Informatica Medicala si Biostatistica
1 01 Introducere in Informatica Medicala
2 02 - Structura sistemelor de calcul
3 03 - Sisteme de operare
4 04 - Birotica si baze de date
5 05 - Retele de calculatoare, Internet
6 06 - Biostatistica - introducere
7 07 - Statistica descriptiva
8 08 - Calculul probabilitatilor
9 09 - Variabile aleatoare
10 10 - Estimari
11 11 - Corelatii si regresii
12 12 - Teste statistice 1
13 13 - Teste statistice 2
14 14 - Teste statistice 3
Alte surse bibliografice disponibile pe serverele catedrei
Laboratoare - aplicatii
Last modified 23.05.2008 04:58:01
Notes
Slide Show
[Pause/Play Narration]
[Previous Slide]
[Next Slide]
Outline
[Expand/Collapse Outline]
Introducere în Informatica Medicala
* Conf. Dr. Tudor Drugan
Regulament
* Studentii au obligatia sa depuna la decanat documentele care atesta motivarea absentelor în cel mult 7 zile calendaristice de la efectuarea acestora si, în aceeasi perioada, sa depuna la catedre motivarea vizata de decanat pentru programarea recuperarilor.
* Motivarile nedepuse atât la decanat cât si la catedre în timpul sus mentionat nu se vor lua în considerare.
Regulament
* Pentru a realiza integral numarul de credite aferent unei discipline de studiu, studentii au obligatia sa participe la minim 70 % din urile disciplinei respective
* NU se admit absente nemotivate si nerecuperate. NU se admit schimbari ale programarilor orelor de laborator.
Regulament
* Studentii care nu au recuperat absentele de la lucrarile practice sau care nu au frecventat 70% din uri în semestrul/anul universitar în care au fost programate vor stabili modalitatea de recuperare (în semestrul/modulul urmator daca acest lucru mai este posibil în anul curent, daca nu în anii urmatori).
Evaluare
* În cadrul examenelor teoretice si practice studentii trebuie sa faca dovada ca au par si învatat cel putin 70% din materie (de exemplu trebuie sa obtina 50% din punctajul testului) iar nota obtinuta (atât la practic cât si la examenul teoretic) sa fie cel putin eg 434i85e ala cu 5.
* Examenul practic are o pondere de 30% în calculul notei finale
Evaluare
* Studentii au voie sa foloseasca in examen urmatoarele surse de "inspiratie":
o urile proprii luate in deul anului
+ Nu se admit copii
o Scheme, note, transcrieri scrise de mana
+ Nu se admit copii
Bibliografie
* 1. Tigan S., de informatica Medicala si
Biostatistica, Tipografia UMF,
* 2. Tigan S., Achimas A., Drugan T., Mircean A., Aplicatii de birotica cu Microsoft Office, SRIMA, Cluj-Napoca, 1998.
* 3. Tigan S., Achimas A., Drugan T., Biostatistica Medicala,
* SRIMA, Cluj, 1999.
* 4. Tigan S., Achimas A., Drugan T., Ramona Galatus, Dorina Gui, Informatica si statistica aplicate in medicina, Ed. SRIMA, Cluj, 2000.
* 5. Tigan S., Achimas A., Drugan T., de Informatica si statistica medicala, Ed. SRIMA, Cluj, 2001
Diagrama studiilor la catedra noastra
INTRODUCERE
Introducere
I. Informatica generala
+ 1. Obiectivele informaticii
+ 2. Structura calculatoarelor
+ - Hard
+ - Soft
+ - Clase de calculatoare
"3"
+ 3. Structuri de date
+ - Fisiere
+ - Baze de date
+ 4. Sisteme de operare (WINDOWS)
+ 5. Interfete cu utilizatorul
+ Linie de comanda
+ Meniu
+ Grafica
Dispozitive de intrare
tastatura, mouse
Memorii externe
discheta, hard disk,
CD-ROM
Dispozitive de iesire
monitor, imprimanta
Nr. de nascuti
de sex masculin (a) 1927054
Nr. total de nasteri (b) 3760358
Probabilitatea empirica a nasterii
unui copil de sex masculin (a/b)
Desi definitia clasica poate fi adesea utila ea nu este satisfacatoare pentru ca, pe de o parte, cere probe (încercari) echiprobabile, ceea ce presupune ca aceasta notiune a fost deja definita. Pe de alta parte aceasta cerinta limiteaza utilizarea sa
9Definitia clasica a probabilitatii
Astfel, daca încercarile constau în determinarea grupei sangvine, rezultatele posibile fiind: A, B, AB, O, acestea nu sunt echiprobabile.
Grupa Sangvina Probabilitatea
O
A
B
AB
Acesta este motivul pentru care este necesara o abordare mai generala a notiunii de probabilitate printr-o introducere axiomatica a acestei notiuni
10Spatiul fundamental de evenimente
* Fie H un experiment aleator dat pentru care E reprezinta multimea tuturor rezultatelor posibile. E se numeste multime fundamentala sau spatiu fundamental (spatiul evenimentelor elementare). Spatiul fundamental poate sa fie finit sau infinit.
* Astfel ca, o submultime A a lui E se numeste eveniment, iar daca A are un singur element din E el este un eveniment elementar.
* Orice eveniment a carui realizare depinde de cel putin doua evenimente elementare este un eveniment compus.
* Multimea vida Æ si multimea fundamentala E sunt si ele evenimente, si anume, evenimentul imposibil (Æ) si respectiv evenimentul cert (E). Evenimentul sigur se produce cu certitudine la orice efectuare a experimentului, iar evenimentul imposibil este nerealizabil în urma efectuarii experimentului.
11Spatiul fundamental de evenimente
* In mod asemanator cu operatiile de reuniune si intersectie cu multimi se definesc operatii similare cu evenimente. Astfel fiind date doua evenimente A si B, reuniunea lor C=AÈB este un eveniment care are loc daca cel putin unul dintre evenimentele A sau B are loc, si intersectia D=AÇB este evenimentul care are loc numai când A si B au loc simultan.
* Prin contrarul (complementarul) unui eveniment A se întelege un eveniment care se realizeaza ori de câte ori nu se realizeaza A. Acesta se noteaza prin non A (sau C(A) ori ).
* Daca doua evenimente A si B sunt disjuncte ( A Ç B = Æ), adica daca nu se pot realiza simultan, se spune ca ele sunt incompatibile. Doua evenimente A si B care se pot realiza simultan se numesc compatibile.
* Evenimentul A implica evenimentul B si se noteaza prin AÌB, daca evenimentul B se produce ori de câte ori se produce A.
12Spatiul fundamental este finit
* Experimentul H consta în aruncarea unui zar.
o Spatiul fundamental în acest caz este multimea tuturor rezultatelor posibile la aruncarea zarului: E = . In acest caz spatiul fundamental E este finit.
o Printre evenimentele posibile (submultimi ale lui E) se pot considera:
+ A = (obtinerea unei fete pare)
+ B = (obtinerea unei fete impare)
+ C = ( eveniment elementar).
o In acest caz, evenimentele A si B sunt incompatibile. Evenimentele elementare sunt echiprobabile.
13Spatiul fundamental este finit
* Experimentul H consta în determinarea grupei sangvine.
o In acest caz spatiul fundamental este E = . E este evident finit însa spre deosebire de exemplul 1.1, evenimentele elementare , , si nu sunt echiprobabile.
14Spatiul fundamental este infinit si numarabil
* Experimentul H consta în aruncarea succesiva a unui zar pâna ce se obtine fata 5.
o Spatiul fundamental în acest caz este alcatuit din numarul aruncarilor necesare, care variaza de la 1 la infinit:
+ E = .
o Spatiul fundamental E este infinit, însa elementele sale fiind ordonate într-un sir, E este un exemplu de spatiu fundamental numarabil.
15Spatiul fundamental este infinit si numarabil
* Experimentul H consta în numararea internarilor într-un spital într-un interval de timp dat (saptamâna, luna, an etc.)
o Spatiul fundamental E variaza de la 0 la infinit, adica
+ E = .
o In acest caz, E este o multime infinita si numarabila.
16Spatiul fundamental este infinit si nenumarabil
* Experimentul H consta în aruncarea unei bile sferice într-o cutie dreptunghiulara.
o In urma unei încercari dupa oprirea bilei ea are un punct de contact cu baza cutiei.
o Spatiul fundamental E, în acest caz, este alcatuit din punctele de contact.
o Aici E este o multime infinita si nenumarabila.
17Spatiul fundamental este infinit si nenumarabil
* Experimentul H consta în masurarea temperaturii corporale.
o Spatiul fundamental E este alcatuit din toate valorile posibile ale temperaturii corporale, astfel putem considera ca în E intra toate valorile din intervalul [35, 41], sau ca
+ E = [35,41].
o In acest caz, spatiul fundamental este o multime infinita si nenumarabila.
18Spatiul fundamental este infinit si nenumarabil
* Experimentul H consta în masurarea tensiunii arteriale sistolice (TAS).
o Spatiul fundamental E este alcatuit din toate valorile posibile ale TAS, astfel putem considera ca E este inclus în intervalul [0, ¥).
o In acest caz, de asemenea, spatiul fundamental este o multime infinita si nenumarabila.
19Definitia axiomatica
* Fie E un spatiu fundamental asociat unui experiment H si W multimea tuturor evenimentelor, adica multimea partilor lui E:
* W = P(E) .
* Se spune ca functia Pr:W®R este o functie de probabilitate, iar prin Pr(A) se noteaza probabilitatea evenimentului A, daca satisface urmatoarele axiome:
* M1. 0 £ Pr(A) £ 1, " AÎW
* M2. Pr(E) = 1
* M3. Daca A si B sunt incompatibile (adica nu pot avea loc simultan) atunci
* Pr(AÈB) = Pr(A) + Pr(B).
20Definitia axiomatica
* Exemplu: (Hipertensiune) Fie A evenimentul ca o persoana sa aiba tensiune arteriala diastolica normala (TAD) adica TAD <90. Fie B evenimentul ca o persoana sa aiba TAD la limita, adica 90 £ TAD < 95. Presupunem ca Pr(A) = 0.7, Pr(B) = 0.1 . Fie C evenimentul ca o persoana are TAD < 95. Evident C=AÈB si AÇB=Æ. Atunci, Pr(C) =Pr(A) + Pr(B).
* O modalitate de a defini în mod concret functia de probabilitate este cu ajutorul unei "masuri" definite pe spatiul fundamental E, adica:
21Definitia axiomatica - proprietati
* T1. Daca
A1, A2, ..., An sunt evenimente incompatibile doua câte doua atunci: 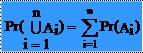
* Proprietatea T1 poate fi demonstrata usor prin inductie prin utilizarea axiomei M3.
22Definitia axiomatica - proprietati
* T2. Pr(Æ) = 0.
o Intr-adevar, deoarece oricare ar fi evenimentul A, el este incompatibil cu Æ, în baza axiomei M3, rezulta ca
o Pr(A) = Pr(AÈÆ) = Pr(A) + Pr(Æ).
* T3. Pr(non A) = 1 - Pr(A).
o Intr-adevar, din M3 rezulta usor ca:
o Pr(AÈ non A) = Pr(A) + Pr(non A),
o iar din M2 avem:
o Pr(AÈ non A) = Pr(E) = 1.
23Definitia axiomatica - proprietati
* T4. Daca AÍB atunci Pr(A) £ Pr(B).
* Intr-adevar, pentru ca B = A È (B -A) iar multimile A si B - A sunt disjuncte, aplicând axiomele M3 si M1 rezulta imediat ca:
* Pr(B) = Pr(A) + Pr(B-A) ³ Pr(A).
* T5. Pentru orice evenimente A si B are loc egalitatea:
* (1) Pr(AÈB) = Pr(A) + Pr(B) - Pr(AÇB) .
* Deoarece, AÈB = (A-B) È B, iar multimile A-B si B sunt disjuncte, în baza axiomei M3, rezulta ca:
* (2) Pr(AÈB) = Pr(B-A) + Pr(B).
24Definitia axiomatica - proprietati
* Pe de alta parte, fiindca A= (A-B) È (A Ç B), iar multimile (A-B) si (A Ç B) sunt disjuncte, prin M3 se obtine egalitatea:
* Pr(A) = Pr(A-B) + Pr(A Ç B)
* de unde rezulta:
* Pr(A-B) = Pr(A) - Pr(A Ç B).
* Insa, înlocuind Pr(A-B) astfel obtinut în (2), rezulta egalitatea (1) care trebuia demonstrata.
25PROBABILITĂŢI CONDIŢIONATE
26Probabilitate conditionata
* Daca A si B sunt doua evenimente arbitrare, prin probabilitatea conditionata a lui A de catre B, notata prin Pr(A/B), se întelege probabilitatea de a se realiza evenimentul A daca în prealabil s-a realizat evenimentul B.
* Prin
definitie: 
* sau raportul dintre numarul elementelor din B care sunt si în A la numarul elementelor lui B.
27Probabilitate conditionata
* Are loc
urmatoarea regula de calcul a probabilitatii
intersectiei a doua evenimente: ![]()
* sau
![]()
28Probabilitate conditionata
* Aceste formule sunt cunoscute si sub numele de regula generala de înmultire a probabilitatilor. Mai general au loc urmatoarele reguli de înmultire a probabilitatilor:
![]()
Testul / Afectiunea T pozitiv non (T) negativ Total
A a b a+b
non (A) c d c+d
Total a+c b+d n
* Pr(A) se numeste prevalenta afectiunii A.
33Sensibilitatea testului
* Probabilitatea,
notata cu Se, de a obtine un test pozitiv, stiind ca testul
este aplicat unei persoane care poseda afectiunea, se numeste
sensibilitatea testului se exprima cu ajutorul unei
probabilitati conditionate: 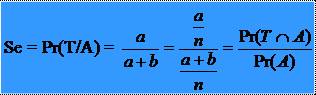
34Specificitatea testului
Pentru caracterizarea unui test diagnostic se utilizeaza si specificitatea testului care se defineste prin probabilitatea de a obtine un test negativ pentru o persoana care nu poseda afectiunea (probabilitate conditionata):
Testul / Afectiunea T pozitiv non (T) negativ Total
A a b a+b
non (A) c d c+d
Total a+c b+d n
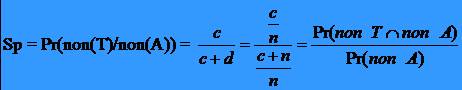
35Valoarea pozitiva predictiva VPP
* este probabilitatea
ca un test pozitiv sa indice o persoana cu afectiunea A: 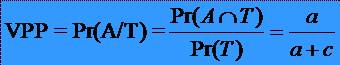
36Valoarea predictiva negativa VPN
* este probabilitatea ca un test negativ sa indice o persoana fara afectiune:
![]()
37Raportul de asemanare
* Likehood ratio (LR)
* LR = Se / (1-Sp)
* Un semn (test) diagnostic este cu atât mai bun cu cât are o Se si Sp mai apropiata de 1
38Exemplu
* Se masoara GOT la 94 de pacienti cu dureri toracice. Ne intereseaza numarul de infarcturi miocardice aparute la acest esantion
* Se=25/48=52,1%
* Sp=42/46=91,3%
Exemplu
lSe masoara GOT la 94 de pacienti cu dureri toracice. Ne intereseaza numarul de infarcturi miocardice aparute la acest esantion
.Se=40/48=83,3% .Sp=43/46=93,5%
GOT=<120 GOT>120
Infarct 40 8
Sanatosi 3 43
Prag=120 U
40Curba ROC
Receiving-Operating
Characteristic = reprezentarea grafica a valorii informationale a
unui test fata de un diagnostic în domeniul [Se, 1-Sp] atunci când
variaza pragul ales 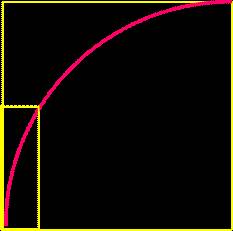
41Curba ROC generalizata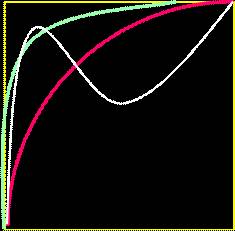
* Un test A este mai bun ca un test B daca:
o Se(A)>Se(B) si Sp(A)>=Sp(B)
o Sau: Sp(A)>Sp(B) si Se(A)>=Se(B)
* Nu se pot clasifica cele doua teste daca
o Se(C)>Se(B) si Sp(C)<Sp(B)
o Se(C)<Se(B) si Sp(C)>Sp(B)
42VPP, VPN
* Valoarea predictiva pozitiva VPP a unui test de screening este probabilitatea ca o persoana sa aiba boala daca testul este pozitiv, adica
* VPP =Pr(boala | test+).
* Valoarea predictiva negativa VPN a unui test de screening este probabilitatea ca o persoana sa nu aiba boala daca testul este negativ, adica
* VPN =Pr(nu boala | test-).
* Un simptom sau un set de simptome poate fi privit ca un test de sreening pentru o anumita boala. Cu cât mai mari sunt valorile predictive ale testului cu atât mai valoros este testul respectiv.
43VPP, VPN
* Clinicienii adesea nu pot masura direct valoarea predictiva a unui set de simptome. Totusi ei pot masura cât de frecvent apar simptomele la persoane bolnave si respectiv normale. Aceste masuri sunt definite astfel:
o Sensibilitatea unui simptom (sau set de simptome sau test de sreening) este probabilitatea ca simptomul sa fie prezent daca persoana are boala.
o Specificitatea unui simptom (sau set de simptome sau test de sreening) este probabilitatea ca simptomul sa nu fie prezent daca persoana nu are boala respectiva.
* Un fals negativ este o persoana pentru care testul este negativ dar care de fapt are boala.
* Un fals pozitiv este o persoana pentru care testul este pozitiv dar care de fapt nu are boala.
* Este important ca atât senzitivitatea cât si specificitatea sa fie ridicate pentru ca simptomul sau testul sa fie predictiv pentru o boala.
44Independenta a doua evenimente
* Doua evenimente A si B se numesc independente daca si numai daca
* Pr(AÇB) = Pr(A) × Pr(B).
* Aceasta proprietate se mai numeste si legea de înmultire a probabilitatilor.
* Doua evenimente A si B sunt dependente daca
* Pr(AÇB) ¹ Pr(A) × Pr(B).
* Au loc urmatoarele proprietati privind probabilitatile conditionate:
o Daca A si B sunt evenimente independente, atunci Pr(B|A) =Pr(B)
o Daca A si B sunt evenimente dependente, atunci Pr(B|A) ¹Pr(B) si Pr(AÇB)¹Pr(A) Pr(B).
45Independenta a doua evenimente
* Intr-adevar, egalitatile Pr(B/A) = Pr(B) si Pr(A/B) = Pr(A), exprima bine independenta celor doua evenimente prin faptul ca probabilitatea evenimentului B (respectiv A) nu depinde de realizarea evenimentului A (respectiv B).
* Urmatoarea proprietate se mai numeste si legea de adunare a evenimentelor independente.
* Daca A si B sunt doua evenimente independente, atunci Pr( A ÈB ) = Pr(A) + Pr(B) (1 - Pr(A)).
46Formula lui BAYES
* Sa consideram doua evenimente A si B care nu sunt independente. Atunci din formulele:
* si se deduce formula lui BAYES:
* Dar fiindca
o Pr(B) = Pr((BÇnonA) È (BÇA)) =Pr(BÇnonA) + Pr(BÇA),
* aplicând formula probabilitatilor conditionate se obtine:
o Pr(B)=Pr(B|A) Pr(A) + Pr(B|nonA) Pr(nonA).
* De aici
rezulta urmatoarea forma a formulei lui Bayes: ![]()
47Formula lui BAYES - exemplu
* Se stie
ca 60% din populatia dintr-o
* Fie A
evenimentul ca o persoana sa fie alergica, iar U evenimentul ca
o persoana sa locuiasca în mediul urban. Atunci probabilitatea
cautata este: 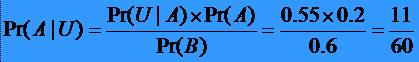
48Formula lui BAYES
* Formula lui Bayes poate fi utila în stabilirea unui diagnostic medical. Fie D o maladie si S un semn. In acest caz, se pot considera urmatoarele probabilitati:
o Pr(D/S) -
probabilitatea ca maladia D sa fie prezenta atunci când la un bolnav
s-a constatat semnul
o Pr(D) - probabilitatea lui D daca nu exista nici o informatie. Este de fapt frecventa maladiei D în ansamblul populatiei (prevalenta lui D). Aceasta probabilitate se numeste probabilitate a priori.
o
Pr(S/D)/Pr(S) este frecventa semnului S în cazul maladiei D raportata
la frecventa sa în ansamblul populatiei (care are sau nu maladia D).
Aceasta probabilitate se numeste valoarea diagnostica a lui S pentru
D (care va fi cu atât mai buna cu cât
Notes
Slide Show
[Pause/Play Narration]
[Previous Slide]
[Next Slide]
Outline
[Expand/Collapse Outline]
1Variabile aleatoare * Tudor Drugan* 2006-2007
2Definitie
* Fie E un spatiu fundamental care corespunde unui anumit experiment aleator. Nu este necesar ca rezultatele unui experiment aleator sa fie numere, dar este adesea util ca fiecarui rezultat sa i se atribuie o valoare numerica specifica. Prin aceasta operatie se creeaza o anumita variabila aleatoare.
* Se numeste variabila aleatoare pe un spatiu fundamental E si se noteaza prin X, o functie definita pe E cu valori în multimea numerelor reale.
* Unei variabile aleatoare X i se pot asocia diferite probabilitati cu care aceasta variabila aleatoare poate lua anumite valori, ca de exemplu:
o Pr( X = a) - probabilitatea ca "X sa ia valoarea a";
o Pr( a £ X £ b ) - probabilitatea ca "X sa ia o valoare în intervalul [a,b]".
3Definitie
* O variabila aleatoare se numeste discreta daca ea poate lua un numar finit sau cel mult numarabil de valori
4Exemple
* Numarul de internari într-un spital într-un interval de timp dat X=. Aceasta este o variabila aleatoare discreta infinita.
* Numarul de bacterii într-un mililitru de apa X=.
* Numarul de indivizi cu RH-negativ dintr-un grup de n persoane luate la întâmplare X=. Aceasta este o variabila aleatoare discreta finita
5Definitie
* O variabila aleatoare este continua atunci când variaza în mod continuu într-un interval si poate lua o multime nenumarabila de valori.
6Exemple
* temperatura corporala,
* concentratia unei substante în sânge,
* capacitatea pulmonara, etc.
7LEGEA DE PROBABILITATE A UNEI VARIABILE ALEATOARE FINITE
* Fie X o variabila aleatoare pe un spatiu fundamental E finit, adica
o X =.
* Multimea de probabilitati
o p(x1 ), p(x2 ), ..., p(xi), ..., p(xn )
* asociate valorilor:
* x1 , x2, ..., xi, ..., xn
* se numeste distributia sau legea de probabilitate a variabilei aleatoare X.
8LEGEA DE PROBABILITATE A UNEI VARIABILE ALEATOARE FINITE
* Distributia
unei variabile aleatoare finite X se mai noteaza prin urmatorul
tabel: 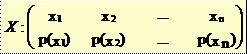
* Probabilitatile care apar în distributia unei variabile aleatoare finite X verifica urmatoarea conditie:
9Exemple
* Probabilitatea
de aparitie a uneia dintre fetele ale unui zar este
1/6. In acest caz avem variabila aleatoare: 
* Pentru ca
probabilitatea p(x) este
10Media sau speranta matematica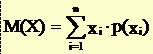
* Valoarea M(X) se mai numeste si valoarea asteptata a variabilei aleatoare X.
* Observatii:
o Daca legea de probabilitate a lui X este uniforma, adica p(xi) = 1/n , pentru orice i= 1,2,...,n, atunci M(X) este media aritmetica a numerelor x1 , x2, ..., xi, ..., xn.
11Variatia si abaterea standard
* Variatia variabilei aleatoare X se defineste prin
* V(X) = M( [X- M(X)]2)
* Sau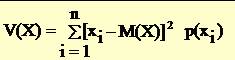
* Prin definitie abaterea standard este:
12Variabile aleatoare centrate reduse
* Unei variabile aleatoare X cu media M(X) si abaterea standard s(X) i se poate asocia o variabila aleatoare Y numita variabila aleatoare centrata redusa definita prin:
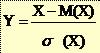
* In baza proprietatilor mediei si abaterii standard, se poate arata usor ca variabila aleatoare centrata redusa are media M(Y)=0 si abaterea standard s(Y)=1.
13VARIABILE ALEATOARE DEFINITE PE UN SPAŢIU FUNDAMENTAL INFINIT
14Cazul discret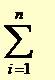
* Notiunile si proprietatile prezentate anterior pentru variabilele aleatoare finite se pot introduce în mod analog pentru cazul variabilelor aleatoare discrete având o multime infinita de valori, prin înlocuirea sumei finite cu una infinita
15Cazul continuu
* In cazul unei
variabile aleatoare continue X, se considera o functie f:R®R
numita densitate de probabilitate, care are proprietatile: 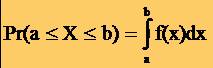
* f(x) ³ 0, " xÎR
16Cazul continuu
* In acest caz functia de repartitie F asociata variabilei aleatoare X este definita prin:
* De
asemenea, media lui X este definita
prin : ![]()
* iar variatia
lui X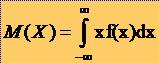
17Legi de distributie
(principalele distributii de probabilitate)
18Introducere
* In general distributiile variabilelor definite pe o populatie, care face obiectul unui studiu, nu se cunosc.
* Din punct de vedere practic se încearca încadrarea acestor distributii în unele legi teoretice care constituie modele pentru aceste variabile statistice
19Principalele legi de distributie
* legea normala sau legea LAPLACE-GAUSS
o variabile aleatoare continue
* legea BINOMIALĂ (BERNOULLI)
o variabile aleatoare finite
* legea POISSON
o variabile aleatoare discrete infinite
* legea STUDENT (t)
* legea c2 a lui PEARSON
* legea F a lui FISHER.
20LEGEA NORMALĂ
* Aceasta lege de probabilitate a carei functie de probabilitate are o alura tipica de clopot numita curba normala sau curba lui Gauss este un model pentru multe variabile aleatoare continue
* Aceasta distributie depinde de doi parametri:
o media m
o abaterea standard s
* si are
densitatea de probabilitate urmatoare: 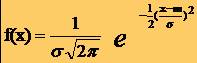
21LEGEA NORMALĂ
* Daca X satisface o lege normala de medie m si abatere standard s atunci se spune ca X este de tipul N(m, s).
* Pentru variabila normala X au loc:
o M(X) = m
o Var(X) = s.
22LEGEANORMALĂ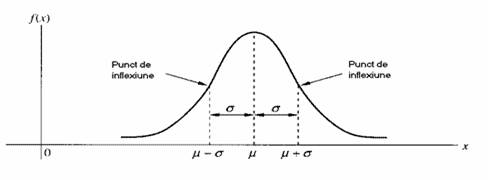
23LEGEA NORMALĂ REDUSĂ
* Este evident ca exista o gama infinita de legi normale, care corespund câte unei perechi de parametri (m, s).
* Toate aceste
distributii normale se pot reduce la una singura, având media 0
si abaterea standard 1, cu ajutorul unei schimbari de variabila:
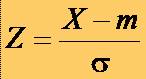
24LEGEA NORMALĂ REDUSĂ
* Aceasta este
legea normala redusa cu densitatea de probabilitate: 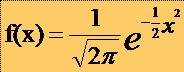
25LEGEA NORMALĂ REDUSĂ
* Acestei legi de probabilitate îi sunt asociate un anumit numar de tabele care permit utilizarea practica a acestei legi.
* Unul dintre aceste tabele este Tabelul p(u) care contine pentru fiecare valoare u probabilitatea ca variabila Z sa fie în exteriorul intervalului [-u,u].
* De asemenea, un alt tabel asociat legii normale reduse este Tabelul abaterii standard.
* Au loc relatiile
o p(u) =Pr( Z < -u sau Z> u)
o Pr(-u £ Z £ u) =1 - p(u).
* Astfel din tabelul ecartului redus p(1) = 0.32 si deci 1- p(1) = 0.68, iar p(1.96) =0.05 si deci 1- p(1) =0.95
26LEGEA NORMALĂ REDUSĂ
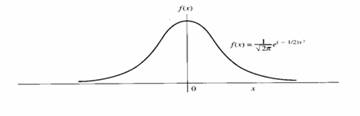
27LEGEA BINOMIALĂ SAU DISTRIBUŢIA LUI BERNOULLI
* Variabile aleatoare finite
* Modelul legii binomiale este urmatorul:
o Un experiment este alcatuit din repetarea unei încercari elementare de n ori, n fiind un numar natural dat.
o Rezultatele posibile ale fiecarei încercari elementare sunt doar doua evenimente numite de obicei: succes (S) si esec (E).
o Probabilitatile p de succes si q = 1 - p de esec sunt constante de la o încercare la alta.
o Cele n încercari repetate sunt independente una de cealalta
28LEGEA BINOMIALĂ SAU DISTRIBUŢIA LUI BERNOULLI
* Numarul de succese obtinute din cele n încercari repetate este o variabila aleatoare de tip binomial care depinde de parametrii n si p si este de obicei notata prin Bi(n,p). Aceasta variabila aleatoare X poate sa ia valorile 0, 1, 2, ..., n si are urmatorul tabel de distributie:
29LEGEA BINOMIALĂ SAU DISTRIBUŢIA LUI BERNOULLI
* speranta matematica a legii binomiale este:
* M(X) = n p,
* iar variatia:
* Var(X) =n p q,
* si deci abaterea standard:
30Comportarea la limita a legii binomiale când n este mare
* Se poate arata ca atunci când np ³ 10 si nq ³ 10, distributia variabilei binomiale X (frecventa absoluta a succeselor) tinde sa se apropie de o lege normala
31Exemple
* Presupunem ca de regula un anumit vaccin contra pojarului produce o reactie (febra) cu o probabilitate p=0.15 . Care este probabilitatea ca din 6 copii vaccinati 4 sa aiba o reactie în urma vaccinarii?
* Raspuns: In acest caz avem n = 6, k = 4, p =0.15, q = 1-p = 0.85 . Atunci
![]()
* Aceasta probabilitate fiind mai mica de 1% se poate considera ca aceasta situatie apare cu o sansa foarte mica.
32Exemple
* Presupunem
ca de regula un anumit vaccin contra pojarului produce o reactie
(febra) cu o probabilitate p=0.5 . Care este probabilitatea ca din 600
copii vaccinati cel putin 4 sa aiba o reactie în urma
vaccinarii? ![]()
33LEGEA LUI POISSON
* Variabila aleatoare POISSON este o variabila discreta care ia o infinitate numarabila de valori: 0,1,2,...,k,... , care reprezinta numarul de realizari într-un interval dat de timp sau spatiu ale unui eveniment
* de exemplu
o numarul de internari pe an într-un spital,
o numarul de bacterii într-un mililitru de apa,
o numarul de dezintegrari ale unei substante radioactive într-un interval de timp T dat
34LEGEA LUI POISSON
* Modelul acestei variabile aleatoare presupune ca sunt îndeplinite urmatoarele conditii:
o numarul de realizari ale evenimentului într-un interval este independent de numarul de realizari în orice alt interval (repartitie aleatoare în timp sau spatiu),
o numarul asteptat de realizari într-un interval este proportional cu dimensiunea sa si nu depinde de pozitia sa în timp sau spatiu,
o într-un interval suficient de mic probabilitatea de a observa mai mult de o realizare a evenimentului este neglijabila în raport cu probabilitatea de a observa una singura (nesimultaneitatea realizarii a doua evenimente în timp sau spatiu).
35LEGEA LUI POISSON
* Aceasta
variabila aleatoare X este caracterizata de un parametru q care
reprezinta numarul mediu teoretic (asteptat) de realizari
ale evenimentului în intervalul considerat si are urmatoarea lege de
distributie: 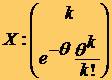
36LEGEA LUI POISSON
* Despre variabila
aleatoare de tip Poisson X se mai spune ca este de tipul
* Speranta matematica si variatia în cazul legii lui Poisson sunt egale ambele cu q, adica :
* M(X) = Var(X) = q.
37Exemple
* Rata de
mortalitate pentru o anumita boala este de 7 la 1000 de cazuri. Care
este probabilitatea ca într-un grup de 400 de persoane aceasta boala
sa cauzeze 5 decese? 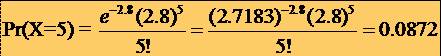
* Raspuns: Avem p =7/1000=0.007, m = np = 400 x 0.007= 2.8
38Exemple
* Rata de mortalitate pentru o anumita boala este de 10 la 1000 de cazuri. Care este probabilitatea de a avea mai putin de 7 decese într-un grup de 500 persoane? Care este probabilitatea de a avea 7 sau mai multe decese într-un grup de 500 persoane?
* Raspuns: Avem
* p =10/1000=0.01, m = np = 500 x 0.01= 5
* Probabilitatea
de a avea mai putin de 7 decese este: ![]()
* Probabilitatea de a avea 7 sau mai multe decese este:
* Pr(X³7) = 1- Pr(X<7) = 0.2378
39LEGEA STUDENT (T)
* Variabila aleatoare Student t este o variabila aleatoare continua care ia valori în intervalul (-¥ , +¥ ), a carei functie densitate de probabilitate depinde de un singur parametru, numarul de grade de libertate.
* Fie X0, X1, ., Xn variabile aleatoare independente care toate urmeaza legea normala centrata redusa. Atunci variabila aleatoare
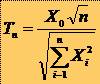
* urmeaza o lege de probabilitate Student cu n grade de libertate.
40LEGEA STUDENT (T)
* Densitatea de
probabilitate a variabilei aleatoare Student Tn este: 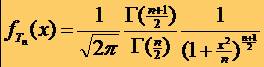
* unde G este
functia Gamma definita astfel: 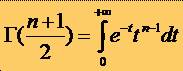
41LEGEA STUDENT (T)
* Distributia acestei variabile aleatoare este simetrica în raport cu originea si are o forma de clopot:
o Pr[ Tk < -x ] = Pr[ Tk > x].
* Atunci când k tinde la ¥, distributia Student tinde catre o distributie normala redusa.
* Daca n>30 legea lui Student si legea normala sunt foarte apropiate.
* Aceasta variabila aleatoare este utilizata, în anumite conditii de normalitate, în testul de comparatie a mediilor numit si testul Student sau testul t.
42LEGEA HI-PĂTRAT (PEARSON)
* Distributia
c2 descrie comportarea unei sume de patrate a unor variabile independente
normal distribuite, fiecare având o medie egala cu zero si abatere
standard egala cu 1. Astfel variabila X, definita prin egalitatea![]()
* Unde Xi2 reprezinta patratul unei observatii selectate aleator dintr-o populatie normal distribuita având media zero si deviatia standard 1, este c2 distribuita cu n grade de libertate.
* Densitatea de
probabilitate a legii c2 este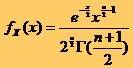
43LEGEA HI-PĂTRAT (PEARSON)
* Forma acestei distributii depinde de numarul de termeni Xi2 independenti din suma. Numarul de termeni Xi2 independenti se numeste numarul de grade de libertate .
* Fiecarui nivel d al gradelor de libertate i se asociaza o distributie c2 distincta. Media si variatia unei distributii c2 sunt :
* M(c2) = d, Var(c2 ) = 2 d,
* unde d este numarul de grade de libertate.
44LEGEA F (FISHER)
* Distributia F introdusa de R. A. Fisher, este definita pe intervalul [0,+¥) si descrie comportarea câtului a doua variabile cu distributie Hi-patrat fiecare fiind împartita prin numarul gradelor sale de libertate.
* Un membru al acestei clase de distributii este determinat prin numarul de grade de libertate ale numaratorului dn si respectiv numarul de grade de libertate ale numitorului dm, distributiile F distincte fiind determinate de perechi (dn, dm) distincte.
45LEGEA F (FISHER)
* In general, pentru dn si dm > 2 distributia F este unimodala si pozitiv asimetrica. Atunci când numarul gradelor de libertate creste distributia F se apropie pe domeniul sau de definitie de o distributie normala.
* Aceasta distributie este utilizata în testele de comparatie a variatiilor si ca aplicatie a acestora în testele ANOVA.
46DISTRIBUŢII DE EsANTIONARE
47POPULAŢIA DE EsANTIOANE
* Atunci când se doreste evaluarea, într-o populatie, valoarea medie a unui caracteristici cantitative (talia, greutatea, vârsta, cantitatea de uree din sânge, etc.) sau proportia (frecventa) acelor elemente ale populatiei care prezinta un caracter dat, cel mai frecvent nu dispunem decât de esantioane (selectii, grupe) extrase din aceasta populatie.
* Chiar daca aceste esantioane au fost extrase fara nici o grija ca sa fie "reprezentative", media sau proportia pe care o furnizeaza se îndeparteaza mai mult sau mai putin de valorile lor exacte (teoretice) datorita hazardului esantionarii.
48POPULAŢIA DE EsANTIOANE
* Astfel, dintr-o populatie data P, se pot extrage în diferite moduri esantioane de o dimensiune n data.
* Multimea esantioanelor posibil de extras din populatia P constituie o noua populatie numita "populatia de esantioane".
49POPULAŢIA DE EsANTIOANE
* Estimarea caracteristicilor unei populatii pe baza esantioanelor este fundamentata pe ideea ca acestea sunt aleatoare si reprezentative pentru populatia respectiva.
* Într-un esantion real, chiar ales aleator, nu putem fi siguri ca o anumita caracteristica va fi identica cu cea a populatiei.
* Chiar si numarul redus de cazuri dintr-un esantion poate perturba o caracteristica.
* Esantionarea aleatoare implica "dreptul" fiecarui membru al populatiei de a fi ales dar nu garanteaza reprezentativitatea proportionala a tuturor partilor unei populatii.
50POPULAŢIA DE EsANTIOANE
* In cele ce urmeaza, utilizând aceasta populatie de esantioane se vor studia, în special, proportiile, mediile si variatiile observate (f, m, s2).
* Daca extragerea esantioanelor E1, E2, ..., Ek, ... este întâmplatoare, acest fapt conduce la valori diferite pentru cantitatile f, m si s2.
* Se spune ca ele au fluctuatii de esantionare. In realitate ele sunt variabile aleatoare a caror distributie se va studia în cele ce urmeaza.
51DISTRIBUŢIA DE EsANTIONARE A UNEI MEDII OBSERVATE
* Sa consideram o variabila cantitativa X, având în populatia P o medie m si un ecart-tip s. Se extrag la întâmplare din populatia P esantioanele E1,E2,...,Ek,... care au toate acelasi efectiv n. Fie m = (m1, m2, ..., mk,...) variabila aleatoare care ia ca valori mediile observate ale variabilei X pe esantioanele E1,E2,..., Ek, ... .
* Speranta
matematica sau media acestei variabile aleatoare este: ![]()
* Insa
tinând seama de proprietatile mediei unei variabile aleatoare
rezulta ca: ![]()
52DISTRIBUŢIA DE EsANTIONARE A UNEI VARIABILE CALITATIVE
* Se considera o variabila calitativa Y cu proprietatea ca o "valoare" a ei are o frecventa relativa (sau o proportie) p în populatia P.
* Pentru esantioanele E1, E2, ..., Ek, ... având acelasi efectiv si extrase aleator din populatia P se observa frecventele f1, f2, ..., fk, ... pentru valoarea considerata. Datorita fluctuatiilor de esantionare frecventele esantioanelor alcatuiesc o variabila aleatoare de esantionare f = (f1, f2, ..., fk, ...).
* Se poate arata ca pentru aceasta variabila aleatoare de esantionare:
* M(f) = p iar , unde q = 1 -p,
* si deci abaterea ei standard este![]()
53Intervalul de pariu
* Fiind data o variabila aleatoare X, careia i se cunoaste distributia în populatia P se pune problema determinarii unui interval [a,b] care contine cu o probabilitate data egala cu 1-a orice valoare a lui X obtinuta prin extragere întâmplatoare din P.
* Acest interval se numeste intervalul de pariu cu riscul a pentru X . Astfel se poate afirma, înainte de extragerea unei valori a lui X, ca aceasta va fi în interval cu riscul a de eroare.
54Intervalul de pariu pentru o medie observata
* Intervalul de
pariu cu riscul a pentru o medie observata pe esantioane de talie n
extrase dintr-o populatie P pentru
o variabila aleatoare X de tipul N(m,s) este de forma: 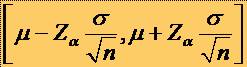
* unde Za este valoarea ecartului tip corespunzatoare probabilitatii a
55Intervalul de pariu pentru o frecventa observata
* La fel ca mai sus, intervalul de pariu cu riscul a pentru o frecventa observata pe esantioane de talie n extrase dintr-o populatie P pentru o variabila aleatoare X calitativa, care are un caracter ce apare cu frecventa teoretica p în populatia P, este de forma:
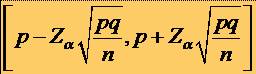
* unde Za este valoarea ecartului tip corespunzatoare probabilitatii a , iar q = 1 - p.
Notes
Slide Show
[Pause/Play Narration]
[Previous Slide]
[Next Slide]
Outline
[Expand/Collapse Outline]
1ESTIMAREA PARAMETRILOR STATISTICI
2Probabilitati
* = sansa ca un eveniment sa aiba loc considerând toate rezultatele posibile
* Valoarea predictiva a probabilitatii:
o Reflecta ce "ar trebui" sa se întâmple si nu ce o sa se întâmple efectiv
o Pentru un pacient supus unei operatii cu o rata de succes de 75% rezultatul nu poate fi 75% succes
* Probabilitatea poate fi privita ca o masura a capacitatii esantionului analizat de a estima caracteristica unei populatii
3Exemplu: distributia greutatii
* Media = 69, s = 3
o p=0,68
* Mai mare de 78 (198)
o P=0,0013
4Principii generale
* In studiul într-o populatie P a parametrilor a unei caracteristici oarecare (cantitative sau calitative) adesea este necesar sa se urmeze procedeul:
o Se extrage un esantion reprezentativ al acestei populatii.
o Prin mijloacele statisticii descriptive se descrie distributia caracteristicii pe esantionul extras la etapa 1, fiindca talia acestuia permite o investigare exhaustiva a sa. Astfel se poate determina frecventa observata, daca este vorba de o caracteristica calitativa, sau se calculeaza media si variatia, în cazul unei caracteristici cantitative.
o Prin mijloacele statisticii inferentiale sau inductive se extind la întreaga populatie rezultatele observate pe esantion. Adica, pornind de la parametrii observati (frecventa, media, variatia, etc) pe esantion se încearca sa se estimeze parametrii "teoretici" ai întregii populatii.
5Principii generale-(desen, cele de la pct.4)
6Principii generale
* Cazul unei variabile X calitative
* Frecventa teoretica p a variabilei X în populatia P este necunoscuta.
* Din populatia P se extrage la întâmplare esantionul E reprezentativ.
* In esantionul E pentru variabila X se observa o frecventa f.
* Se încearca sa se estimeze valoarea necunoscuta a lui p cu ajutorul lui f observat.
7Principii generale
* Cazul unei variabile X cantitative
o Media teoretica m a variabilei X ca si variatia sa teoretica s2 în populatia P sunt necunoscute.
+ Din populatia P se extrage la întâmplare esantionul E reprezentativ.
+ In esantionul E pentru variabila X se observa o medie m si o variatie s2.
+ Se încearca sa se estimeze valorile necunoscute ale lui m si s2 cu ajutorul lui m si s2 observate.
8Principii generale(desen-cele de la pct.7)
9ESTIMAREA PUNCTUALĂ
* Definitia unui estimator
o Estimatorul unui parametru este o functie depinzând de observatiile efectuate pe un esantion extras la întâmplare care furnizeaza o valoare aleatoare numita estimarea punctuala a parametrului.
+ Daca esantionul E are valorile x1,...,xn pentru caracteristica studiata, estimatorul mediei aritmetice m a unei populatii P este m = (x1+x2+...+xn)/n
10ESTIMAREA PUNCTUALĂ
* Calitatile unui estimator
o Calitatile unui estimator:
o corectitudinea estimarii obtinute,
o precizia acesteia.
o Cele doua notiuni sunt distincte cum va rezulta si din prezentarea care urmeaza.
11Principii generale
12ESTIMAREA PUNCTUALĂ
* Estimator fara bias
o Fie T estimarea punctuala a unui parametru teoretic q al unei populatii.
o T este o variabila aleatoare valorile ei variînd întâmplator odata cu esantionul pe baza caruia se calculeaza.
o Estimatorul T se spune ca este fara bias daca speranta matematica a lui T este egala cu valoarea adevarata (teoretica) a parametrului estimat adica M(T) = q.
o Se spune în acest caz ca estimarea data de T este corecta.
13ESTIMAREA PUNCTUALĂ
* Proprietati ale estimatorilor medie si frecventa:
+ P1. Speranta matematica a mediilor observate, m, pe esantioane extrase aleator este egala cu media teoretica m a populatiei din care sau extras esantioanele, medie considerata pentru valorile unei variabile cantitative luata în studiu: M(m) = m.
+ P2. Speranta matematica a frecventelor observate, f, pe esantioane extrase aleator este egala cu frecventa teoretica p a populatiei din care sau extras esantioanele, frecventa considerata pentru valorile unei variabile calitative luata în studiu: M(f) = p
+ Din P1 si P2 rezulta ca m si f sunt estimatori fara bias si ca estimarile realizate cu ajutorul lor sunt corecte.
14ESTIMAREA PUNCTUALĂ
* P3. Speranta matematica a variatiilor descriptive observate s2 pe esantioane de talie n, extrase aleator este diferita de variatia teoretica s2 a populatiei din care sau extras esantioanele, variatie considerata pentru valorile unei variabile cantitative luata în studiu:
![]()
* P4.
Variatia punctuala de esantionare este un estimator
fara bias pentru s2: ![]()
15Concluzie
* Media, frecventa si variatia de esantionare observate pe esantioane corect extrase (reprezentative) dintr-o populatie P sunt estimatori fara bias ale mediei, frecventei si respectiv variatiei teoretice ale populatiei P
16ESTIMAREA CU INTERVALE DE INCREDERE
* Se spune despre un estimator ca este cu atât mai eficace cu cât variatia sa este mai mica, sau ca precizia sa depinde marimea variatiei sale.
* Estimarea punctuala a unui parametru teoretic furnizeaza o valoare pentru parametrul teoretic estimat.
* Valoarea sa este tributara fluctuatiilor de esantionare si poate fi la o mare distanta de valoarea reala a parametrului estimat.
* Este recomandabil sa se estimeze un parametru teoretic nu printr-o singura valoare ci printr-un interval, numit interval de încredere, în care sa se poata afirma ca parametrul estimat se gaseste cu o probabilitate ridicata.
17ESTIMAREA CU AJUTORUL INTERVALULUI DE INCREDERE
* Intervalul de încredere este un interval marginit de valori (limitele poarta numele de limite de încredere) care include media caracteristicii studiate.
* Cu cât intervalul este mai larg cu atât suntem mai siguri ca media caracteristicii studiate se va regasi în acel interval.
* Marimea încrederii, confidenta, este data de probabilitatea ca valoarea (valorile) studiate sa se gaseasca în acel interval.
18ESTIMAREA UNEI MEDII
* Fie P o
populatie în care variabila X are o media teoretica m
necunoscuta. Din populatia P se extrage la întâmplare esantionul
E reprezentativ. In esantionul E pentru variabila X se observa o
medie m si se calculeaza o variatie punctuala estimata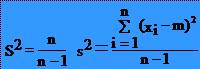
* Se încearca sa se determine pentru valoarea necunoscuta a mediei teoretice m un interval de încredere cu pragul a, (cu ajutorul lui m si S2 observate), adica sa se determine un interval [a,b] în care probabilitatea ca media teoretica m sa se afle este 1-a:
* Pr(a£ m £b) = 1 - a.
19ESTIMAREA UNEI MEDII: ESANTIOANE MARI
* N>=30
* media de esantionare m este o variabila aleatoare normala
* Atunci variabila aleatoare centrata redusa este o variabila aleatoare N(0,1).
* Pentru un prag
de semnificatie a se determina (de exemplu, din tabela ecartului
redus) valoarea Za pentru care probabilitatea ca variabila aleatoare Z sa
fie în intervalul [-Za,Za] este 1-a, adica: ![]()
* Pr(-Za £ Z £ Za) = 1 - a.
20ESTIMAREA UNEI MEDII: ESANTIOANE MARI
* Deci cu o
probabilitate 1-a se poate afirma ca are loc: 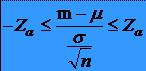
* de unde
rezulta : 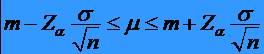
21ESTIMAREA UNEI MEDII: ESANTIOANE MARI
* Prin urmare,
intervalul de încredere pentru media m cu pragul de semnificatie a este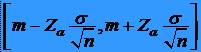
* Atunci când s nu
se cunoaste, el poate fi estimat corect prin si în acest caz intervalul de încredere
cu pragul de semnificatie a pentru media m este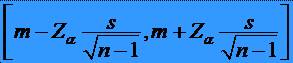
22ESTIMAREA UNEI MEDII: ESANTIOANE MARI
* Cel mai frecvent se utilizeaza un prag de semnificatie a = 0.05. Atunci Za=1.96 si deci intervalul de încredere cel mai utilizat în cazul esantioanelor mari este
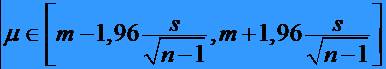
23Exemplu
* Într-o populatie cunoastem media greutatii la nastere a noilor nascuti: 3400g si abaterea standard: 142
* Pe un esantion aleator de 10 nou nascuti:
o media=3275g, abaterea standard=854
o Esantionul este sau nu caracteristic pentru populatie?
* Esantionarea aleatoare implica "dreptul" fiecarui membru al populatiei de a fi ales dar nu garanteaza reprezentativitatea proportionala a tuturor partilor unei populatii
* Alt esantion à alta medie, alta abatere
24Exemplu
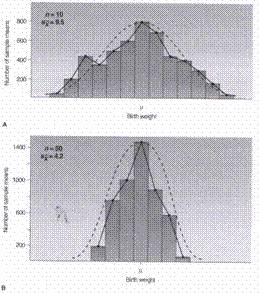
* A - distributia de esantionare a mediei pentru n=10
* B - distributia de esantionare a mediei pentru n=50
* Pe masura ce creste n eroarea de esantionare scade si esantioanele devin mai reprezentative, media lor este mai apropiata de cea a populatiei
25Exemplu (continuare)
* Deviatia standard a distributiei de esantionare este un indicator al erorii de esantionare
26Deviatia standard a distributiei de esantionare
* În practica
este imposibil sa construim distributia de esantionare à
estimarea deviatiei standard a mediei pe baza deviatiei standard
si a dimensiunii esantionului: 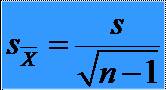
27Exemplu (continuare)
* A = media=115, abaterea standard=30
o Sx=9,5
* B = media=115, abaterea standard=30
o Sx=4,2
* Pe masura ce creste n scade eroarea standard a mediei
* Aproximarea distributiei populatiei
28ESTIMAREA UNEI MEDII: ESANTIOANE MICI
* se poate determina intervalul de încredere al mediei m doar daca variabila studiata X este o variabila aleatoare normala.
* Daca se cunoaste
variatia: 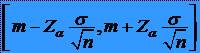
* Nu se cunosate variatia si n<30
29ESTIMAREA UNEI FRECVENTE
* Esantioane mari np, nq>=10
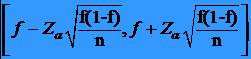
* F este frecventa observata
30Eroarea de esantionare a mediei
* = diferenta dintre media valorilor esantionului si media caracteristici populatiei din care a fost extras esantionul
* Cresterea erorii de esantionare =>
o Scaderea acuratetii mediei esantionului de a estima caracteristica unei populatii
* Scaderea erorii de esantionare =>
o Cresterea acuratetii mediei esantionului de a estima caracteristica unei populatii
31Exemplu
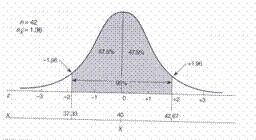
* Studiul Fitzgerald al mobilitatii prin extensie a coloanei lombare la indivizi de vârste cuprinse între 30 si 39 de ani
* n=42, media=40° si s=8,8 °
* Media populatiei poate fi estimata la 40 °
o Care este acuratetea acestei estimari?
o Cum estimam intervalul de încredere?
32Intervale de încredere
* = este un interval marginit de valori (limitele poarta numele de limite de încredere) care include media caracteristicii studiate
* Cu cât intervalul este mai larg cu atât suntem mai siguri ca media caracteristicii studiate se va regasi în acel interval
o Marimea încrederii à probabilitate
* Încrederea (confidenta) 95%
33Exemplu (continuare) 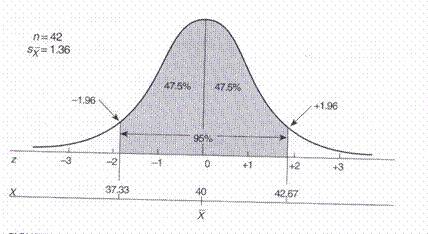
* n=42, media=40°, s=8,8° à Sx=1,36
* 95,45% din distributie este cuprinsa între ±2Sx sau ±2Z
34Exemplu (continuare)
* Estimarea zonei de 95%
* Este marginita de un scor Z de ± 1,96
* Interval de încredere de 95%
35Intervale de încredere
* Formula de
determinare a limitelor intervalului de încredere: 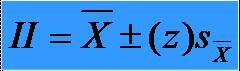
36Exemplu (continuare)
* 95% II = 40,0± (1,96)(1,36)
* 95% II = 40,0±2,67
* 95% II = 37,33 pâna la 42,67
37Exemplu 99%
* Z = ± 2,576
* 99% II = 40,0± (2,576)(1,36)
* 99% II = 40,0±3,50
* 99% II = 36,5 pâna la 43,5
38Intervale de încredere cu esantioane mici
* n<30
* Cu cât esantioanele sunt mai mici cu atât distributia de esantionare este mai dispersata fata de distributia normala
* Se foloseste o alta distributie: distributia t sau Student
* Diferenta majora dintre distributia t si cea normala consta în faptul ca prima îsi schimba forma odata cu schimbarea dimensiunii esantionului
39Calculul intervalului de încredere
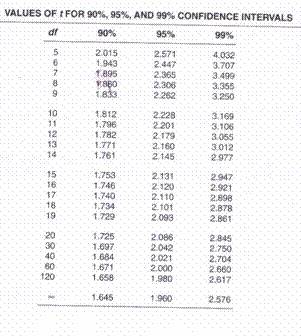
* df = n+1
* df = grade de libertate
40Grade de libertate
* df
* Directiile disponibile pentru miscare într-un spatiu dat
* Numarul de componente care pot varia într-un set de date
* n-1
41Grade de libertate - Exemplu
* 5 masuratori, avem o suma de 30 si o medie de 6
* Dupa ce face primele 4: 8,9,10,11 a cincea poate fi calculata si setul de date are numai 4 grade de libertate
42Calculul intervalului de încredere
* n=6 à df = 5
o II95% à t= ±2,571
* n=10 à df = 9
o II95% à t= ±2,262
* n=30
o II95% à t= ±2,042
* Cresterea lui n determina ca valoarea lui t sa se apropie de 1,96 à curba tinde spre distributia normala
43Aplicatii ale intervalelor de încredere
* Studiul Fitzgerald a stabilit cu o precizie de 95% intervalul de încredere pentru extensia lombara la diferite grupe de vârsta
44Aplicatii ale intervalelor de încredere
* Interpretare:
o 1. Intervalul de încredere al extensiei lombare scade cu vârsta
o 2. Variabilitatea este mai scazuta la tineri
o 3. Intervalele de încredere se întrepatrund
Notes
Slide Show
[Pause/Play Narration]
[Previous Slide]
[Next Slide]
Outline
[Expand/Collapse Outline]
1REGRESII
* LEGATURA INTRE MAI MULTE VARIABILE CANTITATIVE
2Statistici descriptive în doua dimensiuni
* Varsta X: X1, X2,..., Xn
* TAS Y: Y1, Y2,..., Yn.
* Sa se stabileasca daca exista o legatura între variabilele X si Y si sa se determine o modalitate de a masura intensitatea acestei legaturi.
o Coeficientul de corelatie
3Statistici descriptive în doua dimensiuni
* Sa se stabileasca daca Y depinde de X si daca da în ce forma se realizeaza aceasta dependenta.
o Functia de regresie
4DIAGRAMA DE DISPERSIE
* Diagrama de dispersie asociata unei tabel de date bidimensional:
o X: X1, X2,..., Xn
o Y: Y1, Y2,..., Yn
* se obtine reprezentând grafic punctele de coordonate (Xi,Yi) i=1,2,...,n.
5Diagrama de dispersie
* Orientarea si dispersia norului de puncte poate da o prima idee despre relatia între cele doua variabile aflate în studiu.
* In acest sens, o idee ceva mai precisa privind relatia între cele doua caracteristici se obtine împartind diagrama de dispersie în patru cadrane prin doua drepte perpendiculare care trec prin punctul (Xmediu,Ymediu), având coordonatele egale cu mediile celor doua variabile.
6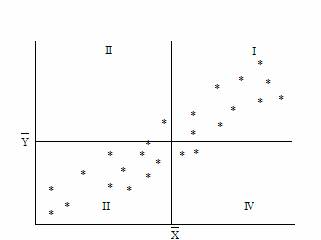 Diagrama
de dispersie
Diagrama
de dispersie
7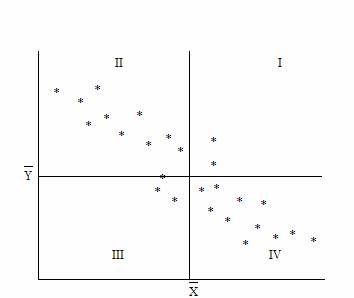 Diagrama
de dispersie
Diagrama
de dispersie
8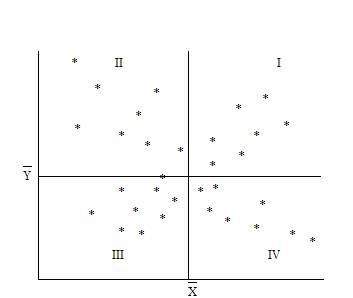 Diagrama
de dispersie
Diagrama
de dispersie
9Indici de corelatie - Suma produselor ecart
Pentru a descrie "intensitatea" relatiei dintre cele doua variabile X si Y se utilizeaza observatia ca daca punctul (Xi,Yi) se afla în cadranele I sau III ale diagramei de dispersie atunci produsul este pozitiv iar atunci când este situat în cadranele II si IV este negativ. Astfel ca o masura a intensitatii relatiei dintre variabilele X si Y este data de suma:
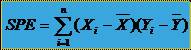 SPE va fi cu
atât mai mare în valoare absoluta cu cât norul de puncte este mai apropiat
de o alura generala crescatoare (SPE > 0 ) sau
descrescatoare (SPE < 0). Un dezavantaj evident al SPE este faptul
ca acest coeficient depinde de numarul de puncte din seria
statistica si de unitatile de masura ale
variabilelor
SPE va fi cu
atât mai mare în valoare absoluta cu cât norul de puncte este mai apropiat
de o alura generala crescatoare (SPE > 0 ) sau
descrescatoare (SPE < 0). Un dezavantaj evident al SPE este faptul
ca acest coeficient depinde de numarul de puncte din seria
statistica si de unitatile de masura ale
variabilelor
10Indici de corelatie -Covarianta COV(X,Y) Pentru a obtine o marime independenta fata de volumul seriei statistice se utilizeaza covarianta seriilor X si Y, calculata prin:
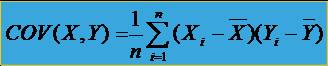
11Coeficientul de corelatie Pearson
Pentru a obtine un indicator independent si de
unitatile de masura ale celor doua variabile se
utilizeaza coeficientul de corelatie sau coeficientul Bravais-Pearson 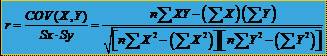 unde SX si SY reprezinta abaterile
standard pentru seriile X si respectiv Y:
unde SX si SY reprezinta abaterile
standard pentru seriile X si respectiv Y: 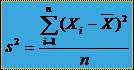
Unde s este variatia
12Interpretarea coeficientului de corelatie
* Coeficientul de corelatie masoara intensitatea relatiei dintre variabilele X si Y si valoarea sa r este totodata cuprinsa între -1 si 1.
* Daca r=1 punctele sunt situate pe o dreapta de panta pozitiva (crescatoare).
* Daca 0 < r < 1, norul de puncte poate fi înlocuit (ajustat) printr-o dreapta de panta pozitiva .
* Dispersia punctelor în jurul dreptei de regresie va fi cu atât mai mare cu cât r se apropie de 0 si cu atât mai mica cu cât r se apropie de 1.
* Daca -1 < r < 0 atunci norul de puncte poate fi aproximat cu o dreapta de panta negativa. Dispersia punctelor fata de dreapta va fi cu atât mai mica cu cât r este mai apropiat de -1.
* Daca r=-1 atunci toate punctele sunt situate pe o dreapta de panta negativa.
13Alura norului de puncte
* Când r este pozitiv relatia între variabilele X si Y este "pozitiva", adica o crestere a lui X determina în general o crestere a lui X.
* Când r < 0 relatia între cele doua variabile este "negativa" adica o crestere a lui X are în general ca si consecinta o diminuare a lui Y.
14Regulile empirice
* un coeficient de corelatie de la -0.25 la 0,25 înseamna o corelatie slaba sau nula,
* un coeficient de corelatie de la 0.25 la 0.50 (sau de la -0.25 la -0.50) înseamna un grad de asociere acceptabil
* un coeficient de corelatie de la 0.5 la 0.75 (sau de la -0.5 la -0.75) înseamna o corelatie moderata spre buna
* un coeficient de corelatie mai mare decât 0.75 (sau mai mic decât -0.75) înseamna o foarte buna asociere sau corelatie
15Testul de semnificatie pentru coeficientul de corelatie Pearson
* Semnificatia coeficientului de corelatie Pearson poate fi evaluata daca valoarea observata a aparut datorita întâmplarii (daca este semnificativ diferita de zero). Valorile critice ale lui r pot fi regasite în Anexa 6 pentru n-2 grade de libertate în cazul aplicarii testului unilateral sau bilateral.
* De exemplu obtinerea unei valori mai mici a lui r decât cea corespunzatoare din tabelul din anexa 6 denota ca valoarea este mai mica decât valoarea critica obtinuta din tabel si ipoteza nula nu poate fi rejectata. Interpretarea este ca datele experimentale nu ne permit enuntarea existentei unei relatii între variabilele luate în calcul
16Corelarea rangurilor: coeficientul de corelatie Spearman
* Coeficientul de
corelatie Spearman, notat rs, este analogul nonparametric al coeficientul
de corelatie Pearson, calculat pentru a fi utilizat cu date ordinale. 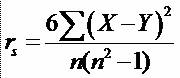
* Unde n este numarul de perechi de variabile
17Testul de semnificatie pentru coeficientul de corelatie Spearman
* Semnificatia coeficientului de corelatie Spearman poate fi evaluata daca valoarea observata a aparut datorita întâmplarii (daca este semnificativ diferita de zero). Valorile critice ale lui r pot fi regasite în Anexa 7 pentru n grade de libertate în cazul aplicarii testului unilateral sau bilateral.
* Valorile obtinute pentru rs trebuie sa fie mai mari sau egale decât valorile critice din tabel pentru ca sa fie semnificative
18Coeficientul de determinare
* este patratul coeficientului de corelatie r, adica d = r*r.
* Prin definitie, coeficientul de determinare reprezinta partea din variatia totala a lui Y explicata prin relatia liniara existenta între X si Y.
* In caz extrem, daca toate punctele se afla pe o dreapta care nu e paralela cu axa Ox (adica nu are panta nula), orice variatie a lui Y este exprimata prin relatia liniara si coeficientul de determinare este 1. Din contra, daca X si Y sunt independente, adica între cele doua variabile nu exista o relatie liniara, coeficientul de determinare va fi zero.
* Acest coeficient, în procente (adica înmultit cu 100) exprima procentajul în care variatia lui Y este data prin relatia liniara între cele doua variabile.
NotesSlide Show [Pause/Play Narration]
[Previous Slide][Next Slide]Outline[Expand/Collapse Outline]
1Teste statistice* Tudor Drugan* 2007-2008
2Notiuni
* Testarea ipotezelor statistice
o Ipoteza nula
o Concepte
* Erori în testarea ipotezelor statistice
* Regiunea critica, directional-nondirectional, grade de libertate, o coada-doua cozi
* Teste parametrice-nonparametrice
3Testarea ipotezelor statistice
* Formularea de noi ipoteze (sau model sau teorie) este una dintre cele mai importante aspecte ale cercetarii stiintifice.
* Aceste ipoteze experimentale încerca sa descrie sau sa explice anumite fenomene reale.
* In multe cazuri exista ipoteze anterioare (descrieri sau explicatii) pe care oamenii de stiinta doresc sa le înlocuiasca cu altele noi.
* Este însa insuficient sa se formuleze sau sa fie prezentata numai o noua ipoteza.
* O ipoteza noua trebuie testata pentru a vedea ca are temei (în concordanta cu observatiile) si pentru a justifica ca este "mai buna" decât alte ipoteze alternative.
* Aceasta conduce la scheme de experimente, esantioane si de observatii în scopul obtinerii dovezii pentru sustinerea (sau respingerea) unei noi ipoteze.
4Metode pentru testarea ipotezelor
* Compararea a doua ipoteze sau teorii concurente
* Aceste doua teorii trebuie prima data formulate ca modele.
* Aceste doua modele în continuare vor fi denumite prin ipoteza nula si ipoteza alternativa.
o Ipoteza nula H0, reprezinta modelul pe care experimentatorul ar dori sa-l înlocuiasca.
o Ipoteza alternativa H1 este noul model care de regula reprezinta o negatie a ipotezei nule.
5Metode pentru testarea ipotezelor
poteza alternativa H1 este noul model care de regula reprezinta o negatie a ipotezei nule.
* Indiferent cum este formulat protocolul experimentului scopul cercetatorului este de a testa ipoteza nula (de cele mai multe ori pentru a o rejecta)
* Ca în justitie: inculpatul este inocent pâna se dovedeste vinovat
* Ipoteza nula nu trebuie probata ci anulata
* Inferenta negativa
6Metode pentru testarea ipotezelor
* Inferenta negativa
* Scopul testului statistic este de a dovedi ca ipoteza nula H0 este falsa
o à nu putem niciodata afirma acceptam ipoteza nula
o O putem nega sau nu o putem nega
* Ca la un proces, rezultatul este vinovat sau nevinovat si nu inocent
o Nevinovat = nu suficient de vinovat pentru a fi acuzat
7Metode pentru testarea ipotezelor
* Prin respingerea ipotezei nule cercetatorul afirma ca rezultatele observate nu sunt datorate întâmplarii
* = efect semnificativ
* Când ipoteza nula nu este rejectata cercetatorul afirma ca diferentele observate sunt datorate întâmplarii si rezultatele nu sunt semnificativ
8Pasii unui test statistic (1)
* Formularea problemei în termenii ipotezelor statistice.
* Pentru aceasta se stabilesc: ipoteza nula H0 si respectiv ipoteza alternativa H1, reprezentând o negare a ipotezei nule.
* Ipoteza nula H0, este ipoteza care trebuie testata, testul efectuându-se sub prezumtia ca ipoteza nula ar fi adevarata.
* Ipoteza alternativa H1, este acea ipoteza care într-un sens sau altul contrazice ipoteza nula. Aceasta ipoteza se mai numeste si ipoteza de lucru.
9Pasii unui test statistic (1)
* Ipoteza alternativa
* Media valorilor în populatia A este diferita de media valorilor în populatia B
10Pasii unui test statistic (1)
* Ipoteze directionale![]()
11Pasii unui test statistic (2)
* Alegerea si calcularea parametrului statistic al testului.
* Parametrul statistic al testului exprima într-o anumita forma, diferenta dintre elementele comparate, dintre care cel putin unul intervine sub forma unei statistici a unui esantion. Ţinând seama de faptul ca esantionul sau esantioanele utilizate sunt aleator extrase din populatiile care fac obiectul testului, parametrul statistic este o variabila aleatoare de selectie, care urmeaza o anumita lege de probabilitate. Un parametru statistic al testului bun trebuie sa îndeplineasca doua conditii:
o a. Trebuie sa se comporte diferit atunci când ipoteza nula H0 este adevarata fata de situatia în care ipoteza alternativa H1 este adevarata.
o b. Distributia de probabilitate a parametrului statistic al testului sub prezumtia ca H0 este adevarata, este cunoscuta.
12Pasii unui test statistic (3)
* Alegerea regiunii critice.
* Trebuie sa fim capabili sa decidem în functie de valoarea parametrului statistic calculat care dintre ipoteze, cea nula sau cea alternativa, este adevarata.
* Daca valoarea parametrului statistic apartine regiunii critice, ipoteza nula H0 va fi respinsa si va fi acceptata ipoteza alternativa H1.
* Daca valoarea parametrului statistic nu apartine regiunii critice, ipoteza nula H0 va fi acceptata.
13Pasii unui test statistic (4)
* Alegerea dimensiunii regiunii critice.
* Pentru aceasta trebuie sa specificam marimea riscului de eroare pe care îl acceptam.
* Pe scurt, definim nivelul de semnificatie, notat cu a, sau marimea riscului pe care suntem dispusi sa ni-l asumam în respingerea ipotezei nule H0 în cazul în care aceasta este adevarata.
* De obicei se alege un nivel de semnificatie între 1% si 5%.
14Pasii unui test statistic (5)
* Concluzia testului.
* Ipoteza nula H0 este respinsa daca valoarea parametrului statistic apartine regiunii critice. Regiunea critica trebuie astfel aleasa încât daca ipoteza alternativa H1 este adevarata, probabilitatea de respingere a ipotezei nule H0 este mai mare decât în cazul în care ipoteza nula H0 ar fi adevarata.
* În realitate, probabilitatea unei respingeri adevarate a ipotezei nule H0 trebuie sa fie mai mare decât probabilitatea unei respingeri false.
15Pasii unui test statistic (5)
* Depinzând de ipoteza alternativa, se poate alege una din urmatoarele trei regiuni critice:
o Regiunea critica unilaterala la dreapta - valoarea parametrului statistic al testului este mai mare sau egala cu valoarea din dreapta a intervalului critic;
o Regiunea critica unilaterala la stânga - valoarea parametrului statistic al testului este mai mica sau egala cu valoarea din stânga a intervalului critic;
o Regiunea critica bilaterala - valoarea parametrului statistic al testului este mai mica sau egala cu valoarea extrema din stânga regiunii critice sau mai mare sau egala cu valoarea extrema din dreapta regiunii critice, valorile extreme ale regiunii critice având nivele egale de semnificatie.
16Decizia
* Stabilirea semnificatiei testului pe baza valorii lui p se face frecvent cu urmatoarea regula empirica:
o 1. Daca 0,01 <= p<0,05 , rezultatele sunt considerate semnificative.
o 2. Daca 0,001 <= p<0,01, rezultatele sunt considerate înalt semnificative.
o 3. Daca p<0,001, rezultatele sunt considerate foarte înalt semnificative.
o 4. Daca p>=0,05, rezultatele sunt considerate nesemnificative statistic.
o 5. Daca 0,05 <= p<0,1, se noteaza o oarecare tendinta spre considerarea unei semnificatii statistice.
* Valoarea p nu este probabilitatea ca ipoteza nula sa fie falsa. O valoare mica a lui p nu înseamna ca exista o probabilitate mica ca ipoteza nula sa fie adevarata.
* Ipoteza de lucru nu poate fi inversata si de exemplu pentru un p = 0,02 nu se poate spune ca avem o probabilitate de 98% ca diferenta sa existe.
* Valoare lui p nu este un indicator al validitatii ipotezei statistice. P se utilizeaza doar pentru a face decizia semnificativa sau nu.
17Erori în testarea ipotezelor statistice
18Eroarea de tip I
* = H0 este respinsa desi este adevarata
* Am concluzionat ca exista reale diferente desi acestea sunt datorate sansei
* Concluzionam ca un tratament este eficient pe baza unei interpretari gresite
19Eroarea de tip II
* = H0 este nu este respinsa desi este falsa
* Am concluzionat ca exista diferentele observate sunt datorate sansei atunci când acestea apar datorita diferentelor dintre esantioane
* Am putea abandona un tratament pe care tocmai îl testam sau o directie de cercetare
20Eroarea de tip I si nivelul de semnificatie
* Probabilitatea comiterii unei erori de tip I = nivelul de semnificatie, α (alfa)
* Probabilitatea este de determinata prin teste statistice
* Nivelul alfa (riscul maxim acceptabil) 5% à exista o sansa de 5% de a respinge incorect ipoteza nula
* p= 0,18 ipoteza nula nu se poate respinge
* p= 0,04 ipoteza nula se poate respinge cu un risc acceptabil de 4% de a comite o eroare de tipul I
21Eroarea de tip II
* = H0 este nu este respinsa desi este falsa
* Am concluzionat ca diferentele observate sunt datorate sansei atunci când acestea apar datorita diferentelor obiective dintre esantioane
* Probabilitatea de a nu rejecta o ipoteza nula falsa = β, probabilitatea de a face o eroare de tipul II
* 1- β = complementul lui β, puterea unui test
* Puterea = probabilitatea ca un test sa respinga ipoteza nula sau sa obtina semnificatie statistica
22Ce determina puterea unui test
* Criteriul de semnificatie
* Varianta
* Dimensiunea esantionului
* Dimensiunea efectului
23Regiunea critica
* = regiunea de respingere, aria marginita de Z=±1,96
24Regiunea critica - exemplu
* Media esantionului=10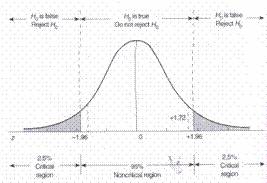 5
5
* s=16
* n=30
* Sx=2,9
* Z=1.72
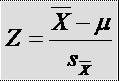
* Testul nu este semnificativ si nu se poate respinge ipoteza nula
25Test non-directional (cu doua cozi)
* Nu s-a evaluat directia diferentei dintre cele doua medii
* Un test cu un nivel de semnificatie α are o probabilitate de α/2 pentru fiecare coada
26Test directional (cu o coada)
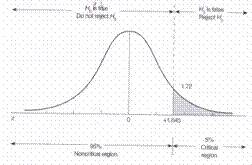
* Nu mai încercam localizarea regiunii critice în ambele cozi
* Media esantionului=105
* s=16
* n=30
* Sx=2,9
* Z=1,645
* Testul este semnificativ se respinge ipoteza nula
27Statistici parametrice si non-parametrice
* Statisticile utilizate pentru a estima parametrii unei populatii sunt statistici parametrice
o Sunt bazate pe extragerea randomizata de esantioane dintr-o populatie normal distribuita
o Esantioanele reprezinta parametrii populatiei
* Daca nu se respecta aceste conditii sunt necesare altfel de teste statistice: teste nonparametrice:
o Nu fac supozitii asupra populatiei
o Pot fi folosite atunci când criteriile de normalitate si omogenitate nu sunt îndeplinite
1![]()
* Conf.Dr. Tudor Drugan* 2007-2008
* Cea mai simpla comparatie statistica este cea între doua grupuri aleator alese
* Acest mod de distribuire permite cercetatorului sa presupuna ca diferentele individuale sunt egal distribuite între grupuri la începutul experimentului si ca cele doua grupuri sunt echivalente
* D.p.d.v statistic cele doua grupuri sunt esantioane extrase din aceiasi populatie deci diferentele dintre ele sunt rezultatul erorii de esantionare sau al întâmplarii
3"Dupa aplicarea unui tratament cercetatorul..."
* Dupa aplicarea unui tratament cercetatorul verifica daca cele doua esantioane mai fac sau nu parte din aceiasi populatie
* Pentru aceasta se aplica un test statistic
4"Compararea mediilor esantioanelor pentru determinarea..."
* Compararea mediilor esantioanelor pentru determinarea statistica a diferentelor se face prin doua caracteristici:
o Media - diferenta mediilor între grupuri caracterizeaza nivelul de separare între grupuri
o Varianta - caracterizeaza variabilitatea în interiorul grupurilor
* Ambele caracteristici sunt o sursa de variabilitate utilizabila pentru a descrie efectele tratamentului
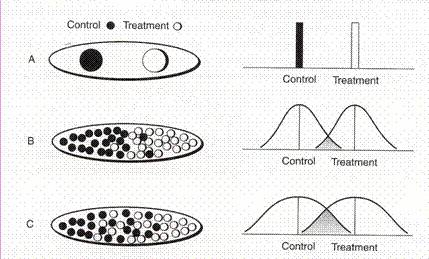
5"Se considera doua esantioane aleator..."
* Se considera doua esantioane aleator extrase, unul experimental si unul de control
* Daca tratamentul a fost eficient tot grupul supus experimentului va atinge acelasi nivel al parametrului studiat
* Exista diferente între grupuri
* Nu exista diferente în interiorul grupurilor
6"Situatia reala"
* Situatia reala
o Exista diferente între grupuri
o Exista diferente în interiorul grupurilor
* Trebuie demonstrat daca diferentele observate între mediile parametrului studiat sunt datorate experimentului si nu întâmplarii
8"W.S"
* W.S. Gossett, 1908 - Student
* Testul t
* Subtipuri:
o Testul t pentru esantioane independente:
+ Variante egale
# O coada
# Doua cozi
+ Variante inegale
o Testul t pentru esantioane perechi
9"Utilizat pentru compararea a doua..."
* Utilizat pentru compararea a doua esantioane independente
* Esantioanele sunt considerate independente deoarece sunt compuse din seturi independente de subiecti între care nu exista nici o relatie derivata din studiu
10"Testul t pentru esantioane independente..."
* Testul t pentru esantioane independente se bazeaza pe aceasta prezumtie
* Se mai numeste si omogenitatea variantelor
* În mod normal omogenitatea variantelor se testeaza statistic
o Testul Levene sau testul Barlett
o Bazate pe statistica F
* Daca variantele nu sunt semnificativ statistic diferite (p>0,05) atunci pot fi considerate egale
* Daca sunt diferite se aplica alta formula de calcul a lui t
11"Numaratorul - diferenta mediilor esantioanelor"
* Numaratorul - diferenta mediilor esantioanelor
* Numitorul - eroarea standard a diferentei dintre medii, o masura a variabilitatii în interiorul esantioanelor
* Estimarea SX1+X2
se face prin variabila Sp, (varianta comuna) care utilizeaza
variantele si dimensiunile esantioanelor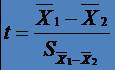
12"Eroarea standard a diferentei mediilor..."
* Eroarea standard a
diferentei mediilor esantioanelor este: 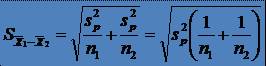
13"Testam ipoteza ca un nou..."
* Testam ipoteza ca un nou model de atela îmbunatateste functia de prindere a mâinii la pacientii cu artrita reumatoida
* Ne intereseaza doar testarea ipotezei directionale, deoarece dorim obtinerea unei ameliorari:
o H1=μ1 > μ2
* Avem un esantion aleator selectat de 20 de pacienti cu artrita reumatoida având niveluri similare de diformitate la nivelul mâinii si la nivelul articulatiilor mâinii
14"Aleator pacientii sunt împartiti în..."
* Aleator pacientii sunt împartiti în doua grupuri:
o n1 - 10 persoane sunt grupul pentru experiment
o n2 - 10 persoane sunt grupul de control
* La cei din grupul experimental se monteaza atela
* Toti pacientii au un program motor similar timp de o saptamâna
* Se masoara puterea de strângere cu mâna în zilele 1 si 8 ale testului iar diferenta este cea care se foloseste în continuare la calcule
15
16
17

19Testul T
* Pentru ca valoarea calculata a lui t sa implice o diferenta semnificativa, ea trebuie sa fie mai mare sau egala cu valoarea critica
* Daca testul este unidirectional atunci si semnul lui t trebuie sa fie corespunzator
* Deoarece t=2,718 si este mai mare decât valoarea critica pentru α =0,05 - 1,734 si este pozitiv atunci media valorilor diferentei fortei mâinii a celor din grupul experimental este mai mare decât la cei din grupul de control
* Putem rejecta H0
* Tratamentul are
un rol pozitiv
* Literatura de specialitate arata ca atunci cînd esantioanele comparate au un numar egal de cazuri violarea regulii egalitatii variantelor nu duce la compromiterea testului Student
* Daca
numarul de cazuri difera între esantioane atunci statistica t
trebuie calculata conform formulei, iar gradele de libertate se
ajusteaza în functie de varianta: 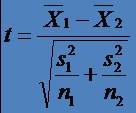
* Daca esantioanele mai mari au si varianta mai mare testul t devine mai putin puternic
o Se obtin mai putine diferente semnificative statistic
* daca
esantionul mai mic are varianta mai mare (de peste 2 ori) creste
sansa unei erori de tipul I
23
24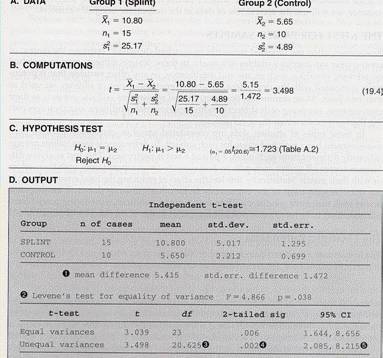
* Se foloseste în protocoale de cercetare care implica masuratori repetate asupra acelorasi indivizi sau asupra unor indivizi cu caracteristici asemanatoare (chiar gemeni)
* Datele sunt considerate împerecheate deoarece pentru fiecare valoare exista o valoare pereche
* Testul evalueaza scorul de diferenta din cadrul fiecarei perechi astfel încât subiectii sunt comparati numai cu ei însisi sau cu perechea lor
* D este
diferenta dintre scoruri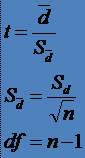
* Se testeaza
utilizarea unei perne de suport lombar pentru îmbunatatirea
unghiului de repaus al pelvisului
* Analiza frecventelor pentru variabile masurabile pe o scara nominala sau ordinala
* Test neparametric care verifica daca distributia observata difera de cea asteptata (teoretica)
29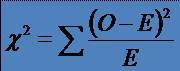
* În aplicare testului Chi-patrat întotdeauna:
o Frecventele sunt date de numarul de cazuri si nu reprezinta procente sau ranguri
o Categoriile sunt exhaustive si mutual exclusive: orice subiect poate apartine unei categorii dar numai uneia
* O - frecventa observata si E - frecventa asteptata
30* Aruncam o moneda de 100 de ori si obtinem de 47 de ori stema desi teoretic ar fi trebuit sa obtinem stema de 50 de ori
* Nu putem rejecta
ipoteza nula, aruncarea cu banul a fost corecta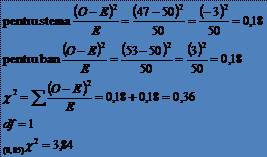

1Teste statistice III * Tudor Drugan* 2007-2008
2
3Obiectivul testului
* Obiectivul testului este de a compara media unei variabile cantitative continue pe un esantion reprezentativ extras dintr-o populatie cu media µ cu o medie cunoscuta µ0 a unei populatii standard. Se presupune ca cele doua populatii au aceiasi variatie s2 care se cunoaste.
4"Conditii de aplicare"
* Conditii de aplicare
o Este necesar sa cunoastem variatia populatiei (daca nu o cunoastem, aplicam testul Student pentru compararea mediei unui esantion cu media unei populatii).
o Testul este corect aplicat daca populatia este normal distribuita. Daca populatia nu este normal distribuita sau talia esantionului este mica (<30) testul da o valoare orientativa.
o Testul este, de asemenea, corect aplicat atunci când talia esantionului este mare ( ≥ 30).
5"Ipotezele testului"
* Ipotezele testului
o 1. Test bilateral: H0: m = m0 versus H1: m m0
o 2. Test unilateral: H0: m = m0 versus H1: m > m0
* unde m = media popolatiei din care este extras esantionul si m0 = media populatiei standard.
* Intr-o alta forma ipotezele testului se pot formula în modul urmator:
o Ipoteza nula: nu exista diferenta semnificativa între media esantionului si media populatiei.
o Ipoteza alternativa pentru testul bilateral: exista diferenta semnificativa între media esantionului si media populatiei.
o Ipoteza nula pentru testul unilateral: media esantionului este semnificativ mai mare decât media populatiei.
6Pragul de semnificatie a
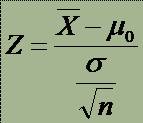
7Regiunea
critica pentru testul unilateral este [1.645, 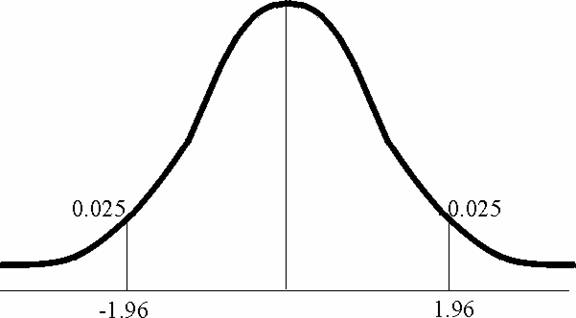
8"O arie actuala de interes..."
* O arie actuala de interes este studierea agregarii familiale a bolilor cardiovasculare (prevalenta bolii printre membrii unei familii este mai mare decât în rândul populatiei generale), prin studiul legaturii dintre nivelul lipidic sanguin si aceste boli.
* Se stie ca nivelul mediu al colesterolului sanguin la copii este de 175 mg/dL.
* La un esantion de 10 copii, proveniti din familii în care tatal a decedat în urma unei boli cardiovasculare, media colesterolului sanguin este de 200 mg/dL iar deviatia standard este de 50 mg/dL.
* Nivelul mediu al colesterolului la aceasta populatie de copii este mai mare decât cel al populatiei generale?
* Este nivelul colesterolului obtinut la acest esantion semnificativ diferit fata de cel al populatiei generale?
9"Datele problemei"
* Datele problemei: m0 = 175, m = 200, n = 10, s = 50.
* Ipotezele testului sunt:
o 1. Test bilateral: H0: m = m0 = 175 versus H1: m <>m0<>175
o 2. Test unilateral: H0: m = m0 = 175 versus H1: m > m0 > 175
* De asemenea, avem:
o Ipoteza nula: nu exista diferenta semnificativa între media colesterolului pentru esantion fata de media populatiei.
o Ipoteza alternativa pentru testul bilateral: exista diferenta semnificativa între media colesterolului la esantion si respectiv la populatia generala.
o Ipoteza alternativa pentru testul unilateral: media colesterolului pentru esantion este mai mare decât media colesterolului la populatia generala.
* Prag de semnificatie a = 0,05
10* 1. Regiunea critica pentru testul bilateral este: (-¥ , -1,96 ] È [1,96 , ¥) (vezi anexa 1).
* 2. Regiunea critica pentru testul unilateral este: [1.645, ¥) ( vezi anexa 1).
* Parametrul statistic calculat al testului:
11* 1. Pentru testul bilateral: Deoarece parametrul statistic calculat al testului nu apartine regiunii critice respingem ipoteza nula; exista o diferenta semnificativa între media colesterolului la esantionul ales si populatia generala.
* 2. Pentru testul unilateral: Deoarece parametrul statistic calculat al testului z este mai mic decât 1,645 nu putem nega ipoteza nula, adica nu exista diferenta semnificativa între media colesterolului la esantion si media colesterolului populatiei generale.
12"Obiectivul testului este de a..."
* Obiectivul testului este de a compara mediile unei variabile cantitative continue între doua populatii, care satisfac conditia au aceeasi variatie s2 si ca ea este cunoscuta.
* Pentru aplicarea testului se utilizeaza doua esantioane reprezentative independente extrase din cele doua populatii
13"Conditii de aplicare"
* Conditii de aplicare
* 1. Populatiile trebuie sa aiba variatii cunoscute si egale. Daca variatiile nu sunt cunoscute, se aplica testul Student pentru compararea mediilor a doua populatii.
* 2. Testul este corect aplicat daca populatiile sunt normal distribuite sau daca esantioanele utilizate au talie mare (³30). Daca populatiile nu sunt normal distribuite sau daca cel putin un esantion are talie mica (<30), testul da o valoare orientativa.
14"Algoritm"
* Algoritm
* Consideram doua populatii cu mediile si respectiv .
* Ipotezele testului:
o 1. Test bilateral: H0: m = m0 versus H1: m m0
o 2. Test unilateral: H0: m = m0 versus H1: m > m0
15"Sub prezumtia ca ipoteza nula..." * Sub prezumtia ca ipoteza nula este adevarata (m1 - m2 = 0), parametrul statistic al testului este dat de formula:
16"Dorim sa studiem daca exista..."
* Dorim sa studiem daca exista diferenta semnificativa între cantitatea de acid uric sangvin la barbatii din mediul urban fata de cei din mediul rural, cunoscându-se ca variatia acidului uric este egala cu 2,1 mg/100ml.
* Din prima populatie (mediul urban) s-a extras un esantion de 10 persoane cu vârste cuprinse între 45 si 60 de ani si s-a obtinut o medie a acidului uric de 5,6 mg/100ml.
* S-a determinat media acidului uric la un esantion de 16 barbati, extras din a doua populatie (mediul rural), cu vârste cuprinse între 45 si 60 de ani din mediul rural si s-a constata o valoare medie de 4,1 mg/100ml.
17"Ipoteza testului"
* Ipoteza testului:
o 1. Test bilateral: H0: m = m0 versus H1: m m0
o 2. Test unilateral: H0: m = m0 versus H1: m > m0
* Ipoteza nula: Media acidului uric la prima populatie nu difera semnificativ fata de media acidului uric la cea de-a doua populatie.
* Ipoteza alternativa, test bilateral: Media acidului uric la cei din mediul urban difera semnificativ fata de media acidului uric la cei din mediul rural.
* Ipoteza alternativa, test unilateral: Media acidului uric la cei din mediul urban este semnificativ mai mare fata de media acidului uric la cei din mediul rural.
18 * Parametrul statistic calculat al testului: 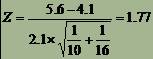
* Pragul de semnificatie: a = 0,05.
* Regiunea critica:
* 1. Regiunea critica pentru testul bilateral: (-¥ , -1,96 ] È [1,96 , ¥) (vezi anexa 1).
* 2. Regiunea critica pentru testul unilateral: [1.645, ¥) ( vezi anexa 1).
19* Concluzie:
* 1. Test bilateral: Deoarece statistica calculata a testului nu apartine regiunii critice nu se poate nega ipoteza nula. Media acidului uric la prima populatie nu difera semnificativ fata de media acidului uric la cea de-a doua populatie.
* 2. Test unilateral: Deoarece statistica calculata a testului apartine regiunii critice, se accepta ipoteza alternativa ca media acidului uric în prima populatie este mai mare decât media în cea de a doua populatie.
20* Scopul acestui test este investigarea semnificatiei diferentei între o frecventa teoretica p (într-o populatie) si o frecventa observata f pe un esantion reprezentativ a unei valori a unei variabile calitative (binare).
21* Conditii de aplicare:
* Testul este corect aplicat daca numarul n al observatiilor esantionului este suficient de mare (np, n(1-p)>10), pentru a justifica utilizarea unei aproximari cu o distributie normala redusa (a distributiei frecventei de selectie).
* Algoritm
* Un esantion randomizat de volum n este extras dintr-o populatie pentru care cunoastem frecventa teoretica p a unei variabile calitative. Pentru aceeasi variabila se calculeaza frecventa ei în esantion f. Parametrul testului este:
22* Suntem interesati de investigarea prevalentei hepatitei B la personalul care lucreaza în laboratoarele unor clinici de boli infectioase din Transilvania.
* Se stie din studii anterioare ca prevalenta hepatitei B în populatia generala din Transilvania este de 9%.
* Un esantion de 100 de persoane care lucreaza în laboratoarele unor spitale de boli infectioase din Transilvania s-a luat în studiu si s-a obtinut o prevalenta a hepatitei B de 6%.
* Exista diferenta semnificativa între frecventa hepatitei B la personalul care lucreaza în laboratoarele unor spitale de boli infectioase din Transilvania fata de populatia generala?
23* Solutie
* Datele problemei: f = 0,06, p = 0,09, . Fie p0 prevalenta (necunoscuta) a hepatitei B în populatia alcatuita de personalul laboratoarelor spitalelor de boli infectioase.
* Ipotezele testului:
* 1. Test bilateral: H0: p0=p1 versus H1:p0<>p1
* 2. Test unilateral: H0: p0=p1 versus H1:p0>p1
24* Ipoteza nula: Nu exista diferenta semnificativa între frecventa hepatitei B la esantionul studiat fata de frecventa hepatitei B în populatia generala.
* Ipoteza alternativa, test bilateral: Exista diferenta semnificativa între frecventa hepatitei B la nivelul esantionului si prevalenta hepatitei B în populatia generala.
* Ipoteza alternativa, test unilateral: Frecventa hepatitei B la nivelul esantionului studiat este semnificativ mai mare fata de frecventa hepatitei B în populatia generala.
25* Statistica testului:
* Pragul de semnificatie: a = 0,05.
* Regiunea critica:
* 1. Regiunea critica, test bilateral: (-¥ , -1,96 ] È [1,96 , ¥) - (vezi anexa 1).
* 2. Regiunea critica, test unilateral: [1.645, ¥) -( vezi anexa 1).
26* Concluzie
* 1. Test bilateral: Deoarece parametrul statistic calculat al testului nu apartine regiunii critice nu se poate nega ipoteza nula. Nu exista diferenta semnificativa între frecventa hepatitei B la esantionul studiat fata de frecventa hepatitei B în populatia generala.
* 2. Test unilateral: Deoarece parametrul statistic calculat al testului nu apartine regiunii critice, nu se poate nega ipoteza nula. Nu exista diferenta semnificativa între frecventa hepatitei B la esantionul studiat fata de frecventa hepatitei B în populatia generala.
27* serveste la compararea a doua distributii, urmând doua modele, care constau în:
o compararea unei distributii observate (sau empirice) pe un esantion cu o distributie teoretica. In acest caz, se cauta sa se determine daca un esantion se aseamana cu un anumit model teoretic, fiind astfel vorba de un test Hi-patrat de ajustare.
o compararea a doua distributii observate în scopul stabilirii fie a independentei dintre doua criterii sau omogenitatea dintr-un tabel de contingenta. Este vorba în acest caz de un test Hi-patrat de omogenitate sau de independenta.
28* Astfel vom presupune ca se cauta efectul fumatului asupra aparitiei cancerului buzei inferioare (M). Pentru aceasta se observa un esantion de 400 de subiecti dintre care:
o 160 au afectiunea M prezenta ( si 240 nu au boala prezenta)
o 130 sunt fumatori T ( si 270 nu sunt fumatori).
29* Se cauta sa se stabileasca daca fumatul influenteaza aparitia maladiei M sau daca aparitia acesteia este independenta de fumat.
* Tabelul de contingenta prezentat se numeste tabel de contingenta observat, iar frecventele pe care le contine se numesc frecvente observate.
30* Se face ipoteza de independenta între cele doua caractere M si T (adica ipoteza nula H0 , în acest caz) atunci
* Se calculeaza un tabel de contingenta teoretic care satisface aceasta ipoteza de independenta.
* Se determina apoi abaterea (ecartul) dintre cele doua tabele de contingenta observat si teoretic.
o Daca aceasta abatere este mica atunci ea este explicata doar prin întâmplare (hazard) si ipoteza de independenta este acceptata.
o Daca aceasta abatere este foarte importanta pentru ca doar întâmplarea sa o explice atunci ipoteza de independenta trebuie sa fie respinsa.
31* Problema este urmatoarea: dispunând de un esantion de n = 400 de subiecti dintre care 160 au maladia M iar 130 sunt fumatori, sa se determine cum sunt repartizati subiectii în functie de cele doua caractere (M si T) daca se presupune ca acestea sunt independente
32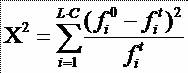
33
* H0: caracterele A si B sunt independente.
* H0: fumatul nu are influenta asupra aparitiei maladiei M.
34
35
* Fie a pragul de semnificatie al testului.
* S-a ales pragul de semnificatie a = 0.05
36
* Regiunea critica este [X2 a ,¥).
* Pentru pragul a =0.05 si cu 1 grad de libertate valoarea = 3.84, astfel ca în acest caz regiunea critica este intervalul [3.84 , ¥).
37
38
* Daca X2 Î[3.84, ¥) se respinge H0 cu un risc de eroare de prima speta £a .
* Daca X2 Ï[3.84, ¥) atunci H0 nu se respinge, acceptându-se H0 cu un risc de eroare de speta a doua b
* X2 =37,22 >> 3.84 asa ca ipoteza nula H0 se respinge cu un risc inferior lui 5%.In concluzie, fumatul se asociaza cu maladia M favorizând-o.
39![]() *
Testul de ajustare se poate aplica în
solutionarea urmatorului model.
*
Testul de ajustare se poate aplica în
solutionarea urmatorului model.
o Se considera un tabel de contingenta observat continând frecventele a doua caractere (având fiecare un numar oarecare de valori).
o Se pune atunci problema daca cele doua caractere sunt legate printr-o anumita lege cunoscuta de probabilitate W.
o Se adopta atunci acelasi procedeu ca în aplicarea testului de independenta cu singura diferenta ca tabelul de contingenta teoretic se calculeaza pe baza utilizarii legii W
40* Cel mai frecvent testul de ajustare este aplicat la studiul unui singur caracter (având k modalitati de realizare) pentru care se încearca sa se afle daca repartitia sa urmeaza o lege teoretica cunoscuta.
* Numarul de grade de libertate a legii utilizate în acest caz este k-1.
* Se poate în acest fel compara cu ajutorul testului de ajustare (cu 1 grad de libertate) o frecventa observata cu o frecventa teoretica.
41![]()
* Este un test destinat analizei cercetarilor multinivel si/sau multifactoriale
* Este utilizat atunci când trebuiesc cercetate 3 sau mai multe conditii sau esantioane
* Bazat pe statistica F si pe prezumtia ca esantioanele sunt extrase aleator dintr-o populatie normal distribuita (în practica se verifica întotdeauna)
42
* Univariat - analiza se aplica asupra unui experiment cu un singur factor, care produce cel putin trei grupuri independente
* Ipoteza statistica:
o H0: μ1 = μ2 = μ3 ... = μn
* Testul statistic utilizat este testul F (propus de Sir Ronald Fischer
43![]()
* Studiu ipotetic asupra efectului utilizarii bastonului sau cârjelor la persoanele cu amputatie unilaterala, masurându-se lungimea pasului
* Varianta totala SSt
* Varianta intergrup SSb
* Varianta intragrup SSe= SSt - SSb
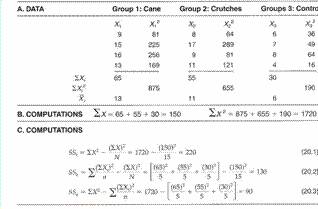
44![]()
* Media patratica intergrup MSb
* Media patratica intragrup MSe

45* Daca nu putem rejecta ipoteza nula, nici un tratament nu este util
Formule
Problema 1. Formule aritmetice simple. Executati în Excel urmatoarele conversii:
Introduceti urmatoarele date :
În celula selectata mai sus : B1 introduceti urmatoarea formula :
=A1*1024*1024 apoi apasati Enter. În celula B1 va aparea rezultatul conversiei în KB, iar pe bara de formule se poate vedea formula dupa care a fost calculata.
!! O formula începe întotdeauna cu =.
Procedati în mod analog pentru urmatoarele conversii.
Informatii utile:
Pentru a micsora numarul de zecimale apasati pe butonul:
Pentru formatarea celulelor selectati domeniul dorit. Alegeti din meniu comanda Format - Cells - Alignment si selectati optiunea Center din caseta derulanta pentru aliniere în centrul celulei, selectati optiunea Merge text pentru reuniunea mai multor celule, selectati optiunea Wrap text pentru spargerea textului pe mai multe rânduri.
Pentru formatare selectati domeniul dorit. Alegeti din meniu comanda Format - Cells - Border si selectati tipul de linie dorita pentru încadrarea celulei sau domeniului selectat, apoi apasati butonul pentru tipul de încadrare dorita.
Problema 2. Operatori. Se da a,b,c în celulele A1, A2, A3 ale unui tabel Excel. Sa se calculeze în Excel urmatoarele formule:
Problema 3. Referinte relative-absolute. În coloana A1 se da numarul de zile de spitalizare pentru 10 pacienti. În celula D1 se da costul unei zile de spitalizare pentru un pacient:
Problema 4. Utilizarea functiilor. În coloana A se da TAD- tensiunea arteriala diastolica la 10 pacienti. În coloana B se da TAS - tensiunea arteriala sistolica pentru 10 pacienti. În coloana C se da Vârsta celor 10 pacienti.
Calculati utilizând functiile Excel:
Laborator Word 1
Problema 1
Tema: crearea unui folder (director), a unui fisier si respective stergerea lor.
Creati un nou folder în My Documents pe care sa îl denumiti Exemplu. Pentru aceasta realizati urmatorii pasi:
dublu clic pe icoana My Documents;
alegeti optiunea File si respectiv Folder.
denumiti acest folder Exemplu.
În folder-ul nou creat, creati un fisier Word. Pentru aceasta, deschideti folder-ul Exemplu (dublu clic pe icoana folder-ului). Din meniul File, alegeti optiunea New si ulterior optiunea Microsoft Word Document. Denumiti acest fisier Exemplu.
stergeti folder-ul Exemplu. Pentru aceasta selectati folderul prin clic pe icoana lui si ulterior apasati tasta Delete. Va aparea o casuta de dialog care va va întreba daca sunteti siguri ca doriti sa stergeti folder-ul Exemplu; alegeti butonul Yes.
Problema 2
Tema: Creati în partitia dvs. 5 foldere: Word, Excel, PowerPoint, Access si respectiv Biostatistica. Pentru aceasta parcurgeti urmatorii pasi:
Problema 3
Introduceti urmatorul text cu formatarile urmatoare: font Arial de marime 12, pentru titlu font arial de marime 14 boldat si subliniat ca în figura de mai jos:
10.1. Informatizarea fisei medicale
Fisa medicala sau dosarul medical informatizat este structura în care sunt consemnate toate datele necesare pentru evidenta si supravegherea pacientilor. Teoretic dosarul unui pacient este distribuit fizic între serviciile interesate: spitale, medici generalisti, societatile de asigurare. Functiile dosarului medical informatizat includ:
îmbunatatirea posibilitatilor de comunicare (de exemplu, între diferite echipe medicale)
îmbunatatirea algoritmilor de luare a unei decizii
utilizate în grup permit: evaluarea, cercetarea si planificarea.
Salvati documentul în folderul Word sub denumirea Word 1a.
roblema 4
Realizati urmatoarea diagrama. Imaginea se va insera cu comanda: Insert Picture From File; imaginea se numeste Computer si o gasiti pe pagina care cuprinde lista cu lucrarile de laborator (dupa Word1).
|
System unit |
|
Monitor |
|
Keyboard |
|
Mouse |
|
Floppy disk drive |
|
CD-ROM drive |
|
CD-ROM |
|
Floppy disks |
|
Hard disk drive |
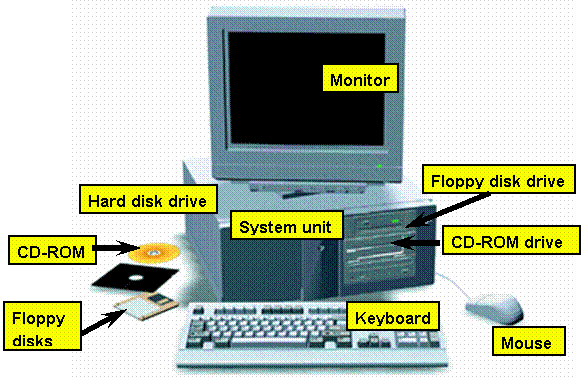
Salvati documentul în folderul Word sub denumirea Word 1b.
Închideti toate aplicatiile si nu uitati sa iesiti din conturile dvs.
Laborator Word 2
Problema 1
Realizati un fisier Word care sa cuprinda urmatorul text. Pentru acest text. utilizati distanta dubla între rânduri. Introduceti si numerotarea paginii la subsol si un antet de pagina cu textul "Informatica si biostatistica medicala".
De asemenea, utilizati si o nota de subsol legata de dosarul medical informatizat "Dosarul medical informatizat este structura în care sunt consemnate toate datele necesare pentru evidenta si supravegherea pacientilor. Dosarul unui pacient trebuie distribuit fizic între serviciile interesate: spitale, medici de familie, societati de asigurare.".
Salvati fisierul cu numele Word 2a în folder-ul Word.


Problema 2
Tema: Realizati în Microsoft Word urmatorul tabel. Folositi optiunile Table Merge Cells, Table Split Cells din meniul Table. Folositi fontul Garamond de 11.
Salvati fisierul sub denunirea de Word 2b în folder-ul Word.
|
Nr. crt. |
Numele si prenumele |
Diagnostic |
|
Analize |
|||||
|
Glicemie |
Tensiune arteriala |
||||||||
|
Dim |
Pranz |
Seara |
TAD |
||||||
|
Dim |
Pranz |
Seara |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Pop Ana |
Diabet |
Ziua 1 |
|
|
|
|
|
|
|
Ziua 2 |
|
|
|
|
|
|
|||
|
Ziua 3 |
|
|
|
|
|
|
|||
|
Ziua 4 |
|
|
|
|
|
|
|||
|
Ziua 5 |
|
|
|
|
|
|
|||
|
|
Popa Ion |
Diabet |
Ziua 1 |
|
|
|
|
|
|
|
Ziua 2 |
|
|
|
|
|
|
|||
|
Ziua 3 |
|
|
|
|
|
|
|||
|
Ziua 4 |
|
|
|
|
|
|
|||
|
Ziua 5 |
|
|
|
|
|
|
|||
Problema 3 - Introducere de formule în Word
Sa se editeze În Word urmatoarele formule: (pentru editare folositi Insert - Object - Microsoft Equation 3.0)
a. 
b. 
Problema 4. Optional
Tema: Creati un index pentru un text oarecare de cel putin trei pagini.
Textul il obtineti cautand pe google urmatoarele cuvinte "Doctori si asistente profesionisti complementari". Din pagina de web selectati cateva ecrane de text pe care le copiati in documentul Word.
Instructiuni:
Va aparea fereastra:
Problema 5. Optional
Tema: Creati un Cuprins pentru un text oarecare.
Instructiuni:
![]() 1.
Creati stilurile de formatare pentru fiecare dintre titlurile care
doriti sa apara în Cuprins cu comanda Styles and Formatting din
meniul Format. (Se poate crea un stil nou cu optiunea New
Style sau se poate alege stilul dorit dintre stilurile de formatare deja
existente: de ex pentru "10.1. Informatizarea
datelor medicale" se poate alege stilul Heading 3, la fel si pentru "10.2.
Tipuri de date si formate ". Iar pentru "Obiective si
beneficii ale dosarului medical informatizat " stilul Heading 2, iar
pentru "Stocarea si comunicarea informatiilor" stilul
Heding 4.
1.
Creati stilurile de formatare pentru fiecare dintre titlurile care
doriti sa apara în Cuprins cu comanda Styles and Formatting din
meniul Format. (Se poate crea un stil nou cu optiunea New
Style sau se poate alege stilul dorit dintre stilurile de formatare deja
existente: de ex pentru "10.1. Informatizarea
datelor medicale" se poate alege stilul Heading 3, la fel si pentru "10.2.
Tipuri de date si formate ". Iar pentru "Obiective si
beneficii ale dosarului medical informatizat " stilul Heading 2, iar
pentru "Stocarea si comunicarea informatiilor" stilul
Heding 4.
![]() 2. Cu ajutorul comenzii Index and Tables din
meniul Insert optiunea Reference creati Cuprinsul astfel:
2. Cu ajutorul comenzii Index and Tables din
meniul Insert optiunea Reference creati Cuprinsul astfel:
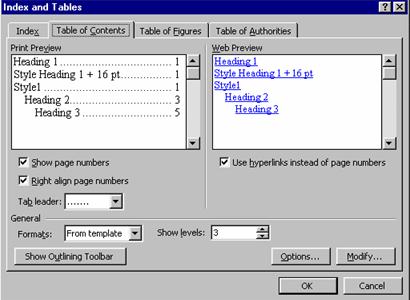
Se poate alege numarul de nivele afisate, aparitia numarului de pagina etc. Iar folosind optiunea Options se poate fixa în dreptul fiecarui stil nivelul titlului :
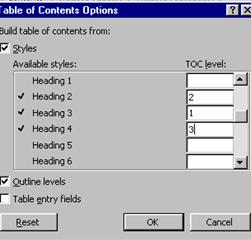
ca în figura de mai sus.
Apoi, pentru crearea Cuprinsului se va apasa tasta OK din fereastra Index and Tables.
Închideti toate aplicatiile si nu uitati sa iesiti din conturile dvs.
Laborator EXCEL
Deschideti aplicatia Microsoft Excel (butonul Start-Programs-Microsoft Excel) si realizati un tabel cu aspectul de mai jos, în care introduceti date pentru 10 pacienti:
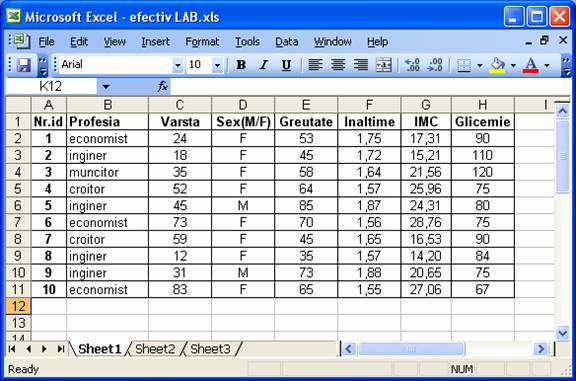
Instructiuni:
Dupa ce introduceti continutul unei celule, validati acest fapt cu [Enter] sau [Tab].
Pentru a edita continutul unei celule folositi tasta [F2] sau dublu clic.
Pentru a introduce o formula într-o celula începeti întotdeauna cu = si adresati celulele prin numele celulei (litera care desemneaza coloana si cifra care indica linia); în cazul nostru formula este Greutate(kg)/Inaltime(m)2, ceea ce se traduce pentru celula G2 în formula: = E2/(F2^2). Când introduceti formula sau daca doriti modificarea ei, puteti face acest lucru scriind în zona rezervata special, bara de formule:
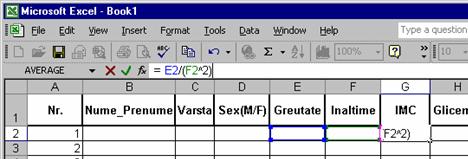
Pentru a multiplica formula respectiv pentru celelalte celule (G3-G14) selectati G3-G14 si folositi din meniu optiunea Edit-Fill-Down;
Pentru a micsora numarul de zecimale selectati celula cu valoarea pentru care doriti micsorarea numarului de zecimale si din Format-Cells-Number alegeti optiunea Number, iar la caseta cu zecimale scrieti numarul de zecimale dorite. Pentru alta varianta mai rapida apasati pe butonul:
![]()
Pentru a realiza graficul distributiei pe sexe a pacientilor:
Realizati un tabel separat sub tabelul dvs. în care sa treceti numarul total de femei si numarul total de barbati astfel:
|
Femei |
|
|
Barbati |
|
Selectati acest tabel, apoi apasati butonul pentru Chart Wizard:
![]()
Lucrare EXCEL - WORD
Nr.crt.
Nitrit
Ph
Tabelul 1.1 Tabelul Ph-ului gastric si a concentratiilor de nitrit urinar
Întreaga dumneavoastra lucrare în Word va arata astfel:
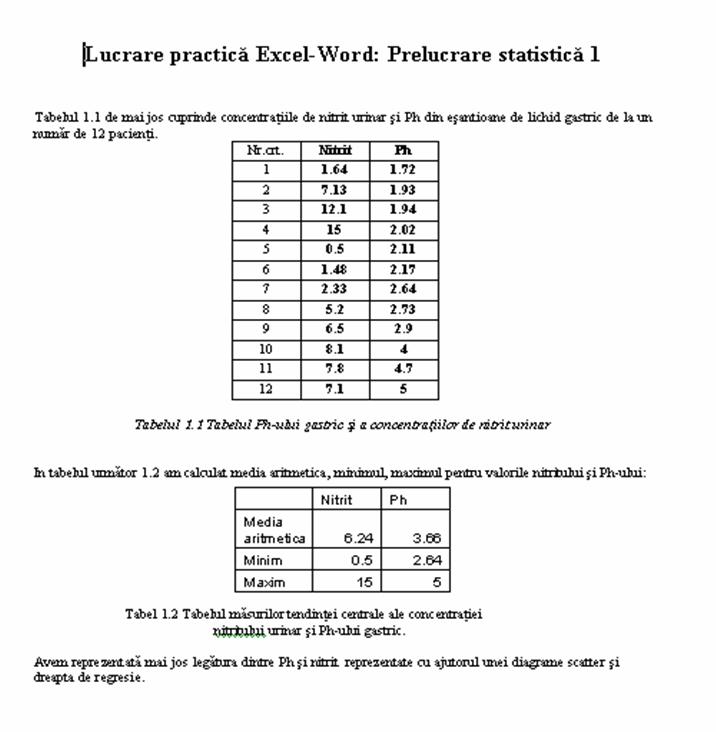
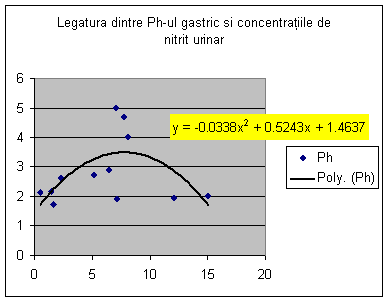
Instructiuni:
![]()
Teme de lucru
Concepeti în PowerPoint urmǎtoarea prezentare:
(Vezi manualul: "Informatica medicala aplicata" pag.60-69)
Problema 1.
Laborator Access
Problema1: Sa se realizeze o baza de date care sa monitorizeze valorile glicemiei si colesterolului unui grup de pacienti.
Solutie propusa: Realizarea unei baze de date folosind Microsoft Access: Start -
Programs - Microsoft Access. Se va deschide aplicatia Access. În
partea din dreapta a aplicatiei, New File, veti selecta butonul
corespunzator unei aplicatii noi, respectiv ![]() .
Se va deschide o casuta de dialog în care trebuie sa
completati numele bazei de date, respectiv Cabinet.
.
Se va deschide o casuta de dialog în care trebuie sa
completati numele bazei de date, respectiv Cabinet.
Atentie!!! Baza de date trebuie sa fie realizata în folder-ul cu numele dvs.
Analiza: Specificatia (textul problemei) fiind foarte vaga se opteaza pentru folosirea urmatoarelor entitati:
Realizati 2 tabele, Pacienti si Consultatii (corespunzatoare entitatilor de mai sus), folosind optiunea Create table in Design View, cu urmatoarea structura :
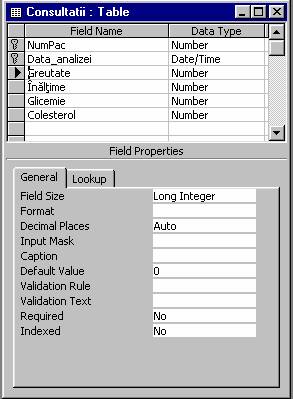
Alegerea cheii primare
Cheia primara este elementul care defineste unicitatea si consistenta datelor într-o baza de date.
Pentru baza noastra de date cheia primara a tabelului Pacienti este formata din câmpul Id_pacient, iar pentru tabelul Consultatii este formata din câmpurile NumPac si Data_analizei.
Pentru selectarea cheii primare: dupa selectarea câmpului sau
câmpurilor dorite se actioneaza butonul: ![]()
Dupa relizarea structurii fiecarui tabel, salvati-l cu Save As din meniul File cu denumirile: Pacienti respectiv Consultatii.
Diagrama entitate - relatie este:
|
|
|

Realizati legatura dintre cele doua tabele:
Pentru a realiza legatura dintre cele doua tabele:
În tabela Consultatii, în mod de editare structura (fereastra deschisa prin actionarea butonului Design din baza de date Cabinet), se alege linia continând NumPac si se modifica tipul câmpului din "Number" în "Lookup Wizard". Legatura se face la tabelul Pacienti, cu afisarea câmpului "Nume". Astfel continutul tabelelor va fi de forma :
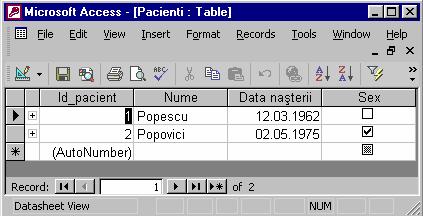
si respectiv:
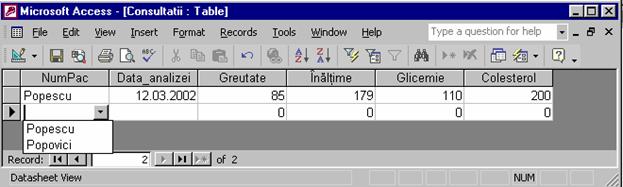
Introduceti cel putin 5 pacienti si pentru fiecare pacient cel putin 2 consultatii
Realizati urmatoarele interogari:
1. Se cere sa se afle care dintre pacienti are glicemia mai mare ca 110.
Realizati o interogare (Queries), utilizând optiunea Create Query in Design View, de forma:
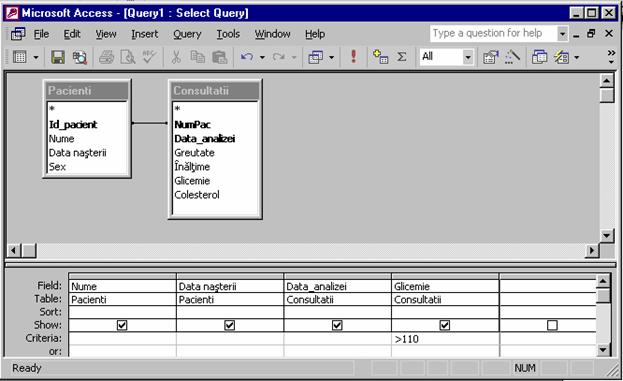
Salvati interogarea sub numele de Query1. Dupa realizare, deschideti Query-ul cu butonul Open si verificati corectitudinea datelor afisate ( ele trebuie sa îndeplineasca conditia data).
Analog primei interogari, gasiti pacientii care au valoarea colesterolului mai mare decât 220.
Realizati un raport:
Se cere sa se realizeze un raport cu interogarile realizate anterior.
Pentru aceasta, alegeti din lista de obiecte, obiectul Reports si ulterior optiunea Create report by using wizard. Din fereastra deschisa alegeti la obtiunea Tables/Queries Query1 ca si în figura urmatoare:
Alegeti toate câmpurile din Query1 pentru a fi introduse în raport
folosind butonul ![]() .
Alegeti ca si tip de raport tipul Stepped iar ca si stil
Corporate. Raportul se va numi Pacienti si va avea forma:
.
Alegeti ca si tip de raport tipul Stepped iar ca si stil
Corporate. Raportul se va numi Pacienti si va avea forma:
Analog, realizati raportul si pentru a doua interogare.
Problema2: Se cere realizarea unei baze de date Access care sa gestioneze activitatea unui cabinet de medic de familie cuprinzând tabelele:
Concepeti în Excel urmatoarele foi de calcul:
(Vezi manualul: "Aplicatii practice de informatica si statistica medicala" pag.58-59)
Problema
1. Realizati un
tabel cu aspectul de mai jos: 
1. Determinati costul spitalizǎrii pentru fiecare pacient stiind cǎ o zi de spitalizare este 300000lei.
Dacǎ Cultura bacterianǎ = 1, atunci Infectie bacterianǎ are valoarea "Da",
altfel Infectie bacterianǎ are valoarea "Nu" .
Se va folosi functia IF.
|
|
Durata spitalizarii |
Varsta |
Leucocite (x103) |
|
Media aritmetica |
=average(B2:B18) |
=average(C2:C18) |
=average(G2:G18) |
|
Minim |
=min(B2:B18) |
=min(C2:C18) |
=Min(G2:G18) |
|
Maxim |
=max(B2:B18) |
=max(C2:C18) |
=Max(G2:G18) |
Instructiuni
Instructiuni:Problema optionalǎ
Pe coloana cu Media pentru celula H3 aveti formula:=(C3+D3+E3+F3+G3)/5
Pe coloana cu Media ponderata pentru celula I3 aveti formula:=((C$1*C3)+(D$1*D3)+(E$1*E3)+(F$1*F3)+(G$1*G3))/H$1
Pe coloana cu Bursa Da/Nu pentru celula J3 aveti formula:=IF(OR(C3<5;D3<5;E3<5;F3<5;G3<5);"Nu";"Da")
Pentru coloanele Medie, Medie ponderata, Bursa formula se poate copia astfel: se selecteaza coloana si se alege optiunea din meniu Edit - Fill Down
|
