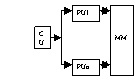
MISD:
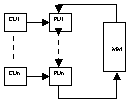
CU:unit de control;MM:modul de mem;PU:unit de prelucrare;
Arhitectura SISD este cea clasica si este realizata in general in tehnica pipe-line;arhitectura SIMD corespunde procesoarelor matriceale;arhitectura MISDexecuta mai multe instructiuni asupra unui flux de date;se creeaza o structura macro-pipe-line,in care iesirea unei PU devine intrare pt urmatoarea PU.Solutia nu este considerate practica;nu exista sist de calcul in arhitectura MISD.Arhitectura MIMD corespunde sist multiprocessor.
b)Clasificare dupa gradul de parallelism:
Fie n=largimea busului de date al procesorului si m=nr de cuvinte ce se prelucreaza pe ciclu;
-n=1,m=1 WSBS(word serial and bit serial)
-n=1,m>1 WPBS
-n>1,m=1 WSBP
-n>1,m>1 WPBP
Gradul maxim de parallelism P e def ca nr max de digitice pot fi prelucrati pe unit de timp de catre sist de calcul.El poate fi calculat astfel:P=n*m.
c)Clasif dupa paralelism si nr de niveluri pipe-line:Se considera prelucrarea paralela si gradul de pipe-line la urm niveluri ale subsistemelor de calcul:
-unitatea de control a procesorului (CPU)
-unitatea aritmetica si logica (ALU)
-logica combinationala necesara efectuarii unei operatii ALU de 1 bit (CLC)
8)Ierarhizarea MEMORIEI
Memori este ierarhizata cu scopul de a realiza transferuri de date intre procesor si memorie sa se realizeze cu o viteza cat mai apropiata de cea a procesorului.
Mem poate fi ierarhizata dupa mai multe ctiterii :
-metoda de accesare a informatiei (memorii RAM- cu acces aleatoriu, memorii SAM-cu acces secvential si memorii(dispozitive de stocare) cu acces direct(DASD-direct acces storage devices),
-timpul de acces -ca timp de intarziere intre comanda si prelucrarea efectiva a informatiei.
Memoria e organizate pe niveluri astfel : nivelul i este ierarhic superior nivelului i+1(i nivel superior iar i+1 inferior). Dimensiunea memoriei este mai mare pe nivelurile inferioare si mai mica pe nivelurile superioare.
Timpul de acces este mai redus catre nivelurile superioare si mai mare spre nivelurile inferioare.
Memoriile se mai pot clasifica in memorii private(accesibile numai de un procesor anume) sau memorii comune(partajate).
In mod uzual un sistem de calcul are trei niveluri ierarhice de memorie:memorie locala, memorie principala(primara) si memoria secundara.
Structura ierarhica a memoriei este organizata astfel incat spatiul de adrese al nivelului i reprezinta un subspatiu al spatiului de adrese al nivelului i+1.Totusi informatia de pe nivelul I poate fi mai acuala decat informatia de pe nivelul i+1.
Se creeaza astefel problema coerentei datelor intre niveluri adiacente, aceasta problema trebuie rezolvata de sistemul de operare (care trebuei sa actualizeze toate copiile, de pe toate nivelurile).
Modelarea performantelor intr-un sistem cu momorie ierarhizata este realizata printr-o functie numita functie de scucces (rata deatingere,H-probabilitatea gasirii informatiei de pe une anumit nivel.
Aceasta functie depinde de granularitatea informatiei transferate, capacitatea memoriei pe acel nivel, politici de administrare a memoriei.H depinde de marimea memoriei H(s).
Se defineste rata de pierderi, F(s)=1-H(s).
9)Timpul mediu global de acces într-un sistem de memorie ierarhizata
Scopul proiectarii unui sistem iererhizat de memorie, cu n niveluri, este atingerea unor performante cat mai apropiate de cele ale memoriei de pe nivelul 1(cache) si un cost cat mai apropiat de acela al nivelului n(memorie de masa).
Atingerea acestor performante depiunde de o multitudine de factori, printre care se pot enumera: modul in care programul acceseaza variabilele din memorie, timpul de acces si dimensiunea memoriilor pe fiecare nivel, marimea blocului de informatie transferat, politici de management al memoriei.
O masura a performantelor este timpul efectiv de
acces la memorie, Ti (de la procesor la nivelul I de memorie) :![]()
Timpul efectiv de acces la memorie, asociat
sistemului de calcul cu memorie ierarhizata:![]() ,n numarul de niveluri de ierarhizare,hi este
frecventa de acces pe nivelul i.
,n numarul de niveluri de ierarhizare,hi este
frecventa de acces pe nivelul i.
Inlocuind hi se obtine: ![]()
Inlocuind Ti cu expresia sa se obtine: ![]()
Pe de alta parte H(sn)=1(probabilitatea de atingere a informatie de pe nivelului cel mai de jos este1).
Si 1-H(si)=F(si) de aici
rezulta: 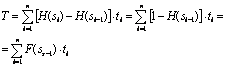
Optimizarea performantelor inseamna minimizarea timpului efectiv de acces ![]() , tinand cont de constrangerile
, tinand cont de constrangerile ![]() , C reprezentand costul total al sistemului de memorie, c(ti)
costul pe unitatea de memorie(octet).
, C reprezentand costul total al sistemului de memorie, c(ti)
costul pe unitatea de memorie(octet).
10)Scheme de adresare pentru memoria principala
Exista doua scheme principale de adresare a memoriei primare:
-cu intercalare de ordin superior
-cu intercalare de ordin inferior
Presupunem ca memoria principala are N=2n cuvinte.
Adresare cu intercalare de ordin superior distribuie adresele in M=2m module, astfel ca fiecare modul I, i=0, M-1, contine adrese consecutive de la i 2n-m la (i+1)2n-m-1.
Adresarea cu intercalare de ordin inferior distribuie adresele astfel incat adresele consecutive sa fie localizate in module consecutive.
Schema permite extinderea simpla a memoriei prin adaugarea a noi module(pana la maxim M module).Totusi plasarea unei zone continue de memorie poate genera conflicte de acces in cazul UPC organizate pipe-line(vectorial sau matricial) deoarece datorita secventarii instructiunilor in program se poate ajunge in situatia ca instructiuni consecutive sa fie plasate in acelasi modul.
Fiabilitatea sistemului de memorie este mai buna pentru intercalarea de ordin superior, deoarece modulul defect poate fi izolat; pentru intercalarea de ordin inferior un modul defect produce deteriorarea catastrofala a performantelor intregului sistem.
In practica se pot utiliza scheme de adresare a memoriei mixte(intre cele doua variante extreme din figura)
11)MEMORIA VIRTUALA
Pentru foarte multe sisteme de calcul exista programe ce nu se pot incadra in limitele memoriei principale.
Solutia consta in utilizarea unor tehnici de management al memoriei astfel incat fiecarui utilizator sa i se aloce suficienta memorie din intregul sistem de memorie ierarhizata.
Managementul memoriei tine seama de structura programului (structuri de date, variabile, functii proceduri); faza de compilare a programului asociaza un idintificator unic pentru fiecare entitate, iar faza de editare a legaturilor asociaza locatii de memorie , in memoria sistemului, pentru fiecare identificator.
Setul de identificatori reprezinta spatiul de memorie virtuala, iar setul locatiilor de memorie din memoria principala defineste spatiul memoriei fizice.
Exista trei politici de conrol al acestui transfer:
-politica de plasare - selectarea unei locatii de memorie pe nivelul dorit unde va fi depus elementul
-politica de reamplasare - selectarea elementului care trebuie sa fie plasat pe alt nivel pentru a face loc elementului curent
-politica de incarcare - ce decide momentul de timp cand elementul va fi adus de pe nivelul inferior
Datorita caracteristicilor unui program numai un set de identificatori referit intr-un interval ∆. Secventa referintelor, pe acest interval, poate fi localizata.
Aceasta localizare poate fi: temporala, spatiala, secventiala.
Localizarea temporala permite identificarea numarului de blocuri necesare la fiecare nivel de memorie; localizarea spatiala permite determinarea dimensiunii blocului de memorie pentru fiecare nivel; localizarea secventiala permite distribuirea de identificatori unici pe fiecare modul de memorie pentru situatiile de accese concurente la memorie.
Intervalul de timp, ∆, numit spatiu de lucru, reprezinta o marime critica a sistemului de calcul.
12)MEMORIE PAGINATA
Spatiul virtual de memorie este partitionat in pagini de lungime fixa. Fiecare adresa virtuala consta in doua campuri: un numar de pagina virtuala, ip si un deplasament iw in interiorul paginii.
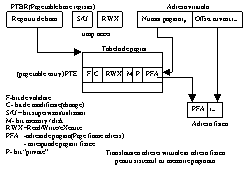

Avantajul paginarii este acela de a rezolva problema implementarii functiei de corespndenta.Memoria asociativa TBL este mai rapida decat memoria uzuala
Dezavantajele paginarii sunt: -sistemele de memorie paginata pot devani ineficiente daca spatiul virtual de adrese este mare; dimensiunea tabelei poate deveni excesiv de mare, paginare nu reprezinta un mecanism pentru implementarea rezonabila a partajarii memoriei,o parte a memoriei fizice este ocupata de tabela de pagini apare fragmentarea datorita tabelei de pagini.
13)MEMORIA SEGMENTATA
Pentr programe cu grad mare de structurare pe blocuri se utilizeaza segmente de memorie ce contin elemente ale programului. Segmentarea reprezinta o tehnica pentru managementul alocarii memoriei virtuale spre deosebire de paginare, care este orientata catre managementul alocarii memoriei fizice. Intr-un sistem cu memorie segmentata se poate defini un spatiu logic de memorie foarte mare.
Exista mai multi algoritmi de plasare a unui segment in memorie:-Algoritmul celei mai bune corespondente; -Algoritmul celei mai nepotrivite corespondente;-Algoritmul primei corespondente;-Algoritmul "buddy".Algoritmi cei mai eficienti sunt 1 si 4.
Dezavantajele segmentarii sunt:-aparitia zonelor libere, intre segmente succesive.Fenomen numit fragmentare externa;intregul segment trebuie adus in memorie, chiar daca numai o parte dn spatil sau de adese este necesar; efectul e mai putin neplacut ca la paginare;fragmentarea datorita tabelei de segmente (similar paginarii)
15)MEMORIA CU SEGMENTE PAGINATE
![]()

16)Alegerea marimii paginii. Pentru sistemele pur segmentate fragmentarea esterna poate fi evitata prin paginare. Marimea paginii trebuie aleasa pentru a reduce efectele negative ale paginarii
Daca s reprezinta marimea segmentului si z marimea
paginii in segment, atunci numarul de pagini in cadrul segmentului este: ![]() , Q[] reprezinta operatorul de rotunjire, s si z in cuvinte.
, Q[] reprezinta operatorul de rotunjire, s si z in cuvinte.
Spatiul de memorieI(s,z)- fragmentarea interna-
este dat de : ![]() reprezinta un spatiu neutilizabil in ultima pagina a
segmentului.
reprezinta un spatiu neutilizabil in ultima pagina a
segmentului.
Tabele de pagini T(s,z) cuvinte cu : ![]() , c=constanta
(reprezinta largimea tabelei)
, c=constanta
(reprezinta largimea tabelei)
Fractiune de memorie pierduta datorita paginarii in cadrul segmentului
este:![]()
In practica valoarea marimii paginii depinde mai mult de eficienta hardware-lui care realizeaza paginarea.
17)POLITICI DE ALOCARE AL MEMORIEI
Managementul memoriei trebuie sa rezolve urmatoarele probleme:
cate pagini de memorie sunt alocate unui proces
cum se decide cata procese vor fi rezidente in memorie
Politica de management al memoriei trebuie sa inbunatateasca rata de generare a exceptiilor (page fault) in situatiile in care o pagina nu se afla in memoria principala , sa creasca viteza de prelucrare a sistemului si sa micsoreze timpul de raspuns.
Exista doua clase de politici de managementul memoriei: cu partitionare fixa si cu partitionare variabila.
Politica de management include o metoda de estimare a localizarii programelor(proceselor).
Desi partitionarea fixa pare mai avantajoasa datorita simplitatii implementarii, politica partitionarii variabile este mai buna in situatia in care localizarea programelor variaza mult in timp.
Politicile de management de memorie pot fi locale sau globale.
Exista mai multe modele pentru localizarea programelor. Aceste modele pot fi utilizate in politica de amplasare/deplasare a paginilor in memorie.
Modelul independentei referintei (IRM). Acest model presupune ca sirul referintelor este o secventa de variabile aleatorii independente cu o distributie uniforma.
Modelul celei mai putin utilizate stive(LRUSM)- se defineste un vector(stiva) a celor mai putin recent utilizate pagini fizice din memorie care contin referinta ceruta.
Modelul LRUSM este putin mai bun decat IRM, acesta fiind similar cu IRM dar aplicat la nivelul unui set de pagini fizice mai putin utilizate si nu la nivelul intregului set de pagini fizice.
Se defineste rata de exceptii globala, f : ![]()
O alta masura pentru determinarea performantele sistemulor de memorie este produsul spatiu-timp,ST:
![]() In final rezulta produsul spatiu timp
In final rezulta produsul spatiu timp ![]()
18) Controlul încarcarii programelor
Memoria principala constitue principala resursa a sistemului de calcul ce este utilizata dinamic de catre procesele active intr-un mediu de multiprogramare.
In mod uzual, numarul de procese active (gradul de multiprogramare) este mai mare decat numarul de procesoare; acest fapt conduce la suspendarea unor procese pentru a utiliza procesorul asociat lor pentru executia altor procese.
Modelul unui sistem de calcul multiprocesor si care utilizeaza multiprogramarea.
Controlul încarcarii programelor
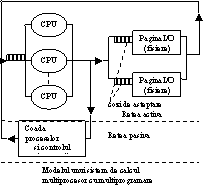
Modelul din figura consta in doua sectiuni principale: reteaua activa(procesoarele, memoria, discul magnetic) si reteaua pasiva(coada de asteptare si controlul incarcarii). Controlul incarcarii programelor defineste politicile de admitere a unor procese in starea activa (implicit controlul gradului de multiprogramare). Fiecare proces este in asteptare sau executie intr-una din cele trei categorii de resurse din reteaua activa. Fiecare categorie din reteaua activa poseda cozi de asteptare de lungime egala cu gradul de multiprogramare.
Notiuni utilizate in la prezentarea unor criterii de incarcare optima a proceselor:
-impul mediu total de servire a unei exceptii "page-fault"
-impul mediu de executie (totala, globala) a unui proces
-umarul mediu de exceptii "page-fault"
-impul mediu de transfer al unei pagini cerute
Exista mai multe criterii pentru controlul incarcarii proceselor:
-criteriul L=S; se incarca un numar de procese(programe), d pana cand L(d)=L=S
-criteriul L=aS, a constanata supraunitara
-imitarea gradului de multiprogramare la d=dmax. Valoarea dmax este ajustata in mod adaptativ, in functie de contextul de lucru. In aceasta situatie utilizarea sistemului ramane la o valoare constanta, acceptabila. Controlul incarcarii va contine, in acest caz, si un dispecer ce planifica procesele, aduce procese din starea pasiva in starea activa.
19)Politici de reamplasare a paginilor din memorie
Exista urmatoarele politici de reamplasare a segmentelor:
-ast recently used (LRU) - se inlocuieste pagina cea mai putin utilizata, relativ la momentul de timp curent.
-lgoritmul optimal al lui Belady (MIN) - se inlocuieste pagina ce va fi referita cel mai tarziu, relativ la momentul de timp curent.
-east frequently used (LFU) - se inlocuieste pagina care a fost referita cel mai putin frecvent.
-irst In First Out (FIFO) se inlocuieste pagina care a stat in memorie cel mai mare interval de timp.
-lgoritmul CLCK- varianta a algoritmului FIFO, ce aproximeaza algoritmul LRU.
-ast In First Out (LIFO) - se inlocuieste pagina care a stat in memorie cel mai putin timp
-andom (RAND) - se alege in mod aleator o pagina care va fi inlocuita.
Algoritmii LRU, LFU, LIFO, FIFO si RAND sunt algoritmi realizabili. Algoritmul MIN este nerealizabil practic dar aste utilizat pentru comparatie cu ceilalti algoritmi (ca referinta deoarece este algoritmul optimal).
Exista si algoritmi complecsi de alocare; in acesti algoritmi regula de reamplasare al paginilor se aplica la nivel global, pentru toata memoria principala, fara a identifica procesul care utilizeaza pagina.
Un alt exemplu este acela al algoritmului setului de lucru (Working Set-WS). Acest algoritm mentine in memorie acele pagini ale fiecarui proces, care au fost referite la un interval de timp (prestabilit) in urma. Daca nu exista loc in memorie o parte din procese vor fi dezactivat
21)Metode de mapare a mem cache:Exista 4 politici de baza pt plasarea blocurilor din mem principala in mem cache:mapare directa,mapare asociativa,mapare asociativa pe seturi si mapare de sector.Mem principala se alege de 256k cuvinte. Adresa fizica va fi reprez pe 18 biti.Exista 256k/16=16 384 blocuri in mem principala si 128 de blocuri in mem cache.
a)Maparea directa:blocul i din mem principala e asociata cu blocul (i MOD 128) din mem cache.Fiecare bloc din mem cacheare asociat un camp "tag".Campul "tag" din adresa mem principale se compara cu fiecare camp "tag" al mem cache.Dupa gasirea corespondentei dintre campurile tag se alege campul "bloc" din adresa mem principale si campul "cuvant" din aceeasi adresa pt selectarea octetului ce va fi transferat din blocul mem cache in blocul mem principale.
Avantajul acestei mapari directe este accesul simultan la datele dorite si la campul tag.Daca campul tag nu exista in mem cache,datele vor fi suprimate.Un dezav al maparii directe apare atunci cand 2 sau mai multe blocuri din mem principala , utilizate alternativ, sunt asociate aceluiasi bloc cache.Aceasta situatie are probabilitate mica in sistemele uniprocesor,dar probabilitatea creste pt sist multiprocesor cu mem cache comuna.
b)Maparea asociativa:in acest caz orice bloc din mem principala poate fi asociat cu orice bloc din mem cache.Metoda este cea mai buna,dar si cea mai scumpa.Maparea asociativa elimina conflictele de acces intre blocuri,dar timpul de acces creste datorit faptului ca este necesara o cautare asociativa.
c)Maparea asociativa pe seturi: Aceasta mapare reprez un compromis intre maparea directa si cea asociativa.Mem cache este impartita in S seturi.Blocul i,din mem principala ,poate corespunde cu orice bloc din mem cache apartinand setului (i mod S) .Nr de seturi,S,determina costul cautarii.Setul se determina direct din adresa,apoi se cauta campul tag corespunzator adresei in set.
d)Maparea de sector:In aceasta situatie atat mem cache cat si mem principala sunt impartite in sectoare,iar sectoarele in blocuri.Unui sector din mem principala ii este asociat un sector din mem cache.Numai blocul din mem principala ce a generat exceptia este adus in cache,iar restul blocurilor din sectorul mem cache sunt marcate "invalid".Obs:Dimensiunea blocului in mem cache este aleasa in raport cu proprietatea de localizare a programelor.Mem cache este adresata cu adrese fizice si nu cu adrese virtuale.Algoritmii de reamplasare a blocurilor din mem cache sunt similari celor de reamplasare al managementului mem.
22)Clasificarea sist de intrare/iesire:Subsist de intrare-iesire consta in interfete de intrare-iesire si dispozitive periferice.Functiile interfetei I/O sunt de a separa exteriorul de bus-urile CPU,a stoca datele si a realiza conversia datelor la formatul de lucru al CPU.Setul de comenzi care controleaza o operatie I/O se num driver I/O.Interfata poate interoga,porni sau opri dispozitivul periferic sau poate interoga CPU pt a transfera datele.Dupa modul in care CPU este implicata in operatia de intrare-iesire aceste operatii si sist de I/O se pot clasifica in:
a)op I/O controlate prin program
b)op I/O cu acces direct la mem(DMA)
c)op I/O controlate de circuite specializate
23)Canalul I/O sector
-efectueaza o singura operatie I/O la un moment dat. Din momentul selectarii disp periferic operatia I/O se incheie complet pana la efectuarea urmatoarei tranzactii.
Efectuarea unei tranzactii I/O e initiate de CPU ce genereaza adr dispozitivului periferic si un semnal de start. Canalul citeste un cuv din mem; acest cuv a fost initializat inainte de generarea semn de start al cpu si contine adr de start a prog de transfer I/O ce va fi executat de canal. Prog canalului e constituit dintr-o succesiune de cuv de control; aceste instructiuni indica tipul transferului, durata bl de date, operatii speciale. Vit max de transfer este de 1-3Mo/sec.
24)Canalul I/O multiplexor
-un processor I/O ce poate controla cateva tranzactii I/O diferita.Transferurile de date sunt multiplexate in timp printr-o interfata unica cu CPU. 2 tipuri: canal multiplexor orientat pe blocuri si canal multiplexor orientat pe character. Un canal multiplexor orientat pe character e constituit dintr-un set de subcanale fiecare actionand ca un canal selector de viteza mica.
Fiecare subcanal consta dintr-un buffer, registru de adr a perifericului, flag de cerere de transfer I/O, flagurile de control si stare. Totusi subcanalele impart logica pentru controlul global al canalului.logica de control a canalului scaneaza cyclic flagurile de cerere de transfer setat vor efectua o tranzitie I/O; dupa incheierea tranzactiei I/O se scaneaza urmatorul subcanal. Viteza maxima de transfer e de 100-200ko/sec.
25.Conectarea subsistemelor i/o cu mem si/sau CPU in sist cu mem cache.
-in acest caz exista 2 configuratii:
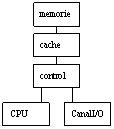
canalul concureaza CPU ptr a accesa mem cache.Ptr ca sist I/O e mai lent decat CPU,prin utilizarea cacheului nu se imbunatateste sensibil vit de transfer I/O. Localizarea referintelor transferate prin canal I/O e mica, deci va creste traficul dintre mem si cache, va conduce la performante slabe al CPU.
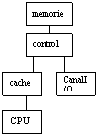
canalul concureaza cu mem cache ptr a accesa mem principala. Apare o problema de coerenta a datelor. Solutia e introducerea unui flag de modificare a referintei, acest flag va fi citit la fiecare cerere de transfer I/O,cand referinta a fost modificata in cache,canalul I/O va prelua referinta tot din cache.
26.Prelucrarea pipe-line
-realiz un parallelism temporal..
-subimpartirea task-urilor intr-o secv de sub task-uri, fiecare dintre eleurmand sa fie executat intr-unul dintre niv struct pipeline. Taskuri successive -orientate prin struct pipe-line, executia lor efectuata cu suprapunere in timp.Probleme: impartirea task-urilor in subtaskuri si egalizarea timpilor de executie ptr fiecare niv.. str pipeline pot fi fara reactie sau cu r.
Ptr un task T sut def taskurile. Tj nu poate incepe executia pana cand alte tascuri Ti (i<j) nu au terminat executia.ptr o str liniara pipeline Tj nu poate incepe executia pana cand toate taskurile Ti nu s-au terminat.
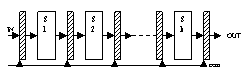
Perioada ceasului
-niv a str pipeline Si, are un timp de prog,τj. Se not τ1 intarzierea asociata fiecarui latch.
, τ=max+ τ1= τm+ τ1 unde τm -timpul de propagare max
frecventa f=1/ τ
Ideal o str pipeline cu k niv poate procesa n task-uri in Tk=k+(n-1) perioade de ceas.
Viteza de ptrelucrare sk - in rap cu echiv sau non pipeline: sk = T1/Tk= nk/[k+(n-1)]. Vit max e sk,max=k si se obt ptr n f mare si nu este atinsa niciodata.
Eficienta
Aria dintre intervale de timp sin iv din diagrama spatiu -timp=produs sp-timp.. un element dat al prod sp-timp cuprinsa intre 2 momente successive de timp ti si ti+1 si 2 niv successive Si si Si+1 poate fi ocupat sau liber.
Eficienta e masurata ca rap procentual al elem prod timp-sp ocupate si al nr total de elem timp-sp.
Daca n,k, τ - nr de taskuri, nr de niv ale struct pipeline si perioada ceasului =>
η= nkτ/=n/[k+(n-1)]=sk/k
S-a consid un timp de observatie ge k=n-1 ciclii de ceas;sunt s[k(k-1)/2]elemente libere. Nr total de element e k(k+n-1),iar nr de elem ocupate este kn. Daca n>>, atunci η tinde catre1.
Rata de prelucrare(productivitatea)ω = nr de rezultate ce pot fi incheiate de catre struct pipeline.
ω=n/[kτ+(n-1)τ]= η/τ, unde n e nr total de taskuri pe durata de observatie.
27. Clasificare structurilor pipe-line
Criterii de clasificare: dupa locul in care apare: exista structuri care apar in int unui processor:-aritmetice si de instructiuni; daca struct este separate de proc s.n. de procesare. dupa nr. de biti implementati in str. pipe-line:-unifunctie - (o str. cu functie fixa sn pipe-line unifunctie) si multifunctie. dupa nr. de config. functionale :-statica- (pp. o singura config. functionala la un mom. dat) si dinamica - permite cateva configuratii functionale ce exista simultan. scalara- (prelucreaza o secventa de scalari) si vectoriala- prelucreaza vectori
28. Accesul simultan la memorie în structurile pipe-line
Se considera M=2m module de memorie.
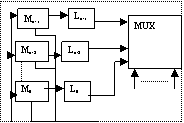
Toate modulele de memorie sunt selectate simultan. Prin utilizarea a m biti de adresa inferiori se selecteaza un cuvant dintr-un modul particular, dintre cele 2m module
Accesul de tip S se utilizeaza ptr transferal a k cuvinte in secvente. Dc accesul nu se face in secventa, performantele sist de mem sunt scazute.
Ptr transferal in secventa a k cuvinte, timpul de transfer este Ta+kτ (Ta= timpul de acces la module, iar τ intarzierea latch-urilor) dc cuv. se citesc incepand din modulul i cu i+k<=M si 1<k<M. dc citirea incepe cu modulul i si i+k>M, atuncitimpul de transfer creste cu Ta.
Este necesar sa fie indeplinita conditia: Mτ< Ta.
29. Accesul concurent la memorie în structurile pipe-line.
Modulele de memorie sunt adresate concuresnt. Bitii de adresa mai putin semnificativi se;ecteaza modulul, iar ceilalti (n-m) biti de adresa selecteaza elemental in iteriorul modulului. Apare o concurenta in accesarea modulelor, datorita modului de selectie. Accesul de tip C se utilizeaza pentru transferal secventelor de cuvinte, cu timpul de transfer Ta+ kτ= Ta+ Ta/M, indiferent de modulul de unde se incepe citirea. Schema desi este mai complicate dpdv hardware, este mai performanta.
F1)Principiile proiectarii procesoarelor pipe-line
a)Preincarcarea instructiunilor si manevrarea salturilor
Unele op pot cauza efecte nedorite asupra performantelor struct pipe-line.cand instruct I este in exec, aparitia unei intrruperi amana exec instruct i+1 pana cand intreruperea a fost servita.
2 tipuri de intreruperi : precise(apar ca urmare a detectarii unui cod de instruct ilegal) si imprecise(apar la niv de incarcare a operanzilor sau la niv de exec propriu-zisa). Cand apare una imprecise nu se mai admit instruct in pipe pana la servirea intreruperii. Pot aparea erori-instruct care aflate deja in pipe sunt exec inainte de servirea intreruperii, desi nu trebuia.se corecteaza cu un mecanism hardware-salturi in program.
Aparitia unei instruct de salt in fluxul de instruct deja incarcat in pipe-line det modif contextului progr=instruct devin nefolositoare.la terminarea instruct de salt se initiate urmatoarea instruct. Se intr. un timp suplimentar necesar golirii structurii pipe-line.
Fie n cicli de instruct pipe-line, p=prob ca o instruct sa fie conditionata, q= prob ca saltul sa se produca, m=nr. instruct ce asteapta sa intre in str. pipi-line. mpq=nr. instruct care produc salturi;ptr fiecare salt sunt necesari (n-1) cicli sau (n-1)/n instruct ptr a se sterge str. pipe-line..rezulta un tim suplimentar de prelucrare egal cu mpq(n-1)/n.
Rezulta un timp de prelucrare ptr m instruct de (m+n-1)/n+ mpq(n-1)/n..
Performantele de masoara ca m impartit la (m+n-1)/n+ mpq(n-1)/n
Tehnica de preincarcare a instruct imbunatateste perf struct pipe-line, darn u elimina complet efectul aparitiei salturilor.
b)Utilizarea buffer-elor de date si bus-urilor structurate.
Vit. de prelucrare a segmentelor struct pipe poate fi neuniforma si rezulta gatuiri.acestea pot fi evitate prin subdivizarea segmentului cu timp de prelucrare mare sau multiplicarea segmentului de viteza redusa. O alta met de netezire a fluxului este utilizarea buffer-elor de date-permite evitarea intreruperii funct. blocurilor din struct. pipe-line in general datorita conflictelor de acces la memorie-dc un registru e utilizat in comun de catre 2 strcu, una dintre ele tre sa astepte pana cand dealalta termina accesul la resursa comuna.
Prin utilize unei strct de bus-uri de pot defini rute distincte de acces ptr accesarea cu intarziere minima a inf dorite.
c)Imbunatatirea performantelor calc cu unitati de prelucrare pipie-line multiple
Exista posib ca intre 2 unitati de prelucrare conectate pe un bus comun sa apara sit de conflict sau in care unitatile isi transfera date-transfer care se realizeaza prin mem sau registre.este dorit sa se minimizeze accesele la mem=>tehnica de eviatare a acceselor la mem fol registre = internal forwarding
F3)Detectia hazardului
Acesta este datorat conflictului de utilizare a resurselor in timpul exec instruct pipe-line.
3 clase da hazard: WAR(write after read),RAW(read after write),WAW(write after write)
Mem si registrele de def drept resurse, iar continutul lor se numeste data. Domeniul D(i) al instruct i este setul de resurse ale caror date pot afecta exec instruct i. gradul R(i) asociat instruct i=setul de resurse ale caror date pot fi modif de exec instruct.
R(i) ∩D(j) #Φ ptr RAW(exec inst j este efectata de date ce pot fi modif de inst i)
R(i) ∩R(j) #Φ ptr WAW(inst i modif rez ale inst j,sau invers)
D(i) ∩R(j) #Φ ptr WAR(exec inst i este afectata de date ce pot fi modif de inst j)
F4)Secventarea sarcinilor si prevenirea coliziunilor
Dc in sist de calcul pipe-line exista mai multe procese utiliz unit funct se va face cu posibile coliziuni; inetrvalul de timp dintre 2 initieri ale unor procese sn latenta. Secventa de latente intre 2 proc consec sn cilcu de latenta si este periodica. Procedura de alegere a secventei de latente sn. strategie de control care tre sa minimizeze latenta dintre proc initiat la mom current sic el mai recent process initiat anterior. Coliziunea apare in mom in care 2 proc sunt initiate cu o latenta ce conduce la concurenta asupra unit funct.dc se fol tabela de rezervare, coliziunea apare cand latenta este egala cu dist (in cicli pipe-line) dintre 2 col marcate pe niste linii oarecare ale tabelei. Setul interzis de latente contine toate latentele posibile care cauzeaza ciliziuni intre 2 initieri de proc.
Se def vectorul de coliziune C=(Cn,..,C2,C1), unde Ci=1, dc i apartine F, dc nu Ci=0 si Cn=1 mereu, unde F este setul interzis
Se reprez diagrama de stare,starea init este starea in care C coresp setului interzis de latente, tranzitiile posib din starea init sunt cele coresp latentelor permise din vectorul C, iar starea urmatoare se obtine prin deplasarea la dreapta a starii curente cu un nr. de poz det de tranz,dupa care se efec un SAU logic cu starea init, astfel incat sa nu apara coliz
F5)Cerintele prelucrarii vectoriale
Un operant de tip vector este un set ordonat de n elem.instruct ce op asupra lui pot produce un rez scalar sau vect.. op potrivite tre sa aiba caract: procese identice se repeta de f multe ori, iar fiecare proc se poate imp in subproc;operanzii succesivi alim struct pipe-line ai necesita minimum de buffe-ere sau control local;op efec in struct pipe-line tre sa fie capabile sa-si imparta o gama extinsa de resurse
Imbunatatirea perf prelucrarii vect se realiz prin: un set bogat de inst vect; inst combinate; alegerea unui algoritm de prelucrare potrivit; utiliz unui compilator orientat catre preluc vect. Paralelismul se atinge prin 4 directii: utilize unui algoritm parallel; utilize unui limbaj de nivel inalt parallel; generarea unui cod obiect efficient; utilize unei masini de calcul cu cod eficient. Algoritmul rezolva problema intr-o maniera paralele. Limbajul este de oicei secvential.
F6)Planif struct pipe-line pt task-uri vect indep
Pp ca exista un nr m de struct pipe-line ce pot utiliz ptr exec a n taskuri, fiecare task avand un timp de calcul τi (i de la 1 la n), se consid ca taskurile sunt indep intre ele si se organiz in grupe sau partitii, dupa cum fol rez altor taskuri.
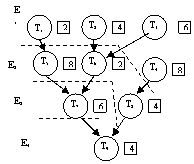
T5 fol rez prod de T1.prelucrarea vect se face cu o struct pipe-line multipla. Prima gupa contine taskuri care nu necesita rez altor taskuri-E1; a doua grupa fol rez din E1- E2; a treia grupa fol rez din E2- E3.
![]() ; n>1;t0=timp de init a str. pipe-line;ta=timp
mediu de exec
; n>1;t0=timp de init a str. pipe-line;ta=timp
mediu de exec
n=1 =>![]() ; se mai definesc
; se mai definesc ![]() si
si ![]()
algoritm:
initial se reseteaza toate str pipe-line, consumandu-se un int de timp t0; planif incepe cu prima str pipe-line si cu primu task din partitia curenta; se incearca sa se aloce acestui prim task un int de timp egal cu timpu de exec, fara a se depasi mom de timp t1.
Se recalc timpu mediu, t1 si t2.
![]() ;
; ![]() si
si ![]()
Se reia proc de planif
Ptr P1: ![]() ;
;

2![]() -t1=
-t1=![]() =2.5
=2.5
Ptr P2: ![]() ;
; 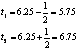
![]() =3.25
=3.25
Ptr P3 ![]() ;
; 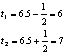
![]() =2.25
=2.25
Ptr P4 ![]() ;
; 
In practica pe at posibil se iau toate permutarile posibile de taskuri, se face cate o diagrama si se calc suma timpilor de neutilizare. Pt partitia cu un singur task, algoritmul se aplica simplificat
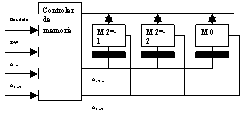
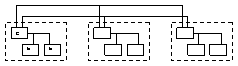
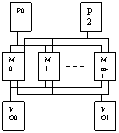
F7)Sistemele multiproc slab cuplate ierarhizate
![]() P-proc; S- control local; M-mem;
I/O-porturi I/O busuri
P-proc; S- control local; M-mem;
I/O-porturi I/O busuri
Modul de calc.
organigrama clusterelor in retea
S - blocul de control local -asigura in mod suplimentar fata de blocul CAS translatarea adr virtuale in adr fizica, daca adr virtuala corespunde unei adr fizice din al modul de calc.
Modulele de calc sunt conectate pe un bus comun=bus map, ce interconecteaza un cluster de module de calc. adr pe bus map sunt controlate de un controller de bus. El permite interconectarea mai multor clustere intre ele prinintermediul unuia sau mai multor bus-uri intercluster.
Controlul de bus: - arbitru de bus, interfata de comunicare cu busurile cluster, processor de mapare. In struct controller de bus exista mai multe cozi de asteptare-ptr uniformizarea vit de prelucrare intre blocuri: -coada de servire (cererile destinate arb de bus asteapta), o coada de returnare (unde asteapta mesajele de raspuns ptr arb de bus), coada de executie (mesaje prelucrate de proc de mapare), coada de executie (ptr result prelucrarii effectuate de proc de mapare)
Sccese la mem - in int aceluiasi cluster si intercluster
F7)Sisteme multiproc strans cuplate
Viteza de prelucrare intr-un sist multiproc slab cuplat poate fi scazuta in rap cu cerintele aplicatiei => sist multiproc cuplate strans
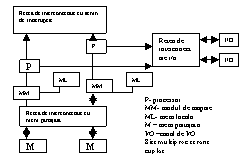
Proc sunt interconecate cu mem prin reteaua de interconectare. Modulul de mapare asociaza unei adr logice o adr fiz associate unuia din modulele de mem partajata.. Fiecare proc are mem locala
Leg cu dispozitivele i/o este facuta tot de o retea de interconectare. Ptr a evita conflictele de acces la mem, nr de module de mem partajata e mai mare decat nr de proc din sist. Proc pot fi sau nu identice. Disp de I/O pot fi conectate simetric sau asimetric. Modurile de conectare sunt imp ptr fiabilitatea sist.
Conectare asimetrice a disp I/O - defect unui proc =>pierderea datelor I/Oce erau transferate de acest proc.
Conectarea simetrica la defect unui proc , canalele i/Osunt disponibile ptr alte procesoare functionale.
F8)Retele de interconectare in sist multiproc
Conectare:- bus comun, retea crossbar, cu memorii cu multiport
Conectarea prin bus comun: -structura :

Op de transfer sunt controlate in totalitate de catre interfata de bus a fiecarui bloc conecatat pe bus. Un bloc ptr a se conecta tre sa verifice daca busul e liber, dupa care ocupa busul si informeaza celalalte busuri, el devenind master in system. Vit de transfer intre blocuri e lim de mechanism de ocupare a busurilor. Conecatrea mai multor proc la acelasi bus=>conflicte de acces..
Dezavantaj, defectarea unui bloc conectat pe busul comun duce la deteriorarea funct intreg sist.

struct unui sist multiproc strans cuplat cu busuri unidirectionale
Daca se creste nr de busuri commune, bidirectionale, aglomerarea de bus scade, dar complexitatea hard creste mult.
Fact care influenteaza caract schemei de interconectare cu bus comun: - nr de blocuri; algoritmul de arbitrare de buis ; tipul controlului de bus; largimea datelor; sincronizarea intre proc; detectia situatiilor de eroare.
Algoritmi de arbitrare de bus
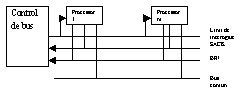
Algoritmul cu prioritati statice
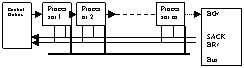
Proc ce concureaza la ocuparea busului au prioritati fixe. Un proc genereaza o cerere de bus(BR/)- sunt conecate pe o linie comuna . proc ce va ocupa busul va fi primul ce a receptionat semnalul BG/, acesta fiind generat daca SACK e inactive.
Se aloca fiecarui proc un interv de timp om care busul ii e oferit. Daca proc nu utilizeaza busul in interv oferit tre sa astept urm ciclu.
E ptr o incarcare mica de bus.
Algoritmul cu prioritati dinamice
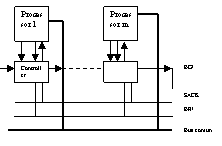
Nu exista bloc de control al busului centralizat. Blocul e divizat in sub-blocuri descentraliz. BG/ - conectat in bucla inchisa intre subblocuride control a bus. Subblocul conectat cu proc care a preluat busul=master modif dist dintre proc si subblocul de control de bus. Proc acesta va avea la urm cerere de bus prioritate min. Intre fiecare subbloc de control al busului si proc asociat este o legatura electrica ptr dialog.
Algoritmul cu interogare ciclica(polling)
Linia BG/ inlocuita prin log2n linii de interogare conectate la fiecare proc printr-un circ de decodare. Cand proc isi recunoaste codul de interogare=>activeaza semnalul SACK si ocupa busul. Blocul de control al busului intrerupe ciclul de interogare pana cand proc ce ocupa busul isi incheie operatiile pe acesta. Prioritatea proc e data de acest cod de interogare.
Algoritmul cu cereri independente
Fiecare proc emite o cerere de bus independ care e procesata de bl de control al bus. Bl raspunde cu semnale BG/ independ. Complex hard e ridicata.
Algoritmul FCFS
Nu prefera nici un proc: prima cerere de bus sosita e acceptata si servita. Alg optim , dar greu de implement ptr ca: - tre un mecanism de inregistr a ordinii cererilor de bus; poate ca 2 cereri de bus sa soseasca odata, ptr ca ordina relative a acestora san nu fie cea care tre.
Utilizat ca etalon ptr ceilalti alg de arbitrare.
Interconectarea cu retele crossbar
Asigura connect fara blocaj intre procesoare, mem si disp I/O.
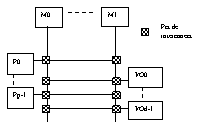
Nr max de transferuri simult e limit de nr de module de mem si de vit acestora. Punctul de interconectare tre sa asigure: dezv cererilor multiple de acces, acordarea unei prioritatifiecarei cereri si transferal propiu zis al info.
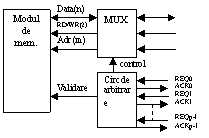
Struct funct a unui pct de interconectare
Fiecare proc ce doreste intreconect cu o resursa trimite catre pct de interconnect adr, datele si semnalele de comanda rd/wr si semn de cerere(REQ). pct de interconnect: bl mux, modul de arbitrare a cererilor multiple. Modului de arb a cererilor multiple rezolva cererile REQ si informeaza proc prin semn ACK. Costisituare dpdv hard.
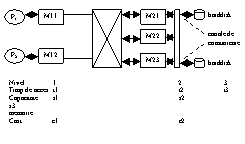
Interconecatrea memorie multiport
Daca bl constituente ale pct de interconectare din reteaua crossbar sunt distribuite la interfata cu modulele de memorie, atunci se creaza un sist de interconectare cu mem uniport, cum e in fig urmat:
Cic cu mem multiport: circ de mem RAM classic si un circ de arb a acceselor multiple. Mem multiport pot fi realizate intr-un chip sau in chipuri separate.
Comparatie intr modurile de interconnect ptr sist multiproc strans cuplate
Interconectarea cu bus comun:
-struct simpla si ieftine;
-modif hard simplu de efectuat;
-eficienta scazuta ptr rate mari de transfer de bus;
-defectarea unei componente poate conduce la nefunct intreg sist.;
-metoda potrivita ptr sist mici.
Interconectarea cu retea crossbar:
-cea mai complexa met;
-ofera rata de transf potentiala cea mai mare;
-unitatile functionale sunt simple;
-pct de interconectare sunt f complexe, dpdv hard.
Interconectarea cu mem multiport:
-necesita module de mem cu inteligenta ptr arbitrarea acceselor multiple;
-struct hard mai ieftina decat reteaua crossbar;
-necesita multe elemente de conectica.
|
