Aplicatie pentru clustering-ul documentelor web
Scopul acestei aplicatii este de a grupa rezultatele unui motor de cautare, in urma unei interogari a unui utilizator, sub forma unor categorii de documente web etichetate sugestiv pentru a ajuta la extragerea informatiei. Astfel, pe baza unei cautari aplicatia preia un numar de documente web returnate de motorul de cautare, le preproceseaza, aplica un anumit algoritm de clustering si prezinta categoriile obtinute intr-o forma vizuala.
Etapele parcurse in realizarea acestei aplicatii de clustering a paginilor web sunt:
(1) tokenizarea - ajuta la identificarea cuvintelor si expresilor prin separarea acestora prin intermediul unor delimitatori precum spatiul sau alte semne de punctuatie precum !, ?, 959f59j . etc.
(2) eliminarea cuvintelor irelevante proces in care cuvintele irelevante(stopwords) sunt eliminate din snippet pentru a nu participa la etapa de indexare. Cateva exemple de astfel de cuvinte ar fi cum, despre, asadar.
(3) stemming in aceasta faza cuvintele din snippet-uri sunt inlocuite cu radacinile acestora, cuvantul obtinut prin eliminarea sufixelor si prefixelor
Pentru a avea o imagine mai sugestiva a etapelor descrise anterior, avem schema aplicatiei:
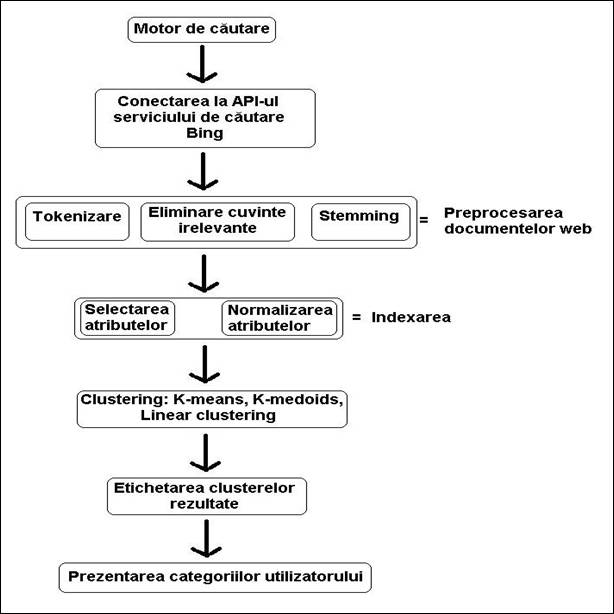
Fig 5.1 Schema bloc a aplicatiei pentru clustering-ul documentelor web
Pentru a accesa acest serviciu a fost nevoie de o cheie de inregistrare si adaugarea unei referinte web in aplicatie care permite apelul functiilor si accesul la clasele necesare pentru a realiza o cautare si de a prelua rezultatele generate de catre motorul de cautare. Mai jos este prezentata o portiune de cod in care este explicat modul in care se realizeaza o cautare si sunt explicati anumiti parametrii necesari realizarii cautarii.
|
//obiectul principal care realizeaza cautarea LiveSearchService service = new LiveSearchService(); //parametru in care sunt specificati ID-ul de conectare, textul de cautare SearchRequest request = new SearchRequest(); //ID-ul aplicatiei necesar conectarii request.AppId = 'F7CFFC58131BBB4FA4691EF0D51658BF1BC05BF5'; // textul dupa care se face cautarea request.Query = querytext; //obiect in care se specifica diferiti parametrii de cautare WebDataMining.net.live.search.api.WebRequest wr = new WebDataMining.net.live.search.api.WebRequest(); //este specificat numarul de pagini dorite wr.CountSpecified = true; //aplicatia va avea acces la 100 de pagini returnate de motorul de cautare wr.Count = 100; //cauta doar documentele web request.Sources = new SourceType[] ; request.Web = wr; //limba in care sunt scrise documentele web request.UILanguage = 'en'; //start cautare si depunere rezultate in obiectul response SearchResponse response = service.Search(request); //salvarea documentelor returnate de serviciul de cautare foreach (WebResult result in response.Web.Results) |
Fig 5.2 Cod pentru accesarea serviciului Bing API in limbajul C Sharp
Structura unei pagini returnate de serviciul de cautare Bing contine principalele campuri:
Title titlul paginii web
Url adresa paginii web
Description tag-ul de descriere a paginii, si anume snippet-ul pe care proceseaza aplicatia
O etapa importanta in procesul de clustering deoarece in acesta faza sunt obtinute cuvintele cheie care reprezinta documentele, in urma impartirii snippet-ului documentului in cuvinte, eliminarea cuvintelor de legatura si aplicarii stemming-ului pe termenii ramasi. Astfel, dupa aplicarea acestor pasi documentul este reprezentat doar de cuvintele importante, zgomotul fiind indepartat, fapt care reduce complexitatea de calcul a algoritmului si creste calitatea clusterelor care vor fi generate.
In aceasta faza snippet-ul paginii este divizat in cuvinte prin utilizarea anumitor delimitatori. In urma procesului de tokenizare documentul este reprezentat de un set de termeni, termeni care sunt mai mult sau mai putin importanti. Unii dintre delimitatorii utilizati sunt ?, ., ,, etc.
In aceasta etapa de preprocesare cuvintele considerate irelevante, care nu contin nici o informatie despre continutul documentului, spre exemplu and, what, to, sunt cuvinte care, desi apar frecvent, nu ne prezinta nici o informatie. Aplicatia de fata are ascociat un fisier stopwords.txt in care sunt stocate cuvintele de legatura pentru limba engleza, asa numitele stop words, care ne ajuta la filtrarea snippet-urilor documentelor pentru a selecta doar cuvintele cheie.
Prin acest proces se determina cuvintele care sunt derivate din acelasi cuvant radacina. Cuvintele care prezinta mici variatii sintactice unele fata de altele, sunt convertite, prin eliminari de sufixe si prefixe, in radacina cuvantului din care au derivat acestea.
De exemplu grupul de cuvinte drug, drugged, drugs, sunt cuvinte derivate din acelasi cuvant radacina, drug, si pot fi privite ca diferite aparitii ale aceluiasi cuvant.
Indexarea documentelor
In aceasta etapa fiecare document este reprezentat de un set de termeni, carora li se asociaza o pondere(weight), in functie de gradul de discriminare pe care il are acel cuvant.
Astfel dupa etapa de preprocesare se construieste vocabularul de termeni ai colectiei documentelor web, care contine toti termenii cheie din toate documentele care urmeaza a fi grupate. Lungimea vocabularului de termeni, in urma procesarii a 100 de documente web, ajunge la 900 de termeni.
S-a mai optat pentru inca o selectie de termeni, si anume cea care elimina termenii din vocabularul colectiei termenii care apar intr-un numar foarte mic de documente, in cel mult doua sau trei snippet-uri, acesti termeni putand fi tratati ca zgomot. Dupa o astfel de filtrare lungimea vocabularului colectiei s-a redus pana la aproximativ 350 de termeni, o lungime rezonabila care va duce la scaderea considerabila a complexitatii de calcul, si care nu va afecta calitatea clusterelor care vor fi generate. In final fiecare document are asociat un vector cu lungimea egala cu cea a vocabularului colectiei documentelor, unde fiecare pozitie reprezinta frecventa de aparitie a teremenului din vocabular in documentul respectiv.
Asignarea de ponderi termenilor din vectorii documentelor
In urma indexarii avem astfel o colectie de documente reprezentata de cate un vector de termeni, la care am asociat o pondere, in acest caz frecventa de aparitie a termenilor in documentul pe care il caracterizeaza, pondere care descrie importanta termenului in documentul care il contine.
Dintre metodele de calcul a ponderii termenilor folosite in aceasta aplicatie amintin:
![]() pentru frecv(d, t) >
pentru frecv(d, t) >
![]() , altfel
, altfel
unde frecv(d, t) reprezinta numarul de aparitii al termenului t in documentul d.
Astfel, prin aceste metode de calcul a ponderilor se incearca o evidentiere a termenilor care sunt mai importanti pentru un document, si sa scada gradul de discriminare al celorlalti termeni fapt care conduce la generarea unor clustere de calitate.
Similaritatea intre doua documente in aceasta aplicatie a fost calculata pe baza urmatoarelor metode:
![]()
unde i = (xi1, xi2, , xin) si j = (xj1, xj2, , xjn) sunt doua obiecte n-dimensionale.
![]()
![]()
![]() - unghiul dintre vectorii
- unghiul dintre vectorii ![]() si
si ![]() si produsul
si produsul ![]()
![]() este definit ca ∑ti=1
este definit ca ∑ti=1 ![]() si norma unui vector fiind
definita astfel
si norma unui vector fiind
definita astfel ![]()
In cazul
calcularii similaritatii intre doua documente,
distanta euclideana nu este foarte potrivita deoarece vectorii
asociati documentelor contin multi termeni egali cu 0, astfel se
obtine o similaritate ridicata chiar daca acestea sunt foarte
diferite. Similaritatea cosinus calculeaza gradul de asemanare intre
doi vectori pe baza unghiului dintre acestia, astfel
doua documente similare au vectorii termenilor similari si implicit unghiul
dintre acestia este relativ mic, ceea ce conduce la o similaritate
ridicata. Daca doua documente sunt identice, acestea vor avea
vectorii, care le reprezinta, identici, adica se vor suprapune iar unghiul ![]() va fi 0 ceea ce
implica similaritatea cosinus sa fie 1, cos(00) = 1, cazul
cel mai favorabil.
va fi 0 ceea ce
implica similaritatea cosinus sa fie 1, cos(00) = 1, cazul
cel mai favorabil.
In continuare este prezentat codul care calculeaza similaritatea intre doi vectori, pe baza forumulelor prezentate mai sus, cu ajutorul a trei functii care primesc ca parametrii cei doi vectori care reprezinta documentele si returneaza similaritatea acestora:
|
public double ComputeEuclideanDistance(List<double> v1, List<double> v2) return Math.Sqrt(dist); } public double ComputeManhattanDistance(List<double> v1, List<double> v2) return Math.Sqrt(dist); } public double ComputeCosinusSimimilarity(List<double> v1, List<double> v2) down = memb1 * memb2; if (down == 0) return 0; up = up / down; return up; } |
Fig 5.2 Cod care calculeaza similaritatea intre doi vectori
In lucrarea de fata au fost implementati urmatorii algoritmi: K-means, K-medoids si Linear-clustering. In cazul primilor doi algoritmi documentele sunt organizate in k clustere, k fiind un parametru de intrare, clusterele fiind formate pentru a optimiza urmatorul criteriu: obiectele din acelasi cluster sa fie cat mai similare, si obiectele din clustere diferite sa fie cat mai disimilare.
Prezentarea algoritmului K-means
Acest algoritm ia ca parametru de intrare variabila k, si partitioneaza setul de documente in k clustere, astfel incat similaritatea intracluster este mare, dar similaritatea intercluster este mica.
Similaritatea clusterului este masurata fata de valoarea medie a documentelor din acel cluster, valoare care mai este numita si centroidul sau centrul de gravitate al clusterului.
Pasii algoritmului sunt urmatorii:
Astfel, avem la intrare:
si la iesire:
un set de k clustere
Un alt criteriu de oprire al fi criteriul erorii patratice, definit prin:
![]() ,
,
unde E este suma erorii patratice pentru toate documentele; p este un document care apartine unui cluster Ci si mi este media clusterului Ci. Cu alte cuvinte, distanta dintre fiecare document si centrul clusterului din care face parte este ridicata la patrat si insumata. Astfel algoritmul incearca sa determine cele k partitii care minimizeaza eroarea patratica, pentru a generea clustere cat mai compacte si cat mai separate.
Mai jos avem o imagine care prezinta o secventa de iteratii in clustering-ul unui set de obiecte in 3 grupuri, prin algoritmul K-means:
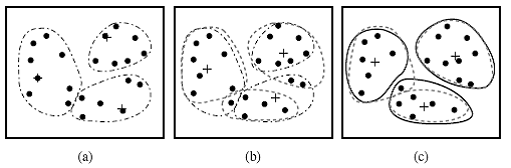
Fig 5.3 Clustering-ul unui set de obiecte prin metoda K-means(centrul fiecarui cluster este marcat prin simbloul +
Algoritmul este relativ eficient in procesarea unui set mare de documente, deoarece complexitatea computationala a algoritmului este O(nkt), unde n este numarul de documente, k este numarul de clustere, si t este numarul de iteratii, cu k << n si t << n. Metoda de clustering K-means nu poate descoperi clustere de diferite forme si clustere care difera mult in dimensiune.
Este sensibila la zgomot si outlieri(documente foarte indepartate de toate clusterele), deoarece un numar mic de astfel de documente influenteaza enorm centroidul clusterului.
In continuare voi prezenta mai pe larg etapele algoritmului de clustering K-means:
a) Selectarea primelor k documente ca fiind clusterele de start
In acesta etapa sunt formate cele k clustere, k fiind parametrul de intrare introdus de utilizator, centroidul clusterului fiind initial chiar documentul din acel cluster. Cele k documente sunt selectate ca fiind primele din colectia de documente.
for (int i = 0; i < k; i++)
b) Atribuirea documentelor ramase la cel mai apropiat cluster
Fiecare document din colectie este adaugat la clusterul cel mai apropiat, dupa ce s-a calculat similaritatea vectorului cu toti centroizii clusterelor.
for (int i = k; i < listMyDocuments.Count; i++)
c) Calcularea noilor centre ale clusterelor formate
Se calculeaza noile conetre ale clusterelor dupa ce toate documentele au fost grupate in cele k categorii.
for (int i = 0; i < k; i++)
d) Reatribuirea documentelor la cele mai apropiate clustere
Documentele sunt atribuite clusterelor celor mai apropiate, dupa calcularea similaritatii intre fiecare document si toti centroizii clusterelor. Aceasta etapa se repeta pana nu mai are loc nici o interschimbare de documente intre clustere.
do
}
for (int i = 0; i < k; i++)
} while (nr_switch > 0);
Cel mai apropiat cluster pentru un anumit document este gasit cu ajutorul functiei:
public int ClosestCategory(MyDocument doc)
return index;
Prezentarea algoritmului
Algoritmul de clustering K-medoids este derivat din metoda de clustering K-means, si reprezinta o varianta imbunatatita a acesteia in sensul ca nu este sensibila la outlieri, deoarece clusterul este reprezentat de un medoid, care este de fapt cel mai apropiat document de centrul clusterului, astfel din start documentele foarte indepartate nu mai sunt luate in calcul, spre deosebire de K-means care la calcularea centroidului tinea cont si de outlieri.
Pasii algoritmului K-medoids sunt:
se selecteaza aleator k documente, fiecare formand un cluster
Astfel, avem la intrare:
iar la iesire:
un set de k clustere
O alta varianta a algoritmului K-medoids s-ar putea baza pe principiul minimizarii sumei disimilaritatii dintre fiecare documente si medoidul clusterului din care face parte acel document. Astfel, este utilizat criteriul erorii absolute:
 ,
,
unde E este suma erorii absolute pentru toate documentele din colectie; p este un anumit documente care apartine unui cluster Cj, si oj este medoidul clusterului Cj.
Prin urmare algoritmul urmareste minimizarea acestei erori E, si se opreste atunci cand ea nu se mai modifica.
In cazul acestui algoritm de clustering nu mai este nevoie de parametrul k, precum la metodele K-means si K-medoids, care specifica numarul de custere care se vor forma, deoarece numarul clusterelor nu este cunoscut, ceea ce reprezinta un avantaj fata de algoritmii prezentati anterior. Singurul parametru ce trebuie cunoscut este un prag(treshold), care reprezinta similaritatea minima dintre un document si clusterele existente, caz in care daca aceasta nu este atinsa, documentul curent va forma propriul cluster. Aceasta metoda de clustering determina clusterele intr-un singur pas.
Reprezentantul clusterului poate fi media obiectelor din clustere(ca si in metoda K-means) sau obiectul cel mai central(K-medoids). In lucrarea de fata s-a optat ca reprezentantul clusterului sa fie media obiectelor din acel cluster.
Pasii algoritmului sunt:
Se ia un document care formeaza primul cluster
Se parcurge restul documentelor: daca documentul curent este destul de similar cu clusterele deja formate, se atribuie documentul respectiv clusterului cel mai apropiat, altfel documentul va forma propriul cluster
In continuare voi prezenta etapele urmate in implementarea acestui algoritm:
a) Primul cluster va contine primul document
Se genereaza primul cluster care va contine primul document din lista de documente de intrare. Apoi se calculeaza media clusterului, care initial va fi chiar vectorul de ponderi al documentului adaugat anterior.
listMyCategories.Add(new MyCategory());
listMyCategories[0].web_docs.Add(listMyDocuments[0]);
listMyCategories[0].ComputeNewCenter();
b) Atribuirea celorlalte documente
Pentru fiecare din documentele ramase, se calculeaza similaritatea fata de clusterele deja formate, iar daca aceasta similaritatea este mai mica decat pragul ales, documentul se va adauga clusterului cel mai apropiat, altfel acesta isi va forma propriul cluster. Apoi se calculeaza noile centre ale clusterelor, ca fiind media documentelor.
for (int i = listMyDocuments.Count - 1; i > 0; i--)
else
for (int j = 0; j < listMyCategories.Count; j++)
Ordinea de intrare a documentelor poate schimba foarte mult clusterele care se vor forma, dar plecand de la ideea ca motoarele de cautare returneaza o lista ordonata de pagini web in functie de importanta acestora, se ceonsidera destul de just ca algoritmul sa proceseze mai intai aceste documente mai relevante pentru cautarea realizata de utilizator.
Ca si o scurta descriere/comparatie a algoritmilor implementati avem:
metoda de clustering liniar: cel mai rapid algoritm, determinand clusterele intr-un singur pas; nu este cunoscut numarul clusterelor care se vor forma; este necesar ca parametru de intrare un prag care poate schimba radical numarul si continutul clusterelor generate
metoda k-means si k-medoids: acesti algoritmi pot fi analizati impreuna deoarece singura diferenta o reprezinta reprezentantul clusterelor; doua metode de clustering mai intense computational, in comparatie cu clustering-ul liniar; numarul clusterelor care se vor forma este cunoscut a priori, prin intermediul parametrului de intrare k.
In cazul tuturor algoritmilor de mai sus, in urma clustering-ului, fiecare obiect este atribuit unui cluster, indiferent de similaritatea dintre acel obiect si cluster.
Aceasta etapa de etichetare a clusterelor este o faza importanta a procesului de clustering de documente web, deoarece aceste etichete sunt vazute de catre utilizator si trebuie sa descrie cat mai bine clusterul pe care il reprezinta, astfel, cel care a realizat cautarea, isi poate forma o idee despre continutul clusterelor si care dintre acestea ar putea contine informatia de care el are nevoie.
Fiecare cluster trebuie etichetat printr-o descriere clara, concisa si distincta, in urma unui proces de etichetare, numit si labeling.
In acesta aplicatie au fost implementate doua metode de etichetare a clusterelor formate, si anume :
cel mai frecvent termen, si anume, eticheta clusterului va fi de fapt cel mai frecvent termen din lista de documente continute de acel cluster;
o expresie formata din cei mai frecventi doi termeni care sunt prezenti in clusterul respectiv.
S-a optat pentru aceste metode, deoarece s-a considerat ca termenii care apar cel mai frecvent, apar in mai multe documente si astfel au o pondere mai mare si astfel sunt cei mai buni candidati in reprezentarea clusterelor formate.
Reprezinta ultima etapa in procesul de clustering, aici fiind prezentate categoriile de documente generate. Este nevoie de o prezentare care sa faciliteze parcurgerea si vizualizarea continutului clusterelor formate, prezentare prin care utilizatorul sa simta o oarecare usurinta in cautarea informatiei necesare.
Clusterele formate vor fi afisate sub forma unui arbore, unde pentru fiecare cluster se va afisa eticheta acestui la care este concatenat numarul de documente web pe care le contine acel cluster, spre exemplu Tennis(23). Daca utilizatorul va selecta un anumit cluster, se va putea vizualiza documentele continute de acel cluster, iar in momentul selectarii unui anumit document, se poate accesa pagina web care este prezentata intr-o alta fereastra.
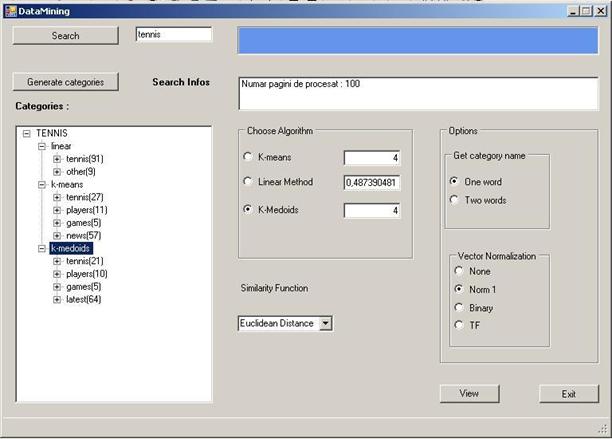
Fig 5.4 Prezentarea clusterelor sub forma unui arbore(rezultatele obtinute in urma clustering-ului documentelor cu cei trei algoritmi).
In acest scurt subcapitol se incearca o evaluare a algoritmilor implementati, si anume prin intermediul unor metrici de analiza a clustering-ului, sa determinam care dintre metodele de clustering este mai eficienta si genereaza clustere de calitate.
In continuare voi prezenta metricile de evaluare implementate in aplicatia de fata, metrici care au ajutat la compararea celor trei algoritmi:
![]() ,
,
unde n este numarul de documente care au
fost supuse clustering-ului, cazul de fata 100; k este numarul de clustere formate, iar ![]() reprezinta lungimea
clusterului care contine cele mai multe documente
reprezinta lungimea
clusterului care contine cele mai multe documente
![]()
unde c este ceontroidul medoidul clusterului C, format din documentele xi;
Astfel, cu cat este mai mica aceasta valoare, cu atat sunt mai similare documentele din acel cluster. Calculul acestei metrici pentru mai multe clustere se face prin adunarea gradului de compactare pentru fiecare cluster in parte. Astfel ne dorim sa determinam clustere care minimizeaza aceasta metrica.
![]()
Astfel, pentru fiecare cluster se determina clusterul cel mai apropiat, iar distanta dintre acestia este adaugata metricii. Pe baza acestei metrici cautam clustere care o maximizeaza, prin urmare clusterele fiind foarte disimilare si diferite prin continut.
![]() , ne spune cat de imprastiat este clusterul
, ne spune cat de imprastiat este clusterul
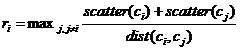 , pentru fiecare cluster determinam un cluster care maximizeaza
acest raport, cu alte cuvinte ri favorizeaza
clusterele care sunt apropiate si cu raza mare
, pentru fiecare cluster determinam un cluster care maximizeaza
acest raport, cu alte cuvinte ri favorizeaza
clusterele care sunt apropiate si cu raza mare
![]()
Prin intermediul acestei metrici cautam clusterele care minimizeaza parametrul r, caz in care distantele intre clustere sunt mari si gradul de imprastiere este mic. Astfel s-a gasit un echilibru intre cele doua metrici: separability(distanta), sa fie mare, si compactness(imprastierea), sa fie mic.
|
