Grant: A2105, IMBUNATATIREA ASPECTELOR PROZODICE IN SINTEZA TEXT-TO-SPEECH PENTRU LIMBA ROMANA
Inteligenta artificiala si sistemele inteligente presupun, printre altele, utilizarea dialogului verbal om-calculator. Interfetele necesare acestui dialog au constituit, in ultimele doua decenii, un subiect de mare interes in cercetare si dezvoltare, dar problemele legate de aceste interfete au fost rezolvate doar partial. In prezent, nu exista o metodologie coerenta pentru deducerea unor reguli de prozodie si pentru includerea de elemente prozodice in cadrul sintezei bazate pe text (Text-to-speech, TTS) si cu atat mai putin sisteme TTS care sa realizeze coerent acest deziderat, de mare complexitate.
Un grup interdisciplinar, format din specialisti din cadrul retelei de cercetare a Academiei Romane, Universitatii Tehnice Iasi, Universitatii Al.I. Cuza Iasi si INI a abordat in ultimul deceniu, din diverse perspective, sinteza semnalului vocal - cu preocupare pentru naturaletea vocii produse. Fara a ne propune sa solutionam total problema, nici pe orizontala (toate influentele asupra prozodiei), nici pe verticala (toate regulile de modificare a prozodiei date de un tip de influente, de ex. legaturile gramaticale, sau cele de sens), grupul respectiv (care nu se reduce la autorii prezentei lucrari) si-a propus sa demonstreze si sa exemplifice viabilitatea unui complex de metode, dintre care unele originale.
In timp ce tipic pentru masina este transmisia de date, pentru om definitorie este comunicarea. Diferenta consta in participarea intelectuala si afectiva a persoanei la actul comunicarii, participare reflectata atat la nivelul limbajelor neverbale (gestica, mimica etc.), cat si la nivelul vocal. Aceasta participare afectiva da varietate, coloratura si sensuri suplimentare, nu neaparat pe plan semantic, semnalului vocal. Sinteza vocii, in prezent, este limitata de lipsa afectului, varietatii si sensurilor suprapuse in planuri multiple. Vocea masinii ramane astfel cantonata intr-o regiune "moarta" a comunicarii, este monotona si obositoare in perspectiva unei expuneri indelungate la aceasta.
Prozodia, adica structura acustica ce se extinde pe mai multe segmente de semnal vocal, chiar peste mai multe cuvinte sau propozitii, implica ritm, accent, intonatie, timbru, afect si alte caracteristici ale vocii inca insuficient intelese sau vag definite in literatura. Informatia paralingvistica ce este continuta de prozodie nu este nicaieri regasita la nivelul "spus" prin cuvinte, dar - asa cum este pre 343b11d cizat in [1] - aceasta informatie poate fi chiar mai importanta pentru ascultator decat informatia lingvistica propriu-zisa. Incapacitatea sistemelor actuale de sinteza vocala de a reda prozodia naturala este evidentiata chiar de marii producatori de aplicatii [2] si este bine cunoscuta in mediul cercetatorilor in domeniul sintezei vorbirii: "One of the most difficult problems in speech to date is prosodic modeling". Sunt deja disponibile diferite sintetizoare TTS cum ar fi: MITTALK, JSRU, MBR-PSOLA, sintetizorul multilingv INFOVOX, I.N.R.S, cel dezvoltat la AT&T, multe fiind sintetizoare de tip Klatt, celelalte tipic concatenative. Dar naturaletea semnalului vocal nu a fost una din reusitele acestor sintetizoare, dupa cum se afirma recent in [3]: "These applications have proved acceptable, and even popular, provided the intelligibility of the synthetic utterances was high enough. Naturalness was not a major issue in most cases".
De maxim interes pentru cercetarea romaneasca este Sintetizorul Fuzzy de Voce (SiFuzzyV-IIT) de tip Klatt, dezvoltat la Institutul de Informatica Teoretica - Iasi, bazat pe sisteme neurofuzzy (premiera mondiala in domeniu; detinatorul titlului "Marca de Aur" acordat in cadrul expozitiei "Fabricat in Romania" - Iasi, 2002). Prezentam, in continuare, cateva din realizarile acestuia, precizand si zonele ramase neacoperite in imbunatatirea sintezei TTS.
Cele doua calitati ale vocii naturale, adaptivitatea - in sens larg - si variabilitatea se pot realiza, cu costuri nu neaparat mari, la nivelul sintetizoarelor actuale, cu adaptari minimale (sau deloc) la nivel hardware si cu imbunatatiri ale programelor de control. Sinteza adaptiva se refera la adaptarea la: (i) contextul semantic al cuvintelor si frazelor sintetizate; (ii) contextul afectiv-evaluativ al cuvintelor si frazelor sintetizate; (iii) conditiile sonore ambientale; (iv) interlocutorul sistemului de sinteza automata, atunci cand acesta este recunoscut.
Pana in prezent, cercetatorii din tara noastra (colectivul de cercetare de semnal vocal al Institutului de Informatica Teoretica, in colaborare cu Univ. Tehnica "Gh. Asachi" Iasi) au reusit implementarea unui sistem de sinteza vocala de tip Text-to-Speech, care este o realizare notabila in domeniul procesarii semnalului vocal. In elaborarea acestor aplicatii de tip TTS pentru limba romana a fost urmarita atingerea unui nivel bun de inteligibilitate si naturalete a vorbirii sintetizate. Ca urmare a acestor preocupari, doua aspecte ale producerii de semnal vocal au fost vizate: generarea de unde glotale si modelarea tractului vocal.
Este cunoscut faptul ca modelul glotal contribuie in mod decisiv la generarea semnalului vocal datorita faptului ca glota este un sistem dinamic neliniar cu influente majore asupra unor aspecte importante ale prozodiei vorbirii. Un alt aspect determinant pentru obtinerea vorbirii sintetizate de calitate este modelarea corecta a rezonantelor tractului vocal.
Vizat fiind cu precadere al doilea aspect, cel al modelarii rezonantelor tractului vocal, stadiul actual al cercetarilor se materializeaza intr-un sistem de sinteza TTS. Acesta este constituit dintr-un traductor litera-sunet si un sintetizor bazat pe reguli.
Scopul cercetarii este dezvoltarea si implementarea unui sistem de sinteza TTS care sa contina un modulul NLP imbunatatit, format din: (i) traductorul litera-sunet (LTS - letter-to-sound transducer); (ii) un modul de analiza morfo-sintactica si de identificare a informatiei la nivel de discurs; (iii) un modul de generare de elemente prozodice.
De asemenea, sintetizorul deja folosit trebuie reproiectat astfel incat noua iesire a modulului NLP, de o complexitate mai mare fata de iesirea predecesorului sau, sa poata fi prelucrata.
Una dintre cele mai elementare adaptari ale semnalului vocal generat de om este cea de adaptare la conditiile de mediu. Adaptarea la un mediu real, cu fond de zgomot, se realizeaza pe patru cai principale: prin modificarea amplitudinii semnalului (mai mare in mediul de zgomot ridicat), prin modificarea spectrului (creste contributia frecventelor inalte), prin modificarea ritmului (scaderea ritmului, cresterea duratei vocalelor), si prin cresterea duratei dintre cuvinte, care devin separate, segmentate in timp. Adaptarile realizate - instinctiv de un vorbitor uman - se opereaza deci la un nivel relativ elementar, cu modificari de prozodie minimale. Deoarece parametrii respectivi sunt relationati cu impactul pe care il au asupra inteligibilitatii vorbirii, deci sunt dati de calitati subiective, este necesara o definire probabilista sau fuzzy a lor. In tara noastra, datorita experientei existente in domeniul fuzzy si datorita naturaletei si simplitatii unei astfel de abordari, a fost preferata varianta unei logici nuantate de calcul a acestor parametri.
Determinarea influentei contextului afectiv-evaluativ asupra prozodiei nu este o sarcina imposibil de abordat. Pot fi date exemple de situatii cu grad ridicat de generalitate cand controlul sintezei TTS se poate implementa cu un efort relativ redus. De exemplu, atunci cand se determina (printr-o masuratoare simpla, de frecventa medie in spectrul vocal, sau de fundamentala) ca interlocutorul este un copil sau o persoana de gen feminin, se poate selecta una sau ambele dintre alternativele: (i) sistemul de sinteza automata se seteaza pe o voce de acelasi tip (copil/feminin); (ii) sistemul de sinteza automata se seteaza pe voce "calda" si "vorbire clara".
Variabilitatea de tip natural a semnalului vocal sintetizat se poate obtine prin modularea diverselor controale (al amplitudinii, lungimii vocalelor, accentului, pitch-ului etc.) sau semnale lent variabile, generate de sisteme care prezinta dinamica neliniara (haos). Parametrii sistemului haotic respectiv pot modela un anume subiect; ca acesti parametri reprezinta individul vorbitor si "personalitatea" lui este una din solutiile oferite de cercetarea romaneasca in domeniu. O consecinta a unei astfel de formulari a solutiei implica modularea haotica a mai multor parametri de sinteza (amplitudine, frecventa centrala a formantilor, largimea formantilor, elemente prozodice etc.), fiind necesare mai multe generatoare haotice, cate unul pentru fiecare parametru controlat. Alternativ, a fost folosit un sistem nuantat (fuzzy) haotic, aceste sisteme generand simultan un numar mare de iesiri necorelate sau slab corelate.
Delimitarea unor reguli de prozodie subintinse contextului semantic trebuie sa constituie unul din principalele obiective ale demersului de imbunatatire a sintezei TTS pentru limba romana. Dar pentru realizarea acestui deziderat este necesara si constituirea unui analizor morfo-sintactic.
Proprietatile prozodice ale semnalului vocal au diferite functii in comunicare. Cel mai evident efect pare a fi cel de focalizare a atentiei auditorului asupra unui anumit cuvant al enuntului. Axate fiind pe modelul cuvant dominant - cuvant dependent, gramaticile de dependenta par a fi cele mai potrivite pentru o implementare TTS.
Inca de la inceputurile procesului de informatizare a limbii romane, pentru determinarea structurii unui discurs, au fost folosite, cu predilectie, gramaticile de constituenti, desi gramaticile de dependenta puteau fi asociate unei anumite traditii.
Putem argumenta, pe linia clasicei taxonomii lingvistice - limbi analitice (engleza, germana etc.), limbi sintetice (romana, rusa etc.) -, ca o gramatica preocupata de identificarea dependentelor intre cuvinte ar fi mai potrivita pentru limba romana decat una independenta de context.
Modelele sintactice de dependenta sunt mai mult preocupate de cuvant decat de o categorizare abstracta a constituentilor prezentand, astfel, o adecvare computationala [4] mai mare decat gramaticile de constituenti. Un exemplu fericit pentru o astfel de abordare este proiectul "Prague Dependency Tree Bank" [5] prin care se intentioneaza adnotarea complexa a corpusului ceh. Faptul ca o gramatica de constituenti ofera un grad prea mare de granularitate a informatiei, materializata printr-un detaliu informational care nu este necesar unei aplicatii TTS nevoita sa reactioneze prompt, este altul din motivele care ne sugereaza alegerea unei gramatici de dependenta.
Acest tip de formalisme, devine din ce in ce mai utilizat, mai ales in cadrul unei abordari probabilistice a limbii, deoarece rezolva in mod direct, prin stabilirea relatiilor dintre cuvinte, una dintre cele mai mari dificultati intampinate de o gramatica de constituenti la parsarea propozitiei - informatia lexicala.
Renuntand la distinctia cuvant dominant - cuvant dependent, prezenta in structura de dependenta traditionala, rezulta o gramatica de constituenti la care fiecare regula introduce macar un nod terminal, putand folosi, astfel, rezultatele remarcabile obtinute prin utilizarea gramaticilor de constituenti probabilistice. Asemenea abordari ale unei gramatici de dependenta, cu legaturi nedirectionate, exista deja, una dintre ele fiind LinkGrammar [6]. Acest formalism permite, de asemenea, specificarea si a unor dependente intre dependente, cunoscut fiind faptul ca presupozitia independentei legaturilor dintre cuvinte nu are si acoperire practica.
4. Stadiul deducerii de reguli prozodice specifice diferitelor limbaje (colocviale sau de domeniu)
De mare importanta pentru modelarea vocii o are domeniul de care apartine textul. Paradoxal, mai dificila va fi modelarea vocii pentru limbajul colocvial decat pentru cele specifice, unde ne vom confrunta mai mult cu o insiruire de prescriptii.
Ramane insa problema formalizarii relatiei dintre sintaxa, semantica, pragmatica si prozodie. De asemenea, in aceeasi situatie problematica este si derivarea unui semnal vocal natural din modele prozodice abstracte. De aceea, nu este surprinzator faptul ca sistemele comerciale de sinteza TTS sunt atat de sofisticate lingvistic, preocupate mai mult de structura de suprafata a discursului decat de cea de profunzime. Rezultatul descriptiilor sintactico-prozodice organizeaza propozitiile intr-o ierarhiei de cel mult doua niveluri [7], dand seama doar de o dependenta intre propozitii, fara rafinarea acesteia.
Ca urmare, in cadrul demersului pentru determinarea aspectelor prozodice, avem nevoie si de o parsare de profunzime a textului. Vom beneficia de avantajul ca in cadrul sintetizarii TTS nu este foarte relevant gradul de complexitate a structurii discursului (de exemplu, citirea unui text stiintific nu implica intelegerea totala a informatiei transmise).
Doua sunt modalitatile prin care se poate extrage informatia la nivelul discursului. Parsarea bazata pe coeziunea textului are avantajul ca se mentine doar la un nivel lexical, putand fi usor reprezentata computational, desi necesita mecanisme complexe de dezambiguizare si de rezolutie a anaforelor. Coerenta textului folosita drept criteriu de parsare la nivel de discurs, desi greu de implementat computational (adnotarea structurilor retorice constituind o provocare chiar si pentru un subiect uman) prezinta avantajul unei reprezentari generale a unui fragment de text, reprezentare care poate fi formalizata cu ajutorul arborilor. Astfel, foarte importante pentru determinarea tonalitatii vocii (pitch, forma formantilor si corelarea lor - frecventele centrale ale formantilor, latimea lor de banda) sunt structurile retorice de contrast, elaborare, evaluare, exemplificare, explicare etc. In perspectiva unei astfel de abordari ar putea fi folosite, printre altele, cercetarile lui Daniel Marcu in domeniul rezumarii textelor, care demonstreaza practic posibilitatea adecvarii computationale a RST (Rhetorical Structure Theory) [8].
Nici unul din sistemele actuale de sinteza TTS nu este capabil sa genereze un semnal vocal care sa poata fi caracterizat ca natural sau placut auzului [9]. Dar aceasta imposibilitate de a accede la caracteristici ale limbajului proprii umanului nu este o tara singulara domeniului sintezei vocale. Dificultatea provine din accentul prea mare pus pe functia referntiala/informativa a limbii, fiind ignorate aspecte ce tin de manifestari asa-zis "paralele" ale limbajului, cum ar fi functia expresiva (de manifestare a emotivitatii, intentionalitatii vorbitorului) si functia apelativa (ce tine de performanta discursului si de continutul actional al unor enunturi).
Un demers ce-si propune imbunatatirea sintezei semnalului vocal pentru limba romana, pornind numai de la textul propriu-zis, nu poate acoperi toate aspectele mentionate mai sus. Dar chiar si implementarea doar a unora dintre acestea poate avea rezultate exceptionale la nivelul naturaletei semnalului vocal.
5. Elemente privind prozodia
Observatii privind definirea conceptului de accent
Constatarile facute in studiile anterioare si in continuare in cadrul acestei faze au fost surprinzatoare si ne-au determiant sa regandim problema accentelor. Surpriza a fost sa constat ca accentele sunt PERCEPUTE DIFERIT de diversi ascultatori. Concluzia noastra este ca accentele nu sunt un proces acustic, fizic, nici macar nu sunt un fapt al vorbirii, ci sunt un fapt al comunicarii, al relatiei lingvistice, semantice, emotionale etc. care se stabileste intre ascultator si vocea respectiva. 'Accentul' nu exista doar ca dat al vocii, ci se construieste din materia bruta a vocii de catre ascultator. Accentele, asa cum sunt uzual intelese si definite, nu exista. Vom putea deci vorbi de accent acustic si de accent interpretat.
Consecinte privind producerea sintetica a accentelor
Este iluzoriu ca un sistem de sinteza sa creeze "accente" in sensul determinist. Ceea ce putem spera este ca, pentru un set de ascultatori aflati intr-o anumita stare culturala, emotionala etc., semnalul vocal generat sa fie perceput ca avand un accent precizat. Vom discuta deci acei parametri acustici care permit ca un acccent acustic sa poata fi determinat de catre ascultator ca un anume accent interpretat.
Una dintre problemele dificile in
rezolvarea acestui grant a fost aceea de a accepta o definitie precisa pentru
"accent acustic". Din studiul literaturii se poate trage concluzia ca o asemnea
definitie nu este uniform acceptata de comunitatea din domeniu. Sintetizand
parerile cele mai des intalnite, putem spune ca accentul este dat de modificari
ale urmatorilor parametri: pitch, ![]() ; variablitatea fonemului, pentru o frecventa fundamentala
; variablitatea fonemului, pentru o frecventa fundamentala![]() precizata (
precizata (![]() ), durata fiecarui fonem; durata totala a unei silabe sau
cuvant; energia, E, durata pauzelor
dintre cuvinte.
), durata fiecarui fonem; durata totala a unei silabe sau
cuvant; energia, E, durata pauzelor
dintre cuvinte.
6. Principiul maximizarii integrarii contextuale si procesarea/adnotarea pentru accente
Dupa cum am subliniat in mai multe lucrari, este frecvent intalnita in literatura ideea ca accentele sunt dependente de contextual informational. A fost formulat in literatura pricipiul accentuarii informative, care afirma ca accentul este pus in asa fel incat sa maximizeze informatia dobandita de ascultator. Ulterior, s-a realizat ca acest principiu nu functioneaza decat in contextual unor intrebari directe, de exemplu: Cine a mancat inghetata (Ion sau pisica)? Pisica a mancat inghetata de ieri. Accentul in prima propozitie este pe cine, subiect si atrage accentual in a doua propozitie pe pisica, deoarece maximul de informatie dobandita de ascultator este prin precizarea subiectului mancator si nu prin aflarea actiunii - faptului ca obiectul (inghetata) a fost mancata - sau aflarea obiectului (inghetata) care a fost mancat sau aflarea timpului actiunii (de ieri).
Noi am facut o adaugire si clarificare la aceasta teorie, a accentului maximizator de informatie dobandita, adaugire legata de folosirea semnelor de punctuatie. Aceasta, cu atat mai mult cu cat, desi vom abandona ulterior principiul enuntat, ca functionand doar partial, vom pastra remarca facuta aici.
Desigur, daca ar fi fost important ca interlocutorul sa afle doua informatii, anume subiectul mancator si timpul actiunii, atunci propozitia ar fi necesitat un semn de punctuatie care sa atraga atentia asupra acestei duble informatii, cu dublu accent:
Pisica [accent principal, informatie de raspuns la intrebare directa] a mancat inghetata, de ieri [accent secundar, informatie suplimentara].
Mai multi autori au subliniat ca principiul maximizarii informatiei este pertinent numai in cazul intrebarilor directe si nu poate fi prelungit la alte tipuri de context, decat cu greu. Noi dorim sa amendam aceasta remarca pesimista, venind in sprijinul principiului enuntat, chiar daca ii gasim limitari si il inlocuim cu un principiu mai tare.
Primul amendament este ca maximizarea informatiei poate functiona in cazul intrebarilor implicite sau preliminate. De exemplu, vorbitorul prelimineaza o intrebare care ar putea veni din partea interlocutorului si atunci da doua raspunsuri - unul la o intrebare directa, altul la o intrebare preliminata. Vom relua exemplul anterior:
(A) - Ei, iar a fost mancata inghetata.(B) - Asa-i! (B) - Cine a mancat inghetata (Ion sau pisica)? (C) - Pisica a mancat inghetata, de ieri.
Aici, (B) se asteapta ca, daca raspunde doar "Pisica a mancat inghetata" sa i se puna intrebarea "cand si atunci furnizeaza deja raspunsul.
Un aspect la fel de important in stabilirea prozodiei (accentuarii) il reprezinta marcherii de discurs. Importanta marcherilor de discurs este bine cunoscuta din literatura de specialitate si nu vom insista asupra acestui aspect. Unele elemente teoretice privind marcherii si rolul lor sunt insa insificient clarificate; asupra lor vom atrage atentia mai jos.
7. Marcheri
Marcherii joaca un rol esential in determinarea accentului la conversia TtS. Marcherii de discurs se pot clasifica in mai multe categorii:
marcheri de stil de vorbire (de tip de document); de exemplu, de tip Biblic: Dumnezeu, sfant, Cel, Cel care, El
marcheri de enumerare
marcheri generali (de accentuare): insa, dar, dara, totusi,
marcheri interogativi: cum, care, cine, unde
marcheri copulativi: si, inca, si care, si cine, si cum etc.;
marcheri de diferentiere: dar care, dar ce, dar cum, dar cine etc.; dar unde, insa cum; insa ce etc; si totusi;
marcheri de continuare: si iarasi; si asa etc.;
Fisierul de marcheri arata ca in exemplele de mai jos. De notat ca fisierul de marcheri este diferit de la domeniu la domeniu. De exemplu, intr-un text de teologie, devin marcheri cuvinte precum "sfant", ce au un comportament de cuvant uzual in alte texte. Intr-un text (de exemplu de matematica), unii marcheri isi pierd comportamentul accentuant din alte domenii. Astfel, cuvantul "daca" are rol de marcher (de accent) in limbajul colocvial, pe cand intr-un text de logica sau de matematica capata un caracter de element constructiv oarecare al unui anume tip de fraza.
Tabelul 1. Exemple de marcheri
|
Marcheri prozodici simpli |
Marcheri prozodici compusi |
Marcheri specifici domeniului sau cu frecventa crescuta in anumite domenii de text |
|
Dar totusi insa nici chiar intotdeauna niciodata de asemenea (marcher simplu, format din 2 cuvinte) nu (in unele contexte) caci iata oare cum de (marcher simplu, format din 2 cuvinte) |
dar chiar dar si insa si si totusi nici daca nici chiar chiar si chiar daca chiar daca totusi dar niciodata pana nu si care si cum dar care tot nu asa cum |
sfant (texte religioase) amin (Biblia, texte religioase) caci (Biblia, frecventa crescuta) pana nu (Biblia, frecventa crescuta) |
|
|
|
|
|
|
|
|
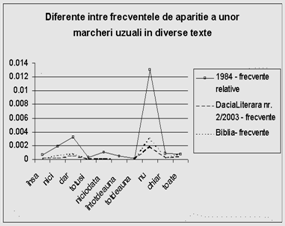
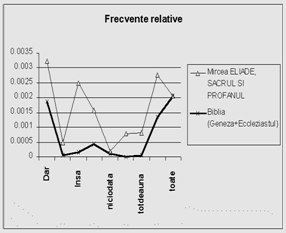
Figura 1. Frecvente relative ale unor marcheri in doua texte |
|
|
|
De remarcat ca pentru un domeniu dat, raportul frecventelor relative intre diversi marcheri poate fi mai importanta pentru determinarea domeniului, decat frecventele relative. Astfel, in general, in Eclesiastul, frecventele relative ale marcherilor sunt vizibil mai mici decat in alte texte analizate - cu o singura exceptie: marcherul "toate". Prin urmare, desi frecventa relativa a acestui marcher in Eclesiastul este egala cu cea din alte texte (de ex., la Mircea Eliade - Sfantul si Profanul), raportul
Frecventa relativa intermarcher (M)![]()
este diferit. Propunem deci ca un nou indicator al specificitatii textului (si ca un nou concept, introdus de titularul de grant) frecventa inter-marcher. Pe baza acestui indicator, Eclesiastul devine usor identificabil automat (text de domeniu specific), fata de lucrarea profana amintita mai sus.
Marcheri compusi; relatia dintre text, domeniu si statistica marcherilor
O problema care a aparut pe parcursul cercetarii si care a fost aprofundata, a fost aceea a marcherilor de discurs. Rezultatul analizei ne-a condus la mai multe concluzii de interes teoretic si la mai multe reguli de control al sintezei.
In primul rand, analiza facuta ne permite sa afirmam ca in limba romana apar ceea ce coordonatorul acestui grant a denumit "marcheri combinati". Acestia sunt formati din doi marcheri simpli, precum "dar" si "si" (dar si), "macar" si "daca" (macar daca), "dar" si "numai" (dar numai), "insa" si "daca" (insa daca) etc. Astfel de marcheri nu apar, sau, daca sunt permisi, sunt adesea evitati in unele limbi; pe cand in limbile romanice sunt acceptati. De exemplu, in limba engleza, "but also" "even if" etc. sunt acceptabili, dar nerecomandabili ca stil, pe cand in limba franceza "mais aussi" , "meme si" sunt acceptati. Am numit primul marcher, pe care consideram ca are un rol de intarire a celui de al doilea, "marcher-modificator", iar al doilea marcher "marcher principal". Regula pe care am dedus-o in scopul controlului sintetizorului este ca aparitia unui marcher compus (cu modificator) reprezinta un accent mai puternic al frazei. Mai notam ca exista si marcheri formati din trei elemente (cuvinte), anume un marcher compus (de exemplu, "chair si") folosit ca modificator pentru un al doilea marcher. Exemple sunt "chiar si daca", chiar si numai" etc.
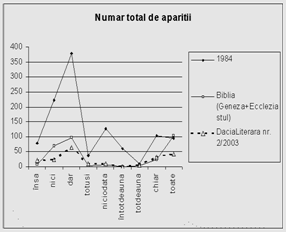
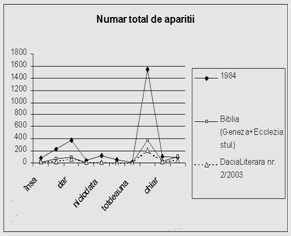
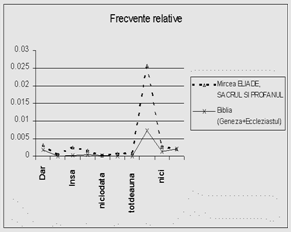
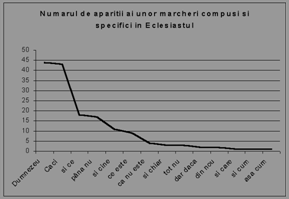
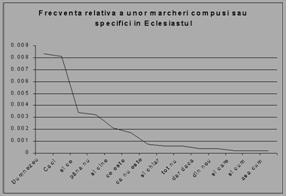
O a doua concluzie dedusa din analiza marcherilor este aceea ca acestia sunt folositi destul de diferit, pe de o parte, de la autor la autor, iar pe de alta parte, au o pondere discursiva diferita in unele domenii. Aceasta are o consecinta importanta: putem identifica (sau rejecta la identificare) unele domenii chiar si numai dupa statistica marcherilor din text. Aceasta este o concluzie favorabila vitezei de procesare a textului in vederea sintezei. Intr-adevar, reamintim ca identificarea marcherilor este o etapa necesara, deci realizarea suplimentara a statisticii marcherilor nu va mai fi atat de consumatoare de timp. In figurile de mai jos, ilustram statisticii ale unor marcheri.
|
|
|
|
|
|
Figura 2. Detalii privind frecventele relative ale unor marcheri de discurs, in diverse texte
Se constata din graficele anterioare ca marcherii de prozodie/ideatie nu sunt doar destul de diferiti, ca frecventa de aparitie, de la un text la altul, de la un domeniu la altul, ci reprezinta, prin insasi aceasta diferentiere, un bun mod de depistare a domeniului din care face parte textul (presupus a nu fi clasificat, ca domeniu).
O exemplificare a pronuntiei diferite, functie de interpretare, este ilustrata mai jos.
Trei pronuntii diferite ale aceleiasi fraze
|
"ai mei", pronuntie normala (S: Gabi) |
|
|
|
|
|
|
|
|
"ai mei", pronuntie afirmativa (S: HN) |
|
|
|
|
|
|
|
|
|
Figura 3
O a doua ilustrare a modificarilor de accent este ilustrata mai jos pentru cazul marcherilor compusi.

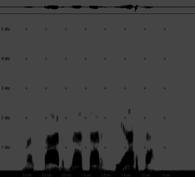

Figura 4. Sonograme pentru "macar daca ar fi asa", cu accente pentru "macar", "daca", sau fara accent.
Caci ___ , nu ___ .
Nu ___ , si nu ___ .
___ , nu ___ , si ___ , nu ___ .
___ , dar ___ .
___ , si ___ .
___ si ___ si ___ , caci ___ .
Dar ___ , si ___ , si___ , (aceasta) este ___ .
Caci nu ___ , daca (de vreme) ___ .
Caci chiar daca ___ , ce [utilitate] ___ .
Mai mult ___ decat , si ___ decat ___ .
Mai bine/bun ___ decat ___ , caci ___ , si [ V. pozitiv] ___ , [V negativ] ___ .
Mai bine ___ decat ___ , caci ___ , si [V pozitiv] ___ , [V negativ ] ___ .
Mai bine ___ , decat ___ caci ___ si ___ .
[Subst pozitiv] [ V negativ] ___ si [ Subst +] [ V -] ___.
8. Adnotarea la nivel fonetic
In literatura, printre parametrii care sunt "adnotati" se numara, la nivel fonetic:
variatia (traiectoria, "conturul") frecventei de baza (excitatiei, pitch-ului, formantul F0)
variatia (traiectoria) formantilor 1, 2, 3 si eventual superiori (F4, F5)
variatia latimii formantilor (fisier separat; nu se practica uzual, desi este utila in sinteza)
variatia (conturul) energetic
variatia NTZ (numarului de treceri prin zero; util in special in recunoasterea vorbirii)
segmentarea la nivel fonemic
evidentierea traseelor vocalice si nevocalice
transscrierea (transcriptia in alfabetul fonetic)
segmentarea la nivel silabic
segmentarea la nivel de cuvant
adnotarea accentelor primare si secundare
adnotarea caracteristicilor emotionale
determinarea alinierilor in timp, pentru pronuntii multiple
Fata de aceasta situatie, care este si redundanta si prea prolifica pentru aplicatia noastra, noi am ales o adnotare specifica pentru accente, descrisa mai jos. Printre fisierele adnotate, se numara Cartea 21. Ecclesiastul, Biblia ortodoxa (domeniu 'religios-ortodox') si Al. Husar, Misiunea culturala (I), Dacia Literara nr. 2, 2003 (domeniu 'publicistic').
Instrumente si standarde
In alegerea instrumentelor flosite, s-a tinut cont de necesitatea de a asigura o anume generalitate si portabilitate a rezultatelor si instrumentelor dezvltate de noi. Inca de la inceputul cercetarii, am ales utilizrea fisierelor de tip XML, tinand cont de tendinta de stabilire a unor standarde precum Coice-XML. Instrumentele folosite in adnotarea textelor au fost:
Adnotarea folosita este derivata din standardul TEI (Text Encoding Initiative). Aceasta alegere este justificata de necesitatile de portabilitate.
9. Reguli de prozodie
Regulile concrete se refera la semne de punctuatie si marcheri (premisele reguilii presupun existenta unui singur asmenea indicator prozodic), precum si la consecintele pentru variatia formantului F0 si a pauzelor (in concluziile regulilor). Aceste reguli au fost stabilite in forma generala de titular si au fost particularizate in cadrul discutiilor in colectiv. Exemplificari ale acestor reguli sunt prezentate in tabelul de mai jos. De notat ca exista o anume ordine de aplicare a regulilor (o ascendenta a unor reguli fata de altele).
|
Regula nr. |
Premisa |
Consecinta |
Ordinea de aplicare |
|
|
Adnotarea intonatiei generale a propozitiei |
Semnul de punctuatie terminal ('.', '?', '!') este adnotat cu atributele pitch='low'/'high' si edge='final' Cuvantul de inceput de propozitie este adnotat cu pitch='high'/'low' si edge='start'. |
|
|
|
Adnotare semn de punctuatie intermediar |
Cuvantul de dupa semnul de punctuatie intermediar este adnotat cu pitch='high' si edge='inter'. Cuvantul de dinaintea semnului de punctuatie este adnotat cu pitch='low' si edge='inter' daca nu este situat imediat dupa un alt semn de punctuatie. |
|
|
|
Adnotare marcheri |
Cuvantul cu rol de marcher aferent domeniului este adnotat cu pitch='high' |
|
|
|
Adnotare intonatie descendent interogativa |
Pronumele interogative de la inceput de propozitie sunt adnotate cu pitch='high' si edge='start' iar semnul de punctuatie '?' cu pitch='low' si edge='final' |
|
Interfata fisier adnotat XML-sintetizor
Interfata intre fisierele XML si fisierele text este constituita de functii de citire XML si transformare in text. Functiile au fost realizate in Visual C 6.0.
Figura 5. Niveluri de adnotare
3. Dependente de prozodie
3.1. Tipar intonational preponderent descendent
3.1.1. Cuvant dominant '.'; cuvant dominat ','
3.2. Tipar intonational preponderent ascendent
3.3. Tipar intonational parentetic
3.4. Tipar intonational emfatic
4. Tonalitate.
Acesta consta in etichete pentru elemente distinctive ale fundamentalei transpuse intr-o secventa de tonalitate inalta <HIGH> sau joasa <LOW> marcata cu atribute speciale indicand functia lor intonationala. Acestea figureaza fie ca parte a accentelor tinand de frecventa fundamentala sau ca intonatie a propozitiei (demarcand unitati prozodice).
Relatia acestui nivel intonational cu nivelul ortografic poate fi consemnata relativ cu miscarile frecventei fundamentale in vecinatatea silabelor accentuate si a marginilor a doua tipuri de segmente (la limitele secventelor intermediare si la extremele propozitiei). Aceste relatii sunt indicate cu ajutorul atributelor urmatoare:
<LOCATION> cu valorile:
<ON> pentru tonalitate (inalta sau joasa) pe silaba accentuata
<NEAR> pentru tonalitate (inalta sau joasa) langa sau pana in silaba accentuata
<EDGE> cu valorile
<INTER> pentru marcarea marginii unei secvente intonationale intermediare
<FINAL> pentru marcarea marginii unei secvente intonationale
5. Pauze
Nivelul pauzelor reproduce gruparea prozodica a cuvintelor dintr-o rostire prin marcarea, la sfarsitul fiecarui cuvant, a coeziunii cu cuvantul urmator. Marcarea este facuta pe o scara valorica de la 0 (pentru cea mai puternica coeziune perceputa) la 4 (pentru cuvinte disjuncte).
9. Concluzii
Metodele puse la punct in cadrul acestui grant au permis imbunatatirea calitatii sintezei vocale la un sintetizor Klatt prin introducerea unor elemente de prozodie specifice domeniului de discurs. Parte din metode si rezultate sunt originale, iar parte din rezultate constituie adaptari, dupa literatura internationala, la specificul limbii romane. Reguli mai complexe de determinare a acentelor in fraza si de adnotare a textului ne-au permis demonstrarea unor imbunatatiri spectaculoase ale sintezei vocale si transferarea rezultatelor noastre pentru preluare de catre alte colective.
Acest text nu trebuie considerat un text definitiv, sau o lucrare in sensul uzual al cuvantului; el reprezinta doar o trecere in revista a unora dintre elementele tratate in cercetarea raportata. O expunere mai metodica se poate gasi in lucrarile publicate.
Lucrari publicate sau comunicate in legatura cu grantul
Teodorescu H.N.: Interrelationship, Communication, Semiotics, and Artificial Consciousness. In: Kitamura, T. (Ed.): What Should be Computed to Understand and Model Brain Functions? FLSI Book Series, vol. 3, World Scientific, 2000
Dan Cristea, H.N. Teodorescu, Dan-Ioan Tufis, Student Projects in Language and Speech Processing. Language Resources: Integration and Development in e-learning and in teaching Computational Linguistics. International Workshop preceding LREC 2004, 4th International Conference on Language Resources and Evaluation, Lisbon, Portugal - 24th May 2004. https://nats-www.informatik.uni-hamburg.de/view/Main/AcceptedPapers. LREC 2004 Fourth International Conference on Language Resources and Evaluation. Workshop on Language Resources: Integration and Development in e-Learning and in Teaching Computational Linguistics, pp. 17-22.
Horia-Nicolai Teodorescu, Vasile Apopei, Doina Jitca, Implementation of stress and emotion rendering rules in synthesized speech. The 3rd Conference on Speech Technology and Human - Computer Dialog, "SpeD 2005", Technical University of Cluj-Napoca Cluj-Napoca, May 13-14, 2005
Horia-Nicolai Teodorescu, Metode de caracterizare calitativa a interfetelor vocale, ECIT2004, Conferinta ECIT2004, Iasi, 20-24 Iulie 2004
Horia-Nicolai Teodorescu, Calitatea Interfetelor Vocale, INVENTICA2004, Iasi, Mai 2004
Vasile Apopei, Doina Jitca, Florin Grigoras, Modeling Formantic Transitions in Klatt Speech Synthesizer. ECIT2004, Iasi, 20-24 iulie 2004
Alexandru Ceausu, Andrei Ciubotaru, Improved text auto-completion for mobile devices, Simpozionul EEA, Pitesti, 3-4 iulie 2004
Horia Nicolai Teodorescu, Alexandru Ceausu, Vasile Apopei, Imbunatatirea aspectelor prozodice in sinteza text-to-speech pentru limba romana. Revista de Inventica, nr. 4/2003
Alexandru
Ceausu, Tehnici de identificare a colocatiilor.
Aplicatia N-gram. Revista de Inventica (nr. 41 / vol VIII / an XIII - 2003),
pp. 23-28
H.N. Teodorescu, C.B. Branzila, Analysis of the Dynamics of the Words in the Romanian and English Languages, CD-Proc. ATM2003 6-7 Nov. 2003, pp. 239-246
Alexandru Ceausu, Specificatii XML pentru sinteza text-to-speech. CD-Proceedings Simpozionul de Sisteme Inteligente SIA 2003, Iasi, Sept. 2003, Eds. H.N. Teodorescu, C. Gaindric, E. Sofron. Ed. Tehnici si Tehnologii, Iasi, 2003
Dan Cristea, H.N. Teodorescu, Dan-Ioan Tufis, Student Projects in Language and Speech Processing. Language Resources: Integration and Development in e-learning and in teaching Computational Linguistics. International Workshop preceding LREC 2004, 4th International Conference on Language Resources and Evaluation, Lisbon, Portugal - 24th May 2004. https://nats-www.informatik.uni-hamburg.de/view/Main/AcceptedPapers. LREC 2004 Fourth International Conference on Language Resources and Evaluation. Workshop on Language Resources: Integration and Development in e-Learning and in Teaching Computational Linguistics, pp. 17-22.
Horia-Nicolai Teodorescu, Vasile Apopei, Doina Jitca, Implementation of stress and emotion rendering rules in synthesized speech. The 3rd Conference on Speech Technology and Human - Computer Dialog, "SpeD 2005", Technical University of Cluj-Napoca Cluj-Napoca, May 13-14, 2005
Vasile Apopei, Doina Jitca, Florin Grigoras, Modeling Formantic Transitions in Klatt Speech Synthesizer. ECIT2004, Iasi, 20-24 iulie 2004
|

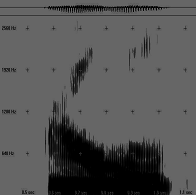
 "ai mei", pronuntie mirare (S: Gabi)
"ai mei", pronuntie mirare (S: Gabi) 
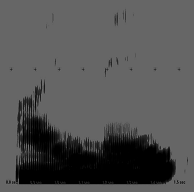
 "ai mei", pronuntie mirare (S: HN)
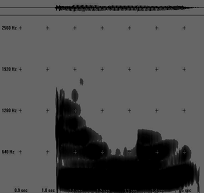
"ai mei", pronuntie mirare (S: HN) "ai mei", pronuntie normala (S: mpferm)
"ai mei", pronuntie normala (S: mpferm)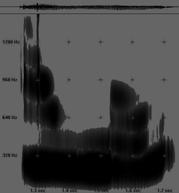 "ai mei", pronuntie
afirmativa (S: mpferm)
"ai mei", pronuntie
afirmativa (S: mpferm)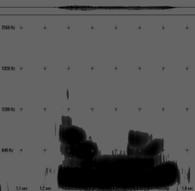 "ai mei", pronuntie mirare (S: mpferm)
"ai mei", pronuntie mirare (S: mpferm)