7.1 Esantion
Indicatorii statistici calculati pentru un esantion anume sunt simple aproximari pentru parametrii reali ai populatiei din care provine esantionul. Astfel, media, sau deviatia standard calculate pentru bilirubina totala la pacientii din esantionul de 229 de ciroze si cancere hepatice, sunt aproximari ale acelorasi indicatori pentru bilirubina totala a întregii populatii de bolnavi de ciroza si cancer hepatic.
Se pune în mod natural problema de a stabili câta încredere se poate avea în aceste aproximari, sau cât de precise sunt ele. Raspunsul la o astfel de întrebare se poate da cu ajutorul testelor statistice, despre care se va discuta în capitolul urmator. Acum sa încercam sa precizam doar conditiile pe care trebuie sa le avem îndeplinite pentru ca gradul de siguranta în asertiunile pe care le facem despre o populatie pe baza rezultatelor obtinute pe un esantion, sa fie cât mai mare. Înainte de a preciza aceste conditii, sa stabilim de ce aprecierea acestei precizii de aproximare este importanta.
Deci, sa plecam de la faptul ca avem media si deviatia standard calculate pentru o anumita variabila pe un esantion anume. Daca modul în care a fost ales esantionul ne da posibilitatea sa afirmam ca acestea sunt bune aproximari ale mediei si deviatiei standard pentru întreaga populatie, atunci acesta este de fapt singurul lucru pe care ne putem baza, în afara, eventual, a unor medii sau deviatii date în literatura de specialiate.
În cazul în care nu avem astfel de date din surse bibliografice, caz destul de des întâlnit, sau când acestea nu concorda, mai rar, dar se mai întâmpla, atunci media întregii populatii nu ne va fi de fapt cunoscuta decât prin aproximarile date pe esantioane, caci, este evident ca este imposibil sa se faca masuratori pentru întreaga populatie. De fapt, sursele bibliografice nu ne dau nici ele decât tot aproximari foarte bune ale adevaratei medii sau deviatii stan 16216j914q dard, obtinute tot pe niste esantioane extrase din populatia respectiva.
Pentru o discutie ceva mai exacta, sa introducem câtiva termeni: vom numi esantion sau lot, o submultime a unei populatii statistice. Extrapolarea unor rezultate obtinute prin masuratori pe un esantion la întreaga populatie o vom numi inferenta. De exemplu, daca media bilirubinei totale pe un esantion de ciroze este 2,35, putem face afirmatia generalizatoare, sau inferenta, ca media bilirubinei la ciroze este 2,35.
Cât de îndreptatite sunt astfel de inferente vom vedea ceva mai departe, dar adevarate sau nu, în principiu se pot face orice astfel de inferente. O afirmatie despre o populatie, despre care nu stim daca este sau nu adevarata, si pe care , eventual încercam sa o verificam, o vom numi ipoteza statistica. De exemplu se poate face ipoteza ca media bilirubinei la cirozele si cancerele hepatice este 2,35 si ne propunem sa verificam acesata ipoteza în ce priveste veridicitatea ei. În cele ce urmeaza, vor fi expuse unele tehnici de inferenta care pleaca de la ideia ca esantioanele pe care se lucreaza îndeplinesc niste conditii destul de naturale, firesti, dar obligatorii întrucât toate concluziile care se trag sunt conditionate de ele. Vom enumera în continuare câteva din aceste conditii:
a) Volumul
Vom numi volum al unui esantion, numarul de indivizi din acel esantion. Evident ca masuratori efectuate pe un individ dintr-o populatie, sau pe câtiva indivizi, nu ne pot oferi o imagine veridica a rezultatelor care s-ar obtine daca s-ar putea masura întreaga populatie. Se pune întrebarea, câti indivizi trebuie masurati, astfel încât sa avem un minim de siguranta asupra rezultatelor obtinute? Raspunsul la aceasta întrebare nu exista. Nimeni nu ne poate spune acest numar, sa-i zicem, minimal de masuratori. O afirmatie care tine mai mult de un soi de folclor statistic, spune ca nu se poate face statistica cu mai putin de 30 de masuratori. În realitate acest numar depinde foarte mult de populatia asupra careia se lucreaza. O afectiune foarte raspândita ca diabetul zaharat, care da o populatie foarte numeroasa la nivelul unei tari sa zicem, de câteva zeci de mii de cazuri, nu poate fi studiata pornind de la esantioane de 30 - 40 de indivizi, ci în mod necesar, de cel putin câteva sute. Din contra, o maladie rara care abia daca strânge câteva zeci de indivizi la nivelul unei tari, pune problema gasirii la un moment dat a câtorva indivizi si nicidecum a câtorva zeci. De altfel, statistica a demonstrat ca în realitate numarul de indivizi din esantion este doar cel care da siguranta inferentei, un volum prea mic al esantionului, ducând pur si simplu la rezultate nesemnificative, asa cum se va vedea. Cu cât mai multe înregistrari, cu atât mai sigure inferentele pe care le facem.
b) Reprezentativitatea
Este conditia cruciala, care necesita discutii foarte complexe si argumente serioase, inclusiv matematice si care se poate rezuma în cerinta ca esantionul pe baza caruia se fac inferente despre populatie sa reflecte particularitatile populatiei din care provine. Astfel, în cazul unei maladii cu incidenta crescuta în rândul femeilor, cum este Lupus Eritematos Sistemis, nu se pot lua esantioane în care proportia de barbati si femei este aceiasi ci esantioane care sa aiba cam aceiasi proportie de femei si barbati ca si populatia. Acesta este un exemplu legat de repartitia pe sexe, dar în realitate, trebuie sa se tina seama de o serie de alte conditii obligatorii, legate de particulatitatile de vârsta, mediu de provenienta, rasa, uneori chiar nivel de cultura sau zona geografica si altele. Vom spune ca un esantion este reprezentativ numai în conditiile în care el reflecta la scara mica toate, sau cât de multe posibil, particularitatile populatiei din care provine.
c) Aleatorizarea sau randomizarea
Este o conditie legata de precedenta si presupune ca alegerea indivizilor din esantion trebuie facuta la întâmplare caci numai astfel pot fi eliminate unele tendinte subiective ale celui care face alegerea si care, oricât ar dori, nu se poate sustrage tuturor pericolelor de a alege indivizii din esantion dupa niste criterii pe care de cele mai multe ori nici nu le banuieste dar ele ar putea exista. Sunt cazuri speciale în care alegerea indivizilor din esantion se face dupa criterii anume dar acestea au fost verificate de-a lungul timpului si au un suport stiintific bine întemeiat. Pentru a înlatura orice suspiciune de alegere subiectiva, se prefera alegerea întâmplatoare. O mentiune speciala merita cazul în care înregistrarile provin de fapt din baze de date construite si completate în timpul actului medical la un cabinet de specialitate, într-o clinica, etc, caz în care, evident ca nu avem posibilitatea de a controla modul în care pacientii se prezinta la medic. În aceste cazuri facem observatia ca în afara unor evenimente speciale de tipul epidemiilor, campaniilor de control medical monitorizat, când pacientii nu se mai prezinta la medic la întâmplare, ci sunt mânati de o cauza ce nu tine direct de hazard, înregistrarile obisnuite produc esantioane care sunt de obicei întâmplator alese din populatiile respective.Totusi este bine sa se verifice pe cât posibil daca esantioanele înregistrate îndeplinesc celelalte conditii cerute.
d. Independenta masuratorilor
Orice calcul statistic facem cu datele pe care le avem la dispozitie presupune apriori ca ele sunt independente una de alta. În medicina aceasta cerinta este de obicei îndeplinita în mod automat si anume, atunci când datele reprezinta valorile aceluiasi parametru masurat la mai multi pacienti, deoarece valoarea obtinuta pentru pacientul nr.1 este independenta de valoarea obtiunuta pentru pacientul nr.2 si ambele sunt independente de valorile pe care le obtinem la ceilalti pacienti. Sunt însa cazuri în care un pacient care a fost internat de mai multe ori si parametrul urmarit este masurat de fiecare data, valorile obtinute nu sunt neaparat independente unele de altele.
De exemplu, daca ne intereseaza valorile legate de functia hepatica, la pacienti cu ciroza hepatica, atunci, la reinternari, masurarea unui parametru care nu este direct legat de functia hepatica nu da valori independente. Tensiunea sistolica ar putea fi chiar aceeasi la câteva reinternari si reînregistrarea ei de fiecare data, va arata o tendinta de constanta artificiala. Un parametru legat de functia hepatica, cum ar fi bilirubina totala (BRT), ar putea sa ne intereseze si sa consideram util sa îl înregistram la fiecare reinternare dar nici în acest caz, valorile obtinute nu sunt independente ci mai curând înregistrarea lor este utila pentru urmarirea evolutiei în timp a parametrului BRT. În concluzie, înregistrarea datelor despre un acelasi pacient de mai multe ori este extrem de riscanta pentru acuratetea rezultatelor pe care le obtinem.
7.2 Esantionare
si acum sa trecem la modalitatile prin care se realizeaza inferenta statistica. De la început trebuie precizat ca un rol central îl joaca distributia Gaussiana care de fapt nu este o distributie ca oricare alta ci, datorita proprietatilor ei naturale, în special simetria, are un statut oarecum privilegiat. Pentru a ne da seama de acest lucru, sa presupunem ca ne aflam în fata unei populatii cu un numar foarte mare de indivizi, ceea ce, din punct de vedere statistic se denumeste ca "practic infinita". Sa presupunem pentru simplitate ca media populatiei respective în ceea ce priveste un anumit parametru este m iar deviatia standard este s, valori care pot fi de fapt necunoscute, iar distributia variabilei respective este normala. Sa mai presupunem ca, nestiind statistica, încercam sa aproximam pe m prin medii obtinute pe esantioane de volum mult prea mic, sa zicem de doi indivizi.
Putem chiar sa ne imaginam ce se întâmpla daca luam foarte multe astfel de esantioane, poate chiar pe toate. Vom obtine foarte multe medii aproximative, aproximatii care sunt, multe dintre ele foarte departe de adevarata medie. Vom numi aceste medii aproximative, medii de esantionare de volum 2. Se naste astfel o serie statistica, a acestor medii, care are o importanta deosebita, deoarece are anumite proprietati pe care le vom descrie în continuare, care ne vor ajuta în a estima cât de bune sunt aproximarile prin medii de asantionare.
Fie seria statistica M2: m1, m2, m3.........., seria acestor medii de esantionare de volum 2. Se poate demonstra ca:
media seriei statistice M2 este m, adica media pe care vrem sa o aproximam.
deviatia
standard a seriei M2 este ![]() , unde s este deviatia standard
reala.
, unde s este deviatia standard
reala.
distributia seriei M2 este normala (Gaussiana). Din acest motiv se mai spune ca distributia mediilor de esantionare pe esantioane dintr-o distributie normala este normala.
Daca mediile de esantionare se obtin nu pe esantioane de volum 2, ceea ce este evident cam putin, ci pe esentioane, toate egale, de volum n, atunci, notând seria statistica a acestor medii tot cu Mn: m1, m2, m3......., vom avea asemanator cu cele de mai sus:
media seriei statistice Mn este m.
deviatia
standard a seriei Mn este ![]()
distributia seriei Mn este normala.
În figura 7.1 sunt reprezentate histogramele corespunzatoare cazurilor când luam foarte multe medii pe loturi de câte 2 sau 3 sau 4, pâna la 100 (2, 3, 4, 9, 16, 25, 36, 100). Se observa toate cele trei afirmatii punctate mai sus.
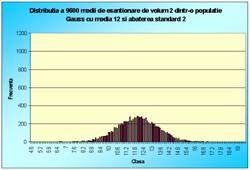
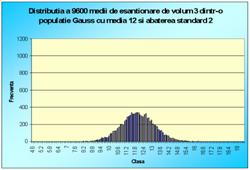
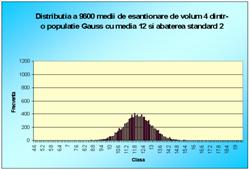
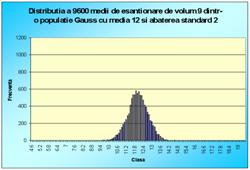
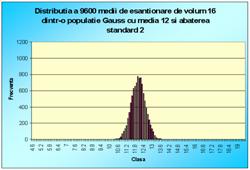
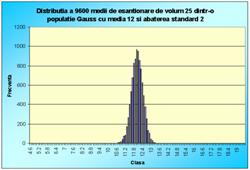
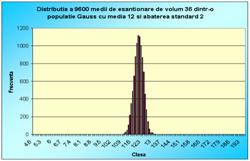
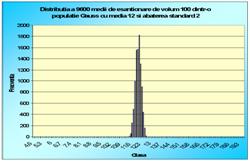
Figura 7.1 Prima histograma este executata pe seria statistica a mediilor pe loturi de câte doi indivizi extrasi dintr-o populatie de 10000 de indivizi. A doua histograma pe seria mediilor pe loturi de câte 3, extrase din aceeasi populatie. Apoi pe loturi de 4, 9, 16, 25, 36 si 100 de indivizi. S-e observa tot mai accentuat tendinta de scadere a dispersiei, pe masura ce creste volumul loturilor
În figura 7.2, se poate observa aceiasi ideie din figura 7.1, pentru cazul când populatia de baza nu este o populatie cu repartitia Gauss ci una extrem de asimetrica. Se observa totusi ca si în acest caz, pe masura cresterii volumului loturilor, histogramele sunt tot mai simetrice.
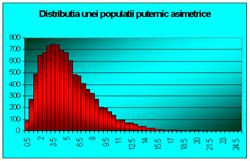

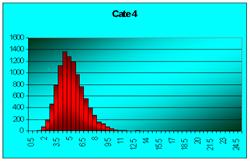
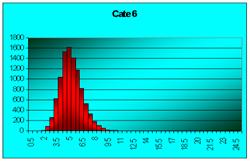
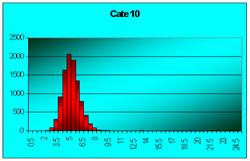

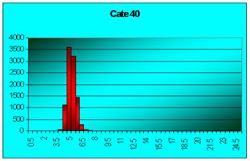
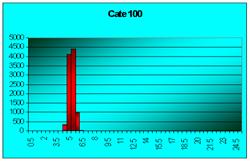
Figura 7.2 Prima histograma este executata pe seria statistica a mediilor pe loturi de câte doi indivizi extrasi dintr-o populatie de 10000 de indiviz foarte asimetric repartizatai. A doua histograma pe seria mediilor pe loturi de câte 4, extrase din aceeasi populatie. Apoi pe loturi de 6, 10, 20, 40, 100 de indivizi. S-e observa tot mai accentuat tendinta de scadere a dispersiei, pe masura ce creste volumul loturilor
Sa observam ca deviatia standard a distributiei mediilor de esantionare se mai numeste "eroare standard" si este un indicator important care dupa cum se va vedea mai jos este tocmai cel care ne ajuta sa apreciem precizia sau siguranta de calcul a mediei pe care o estimam.
Bineînteles ca mediile
obtinute pe esantioane de volum n
vor fi cu atât mai aproape de realitate cu cât n este mai mare. Acest aspect nu trebuie neaparat demonstrat
caci are un suport intuitiv evident: o aproximare a mediei unei
populatii este în principiu, cu atât mai buna cu cât esantionul
extras este mai numeros. Acest lucru ne spune ca daca
reprezentam curba Gauss a mediilor de esantionare, ea va fi cu atât
mai "strânsa " în jurul mediei, cu cât esantioanele sunt de volum mai
mare, deoarece este mai putin probabil sa avem medii foarte
îndepartate de media reala. Pe când folosirea de esantioane
restrânse ca acelea formate din doi indivizi poate duce la medii foarte departe
de cea reala, mediile obtinute pe esantioane mai numeroase vor
fi în general mult mai apropiate de media reala. De altfel, formula ![]() , ne spune tocmai
acest lucru, caci se vede ca o crestere a lui n conduce la un numitor mare si
deci la o abatere standard mica. De exemplu, daca media
populatiei este m=50 si
deviatia standard este s=10
si încercam calculul mediei pe esantioane formate din 4
indivizi, atunci mediile m1, m2, m3,........ se distribuie în în jurul lui 50 cu o
deviatie s4 = s/2 = 10/2 =5. Daca însa, folosim
esantioane de 100 de indivizi, mediile se vor distribui tot în jurul
mediei reale m=50, dar de data
aceasta deviatia standard a distributiei lor este s100=s/10=10/10=1,
adica mult mai strâns în jurul lui m=50. Se vede deci, ca mediile de
esantionare sunt tot mai apropiate de adevarata medie pe
masura ce numarul de indivizi din esantion creste.
, ne spune tocmai
acest lucru, caci se vede ca o crestere a lui n conduce la un numitor mare si
deci la o abatere standard mica. De exemplu, daca media
populatiei este m=50 si
deviatia standard este s=10
si încercam calculul mediei pe esantioane formate din 4
indivizi, atunci mediile m1, m2, m3,........ se distribuie în în jurul lui 50 cu o
deviatie s4 = s/2 = 10/2 =5. Daca însa, folosim
esantioane de 100 de indivizi, mediile se vor distribui tot în jurul
mediei reale m=50, dar de data
aceasta deviatia standard a distributiei lor este s100=s/10=10/10=1,
adica mult mai strâns în jurul lui m=50. Se vede deci, ca mediile de
esantionare sunt tot mai apropiate de adevarata medie pe
masura ce numarul de indivizi din esantion creste.
Aceasta distributie ne
ofera posibilitatea de a estima siguranta cu care este
aproximata media din chiar forma ei. O distributie a mediilor de
esantionare foarte strânsa arata în genereal precizii bune. Dar
o distributie "strânsa", înseamna o eroare standard mica. si
mai rezulta ca, de fapt se poate spune doar, ce proportie dintre
mediile de esantionare sunt suficient de apropiate de adevarata
medie. Mai precis, daca avem media ![]() si
deviatia standard s pentru un
esantion cu n indivizi, si
deci pe sn, cunoscând distributia mediilor pe esantioane
de n indivizi, stim ca
intervalul
si
deviatia standard s pentru un
esantion cu n indivizi, si
deci pe sn, cunoscând distributia mediilor pe esantioane
de n indivizi, stim ca
intervalul ![]() -2sn ,
-2sn , ![]() +2sn , contine aproximativ 95% dintre
mediile tuturor esantioanelor de n
indivizi.
+2sn , contine aproximativ 95% dintre
mediile tuturor esantioanelor de n
indivizi.
Esantionarea este un proces cu încarcatura pur statistica, el punând la încercare fondul de gândire probabilista pe care fiecare îl avem prin educatie, fara sa fi învatat neaparat probabilitati sau statistica. Gândirea comuna, sau uzuala, ne spune ca este natural ca masuratori multe sa ne conduca la o precizie mai buna. Exista totusi multe limite ale gândirii comune care ne pot arunca în capcane greu de ocolit.
Pentru a fi mai siguri pe
judecatile bazate pe ideile de mai sus, sa aruncam o
privire mai atenta asupra intervalului ![]() -2sn ,
-2sn , ![]() +2sn , care, spuneam ca va contine
cam 95% din toate mediile pe esantioane de volum n. Deoarece
+2sn , care, spuneam ca va contine
cam 95% din toate mediile pe esantioane de volum n. Deoarece ![]() , se observa
ca precizia depinde de mai multi factori:
, se observa
ca precizia depinde de mai multi factori:
Odata cu creseterea lui n, asa cum am spus mai sus, sn
scade si deci intervalul
![]() -2sn ,
-2sn , ![]() +2sn , este mai scurt. Aceasta
scadere nu este liniara, adica dublarea lui n nu duce la înjumatatirea intervalului, ci pentru
aceasta este nevoie ca n sa fie
de 4 ori mai mare. Într-adevar, s4n are valoarea
+2sn , este mai scurt. Aceasta
scadere nu este liniara, adica dublarea lui n nu duce la înjumatatirea intervalului, ci pentru
aceasta este nevoie ca n sa fie
de 4 ori mai mare. Într-adevar, s4n are valoarea ![]() , de unde se vede
ca înjumatatirea lui s
se realizeaza când n creste
de 4 ori.
, de unde se vede
ca înjumatatirea lui s
se realizeaza când n creste
de 4 ori.
Valoarea lui sn este direct
proportionala cu deviatia standard s, a populatiei din care provine esantionul si deci
la acelasi volum n, intervalul ![]() -2sn ,
-2sn , ![]() +2sn , poate sa fie mai mare sau mai mic
în functie de s. Nu trebuie
însa uitat ca în practica este folosita deviatia
standard de esantionare în locul lui s
care este necunoscuta, si deci vom avea incluse si eventualele
erori de masuratoare.
+2sn , poate sa fie mai mare sau mai mic
în functie de s. Nu trebuie
însa uitat ca în practica este folosita deviatia
standard de esantionare în locul lui s
care este necunoscuta, si deci vom avea incluse si eventualele
erori de masuratoare.
Intervalul ![]() -2sn ,
-2sn , ![]() +2sn , este obtinut luând în stânga
si dreapta mediei de esantionare doua abateri sn,
adica doua erori standard. Alegerea a doua erori standard în
stânga si doua în dreapta, se datoreste dorintei de a
cuprinde în interval aproximativ 95% din toate mediile de esantionare pe
esantioane de volum n. Daca
am dori o precizie mai mare, de exemplu 99%, atunci suntem obligati
sa luam în stânga si în dreapta mediei de esantionare 2,58
erori standard si nu doua.
+2sn , este obtinut luând în stânga
si dreapta mediei de esantionare doua abateri sn,
adica doua erori standard. Alegerea a doua erori standard în
stânga si doua în dreapta, se datoreste dorintei de a
cuprinde în interval aproximativ 95% din toate mediile de esantionare pe
esantioane de volum n. Daca
am dori o precizie mai mare, de exemplu 99%, atunci suntem obligati
sa luam în stânga si în dreapta mediei de esantionare 2,58
erori standard si nu doua.
Judecatile de mai sus sunt valabile ca afirmatii statistice si nu absolute. În special dependenta lui sn de n este de natura sa însele bunul simt daca este tratata cu superficialitate. Am fi de exemplu tentati sa afirmam ca media de esantionare obtinuta pe un esantion de volum mai mare este totdeauna mai precisa decât media de esantionare obtinuta pe un esantion de volum mai mic, ceea ce nu este adevarat. Adevarata este doar afirmatia:
Este mai probabil ca o medie de esantionare pe un esantion de volum mai mare sa fie mai precisa decât una obtinuta pe un esantion de volum mai mic.
Este posibil ca, prin jocul întâmplarii, o medie obtinuta pe un esantion mai mare sa fie mai departe de media reala decât o medie obtinuta pe un esantion mai mic. Numai ca aceasta situatie este mai putin probabila, cu atât mai putin probabila cu cât diferenta de volum între cele doua esantioane este mai mare.
7.3. Formula dispersiei de esantionare
Este diferita ca forma de formula dispersiei calculata pentru întreaga populatie. Într-adevar, pentru o medie a populatiei egala cu m, numarul de indivizi din populatie fiind N, formula dispersiei se scrie:
![]()
iar daca
media de esantionare pe un esantion de volum n<N este ![]() , atunci formula
pentru dispersia de esantionare este cea cunoscuta din capitolul al
doilea:
, atunci formula
pentru dispersia de esantionare este cea cunoscuta din capitolul al
doilea:
![]()
Diferenta neasteptata este ca la prima numitorul este N, iar la a doua, unde ne-am fi asteptat sa fie n, este n-1. Dar folosirea unei dispersii cu n la numitor pune unele probleme printre care:
a. Sa consideram cazul când media m este cunoscuta. În acest caz, pentru n valori x1, x2,...xn, dispersia se estimeaza ca
![]()
unde cu Dm
am notat estimatorul de mai sus care este un estimator pentru dispersia
populatiei s2. Dar
daca m este necunoscuta
si este aproximata cu ![]() , atunci daca
am pune ca estimator al dispersiei expresia:
, atunci daca
am pune ca estimator al dispersiei expresia:
![]()
ne confruntam cu urmatoarea problema: media
de esantionare are o proprietate importanta, si anume, suma
patratelor deviatiilor individuale de la media ![]() este mai mica
decât suma patratelor deviatiilor individuale de la orice alt
numar, inclusiv media reala m.
deci avem, pentru orice serie de valori:
este mai mica
decât suma patratelor deviatiilor individuale de la orice alt
numar, inclusiv media reala m.
deci avem, pentru orice serie de valori:
![]()
în consecinta, si pentru media m, vom avea:
![]()
ceea ce ne da prin împartire cu n
![]()
ceea ce arata ca estimatorul
![]()
este mereu mai mic sau egal cu cel nedeplasat Dm., adica subestimeaza disperia populatiei. Luarea lui n-1 la numitor creste D realizând eliminarea subestimarii. S-a demonstrat ca folosirea lui n-1 la numitor este exact ceea ce trebuie pentru eliminarea acestui neajuns.
Un alt mod de a motiva formula mai putin obisnuita a lui D, este de gândi în termini de grade de libertate. Când media m este cunoscuta, cele n valori x1, x2,...xn sunt independente si deci avem n grade de libertate. Când media este necunoscuta, cele n valori x1, x2,...xn nu mai sunt independente caci sunt supuse la o legatura, iar numarul de grade de libertate este n-1. Aceasta deoarece numarul de grade de libertate este în general egal cu numarul de valori independente luate în calcul, minus numarul de relatii estimate pe parcurs, si folosite apoi în calcul, în cazul nostru unu. Deci, vom avea pentru cele doua cazuri:
![]()
![]()
7.4 Intervale de încredere
7.4.1 Definitie
Estimarea unui parametru printr-o valoare numerica este asa cum s-a vazut supusa unor erori inerente. Nu exista metoda perfecta de a masura ceva si ca urmare, orice înregistrare de date se face cu erori care se datoreaza în primul rând procesului de masurare. De aceea, o metoda comoda de a estima un parametru este aproximarea sa daca este posibil, printr-un interval în care se afla adevarata valoare a parametrului de estimat.
Din pacate, nu este posibil sa gasim în general un interval finit în care sa fim absolut siguri ca se afla valoarea parametrului de estimat. Acest lucru este posibil de exemplu atunci când avem informatii apriorice despre parametrul respectiv, de exemplu când este sigur ca valoarea lui este în intervalul unitate, sau, cum este cazul coeficientului de corelatie, valoarea lui este cuprinsa în intervalul [-1, 1]. To ceea ce se poate face este sa gasim un interval în care valoarea reala a parametrului pe care îl estimam se afla cu o siguranta dinainte fixata. Daca fixam nivelul de siguranta la o valoare suficienta, de exemplu 95% sau 99%, ne putem declara multumiti.
Vom numi interval de încredere de siguranta α%, un intreval de numere reale în care suntem α% siguri ca se afla adevarata valoare a parametrului pe care îl estimam.
7.4.2 Calcul
Sa consideram ca suntem în
cazul în care un esantion este extras dintr-o populatie despre care
stim ca este distribuita normal si a carei dispersie ![]() o cunoastem. Nu acesta este cazul de
obicei în practica, dar se va vedea ca rationamentul
urmator va merge si pentru alte cazuri.
o cunoastem. Nu acesta este cazul de
obicei în practica, dar se va vedea ca rationamentul
urmator va merge si pentru alte cazuri.
Conform celor afirmate în 7.2, media de
esantionare are o distributie tot normala, cu media m, (media necunoscuta a populatiei, cea pe care dorim sa o
estimam, si dispersia ![]() , sau abaterea
standard
, sau abaterea
standard ![]() . Dar daca
distributia lui
. Dar daca
distributia lui ![]() este normala cu media
este normala cu media ![]() si abaterea standard
si abaterea standard ![]() , atunci este
adevarata formula:
, atunci este
adevarata formula:
![]()
adica,
probabilitatea ca variabila aleatoare![]() sa aiba
valori cuprinse între media plus minus 1,96 deviatii standard este 0,95,
aproape unu.
sa aiba
valori cuprinse între media plus minus 1,96 deviatii standard este 0,95,
aproape unu.
Dar daca înlocuim inegalitatea
![]()
cu inegalitatea
echivalenta obtinuta schimbând m si ![]() între ele:
între ele:
![]() ,
,
iar inegalitatea
![]() ,
,
cu inegalitatea evident echivalenta,
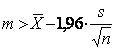 ,
,
vom obtine folosind din nou dubla inegalitate:
![]()
Am obtinut
astfel o afirmatie a carei importanta este
fundamentala în statistica: adevarata medie se afla cu o
probabilitate de 95%, adica aproape sigur, în intervalul format prin
adunarea si scaderea din media de esantionare ![]() , a unei valori egale cu 1,96
, a unei valori egale cu 1,96 ![]() . În
practica, se pune în locul lui s,
necunoscut, deviatia standard de esanationare. Se demonstreaza
ca în acest caz, trebuie sa ne referim la repartitia tia
Student si sa luam în locul a 1,96 erori standard stânga
dreapta, un numar de erori standard dat de
. În
practica, se pune în locul lui s,
necunoscut, deviatia standard de esanationare. Se demonstreaza
ca în acest caz, trebuie sa ne referim la repartitia tia
Student si sa luam în locul a 1,96 erori standard stânga
dreapta, un numar de erori standard dat de ![]() , unde n este volumul lotului.
, unde n este volumul lotului.
Formula de calcul pentru intervalul de încredere de 95% este deci:
![]()
În general, pentru calculul intervalului de încredere de siguranta α%, formula este:
![]()
Exemplu de calcul
Media de esantionare pentru o serie statistica în care am masurat latenta semnalului pe nervul optic, este 112,2 iar abaterea standard este 12,5. Volumul esantionului este de 156 de indivizi. Sa se calculeze intervalul de încredere de 95%.
Eroarea standard este ![]()
În tabele statistice, corespunzator
la 155 grade de libertate se gaseste ![]()
Deci limitele inferioara si superioara pentru intervalul de încredere sunt:
![]()
![]()
Deci, intervalul de încredere este:
![]()
Un interval de încredere este totdeauna centrat pe media de esantionare, lucru care este normal, el fiind obtinut prin adaugarea si scaderea din media de esantionare a aceleiasi cantitati tαErr. Deci daca suntem întrebati unde este media de esantionare în raport cu limitele unui interval de încredere al ei, spunem simplu ca este la mijloc. Ceea ce ne intereseaza însa, este unde se afla media reala în raport cu intrevalul de incredere asociat, sau care o estimeaza, pentru ca de fapt chiar acesta este scopul pentru care construim intervale de încredere, ca sa estimam media reala. Dupa definitia intervalului de încredere, media reala se afla α% sigur (95% sigur, 99% sigur, etc), între limitele intervalului de încredere. De obicei suntem tentati sa spunem ca este la mijloc, ceea ce nu este adevarat. Media reala, poate fi oriunde în interiorul intervalului de încredere, asa cum poate sa fie în afara lui, cu o probabilitate foarte mica. Nu este corect sa spunem nici macar ca este mai probabil sa se afle la mijlocul sau în jurul mijlocului intervalului de încredere. Ea se afla oriunde în intervalul de încredere, la fel de probabil spre mijloc sau spre capete.
7.4.3 Estimarea unei proportii si a indicelui OR
Atunci când urmarim estimarea proportiei de indivizi dintr-o populatie care au o anumita calitate care ne intereseaza (pozitivi), fata de ceilalti indivizi ai populatiei care nu au calitatea respectiva (negativi), trebuie extras aleator un esantion de volum n si numarate cazurile care au calitatea ce ne intereseaza. Sa zicem ca din cei n indivizi alesi în esantion, X, un numar mai mic decât n sunt pozitivi.
Variabila aleatoare care estimeaza
proportia cautata este ![]() , obtinut ca raport între pozitivi si total. Deci:
, obtinut ca raport între pozitivi si total. Deci:
![]()
Daca populatia din care s-a
extras esantionul este suficient de larga si daca
extragerea s-a facut aleator, atunci distributia lui X este
binomiala ![]() . Reamintim ca în aceasta situatie,
probabilitatea ca exact X dintre
indivizii din esantion sa aiba calitatea cautata,
(sa fie pozitivi), este
. Reamintim ca în aceasta situatie,
probabilitatea ca exact X dintre
indivizii din esantion sa aiba calitatea cautata,
(sa fie pozitivi), este ![]() .
.
Variabila aleatoare ![]() obtinuta ca
raportul dintre numarul indivizilor pozitivi si numarul total de
indivizi din esantion, va lua valori care aproximeaza mai mult sau
mai putin bine valoarea adevarata a proportiei, pe care nu
o cunoastem si care este p.
Valorile lui
obtinuta ca
raportul dintre numarul indivizilor pozitivi si numarul total de
indivizi din esantion, va lua valori care aproximeaza mai mult sau
mai putin bine valoarea adevarata a proportiei, pe care nu
o cunoastem si care este p.
Valorile lui ![]() , daca s-ar reface calculele pe toate esantioanele
de n indivizi, se distribuie astfel
încât:
, daca s-ar reface calculele pe toate esantioanele
de n indivizi, se distribuie astfel
încât:
Media
lui ![]() (calculata din
valorile care s-ar obtine) este p, adevarata proportie.
(calculata din
valorile care s-ar obtine) este p, adevarata proportie.
Dispersia
lui ![]() este
este ![]()
Deci aproximatele ![]() se distribuie în jurul adevaratei proportii si
pe masura ce vom mari numarul de observatii n, adica volumul esantionului,
împrastierea valorilor aproximative
se distribuie în jurul adevaratei proportii si
pe masura ce vom mari numarul de observatii n, adica volumul esantionului,
împrastierea valorilor aproximative ![]() în jurul
adevaratei proportii tinde sa scada.
în jurul
adevaratei proportii tinde sa scada.
Mai mult, pentru valori suficient de mari
ale lui n, ![]() , este distribuita aproximativ normal. Deci se pot
construi intervale de încredere pentru
, este distribuita aproximativ normal. Deci se pot
construi intervale de încredere pentru ![]() .
.
Dispersia coeficientului OR este data de formula:
![]()
si se observa ca doua tabele care au aceeasi valoare pentru OR, pot avea dispersii foarte diferite în functie de valorile pe care le contin în cele patru celule.
Având în vedere formula de calcul a intervalului de încredere de 95% care este:
![]()
vom obtine pentru cele 5 cazuri din tabelul 3.18 intervalele:
A).![]()
![]()
B).![]()
![]()
C).![]()
![]()
D).![]()
![]()
E).![]()
![]()
Aceste intervale de încredere ne spun toate ca exista o tendinta de dependenta între cauza si efect, dar indeterminismul acestei constatari difera mult la cele cinci cazuri. În cazul A, intervalul I=[0,0494; 0,524], arata ca avem o cunoastere destul de vaga a valorii reale a lui OR. De exemplu, daca OR ar fi în realitate la capatul din stânga al acestui interval, ar putea fi de exemplu 0,05, iar daca ar fi la capatul din dreapta, ar putea fi 0,5 ceea ce ne spune cu totul altceva despre taria legaturii între cauza si efect.
si în cazurile B, C, D, indeterminismul este destul de mare, desi se vede ca precizia este mai buna, intervalele fiind mai scurte. În cazul E, stim ca aproape sigur, adevaratul OR este între aproximativ 0,21 si 0,36, ceea ce ne duce la concluzia ca tendinta de legatura este destul de slaba.
|
