Simulare de sisteme
Specificarea problemelor.
O problema se poate specifica la nivelul interfetei dintre algoritmul ce o rezolva si mediul extern.
O specificare de problema P este o multime de evenimente de intrare in(P), o multime de evenimente de iesire out(P) (cele doua multimi constituind interfata lui P) si o multime seq(P) de secvente admisibile de evenimente de intrare si evenimente de iesire (care precizeaza interleavingurile permise dintre intrari si iesiri).
Fiecare eveniment de intrare sau de iesire are un nume si poate avea asociate date ca parametri.
Exemplu. Problema excluderii mutuale pentru n procesoare:
evenimente de intrare: Ti, Ei, 0 i n-1, unde
Ti indica faptul ca utilizatorul i doreste sa încerce sa intre în sectiunea critica.
Ei indica faptul ca utilizatorul i doreste sa iasa din sectiunea critica.
evenimentele de iesire: Ci, Ri 0 i n-1, unde
Ci indica faptul ca utilizatorul i poate acum sa intre în sectiunea critica.
Ri indica faptul ca utilizatorul i poate acum sa intre în sectiunea remainder.
o secventa a a acestor evenimente este admisibila daca pentru "i:
a|i cicleaza (Ti,Ci,Ei,Ri)
ori de câte ori Ci apare în a, atunci "j eveniment asociat lui j ce apare în a înaintea lui Ci nu este lj.
(Conditia 1 arata ca utilizatorul si algoritmul interactionaza propriu; ea impune utilizatorului un mod corect de comportare. Conditia 2 afirma ca nu doi utilizatori simultan în sectiunea critica).
În problemele de simulare vom fi interesati în implementarea unor anumite tipuri de sisteme de comunicatie între procesoare pe baza unor primitive.
Aceste sisteme de comunicatie vor fi descrise cu ajutorul unei specificatii de problema.
Exemple
1. Transmiterea asincrona de measej point-to-point
interfata:
sendi (M): eveniment de intrare asociat procesorului pi care trimite o multime M (eventual vida) de mesaje. Fiecare mesaj include o indicatie a trimitatorului si a destinatarului; exista cel mult un mesaj pentru fiecare destinatar si perechea transmitator-destinatar trebuie sa fie compatibila cu topologia sistemului.
recvi(M): eveniment de iesire asociat procesorului pi în care o multime M de mesaje este primita. Fiecare mesaj trebuie sa-l aiba pe pi ca destinatar.
multimea secventelor admisibile.
Fie a o secventa de evenimente de intrare si iesire.
Notam cu R multimea tuturor mesajelor ce apar în toate evenimentele recvi(M) din a si cu S multimea tuturor mesajelor ce apar în toate evenimentele sendi(M) din a. Exista o functie K:R S care asociaza fiecarui mesaj din R un mesaj cu 16116m128q acelasi continut din S a.î.:
Integrity: K este bine definita. Orice mesaj primit a fost în prealabil trimis. Nu este permisa coruptia mesajelor.
No duplicates: K este injectiva. Nici un mesaj nu este primit mai mult de o data.
Liveness: K este surjectiva. Orice mesaj trimis va fi primit.
Observatie. Aceste proprietati vor fi modificatecând se vor considera si defectiunile în sistem.
Broadcast asincron
interfata (la un sistem cu broadcast asincron de baza).
bc-sendi(m): eveniment de intrare în care procesorul pi, trimite un mesaj m tuturor procesoarelor.
bc-recvi(m,j): eveniment de iesire în care procesorul pi primeste mesajul m, în prealabil difuzat de pj.
multimea secventelor admisibile. Fie a o secventa de evenimente de intrare si de iesire.
Exista K o aplicatie care asociaza fiecarui bc-recvi(m,j) din a un evniment precedent bc-sendj(m) a.î.
Integrity: K este bine definita (orice mesaj primit a fost în prealabil trimis).
No duplicates: Pentru ficare procesor pi i n-1, restrictia lui K la evenimentele bc-recvi este injectiva (nici un mesaj nu este primit mai mult de o data de un procesor).
Liveness: Pentru ficare procesor pi i n-1, restrictia lui K la evenimentele bc-recvi este surjectiva (orice mesaj trimis este primit de fiecare procesor).
Observatie: Din nou s-a presupus ca nu exista defectiuni.
Procese
Pe fiecare procesor se vor executa bucati de cod care implementeaza sistemul de comunicatie dorit. Deci nu va mai fi corect sa identificam "algoritmul" cu procesorul, pentru ca avem procese multiple ce se executa pe acelasi procesor. Vom folosi notiunea de nod iar sistemul de comunicatie va fi reprezentat ca o cutie neagra în care este implementata o "stiva de protocoale".
Un sistem este o colec
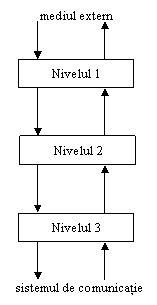
tie de noduri p0,...,pn-1, un sistem de
comunicatie C si un mediu
extern E.
C si E nu sunt explicit modelate ca procese. Ele vor fi date ca specificatii de probleme, care impun conditii asupra comportarii lor.
În fiecare nod exista o stiva de nivele cu acelasi numar de nivele. Fiecare nivel interior comunica cu cele doua nivele adiacente. Nivelul de jos comunica cu sistemul de comunicatie si nivelul de sus cu mediul extern.
Fiecare proces este modelat ca un automat cu o multime (posibil infinita) de stari si o multime de stari initiale. Tranzitiile dintre stari sunt declansate de aparitia evenimentelor procesului. Un proces are patru tipuri de evenimente:
intrari din nivelul de deasupra (sau nivelul exterior daca este nivelul de sus).
iesiri catre nivelul de deasupra.
intrari din nivelul de dedesubt (sau sistemul de comunicatii daca este nivelul de jos) .
iesiri catre nivelul de dedesubt.
Evenimentele de tipul 1 si 2: interfata - top a procesului
Evenimentele de tipul 3 si 4: interfata - bottom a procesului.
Un eveniment este activat într-o stare a procesului daca exista o tranzitie din acea stare, etichetata cu acel eveniment.
Un eveniment de intrare poate fi activat în orice stare a procesului.
Evenimentele de iesire sunt activate de functia de tranzitie a procesului.
Intrarile din mediul extern si din sistemul de comunicatii sunt intrarile nodului.
Procesele de pe un singur nod interactioneaza a.î. numai un numar finit de evenimente (diferit de intrarile nodului) sunt activate de o intrare în nod.
O configuratie a sistemului specifica o stare pentru orice proces de pe orice nod (configuratia nu include starea sistemului de comunicatie). O configuratie initiala contine numai stari initiale ale proceselor.
O executie a sistemului este un sir C0, F , C1, F ,C2,.... alternativ de configuratii si evenimente, începând cu o configuratie si, daca este finit, sfârsind cu o configuratie a.î.:
Configuratia C0 este o configuratie initiala.
"i 1 evenimentul Fi este activat în configuratia Ci-1 si configuratia Ci este rezultatul lui Fi actionând pe Ci-1. (Orice componenta de stare este aceeasi în Ci ca si în Ci-1 cu exceptia (cel mult doua) proceselor pantru care Fi este eveniment). Starile acestor procese se schimba conform functiei de tranzitie a acestor procese.
"i 1, daca Fi nu este o intrare pentru un nod, atunci i > 1 si este un eveniment pe acelasi nod ca si Fi-1. (Primul eveniment trebuie sa fie o intrare pe un nod).
"i 1 daca Fi estte intrare pe un nod atunci în Ci-1 nu a fost avtivat nici un alt eveniment (diferit de un eveniment de intrare în nod).
Observatie: Din 3. si 4. rezulta ca un nod este declansat de o intrare în nod (din exterior sau din sistemul de comunicatie) si aceasta declansare cauzeaza un lant de evenimente pe acest nod care apare atomic pâna ce alet evenimente nu mai sunt declansate.
Planificarea unei executii este sirul evenimentelor din executie.
Daca a este o executie atunci top(a) (respectivc bot(a)) este restrictia planificarii lui a la evenimentele din inerfata top (respectiv bottom) a nivelului top (respectiv bottom).
O executie este fair daca orice eveniment (diferit de o intrare într-un nod) care este activat va apare (odata si odata; executia nu se opreste prematur, când mai exista pasi de urmat).
O executie a are calitatea de a fi user-compliant pentru o specificatie de problema P, daca mediul extern satisface restrictiile de intrare ale lui P: pentru orice prefix a F a lui a unde F este o intrare din mediul extern, daca a' este prefix al unui element din seq(P), atunci asa este si a F
O executie este corecta pentru sistemul de comunicatie C daca bot(a este un element al lui seq(C). (Sistemul de comunicatie este corect, în conformitate cu specificatiile de problema a lui C).
O executie este (P,C) - admisibila daca estge fair, user - compliant pentru specificatia de problema P si corecta pentru sistemul de comunicatii C.
Atunci când P si C sunt clare din context executia se va numi admisibila.
Sistemul de comunicatii C, simuleaza (global) sistemul de comunicatii C2 daca exista o colectie de procese unul pentru fiecare nod numit Sim (procesul de simulare) care satisface:
Interfata top a lui Sim este interfata lui C2.
Interfata bottom alui Sim este interfata lui C1.
Pentru orice executie (C2, C1) - admisibila a lui Sim exista un sir s în seq(C2) a.î. s=top(a
(Executia simularii în topul sistemului de comunicatie C1 produce aceleasi aparitii în mediul extern pe care le face sistemul de comunicatii C2).
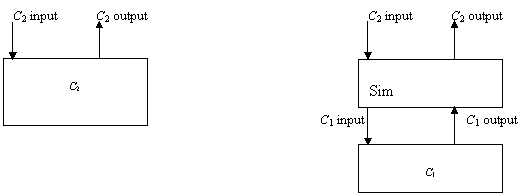
O definitie mai slaba a simularii, este simularea locala.
O executie a este local user - compliant pentru o specificatie de problema P, daca " a F un prefix al lui a, unde F este o intrare din mediul extern, daca s seq(P) a.î. a'|i este prefix al lui s'|i pentru "i , atunci s seq(P) a.î. a F|i este un prefix al lui s'|i pentru "i (mediul extern satisface restrictiile de intrare ale lui P pentru fiecare nod, dar nu neaparat global).
O executie este (P,C) - local admisibila daca este fair, local user - compliant si corecta pentru sistemul de comunicatii C.
Definitia simularii locale este aceeasi cu a simularii globale cu exceptia conditiei 3 care devine acum:
Pentru orice executie (C2, C1) - local admisibila a a lui Sim s seq(C2) a.î. s|i=top(a)|i "i 0 i n-1.
Vom descrie un algoritm asincron de tip MP ca o lista de evenimente de intrare si iesire.
Fiecare eveniment va avea un nume si se vor descrie schimbarile locale care vor fi cauzate de aparitia acestui eveniment, într-un pseudocod secventia uzual.
Pe lânga schimbarile locale de stare, aparitia unui eveniment poate cauza si activarea unor evenimante de iesire. Acestea vor fi indicate astfel: "enable input X". Daca rezultatul unui eveniment de iesire este dezactivarea lui (nu se fac alte schimbari locale) nu va fi trecut în lista de evenimente.
Pentru a specifica calitatea unui serviciu de broadcast (proprietati ce vor fi descrise mai jos) interfata descrisa mai anterior pentru un serviciu broadcast de baza se modifica astfel:
bc-sendi(m,qos): eveniment de intrare asociat procesorului pi, care trimite un mesaj m tuturor procesoarelor; qos este un parametru ce descrie calitatea serviciului cerut.
bc-recvi(m,j,qos): eveniment de iesire în care procesorul pi primeste mesajul m în prealabil difuzat de pj; qos este ca mai sus.
Observatie: Atunci când ne referim la un serviciu broadcast de baza vom considera qos=basic. Un mesaj difuzat este primit si de transmitator.
Operatiile bc - send si bc - recv nu sunt blocante: nu se asteapta ca un mesaj sa fie primit de toate procesoarele iar operatia bc - recv actioneaza în modul de lucru bazat pe întreruperi.
Se pot discuta doua categorii de calitati prin adaugarea de noi proprietati pentru secventele admisibile (pe lânga cele ale situatiei qos=basic: integrity, no duplicates, liveness).
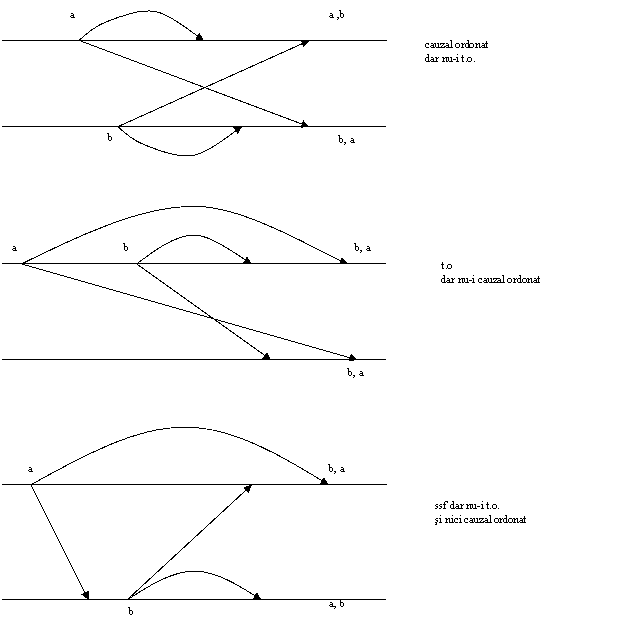
Ordonare
Un sistem de broadcast single-source FIFO (qos=ssf) satisface proprietatile lui basic si
Un sistem de broadcast total ordonat (qos=to) satisface proprietatile lui basic si
Totally Ordered " m1, m2 si " pi, pj daca m1 este primit în pi înaintea lui m2 , atunci m2 nu este primit în pj înaintea lui m1.
În cele doua conditii, primit este un bc - recv cu qos pe una din cele doua valori iar trimis este un bc - send cu qos corespunzator.
Pentru a defini al treilea model de broadcast cu ordonare este necesar sa extindem relatia de aparitie a unui eveniment înaintea altuia, la mesaje.
Se presupune ca toate comunicarile de la un nivel superior al aplicatiei se executa numai cu bc - send si bc - recv (nu exista mesaje "behind of the scenes").
Definitie: Data o secventa de evenimente bc - send si bc - recv spunem ca mesajul m1 se întâmpla înaintea mesajului m2 daca
evenimentul bc - recv pentru m1 se întâmpla înaintea evenimentului bc - send pentru m2 sau
m1 si m2 sunt trimise de acelasi procesor si m1 este trimis înaintea lui m2.
Un sistem de broadcast ordonat cauzal, qos=co, satisface proprietatile lui basic si
Causally Ordered " m1, m2 si " pi daca m1 se întâmpla înaintea lui m2 atunci m2 nu-i primit de pi înaintea lui m1.
Exemple
Siguranta în functionare (Reliability)
Un sistem de broadcast este reliable (în prezenta a f defecte) daca pentru orice secventa a de bc - send si bc - recv sunt satisfacute conditiile: Integrity, No duplicates iar Liveness se modifica astfel:
Nonfaulty Liveness: Daca se considera restrictia lui K la evenimentele asociate procesoarelor nedefecte atunci K este surjectiva (toate mesajele difuzate de un procesor nedefect sunt primite odata si odata de procesoarele nedefecte).
Faulty Liveness: Daca un procesor nedefect are un eveniment bc - recv caruia K îi asociaza un eveniment bc - send al unui procesor defect, atunci orice procesor nedefect are un eveniment bc - recv caruia K îi asociaza acelasi eveniment bc - send (orice mesaj trimis de un procesor defect este sau primit de toate procesoarele nedefecte sau de niciunul).
Observatie: Conditiile nu depind de tipul de defectiune a procesoarelor; vom considera totusi numai defectiuni de tip crash.
Anumite combinatii de proprietatilor ale serviciilor de tip broadcast au nume specifice date de importanta lor practica:
broadcast atomic = broadcast reliable cu t.o.
broadcast FIFO atomic = broadcast atomic cu ssf.
broadcast cauzal atomic = broadcast atomic cu c.o.
(ultimele doua sunt echivalente).
Implementarea serviciilor de broadcast
1. Basic
Se implementeaza simplu în topul unui sistem point-to-point MP fara defectiuni.
Când apare un bc - send pentru un mesaj m la un procesor pi, pi foloseste sistemul point-to-point MP pentru a trimite o copie a lui m la toate procesoarele.
Când un procesor primeste mesajul de la pi pe sistemul point-to-point, executa evenimentul bc - recv pentru m si i.
2. ssf
Se implementeaza în topul unui sistem basic. Fiecare procesor asigneaza un numar de ordine pentru fiecare mesaj pe care îl difuzeaza; acesta este incrementat cu 1 ori de câte ori un nou mesaj este difuzat. Primitorul unui mesaj de la pi cu numar de secventa T asteapta pâna se executa bc - recvi cu qos=ssf a tuturor mesajelor de la pi cu numarul de ordine mai mic decât T.
3. t.o.
Un algoritm nesimetric
Se bazeaza din nou pe un sistem de broadcast basic. Pentru a difuza un mesaj m, procesorul pi îl trimite utilizând basic unui procesor central pc care asigneaza un numar de ordine si îl difuzeaza folosind basic.
Procesoarele executa receive pentru sitemul cu t.o. în ordinea specificata de numarul de ordine al mesajelor, asteptând daca este necesar pâna primesc toate mesajele cu numar de ordine mai mic.
Clar, ordinea în care se executa receive pentru sistemul cu t.o. este aceeasi la toate procesoarele si anume cea în care au fost trimise de procesorul central.
Rolul procesorului central poate fi preluat si de alte procesoare cu ajutorul unui token de identificare care sa circule printre procesoare.
Un algoritm nesimetric
Ideea este de a asigna timestamp-uri mesajelor.
Algoritmul se bazeaza pe un sistem de broadcast cu calitati ssf.
Agoritm de broadcast t.o. (codul pentru pi, 0 i n-1)
Initial ts[j]=0, 0 j n-1 si pending este vida.
atunci când apare bc - sendi(m,to):
ts[i]:=ts[i] +1
adauga<m,ts[i],i> la pending
enable bc - sendi(<m,ts[i]>,ssf)
atunci când apare bc - recvi(<m,T>,j,ssf) ji :
// ignora mesajele catre el însusi
ts[j]:=T
adauga<m,T,j> la pending
if T>ts[i] then
ts[i]:=T
enable bc - sendi(<ts-up,T>,ssf)
//difuzeaza un mesaj de actualizare a timestamp-ului
atunci când bc - recvi(<ts-up,T>,j,ssf) ji:
ts[j]:=T
enable bc - recvi(m,j,to) atunci când
<m,T,j> este intrarea în pending cu cel mai mic (T,j) si
T ts[k] "k
result: remove<m,T,j> din pending
Explicatii
Fiecare procesor mentine un contor crescator: timestamp-ul sau, folosit pentru a stampila mesajele pe care vrea sa le difuzeze. În plus, fiecare procesor are un vector în care estimeaza timestamp-urile celorlalte procesoare. Intrarea j din acest vector semnifica faptul ca pi nu va primi (înca o data) un mesaj de la pj cu un timestamp mai mic sau egal cu acea valoare.
Aceste componente ale vectorului sunt actualizate cu ajutorul timestampe-urilor asociate mesajelor sau folosind un mesaj special de actualizare trimis de pj.
Timestamp-ul propriu al fiecarui procesor va fi mai mare sau egal cu estimarea sa a timestamp-urilor celorlalte procesoare. Atunci când procesorul trbuie sa-si mareasca timestamp-ul pentru a asigura conditia precedenta va trimite un mesaj de actualizare a timestamp-urilor tuturor celorlalte procesoare.
Fiecare procesor mentine o multime de mesaje ce asteapta sa fie primite (pentru sistemul cu t.o.). Un mesaj cu timestamp-ul T este primit t.o., atunci când orice intrare în vector este mai mare sau egala decât T. Fie a o executie fair a algoritmului care este corecta pentru sistemul de comunicatii ssf.
Lema 1: Pentru "procesor pi si "bc - sendi(m,to) din a, pi asigneaza lui m un timestamp unic si aceste timestamp-uri sunt asignate în ordine crescatoare în raport cu aparitiile lor în a
Lema 2: Timestamp-urile asignate mesajelor din a, împreuna cu id-urile procesoarelor formeaza o ordine totala (aceasta ordine este numita ordinea timestamp).
Teorema: Algoritmul precedent este algoritm de broadcast t.o.
Demonstratie
Trebuie demonstrat ca au loc conditiile:
Integrity, No Duplicates, Liveness si Total Ordering.
Primele doua sunt satisfacute deoarece sistemul ssf pe care se bazeaza algoritmul le satisface.
Liveness: Presupunem ca exista un procesor pi care are o intrare în pending care astepta la nesfârsit. Fie <m,T,j> intrarea blocata în pending cu cel mai mic (T,j).
Întrucât procesoarele asigneaza timestamp-urile în ordine crescatoare odata si odata <m,T,j> va fi cea mai mica intrare în multimea pending a lui pi. Pentru a fi blocata trbuie sa existe k a.î. T>ts[k] în pi la nesfârsit. Deci la un moment dat pi nu mai creste ts[k]. Fie T' cea mai mare valoare pe care pi o da lui ts[k]. Clar, k i. Deci de la un loc încolo pi nu mai primeste mesaje de la pk (în sistemul ssf). Deci pk nu va mai trimite mesaje cu timestamp-ul mai mare decât T'. Dar aceasta înseamna ca pk nu va primi mesajul <m,T,j> de la pj contrazicând corectitudinea sistemului ssf.
Total Ordering: Presupunem ca pi executa bc - recvi(m1,j1,to) si apoi
bc - recvi(m2,j2,to). Trebuie sa aratam ca (T1,j1)< (T2,j2) unde Ti este timestamp-ul lui mi, (i=1,2).
Cazul I: <m2,T2,j2> este în pendingi atunci când bc - recv i(m1,j1,to) apare. Atunci, clar, (T1,j1)< (T2,j2) întrucât, altfel, m2 ar fi fost acceptat înaintea lui m1.
Cazul II: <m2,T2,j2> nu este în pendingi atunci când bc - recv i(m1,j1,to) apare.
Avem T1 tsi[j2].
Deci pi a primit un mesaj m de la ![]() (pe sistemul ssf) înaintea acestui moment cu timestamp-ul T T1. Din proprietatea ssf,
(pe sistemul ssf) înaintea acestui moment cu timestamp-ul T T1. Din proprietatea ssf, ![]() trimite m2 dupa ce el trimite m si deci
timestamp-ul T2 al lui m2 este mai mare decât T. Deci T2 > T1.
trimite m2 dupa ce el trimite m si deci
timestamp-ul T2 al lui m2 este mai mare decât T. Deci T2 > T1.
Cauzalitate
Sa observam ca timestamp-ul asignat unui mesaj m difuzat de pi este strict mai mare decât timestamp-ul oricarui mesaj primit de pi dupa primirea mesajului m. Deci:
Teorema: Algoritmul precedent este un algoritm de broadcast c.o.
Observatie: Cauzalitatea se poate obtine si fara t.o., pornind de la un sistem de broadcast basic si folosind timestamp-urile vectoriale. O ratiune pentru aceasta, este aceea ca se poate obtine calitatea c.o. chiar în prezenta defectiunilor în timp ce t.o. nu poate fi asigurata în prezenta defectiunilor.
Reliabilitate
Vom implementa un serviciu de broasdcast reliabil în topul unui sistem cu MP point-to-point în prezenta a f caderi. Interfata sistemului MP point-to-point este fomata din evenimente de intrare sendi(M), recvj(M) unde M este o multime de mesaje, ficare mesaj incluzând o indicatie a trimitatorului si a primitorului. Secventele admisibile se definesc având urmatoarea proprietate (procesoarele sunt partitionate în defecte si nedefecte primele fiind în numar de cel mult f).
Integrity: Orice mesaj primit de un procesor pi i-a fost în prealabil trimis de
un procesor.
No duplicates: Nici un mesaj trimis nu este primit mai mult de o singura
data.
Nonfaulty Liveness Orice mesaj trimis de un procesor nedefect la un
procesor nedefect va fi odata si odata primit.
Algoritmul de broadcast reliabil (codul pentru pi, 0 i n-1)
la aparitia lui bc - sendi(m,reliable):
enable bc - sendi(<m,i>,basic)
la aparitia lui bc - recvi(<m,k>,j,basic):
if m nu a fost deja primit then
enable bc - sendi(<m,k>,basic)
enable bc - recvi(m,k,basic)
Teorema: Algoritmul precedent este un algoritm de broadcast reliabil.
Observatii
Calitatea de ssf se obtine exact ca în cazul lipsei caderilor.
Broadcast-ul t.o. reliabil nu se poate obtine atunci când sistemul pe care se bazeaza este asincron (altfel s-ar putea rezolva problema consensului în sisteme asincrone)
Broadcast-ul c.o. se obtine utilizând algoritmul dat pe un sistem de broadcast reliabil.
Toate problemele de implementare precedente pot fi extinse pentru a considera asa numitul multicast în care un mesaj trebuie trimis la un grup de procesoare si nu la toate. Implementarile sunt simple atunci când grupurile sunt statice. Atunci când grupurile se pot modifica, în fiecare executie apar probleme la întretinerea dinamica a lor.
Memorie Partajata Distribuita
Memoria Partajata Distribuita (Distributed Shared Memory), DSM, este o simulare a unui sistem de comunicatie bazat pe memorie partajata cu ajutorul unui sistem de tip transmitere mesaje (MP).
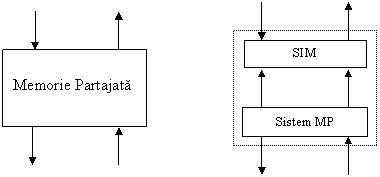
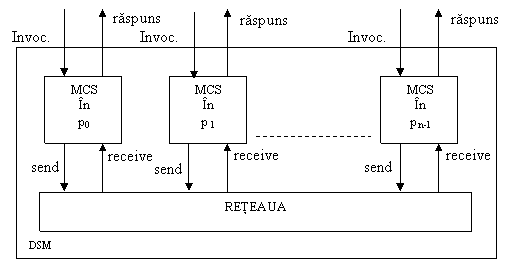
Programul
de simulare va fi numit MCS (memory consistency system) care este alcatuit
din procese locale în fiecare procesor pi. Schematic:
Pentru simplitate, vom considera ca obiectele din memoria partajata sunt registri read/write.De asemenea, nu vom considera defectiuni ale procesoarelor.
Fiecare obiect partajat are o specificare secventiala care indica comportarea dorita a obiectului în absenta concurentei.
O specificare secventiala consta dintr-o multime de operatii si o multime de secvente de operatii (multimea secventelor legale de operatii).
Exemplu: Un obiect read/write X suporta operatiile read si write.
Invocarea unui read este readi (X) si raspunsul returni (X, v), unde i indica nodul si v valoarea returnata.
Invocarea unui write este writei (X, v) si raspunsul acki (X)
O secventa de operatii este legata daca fiecare read returneaza valoarea celui mai recent write precedent (valoarea initiala daca aceasta nu exista).
Sistem de comunicatie Linearizable Shared Memory ( LSM)
Intrari: invocari ale obiectelor partajate.
Secventele admisibile: O secventa s de intrari si iesiri este admisibila daca satisface:
Correct interaction "i s I este un sir alternat de invocari si raspunsuri
pereche, începând cu o invocare (fiecare procesor trebuie sa
astepte un raspuns de la un obiect înainte de a invoca un alt
obiect; este interzis accesul tip pipeline)
Liveness " invocare are un raspuns pereche.
Linerizability: Exista o permutare a tuturor operatiilor din s a.î.
pentru orice obiect O, p O este legala (adica apartine specificarii secventiale a lui O)
daca raspunsul la operatia o1, apare în s înainte de invocarea operatiei o2, atunci o1 apare înaintea lui o2 în p
(Este posibila o reordonare a operatiilor din secventa a a.î. sa respecte
semantica obiectelor -exprimata de specificarile secventiale- si
ordonarea dupa timpul real de aparitie a evenimentelor, în toate nodurile.)
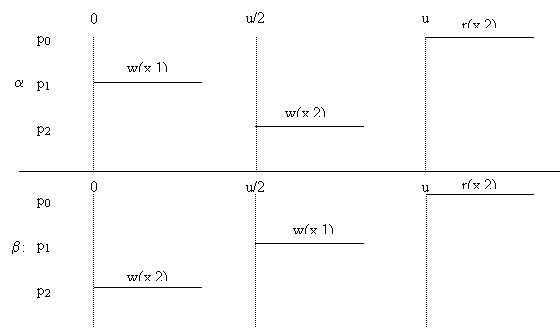
Exemplu: Fie x si y registri, initializati cu 0.
Atunci s = write0(x, 1) write1(y, 1) ack0(x) ack1(y) read0(y) read1(x) return0(y,1) return1(x, 1) este liniarizabila întrucât p = w0w1r1r0 este o permutare care satisface conditiile din definitie.
Însa, s = write0(x, 1) write1(y, 1) ack0(x) ack1(y) read0(y) read1(x) return0(y,0) return1 (x, 1) nu-i liniarizabila.
Pentru a respecta semantica lui y, r0 trebuie sa preceada w1. Dar aceasta nu respecta ordonarea dupa timpul real pentru ca w1 precede r0 în s
Aceleasi intrari si iesiri iar secventele admisibile s satisfac Correct interaction, Liveness si
Sequentially consistent: Exista o permutare p a operatiilor din s a.î.
pentru orice obiect O, p|O este legala.
daca raspunsul pentru operatia o1 în nodul pi (oarecare) apare în s înaintea invocarii operatiei o2 în nodul pi, atunci o1 apare înaintea lui o2 în p
Observatii
Se cere deci ca sa se pastreze ordinea operatiilor din acelasi nod care nu se suprapun si nu pentru toate operatiile.
În exemplul precedent s este secventa consistenta, permutarea dorita este w0r0w1r1. Deci conditia de liniarizare este mai tare decât conditia de consistenta secventiala. Exista secvente care nu sunt secvential consistente:
s = write0(x, 1) write1(y, 1) ack0(x) ack1(y) read0(y) read1(x) return0(y,0) return1(x,0).
Pentru a respecta semantica lui x si y trebuie ca r0 sa preceada w1 si r1 sa preceada w0. Pentru a respecta ordinea evenimentelor din p1 trebuie ca w1 sa preceada r1. Din tranzitivitate rezulta ca r0 precede w0 care încalca ordinea evenimentelor în p0.
Vom presupune ca sistemul MP de baza suporta broadcast t.o. (am aratat cum poate fi implementat). Pentru a evita confuzia vom folosi:
tbc - sendi(m) pentru bc - sendi(m,t.o.) si
tbc - recvi(m) pentru bc - recvi(m,t.o.)
Toti algoritmii folosesc replicarea completa: exista o copie locala a oricarui obiect partajat în starea procesului MCS din fiecare nod. (Asa cum se face, de exemplu în ORCA; gestionarea copiilor în alt stil este posibila dar aceasta este o alta problema).
Atunci când procesul MCS dintr-un nod primeste o cerere sa citeasca sau sa scrie un obiect partajat:
MCS trimite un mesaj broadcast continând cererea si asteapta sa-si primeasca mesajul sau.
Dupa primirea mesajului, executa raspunsul pentru operatia ce asteapta (returnând valoarea copiei obiectului pe care o detine el pentru un read si executând ack pentru write).
Ori de câte ori un proces MCS primeste un mesaj difuzat pentru un write, actualizeaza copia obiectului, în mod corespunzator.
Teorema: Daca sistemul de broadcast este total ordonat atunci algoritmul precedent simuleaza un DSM liniarizabil.
Demonstratie: Fie a o executie admisibila a algoritmului (fair, user compliant pentru sistemul cu memorie partajata si corecta pentru sistemul broadcast de comunicatie). Trebuie sa demonstram ca top(a) este liniarizabil. Fie s= top(a). Ordonam operatiile din s dupa ordinea totala a broadcast-urilor asociate lor din a si obtinem o permutare p
p respecta semantica obiectelor. Fie x un obiect read/write. p|x sete secventa operatiilor ce acceseaza x. Cum broadcast-urile sunt t.o., orice proces MCS primeste mesajele pentru operatiile asupra lui x în aceeasi ordine, care este ordinea lui p, si gestioneaza x corect.
p respecta ordonarea dupa timpul real de aparitie a operatiilor în a
Presupunem ca o1 se termina în a înainte ca operatia o2 sa înceapa.
Atunci broadcast-ul corespunzator lui o1, a fost primit de initiatorul sau înainte ca broadcast-ul lui o2 sa fie trimis de initiatorul sau. Evident, boadcastul lui o2 este ordonat dupa cel al lui o1. Deci operatia o1 apare în p înaintea lui o2.
Observatie: Cum un serviciu broadcast t.o. se poate implementa în topul unui sistem MP point-to-point, rezulta ca un DSM liniarizabil se poate implementa în topul unui sistem MP.
Nu este evident de ce trebuie difuzat un mesaj pentru operatia read, atâta timp cât nu se modifica nici o copie a obiectului ca rezultat al primirii mesajului de citire. Consideram algoritmul în care read-ul returneaza imediat valoarea din copia procesului MCS respectiv si renunta la broadcast.
Fie o executie în care valoarea initiala a lui x este 0. Procesorul pi invoca o scriere a lui 1 în x si executa un tbc - send pentru write. Mesajul difuzat ajunge la procesorul pj care-si actualizeaza copia sa locala a lui x pe 1, dupa care, sa spunem, executa un read pe x ce returneaza valoarea noua 1. Consideram un al treilea procesor pk care nu a primit mesajul de broadcast al lui pi si are înca valoarea copiei lui x pe 0. Presupunem ca pk citeste x (dupa ce pj executa read, dar înainte de a primi broadcastul lui pi); clar va obtine valoarea 0.
Nici o permutare a acestor trei operatii nu poate fi si conforma cu specificatia lui read/write si sa pastreze ordonarea dupa timpul real de aparitie a operatiilor în a
Totusi acest algoritm îndeplineste conditia de consistenta secventiala.
(codul pentru procesorul pi)
Initial, copy[x] pastreaza valoarea initiala a obiectului partajat x pentru orice x.
atunci când apare readi(x):
enable returni(x, copy[x])
atunci când apare writei(x,v):
enable tbc - sendi(x,v)
atunci când apare tbc - recvi(x,v) din pj :
copy[x]:=v
if j=i then enable acki(x)
Fie a o executie admisibila a algoritmului.
Lema 1 Pentru orice procesor pi copiile locale ale lui pi sunt actualizate de operatiile write în aceeasi ordine în fiecare procesor si aceasta ordine pasteraza ordinea operatiilor write asociate fiecarui procesor.
Aceasta ordine va fi numita ordine tbcast.
Lema 2 Pentru orice procesor pi si orice obiecte partajate x si y daca un read r al obiectului y urmeaza dupa un write w asupra obiectului x în top(a)|i atunci readul r al copiei locale a lui pi a lui y urmeaza dupa write-ul w al lui pi asupra copiei locale a lui x.
Din cele doua leme rezulta.
Teorema: Algoritmul precedent implementeaza un DMS secvential consistent cu read local.
Demonstratie: Trebuie demonstrat ca top(a) satisface conditia de consistenta secventiala.
Constructia lui p
Ordonam write-urile din p conform ordinii tbcast. Trebuie sa mai inseram read-urile. Pentru fiecare read din a parcurs de la stânga la dreapta: Read-ul r executat de pi asupra lui x este plasat imediat dupa ultima aparitie din p asociata (1) aparitiei precedente din a asupra lui pi (read sau write asupra oricarui obiect) si (2) write-ului care a cauzat ultima actualizare a copiei locale a lui x detinuta de pi, care precede punctul în care returul lui r a fost activat.
În caz de egalitate se foloseste id-ul procesoarelor pentru stabilirea ordinii (de exemplu daca orice procesor citeste un obiect inainte ca orice procesor sa scrie un obiect atunci p începe cu read-ul lui p0, urmat de read-ul lui p1 s.a.m.d).
Trebuie demonstrat ca top(a)|i=p|i. Din constructe, pentru un procesor pi fixat ordinea relativa a doua read sau a doua write este aceeasi în top(a)|i ca si în p|i. Ceea ce trebuie aratat este ca r si w sunt în aceasta ordine si aceasta rezulta din codul algoritmului. În plus trebuie aratat ca p este legala.
Se poate inversa rolul celor doua operatii:
Facem write-ul local si read-ul încet (datorita tbc - send-urilor)
(codul pentru procesorul pi 0 i n-1)
Initial, copy[x] pastreaza valoarea initiala a obiectului partajat x pentru " x si num=0.
Atunci când apare readi(x):
if num=0 then enable returni(x,copy[x])
atunci când apare writei(x,v):
num:=num+1
enable tbc - sendi(x,v)
enable acki(x)
atunci când apare tbc - recvi(x,v) din pj:
copy[x]:=v;
if j=i then
num:=num-1
if num=0 and (exista un read care asteapta pe x) then
enable returni(x,copy[x])
Ideea algoritmului: Când apare un write(x) în pi se trimite un mesaj de broadcast ca si în algoritmul precedent; totusi el este confirmat imediat. Când apare un read(x) în pi, daca pi nu are actualizari care asteapta (pe " obiect nu numai pe x) atunci returneaza valoarea curenta a copiei sale a lui x. Altfel, asteapta pâna primeste mesajul de broadcast pentru toate write-urile pe care el le-a initiat si abia atunci returneaza. Aceasta se realizeaza mentinând un contor al tuturor write - broadcasturilor initiate de el si asteapta pâna acesta este zero.
În esenta, algoritmul implementeaza un pipeline pentru actualizarea write-urilor generate de acelasi procesor.
Teorema: Algoritmul precedent implementeaza un DMS secvential consistent cu write local.
Observatie: Acest algoritm, ca si precedentul nu asigura linearitatea.
Vom presupune ca DSM a fost implementat în topul unui sistem de tip MP, point-to-point.
Adaptam definitia unei executii cu timpi (timed execution) pentru sistemul simulat, considerând ca numai evenimentelor de intrare într-un nod li s-au asignat timpi, celelalte evenimente din nod mostenind timpii evenimentelor de intrare în nod, care le-au declansat.
În plus vom considera ca:
orice mesaj are o întârziere într-un interval [d-u,d], unde 0 < u d.
Pentru un MCS fixat si o operatie op vom nota cu top timpul, în cazul cel mai nefavorabil, peste toate executiile admisibile, necesitat de operatia op (diferenta dintre timpul real de aparitie a raspunsului si timpul real de aparitie al invocarii).
Teorema 1: Pentru orice MCS secvential consistent care asigura doua obiecte partajate read/write, tread + twrite d.
Demonstratie: Fie un MCS secvential consistent si doua obiecte partajate x si y, initial 0 amândoua.
Exista o executie admisibila a a lui MCS a.î.
top(a ) = write0(x, 1) ack0(x) read0(y) return0(y,0)
si write începe la timpul 0 iar read raspunde inaintea timpului d.
Presupunem, în plus, ca orice mesaj trimis in a are intirzierea d. Rezulta ca nici un mesaj n-a fost primit de nici un nod la momentul de timp când read primeste raspunsul.
Similar, exista o executie admisibila a a lui MCS a.î.
top(a ) = write1(y, 1) ack1(y) read1(x) read1(x) return1(x,0)
write apare la timpul 0, raspunsul la read apare înaintea timpului d. Deci nici un mesaj n-a fost primit în nici un nod la momentul de timp când read primeste raspunsul.
Vom construi o noua executie a care combina comportarea lui p0 în a (în care p0 scrie x si citeste y) cu comportamentul lui p1 în a (scrie y si citeste x). Cum amândoua operatiile pe fiecare procesor se termina înainte de momentul d, p0 nu stie despre opearatiile lui p1 si invers. Deci procesoarele returneaza aceeasi valoare în a pe care ele le fac în a a ). Dupa timpul d în a, se permite ca orice mesaj ce asteapta sa fie livrat, dar este deja prea târziu pentru a mai afecta valorile returnate anterior. Clar, aceste valori sunt inconsistente cu conditia de consistenta secventiala.
Formal, fie ai|i (i=0,1) si hi prefixul cel mai lung al lui ai|i ce se termina înaintea timpului d, si a'=merge(h h a' este prefixul unei executii admisibile a. Dar top(a) este exact secventa s din observatia de dupa definitia conditiei de secvential consistenta, care s-a vazut ca nu-i secvential consistenta.
Observatie: Marginea inferioara obtinuta este valabila în particular si pentru MCS liniarizabil. În acest caz se poate spune chiar mai mult.
Teorema 2: Pentru orice MCS liniarizabil care asigura un obiect partajat read/write scris de doua procesoare si citit de un al treilea
![]()
Demonstratie: Fie un MCS liniarizabil si un obiect partajat x initial 0 care
este citit de p0 si scris de p1 si p2.
Presupunem prin reducere la absurd ca ![]() .
.
Exista o executie admisibila a a lui MCS a.î.
top(a) = write1(x, 1) ack1(x) write2(x, 2) ack2(x) read0(x) return0(x,2).
write1(x,1) apare la timpul 0, write2(x,2) apare la timpul u/2 si read0(x) apare la timpul u.
întârzierile mesajelor în a sunt: d din p1 la p2; d-u din p2 la p1 si d-u/2 pentru orice alta pereche ordonata de procesoare.
Fie b=shift(a,<0,u/2,-u/2>) adica îl dam pe p1 înainte cu u/2 si pe p2 înapoi cu u/2.
b este înca admisibila, întrucât întârzierea mesajelor din p1 sau în p2 devine d-u, întârzierea mesajelor din p2 sau în p1 devine d si toate celelalte întârzieri ramân neschimbate.
Dar top(b)=write2(x, 2) ack2(x) write1(x, 1) ack1(x) read0(x) return0(x,2). Dar aceasta încalca liniarizabilitatea deoarece read-ul lui p0 ar trebui sa returneze 1 si nu 2.
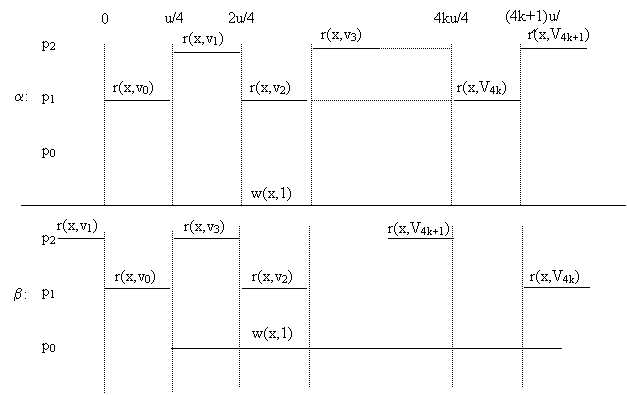
Teorema 3: Pentru orice MCS care asigura un obiect partajat x citit de doua procesoare si scris de un al treilea
![]()
Demonstratie: Fie un MCS liniarizabil si x un obiect partajat, initial 0 care
este scris de p0 si citit de p1 si p2.
Presupunem prin reducere la absurd ca ![]()
Ideea demonstratiei este aceeasi ca în teorema precedenta, numai ca este ceva mai elaborata.
Fie ![]() . Consideram a o executie admisibila a lui MCS în care toate întârzierile
mesajelor sunt d-u/2 comtinând urmatoarele evenimente:
. Consideram a o executie admisibila a lui MCS în care toate întârzierile
mesajelor sunt d-u/2 comtinând urmatoarele evenimente:
La momentul u/4, p0 face un write0(x,1)
La un moment intre ![]() si
si ![]() , p0 face ack0(x). (
, p0 face ack0(x). (![]() si deci write-ul lui p0 se termina în
acest interval).
si deci write-ul lui p0 se termina în
acest interval).
La momentul ![]() , p1 face read1(x) 0 i 2k.
, p1 face read1(x) 0 i 2k.
La un moment între ![]() si
si ![]() , p1 face return1(x,V2i) 0 i 2k.
, p1 face return1(x,V2i) 0 i 2k.
La momentul ![]() , p2 face read2(x) 0 i 2k.
, p2 face read2(x) 0 i 2k.
La un moment între ![]() si
si ![]() , p2 face return2(x,V2i+1) 0
i 2k.
, p2 face return2(x,V2i+1) 0
i 2k.
Deci în top(a), read-ul lui p1 al lui V0 precede write-ul lui p0, read-ul lui p2 al lui V4k+1 urmeaza dupa write-ul lui p0, nu avem read-uri suprapuse si ordinea citirilor valorilor din x este V0, V1, V2,...,V4k+1.
Din liniarizabilitatea v0=0 si V4k+1=1. j 0 j 4k a.î. Vj=0 si Vj+1=1. Presupunem ca j este par deci Vj este rezultatul unui read al lui p1.
Definim b=shift(a,<0,0,-n/4>) adica îl dam înapoi pe p2 cu n/4. b este admisibila, întrucât întârzierea mesajelor în p2 devine d-n, întârzierea mesajelor din p2 devine d si celelalte întârzieri ramân neschimbate.
v1, v0, v3, v2,...,vj+1, vj,..... Deci în top(b) avem vj+1=1 citit înaintea lui vj=0, care violeaza liniarizabilitatea.
Simulari tolerante la defectiuni ale obiectelor read-write
Simularea unui obiect de nivel înalt cu unul de nivel jos este utila pentru proiectarea algoritmilor folosind primele obiecte desi executia se face într-un sistem realist ce dispune doar de ultimele.
Vom prezenta simulari de sisteme cu memorie partajata în topul altor tipuri de obiecte cu memorie partajata sau în topul unui sistem asincron de tip transmisie de mesaje, în prezenta defectiunilor de tip crash.
Considerarea caderilor se poate face în doua moduri echivalente: definim un sistem de memorie partajata care sa permita defectiuni sau modificam definitia simularii pastrând definitia sistemelor de memorie partajata libere de defectiuni.
Intrarile sunt invocari ale obiectelor partajate si iesirile sunt raspunsuri de la obiectele partajate. Se presupune o partitie a procesoarelor cu doua clase, procesoare defecte si nedefecte, numarul celor defecte este mai mic sau egal cu f. O secventa s de i|o este admisibila daca urmatoarele proprietati au loc:
Correct Interaction: Pentru fiecare procesor pi, s|i este sir alternat de invocari si raspunsuri pereche, începind cu o invocare.
Nonfaulty Liveness: Orice invocare a unui procesor nedefect are un raspuns pereche.
Extended Liniarizability: Exista o permutare p a tuturor operatiilor complete din s (cele care au raspuns) si a unei submultimi a operatiilor incomplete a.î.:
p|o este legala pentru orice obiect o.
Daca în s, raspunsul la operatia o1 apare înaintea invocarii lui o2 , atunci o1 apare înaintea lui o2 în p
Vom studia daca sistemul de comunicatie C1 poate simula sistemul de comunicatie C2 , unde C2 este un sistem cu memorie partajata cu un anumit tip de obiecte care admite f caderi de procesoare, iar C1 este un sistem de comunicatie (sau cu memorie partajata sau de tip MP) care admite f caderi de procesoare.
De fapt vom discuta cazul f=n-1, numit wait-free datorita definitiei urmatoare echivalente.
O simulare a unui sistem de tip memorie partajata (fara defectiuni) de catre alt sistem de tip memorie partajata (tot fara defectiuni) se numeste wait-free daca:
Pentru orice executie admisibila a a programului de simulare, daca a' este un prefix în care un procesor pi are o operatie incompleta (exista în a' o invocare din mediul extern în pi fara un raspuns pereche) a a b, atunci b|pi contine raspunsul la aceasta operatie.
(Orice operatie trebuie sa fie capabila sa se termine în orice punct fara asistenta altor procesoare, f=n-1; operatiile pe procesoarele nedefecte se desfasoara normal).
Observatie: Conditia de liniarizabilitate corespunde intuitiei ca operatiile (de nivel înalt) apar ca fiind executate atomic într-un anumit moment în timpul executiei lor. Acest moment se afla undeva între invocarea si raspunsul la operatie si se numeste punct de liniarizabilitate. Un mod de a demonstra ca o secventa este liniarizabila este acela de a asigna explicit fiecarei operatii un punct de liniarizabilitate. Acesta va asigura ordinea temporala a operatiilor ce nu se suprapun. Daca se arata în plus ca fiecare nod returneaza valoarea operatorului write cu punctul de liniarizabilitate cel mai recent ce precede operatorul read, am demonstrat ca executia este liniarizabila.
Vom prezenta în continuare urmatorul lant de simulari wait-free ale registrelor de tip read-write.

Binar - Multivaluat
Un registru este single - reader (s - r) daca exista un singur procesor (cititorul) ce poate citi din el si single - writer daca exista un singur procesor (scriitorul) ce poate scrie în el, (s - w).
Simularea unui registru cu K valori, de tip s - r, s - w cu ajutorul unor registre s - r, s - w cu valori binare.
Pentru simplitate vom considera un singur registru R cu K valori si doua procesoare bine definite scriiorul si cititorul. Pentru simularea lui R, vom considera un tablou de K registri binari B[0..K-1]. Valoarea i va fi reprezentata de un 1 în componenta B[i] si 0 în celelalte. Deci, valorile posibile ale lui R sunt .
O operatie read(R) va fi simulata prin scanarea vectorului B începând cu indicele 0 si returnând prima componenta egala cu 1 (daca exista). O operatie write(R,v) va fi simulata punând 1 în B[v] si si stergând componenta egala cu 1 ce corespunde valorii precedente a lui R.
Acest scenariu simplu functioneaza în cazul operatiilor R si W care nu se suprapun.
Daca operatiile cititorului sunt în ordine read(R,2) read(R,1)iar ale scriitorului write(R,1) write(R,2) atunci, o liniarizare a acestor operatii va trebui sa se pastreze ordinea operatiilor fiecarui procesor. Pentru a fi îndeplinit semantica registrului R va trebui ca write(R ,1) sa apara înainte de read(R,2) pe cînd write(R,1) trebuie sa apara înainte de read(R,1) si dupa read(R,2). Deci, sau ordinea operatiilor read sau ordinea operatiilor write trebuie schimbata. Algoritmul urmator rezolva aceasta problema a inversiunilor "nou - vechi" ale valorilor.
Algoritmul de liniarizare registru multi-valuat cu registre binare
Initial registrii partajati B[0].....B[K-1] sunt 0 cu exceptia lui B[i]=1, unde i este valoarea initiala a lui R
când apare read(R): //cititorul citeste din registrul R
i:=0
while B[i]=0 do i:=i+1
up,v:=i
for i:=up-1 downto 0 do
if B[i]=1 then v:=i
return(R,v)
când apare write(R,v): //scriitorul scrie valoarea v în registrul R
B[v]:=1
for i:=v-1 downto 0 do B[i]:=0
ack(R)
Evident , algoritmul este wait-free; fiecare write executa cel mult K operatii write de nivel jos iar fiecare read executa cel mult 2K-1 operatii read de nivel jos.
Pentru a demonstra ca algoritmul este corect trebuie sa aratam ca orice executie edmisibila este liniarizabila, admite o permutare a operatiilor de nivel înalt a.î. sa se pastreze ordinea operatiilor care nu se suprapun si în care orice read returneaza valoarea ultimului write precedent.
Fixam o executie a admisibila a algoritmului. Cum a este corecta pentru sistemul de comunicatie cu registre binare, operatiile cu registre binare sunt liniarizabile. Deci fiecare operatie de nivel jos admite un punct de liniarizabilitate.
Asociem fiecarei configuratii a executiei a o "valoare actuala" a registrului multivaluat R: valoarea actuala a lui R este
![]()
În aceasta definitie valoarea lui B(i) este în raport cu punctele de liniarizabilitate ale operatiilor de nivel jos.
Construim o liniarizare a lui a. Punctele de liniarizabilitate al operatiei write(R,k) este imediat dupa prima configuratie din intervalul ei în care b[k]=1 si B[0]=...=B[k-1]=0. La terminare alui write(R,k) (atunci când apare ack(R)) aceasta este situatia, dar punctul de liniarizabilitate poate fi mai înainte (daca, de exemplu valoarea precedenta a lui R a fost mai mare decât k, el este imediat dupa executia operatiei de nivel jos B[k]:=1).
Punctul de liniarizabilitate a lui read(R) care se termina cu return(R,k) este imediat dupa prima configuratie din intervalul ei, în care k este asignat variabilei locale v, (linia 3 sau 5).
Lema 1: Valoarea actuala a lui R ramâne fixa între doua puncte de liniarizabilitate ale operatiei write consecutive de nivel înalt.
Lema 2: Pentru fiecare operatie read r (de nivel înalt) din 2, r returneaza valoarea scrisa în R de operatia write (de nivel înalt) cu ultimul punct de liniarizabilitate înaintea ultimului punct de liniarizabilitate al lui r.
Din cele doua leme rezulta urmatoarea
Teorema. Algoritmul precedent reprezinta o simulare wait-free a unui registru K-valuat folosind K registri binari s-r, s-w, în care fiecare operatie necesita O(K) operatii de nivel jos.
Single - reader Multi - reader
Mai multe procesoare (n) citesc din acelasi registru. Vom permite existenta unui singur scriitor pentru fiecare registru. Registrului R i se va asocia o colectie de n registre s - w, s - r Val[i] i=1,n , unul pentru fiecare cititor.
Un scenariu simplu de simulare:
write(R,v) va obliga cititorul sa parcurga toate cele n registre Val[i] si sa memoreze v în ele.
read(R) : cititorul i returneaza valoarea din Val[i].
Din pacate aceasta simulare este incorecta, exista executii care nu sunt liniarizabile.
Exemplu
Valoarea initiala a registrului este 0. Scriitorul pw doreste sa scrie 1 în registru. Consideram urmatoarea secventa de operatii:
pw starteaza operatia de write(R,1), scriind 1 în Val[1]
p1 citeste din R si returneaza 1 din Val[1]
p2 citeste din R si returneaza 0 din Val[2]
pw primeste ack dupa scrierea lui 1 în Val[1], scrie 1 în Val[2] si confirma (ack) scrierea sa (de nivel superior).
Citirea lui p1 trebuie ordonata dupa scrierea lui pw si citirea lui p2 înaintea scrierii lui pw. Deci citirea lui p1 trebuie ordonata dupa citirea lui p2.Totusi, citirea lui p1 apare înaintea citirii lui p2.
Are loc urmatoarea teorema:
Teorema
În orice simulare wait-free a unui registru s - w, m - r cu orice numar de registre s - r, s - w, cel putin un cititor trebuie sa scrie.
Solutia pentru simulare va necesita ca cititorii sa-si scrie unii altora creind o ordine între ei. Înainte de a returna valoarea din read-ul sau, un cititor îi va anunta pe ceilalti aceasta valoare. Un cititor va citi valoarea scrisa de scriitor pentru el, dar si valorile anuntate de ceilalti cititori. Va alege cea mai recenta valoare pe care el a citit-o. Vom presupune ca registrele pot lua un numar nemarginit de valori. În aceasta ipoteza, scriitorul poate asocia un numar întreg drept timestamp (a câta oara a scris) pentru fiecare valoare scrisa. În continuare vom referi o valoare ca fiind perechea ce contine o valoare reala si numarul sau de ordine.
Se vor folosi tablourile de registre s - r :
Val[i]: valoarea scrisa de pw pentru cititorul pi 1 i n
Report[i,j]: Val returnata de cea mai recenta operatie read
executata de pi; scris de pi si citit de pj 1 i,j n
Algoritm de simulare a unui registru m - r R cu registri s - r
Initial, Report[i,j]=Val[i]=(v0,0) 1 i,j n (unde v0 este valoarea initiala a
lui R)
când apare readr(R) : //cititorul r citeste din registrul R
(v[0],s[0]):=Val(v) // cea mai recenta valoare raportata lui pr , de scriitor
for i:=1 to n do
(v[i],s[i]):=Report[i,r] // cea mai recenta valoare raportata lui pr , de pi
fie j a. î. s[j]=max(s[0],s[1],...,s[n])
for i:=1 to n do
Report[r,i]:= (v[j],s[j]) // pr raporteaza fiecarui cititor pi
returnr(R,r[j])
când apare write(R,v) : //scriitorul scrie în registrul R
seq:=seq+1
for i:= to n do
Val[i]:=(v,seq)
ack(R)
Algoritmul este wait-free : fiecare operatie simulata executa un numar fix de oparatii de nivel jos (n pentru write si 2n+1 pentru read).
Liniarizabilitatea se demonstreaza considerind o executie admisibila a oarecare si construind explicit permutarea p
Single - writer Multi - writer
Ideea algoritmului de simulare. Fiecare scriitor anunta valoarea pe care intentioneaza sa o scrie, tuturor cititorilor (scriindu-le-o în registrul fiecaruia, registru de tip s - w, m - r). Fiecare cititor citeste toate valorile scrise de scriitori si o alege pe cea mai recenta dintre ele. Depistarea valorii cea mai recenta se face cu ajutorul unui timestamp asociat fiecarei valori. Spre deosebire de algoritmul precedent, timestamp-ul nu este generat de un singur procesor (unicul writer) ci de mai multe procesoare (toti scriitorii posibili).
Scriitorii sunt p0,...,pm-1 iar cititorii sunt toate procesoarele p0,p1,...,pn-1. Se vor folosi tablourile de registri s - w, m - r :
TS[i] timestamp-ul vectorial al scriitorului pi 0 i m-1. Este scris de pi si citit de toti scriitorii.
Val[i] Ultima valoare scrisa de scriitorul pi 0 i m-1, împreuna cu timestamp-ul vectorial asociat cu acea valoare. Scris de pi si citit de toti cititorii.
Algoritm de simulare a unui registru m - w R cu registri s - w
Initial, TS[i]=<0,...,0> si
Val[i] este valoarea initiala a lui R 0 i m-1
când apare readr(R): // cititorul pr citeste din registrul R, 0 r n
for i:=0 to m-1 do (v[i],t[i]):=Val[i] //v,t sunt locale
fie j a.î. t[j]=max // maximul lexicografic
returnr(R,v[j])
când apare writew(R,v): //scriitorul pw scrie v în R, 0 w m-1
ts:=NewCTS() //ts este local
val[w]:=(v,ts)
ackw(R)
procedure NewCTSw() //scriitorul pw obtine un nou timestamp vectorial
for i:=1 to m do lts[i]:=TS[i].[i]
lts[w]:=lts[w]+1
TS[w]:=lts
return lts
Simularea registrilor partajati în sisteme de tip MP
În cazul existentei defectiunilor, metoda descrisa pentru simularea memoriei partajate în topul unui sistem broadcast t.o., bazata pe asteptarea confirmarii din sistemul MP, nu mai functionaza. Atunci când exista defectiuni, un procesor nu poate fi sigur ca va primi un mesaj trimis catre el. Mai mult, nu poate astepta o confirmare de la destinatar, pentru ca acesta poate pica.Vom folosi toate procesoarele ca extra - memorie pentru a implementa fiecare registru partajat (nu numai scriitorii si cititorii acelui registru). Desigur, valorile sunt acompaniate de numare de ordine. Metoda pe care o vom descrie functioneaza în ipoteza ca numarul procesoarelor defecte f satisface f < n/2 (se poate demonstra ca nu este posibila o simulare a unui registru read/write în topul unui sistem asincron MP daca n 2f).
Consideram un registru particular ce va fi simulat. Când scriitorul doreste sa scrie o valoare în acest nou registru, incrementeaza un numar de ordine si trimite un mesaj <newval> continând noua valoare si numarul de ordine, tuturor procesoarelor.
Fiecare primitor actualizeaza o variabila locala cu aceasta informatie, daca numarul de ordine asociat este mai mare decât valoarea curenta a numarului de ordine din variabila locala; în orice eveniment receptorul trimite un mesaj de <ack>.
Odata
ce scriitorul primeste <ack> de la cel putin ![]() procesoare el
termina de scris. Cum n>2f
procesoare el
termina de scris. Cum n>2f ![]() si deci avem
garantia ca va termina de scris.Când cititorul doreste sa
citeasca un registru, el trimite un mesaj de tip <request> tuturor
procesoarelor. Fiecare procesor trimite înapoi un mesaj de tip <value>
continând informatia curenta pe care o detine. Odata
ce cititorul primeste <value> de la cel putin
si deci avem
garantia ca va termina de scris.Când cititorul doreste sa
citeasca un registru, el trimite un mesaj de tip <request> tuturor
procesoarelor. Fiecare procesor trimite înapoi un mesaj de tip <value>
continând informatia curenta pe care o detine. Odata
ce cititorul primeste <value> de la cel putin ![]() procesoare, el
returneaza valoarea cu cel mai mare numar de secventa
dintre cele primite.
procesoare, el
returneaza valoarea cu cel mai mare numar de secventa
dintre cele primite.
Comunicarea
cu ![]() procesoare
garanteaza un quorum pentru
fiecare operatie read sau write. Cum în aceste quorum-uri avem majoritatea
procesoarelor, va exista un procesor în intersectia oricarui quorum
al unui read cu orice quorum al unui write. Acesta garanteaza faptul
ca ultima valoare scrisa va fi obtinuta.
procesoare
garanteaza un quorum pentru
fiecare operatie read sau write. Cum în aceste quorum-uri avem majoritatea
procesoarelor, va exista un procesor în intersectia oricarui quorum
al unui read cu orice quorum al unui write. Acesta garanteaza faptul
ca ultima valoare scrisa va fi obtinuta.
Pentru a evita problemele potentiale legate de asincronie, si scriitorul si cititorul mentin o variabila locala status [0..n-1] pentru a guverna comunicarea; status[j] contine una din valorile:
not-sent: mesajul pentru cea mai recenta operatie n-a fost înca trimis lui pj (pentru ca pj n-a confirmat un mesaj anterior)
not-acked: mesajul pentru cea mai recenta operatie a fost trimis lui pj dar n-a fost confirmat de pj
acked: mesajul pentru cea mai recenta operatie a fost confirmat de pj
În plus, fiecare procesor are un numarator num-acks cu care-si numara raspunsurile primite în timpul operatiei curente.
Algoritm pentru simularea unui registru read/write cu MP
(codul pentru unicul scriitor)
Initial status[j]=acked pentru "j, seq=0 si pendinng=false
Când apare writew(v): // procesorul pw scrie în registru
pendinng:=true
seq:=seq+1
num-acks:=0
for "j do
if status[j]=ackd then //are raspuns dat pentru operatia precedenta
enable sendw<newval, (v,seq)> to pj
status[j]:=not-acked
else status:=not-sent
Când apare <ack> de la pj:
if not pending then status[j]:=acked //nici o operatie în executie
else if status[j]=not-sent then //raspuns la un mesaj precedent
enable sendw(<newval>, (v,seq)> to pj
status[j]:=not-acked
else //raspuns la operatia curenta
status[j]:=acked
num-acks:= num-acks+1
if ![]() then //confirmare de la majoritatea
then //confirmare de la majoritatea
pending:=false
enable ackw
Algoritm pentru simularea unui registru read/write cu MP
(Codul pentru unicul cititor pi)
Initial status[j]=acked pentru "j, seq=0 si pendinng=false
Când apare readi():
pendinng:=true
num-acks:=0
for "j do
if status[j]=acked then //are raspuns dat pentru operatia precedenta
enable sendi<request> to pj
status[j]:=not-acked
else status:=not-sent
Când apare receive<value, (v,s)>
if not pending then status[j]:=acked //nici o operatie în executie
else if status[j]=not-sent then //raspuns la un mesaj precedent
enable sendi<request> to pj
status[j]:=not-acked
else //raspuns la operatia curenta
if s>seq then
status[j]:=acked
num-acks:= num-acks+1
if ![]() then
then
pending:=false
enable returni(val)
Algoritm pentru simularea unui registru read/write cu MP
(codul pentru orice procesor pi 0 i n-1, inclusiv pw si pi)
Initial last=(v0,0) unde v0 este valoarea initiala a registrului simulat
 Când apare receivew<newval,(v,s)>
:
Când apare receivew<newval,(v,s)>
:
last:=(v,s)
enable sendi(ack) to pw
Când apare receive i(request):
3.enable sendi(value, last) to pi
|
