Ultimul capitol a definit contextul unui proces si a explicat algoritmii care îl manipuleaza; acest capitol va descrie utilizarea si implementarea apelurilor sistem care controleaza contextul unui proces. Apelul sistem fork creeaza un nou proces, apelul exit termina executia unui proces si apelul wait permite unui proces parinte sa-si sincronizeze executia cu terminarea unui proces fiu. Semnalele informeaza procesele despre aparitia evenimentelor asincrone. Deoarece nucleul sincronizeaza executia apelurilor sistem wait si exit prin intermediul semnalelor, sunt prezentate semnalele înaintea apelurilor sistem wait si exit.
Apelul sistem exec permite unui proces sa lanseze în executie un "nou" program, suprapunând peste spatiul propriu de adrese imaginea unui fisier executabil. Apelul sistem brk permite unui proces sa aloce mai multa memorie în mod dinamic; similar, sistemul permite stivei utilizator sa creasca în mod dinamic prin alocarea unui spatiu suplimentar când este necesar, folosind aceleasi mecanisme ca si pentru apelul sistem brk. În sfârsit, este prezentata pe scurt constructia principalelor bucle ale shell-lui si ale procesului init.
Figura 8.1 prezinta relatiile existente între apelurile sistem descrise în acest capitol si algoritmii de gestiune a memoriei descrisi în capitol anterior. Desi aproape toate apelurile sistem utilizeaza algoritmii sleep si wakeup, acest lucru nu este aratat în figura. În plus, apelul exec interactioneaza cu algoritmii sistemului de fisiere descrisi în capitolele 4 si 5.
|
Apelurile sistem care se refera la managementul memoriei |
Apelurile sistem care se refera la sincronizare |
Alte apeluri sistem |
|
||||||||
|
Fork |
exec |
brk |
Exit |
wait |
signal |
kill |
setpgrp |
setuid |
|
||
|
Dupreg Attachreg |
detachreg allocreg attachreg growreg loadreg mapreg |
growreg |
Detachreg | ||||||||
Fig. 8.1. Apelurile sistem ale proceselor si relatiile cu alti algoritmi
Singurul mod prin care un utilizator poate crea un nou proces în UNIX este folosirea apelului sistem fork. Procesul care apeleaza fork este numit proces parinte, iar noul proces creat este numit proces fiu. Sintaxa pentru apelul sistem fork este:
pid=fork();
La revenirea din apelul sistem fork, doua procese au copii identice ale contextului de nivel utilizator, exceptie facând valoarea de retur pid. În procesul parinte, pid are valoarea identificatorului procesului fiu; în procesul fiu, pid are valoarea zero. Procesul 0, creat intern de catre nucleu când sistemul este initializat este singurul proces care nu este creat prin intermediul apelului sitem fork.
Nucleul executa urmatoarea secventa de operatii la apelul sistem fork:
Aloca o intrare în tabela de procese penrtru noul proces.
Atribuie un identificator unic procesului fiu.
Face o copie logica a contextului procesului parinte. Deoarece în mod sigur portiuni ale procesului, cum ar fi zona de cod, pot fi partajate între procese, nucleu poate uneori incrementa numarul de referiri al unei regiuni în schimbul copierii regiunii la o noua locatie fizica în memorie.
Incrementeaza contorii tabelei de inoduri si tabelei de fisiere asociate procesului.
Întoarce în procesul parinte numarul identificatorului atribuit procesului fiu si valoarea zero în procesul fiu.
Implementarea apelului sistem fork nu este triviala deoarece procesul fiu pare a-si începe secventa de executie dintr-un punct aflat în "aer". Algoritmul pentru apelul fork difera putin de la sistemul cu paginare la cerere la sistemul cu swapping; discutia care urmeaza se bazeaza pe sistemul traditional cu swapping dar va sublinia locurile în care apar schimbari pentru s 848b12i istemul cu paginare la cerere. De asemenea se presupune ca sistemul are suficienta memorie pentru a pastra procesul fiu.
Capitolul 12 va considera cazul în care nu exista suficienta memorie pentru procesul fiu si descrie implementarea apelului sistem fork într-un sistem bazat pe
paginare la cerere.
|
algoritm fork intrari: niciuna iesiri: la procesul parinte, identificatorul procesul fiu (PID) la procesul fiu, 0 } |
Figura 8.2. Algoritmul pentru fork
Figura 8.2 prezinta algoritmul pentru apelul sistem fork. Nucleul se asigura mai întâi daca are resurse disponibile pentru a termina cu succes apelul sistem fork.
Într-un sistem bazat pe swapping, acesta are nevoie de spatiu în memorie sau pe disk pentru a pastra procesul fiu; într-un sistem bazat pe paginare la cerere, acesta trebuie sa aloce memorie pentru tabelele auxiliare cum ar fi tabelele de pagini. Daca nu sunt resurse disponibile, apelul sistem fork esueaza. Nucleul gaseste o intrare în tabela de procese pentru a începe constructia contextului procesului fiu si se asigura ca utilizatorul care a apelat fork nu are deja prea multe procese în curs de executie. De asemenea selecteaza un identificator unic pentru noul proces, acesta trebuind sa fie mai mare decât cel mai recent atribuit. Daca un alt proces detine deja acel numar identificator, nucleul încearca sa atribuie urmatorul numar identificator mai mare. Când numerele identificator ajung la valoarea maxima, atribuirea acestora începe din nou de la zero. Deoarece cele mai multe procese se executa pentru scurt timp, cele mai multe numere identificator nu sunt utilizate atunci când atribuirea identificatorilor se reia.
Sistemul limiteaza numarul proceselor care se pot executa simultan de catre un utilizator astfel ca acesta nu poate ocupa multe intrari din tabela de procese, lucru care ar duce la împiedicarea altor utilizatori de a crea procese noi. De asemenea utilizatorii obisnuiti nu pot crea un proces care ar duce la ocuparea ultimei intrari din tabela de procese, altfel sistemul s-ar putea bloca. Deci, daca nici un proces nu se va termina în mod natural, nu se va putea crea un nou proces deoarece nu exista nici o intrare libera în tabela de procese. Pe de alta parte, un administrator de retea poate executa un numar nelimitat de procese, numarul acestora fiind limitat doar de marimea tabelei de procese si, trebuie mentionat faptul ca acesta poate ocupa ultima intrare libera din tabela de procese. Administratorul de retea are, astfel, posibilitatea de a lansa un proces care sa forteze celelalte procese sa se termine (vezi Sectiunea 8.2.3 pentru apelul sistem kill).
Mai departe nucleul initializeaza intrarea din tabela de procese pentru procesul fiul creat prin copierea diferitelor câmpuri din intrarea procesului parinte. De exemplu, procesul fiu mosteneste numerele identificatorilor utilizator efectiv si real ai procesului parinte si valoarea nice a acestuia, utilizata pentru calcularea prioritatii de planificare. Nucleul depune identificatorul procesului parinte în intrarea procesului fiu, pune procesul fiu în structura arborescenta a proceselor si initializeaza diferiti parametri de planificare, cum ar fi valoarea prioritatii initiale, folosirea initiala a U.C.P. si alte câmpuri de timp. Starea initiala a procesului este "în curs de creare" ( Figura 7.1).
Nucleul ajusteaza acum contoarele de referinta pentru fisierele cu care procesul fiu este automat asociat.
Procesul fiu se afla în directorul curent al procesului parinte. Numarul proceselor care au acces la director va fi incrementat cu 1 si, în consecinta, nucleul incrementeaza contorul de referinta al inodului. Apoi, daca procesul parinte sau unul din stramosi executase apelul sistem chroot pentru a schimba radacina, procesul fiu mosteneste radacina schimbata si incrementeaza contorul de referinta al inodului respectiv. În final, nucleul cauta în tabela descriptorilor de fisiere utilizator specifica procesului parinte, gaseste intrarile pentru fisierele deschise, cunoscute de catre proces si incrementeaza contoarele de referinte din intrarile în tabela globala de fisiere asociate fisierelor deschise. Procesul fiu nu numai ca mosteneste drepturile de acces la fisierele deschise, dar si partajeaza accesul la fisiere cu procesul parinte deoarece ambele procese manipuleaza aceleasi intrari din tabela de fisiere. Efectul apelului sistem fork este identic cu cel al apelului dup raportat la fisierele deschise: o noua intrare în tabela descriptorilor de fisiere utilizator va adresa o intrare din tabela de fisiere pentru un fisier deschis. Totusi, pentru apelul sistem dup, intrarile din tabela descriptorilor de fisiere utilizator sunt asociate unui singur proces, pe când pentru apelul sistem fork, ele sunt în procese diferite.
Nucleul este acum gata pentru a crea contextul de nivel utilizator al procesului fiu. Nucleul aloca memorie pentru zona u area, regiunile si tabelele de pagini (PT) auxiliare ale procesului fiu, duplica fiecare regiune din procesul parinte folosind algoritmul dupreg si ataseaza fiecare regiune la procesul fiu folosind algoritmul attachreg. În sistemul bazat pe swapping, acesta copiaza continutul regiunilor care nu sunt folosite în comun într-o noua zona a memoriei principale. În sectiunea 7.2.4 s-a aratat ca zona u area contine un pointer catre intrarea asociata din tabela de procese. Exceptând acest câmp, continutul zonei u area a fiului este initial identic cu cel al zonei u area a parintelui, dar ele pot sa difere dupa terminarea apelului sistem fork. De exemplu procesul parinte poate deschide un nou fisier dupa terminarea apelului sistem fork, dar procesul fiu nu poate avea automat acces la el.
Pâna în prezent, nucleul a creat portiunea statica a contextului procesului fiu; acum acesta creeaza portiunea dinamica a acestuia. Nucleul copiaza cadrul 1 al contextului procesului parinte, continând contextul registru salvat si cadrul stivei nucleu pentru apelul sistem fork. Daca implementarea este una în care stiva nucleu este parte a zonei u area, nucleul creeaza automat stiva nucleu a procesului fiu când acesta creeaza zona u. area a acestuia. Altfel, procesul parinte trebui sa copieze propria stiva nucleu într-o zona privata de memoriei asociata cu procesul fiu. În ambele cazuri, stivele nucleu pentru procesele fiu si parinte sunt identice.
Nucleul creeaza apoi un cadru context identic (2) pentru procesul fiu, continând contextul registru salvat pentru cadrul context (1). Acesta seteaza numaratorul de program si alti registrii în contextul registru salvat astfel încât sa poata reface contextul procesului fiu, desi acesta nu a fost executat niciodata înainte, si astfel încât procesul fiu sa se poata recunoaste singur ca fiind un proces fiu când acesta se va executa. De exemplu, daca codul nucleu testeaza valoarea registrului 0 pentru a decide daca procesul este parinte sau fiu, acesta scrie valoarea corespunzatoare în contextul registru salvat corespunzator fiului în cadrul context 1. Mecanismul este similar cu cel discutat pentru o comutare de context.
Când contextul procesului fiu este gata, procesul parinte termina partea sa de apel fork prin schimbarea starii fiului în "gata de executie)" si prin returnarea catre utilizator a identificatorului de proces al fiului. Nucleul planifica mai târziu procesul fiu pentru executie cu ajutorul algoritmului normal de planificare si procesul fiu îsi termina astfel partea sa de apel fork. Contextul procesului fiu a fost completat de catre procesul tata; în nucleu, procesul fiu pare a fi trezit dupa asteptarea eliberarii unei resurse. Procesul fiu executa portiunea de cod din apelului sistem fork, în acord cu numaratorul de program, pe care nucleul l-a refacut din contextul registru salvat aflat în cadrul context 2 si întoarce zero la revenirea din apelul sistem.
Figura 8.3 da o imagine logica a proceselor parinte si fiu si a relatiilor lor cu alte structuri de date ale nucleului, imediat dupa terminarea apelului sistem fork. Concluzionând, ambele procese partajeaza fisierele pe care procesul parinte le-a deschis în timpul apelului sistem fork si contorul de referinta din intrarile tabelei de fisiere pentru aceste fisiere creste cu 1. Similar, procesul fiu are acelasi director curent si aceeasi radacina ca a parintelui si contoarele de referinta ale inodurilor apartinând acestor directoare cresc cu valoarea 1. Procesele au copii identice ale regiunilor de text, date si stiva utilizator; tipul regiunii si implementarea sistemului stabilesc daca procesele pot partaja o copie fizica a regiunii de text.
Consideram programul din figura 8.4, un exemplu de partajare a accesului la fisiere pe timpul executarii apelului sistem fork. Un utilizator poate apela programul cu doi parametri, numele unui fisier existent si numele unui fisier nou care va fi creat. Procesul deschide fisierul existent, creeaza noul fisier si presupunând ca nu apar erori, executa apelul sistem fork si creeaza un proces fiu.
Intern, nucleul face o copie a contextului procesului parinte pentru procesul fiu iar procesul parinte si procesul fiu se executa în spatii de adrese diferite.
Fiecare proces poate accesa copiile private ale variabilelor globale fdrd, fdwt si c si copiile private ale variabilelor de stiva argc si argv, dar nici un proces nu poate accesa variabilele celuilalt proces. Cu toate acestea, nucleul copiaza zona u area a procesului parinte în procesul fiu în timpul apelului sistem fork si fiul astfel mosteneste dreptul de acces la fisierele parintelui (acestea sunt fisierele pe care parintele le-a deschis si creat) folosind aceiasi descriptori de fisiere.

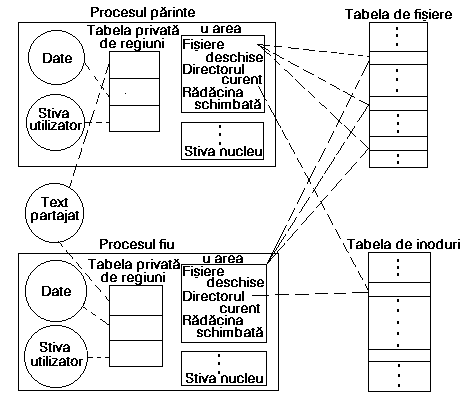
Figura 8.3. Relatii între procesul parinte si procesul fiu dupa
executarea apelului sistem fork
Procesele parinte si fiu apeleaza functia rdwrt independent, apoi executa un ciclu, citind câte un octet din fisierul sursa si scriindu-l apoi în fisierul destinatie. Functia rdwrt termina atunci când apelul sistem read întâlneste sfârsitul fisierului. Nucleul incrementase contoarele fisierelor sursa si destinatie din tabela de fisiere si descriptorii fisierelor din ambele procese refera aceeasi intrare din tabela de fisiere. Asa ca, descriptorii de fisier fdrd pentru ambele procese refera aceeasi intrare din tabela de fisiere pentru fisierul destinatie si descriptorii de fisier fdwr pentru ambele procese refera aceeasi intrare din tabela de fisiere pentru fisierul sursa.
#include <fcntl.h>
int fdrd, fdwt;
char c;
main (argc, argv)
int argc;
char *argv[ ];
rdwrt ()
}
Figura 8.4. Program în care procesele parinte si fiu partajeaza
accesul la fisiere
De aceea, cele doua procese nu vor citi sau scrie niciodata de la (la) aceleasi adrese, deoarece nucleul incrementeaza deplasamentul în fisier dupa fiecare apel de citire sau scriere. Desi procesele par sa copieze fisierul sursa de doua ori mai repede, continutul fisierului sursa depinde de ordinea în care nucleul a planificat procesele. Daca acesta planifica procesele astfel încât ele sa alterneze în executarea propriilor apeluri sistem, sau chiar daca alterneaza executia perechii de apeluri read-write dintr-un proces, continutul fisierului destinatie va fi identic cu continutul fisierului sursa. Dar sa consideram urmatorul scenariu, în care procesele sunt gata sa citeasca o secventa de doua caractere "ab" din fisierul sursa. Presupunem ca procesul parinte citeste caracterul 'a', dupa care nucleul face o comutare de context pentru a executa procesul fiu înainte ca parintele sa scrie. Daca procesul fiu citeste caracterul 'b' si îl scrie în fisierul destinatie înainte ca procesul parinte sa fie reprogramat, fisierul destinatie nu va contine sirul "ab", ci "ba". Nucleul nu garanteaza rata relativa de executie a proceselor.
Acum sa consideram programul din figura 8.5, care mosteneste descriptorii de fisiere 0 si 1 (intrarea si iesirea standard) de la procesul parinte. Executia fiecarui apel sistem pipe aloca în plus doi descriptori de fisiere în sirurile toÎpar si toÎchild. Procesul executa apelul sistem fork si face o copie a contextului sau: fiecare proces poate accesa datele proprii, ca în exemplul anterior. Procesul parinte închide fisierul sau standard de iesire (descriptorul de fisier 1) si duplica (dup) descriptorul de scriere întors de apelul sistem pipe în sirul toÎchild. Deoarece primul slot liber din tabela descriptorilor de fisiere utilizator a procesului parinte este chiar acela eliberat prin apelul sistem close, nucleul copiaza descriptorul de scriere rezultat în urma executarii apelului sistem pipe în slotul 1 al acesteia si astfel descriptorul fisierului standard de iesire devine descriptorul de scriere al pipe-lui pentru toÎchild. Procesul parinte face operatii similare astfel încât descriptorul intrarii standard sa devina descriptorul de citire al pipe-lui pentru toÎpar. Analog, procesul fiu îsi închide fisierul standard de iesire (descriptor 0) si duplica descriptorul de citire al pipe-lui pentru toÎchild. Întrucât primul slot liber în tabela descriptorilor de fisiere utilizator este slotul intrarii standard anterioare, intrarea standard a fiului devine descriptorul de citire al pipe-lui pentru toÎchild. Fiul face operatii similare astfel încât descriptorul iesirii standard sa devina descriptorul de scriere al pipe-lui pentru toÎpar. Ambele procese închid descriptorii de fisiere întorsi de apelul pipe ( o buna metoda de programare ). Ca rezultat, când procesul parinte scrie la iesirea standard, acesta scrie în pipe-ul toÎchild si trimite date procesului fiu, care citeste pipe-ul ca pe propria intrare standard. Când procesul fiu scrie la iesirea standard, acesta scrie în pipe-ul toÎpar si trimite datele procesului parinte care citeste pipe-ul ca pe propria intrare standard. Procesele schimba astfel mesaje prin intermediul pipe-urilor.
Rezultatele acestui exemplu sunt aceleasi, indiferent de ordinea în care procesele îsi executa apelurile sistem respective. Adica nu este nici o diferenta, daca procesul parinte revine din apelul sistem fork înaintea fiului sau dupa el. Similar, nu este nici o diferenta data de ordinea relativa în care procesele îsi executa apelurile sistem pâna când acestea intra în propriul ciclu: structurile nucleului sunt identice. Daca procesul fiu executa apelul sistem read înainte ca procesul parinte sa execute apelul sistem write, procesul fiu va intra în asteptare pâna când procesul parinte scrie în pipe si îl trezeste. Daca procesul parinte scrie pipe-ul înainte ca procesul fiu sa citeasca din pipe, procesul parinte nu va termina de citit de la intrarea sa standard pâna când fiul nu citeste de la intrarea sa standard si nu scrie la iesirea sa standard. Din acest motiv, ordinea de executie este fixata: fiecare proces termina un apel sistem read si un apel sistem write si nu poate executa urmatorul apel sistem read pâna când celalalt proces nu termina un apel sistem read si un apel sistem write.
#include <string.h>
char string[ ]=" Salut !";
main ()
}
/* procesul parinte se executa aici */
close(1); /* rearanjeaza intrarile si iesirile standard */
dup(to_chil [1]);
close(0);
dup(to_par [0]);
close(to_chil [1]);
close(to_par [0]);
close(to_chil [0]);
close(to_par [1]);
for(i=0; i<15; i++)
}
Figura 8.5. Utilizarea pipe-urilor, a apelurilor sistem dup si fork
Procesul parinte face exit dupa cele 15 iteratii din ciclu; apoi procesul fiu citeste "sfârsit de fisier" (EOF), deoarece pipe-ul nu are procese care sa scrie, si se termina. Daca procesul fiu ar fi scris în pipe dupa ce procesul parinte s-a terminat, primul ar fi receptionat un semnal care indica scrierea într-un pipe fara procese cititoare. Am mentionat mai devreme ca o metoda buna de programare este aceea de a închide descriptorii de fisiere inutili. Acest lucru este adevarat din trei motive. Primul, se conserva descriptorii de fisiere în limitele impuse de sistem. Al doilea, daca un proces fiu apeleaza execs, descriptorii fisierelor ramân asignati în noul context, asa cum se va vedea. Închiderea fisierelor neesentiale înainte unui apel exec permite programelor sa ruleze într-un mediu curat, numai cu descriptorii fisierelor standard de intrare, iesire si eroare deschisi. Al treilea, citirea dintr-un pipe întoarce "sfârsit de fisier" doar daca nici un proces nu are pipe-ul deschis pentru scriere.
Daca procesul cititor pastreaza descriptorul de scriere al pipe-lui deschis, acesta nu va sti niciodata când închid pipe-ul procesele care scriu. Exemplul de mai sus nu ar lucra corect daca procesul fiu nu si-ar închide descriptorii de scriere ai pipe-lui înaintea intrarii în ciclu.
Semnalele informeaza procesele despre aparitia evenimentelor asincrone. Procesele îsi pot trimite semnale prin intermediul apelului sistem kill, sau nucleul poate trimite intern semnale. Exista 19 semnale în versiunea de UNIX System V care pot fi clasificate dupa cum urmeaza :
Semnale pentru terminarea proceselor, transmise atunci cînd un proces executa apelul sistem exit sau când un proces executa apelul sistem signal cu parametrul "terminare fiu";
Semnale de atentionare în cazul exceptiilor produse de procese, de exemplu când un proces acceseaza o adresa în afara spatiului lor virtual de adrese, când un proces încearca sa scrie în zonele de memorie protejate la scriere (cum ar fi codul programului), când executa o instructiune privilegiata, sau pentru diferite erori hardware;
Semnale pentru situatii fara iesire aparute în timpul apelurilor sistem, cum ar fi lipsa resurselor în timpul executiei apelului sistem exec dupa ce spatiul initial de adrese fusese eliberat (vezi Paragraful 8.5);
Semnale determinate de conditii de eroare neasteptate aparute în timpul unui apel sistem, cum ar fi executarea unui apel sistem inexistent (procesul a furnizat numarul unui apel sistem care nu corespunde unui apel sistem corect), scrierea unui pipe care nu are proces cititor, sau folosirea unei valori "referinta" ilegale pentru apelul sistem lseek. Ar fi mult mai comod sa se întoarca o eroare în astfel de situatii în schimbul generarii unui semnal, dar folosirea semnalelor pentru a abandona procesele care nu se comporta corespunzator este mult mai practica (folosirea semnalelor în aceste cazuri suplineste lipsa verificarii erorilor de catre programator în cazul apelurilor sistem) ;
Semnale provenite de la procesele în modul utilizator, de exemplu când un proces doreste sa receptioneze un semnal alarm dupa un anumit timp, sau când procesele trimit unul altuia semnale în mod arbitrar, prin intermediul apelului sistem kill;
Semnale provenite de la interactiunea cu un terminal, atunci când un utilizator întrerupe un terminal, sau când un utilizator apasa tastele "break" sau "delete";
Semnale de urmarire a executiei unui proces.
Tratarea semnalelor difera în funtie de modul în care nucleul trimite un semnal unui proces, modul în care trateaza procesul un semnal si modul în care un proces îsi controleaza reactia la aparitia unui semnal. Pentru a trimite un semnal unui proces, nucleul seteaza un bit în câmpul "semnal" din intrarea tabelei de procese, corespunzator tipului semnalului receptionat. Daca procesul este în asteptare la o prioritate întreruptibila, nucleul îl trezeste. Sarcina celui care trimite semnalul (proces sau nucleu) este terminata. Un proces poate memora diferite tipuri de semnale receptionate, dar nu are memorie pentru a pastra numarul de semnale de acelasi tip pe care le-a receptionat. De exemplu, daca un proces receptioneaza un semnal hangup si un semnal kill, acesta seteaza bitii corespunzatori din câmpul semnal din tabela de procese, dar nu poate spune câte instante ale semnalelor au fost receptionate.

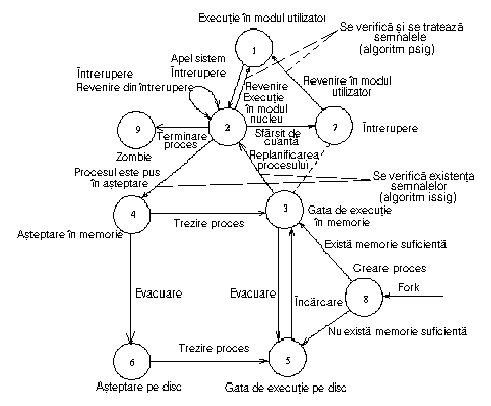
Figura 8.6. Verificarea si tratarea semnalelor în diagrama de stari ale
procesului
Nucleul verifica receptionarea unui semnal când un proces este gata sa se întoarca din modul nucleu în modul utilizator si când acesta intra sau paraseste starea de asteptare la o prioritate de planificare scazuta (vezi Figura 8.6). Nucleul trateaza semnalele doar când un proces se întoarce din modul nucleu în modul utilizator. Astfel, un semnal nu are un efect imediat într-un proces care ruleaza în modul nucleu. Daca un proces ruleaza în modul utilizator si nucleul trateaza o întrerupere care presupune trimiterea unui semnal catre proces, nucleul va recunoaste si trata semnalul când se va întoarce din întrerupere. Astfel, un proces nu se va executa niciodata în modul utilizator înainte de tratarea semnalelor importante. Figura 8.7 prezinta algoritmul pe care nucleul îl executa pentru a determina daca un proces a receptionat un semnal. Cazul semnalelor de tipul "terminare fiu" va fi tratat mai târziu. Asa cum se va vedea, un proces are posibilitatea de a ignora semnalele primite prin intermediul apelului sistem signal. În algoritmul issig, nucleul sterge indicatorii care marcheaza aparitia semnalelor pe care procesul vrea sa le ignore dar noteaza existenta semnalelor pe care acesta nu le ignora.
|
algoritmul issig /* test pentru receptionarea semnalelor */ intrari: niciuna iesiri: adevarat, daca procesul receptioneaza semnale pe care nu le ignora fals, în celelalte cazuri else if(daca nu ignora semnalul) return (adevarat); sterge bitul semnalului receptionat din câmpul semnal aflat în tabela de procese; } return (fals); } |
Figura 8.7. Algoritm pentru recunoasterea semnalelor
Nucleul trateaza semnalele în contextul procesului care le receptioneaza, deci un proces trebuie sa ruleze pentru a putea trata semnalele. Exista trei cazuri în tratarea semnalelor: procesul se termina la receptionarea semnalului, acesta ignora semnalul, sau executa o functie particulara (definita de utilizator). Actiunea implicita este de a apela exit în modul nucleu, dar un proces poate specifica o actiune speciala, pe care sa o execute la receptionarea unui anumit semnal cu ajutorul apelul sistem signal.
Sintaxa pentru apelul sistem signal este
oldfunction=signal (signum, function);
unde signum este numarul semnalului pentru care procesul specifica actiunea, function este adresa functiei (utilizator) pe care procesul doreste sa o apeleze la receptia semnalului si valoarea de revenire oldfunction valoarea parametrului function la ultimul apel al lui signal cu parametrul signum. Procesul poate apela signal cu valoarea 1 sau 0 în loc de adresa functiei: procesul va ignora viitoarele aparitii ale semnalului daca valoarea parametrului este 1 (Paragraful 8.4 trateaza cazul special pentru ignorarea semnalului "terminare fiu") si se termina daca valoarea parametrului este 0 (valoarea implicita). U area contine un sir de câmpuri pentru tratarea semnalelor, un câmp pentru fiecare semnal definit în sistem. Nucleul stocheaza adresa functiei definite de utilizator în câmpul care corespunde numarului semnalului. Modul de tratare a semnalelor de un anumit tip nu are efect în tratarea semnalelor de alte tipuri.
|
algoritmul psig /* tratarea semnalelor dupa recunoasterea existentei lor*/ intrari: niciuna iesiri: niciuna if (semnalul este de tipul celor pentru care sistemul trebuie sa creeze o imagine a procesului pentru depanare) apeleaza imediat algoritmul exit; } |
Figura 8.8. Algoritm pentru tratarea semnalelor
Când trateaza un semnal (figura 8.8) nucleul determina tipul semnalului si sterge bitul semnalului corespunzator din intrarea tabelei de procese, setat când procesul a receptionat semnalul. Daca functia de tratare a semnalului are valoarea implicita, nucleul va scoate imaginea a procesului pentru anumite tipuri de semnale înainte de terminarea acestora. Aceasta este o facilitate pentru programatori, permitând acestora depaneze programele. Nucleul scoate imaginea procesului pentru semnalele care sugereaza ca ceva este gresit în proces, cum ar fi faptul ca procesul executa o instructiune ilegala sau când acesta acceseaza o adresa în afara spatiului sau virtual de adrese. Dar nucleul nu scoate imaginea procesului pentru semnalele care nu implica o eroare la executarea programului. De exemplu, receptionarea unui semnal de întrerupere, trimis când un utilizator apasa tastele "delete" sau "break" la terminal, sugereaza ca utilizatorul doreste sa termine prematur un proces iar receptionarea semnalului hangup sugereaza ca terminalul login nu va mai fi "conectat" pentru mult timp. Aceste semnale nu implica faptul ca ceva este gresit în proces. Semnalul quit, totusi, provoaca scoaterea imaginii procesului chiar daca este initiat din afara. Uzual trimis prin apasarea tastei control + bara verticala, semnalul quit permite programatorului sa obtina o imagine a procesului care se executa, imagine care este folosita când acesta intra într-un ciclu infinit.
Când un proces receptioneaza un semnal pe care anterior a decis sa-l ignore, acesta continua ca si când semnalul nu ar fi aparut. Deoarece nucleul nu reseteaza câmpul din u area care arata ca semnalul este ignorat, procesul va ignora semnalul si la aparitia ulterioara a acestuia. Daca un proces receptioneaza un semnal pe care acesta anterior a decis sa-l intercepteze, acesta executa functia de tratare a semnalului specificata de utilizator imediat dupa revenirea în modul utilizator, dupa ce nucleul parcurge urmatorii pasi:
Nucleul acceseaza contextul registru salvat, gasind numaratorul de program si indicatorul de stiva pe care acesta îi salvase pentru revenirea în procesul utilizator.
Acesta sterge câmpul rutinei de tratare a semnalului din u area, setându-l la valoarea implicita.
Nucleul creeaza un cadru stiva nou în stiva utilizator, scriind aici valorile numaratorului de program si indicatorului de stiva restabilite din contextul registru salvat si aloca spatiu nou, daca este necesar. Stiva utilizator arata ca si cum procesul a apelat o functie de nivel utilizator (interceptorul de semnale) în punctul în care acesta a facut apelul sistem sau în punctul în care nucleul îl întrerupsese (înainte de recunoasterea semnalului).
Nucleul schimba contextul registru salvat: acesta seteaza valoarea numaratorului de programe la adresa functiei de interceptare a semnalului si seteaza valoarea indicatorului de stiva pentru a tine evidenta cresterii stivei utilizatorului.
Dupa întoarcerea din modul nucleu în modul utilizator, procesul va executa functia de tratare a semnalului; când acesta termina functia de tratare a semnalului, se întoarce în punctul din codul utilizator unde a aparut apelul sistem sau s-a produs întreruperea, imitând o întoarcere din apelul sistem sau întrerupere.
De exemplu, figura 8.9 contine un program care intercepteaza semnale de întrerupere (SIGINT) si îsi trimite un semnal de întrerupere (rezultatul apelului kill); figura 8.10 contine partile relevante ale programului dezasamblat pe un VAX 11/780. Când sistemul executa procesul, apelul la rutina de biblioteca kill se va face la adresa ee (în hexazecimal) si rutina executa instructiunea chmk (schimbarea modului în modul nucleu) la adresa 10a pentru a face apelul sistem kill. Adresa de retur din apelul sistem este 10c.
În timpul executarii apelului sistem, nucleul trimite un semnal de întrerupere catre proces. Nucleul ia în considerare semnalul de întrerupere când se întoarce în modul utilizator, scoate adresa 10c din contextul registru salvat si o plaseaza în stiva utilizator.
Nucleul ia adresa functiei de interceptare a semnalului (catcher), 104, si o pune în contextul registru salvat. Figura 8.11 ilustreaza starile stivei utilizator si contextul registru salvat.
Exista câteva anomalii în algoritmul descris aici pentru tratarea semnalelor. Prima si cea mai importanta este ca înainte ca un proces sa se întoarca în modul utilizator dupa ce acesta trateaza un semnal, nucleul sterge câmpul din u area care contine adresa functiei utilizator de tratare a semnalului. Daca procesul doreste sa trateze semnalul din nou, acesta trebuie sa apeleze din nou apelul sistem signal.
Aceasta are din nefericire si alte consecinte: o conditie de concurenta rezulta deoarece a doua instanta a semnalului poate sosi înainte ca procesul sa aiba ocazia sa invoce apelul sistem. Pentru ca procesul este executat în modul utilizator, nucleul ar putea face o comutare de context, crescând sansa ca acesta sa receptioneze semnalul înaintea resetarii interceptorului de semnal.
|
#include <signal.h> main() catcher() |
Figura 8.9. Codul sursa al programului care intercepteaza semnale
**** DEZASAMBLORUL VAX ****
#main()
e4:
e6: pushab 0x18(pc)
ec: pushl $0x2
# urmatoarea linie apeleaza signal
ee: calls $0x2,0x23(pc)
f5: pushl $0x2
f7: clrl -(sp)
# urmatoarea linie apeleaza rutina de biblioteca kill
f9: calls $0x2,0x8(pc)
100: ret
101: halt
102: halt
103: halt
#catcher()
104:
106: ret
107: halt
#kill()
# urmatoarea linie executa o 'instructiune trap'
(schimba modul în modul nucleu)
10a: chmk $0x25
10c: bgequ 0x6 <0x114>
10e: jmp 0x14(pc)
114: clrl r0
116: ret
Figura 8.10. Dezasamblarea programului care intercepteaza semnale

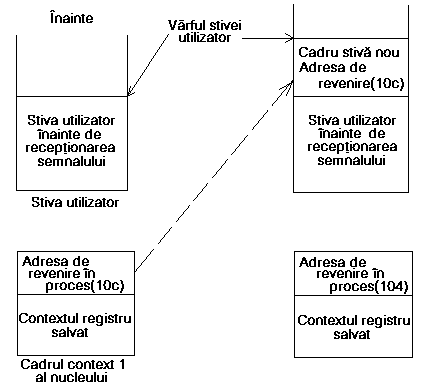
Figura 8.11. Stiva utilizator înainte si dupa receptionarea semnalului
Programul din figura 8.12 ilustreaza conditia de concurenta. Procesul apeleaza signal pentru a aranja interceptarea semnalului de întrerupere si executa functia sigcatcher. Apoi creeaza un proces fiu, invoca apelul sistem nice pentru a-si micsora prioritatea de planificare relativa la procesul fiu (vezi capitolul 9) si intra într-un ciclu infinit.
Procesul fiu îsi suspenda executia pentru 5 secunde pentru a da procesului parinte posibilitatea sa execute apelul sistem nice si sa-si scada prioritatea. Apoi procesul fiu intra într-un ciclu, trimitând un semnal de întrerupere (prin apelul sistem kill) procesului parinte în timpul fiecarei iteratii.
Daca apelul sistem kill se termina datorita unei erori, probabil pentru ca procesul parinte nu mai exista, procesul fiu se termina. Ideea este ca procesul parinte ar trebui sa invoce interceptorul de semnale de fiecare data când acesta receptioneaza un semnal de întrerupere. Interceptorul de semnale tipareste un mesaj si apeleaza din nou signal pentru a intercepta urmatoarea aparitie a unui semnal de întrerupere, si procesul parinte continua sa execute ciclul infinit
|
#include <signal.h> sigcatcher() main() /* prioritate scazuta, posibilitate mare de aparitie a conditiilor de concurenta */ nice(10); for(;;); } |
Figura 8.12. Program ce demonstreaza conditiile de concurenta în
interceptarea semnalelor
Este posibil sa apara, totusi, urmatoarea secventa de evenimente:
1. Procesul fiu trimite un semnal de întrerupere procesului
parinte.
2. Procesul parinte intercepteaza semnalul si apeleaza interceptorul de semnale, dar nucleul întrerupe procesul si comuta contextul înaintea executarii apelului sistem signal.
3. Procesul fiu se executa din nou si trimite un alt semnal de întrerupere catre procesul parinte.
4. Procesul parinte receptioneaza al doilea semnal de întrerupere, dar acesta nu a facut setarile pentru a intercepta semnalul. Când acesta reia executia, se termina.
Programul a fost scris pentru a permite o astfel de comportare, deoarece invocarea apelului sistem nice de catre procesul parinte determina nucleul sa planifice procesul fiu mai des. Totusi este nedeterminat când va aparea acest efect.
Dupa cum afirma Ritchie, semnalele au fost proiectate ca evenimente care sunt fatale sau se pot ignora, nu în mod necesar ca evenimente care trebuiesc tratate si din acest motiv conditiile de concurenta nu au fost fixate în versiunile anterioare. Cu toate acestea, ele pun serioase probleme programelor care doresc sa intercepteze semnale. Problema ar putea fi rezolvata daca câmpul semnal nu ar fi sters la receptionarea semnalului. Dar o astfel de solutie ar putea da nastere unei noi probleme: daca semnalele sosesc continuu si sunt preluate, stiva utilizator ar putea creste peste limita admisa datorita numarului mare de apeluri. Ca alternativa, nucleul ar putea reseta valoarea functiei de tratare a semnalului astfel încât acestea sa ignore semnalele de tipul respectiv pâna când utilizatorul precizeaza din nou ce va face cu acestea. O astfel de solutie implica o pierdere de informatie, deoarece procesul nu are cum sa stie câte semnale receptioneaza. Totusi, pierderea de informatie nu este mai severa decât ar fi în cazul în care procesul receptioneaza mai multe semnale de un anumit tip înainte sa le poata trata. În sfârsit, sistemul BSD permite unui proces sa blocheze si sa deblocheze receptionarea unor semnale printr-un apel sistem nou; când un proces deblocheaza semnalele, nucleul trimite semnalele netratate care au fost blocate catre proces. Când un proces receptioneaza un semnal, nucleul blocheaza în mod automat receptionarea altor semnale pâna la tratarea completa a acestuia. Aceasta metoda este similara modului în care nucleul reactioneaza la întreruperile hardware: acesta blocheaza transmiterea de noi întreruperi în timp ce sunt tratate cele anterioare.
O a doua anomalie în tratarea semnalelor se refera la interceptarea semnalelor care apar în timp ce procesul se afla într-un apel sistem, asteptând la un nivel de prioritate întreruptibila. Semnalul determina procesul sa execute un apel longjmp din starea de asteptare, sa revina în modul utilizator si sa apeleze functia de tratare a semnalului. Când aceasta functie se termina, procesul apare ca si cum ar reveni din apelul sistem cu o eroare care indica faptul ca acesta a fost întrerupt.
Utilizatorul poate verifica eroarea întoarsa si relua apelul sistem, dar uneori este mai convenabil daca nucleul face automat acest lucru, asa cum se face în sistemul BSD.
O a treia anomalie apare în cazul în care un proces ignora un semnal. Daca semnalul soseste în timp ce procesul se afla în asteptare pe un nivel de prioritate intreruptibila, procesul se va trezi dar nu va executa un apel longjmp. Aceasta înseamna ca nucleul îsi da seama ca procesul ignora semnalul doar dupa ce îl trezeste si îl executa. O politica mai buna ar fi ca procesul sa fie lasat în asteptare. Cu toate acestea, nucleul memoreaza adresa functiei de tratare a semnalului în u area, si u area nu poate fi accesata atunci când semnalul este trimis procesului. O solutie la aceasta problema ar fi înscrierea adresei functiei de tratare a semnalului în intrarea din tabela de procese, unde nucleul ar putea verifica daca procesul trebuie trezit la receptionarea unui semnal. Ca o alternativa, procesul ar putea imediat sa se întoarca în starea " asteptare" utilizând algoritmul sleep, daca îsi da seama ca nu ar fi trebuit trezit. Cu toate acestea, procesele utilizator nu realizeaza daca procesul a fost trezit, deoarece nucleul mentine intrarea în algoritmul sleep într-o bucla while (vezi Capitolul 2), punând procesul înapoi în asteptare daca evenimentul pentru care astepta nu a aparut într-devar.
În sfârsit, nucleul nu trateaza semnalele "terminare fiu" la fel ca pe celelalte semnale. În particular, când procesul îsi da seama ca a primit un semnal "terminare fiu", pune pe zero câmpul semnal din intrarea în tabela de procese si în acest caz actioneaza ca si cum nici un semnal nu ar fi fost transmis. Efectul unui semnal "terminare fiu" este trezirea unui proces care asteapta pe un nivel de prioritate întreruptibila. Daca procesul intercepteaza un semnal "terminare fiu", el apeleaza functia de tratare utilizator ca si pentru alte semnale. Operatiile pe care le face nucleul daca procesul ignora semnalele "terminare fiu", vor fi discutate în paragraful 8.4. În sfârsit, daca un proces invoca apelului sistem signal cu parametrul "terminare fiu", nucleul trimite procesului apelant un semnal "terminare fiu" daca acesta are procese în starea zombie. În paragraful 8.4. se vor prezenta conventiile pentru apelul signal cu parametrul "terminare fiu".
Desi procesele într-un sistem UNIX sunt identificate printr-un numar unic (PID), sistemul trebuie sa identifice uneori procesele dupa "grup". De exemplu, procesele cu un stramos comun care este un shell de logare în sistem sunt în general înrudite si de aceea toate aceste procese primesc semnale când un utilizator apasa tastele "Delete" sau "Break" sau când linia catre terminal este întrerupta. Nucleul utilizeaza identificatorul grupului de procese pentru a identifica grupurile de procese înrudite care trebuie sa primeasca un semnal comun la aparitia anumitor evenimente. Acesta salveaza identificatorul grupului de procese în tabela de procese; procesele aflate în acelasi grup au acelasi identificator de grup.
Apelul sistem setpgrp initializeaza numarul de grup pentru un proces si-l seteaza ca fiind egal cu valoarea identificatorului de proces propriu. Sintaxa apelului sistem este:
grp=setpgrp();
unde grp este noul numar al grupului de procese. Un proces fiu retine numarul de grup de procese al procesului parinte în timpul apelului sistem fork. Setpgrp are, de asemenea, importanta în setarea terminalului de control al unui proces (vezi Paragraful 6.3.5.).
Procesele trimit semnale folosind apelului sistem kill. Sintaxa pentru acest apel este:
kill (pid, signum)
unde pid identifica setul de procese care primesc semnalul si signum este numarul semnalului trimis. În lista care urmeaza se arata corespondenta dintre valorile parametrului pid si seturile de procese.
Daca pid este un întreg pozitiv, nucleul trimite un semnal procesului care are identificatorul de proces pid.
Daca pid este 0, nucleul trimite semnal tuturor proceselor din grupul procesului care a trimis semnalul.
Daca pid este -1, nucleul trimite semnalul tuturor proceselor al caror identificator al utilizatorului real este egal cu identificatorul utilizatorului efectiv al procesului care a trimis semnalul (Paragraful 8.6. va defini identificatorul utilizatorului real si efectiv). Daca procesul care trimite semnalul are identificatorul utilizator efectiv al superutilizatorului, nucleul trimite semnalul tuturor proceselor cu exceptia proceselor 0 si 1.
Daca pid este un întreg negativ diferit de -1, nucleul trimite semnalul tuturor proceselor din grupul de procese care au valoarea absoluta egala cu valoarea parametrului pid.
În toate cazurile, daca procesul care trimite semnalul nu are identificatorul utilizatorului efectiv egal cu al superutilizatorului, sau daca identificatorul sau utilizator efectiv sau real este diferit de identificatorul utilizator efectiv sau real al procesului care receptioneaza, kill esueaza.
#include <signal.h>
main()
}
kill(0,SIGINT);
}
Figura 8.13. Exemplu de utilizare a lui Setpgrp
În programul din figura 8.13, procesul schimba numarul sau de grup si creeaza 10 procese fiu. La creare, fiecare proces fiu are acelasi numar de grup cu al procesului parinte, dar procesele create în timpul iteratiilor impare din ciclu îsi modifica numarul de grup. Apelurile sistem getpid si getpgrp întorc identificatorul procesului si identificatorul grupului pentru procesul care se executa, iar apelului sistem pause suspenda executia procesului pâna când acesta receptioneaza un semnal. La sfârsit, procesul parinte executa apelul sistem kill si trimite un semnal de întrerupere tuturor proceselor din grupul sau. Nucleul trimite semnalul catre cele 5 procese "pare" care nu si-au schimbat propriul numar de grup de procese, dar cele 5 procese "impare" continua ciclul.
Într-un sistem UNIX procesele se termina prin executia apelului sistem exit. Un proces care intra în starea zombie (vezi Figura 7.1), îsi abandoneaza resursele si îsi distruge contextul mai putin intrarea din tabela de procese. Sintaxa pentru apel este:
exit (status)
unde valoarea status este întoarsa procesului parinte pentru examinare.
algoritm exit
intrari: codul de retur pentru procesul parinte
iesiri: niciuna
închide toate fisierele (versiunea interna a algoritmului close);
elibereaza directorul curent (algoritmul iput);
elibereaza radacina curenta (schimbata) daca exista (algoritmul
iput);
elibereaza regiunile si memoria asociata procesului (algoritmul
freereg);
scrie înregistrarea cu informatii de contabilitate;
trece procesul în starea zombie;
atribuie valorii identificatorului procesului parinte pentru toti
fii, valoarea identificatorului procesul init (1);
daca vreun proces fiu era în starea zombie, trimite semnalul "terminare fiu" catre procesul init;
trimite semnal "terminare fiu" procesului parinte;
comuta contextul;
}
Figura 8.14. Algoritmul pentru terminarea proceselor
Procesele pot apela exit explicit sau implicit la sfârsitul programului: rutina de initializare existenta în toate programele C apeleaza exit când programul revine din functia main care este punctul de intrare al tuturor programelor. Ca o alternativa, nucleul poate apela exit intern pentru un proces la primirea unor semnale pe care nu doreste sa le intercepteze, dupa cum s-a discutat anterior. În acest caz, valoarea parametrului status este numarul semnalului.
Sistemul nu impune limite de timp pentru executia unui proces si astfel procesele pot exista pentru o perioada îndelungata. De exemplu, procesele 0 si 1 exista de-a lungul întregii functionari a sistemului. Alte exemple sunt procesele getty, cate urmaresc o linie de terminal, asteptând logarea unui utilizator, si procesele administrative dedicate.
Figura 8.14. prezinta algoritmul exit. Nucleul mai întâi dezactiveaza tratarea semnalelor de catre proces deoarece aceasta nu mai are nici un sens. Daca procesul care se termina este un lider de grup de procese asociat cu un terminal de control (vezi Paragraful 6.3.5), nucleul presupune ca utlizatorul nu mai face nimic util si trimite un semnal de întrerupere catre toate procesele aflate în grupul de procese. Astfel, daca un utilizator tasteaza "sfârsit de fisier" (CTRL+D) în timp ce mai exista procese în executie asociate terminalului, procesul care se termina le va trimite un semnal de întrerupere. Nucleul initializeaza, de asemenea, numarul de grup cu 0 pentru procesele din grup, deoarece este posibil ca mai târziu un alt proces sa obtina identificatorul procesului care tocmai s-a terminat si sa fie de asemenea lider de grup. Procesele care au apartinut vechiului grup nu vor apartine si noului grup. Nucleul parcurge descriptorii fisierelor deschise, închizându-le pe fiecare prin algoritmul intern close, si elibereraza inodurile care au fost folosite pentru directorul curent si radacina schimbata (daca exista) prin algoritmul iput.
Nucleul elibereaza apoi toata memoria utilizatorului prin eliberarea regiunilor corespunzatoare cu algoritmul detachreg si schimba starea procesului în zombie. El salveaza codul de stare al apelului exit si timpii de executie în modurile utilizator si nucleu acumulati de proces si descendentii lui în tabela de procese. Descrierea apelului wait în paragraful 8.4 arata cum un proces obtine datele de timp pentru procesele descendente. Nucleul mai scrie, de asemenea, o înregistrare cu informatii de contabilitate într-un fisier global care contine diferite statistici cum ar fi identificatorul utilizatorului, utilizarea U.C.P. si a memoriei, precum si cantitatea de operatii de intrare/iesire. Programele de nivel utilizator pot citi mai târziu fisierul de contabilitate pentru a obtine diferite date statistice utile pentru urmarirea performantelor si pentru taxarea clientului în functie de serviciile oferite.
La sfârsit, nucleul deconecteaza procesul de la arborele de procese facând ca procesul 1 (init) sa adopte toate procesele sale fiu. Aceasta presupune ca procesul 1 sa devina parintele legal al tuturor proceselor fiu în executie pe care procesul care se termina le-a creat. Daca vreunul din procesele fiu este în starea zombie, procesul care se termina trimite catre procesul init semnalul "terminare fiu" pentru ca acesta sa-l stearga din tabela de procese (vezi Paragraful 8.9.); procesul care se termina trimite si parintelui sau un semnal "terminare fiu". Într-un scenariu tipic, procesul parinte executa un apel sistem wait pentru a se putea sincroniza cu procesul fiu care se termina. Procesul aflat în starea zombie face o comutare de context astfel ca nucleul poate sa planifice un alt proces pentru executie; nucleul nu va planifica pentru executie un proces aflat în starea zombie.
În programul din figura 8.15 un proces creeaza un fiu care îsi tipareste propriul identificator si executa apelul sistem pause suspendându-si executia pâna când primeste un semnal. Procesul parinte tipareste identificatorul procesului fiu si se termina întorcând identificatorul procesului fiu drept cod de stare. Daca apelul exit nu ar fi prezent, rutina de initializare ar apela exit la întoarcerea programului din functia main. Procesul fiu creat de parinte continua sa existe pâna când primeste un semnal, chiar daca procesul parinte s-a terminat.
main()
/* parinte */
printf("fiul PID %d\n", fiu);
exit(fiu);
}
Figura 8.15. Exemplu de utilizare a apelului sistem exit
Un proces îsi poate sincroniza executia cu terminarea unui proces fiu prin executia apelului sistem wait. Sintaxa pentru acest apel sistem este:
pid=wait (statÎaddr);
unde pid este identificatorul de proces al fiului în starea zombie, iar statÎaddr este adresa unui întreg din spatiul utilizator care va contine codul de terminare al procesului fiu.
Figura 8.16 prezinta algoritmul wait. Nucleul cauta un fiu al procesului în starea zombie si daca nu gaseste nici unul întoarce o eroare. Daca gaseste un fiu în starea zombie, extrage identificatorul procesului si parametrul furnizat de apelul sistem exit procesului fiu si întoarce aceste valori la terminarea apelului sistem. Un proces care se termina poate astfel specifica diferite coduri de retur pentru a preciza motivul terminarii sale, dar multe programe nu fac acest lucru în practica. Nucleul adauga timpul acumulat de executia procesului fiu în modurile utilizator si nucleu la câmpurile corespunzatoare din u area a procesului parinte si în final elibereaza intrarea din tabela de procese ocupata formal de procesul în starea zombie. Aceasta intrare devine disponibila pentru noi procese.
Daca procesul care executa apelulwait are procese fiu, dar niciunul dintre acestea nu se afla în starea zombie, el trece în asteptare la un nivel de prioritate întreruptibila pâna la sosirea unui semnal. Nucleul nu contine un apel explicit de trezire a unui proces care asteapta în apelul wait: astfel de procese sunt trezite numai la primirea unor semnale. Pentru orice semnal, cu exceptia semnalului "terminare fiu" procesul va reactiona dupa cum s-a descris anterior. Cu toate acestea, daca semnalul este "terminare fiu", procesul ar putea raspunde în mod diferit.
În cazul implicit el va fi trezit din starea de asteptare în apelul wait si va invoca algoritmul issig pentru a verifica daca a receptionat semnale. Algoritmul issig (Figura 8.7) recunoaste cazul special al semnalului "terminare fiu" si întoarce "fals". Ca urmare nucleul nu executa un apel longjmp din starea de asteptare ci se întoarce în apelul wait. Nucleul va relua bucla din apelul wait, gaseste un fiu în starea zombie -cel putin unul exista- elibereaza intrarea fiului din tabela de procese si iese din apelul sistem wait.
Daca procesul intercepteaza semnalul "terminare fiu", nucleul apeleaza rutina utilizator de tratare a semnalului, asa cum face pentru alte semnale.
Daca procesul ignora semnalele "terminare fiu", nucleul reia bucla din apelul wait, elibereaza sloturile din tabela de procese corespunzatoare proceselor fiu aflate în starea zombie si cauta alti fii.
|
algoritm wait intrari: adresa unei variabile de memorare a starii procesului care se termina iesiri: identificatorul procesului fiu si codul de terminare al acestuia if(procesul nu are fii) return eroare; asteapta la un nivel de prioritate întreruptibita pe evenimentul : terminarea unui proces fiu; } } |
Figura 8.16. Algoritmul pentru wait
De exemplu, un utilizator obtine diferite rezultate când apeleaza programul din figura 8.17 cu sau fara parametri. Sa consideram mai întâi cazul în care utilizatorul apeleaza programul cu un parametru (argc este 1, numele programului). Procesul parinte creeaza 15 procese fiu, care eventual se termina cu codul de retur i, valoarea variabilei din ciclu în momentul crearii procesului. Nucleul executa apelul sistem wait pentru procesul parinte, gaseste un proces fiu în starea zombie si întoarce identificatorul sau de proces si codul lui de terminare. Nu este determinat care din procesele fiu este gasit.
În biblioteca C, procedura pentru apelul sistem exit pastreaza codul de terminare în bitii 8 la 15 ai variabilei retÎcode si întoarce identificatorul procesului fiu pentru apelul wait. Astfel variabila retÎcode este egala cu 256*i, depinzând de valoarea lui i pentru procesul fiu si variabila retÎval este egala cu valoarea identificatorului procesului fiu. Daca utilizatorul apeleaza programul de mai sus cu un parametru (argc>1), procesul parinte apeleaza signal pentru a ignora semnalele " terminare fiu". Sa presupunem ca procesul parinte asteapta în apelul wait înainte ca vreun proces sa se termine: când un proces fiu se termina, el trimite un semnal "terminare fiu" catre procesul parinte: procesul parinte este trezit, pentru ca asteptarea sa în apelul wait este la un nivel de prioritate întreruptibila. Când procesul parinte ruleaza, acesta gaseste ca semnalul a fost "terminare fiu"; dar pentru ca el ignora aceste semnale, nucleul sterge intrarea procesului aflat în starea zombie din tabela de procese si continua executia apelului wait ca si cum nu ar fi existat nici un semnal.
|
#include <signal.h> main(argc,argv) int argc; char *argv[ ]; ret_val=wait(&ret_code); prinf("valoarea de retur= %x codul de retur= %x \n",ret_val, ret_code); } |
Figura 8.18. Exemplu de asteptare si ignorare a semnalelor " terminare fiu"
Nucleul executa procedura anterioara de fiecare data când procesul parinte receptioneaza un semnal "terminare fiu" pâna când în final ajunge în bucla apelului wait si constata ca procesul parinte nu mai are fii. Apelul sistem wait întoarce atunci -1. Diferenta între cele doua apelari ale programului este ca procesul parinte asteapta terminarea unui proces fiu în primul caz si a tuturor proceselor fiu în al doilea caz.
Versiunile mai vechi ale sistemului UNIX implementau apelurile exit si wait fara semnalul "terminare fiu". În loc sa trimita semnalul "terminare fiu", apelul exit trezea procesul parinte. Daca procesul parinte era în asteptare în apelul sistem wait,acesta se putea trezi, gasea un proces fiu în starea zombie si apoi se termina. Daca acesta nu era în asteptare în apelul wait, trezirea nu ar fi avut nici un efect; ar fi gasit un fiu în starea zombie în urmatorul apel wait. În mod similar, procesul init ar fi asteptat în apelul wait si procesele care s-ar fi executat l-ar fi trezit pentru a adopta noi procese aflate în starea zombie.
Problema acestei implementari este imposibilitatea înlaturarii proceselor în starea zombie daca procesul parinte nu executa un apel wait. Daca un proces creeaza mai multe procese fiu dar nu executa niciodata apelul wait, tabela de procese se va umple cu procesele fiu aflate în starea zombie dupa terminarea acestora. De exemplu, sa luam programul din figura 8.18. Procesul citeste din fisierul sau standard de intrare pâna când acesta întâlneste sfârsitul de fisier, creând un proces fiu la fiecare citire.
#include <signal.h>
main(argc,argv)
}
Figura 8.18. Exemplu care prezinta motivul implementarii semnalului
"terminare fiu"
Cu toate acestea, procesul parinte nu asteapta terminarea vreunui proces fiu deoarece doreste terminarea cât mai rapida a proceselor fiu iar un proces fiu poate se poate termina dupa un timp îndelungat.
Daca procesul parinte executa apelul signal pentru a ignora semnalele "terminare fiu" , nucleul va elibera intrarile proceselor aflate în starea zombie în mod automat. Altfel, procesele aflate în starea zombie ar putea umple, eventual la maxim, locurile permise în tabela de procese.
Apelul sistem exec apeleaza un alt program suprapunând peste spatiul de memorie al unui proces o copie a unui fisier executabil. Continutul contextului de nivel utilizator care a existat înaintea apelului exec nu mai este accesibil pentru mult timp cu exceptia parametrilor apelului exec pe care nucleul îi copiaza din vechiul spatiu de adresa în cel nou. Sintaxa apelului sistem este:
execve(numeÎfisier, argv, envp)
unde numeÎfisier este numele fisierului executabil apelat, argv este un sir de pointeri catre caractere care sunt parametrii programului executabil iar envp este un sir de pointeri catre caractere care reprezinta mediul programului executat. Exista mai multe functii de biblioteca care apeleaza exec cum ar fi execl, execv, execle, etc. Când un program foloseste parametrii în linia de comanda, cum ar fi
main(argc,argv)
parametrul argv este o copie a parametrului argv pentru apelul exec.
copiaza parametrii apelului exec în noua regiune de stiva a
utilizatorului;
procesare speciala pentru programele de tip setuid, si pentru
executia pas cu pas;
elibereaza inodul fisierului (algoritmul iput);
}
Figura 8.19. Algoritmul pentru apelul altor programe
Figura 8.20 prezinta formatul logic al unui fisier executabil, asa cum exista în sistemul de fisiere, generat de obicei de asamblor sau încarcator. Acesta contine 4 parti:
1. Antetul principal care precizeaza câte sectiuni sunt în fisier, adresa de start pentru executia procesului si "numarul magic" care da tipul fisierului executabil.
2. Antetele de sectiuni care descriu fiecare sectiune din fisier, dând marimea sectiunii, adresele virtuale pe care ar trebui sa le ocupe sectiunea atunci când ruleaza în sistem si alte informatii.
3. Sectiunile de date (text) care sunt initial încarcate în spatiul de adrese al procesului.
4. Diferite sectiuni care pot contine tabele de simboluri si alte date utile pentru depanare.
Formatele specifice au evoluat de-a lungul anilor dar toate fisierele executabile au continut un antet principal cu un "numar magic".
Numarul magic este un întreg pe 8 biti care identifica fisierul ca un modul încarcabil si da nucleului posibilitatea sa distinga diferite caracteristici de rulare ale sale. De exemplu, folosirea unui anumit numar magic pe un PDP 11/70 informeaza nucleul ca procesul poate utiliza pâna la 128 ko de memorie în loc de 64 ko; numarul magic joaca, de asemenea, un rol important în sistemele cu paginare, dupa cum se va vedea în capitolul 12.

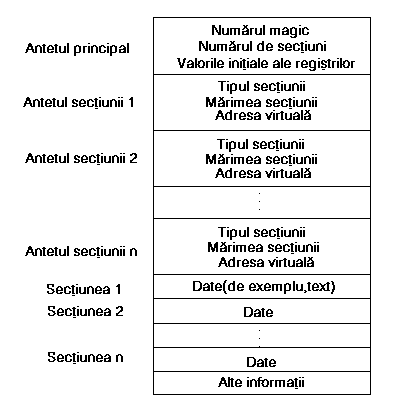
Figura 8.20. Imaginea unui fisier executabil
În acest moment, nucleul a accesat inodul fisierului executabil si a verificat daca îl poate executa. Nucleul este pe punctul de a elibera resursele de memorie care formeaza contextul de nivel utilizator al procesului. Dar, deoarece parametrii pentru noul program sunt continuti în spatiul de memorie care trebuie eliberat, nucleul copiaza parametrii din vechiul spatiu de memorie care trebuie eliberat într-un buffer temporar, pâna când vor fi atasate regiunile noului spatiu de memorie. Deoarece parametrii apelului exec sunt adresele utilizator ale unor câmpuri care contin siruri de caractere, nucleul copiaza adresele câmpurilor si apoi sirurile de caractere în spatiul nucleului pentru fiecare câmp în parte. El ar putea alege diferite locuri pentru a pastra sirurile de caractere, în functie de implementare. Cele mai obisnuite locuri sunt stiva nucleu, zonele nealocate (cum ar fi paginile) de memorie care pot fi împrumutate temporar sau memoria secundara, cum ar fi un dispozitiv de swapping.
Cea mai simpla implementare pentru copierea parametrilor în noul context de nivel utilizator este folosirea stivei nucleu. Dar, deoarece configurarea sistemului impune în mod obisnuit o limita de marime pentru stiva nucleu si deoarece parametrii apelului exec pot avea o lungime variabila, aceasta implementare trebuie sa fie combinata cu altele. Din celelalte variante, implementarile utilizeaza cea mai rapida metoda. Daca este usor sa se aloce pagini de memorie, o astfel de metoda este preferabila deoarece accesul la memoria primara este mai rapid decât la cea secundara (cum ar fi un dispozitiv de swapping).
Dupa copierea parametrilor apelului exec în locul de pastrare din nucleu, nucleul detaseaza vechile regiuni ale procesului folosind algoritmul detachreg. Tratamentul special pentru regiunile de text va fi discutat mai târziu în acest paragraf. În acest moment procesul nu are context de nivel utilizator asa încât erorile care apar de acum înainte duc la terminarea sa, cauzata de un semnal. Astfel de erori pot fi: rularea în afara spatiului din tabela de regiuni a nucleului, încercarea de a încarca un program a carui marime depaseste limita sistemului, încercarea de a încarca un program ale carui adrese de regiuni se suprapun, si altele. Nucleul aloca si ataseaza regiuni pentru text si date, încarcând continutul fisierului executabil în memoria principala (algoritmii allocreg, attachreg si loadreg). Regiunea de date a unui proces este initial împartita în doua: date initializate în momentul compilarii si date care nu se initializeaza în momentul compilarii ("bss"). Alocarea si atasarea initiala a regiunilor de date se face pentru datele initializate. Nucleul mareste apoi regiunea de date folosind algoritmul growreg pentru datele "bss" si initializeaza valoarea acestora cu 0.
În final, aloca o regiune pentru stiva procesului, o ataseaza procesului si aloca memorie pentru pastrarea parametrilor apelului exec. Daca nucleul a salvat parametrii apelului exec în pagini de memorie, acesta poate utiliza acele pagini pentru stiva. În caz contrar, el copiaza parametrii apelului exec în stiva utilizatorului.
Nucleul sterge adresele interceptorilor de semnale utilizator din u area, deoarece acele adrese nu mai au sens în noul context de nivel utilizator. Semnalele care au fost ignorate ramân ignorate si în noul context. Nucleul seteaza apoi contextul registru salvat pentru modul utlizator, setând valorile initiale ale indicatorului de stiva si numaratorului program: încarcatorul a scris numaratorul de program initial în antetul fisierului. Nucleul executa actiuni speciale pentru programele de tip setuid si pentru executia proceselor pas cu pas. In final, el invoca algoritmul iput, eliberând inodul care a fost alocat initial prin algoritmul namei la începutul apelului exec. Utilizarea algoritmilor namei si iput în apelul exec corespunde deschiderii si închiderii unui fisier; starea unui fisier în timpul apelului exec este asemanatoare celei a unui fisier deschis cu exceptia absentei unei intrari în tabela de fisiere. Când procesul revine din apelul exec, el executa codul noului program. Totusi, este acelasi proces de dinainte de apelul exec: identificatorul sau de proces nu s-a schimbat, si nu s-a schimbat nici pozitia sa în ierarhia de procese. Numai contextul de nivel utilizator s-a schimbat.
main()
Figura 8.21. Utilizarea apelului sistem exec
De exemplu, programul din figura 8.21 creeaza un proces fiu care apeleaza exec. Imediat dupa ce procesul parinte si procesul fiu revin din apelul fork acestea executa copii independente ale programului. Când procesul fiu este pe cale de a apela exec, regiunea sa de cod (text) consta din instructiunile programului, regiunea sa de date contine sirurile "/bin/date", si "date", iar stiva sa contine cadrele stiva pe care procesul le-a introdus. Nucleul gaseste fisierul "/bin/date" în sistemul de fisiere, observa ca toti utilizatorii îl pot executa si determina daca este un modul încarcabil executabil. Prin conventie primul parametru al listei de parametri argv pentru apelul exec este calea catre numele fisierului executabil. Procesul are astfel acces la numele programului de nivel utilizator, ceea ce uneori reprezinta o caracteristica utila.
Nucleul copiaza apoi sirurile "/bin/date" si "date" într-o zona interna de pastrare si elibereaza regiunile de cod, date si stiva ocupate de proces. El aloca procesului regiuni noi de cod, date si stiva, copiaza sectiunea de text a fisierului "/bin/date" în regiunea de text si sectiunea de date a fisierului în regiunea de date. Nucleul reconstruieste lista initiala de parametri (aici sirul de caractere "date") si o pune în regiunea de stiva. Dupa apelul exec, procesul fiu nu mai executa vechiul program ci executa programul "date". Când programul "date" se termina, procesul parinte primeste starea de terminare a acestuia din propriul apel wait.
|
#include <signal.h> main() f() sigcatch(n) int n; |
Figura 8.22 Exemplu de program care scrie în regiunea proprie de text
Pâna acum, am presupus ca, textul si datele procesului ocupa sectiuni separate în programul executabil si, din acest motiv, regiuni separate la rularea programului. Sunt doua avantaje pentru pastrarea textului si a datelor programului separat: protectie si folosire în comun .
Daca textul si datele s-ar afla în aceeasi regiune, sistemul nu ar putea împiedica un proces sa-si suprascrie zona de text, pentru ca nu ar sti care adrese contin instructiuni si care date. Dar daca textul si datele sunt în regiuni separate, nucleul poate activa mecanismul de protectie hardware pentru a împiedica procesele sa-si suprascrie zona de text. Daca procesul încearca din greseala sa-si suprascrie spatiul sau de text, se genereaza o întrerupere de protectie care în mod obisnuit duce la terminarea procesului.
De exemplu, programul din figura 8.22 atribuie pointerului ip adresa functiei f si apoi aranjeaza sa fie interceptate toate semnalele. Daca programul este compilat astfel încât codul si datele sunt în regiuni separate, procesul care executa programul genereaza o întrerupere de protectie când se încearca sa se scrie continutul lui ip, deoarece se încearca scrierea în regiunea de cod care este protejata la scriere. Procesul intercepteaza semnalul si se termina fara a executa instructiunea printf din functia main. Totusi, daca programul a fost compilat astfel încât codul si datele sa fie în aceeasi regiune (regiunea de date), nucleul nu îsi da seama ca un proces a suprascris adresa functiei f. Adresa functiei f contine valoarea 1! Procesul executa instructiunea printf dar executa o instructiune nepermisa când se apeleaza functia f. Nucleul trimite semnalul SIGILL si procesul se termina. Pastrarea datelor si instructiunilor în regiuni separate face usoara protectia împotriva erorilor de adresare. Versiunile anterioare de UNIX permiteau codului si datelor sa se afle în aceeasi regiune din cauza limitarii lungimii proceselor impusa de calculatoarele PDP: programele erau mai mici si necesitau mai putini registri de "segmentare" daca codul si datele ocupau aceeasi regiune. Versiunea curenta a sistemului nu are o astfel de limitare a marimii proceselor si viitoarele compilatoare nu vor accepta optiunea de încarcare a codului si datelor în aceeasi regiune.
Al doilea avantaj al scrierii în regiuni separate a codului si datelor este ca se permite partajarea regiunilor. Daca procesul nu poate scrie în regiunea sa de cod, codul nu se poate schimba în timpul ce nucleul îl încarca din fisierul executabil. Daca mai multe procese executa un fisier, ele pot sa partajeze regiunea de cod, economisind memorie. Astfel, când nucleul aloca o regiune de cod pentru un proces în apelul sistem exec, acesta verifica daca fisierul executabil permite ca regiunea sa de text sa fie partajata, indicatie data de numarul magic.
|
|
|
algoritmul xalloc /* aloca si initializeaza regiunea de cod */ intrari: inodul fisierului executabil iesiri: niciuna ataseaza regiunea la proces (algoritmul attachreg); deblocheaza regiunea; return; } /* nu exista o regiune de cod...creeaza una */ aloca o regiune de cod (algoritmul allocreg); /* regiunea este blocata */ if( inodul are bitul sticky setat) comuta pe 0 indicatorul sticky al regiunii; ataseaza regiunea la adresa virtuala indicata de antetul indicat de inod (algoritmul attachreg); if(fisierul este formatat special pentru un sistem cu paginare) /* Capitolul 12 va prezenta acest caz */ else /* nu este formatat pentru un sistem cu paginare */ citeste codul fisierului în regiune (algoritmul loadreg); schimba protectia regiunii în tabela privata de regiuni în read only; deblocheaza regiunea; } |
|
}
Figura 8.23 Algoritmul pentru alocarea regiunilor de cod
Daca fisierul executabil permite partajarea regiunii sale de text, nucleul urmeaza algoritmul xalloc pentru a gasi o regiune existenta pentru codul fisierului sau pentru a asigna una noua (vezi figura 8.23).
În algoritmul xalloc, nucleul cauta în lista regiunilor active regiunea de cod a fisierului, identificând-o pe aceea al carei pointer indica inodul fisierului executabil. Daca o asemenea regiune nu exista, nucleul aloca o regiune noua (algoritmul alloreg), o ataseaza procesului (algoritmul attachreg), o încarca în memorie (algoritmul loadreg) si îi schimba protectia în read-only. Ultimul pas provoaca o întrerupere de protectie a memoriei daca un proces încearca sa scrie în regiunea de cod. Daca, în cautarea prin lista regiunilor active, nucleul localizeaza o regiune care contine codul fisierului, se asigura ca regiunea este încarcata în memorie (altfel asteapta) si o ataseaza procesului.
Nucleul deblocheaza regiunea la sfârsitul algoritmului xalloc si decrementeaza contorul regiunii mai târziu, când acesta executa algoritmul detachreg, în timpul apelului exit sau exec. Implementarea traditionala a sistemului contine o tabela de text pe care nucleul o manipuleaza în modul deja descris pentru regiunile de cod. Setul regiunilor de text poate fi astfel vazut ca o versiune moderna a vechii tabele de text.
Sa ne amintim ca atunci când se aloca o regiune pentru prima data prin algoritmul allocreg (Paragraful 6.5.2), nucleul incrementeaza contorul de referinte al inodului asociat cu regiunea, dupa ce acesta fusese incrementat în algoritmul namei (apelul iget) la începutul apelului exec. Pentru ca nucleul decrementeaza contorul de referinte o singura data în algoritmul iput, la sfârsitul apelului exec, contorul de referinte al inodului fisierului care este executat este cel putin egal cu 1: de aceea, daca un proces face un apel unlink pentru un fisier, continutul lui ramâne intact. Nucleul nu mai are nevoie de fisier dupa încarcarea sa în memorie, dar are nevoie de un pointer catre inodul fisierului, pointer situat într-un câmp din intrarea în tabela de regiuni, pentru a identifica fisierul care corespunde regiunii respective. Daca contorul de referinte ar fi fost redus la 0, nucleul ar fi putut realoca inodul din memoria interna altui fisier, compromitând semnificatia pointerului catre inod: daca utilizatorul ar fi executat un fisier nou, nucleul ar fi gasit regiunea de cod a vechiului fisier cu erori. Nucleul evita aceasta problema incrementând contorul de referinte al inodului în algoritmul allocreg, prevenind reasignarea inodului din memoria interna. Când procesul detaseaza regiunea de cod în timpul apelurilor exit sau exec, nucleul decrementeaza contorul de referinte în algoritmul freereg, mai putin în cazul în care inodul are bitul sticky setat, asa cum se va vedea.

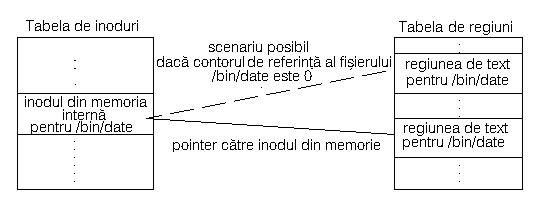
Figura 8.24 Relatiile între tabela de inoduri si tabela de regiuni
pentru partajarea codului
De exemplu, reconsideram executia fisierului "/bin/date" din figura 8.21 si presupunem ca acesta are zone de cod si date separate. Prima data procesul executa "/bin/date", apoi nucleul aloca o intrare pentru cod în tabela regiunilor (Figura 8.24) si lasa contorul de referinte al inodului la valoarea 1 (dupa executia completa a apelului exec). Când "/bin/date" se termina, nucleul parcurge algoritmii detachreg si freereg, decrementând contorul de referinte al inodului la 0. Totusi, daca nucleul nu ar fi incrementat contorul de referinte pentru inodul fisierului "/bin/date" prima data când s-a apelat exec, contorul de referinte ar fi 0 si inodul s-ar gasi în lista libera pe timpul executiei procesului. Sa presupunem ca un alt proces executa fisierul "/bin/who" si nucleul aloca inodul din memoria interna folosit anterior pentru fisierul "/bin/date" fisierului "/bin/who". Nucleul cauta în tabela regiunilor inodul fisierul "/bin/who", dar gaseste inodul fisierului "/bin/date". Presupunând[DV1] [DV2] ca regiunea contine codul fisierului "/bin/who", nucleul poate executa un program gresit. În consecinta, contorul de referinte al inodului fisierului care are zona de cod folosita în comun este cel putin 1, asa ca nucleul nu poate realoca inodul.
Posibilitatea de partajare a regiunii de cod permite nucleului sa scada timpul de începere a executiei unui program prin folosirea bitului sticky. Administratorul de sistem poate seta bitul sticky cu apelul sistem chmod pentru fisierelor executabile utilizate frecvent. Când un proces executa un fisier care are setat bitul sticky, nucleul nu poate elibera memoria alocata pentru cod când, mai târziu, este detasata regiunea în timpul apelurilor exit sau exec, chiar daca contorul de referinte scade la 0.
Nucleul lasa regiunea de cod intacta, cu contorul de referinte al inodului egal cu 1, chiar daca aceasta nu mai este atasata altui proces. Când alt proces executa fisierul, gaseste intrare în tabela de regiuni pentru codul fisierului. Timpul de start al procesului este mic, pentru ca el nu trebuie sa citeasca codul fisierului din sistemul de fisiere: daca codul se afla înca în memorie, nucleul nu face nici o operatiune de I/O pentru citirea codului; daca nucleul a evacuat codul în zona de swap, acesta încarca mai repede codul de pe dispozitivul de swap decât din sistemul de fisiere, asa cum se va vedea în capitolul 11.
Nucleul sterge intrarile pentru regiunile de cod in modul cu bitul sticky setat în urmatoarele cazuri:
1. Daca un proces deschide fisierul pentru scriere, operatiile de scriere vor schimba continutul fisierului, invalidând continutul regiunii.
2. Daca un proces schimba modul de acces la fisier (chmod) astfel încât bitul sticky nu mai este setat, fisierul nu trebuie sa mai ramâna în tabela de regiuni.
3. Daca un proces executa un apel unlink pentru fisier, nici un proces nu va mai putea sa-l execute în continuare pentru ca fisierul nu mai are intrare în sistemul de fisiere; din acest motiv nici un proces nou nu va accesa intrarea fisierului din tabela de regiuni. Pentru ca nu este nevoie de regiunea de cod, nucleul o poate sterge pentru a elibera unele resurse.
4. Daca un proces "demonteaza" sistemul de fisiere, fisierul nu va mai fi accesibil si nici un proces nu-l va mai putea executa,la fel ca în cazul precedent.
5. Daca nucleul ruleaza în afara spatiului de memorie pe dispozitivul swap, el încearca sa elibereze spatiul disponibil prin eliberarea regiunilor cu bitul sticky setat care sunt neutilizate în momentul respectiv. Desi alte procese pot avea nevoie curând de o astfel de regiune de cod, nucleul are mai multa nevoie de spatiu de memorie, imediat.
Regiunea de cod cu bitul sticky setat trebuie sa fie stearsa în primele doua cazuri pentru ca ea nu mai reflecta starea curenta a fisierului. Nucleul sterge intrarile regiunilor cu bitul sticky setat în ultimele trei cazuri, pentru ca acest lucru este mult mai practic.
Desigur, nucleul elibereaza regiunile doar daca nici un proces nu le utilizeaza în momentul respectiv (contorul lor de referinte este 0); altfel apelurile sistem open, unlink, unmount (cazurile 1,3 si 4) esueaza.
Scenariul pentru apelul sistem exec este putin mai complicat daca procesul se executa pe el însusi. Daca utilizatorul tipareste:
sh script
shell-ul creeaza un proces fiu si acesta executa shell-ul si comenzile din fisierul "script". Daca un proces se executa singur si permite partajarea propriei regiuni de cod, nucleul trebuie sa evite situatiile de blocare a inodurilor si a regiunilor. De aceea, nucleul nu poate bloca vechea regiune de cod,nu o poate mentine blocata, si apoi nu poate încerca sa blocheze noua regiune de cod, deoarece regiunile (veche si noua) sunt una si aceeasi. în schimb, nucleul paraseste vechea regiune de cod atasata la proces, pentru ca aceasta nu va fi utilizata niciodata.
Procesele apeleaza de obicei exec dupa fork; astfel procesul fiu copiaza spatiul de adrese al procesului parinte în timpul apelului sistem fork, suprascrie acest spatiu în timpul apelului exec si executa o imagine program diferita de cea a procesului parinte. Nu ar fi mai natural sa combinam cele doua apeluri într-unul singur pentru a apela programul si a-l rula ca pe un proces nou? Ritchie presupune ca apelurile sistem fork si exec sunt apeluri sistem diferite pentru ca atunci când s-a proiectat sistemul UNIX, el si Thomson au putut sa adauge apelul sistem fork fara a face prea multe schimbari asupra codului din nucleul existent.Separarea apelurilor fork si exec este importanta din punct de vedere functional, pentru ca procesele pot manipula proprii descriptori de fisiere standard de intrare si iesire independent pentru a initializa pipe-urile mai elegant decât daca ambele apeluri ar fi combinate într-unul singur. în exemplul de shell din paragraful 8.8. se va vedea aceasta trasatura.
Nucleul asociaza doi identificatori utilizator (UID) unui proces, indenpendent de identificatorul procesului: identificatorul utilizator real si identificatorul utilizator efectiv sau setuid. Identificatorul utilizator real identifica utilizatorul care este responsabil pentru rularea procesului. Identificatorul utilizator efectiv este folosit pentru a asigna dreptul de proprietate asupra fisierelor nou create, pentru a verifica drepturile de acces la fisier si dreptul de a trimite semnale catre procese prin intermediul apelului sistem kill.
Nucleul permite unui proces sa-si schimbe propriul identificator utilizator efectiv când executa un program de tip setuid sau când acesta executa apelul sistem setuid explicit.
Un program de tip setuid este un fisier executabil care are setat bitul setuid în câmpul drepturilor de acces. Când un proces executa un program de tip setuid, nucleul seteaza câmpurile identificatorului utilizator efectiv din tabela de procese si u area, la valoarea identificatorului proprietarului fisierului. Pentru a distinge cele doua câmpuri, vom numi câmpul din tabela de procese identificatorul utilizator " salvat ". Un exemplu va ilustra diferenta dintre cele doua câmpuri.
Sintaxa apelului sistem setuid este:
setuid(uid)
unde uid este noul identificator utilizator si rezultatul sau depinde de valoarea curenta a identificatorului utilizator efectiv. Daca identificatorul utilizator efectiv al procesului apelant este acela al superutilizatorului, nucleul reseteaza câmpurile celor doi identificatori utilizator real si efectiv din tabela de procese si u area, la valoarea uid. Daca identificatorul utilizator efectiv nu este acela al superutilizatorului, nucleul reseteaza identificatorul utilizator efectiv din u area la valoarea parametrului uid daca acesta are valoarea identificatorului utilizator real sau daca are valoarea identificatorului utilizator salvat. În celelalte cazuri, apelul sistem se întoarce cu eroare. În general, procesul mosteneste identificatorii sai (real si efectiv) de la procesul parinte în timpul apelului sistem fork si pastreaza aceste valori pe tot parcursul executiei apelului sistem exec.
Programul din figura 8.25 exemplifica apelul sistem setuid. Presupunem ca fisierul executabil generat prin compilarea programului are proprietar pe "maury" (identificatorul utilizator 8319), bitul sau setuid este activat, si toti utilizatorii au permisiunea sa-l execute. În plus, presupunem ca utilizatorii "mjb" (identificatorul utilizator 5088) si "maury" au în proprietate fisierele cu aceleasi nume, si ambele fisiere au setat dreptul de acces " read-only" . Utilizatorul "mjb" vede urmatoarele date la iesire când executa programul:
uid 5088 euid 8319
fdmjb -1 fdmaury 3
dupa setuid (5088): uid 5088 euid 5088
fdmjb 4 fdmaury -1
dupa setuid (8319): uid 5088 euid 8319
Apelurile sistem getuid si geteuid întorc identificatorii utilizator real si efectiv ai procesului, 5088 si respectiv 8319 pentru utilizatorul "mjb". De aceea, procesul nu poate deschide fisierul "mjb", pentru ca identificatorul sau utilizator efectiv (8319) nu are drept de citire a fisierului, dar poate deschide fisierul "maury".
#include<fnctl.h>
main()
Figura 8.25 Exemplu de întrebuintare a apelului setuid
Dupa apelul setuid pentru a schimba identificatorul utilizator efectiv al procesului cu identificatorul utilizator real ("mjb"), a doua instructiune printf tipareste valorile 5088 si 5088, si identificatorul utilizator pentru "mjb". Acum procesul poate deschide fisierul "mjb", pentru ca identificatorul sau utilizator efectiv are drept de citire a fisierului, dar procesul nu poate deschide fisierul "maury". În final, dupa apelul setuid, pentru a schimba identificatorul utilizator efectiv cu valoarea setuid salvata (8319), a treia instructiune printf va tipari din nou valorile 5088 si 8319. Ultimul caz arata ca procesul poate executa un program de tip setuid si îsi poate schimba identificatorul sau utilizator efectiv cu identificatorul utilizator real.
Utilizatorul "maury" vede urmatoarele date la iesire când executa programul:
uid 8319 euid 8319
fdmjb -1 fdmaury 3
dupa setuid (8319): uid 8319 euid 8319
fdmjb -1 fdmaury 4
dupa setuid (8319):uid 8319 euid 8319
Identificatorii utilizator real si efectiv sunt întotdeauna 8319: procesul nu poate deschide fisierul "mjb" dar poate deschide fisierul "maury". Identificatorul utilizator efectiv pastrat în u area este rezultatul celui mai recent apel sistem setuid sau a executiei unui program de tip setuid; el este singurul responsabil pentru determinarea dreptulurilor de acces la fisier. Identificatorul utilizator salvat în tabela de procese permite unui proces sa-si schimbe propriul identificator utilizator efectiv prin executia apelului sistem setuid, reapelând astfel identificatorul utilizator efectiv initial.
Programul login executat de utilizatori când acestia se logheaza în sistem este un program de tip setuid.) si ruleaza cu identificatorul utilizator efectiv al superutilizatorului. El cere utilizatorulului numele si parola si când este satisfacut apeleaza setuid pentru a-si seta identificatorii utilizator efectiv si real la valorile identificatorilor utilizatorului care încearca sa se logheze (gasite în câmpurile din fisierul "/etc/passwd"). Programul login, în final, executa shell-ul care ruleaza cu identificatorii utilizator efectiv si real setati anterior.
Comanda mkdir este de asemenea un program de tip setuid . Asa cum s-a aratat în paragraful 5.8, doar un proces cu identificatorul utilizator efectiv al superutilizatorului poate crea un director. Pentru a permite utilizatorilor obisnuiti sa creeze directoare, comanda mkdir este un program de tip setuid care poseda drepturile superutilizatorului. Când se executa comanda mkdir, procesul ruleaza cu drepturi de acces de superutilizator, creaza directorul si apoi schimba proprietarul si permisiunile de acces la director în acelea ale utilizatorului real.
Un proces poate mari sau micsora dimensiunea regiunii sale de date prin utilizarea apelului sistem brk. Sintaxa pentru apelul sistem este:
brk(endds);
unde endds devine valoarea celei mai mari adrese virtuale a regiunii de date a procesului (denumita valoare de întrerupere). Ca o alternativa, utilizatorul poate apela:
oldendds=sbrk(increment);
unde increment modifica valoarea curenta de întrerupere cu numarul de biti specificat si oldennds este valoarea de întrerupere înainte de apel. Sbrk este o subrutina din biblioteca C care apeleaza brk. Daca spatiul de date al procesului creste în urma apelului, noul spatiu de date alocat este virtual contiguu în vechiul spatiu de date. Nucleul verifica daca noua dimensiune a procesului este mai mica decât dimensiunea maxima permisa de sistem si daca noua regiune de date nu se suprapune peste spatiul de adrese virtual asignat anterior (Figura 8.26). Daca toate verificarile sunt executate cu succes, nucleul apeleaza growreg pentru a aloca memorie auxiliara (de exemplu, tabele de pagini) pentru regiunea de date si incrementeaza câmpul dimensiune proces. Pe un sistem cu swapping, el încearca de asemenea sa aloce memorie pentru noul spatiu si initializeaza continutul acesteia cu 0; daca nu exista spatiu de memorie, el evacueaza procesul pe disc pentru a obtine spatiul necesar (se va explica în detaliu în capitolul 11). Daca procesul apeleaza brk pentru a elibera spatiul alocat anterior, nucleul elibereaza memoria; daca procesul acceseaza adrese virtuale în spatiul de adrese al paginilor eliberate, se produce o întrerupere de memorie.
algoritmul brk
intrari: noua valoare de întrerupere
iesiri: vechea valoare de întrerupere
schimba dimensiunea regiunii (algoritmul growreg);
initializeaza la 0 adresele din noul spatiu de date;
deblocheaza regiunea de date a procesului;
}
Figura 8.26 Algoritmul pentru schimbarea dimensiunii unui proces
Figura 8.27 prezinta un program care utilizeaza algoritmul brk si datele de iesire rezultate în urma rularii pe un calculator AT&T 3B20. Dupa ce se aranjeaza interceptarea semnalului de violare a segmentarii prin apelul semnal signal, procesul apeleaza sbrk si tipareste valoarea sa initiala de întrerupere. Apoi el intra într-un ciclu, incrementând un pointer catre caractere si scriindu-si continutul pâna când se încearca scrierea la o adresa în afara regiunii de date, provocând semnalul de violare a segmentarii. Interceptând semnalul, functia catcher apeleaza sbrk pentru a aloca alti 256 de octeti în regiunea de date; procesul continua de unde a fost întrerupt în ciclu, scriind în noul spatiu de adrese alocat. Când se cicleaza din nou în afara regiunii de date, se repeta întreaga procedura. Un fenomen interesant apare la masinile a caror memorie este alocata prin pagini, asa cum este masina 3B20. O pagina este cea mai mica unitate de memorie care este protejata prin hardware si deci, prin hardware nu se poate detecta când un proces scrie la adrese care sunt dincolo de valoarea de întrerupere. Acest lucru este aratat în figura 8.27: primul apel sbrk returneaza valoarea 140924, ceea ce înseamna ca sunt 388 octeti lasati în pagina, care contine 2Ko pe o masina 3B20.
|
#include <signal.h> char *cp; int callno; main() catcher (signo) int signo; Date de iesire: valoarea initiala returnata de apelul brk 140924 s-a interceptat semnalul 11 primul la adresa 141312 s-a interceptat semnalul 11 al 2-lea la adresa 141312 s-a interceptat semnalul 11 al 3-lea la adresa 143360 (unele adrese sunt tiparite la al 10-lea apel) s-a interceptat semnalul 11 al 10-lea la adresa 143360 s-a interceptat semnalul 11 al 11-lea la adresa 145408 (unele adrese sunt tiparite la al 18-lea apel) s-a interceptat semnalul 11 al 18-lea la adresa 145408 s-a interceptat semnalul 11 al 19-lea la adresa 145408 |
Figura 8.27 Exemplu de utilizare a algoritmului brk
Procesul va fi întrerupt doar când se adreseaza pagina urmatoare, la adresa 141312.Functia catcher adauga 256 de octeti la valoarea de întrerupere, facând-o 141180, valoare înca mica pentru a fi adresa în pagina urmatoare. De aceea, procesul se întrerupe imediat, tiparind aceeasi adresa, 141312. Dupa urmatorul apel sbrk, nucleul aloca o noua pagina de memorie, asa ca nucleul poate accesa alti 2ko, la adresa 143360, chiar daca valoarea de întrerupere nu este asa mare. La urmatoarea întrerupere, procesul va apela sbrk de 8 ori (pâna când acesta poate continua). Astfel, un proces poate uneori sa se execute dincolo de adresa sa de întrerupere, cu toate ca acesta este un stil de programare necorespunzator.
Nucleul extinde automat dimensiunea stivei utilizator când aceasta este depasita, urmând un algoritm similar algoritmului brk. Initial un proces contine destul spatiu pentru stiva utilizator pentru a pastra parametrii apelului exec, dar poate aparea o depasire a acestui spatiu în timp ce se depun date în stiva de-a lungul executiei procesului. Când se depaseste stiva proprie, masina genereaza o întrerupere de memorie, deoarece procesul încearca sa acceseze o locatie în afara spatiului sau de adrese. Nucleul determina ca motivul pentru care a avul loc întreruperea de memorie a fost depasirea stivei prin compararea valorii indicatorului de stiva cu marimea regiunii de stiva. Nucleul aloca spatiu nou pentru regiunea de stiva asa cum aloca spatiu în algoritmul brk. Când revine din întrerupere procesul are spatiu de stiva necesar pentru a continua.
Acest capitol a acoperit suficiente notiuni pentru a explica cum lucreaza shell-ul. Figura 8.28 arata ciclul principal al shell-lui si demonstreaza executia asincrona, redirectarea iesirii si pipe-urile.
/* citeste linia de comanda pâna la aparitia caracterului "sfârsit de fisier" */
while (read(stdin, buffer, numchars))
if(/* cerere de redirectare catre o un fisier pipe */
/* a doua componenta a liniei de comanda */
close(stdin); dup(fildes[0]);
close(fildes[0]); close(fildes[1]);
/* intrarea standard este acum redirectata catre un pipe */ }
execv(command2, command2, 0); }
/* procesul parinte continua de aici...
asteapta terminarea procesului fiu daca este nevoie*/
if(amper==0) retid=wait(&status);
Figura 8.28 Ciclul principal al shell-lui
Shell-ul citeste o linie de la intrarea sa standard si o interpreteaza dupa un set fixat de reguli. Descriptorii fisierelor standard de intrate si de iesire pentru shell-ul de logare în sistem sunt de obicei ai terminalului pe care utilizatorul îi foloseste asa cum s-a aratat în capitolul 6. Daca shell-ul recunoaste sirul de intrare ca fiind o comanda interna (de exemplu, comenzile cd, for, while si altele), el executa comanda intern fara a mai crea procese; altfel, presupune ca aceasta este numele unui fisier executabil.
Cea mai simpla linie de comanda contine un nume de program si câtiva parametri cum ar fi:
who
grep -n include *.c
ls -1
Shell-ul executa un apel fork si creeaza un proces fiu care executa programul pe care utilizatorul l-a specificat în linia de comanda. Procesul parinte, shell-ul care este folosit de utilizator, asteapta pâna când procesul fiu termina comanda si apoi revine în ciclu pentru a citi comanda urmatoare.
Pentru a rula un proces asincron (în fundal), ca de exemplu
nroff -mm bigdocument &
shell-ul seteaza o variabila interna amper când analizeaza caracterul &. Daca gaseste variabila setata la sfârsitul ciclului, el executa apelul wait dar reia imediat ciclul si citeste urmatoarea linie de comanda.
Figura arata ca procesul fiu are acces la copia liniei de comanda dupa executarea apelului fork. Pentru a redirecta iesirea standard catre un fisier, ca în
nroff -mm bigdocument>output
procesul fiu creeaza fisierul de iesire specificat în linia de comanda; daca apelul creat nu se încheie cu succes (de exemplu, la crearea fisierului într-un director fara drept de acces ), procesul fiu ar trebui sa se termine imediat. Daca apelul creat se încheie cu succes, procesul fiu închide fisierul de iesire standard anterior si duplica descriptorul de fisier al noului fisier de iesire. Descriptorul fisierului de iesire standard refera acum fisierul de iesire redirectat. Procesul fiu închide descriptorul de fisier obtinut prin apelul creat pentru a conserva descriptorii de fisier pentru programul executat. Shell-ul redirecteaza fisierele standard de intrare si eroare într-un mod similar.
Figura 8.29 Relatiile între procese pentru linia de comanda ls -l|wc
Figura 8.29 arata cum trateaza shell-ul o linie de comanda ls-l|wc cu un singur pipe.
Dupa ce procesul parinte apeleaza fork si creeaza un proces fiu, fiul creeaza un pipe. Procesul fiu executa la rândul sau un apel fork; el si fiul sau trateaza fiecare câte o componenta a liniei de comanda. Procesul fiu ( " nepotul " ) creat prin al doilea apel fork executa prima componenta a comenzii (ls): el scrie în pipe, asa ca închide descriptorul fisierului sau standard de iesire, duplica descriptorul de scriere în pipe si închide descriptorul initial de scriere în pipe pentru ca acesta nu mai este necesar. Procesul parinte (wc) al ultimului proces fiu (ls) este fiul procesului shell (vezi Figura 8.29). Acest proces (wc) închide propriul fisier standard de intrare si duplica descriptorul de citire din pipe facându-l sa devina propriul descriptor de fisier standard de intrare. Apoi închide descriptorul initial de citire din pipe pentru ca nu mai are nevoie de el si executa a doua componenta a comenzii din linia de comanda. Cele doua procese care executa linia de comanda, se executa asincron, si iesirea unui proces devine intrare pentru celalalt proces. Procesul shell între timp asteapta pentru ca procesul sau fiu (wc) sa se termine, apoi procedeaza în mod uzual: întreaga linie de comanda este executata complet atunci când procesul care executa comanda wc se termina. Shell-ul reintra în ciclu si citeste urmatoarea comanda.
Pentru a initializa un sistem dintr-o stare inactiva, un administrator trece printr-o secventa "bootstrap": administratorul încarca sistemul. Procedura de încarcare a sistemului variaza în functie de tipul masinii, dar scopul este comun : de a face o copie a sistemului de operare în memorie si de a începe executia acestuia. De obicei încarcarea sistemului se face în mai multe etape. Administratorul poate seta anumite comutatoare pe consola calculatorului pentru a specifica adresa unui program special de încarcare a sistemului codificat hardware, sau poate sa apese un singur buton care indica masinii sa încarce programul preîncarcator din microcodul sau. Acest program poate sa contina doar câteva instructiuni care coordoneaza masina sa execute alt program. Pe sistemele UNIX, procedurile de încarcare a sistemului citesc eventual blocul de boot (blocul 0) al discului si îl încarca în memorie. Programul continut în blocul de boot încarca nucleul din sistemul de fisiere (din fisierul "/unix" de exemplu, sau alt nume specificat de administrator). Dupa ce nucleul este încarcat în memorie, programul încarcator transfera controlul la adresa de start a nucleului, si acesta îsi începe executia (algoritmul start, Figura 8.30).
|
algoritmul start /* procedura de start a sistemului */ intrari: niciuna iesiri: niciuna /* procesul 0 continua aici */ apel fork pentru crearea proceselor nucleu; /* Procesul 0 invoca încarcatorul pentru gestionarea alocarii spatiului de adrese pentru procese în memoria principala si pe dispozitivul swap (disc). Acesta este un ciclu infinit; procesul 0 este în mod obisnuit în asteptare în ciclu, daca nu are ceva de facut */ executa codul algoritmului încarcator; } |
Figura 8.30 Algoritmul pentru încarcarea sistemului
Nucleul îsi initializeaza structurile sale interne de date. De exemplu, construieste listele înlantuite de buffere si inoduri libere, construieste cozile hash de buffere si inoduri, initializeaza structurile de regiuni, intrarile în tabela de pagini si asa mai departe. Dupa terminarea fazei de initializare, nucleul monteaza sistemul de fisiere radacina ("/") si pregateste mediul pentru procesul 0, creeaza u area, initializeaza slotul 0 în tabela de procese si creeaza radacina directorului curent al procesului 0, printre altele.
Când mediul procesului 0 este setat, sistemul apeleaza fork direct din nucleu pentru ca el se executa în modul nucleu. Noul proces, procesul 1, se executa în modul nucleu, îsi creeaza contextul de nivel de utilizator prin alocarea unei regiuni de date si atasarea ei la propriul spatiu de adrese. El mareste regiunea la dimensiunea potrivita si copiaza codul din spatiul de adrese al nucleului în noua regiune: acest cod formeaza acum contextul de nivel de utilizator al procesului 1. Procesul 1 seteaza apoi contextul registru utilizator salvat, revine din modul nucleu în modul utilizator si executa codul pe care tocmai l-a copiat din nucleu. Procesul 1 este un proces de nivel utilizator care este în opozitie cu procesul 0, care este un proces de nivel nucleu si care se executa în modul nucleu. Codul pentru procesul 1, copiat din nucleu, consta din apelul functiei sistem exec pentru executia programului "/etc/init". Procesul 1 apeleaza exec si executa programul în mod normal. Procesul 1 este numit init, pentru ca el este raspunzator de initializarea proceselor noi.
De ce copiaza nucleul codul apelului sistem exec în spatiul de adrese utilizator al procesului 1? El ar putea sa invoce versiunea interna a apelului exec direct din nucleu, dar acest lucru ar fi mai complicat decât implementarea tocmai descrisa.
Pentru a urma procedura descrisa mai înainte, apelul exec ar trebui sa analizeze numele fisierului în spatiul nucleu, nu doar în spatiul utilizator, ca în implementarea curenta. Aceasta generalizare, necesara doar pentru procesul init, ar complica codul apelului exec si ar micsora performantele sistemului
Procesul init (Figura 8.31) este un proces dispecer, care creeaza procesele ce permit utilizatorului sa se logheze în sistem, printre altele. Procesul init citeste fisierul "/etc/inittab" pentru a avea informatii referitoare la procesele care trebuiesc create. Fisierul "/etc/inittab" contine linii care au un câmp "id", un identificator de stare ( utilizator unic, multiutilizator, etc), un câmp "actiune" si un câmp specificatie de program (vezi Figura 8.32).
Procesul init citeste fisierul si, daca starea în care a fost apelat se potriveste cu identificatorul de stare a liniei, creeaza un proces care executa specificatia de program data. De exemplu, când se apeleaza procesul init pentru starea de multiutilizator (starea 2), el creeaza de obicei procese getty pentru a supraveghea liniile terminale configurate într-un sistem.
algoritmul init /* procesul de init, procesul 1 al sistemului */
intrari: niciuna
iesiri: niciuna
/* procesul init nu asteapta */
/*reia ciclul while */
}
while((id=wait((init *)0))!=-1)
}
Figura 8.31 Algoritm init
|
Format: identificator, stare, actiune, specificatie de program Câmpuri separate de coloane Comentarii la sfârsit de linie precedate de '#' co::respawn:/etc/getty console # consola atasata masinii 46:2:respawn:/etc/getty -t 60 tty46 4800H # comentariu |
Figura 8.32 Exemplu de fisier inittab
Când un utilizator se logheaza cu succes în sistem, getty trece prin procedura login si executa procesul shell descris în capitolul 6. Între timp, procesul init executa apelul sistem wait, controlând terminarea propriilor procese fiu si terminarea proceselor fiu ramase "orfane" prin terminarea proceselor lor parinte.
Procesele în sistemul UNIX pot fi procese utilizator, procese "demon", sau procese nucleu. Cele mai multe procese pe sistemele obisnuite sunt procese utilizator asociate utilizatorilor unui terminal. Procesele demon nu sunt asociate cu nici un utilizator, dar executa functii ale sistemului, cum ar fi administrarea si controlul retelelor, executia activitatilor dependente de timp, activitati de tiparire, etc. Procesul init poate crea procese demon care exista pe toata durata de viata a sistemului sau, ocazional, le pot crea utilizatorii. Ele se aseamana cu procesele utilizator prin aceea ca ruleaza în modul utilizator si fac apeluri sistem pentru a accesa serviciile sistemului.
Procesele nucleu se executa doar în modul nucleu. Procesul 0 lanseaza procesele nucleu, cum ar fi procesul vhand (care presupune existenta unui sistem bazat pe paginare la cerere) si apoi devine proces încarcator. Procesele nucleu sunt similare cu procesele demon prin aceea ca ele furnizeaza servicii sistem, dar au un control mai mare asupra prioritatilor lor de executie deoarece codul lor face parte din nucleu. Ele pot accesa algoritmii nucleului si structurile de date ale acestuia direct, fara a utiliza apelurile sistem, astfel ele sunt extrem de puternice. Totusi, ele nu sunt asa flexibile ca procesele demon, pentru ca nucleul trebuie recompilat pentru a le schimba.
|
