Data manipulation
8.1. - Internal and external data
8.2. - Data transfer
8.3. - Procedural data processing
8.3.1. - Procedure control structures
8.3.2. - Navigation in relational data structures
8.3.1.1. - GO TO
8.3.1.2. - SKIP
8.3.1.3. - SCAN
8.3.1.4. - SEEK
8.3.3. - Data base updating commands
8.3.3.1. - APPEND / INSERT
8.3.3.2. - DELETE
8.3.3.3. - REPLACE
8.3.4. - INPUT / OUTPUT commands
8.3.5. - Macrosubstitution
8.3.6. - Procedures and functions
8.3.6.1. - Variables extension
8.3.6.2. - Call by VALUE and by REFERENCE
8.3.6.3. - Recursion
8.3.7. - System functions
8.3.8. - Parameters setting
8.4. - The Relational Algebra
8.4.1. - Structured Query Language (SQL)
8.4.2. - The SELECT command
8.4.3. - The correspondence between the NAVIGATION language and the RELATIONAL ALGEBRA operators
8.5 - Nonprocedural data processing
8.5.1. - Structured Query Language (SQL)
8.5.2. - The SELECT command
8.6. - RECURSIVE structures
8.6.1. - RECURSIVE data structures
8.6.2. - RECURSIVE procedure structures
8.1. - Internal and external data
In a DBMS the Database Fields represents the external data and the internal data are represented by the Memory Variables.
The Memory Variables are only accessory data for construct procedures and not elements of data structures. For this reason the interest related to the Memory Variables are focused only to the transfer of data between external and internal memory and vice - versa.
8.2. - Data transfer
The most important transfer of data is focused on the READ command. The READ command acts in relationship with a DATA LIST. In this list there are specified by the user the INPUT and OUTPUT fields. The declaration of this fields are made with two auxiliary commands:
the @ . SAY . - command used to declare the OUTPUT fields ( only once when the READ is first executed )
the @ . GET . - command used to declare the INPUT fields when they are enabled
command used to declare the OUTPUT fields when they are disabled
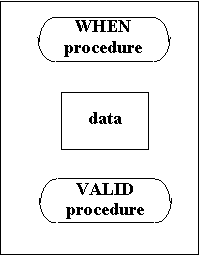
Fig. 10. - The main structure of a data field viewed as an OBJECT
Each field in this set of fields has an OBJECT ORIENTED structure. This means that each field has associated two kind of information:
information about the data structure
information about the associated procedures
The information about the data structure contain:
the name of the input data as a memory variable < var >
the expression for the output data < expr >
the data type derived from the < var > or < expr > type
the screen or print position < row, column >
the displayed and editing format - clause 515h73f s PICTURE and FORMAT
the color scheme - clause COLOR SCHEME
the data size - clause SIZE
the data range -
the default value for on input data - clause DEFAULT
an explanation message about the data semantic - clause MESSAGE
the input data state ( enable or disable for editing ) - clause ENABLE | DISABLE
The information about the associated procedures contain:
the procedure that allows or prohibits editing input data - clause WHEN
the procedure that validates the input value for a data - clause VALID
the displayed error message - clause ERROR
The syntax of the SAY / GET command is given below:
< row, column >
SAY < expr1 >
[ PICTURE < expC1> ]
[ FUNCTION < fcodes1 > ]
[ COLOR SCHEME < expN1 > ]
GET < var >
[ PICTURE < expC2 > ]
[ FUNCTION < fcodes2 > ]
[ COLOR SCHEME < expN2 > ]
[ DEFAULT < expr2 > ]
[ ENABLE | DESABLE > ]
[ MESSAGE < expC3 > ]
[ RANGE [ expr3 ] [ , <expr4 > ]
[ SIZE < expN3 > < expN4 > ]
[ VALID < expL1 > < expN5 > ]
[ ERROR < expC4 > ]
[ WHEN < expL2 > ]
Description:
Use this command to display formatted output on the screen or in a window, to create input screens or to format output for the printer.
Clauses:
< row, column >
< row > and < column > are numeric expressions that determine where output will appear
SAY < expr1 >
< expr1 > is evaluated and displayed starting at < row > and < column >. < expr1 > can be a USD ( User Defined Function ).
if SET DEVICE TO SCREEN has been issued output appears on the screen
if SET DEVICE TO PRINTER has been issued output is directed to the printer
PICTURE < expC1> | FUNCTION < fcodes1 >
When creating a SAY field or a GET field you can include special codes that control how < expr1 > is displayed or how < var > is edited. FUNCTION codes can be included in a PICTURE clause. In this case the PICTURE clause must start with @.
FUNCTION Codes:
A - allows alphabetic character only
B - left justified numeric data within the output field
E - edits date type as BRITISH date
I - centers text within the fields
J - right justified text within the field
S <n> - limit display width to n character
! - any character can be entered
PICTURE Codes:
A - allows alphabetic character only to be entered
L - allows logical data only
N - allows letters and digits only
X - allows any character
9 - allows digits only
. - specifies the decimal position
, - separate digits left of the decimal point
! - converts lower-case to upper-case
[ COLOR SCHEME < expN1 > ]
You can override the current color scheme by specifying a pre-defined color scheme
GET < var >
Places an editing field on the screen or active window.
[ DEFAULT < expr2 > ]
If the < var > memory variable does not exist, it is automatically created and initialized with < expr2 >.
[ ENABLE | DISABLE > ]
Including DISABLES prevents access and changes to a GET field. The field is displayed in the disables colors and the field can not be selected. By default GET fields are enabled.
[ MESSAGE < expC3 > ]
The message < expC3 > is displayed on the last line of the serene, when you position the cursor in the GET field. This message can contain explanations about the input field.
[ RANGE [ expr3 ] [ , <expr4 > ]
Specify the limits of acceptable data values. If the value entered is not within the specified range ( lower bound - expr3 or upper bound expr4 ), a message showing the correct range is displayed.
[ SIZE < expN3 > < expN4 > ]
This clause lets you to control the size of the GET field - both the length < expN3 > and the height < expN4 >.
[ VALID < expL1 > < expN5 > ]
VALID permits validation of input. You can use a snippet of source code or a UDF. The value data is considered incorrect if < expL1 > evaluates false. A message is displayed directing you to reenter the data after pressing Space bar.
[ ERROR < expC4 > ]
< expC4 > lets you to specify a custom error message to be issued when Valid clause evaluates false.
[ WHEN < expL2 > ]
WHEN allows or prohibits editing of GET fields based on the result of < expL2 >. < expL2 > must evaluate true before the cursor can move into the field for editing. If not input is not allowed, the GET field cannot be accessed and the cursor moves to the next GET field.
READ
[ CYCLE ]
The READ command activates objects created with @ . GET commands. When the READ is issued, you may press ENTER, TAB or DOWN arrow to move forward from object to object. Press SHIFT + TAB or the UP arrow to move backward from object to object. Movements from object to object takes place in the order the GET-s were issued.
Entering Data: When you move into a GET field you may enter or editing text. Standard text editing features are available in a GET field.
Exiting the READ: READ can be exited in several ways:
moving forward past the last GET field, or backward past the first field ( if the CYCLE clause isn't included with READ )
pressing ESCAPE or CTRL+W
If CYCLE is included, READ is not terminated when you move forward past the last object or backward past the first GET object. You will be repositioned on the first or last GET object. The terminating buttons, the CLEAR READ command or the TIMEOUT clause will all terminate the READ.
SHOW GETS
SHOW GETS redisplay all GETS objects. When values of GET fields change (you have moved to a new record, for example) SHOW GETS updates the values of the GET fields.
Example:
Lets consider a relation TEACHER (code, name) that is indexed on code. The following program permits:
to read a code
to search for the appropriate tuple
to display the name
clea
sele test
@ 1,10 say 'Code :' get m.cod DEFA '1' VALID f1(m.cod)
@ 1, 20 get name disa
read cycl
func f1
para m.code
seek m.code
if found()
show gets
retu .T.
else
retu .F.
endi
retu
8.3. - Procedural data processing
A procedural data processing consists of a sequence of commands that build a program. This program can be edited, compiled, stored in a file and executed in a source version (.PRG), a compiled version ( .FXP ), an application version ( .APP ), or an executable version ( .EXE ).
8.3.1. - Procedure control structures
The procedure control structures help the user to build application using Structured Programming. These commands and functions are used to control program execution and branching within a program. The specific forms of the main structures are:
for the BLOCK structures:
the PROCEDURE structure :
PROCEDURE < procedure name >
statements
RETURN
The PROCEDURE < procedure name > specifies the beginning of each procedure in a program and identifies the procedure by name. This statement is followed by a series of commands that make up the procedure. You may optionally include RETURN as the last line of a procedure although an implicit RETURN is automatically executed following the last statement of a procedure.
When a procedure is executed with DO < procedure name >, the procedure is searched for in a specific order:
in the file containing the DO statement
in the file opened with SET PROCEDURE TO < file name >
in the programs in the execution chain (from the most recently executed program through the first executed program)
in the directory for a stand alone program file with the same name as the invoked procedure
DO IN < file name > searches only the named file.
the FUNCTION structure :
FUNCTION < function name >
statements
RETURN
The same remarks that were be made at the procedure are available also for the function.
for the SELECTION structures:
SIMPLE SELECTION
Normal IF
IF < expL >
statements
[ ELSE
statements ]
ENDIF
This structured programming command is based on a condition represented by <expL>. Ifs may be nested within one another provided that each IF has a matching ENDIF.
Immediate IF
IIF ( < expL > , < expr1 > , < expr2 > )
The IIF command returns one for the two expressions depending on the value of a logical expression. If the logical expression is evaluated:
true the first expression is returned
false the second expression is returned
IIF-s may be nested within one another because the IIF function is an expression and therefore it can be used as < expr1 > , or <expr2 >.
This function is especially useful in report or label expressions to conditionally specify field contents. From this point of view the IIF function represent a successfully transformation of a PROCEDURE into a DATA.
The IIF function also executes considerable faster that the equivalent IF statement.
MULTIPLE SELECTION
DO CASE
CASE < expL1 >
statements
[ CASE < expL2 >
statements
OTHERWISE
statements ]
ENDCASE
Executes a set of commands based on a logical condition. The successive logical CASE-s are evaluated and the result of the evaluations determine which set of commands (if any) are executed. The execution of the statements continues until the next CASE or ENDCASE is reached. The execution then resumes with the first command following ENDCASE. One and only one CASE will be executed - the first true CASE. If OTHERWISE is included and neither of the condition is true the statements following OTHERWISE are executed.
for the REPEAT structures :
GENERAL FORM
DO WHILE < expL >
statements
[ EXIT ]
[
[ statements ]
ENDDO
Executes commands inside a loop while a logical condition remains true. As long as < expL > remains true the set of statements placed between DO WHILE and its matching ENDDO are executed.
EXIT transfer control outside of the loop.
FOR < memvar > = < expN1 > TO < expN2 > [ STEP < expN3 > ]
statements
[ EXIT ]
[
[ statements ]
ENDFOR | NEXT
Executes a set of statements in a loop a specified number of times. A memory variable < memvar > is used as a counter to determine how many times the statements inside the loop will be executed:
< expN1 > is the initial value of the counter
< expN2 > is the final value of the counter
< expN1 > is the STEP of the counter increment
relational SPECIFIC FORM (related to a set of tuples in a relation):
SCAN [ scope ] [ FOR < expL1 > ] [ WHILE < expL1 > ]
statements
[ EXIT ]
[
[ statements ]
ENDSCAN
SCAN moves through a database file and performs the < statements > for each record that meets the specified conditions. SCAN automatically advances the record pointer to the next record and then tests for the specified conditions.
Only the records that fall within the range of records specified by the scope are scanned.
If FOR is included, the statements are executed for all records within the < scope > for witch < expL1 > is true.
If WHILE is included, the statements are executed for the records within the < scope > as long as < expL2 > remains true.
- Navigation in relational data structures
8.3.2.1. - GO TO
GO | GOTO < expN >
GO | GOTO TOP | BOTTOM
The GO or GOTO commands position the record pointer on a specified record in the currently selected database file.
TOP and BOTTOM specified the BEGIN or END of the DBF.
8.3.2.2. - SKIP
SKIP < expN >
The SKIP command moves the record pointer in the currently selected database file:
if < expN > is a positive number, the record pointer moves towards the end of the file < expN > records
if < expN > is a negative number, the record pointer moves towards the beginning of the file < expN > records
By default < expN > is equal to 1.
If the record pointer is positioned on the last record in the DBF and a SKIP is executed:
RECNO () evaluates to one record greater then the last record in the DBF
EOF () is true
If the record pointer is positioned on the first record in the DBF and a SKIP -1 is executed:
RECNO () evaluates to 1
BOF () is true
8.3.2.3. - SEEK
SEEK < expr >
The SEEK command searches an indexed DBF for the first occurrence of a record whose index key expression matches < expr > . The match must be exact unless SET EXACT is OFF.
If SEEK finds a matching record:
RECNO () will return the record number of the matching record
FOUND () will return true
EOF () will return false
If SEEK doesn't find a matching record and SET NEAR is OFF:
RECNO () will return the number of records in the DBF plus one
FOUND () will return false
EOF () will return true
If SEEK doesn't find a matching record and SET NEAR is ON:
RECNO () will return the number of the closest matching record in the DBF plus one
FOUND () will return false
EOF () will return true
SEEK ( < expr > )
The SEEK () function searches an indexed DBF for the first occurrence of a record whose index key expression matches < expr > .
If SEEK () finds a matching record:
RECNO () will return the record number of the matching record
SEEK () will return true
EOF () will return false
If SEEK () doesn't find a matching record and SET NEAR is OFF:
RECNO () will return the number of records in the DBF plus one
SEEK () will return false
EOF () will return true
If SEEK doesn't find a matching record and SET NEAR is ON:
RECNO () will return the number of the closest matching record in the DBF plus one
SEEK () will return false
EOF () will return true
SEEK () replaces a combination of SEEK and FOUND ().
8.3.3. - Data base updating commands
The update commands were be presented in the section that refers the relational model. In FoxPro programming environment we dispose by the following update commands:
- APPEND / INSERT - witch is used for adding tuples to a relation (a table)
- DELETE - witch is used for remove tuples from a relation (a table)
- REPLACE - witch is used for modify attributes (fields) in tuples of a relation (a table)
8.3.4. - INPUT / OUTPUT commands
ACCEPT [ expC ] TO < memvar >
Accepts character string data from screen directly into a memory variable. No quotation marks are required around the character data.
If the optional [ expC ] string is included, it acts as a prompt and precedes the data entry position.
? | ?? [ < expr1 > ] [ , < expr2 > ] . AT < expN >
Evaluates expression and
displays results on the screen, on the printer or both the screen and the
printer depending on the setting commands SET PRINTER ON | OFF and SET
Clause ? - causes a CARRIAGE RETURN and a LINE FEED to be sent before the result of the expression. This causes the output to be displayed on the next line of the screen or the printer. If no expression is specified, a blank line is displayed or printed. A comma placed between the expressions <expr1> and < expr2 > automatically separates the expressions with spaces.
Clause ?? - displays the results on the current line at the current position of the screen or the printer ; no CARRIAGE RETURN and LINE FEED pair is sent.
Clause AT < expN > - can be used to specify the column number < expN > where the output will be displayed.
8.3.5. - Macrosubstitution
& < memvar >
When the & function precedes a character type memory variable, macro substitution is performed with the memory variable. Macro substitution treats the content of the memory variable as a character string literal. You can use macro substitution in any command or function that accepts a character string literal. With macro substitution, you can prompt for information and then use the information as part of a command or function that requires a literal string. The macro should not exceed the maximum length permitted - 255 characters. Whenever possible, use a name expression instead of macro substitution because a name expression provides significantly faster processing.
Macro substitution statement that appear in structured programming REPEAT commands ( DO WHILE , FOR ), are evaluated only at the start of the loop and are not reevaluated on subsequent iteration, Any change to the < memvar > which take place within the loop are not recognized.
Example:
function F1
para a,b
retu (a+b)
d=4
e=5
n='F1(d,e)'
The result : n=9
8.3.6. - Procedures and functions
The commands can be grouped in procedures and functions. (For the syntax of the procedure and function declaration see the chapter Control Structure). The main difference between a procedure and a function consist in the following:
a procedure is viewed as a SET OF STATEMENTS that are executed during the procedure calling
a function is viewed as a DATA and namely the returned data
From this reason a function must be used in a place of a data or must be preceded by a command. If you want to use a function as a procedure you must invoke them with:
= < function name >
8.3.6.1. - Variables extension
In the X-BASE programming language a variable can be:
SIMPLE variable
if this is a SCALAR it does not be declared but only assigned
if this is an ARRAY its dimensions must be declared with the command:
DIMENSION < array1 > ( < expN1 > [ , ( < expN2 > ] )
< array2 > ( < expN3 > [ , ( < expN4 > ] ) .
One- or two-dimensional arrays of memory variables can be created with this command. DIMENSION is identical in operation and syntax to DECLARE.
Multiple arrays can be created with a single DIMENSION command by including additional array names.
The meaning of the clauses:
< array1 > - the array name
< expN1 > - the row number ( the array SIZE )
< expN2 > - the column number ( the array DIMENSION )
Array elements can contain any type of data.
Elements in an array are referred to by their subscripts that are enclosed in round brackets.
An array can be dynamically re-dimensioned because you can change the size and dimensions of an array by using DIMENSION again. The size of an array can be increased or decreased, one-dimensional arrays can be converted to two dimensions and two-dimensional arrays can be reduced to one dimension.
The extension of the SIMPLE variables is represented by the procedure in that the variables are declared or assigned and all the called procedures in the call branch of the call tree.
PUBLIC variable
To declare a PUBLIC variable, named also a GLOBAL variable you must use the command:
PUBLIC < memvar list >
PUBLIC < array1 > ( < expN1 > [ , ( < expN2 > ] )
< array2 > ( < expN3 > [ , ( < expN4 > ] ) .
Public variables and array can be accessed and modified from any program that you execute during the current working session.
Any variables and array created in the COMMAND window is automatically public.
Any variables and array you wish to declare as PUBLIC must be such declared prior to assigning them a value.
PRIVATE variable
To declare a PRIVATE variable, named also a LOCAL variable you must use the command:
PRIVATE < memvar list >
PRIVATE ALL [ LIKE < skel > | EXCEPT , skel > ]
< skel > - indicates a subset of memory variables that match the skeleton witch can contain the wild characters ? and *
PRIVATE hides variables and arrays defined in a previously executed program from the current program. The hiding of variables created in higher-level programs allows variables of the same name as the private variables to be manipulated without affecting the value of the hidden variables. Once the program containing PRIVATE has completed execution, all memory variables made private are again available.
REGIONAL variable
A REGIONAL variable can be declared within a specified REGION of the program. To declare a REGION of a program you must use the compiler directive:
REGION < number >
To declare the REGIONAL memory variables you must use the command:
REGIONAL < memvar list >
A variable's name is made unique automatically by the compiler, by padding the regional variable's name out to 10 characters with underscores and the current region number.
8.3.6.2. - Call by VALUE and by REFERENCE
To defines memory variables as parameters you must use the command :
PARAMETERS < parameter list >
Parameters within < parameter list > are separated by commas.
PARAMETERS assign data passed from a calling program to local memory variables or arrays. When included, PARAMETERS ( ) must be the first executable statement in the called program.
The data passing is made by default as follows:
for the PROCEDURES - variables are passed by REFERENCE - when the value is changed in the called procedure, the change is passed back to the variable in the calling procedure
for the FUNCTIONS - variables are passed by VALUE - any changes made to the parameters will not be passed back to the calling procedure or function
You can change this mode of data passing in the following way:
for the PROCEDURES - variables are passed by VALUE - if the variables are enclosed in round brackets
for the FUNCTIONS - variables are passed by REFERENCE - if the SET UDFPARMS TO REFERENCE is issued
The function PARAMETERS ( ) will return the number of parameters that were passed to the last routine.
- The Relational Algebra
The Relational Algebra is a collection of operations that are used to manipulate relations. This set of operations has the following properties:
the operations manipulate entire relations
the result of each operation is a new relation
the result can be further manipulated
the operations are used to:
retrieve attribute values from relation tuples
update attribute values in relation tuples
* INSERT tuples in relations
* DELETE tuples in relations
* UPDATE attribute values in tuples
The relational algebra operations are divided into two groups:
traditional operators - set operations from mathematical set theory
UNION - mnemonic -
INTERSECTION - mnemonic - INTERSECT
DIFFERENCE - mnemonic - MINUS
CARTESIAN PRODUCT - mnemonic - TIMES
standard relational operators
SELECTION - mnemonic - SELECT
PROJECTION - mnemonic - PROJECT
JOIN - mnemonic - JOIN
DIVISION - mnemonic - DIVIDE
- The Traditional Operators
The first three operators are binary operators on two sets and imply the constraint of UNION COMPATIBILITY on the two relations. To be UNION COMPATIBLE two relations must satisfy the following condition:
to be defined on the same domains
the order of the domains must be the same
UNION -
mnemonic -
Is used to define a relation that contains the union of the tuples from two relations. The general form of the UNION operation is:
( <relation name 1>) ( <relation name 2>)
where:
denote the UNION operator
The UNION operator has the following properties:
is a binary operator
is commutative
the result contain all the attributes related to the common domains
the degree of the result relation is the same of the original relations
the result will contain tuples that exist in the first or in the second relation
duplicate tuples will be removed from the result
the number of tuples in the result is less than or equal to (n + m) where n is the number of tuples in relation 1 and m is the number of tuples in relation 2
Example 1:
s ( Group='2041' ) (STUDENT)) s (Group='2042') (STUDENT))
The same result can be obtained more simple with:
s ( Group='2041' or Group='2042' ) (STUDENT))
Example 2:
p ( Name, Surname) (STUDENT)) p ( Name, Surname) (TEACHER))
In this case the expression can't be rewritten.
INTERSECTION - mnemonic - INTERSECT
Is used to define a relation that contain the intersection of the tuples from two relations. The general form of the INTERSECT operation is:
( <relation name 1>) ( <relation name 2>)
where:
denote the INTERSECT operator
The INTERSECT operator has the following properties:
is a binary operator
is commutative
the result contain all the attributes related to the common domains
the degree of the result relation is the same of the original relations
the result will contain only the common tuples in the two relations
duplicate tuples will be removed from the result
the number of tuples in the result is less than or equal to (n + m) where n is the number of tuples in relation 1 and m is the number of tuples in relation 2
Example 1:
s ( Group='2041' ) (STUDENT)) s (Sex='Male') (STUDENT))
The same result can be obtained more simple with:
s ( Group='2041' and Sex='Male') (STUDENT))
Example 2:
p ( Name, Surname) (STUDENT)) p ( Name, Surname) (TEACHER))
In this case the expression can't be rewritten.
DIFFERENCE - mnemonic - MINUS
Is used to define a relation that contains the difference of the tuples from two relations. The general form of the INTERSECT operation is:
( <relation name 1>) \ ( <relation name 2>)
where:
denote the DIFFERENCE operator
The DIFFERENCE operator has the following properties:
is a binary operator
is not commutative
the result contain all the attributes related to the common domains
the degree of the result relation is the same of the original relations
the result will contain tuples that exist in the first relation and not in the second relation
the number of tuples in the result is less than or equal to (n + m) where n is the number of tuples in relation 1 and m is the number of tuples in relation 2
Example 1:
s ( Group='2041' ) (STUDENT)) \ (s (Sex='Male') (STUDENT))
The same result can be obtained more simple with:
s ( Group='2041' and not Sex='Male') (STUDENT))
Example 2:
p ( Name, Surname) (STUDENT)) \ (p ( Name, Surname) (TEACHER))
In this case the expression can't be rewritten.
CARTESIAN PRODUCT - mnemonic - TIMES
Is used to define a relation that contain the cartesian product of the tuples from two relations. The general form of the CARTESIAN PRODUCT operation is:
( <relation name 1>) x ( <relation name 2>)
where:
x - denote the CARTESIAN PRODUCT operator
The CARTESIAN PRODUCT operator has the following properties:
is a binary operator
is commutative
can be assimilated with a JOIN operator with a true join condition for all tuples combination
- The Standard Relational Operators
SELECTION - mnemonic - SELECT
Is used to select a subset of the tuples that satisfy a selection condition. In general the SELECT operation is denoted by:
s < selection condition > ( <relation name>)
where:
s denote the SELECT operator
< selection condition > is a Boolean expression
The SELECT operator has the following properties:
is a unary operator
is commutative
the selection condition is built only with attributes from one tuple
the degree of the result relation is the same of the original relation
the number of tuples in the result is less than or equal to that of the original relation
Example:
s ( Sex='Male' ) (STUDENT)
PROJECTION - mnemonic - PROJECT
Is used to select a list of attributes from the definition attributes list of a given relation. The general form of the PROJECT operation is:
p < attribute list > ( <relation name>)
where:
p denote the PROJECT operator
< attribute list > is a subset of the definition attributes list
The PROJECT operator has the following properties:
is a unary operator
is not commutative
duplicate tuples will be removed from the result
the degree of the result relation is equal to the number of the attributes in the attribute list
the number of tuples in the result is less that or equal to that of the original relation
Example:
p ( Name, Surname) (STUDENT)
JOIN - mnemonic - JOIN
Is used to combine related tuples from two relation into a single tuple using a join condition. In general the JOIN operation is denoted by:
(<relation name 1>) r < join condition > (<relation name 2>)
where:
r denote the JOIN operator
< join condition > is a condition with attributes from the two relations
The JOIN operator has the following properties:
is a binary operator
is commutative
the results contains only attributes values from the tuples that satisfies the join condition
duplicate tuples will be removed from the result
the degree of the result relation is (n + m) where n is the degree of the relation 1 and m is the degree of the relation 2
the number of tuples in the result is less than or equal to that of the cartesian product of the original relations
tuples whose join attributes are null don't appear in the result
Types of JOIN:
EQUIJOIN - the join condition contains only = comparison operators
LESSJOIN - the join condition contains only < comparison operators
GREATHERJOIN - the join condition contains only > comparison operators
NATURAL JOIN - the join condition contains only attributes with the same name in both relations
OUTER JOIN
LEFT OUTER JOIN - the result contains all the tuples from the left relation
RIGHT OUTER JOIN - the result contains all the tuples from the right relation
FULL OUTER JOIN - the result contains all the tuples from both relations
POSSIBLE JOIN - the join condition is true only for undefined attribute values
Example:
(STUDENT) s ( code = student) (EXAM)
DIVISION - mnemonic - DIVIDE
The COMPLET SET of Relational Algebra Set
The COMPLET SET of Relational Algebra Set - a set of relational operators with the property that any of the other relational operator can be expressed as a sequence of of operation from this set. Example:
JOIN
PROJECT
DIFFERENCE
CARTESIAN PRODUCT
8.4.3. - The correspondence between the NAVIGATION language and the RELATIONAL ALGEBRA operators
The following examples present how can be implemented the main RELATIONAL ALGEBRA operators using the control structures of the NAVIGATION language.
SELECTION operator
SCAN FOR < selection condition >
statements
ENDSCAN
PROJECT operator
SCAN
Statements < attribbute list >
ENDSCAN
JOIN operator
SCAN FOR < selection condition >
SCAN FOR < join condition >
statements
ENDSCAN
statements
ENDSCAN
8.5. - Nonprocedural data processing
A nonprocedural language for data processing is defined as a language in witch the user describes the desired results starting with the input data. In a relational model all the queries addressed to a database are represented as a final relation. Using a nonprocedural language for retrieving data from a database you must only describe the result-relation in terms of the input relations. The best known of the nonprocedural language is SQL, whose name is derived from Structured Query Language.
8.5.1. - Structured Query Language (SQL)
SQL is a comprehensive database language; it has statements for data definition, query, and update. Hence it is both a DDL and a DML In addition, it has facilities for defining views on the database, for creating and dropping indexes on the files that represent relations, and for embedding SQL statements into a general-purpose programming language such as C , PASCAL , COBOL , BASIC aso.
8.5.2. - The SELECT command
SQL has a basic statement for retrieving information from a database. The basic form of the SELECT statement, sometimes called a SELECT FROM WHERE block, is formed of the three clauses SELECT, FROM and WHERE and has the following form:
SELECT < attribute list >
FROM < table list >
WHERE < condition >
where :
< attribute list > is a list of attribute names whose value are retrieved by the query
< table list > is a list of the relation names required to process the query
< condition > is a conditional ( Boolean ) search expression that identifies the tuples to be retrieved by the query
The X-Base form of the SELECT statement look as follows :
SELECT [ ALL | DISTINCT ]
[ < alias . > ] < select-item > [ AS < column-name > ]
[ , [ < alias . > ] < select-item > [ AS < column-name > ] . ]
FROM < database-file >[< local-alias >] [ , < database-file > [ < local-alias > ] . ]
[ [ INTO < destination > ] | [ TO FILE < file > [ ADDITIVE ] ] | [ TO PRINTER ] ]
[ WHERE < join-condition > [ AND < join-condition > . ]
[ AND | OR < filter-condition > [ AND | OR < filter-condition >. ] ]]
The SELECT is a SQL command used to retrieve data from one or more database files. You can create a SELECT command query in:
the COMMAND window
a PROGRAM , like any other command
the RQBE window
The SELECT clause:
< select-item > - specifies database file fields, constants, and expression to appear in the query results
ALL ( the default value ) - all of the rows in the query results are displayed
DISTINCT - excludes duplicates of any rows from the query results
< column-name > - names or renames the specifies database file fields, constants, and expression
The FROM clause :
< database-file > name of the database file that contain the data to be retrieved by the query
< local-alias > - permits the renaming of the < database-file >
The INTO clause:
- < destination > - ARRAY < array > - a memory variable
CURSOR < cursor > - a temporary TABLE that can be browsed ; once closed the table is deleted
DBF < database-file > - a DBF
The INTO clause:
< file > - a text file
ADDITIVE - appends the output to any existing content of the <file>
TO PRINTER - outputs to the printer
The WHERE clause:
< join-condition > - specifies fields or expressions that link the database files in the FROM clause ; if you include more that one database-file in a query, you should specify a join condition for every database-file after the first.
Cautions
If you include two DBF in a query and don't specify a join-condition, every record in the first DBF will be joined with every record in the second DBF as long as the filter-condition are met. This can produce sizable query results
use caution when joining DBF with empty fields because X-BASE will match empty fields
< filter-condition > - selects the tuples in the DBF-s
Examples:
1.- Selects all the COMPONENTS of the part p1
SELECT code, name, color, weight
FROM PART , COMPONENT
WHERE major-code=code and minor-code='p1'
8.6. - RECURSIVE structures
RECURSIVE structure is that structure that contains an ELEMENT witch can be viewed on a lower level as a repeted initial structure. The main characteristic that represents the recursivity property is the REFERENCE from the included ELEMENT to the initial STRUCTURE.
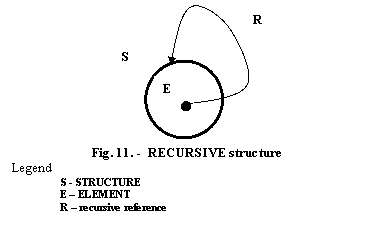
To treat a such structure imply the following phases:
Begin the treatment of the initial structure S
Arriving the element E:
IF the reference is EMPTY continue the treatment
ELSE interrupt the treatment and store the status of the structure S and
begin a new treatment of the structure S viewed as the element E
RETURN to the structure S
Continue the treatment of the structure S
There are two kinds of recursive structures:
Recursive DATA structures
Recursive PROCEDURES structures
The specific problems related to each structure will be presented below.
8.6.1. - RECURSIVE data structures
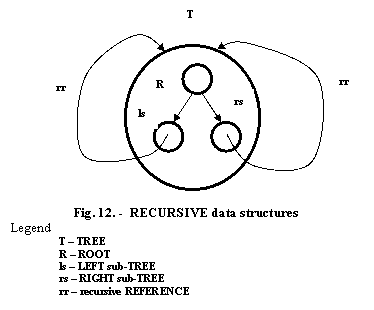
The main recursive structure is the TREE structure. This is also a very frequently used data structure in DataBases. The recursivity of this structure is suggestive presented in the figure 12. Using the graphical tools for describing such structure on the LOGICAL level we arrive to the representation of the two kinds of relationships:
one to many structures (TREES) fig. 13
many to many structures (NETWORKS) fig. 14
By using the LIST of PARTS structure we can illustrate the two kinds of recursive structure. In the first one COMPONENT (c) can be included only in one COMPOUND (a).
In the second one COMPONENT (i) can be shared by multiple COMPOUNDS (j).
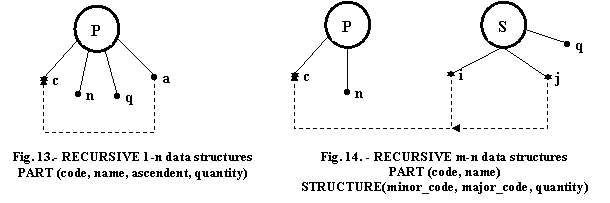
The problem in treating recursive structure is to eliminate the RECURSIVE LINKAGE by attaching to each COMPONENT the appropriate COMPOUND and this for all nested level of descendants. This can be made on two ways: STRUCTURAL or PROCEDURAL.
The
- Writing synchronized views - the referred table is open more times with a new alias
- Writing cursors (SQL views) - the referred table is open more times with a new alias
The
Writing a recursive procedure for tree traversal
in PREORDER - ROOT/LEFT/RIGHT
in ENDORDER - LEFT/RIGHT/ROOT
in POSTORDER - LEFT/ROOT/RIGHT
- Writing extended SQL SELECT queries - SELECT queries with additional clauses that implement the RECURSIVE CLOSURE (TRANSITIVE CLOSURE) of hierarchical structures
START WITH specifies the root row(s) of the hierarchy
CONNECT BY - specifies the relationship between parent & child rows of the hierarchy
WHERE - restricts the rows returned by the query without affecting other rows of the hierarchy
8.6.2. - RECURSIVE procedure structures
In procedure the recursive REFERENCE is replaced by the recursive CALL. This call put the procedure in STAND BY and launches a new INSTANCE of the same procedure. The graphical representation of a recursive PROCEDURE is viewed in fig. 15

The structure of a recursive procedure is presented below by using a PSEUDO-CODE.
Procedure TREE
Locating on ROOT
Do PREORDER procedure
For each SUBTREE
Do TREE
Enddo
Do ENDORDER procedure
Return
Bellow there are two versions of a recursive procedure written for the data structure example LIST of PARTS.
The examples use a relational data structure with the schema:
PART (code, name, ascendant, quantity)
and indexed on Ascendant attribute (that represents all DESCENDANTS of a given Code value)
The difference between the two versions is the following:
the first version use the pure navigation in table
before the recursive call store the position (cursor) in the table
ni=recno()
restore the position in the table before ending the called procedure
go ni
the second version use the data structure recursivity
before the recursive call open the same table like a CHILD TABLE
use part orde des in 0 again
close the CHILD TABLE before ending the called procedure
use
Example of RECURSIVE procedure (Indented List of Parts - Version 1)
* n - level number
* r - indent size
* ni - record number
* coda - ascendent code
** INIT sequence
n=-1
r=5
SET DEFAULT TO d:\lelutiu\cadre\lelutiu\recursiv
use part orde des
do part
** RECURSIV procedure
proc PART
priv ni,m.coda
** increase LEVEL NR.
n=n+1
** call PREORDER procedure
do LIST
** NODE = ASCENDENT ?
if seek (code)
m.coda=asc
** FOR all subtrees
scan while asc=m.coda
ni=recno()
** recursive CALL
do PART
go ni
endscan
endif
** decrease LEVEL NR.
n=n-1
retu
** PREORDER procedure
proc LIST
? name at n*r
retu
Example of RECURSIVE procedure ( Indented List of Parts - Version 2 )
* origine - list origine
* ratio - indent ratio
* parent - parent code
** INIT sequence
clea
clea all
origine=0
ratio=5
parent=0
SET DEFAULT TO d:\lelutiu\cadre\lelutiu\recursiv
** open of CHILD table
use part orde des
set filt to asc=parent
** FOR all subtrees
scan
** recursive CALL
= PART(code,origine)
endscan
** close TABLE
use
func PART
** RECURSIV function
para parent,position
priv parent,position
** call PREORDER procedure
= LIST(position+ratio)
** open of CHILD table
sele 0
use part orde des in 0 again
set filt to asc=parent
** FOR all subtrees
scan
** recursive CALL
= PART(code,position+ratio)
endscan
** close TABLE
use
retu
** PREORDER procedure
proc LIST
para position
? name at position+ratio
retu
|
