De ce este atât de dificil pentru calculatoare sa înteleaga limbajul natural?
Nivelele analizei lingvistice
Importanta rezolutiei anaforei pentru alte aplicatii NLP
CAPITOLUL I - Referinte teoretice
Discursul
Coerenta si coeziunea textului
Centrele
Grup nominal (NP), grup verbal
Anafora
Diferite tipuri de anafora în functie de forma anaforului
Tipuri de anafora în functie de semantica
Catafora
Entitati variabile în timp
Rezolutia anaforei
CAPITOLUL II - Rezolutia automata a anaforei
Cunoasterea necesara pentru rezolutia automata a anaforei
Etapele procesului automat de rezolutie a anaforei
Evaluarea algoritmilor pentru rezolutia anaforei
Primele sisteme pentru rezolutia anaforei
Rezolutia anaforei în prezent
Modelul de reprezentare a anaforei folosit în Genframe
Rezolutia anaforei în Genframe
Structura unui model-AR
Functionarea Genframe-ului
Implementarea sistemului Genframe
Modele existente - trasaturi si asteptari:
Caracterizarea modelului meu:
Noutati aduse de acest model:
Implementarea aplicatiei:
Evaluarea aplicatiei
A învata sa comunici cu calculatorul poate schimba modul în care înveti alte lucruri. (Seymour Papert)
Oamenii sunt fara nici un dubiu cele mai inteligente fiinte. Relatiile dintre oameni se bazeaza pe comunicare, mai ales pe limbaj. Care este relatia dintre inteligenta si limbaj? Cum contribuie limbajul la inteligenta? Dar ce este inteligenta? Sunt numai câteva întrebarile la care filozofii sau oamenii de stiinta au încercat sa raspunda.
Oamenii si-au dorit din totdeauna sa construiasca masini "inteligente" care sa le usureze viata si sa comunice cu ele eventual prin limbaj natural.
În prezent calculatoarele (si robotii) sunt considerate cele mai "inteligente" masini, dar ele sunt departe de a fi atât de inteligente precum si-au dorit oamenii.
În încercarea de a crea inteligenta artificiala informaticienii au "programat" calculatoarele sa imite oamenii: le-au "dotat" cu cunostinte dintr-un domeniu anume si cu un algoritm pentru o functie asociata, sperând ca rezultatele calculatorului sa egaleze sau depaseasca rezultatele oamenilor în acel domeniu. O tendinta actuala în informatica este de a transforma calculatorul pentru a permite realizarea dialogului dintre om si calculator în maniera cea mai naturala - limbajul. De aceasta problema se ocupa Lingvistca computationala, ramura a Inteligentei artificiale.
Rezolutia anaforei este o problema clasica de lingvisitica computationala si are un rol vital într-un numar mare de aplicatii de prelucrare a limbajului natural cum ar fi traducerea automata, abstractizarea automata, extragerea de informatii si raspunderea la întrebari.
Comunicarea este esenta stiintei. (Bachelard)
Aceasta lucrare este despre rezolutia automata a anaforei, o problema esentiala în întelegerea limbajului natural de catre calculatoare. Anafora este un fenomen studiat atât de lingvistica computationala cât si de cea clasica ce a atras atentia multor cercetatori în ultimii ani. Teorii si formalisme ca teoria centrelor, teoria structurilor retorice au inspirat noi cercetari legate de rezolutia automata a anaforei. În plus, aplicatiile orientate spre cercetare ca abstractizarea automata, extragerea de informatii au identificat, independent, importanta rezolutiei anaforei.
Am prezentat rezolutia anaforei pentru limba engleza deoarece pentru aceasta limba sunt mai multe unelte de prelucrare a limbajului (WordNet, parsere, etc.) necesare unui program de prelucrare a limbajului. Exemplele sunt de asemenea în limba engleza pentru întelegerea problemelor specifice limbii engleze referitoare la anafora.
În primul rând va fi explicat de ce întegerea limbajului natural de catre calculator este o problema atât de dificila, cum ar trebui abordata, ce presupune analiza unui text si de ce este rezolutia anaforei importanta. În Capitolul I vor fi prezentate câteva notiuni teoretice necesare întelegerii lucrarii. În Capitolul II este explicat cum functioneaza si cum se evalueaza un algoritm pentru rezolutia anaforei; sunt prezentati algoritmi clasici si tendintele actuale. Capitolul III este dedicat descrierii unui sistem pentru rezolutia automata a anaforei - GenFrame. În capitolul IV este descris si evaluat modelul propus de mine pentru a rezolva problema anaforei. Ultima parte este rezervata concluziilor si sugestiilor.
Întelegerea limbajului natural este o sarcina dificila pentru calculatoare. Principala dificulate rezulta din faptul ca limbajul natural este ambiguu. Oamenii reusesc sa înteleaga informatiile pe care le primesc cu ajutorul "mecanismelor de inteligenta" cu care sunt dotati. Complexitatea acestora îi ajuta sa proceseze informatiile si sa faca asocierile necesare descifrarii acestora. Calculatorul nu reuseste sa gaseasca sensul unei informatii dintr-un set de interpretari posibile deoarece "cunostintele" sale sunt limitate si el este incapabil sa le integreze în contex.
Ambiguitatea poate aparea la nivel lexical pentru ca sunt cuvinte care au mai multe sensuri (bank, file, chair), dar si la nivel sintactic când sunt posibile mai multe analize structurale (I saw the man with the telescope). Mai mult ambiguitate este si la nivelul semantic (The rabbit is ready for lunch - unde rabbit poate fi interpretat si ca agent si ca subiect) sau la nivel pragmatic (Can you open the window - poate fi interpretata si ca intrebare dar si ca rugaminte în functie de situatie). Rezolvarea automata a ambiguitatii presupune existenta unei cantitati imense de cunostinte lingvistice si nelingvistice precum si capacitati de învatare si inferare. De aceea este o problema care poate fi rezolvata doar pentru un domeniu restrâns.
Un sistem de prelucrare a limbajului natural necesita cunostinte despre limbaj, inclusiv identificarea cuvintelor, modul de aranjare a cuvintelor în propozitii, sensul cuvintelor si modul în care sensul lor individual se combina pentru a da înteles propozitiei. La un nivel superior, trebuie sa stie sa identifice propozitii într-un text, sa stabileasca relatii între ele, etc. Pentru ca un sistem de prelucrare automata a limbajului natural sa fie capabil sa înteleaga limbajul ca oamenii, ar trebui sa aiba cunostinte (world and domain knowledge) cât si capacitati de rationare.
Un program NLU (Natural Language Understanding) ar trebui sa fie capabil sa stabileasca relatii între diferite parti ale unei propozitii sau ale unui text.
Fie urmatorul text:
This book outlines the state of the art of anaphora resolution. It discusses the complexity of this NLU task.
(Aceasta carte subliniaza satutul de arta al rezolvarii anaforei. Discuta complexitatea acestei probleme NLU.)
Ruslan Mitkov, Anaphora Resolution
Pentru a prelucra text-ul sunt necesare urmatoarele etape si cunostinte:
Analiza morfologica si lexicala pentru a identifica cuvintele, clasa lexicala (partea de vorbire) si derivarile posibile; sunt necesare cunostinte morfologice si lexicale sub forma unor reguli si dictionare (pentru acronisme de exemplu).
This va fi identificat ca determinant; book ca substantiv, etc.
Despartirea în propozitii.
Analiza sintactica pentru a desparti propozitiile în componenti sintactici (grupuri nominale, grupuri verbale, etc) si aplicarea de reguli gramaticale: this book the state of the art anaphora resolution vor fi recunoscute ca grupuri nominale, iar outlines the state of the art of anaphora resolution ca grup verbal;
Analiza semantica va determina sensul fiecarui cuvânt si cum cuvintele se leaga unele de altele; cunostintele necesare sunt de obicei dictionare sau ontologii: verbul outline necesita un agent, si anume o persoana sau o lucrare scrisa iar subiectul actiunii ar trebui sa fie o problema, un eveniment, un domeniu, etc.
Pentru ca textul sa fie înteles o etapa a analizei textului ar fi determinarea legaturilor anaforice: programul ar trebui sa determine ca it din a doua propozitie refera this book si ca this NLU task refera anaphora resolution
Interpretarea anaforei este vitala pentru succesul unui sistem de traducere automata. În particular, când se traduce dintr-o limba pentru care pronumele au forme diferite pentru fiecare gen în alta limba care nu are forme diferite este esentiala gasirea relatiilor anaforice. Doar un numar limitat de sisteme de traducere automata reusesc sa traduca cu succes un discurs, nu doar propozitii izolate, pentru ca nu rezolva problema anforelor. [Wada, 1990], [Leass & Schwall, 1991], [Nakaiawa et al, 1994], [Saggion & Carvalho, 1994], [Mitkov et al., 1997], [Geldbach, 1997] sunt proiecte care au obtinut rezultate încurajatoare legate de rezolutia anaforei pentru traducerea automata.
Relatia de coreferinta are un rol important si pentru extragerea de informatii. [Al-Kofani et al., 1999] este sistem ce foloseste rezolutiei anaforei pentru extragerea si prelucrarea de informatii.
În domeniul sumarizarii textelor tehnicile de extragere a propozitiilor mai importante au rezultate mai bune daca sunt folosite si relatii anaforice. Lanturile coreferentiale si coreferinta au fost folosite pentru abstactizare. [Baldwin & Morton, 1988], [Azzam, Humphreys & Gaizauskas, 1999] descriu tehnici de sumarizare a textelor folosind lanturile coreferentiale.
Rezolutia coreferintei dintre documente este importanta pentru sumarizarea inter-document. (de exemplu algoritmul [Bagga & Baldwin, 1998] )
Gasirea automata a raspunsurilor la întrebari este ajutata mult de gasirea coreferintelor. [Morton, 1999] gaseste raspunsuri la întrebari prin stabilirea de legaturi coreferentiale între entitatile si evenimentele din întrebari si cele din document.
Alte aplicatii folosesc rezolutia anaforei pentru obtinerea unor rezultate mai bune (de la 92,6% la 97%) în învatarea automata a unor diferite structuri ([Charniak, 2001]), verificarea corectitudinii traducerii ([Canninq et al., 2000])
Tot ceea ce e mai bun în lume este ceea ce produce gândul. (Hegel)
Primul capitol este o prezentare a anaforei si a conceptelor asociate. Prezinta fenomenul de coreferinta si clasificarea anaforei.
Un text nu este numai un sir de semne grafice, dupa cum un discurs vorbit nu e numai un sir de sunete. Pentru a urmari un text sau o cuvântare, expunere utilizam reprezentari mentale, integrând o anumita cunoastere despre lume pe care o aveam cu ceea ce ne este comunicat. Textul adesea refera entitati din lumea reala, fie ele entitati fizice, entitati conceptuale, ori evenimente. Pe masura ce discursul avanseaza, aceste entitati se transforma, îsi modifica trasaturile ori se îmbogatesc cu trasaturi noi, participa în alte evenimente, uneori dispar, apar altele noi. Un text se transforma în discurs doar atunci când cineva îl citeste sau asculta. Când acest personaj începe sa citeasca sau sa asculte, în mintea lui începe un proces de asocieri si evocari, de inferente si de constructii de entitati. Un discurs nu poate fi rupt de procesul citirii sau al ascultarii lui. Discursul trebuie asociat momentului interpretarii lui si nu poate fi confundat cu notatia lui grafica.
Coerenta unui text reprezinta acea calitate a lui de a manifesta o inter-relationare satisfacatoare între elementele lui cât si între ceea ce el comunica si ceea ce stie deja cititorul, informatia este prezentata într-un maniera si o ordine logica, acestea toate atribuindu-i un înteles, ce poate fi usor desprins.
Coeziunea unui text este proprietatea ca partile lui sa fie legate într-un mod care sa le dea calitatea de întreg.
Când un text nu este coerent? Ceea ce pare incoerent într-un anumit context, sau în lipsa unui context, poate capata înteles atunci când un context particular îi este asociat. Nu este vorba despre lipsa de înteles a propozitiilor (de genul celebrului exemplu al lui Chomsky Colourless green ideeas sleep furiously), ci de combinatii de propozitii, care desi independent pot avea sens, sa apara incoerente luate împreuna.
Un segment de discurs este o secventa de enunturi în care se vorbeste despre ceva ori cineva: lucruri, idei, evenimente, fenomene, persoane - în general entitati semantice. Într-un spatiu situational aceste entitati au fiecare câte o reprezentare semantica. În teoria centrelor (CT) [Grosz, Joshi and Weinstein, 1995] acestea sunt numite centre. Ele sunt indexate în text în general prin grupuri nominale. Dar nu oricarui grup nominal îi corespunde un centru.
Ex Politistul parasi în graba postul de observatie pentru a începe o urmarire ca-n filme
Urmatoarelor secvente lexicale le corespund centre: politistul, postul de observatie, o urmarire. Este dificil a spune daca secventelor lexicale graba si filme le sunt de asemenea atasate centre pentru ca expresia în graba este o sintagma cu valoare adverbiala (repede, grabit) iar ca-n filme este una cu valoare adjectivala (aventuroasa, palpitanta). Pentru recunoasterea secventelor cu valoare referentiala putem considera ca criteriu normalitatea de referire în text a unei entitati despre care s-a vorbit deja.
Din punct de vedere reprezentational centrele sunt structuri de caracteristici. Un fapt semnificativ este ca centrele pot fi interpretari partiale care ulterior sa capete caracterizari suplimentare.
Capul lexical (head-ul) unei expresii este acel cuvânt al constructiei care luat singur poate împlini functia întregii expresii. Intuitia în spatele notiunii de head este ca fiecare constituient sintactic contine un anumit cuvânt (numit cap lexical - lexical head) considerat a fi definitoriu pentru grup pentru ca el determina multe dintre proprietatile sintactico-morfologice ale grupului luat ca un întreg. De exemplu head-ul grupului cel mai frumos mar este mar pentru ca întregul grup preia proprietatile gen si numar de la acesta.
Grup nominal (notat NP de la noun phrase în limba engleza) este o expresie a carei head este un substantiv.
Grup verbal (notat VP) îndeplineste rolul unui verb simplu si este alcatuit din verb principal si elemente auxiliare (verbe auxiliare, adverbe, etc.) care formeaza împreuna o singura unitate sintactica si semantica. Cel mai adesea un grup verbal îndeplineste functia de predicat.
Numim anáfora o relatie de referinta, în text, între doua entitati. Vom numi cele doua elemente ale textului care participa în anafora - expresii referentiale.
"Anafora reprezinta relatia dintre un termen (numit "anafor") si un altul (numit "antecedent"), când interpretarea anaforului este într-un anumit mod determinata de interpretarea antecedentului." (Barbara Lust, introducere la Studies in the Acquisition of Anaphora, D. Reidel, 1986)
"Termenul de relatie anaforica este utilizat pentru a marca relatia dintre doua elemente din text care denota acelasi obiect" (Massimo Poesio, What is 'coreference'?)
"În majoritatea textelor obiectul aflat în discutie este mentionat de mai multe ori, iar ceea ce este nou introdus în text este legat într-un fel sau altul de ceea ce s-a discutat deja. Mentionarile ulterioare ale unei entitati pot avea sau nu aceeasi forma de suprafata. Exista o întreaga clasa de expresii, numite expresii anaforice sau expresii referentiale utilizate pentru a indica elementele aflate în corelatie. Ele mai sunt considerate si entitati lexicale." (S. Davies, M. Poessio, Coding Schemas for Co-reference, 2000)
Relatia dintre cei doi termeni ce participa la realizarea unei anafore poate fi diversa. Cea mai comuna este anafora coreferentiala, în care entitatea referita în contextul universului de discurs este aceeasi pentru ambii termeni. Asa cum vom vedea mai jos, daca însa anaforul si antecedentul refera entitati distincte, dar aflate, ele însele, într-o anumita relatie atunci avem de-a face cu o anafora functionala
Relatia dintre anafor si antecedent nu trebuie confundata cu cea dintre anafor si referentul sau. De obicei referentul este o entitate din lumea reala, în timp ce antecedentul este o forma lingvisitca.
Relatia anaforica trebuie înteleasa ca fiind amorsata de cei doi termeni lexicali dar având loc într-un plan semantic, exterior textului. În nici un caz ea nu este o relatie între elemente de text. La modul general o anafora este formata dintr-o pereche de referinte text-situatie, deci de realizari, în care antecedentul este entitatea textuala anterioara anaforului cea mai recenta ce realizeaza acelasi centru ca si anaforul:

Fig. : Triada
anafor-antecedent-centru
Într-o schema simplificatoare, ce scurt-circuiteaza traiectoria situationala, o relatie anaforica poate fi evidentiata numai la nivelul textului. O astfel de reprezentare este doar una conventionala, simplificatoare, pentru ca relatia anaforica este de natura semantica, nu textuala. O maniera de a nota o relatie anaforica este prin indici pe text, anaforul si antecedentul purtând aceiasi indici (asa cum va fi notata în exemplele din aceasta lucrare).
Anafora se clasifica în functie de forma anaforului si în functie de componenta semantica a relatiei anaforice
a) Anafora pronominala
Este cel mai întâlnit tip de anafora. Pronumele este reprezentantul numelui în enunt [Irimia, 1997]. Cel mai adesea el da forma anaforei coreferentiale, în care anaforul este un pronume iar antecedentul este realizat printr-un grup nominal.
Pronume personale:
Ex. 1: The most difficult for Dali was to tell her, between two of nervous laughter, that he loved her.
Cel mai dificil lucru pentru Dali a fost sa-i spuna, între doua râsete nervoase, ca el o iubeste )
Gilles Neret, Dali
Pronume posesive:
Ex. 2: But the best things about Dali1 are his2 roots and his1 antennae. (Dar cele mai bune lucruri la Dali sunt radacinile sale si simturile sale)
Gilles Neret, Dali
Pronume reflexive:
Ex. 3: Dali once again locked himself1 in his studio... (Dali înca o data s-a închis în studioul sau...)
Gilles Neret, Dali
Pronume demonstrative:
Ex. 4: Dali, however, used photographic precision to transcribe the images of his dreams . This1 would become one of the constraints of his work...
(Dali, în orice caz, folosea o precizie fotografica pentru a transcrie imaginile din visurile sale. Aceasta va deveni una din constrângerile operei sale...)
Gilles Neret, Dali
Spre deosebire de exemplele de pâna acum, aici antecedentul este o întreaga propozitie, mai corect - o reprezentare a evenimentului comunicat de propozitie.
Pronume relative:
Ex. 5: Dali ,a Catalan who1 was addicted to fame and gold, paited a lot and talked a lot.
(Dali, un catalan care era dependent de faima si aur, a pictat mult si a vorbit mult.
Gilles Neret, Dali
În limba engleza setul de pronume anaforice este alcatuit din toate pronumle la persoana a III-a - pronume personale, posesive, reflexive, demonstrative, relative la singular si plural. Pronumele personale la persoana I si a II-a sunt folosite într-o maniera diaclitica. Pronumele it poate fi adesea neanaforic. Identificarea automata a pleonastului it în limba engleza nu este o sarcina usoara. În urmatorul exemplu pronumele it nu specifica suficient pentru a fi considerat anaforic:
Ex. 6: It is dangerous to be beautiful - that is how women have learned shame.
(Ø este periculos sa fii frumoasa, astfel au învatat femeile ce este rusinea.)
John Updike,
b) Anafora substantivala definita
Daca anaforul este realizat printr-un grup nominal definit, avem de a face cu o anafora substantivala definita. Desi si pronumele sunt considerate expresii definite, doar grupurile nominale au înteles independent de antecedentul lor. Expresiile definite fac mai mult decât doar sa refere, ele aduc informatii aditionale.
În general, articolul hotarât atasat unui substantiv îi atribuie caracteristica semantica de identitate specifica, cunoscuta deja. Cunoasterea lui se poate datora introducerii lui în text într-un moment precedent:
Ex. 7: I bought a book1. The book2 is verry interesting.
(Am cumparat o carte. Cartea este foarte interesanta)
O expresie definita actioneaza deci si într-un sens si în celalalt: o situatie comuna este referita, iar o situatie noua primeste calificativul de comuna.
Invers, un substantiv articulat definit nu denota însa întotdeauna o referinta punctuala, spre o entitate bine precizata. Se poate spune:
Ex. 8: Take the bus. (Ia autobuzul)
desi pot exista mai multe autobuze care sa poata fi luate. Referinta este spre un obiect din clasa autobuz, fara ca acesta sa fie precizat.
c) Anafora substantivala nedefinita
Când anaforul este un grup nominal nearticulat avem de a face cu o anafora nedefinita. De cele mai multe ori un grup nominal nearticulat introduce o noua entitate în discurs (exemplu 7 în care este introdusa o entitate printr-un substantiv nearticulat referit apoi printr-un substantiv articulat). Uneori însa o anumita relatie anaforica, care nu e una de coreferentialitate, se poate stabili printr-un anafor nedefinit, ca de exemplu introducerea unei entitati de aceeasi natura ca una deja mentionata:
Ex. What beautifull house1! A house2 like this1 is hard to find. (Ce casa frumoasa! O casa ca asta e greu de gasit)
Prima mentiune house introduce aici o entitate. A doua mentiune house introduce o entitate din aceeasi clasa semantica, însa diferita de prima. Pronumele this refera prima entitate.
d) Anafora vida (elipsa)
Anaforele vide sunt anafore "invizibile" - la prima vedere nu se vad deoarece ele nu sunt reprezentate textual printr-un cuvânt sau o propozitie. Din moment ce una din proprietatile si avantajele anaforei este abilitatea de a reduce cantitatea de informatie spre a fi reprezentata printr-o forma lingvistica abreviata, elipsa este poate cea mai sofistificata varietate a anaforei. Se noteaza cu Ø.
Exista mai multe tipuri de elipse. Cea mai întâlnita este anafora vida pronomiala care are loc atunci când un pronume anaforic este omis dar este subînteles. Acest fenomen se întâlneste în limba engleza în împrejurari foarte restrânse, dar este comun în alte limbi cum ar fi româna, spaniola, italiana, poloneza, portugheza, japoneza.
Ex. 10 Zero pronomial anaphora occurs when the anaphoric pronoun is omitted but Ø is nevertheless understood.
(Elipsa se produce când pronumele anaforic este omis, dar Ø totusi este înteles)
Ruslan Mitkov,Anaphora Resolution
În a treia propozitie se astepta but it is nevertheless understood
Alt tip de elipsa este elipsa textuala (numita si anafora functionala :
Ex. 11: Starea acumulatorului îi este indicata utilizatorului. Înainte cu 30 minute de descarcarea completa, calculatorul semnalizeaza pentru 5 secunde.
Strube & Hahn, 1996
Descarcarea completa este o prescurtare pentru descarcarea completa a acumulatorului. Între [descarcarea acumulatorului] si [acumulator], entitatile referite de anafor si antecedent, respectiv, exista o relatie de proprietate: un acumulator are proprietatea de a se descarca, dupa cum are proprietatea de a se încarca.
e) Anafora propozitionala
Anafora propozitionala este anafora pentru care anaforul este o propozitie În exemplul 12 this refera o situatie a carei realizare lexicala este o întreaga propozitie, (Dali, however, used photographic precision to transcribe the images of his dreams) La nivelul situational trebuie gasita o reprezentare a evenimentului descris de fraza.
Ex. 12: Dali, however, used photographic precision to transcribe the images of his dreams . This1 would become one of the constraints of his work...
(Dali, în orice caz, folosea o precizie fotografica pentru a transcrie imaginile din visurile sale. Aceasta va deveni una din constrângerile operei sale...)
Gilles Neret, Dali
a) Coreferinta
Cea mai simpla relatie anaforica este aceea în care atât anaforul cât si antecedentul realizeaza direct acelasi centru. Relatia este în acest caz numita coreferinta.
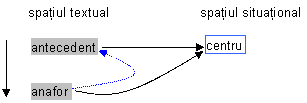
Fig. 2: Relatia anaforica coreferentiala
Ex.13 The most difficult for Dali1 was to tell her, between two of nervous laughter, that he loved her. (Cel mai dificil lucru pentru Dali a fost sa-i spuna, între doua râsete nervoase, ca el o iubeste
Gilles Neret, Dali
Uneori relatia de coreferinta se multiplica în lungul unui text, formând lanturi coreferentiale prin care traseele unor personaje, obiecte, situatii, pot fi urmarite înapoi pâna la prima lor aparitie.
Relatia de coreferinta este simetrica (daca A corefera cu B, atunci B corefera cu A) si tranzitiva (daca A corefera cu B si B corefera cu C, atunci A corefera cu C). Aceste proprietati induc un set de clase de echivalenta în multimea expresiilor referentiale.
b) Anafora functionala
Anaforele functionale sunt cunoscute de asemenea si ca anafore text ([Udo & Strube, 1986]), sau anafore ori referinte de legatura (bridging references - [Clark & Haviland, 1974]). Pentru acest tip de anafora nu exista o relatie de identitate între anafor si antecedent, ci una functionala. Relatia exista aici între expresia anaforica si o expresie antecedent astfel încât una dintre ele este un rol al celeilalte.
Relatia functionala partitiva
Aceasta relatie se stabileste între un anafor al carui centru reprezinta o parte componenta a centrului corespunzator antecedentului:
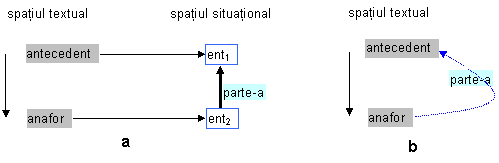
Fig. : Relatie anaforica functionala partitiva
a. reprezentare completa;
b. reprezentare simplificata
Ex. A reserve battery pack supplies the 316LT with power for approximately 2 hours. The status of the accumulator is indicated to the user.
(Un pachet de baterii de rezerva alimenteaza 316LT-ul cu putere pentru aproximativ 2 ore. Starea acumulatorului este indicat utilizatorului.)
Strube&Hahn, 1996
The accumulator trebuie sa fie recunoscut ca parte a lui 316LT (un calculator) mentionat în propozitia precedenta.
Relatia proprietar - obiect posedat
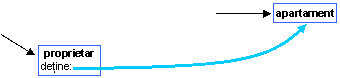 Ex.
4: I have moved in a new flat.
Ex.
4: I have moved in a new flat.
The owner asked me 300.000 per mounth.
Aici [the owner] (proprietarul) poseda [a new flat] (apartamentul nou).
Referinte în care intervin multimi
Ex. 5 Vorbind de-a lor iubire - iubire fara sat -
Ea se lasase dulce si greu pe al lui brat
Eminescu, Strigoii
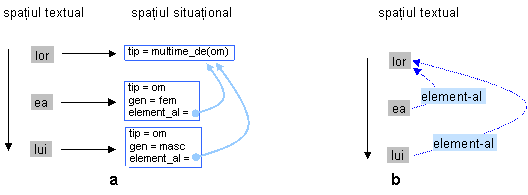
Fig 4: Relatii element - multime.
a: reprezentare completa, b: simplificata
Lingvistii numesc relatia referentiala în care elementul aratator precede elementul referit (de exemplu, pronumele precede entitatea lexicala pe care acesta o refera) - catáfora
Ex.15: When he1 became president, George Bush1 renewed his appeal for a "kinder, gentler nation." (Când el a devenit presedinte, George Bush a înnoit apelul la "natiune nobila si prietenoasa")
(Compton's Interactive Encyclopedia, 1995)
Într-un limbaj care scurt-circuiteaza planul reprezentational, într-o viziune traditionala, ponumele he este o catafora la George Bush. Interpretarea incrementala a acestui text este însa una în care construim întâi o reprezentare pentru he, pentru ca mai apoi George Bush sa completeze cu informatii entitatea corespunzatoare. O astfel de distinctie pozitionala, ca cea pusa în evidenta în definitia cataforei, devine inutila într-o viziune care încearca sa reconstituie procesele cognitive ce stau la baza întelegerii textelor, pentru a crea pe baza lor modele interpretative computationale. Discursul este imposibil de detasat de momentul lecturii lui. Acest lucru atribuie discursului întotdeauna o unica directionalitate, care corespunde axei timpului lecturii, si care este cea a desfasurarii liniare a textului, de la stânga la dreapta (ori de la dreapta la stânga pentru limbile semitice). Relatia de referentialitate trebuie deci sa se proiecteze pe aceasta axa, dinspre entitati "noi" catre entitati "vechi", deci de la dreapta spre stânga (stânga spre dreapta în cazul limbilor semitice), mereu catre înapoi pe axa timpului lecturii. Acesta este motivul pentru care referintele înspre înainte nu sunt posibile, si deci catafora nu exista.
Entitatile din spatiul situational nu sunt constante în lungimea discursului. Doua axe temporale pot fi evidentiate, fara a fi evident pe care ar trebui sa ne situam: prima este axa timpului istorisirii, care este timpul real al istoriei relatate. În acest timp, entitatile despre care se povesteste îmbatrânesc, si deci nu mai sunt aceleasi. Cealalta axa este cea a reprezentarilor create în mintea cititorului de povestea în sine, pentru ca despre o entitatea la mijlocul povestirii stim mai multe decât despre aceeasi entitate la începutul povestirii. Cele doua ipostaze ale aceluiasi personaj sunt diferite deci si pentru ca unul e mai batrân decât celalalt în viata relatata, dar si pentru ca unul e mai bogat decât celalalt în reprezentarile mintale pe care le avem despre el. Din aceste motive relatia de coreferinta este si ea numai o abstractizare, o simplificare, adoptata ori de câte ori din diferite motive pot fi lasate la o parte amanunte temporale asupra entitatilor asupra carora se opereaza. Atunci când, însa, modificarile sunt dramatice, se folosesc în reprezentare indícii care sa evidentieze masura inconstantei entitatilor reprezentate.
Ex.16: Maria1 was dreaming. The girl1 had just finished high-school and was engaged to be married. She imagined her wedding night in the arms of her beloved and imagined herself as his loving and caring wife1. He would have made her a woman1, and a mother1, and they would have grown old together in peace and happiness.
(Maria visa. Fata abia terminase liceul si se logodise. Ea îsi imagina noaptea nuntii în bratele iubitului ei si se imagina fiind o sotie buna si iubitoare. El ar fi transformat-o în femeie si mama si ei ar fi îmbatrânit împreuna în pace si fericire.
Maria este referita printr-o serie de substantive girl, wife, woman, mother), care descriu progresul, schimbarea suferite de entitatea respectiva. Pentru a marca aceste schimbari si pentru a memora informatiile relative aduse ar putea fi utilizata o notatie diferita (pe nivelul semantic) între începutul lantului anaforic si fiecare anafor.
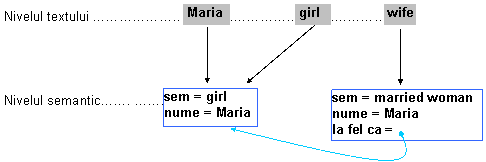
Fig : Reprezentarea entitatilor variabile în timp
Rezolutia anaforei este procesul de determinare a antecedentului unui anafor.
Consideram urmatoarele exemple:
The Queen is not here yet but she2 is expected to arrive in the next half on hour.
(Regina nu este înca aici, dar ea este asteptata sa ajunga în urmatoarea jumatate de ora)
Huddleston, 1984
Pronumele she este un anafor, iar the Queen este antecedentul si ele sunt coreferentiale. Se observa ca antecedentul nu este un substantiv ci un grup nominal (NP).
Stephanie balked, as did Mike. (Stephanie a ezitat, ca si Mike)
Ian MacMillan, Ligth and Power Stories
În aceasta propozitie vebul did este anafor si este un substituient pentru antecedentul balked totusi pentru ca cei doi temeni nu au un referent comun, nu este vorba despre o relatie de coreferinta între cei doi termeni.
Picatura gaureste piatra nu prin forta, ci prin continua ei cadere.(Ovidius)
Acest capitol prezinta sursele de cunoastere necesare pentru rezolutia automata a anaforei si explica ce unelte si resurse sunt nesecare. Este acordata o atentie speciala factorilor ce stau la baza algoritmilor pentru rezolutia anaforei. În continuare sunt descrise succint cele mai semnificative proiecte legate de rezolutia anforei din perioada 1960 - 1980. Urmeaza principale tendinte în cercetarea actuala în domeniul rezolutiei anaforei si modalitatea de evaluare a algoritmilor pentru rezolutia anaforei.
Rezolutia anaforei este o problema provocatoare si necesita o cantitate mare de cunostinte ca suport - de la informatii morfologice si lexicale (la un nivel de jos) la informatii semantice si reguli pragmatice (la un nivel superior).
Cunoastere morfologica si lexicala
Informatiile morfologice si lexicale sunt necesare nu doar pentru identificarea anaforelor pronomiale, ci si pentru prelucrari sintactice ulterioare. Exista anafore care sunt rezolvate doar pe baza informatiilor lexicale cum ar fi genul sau numarul. Faptul ca anaforele nominale (de fapt head-ul) au acelasi numar si gen cu antecedentii este câteodata suficient pentru a alege un singur NP candidat, ca în exemplul:
Ex1: Green1 had no letters from Catherine while în Switzerland and he1 feared the silence. (Green nu are nici o scrisoare de la Catherine din Switzerland si lui îi este frica de liniste.)
Norman Sherry, The Life of Graham Green
Conform unei reguli de potrivire în numar si gen, NP-ul Greene este selectat ca un antecedent al anaforului pronomial he, întru cât ceilalti candidati posibili (Switzerland, Catherine si letters) sunt eliminati pentru ca nu se potrivesc în numar si gen.
Potrivirea în gen este un criteriu util pentru limba engleza când candidatul anaforului este un nume propriu feminin sau masculin, un substantiv ce refera oameni (man, woman, father, mother, son, etc), substantive reprezentând profesii ca nu pot fi referite prin pronumele it, etc. De asemenea acordul în numar ajuta la filtrarea candidatilor. Este luat în considerare numarul entitatii de discurs asociate fiecarui candidat si nu numarul head-ului NP-ului. Antecedentii coordonati (de exemplu John and Mary) sunt referiti prin pronume la plural, în timp ce substantivele colective (commitee, army, team) pot fi referite atât prin pronume la singular (it) cât si prin pronume la plural (they). În unele limbi pluralul pronumelor marcheaza si genul (exemplu în limba româna: ei, ele
Cunoastere sintactica
Cunoasterea sintactica este mai importanta decât cea morfologica si lexicala. Astfel în exemplul 1 Greene no letters, Switzerland si Catherine sunt indentificate ca fiind grupuri nominale.
Sintaxa este indispensabila pentru rezolutia anaforei. Pe lânga rolul important în delimitarea propozitiilor, frazelor si a altor constructii, sintaxa are un rol în formularea unor reguli folosite în procesul de rezolutie a anforei. O regula simpla ar fi ca un pronume este coreferential cu grupul nominal subiect al aceleiasi propozitii sau fraze doar daca este reflexiv. Aceasta regula, bazata pe informatii sintactice despre limitele propozitiilor si frazelor si despre functia sintactica a fiecarui cuvânt, gaseste, de exemplu ca John este anatecedent pentru him în exemplul:
Ex2: Jim1 is running the business for him1. (Jim îsi conduce singur afacerea.)
O alta constrângere sintactica interzice ca un pronume dintr-o propozitie principala sa refere un grup nominal aflat într-o propozitie secundara urmatoare.
Ex3: Because Amanda1 had saved hard, she1 was finally able to buy the car of her dreams.
(Pentru ca Amanda a economisit din greu, ea în sfârsit si-a putut cumpara masina visurilor ei.)
Ex4: She1 was finally able to buy the car of her dreams, because Amanda2 had saved hard.
(Ea, în sfârsit, a putut sa-si cumpere masina visurilor ei, pentru ca Amanda a economisit din greu.)
În exemplul 3 Amanda si she sunt coreferentiale, dar în exemplul 4 conform constrângerii de mai sus nu.
Pentru a putea aplica aceasta regula, un program pentru rezolutia anforei trebuie sa aiba acces la informatii detaliate despre structura frazelor, tipul propozitiilor (principale sau subordonate).
Cunoastere semantica
Oricât de importante ar fi informatiile lexicale, morfologice si sintactice, în multe cazuri, ele singure nu pot ajuta la gasirea antecedentilor. Fie exemplul:
Ex5: The petrified kitten1 refused to come down from the tree. It1 gazed beseechingly at the onlookers below. (Pisicuta împietrita refuza sa coboare din copac. Ø se uita implorând la spectatorii de dedesubt.)
Folosind reguli de acord nu se pot elimina nici the petrified kitten, nici the tree ca potential antecedent, pentru ca ambii au genul neutru. Ar fi necesara o restrictie bazata pe faptul ca verbul to gaze (a privi lung) necesita ca agent o fiinta (un lucru animat). Faptul ca kitten (pisicuta) este o fiinta este o informatie vitala. Într-un sistem de rezolutie automata a anaforei aceste informatii sunt memorate într-o baza de cunostinte, de obicei un dictionar sau o ontologie.
În multe cazuri interpretarea corecta a anaforelor depinde de abilitatea sistemului de a folosi informatia semantica pentru identificarea entitatilor de discurs asociate cu antecedentul.
Fie exemplul:
Ex6: Mary bought several shirts1 at the shop. They1 cost £20.
(Mary a cumparat cateva tricouri din magazin. Ele au costat 20£)
Pentru ca un sistem NLU sa "înteleaga" acest exemplu, nu este suficient ca sistemul sa gaseasca grupul nominal several shirts ca antecedent al pronumelui they ci sa identifice entitatea de discurs asociata (setul de tricouri cumparat de Mary de la magazin). Aceasta descriere nu poate fi obtinuta sintactic si ar trebui gasita automat din logica propozitiei.
În acest fel rezolutia anaforei poate fi privita ca un proces de substitutie: anaforul este înlocuit de o descriere semantica mult mai complexa ce permite interpretarea grupului nominal în fazele urmatoare de procesare semantica ([Grishman, 1986]). Aceasta substitutie ar trebui sa aiba loc dupa analiza semantica, si nu dupa parsare.
Un algoritm de rezolutie a anaforei aplicat dupa analiza semantica a textului ar conduce la rezultate mai bune decât un algoritm aplicat dupa analiza sintactica a textului. Totusi, majoritatea sistemelor de rezolutie a anaforei, în special cele care lucreaza cu baze de cunostinte reduse, nu au modalitati de a realiza analize semantice (sau de alt tip). Prin urmare aceste sisteme nu încearca sa determine entitatile de discurs, ci lucreaza cu constituenti de suprafata (grupuri nominale) iar strategiile de determinare a anaforelor sunt bazate pe iesirea unui parser sintactic (partial sau complet).
Cunoasterea semantica este în mod special importanta pentru interpretarea anaforei indirecte. O strategie semantica clasica este cautarea conflictelor dintre descrierile semantice asociate anaforului si candidatului. Este conflict între cele doua grupuri nominale daca nu sunt într-o relatie de sinonimie, generalizare, specializare sau o relatie de tipul membru - multime. De asemenea este conflict daca modificatorii celor doua grupuri nominale nu sunt compatibili (de exemplu the first primul si the second - al doilea). Aceasta strategie am încercat sa o aplic în algoritmul meu de rezolutie a anaforei.
Cunoastere despre stuctura discursului
Desi criteriile morfologice, lexicale, sintactice si semantice pentru selectia antecedentului unui anafor sunt puternice, ele nu sunt întotdeauna suficente pentru a determina antecedentul din setul de candidati posibili. Mai mult aceste criterii sunt mai degraba niste filtre pentru a elimina candidati nepotriviti. În cazul unei ambiguitati în alegerea antecedentului, de obicei, este ales candidatul cel mai semnificativ. În lingvistica computationala el este numit focus ( focus - [Groz, 1977], [Sidner, 1979]) sau centru (center - [Groz et al, 1983],[ Joshi si Weinstein, 1981]).
În exemplul urmator, nici oamenii, nici calculatorarele nu vor putea interpreta anaforul pronomial it
Ex7: Tilly tried on the dress over her skirt and ripped it.
(Tilly a probat rochia peste camasa ei si ea s-a rupt.)
Daca propozitia ar face parte dintr-un segment de discurs, lucru care ar permite determinarea celui mai semnificativ element, atunci situatia ar fi diferita:
Ex8: Tilly's mother had agree to make her a new dress for the party. She worked hard on the dress for weeks and finally it was ready for Tilly to try on. Impatiet to see what it would look like, Tilly tried on the dress over her skirt and ripped it.
(Mama lui Tilly a fost de acord sa-i faca o rochie pentru petrecere. Ea a lucrat din greu la rochie saptamâni întregi si în final era gata ca Tilly sa o probeze. Grabita sa vada cu îi sta, Tilly a probat rochia peste camasa ei si ea s-a rupt)
În acest segment de discurs, the dress este entitatea cea mai semnificativa si este în centrul atentiei pe parcursul segmentului. Teoria centrelor sau a focusului se bazeaza pe faptul intuitiv ca un discurs este de obiecei structurat în jurul unui subiect central. Mai mult, de obicei, elementul central al unei propozitii sau fraze este reluat folosind un pronume. Aceste ipoteze influenteaza interpretarea pronumelor deoarece odata stabilit elementul central, exista o probabilitate mare ca pronumele urmatoare sa refere acest element.
Când exista doi sau mai multi candidati pentru rolul de antecedent, sarcina de a determina antecedentul poate fi redusa la gasirea centrului / focusului propozitiei sau frazei.
Cunoastere din lumea reala
Rezolutia anaforei ofera o ilustrare a complexitatii întelegerii limbajului natural. Un sistem de rezolutie automata a anaforei ce are doar informatii morfologice, lexicale, sintactice si semantice, probabil ca nu va reusi sa determine corect anafora din exemplul:
Ex9: The soldiers shot at the women1 and they1 fell.
(Soldatii au împuscat femeile si ele/ei au cazut)
Gasirea corecta a antecedentului în acest exemplu este posibila doar daca sistemul are la dispozitie o cunoastere suplimentara, de exemplu sub forma unor reguli:
Regula 1: Daca X împusca pe Y si daca Z (Z ) cade, atunci este mai probabil ca Z sa fie Y.
Regula 2: Daca X împusca pe Y si daca Z (Z ) rateaza, atunci este mai probabil ca Z sa fie X.
Multe exemple de anafore din viata reala necesita cunostinte din lumea reala pentru rezolvarea lor. Integrarea unor astfel de cunostinte într-un sistem practic de rezolutie a anaforei este foarte dificila si este o sarcina consumatoare de timp. Marea majoritate a sistemelor pur si simplu nu au acces la asemenea informatii extra-lingvistice.
Rezolutia automata a anaforei presupune urmatoarele etape:
Identificarea anaforilor;
Gasirea candidatilor;
Selectia antecedentului dintr-o multime de candidati pe baza factorilor de rezolutie a anaforei.
Identificarea anaforilor
Primul pas în procesul de determinare automata a anaforelor este identificarea anaforilor ai caror antecedenti trebuie gasiti. Identificarea automata a acestora, cel putin pentru limba engleza, nu este o sarcina usoara. De exemplu aparitiile neanaforice ale pronumelui it Ex. 1) trebuie recunoscute de program.
Ex. 1: It must be stated that Oskar behaved impeccably.(Ø ar trebui declarat ca Oskar s-a comportat impecabil)
Thomas Keneallz, Schindler's List
În acest caz pronumele it este pleonastic. Exista câtiva algoritmi pentru identificarea acestui tip de pronume. Algoritmul lui Lappin si Leass considera pronumele it pleonastic daca apare într-o constructie de forma:
It is Adjectiv_modal] that [S]
It is Adjectiv_modal] (for [NP]) to [VP]
It is [verb_cognitiv]-ed that [S]
Algoritmul lui Denber's este o varianta a algoritmului lui Lappin si Leass. si acest algoritm este bazat pe folosirea unor sabloane simple. Cei mai detaliati algoritmi pentru identificarea pronumelor pleonastice sunt algoritmul [Paice si Husk, 1987] si algoritmul [Evans, 2000, 2001].
Gasirea grupurilor nominale anaforice este si mai dificila. Este important pentru un program de rezolutie a anaforei sa fie capabil sa identifice grupurile nominale neanaforice. Algoritmul [Bean si Riloff, 1999] generaza (dintr-un text) o lista de grupuri nominale neanaforice si sabloane de grupuri nominale pe care le foloseste mai departe pentru a recunoaste grupurile nominale neanaforice din alte texte. Acest algoritm are un procent de recall de 77,7% si o precizie de 86,6%. Algoritmul lui Vieira si Poesio (2000b) pentru identificarea grupurilor nominale neanaforice se bazeaza pe lucrarea lui Hawkins (1978) care a identificat o serie de corelatii între diferite tipuri de structuri sintactice si aparitia unei entitati noi de discurs. Are un recall de 69% si o precizie de 72%. Algoritmul lui Munoz (2001) prepune clasificarea grupurilor nominale în anaforice si neanaforice folosind reteaua semantica generata de WordNet.
Gasirea candidatilor
Majoritatea sistemelor se ocupa de anafora nominala deoarece rezolutia anaforelor a caror antecedenti sunt grupuri verbale, propozitii sau fraze este foarte dificila. De obicei aceste sisteme considera candidati toate grupurile nominale ce preceda anaforul într-un anumit domeniu de cautare.
Domeniul cautarii candidatilor difera în functie de modelul de procesare adoptat si în functie de tipul anaforului. Pentru ca majoritatea relatiile anaforice sunt în interiorul unui segment de discurs, domeniul de cautare este considerat segmenul de discurs ce contine anaforul ([Kennedy & Bogureav, 1996]). Sistemele de rezolutie a anaforei pronomiale care nu au instrumente de determinare a granitelor segmentelor de discurs considera, de obicei, domeniul de cautare propozitia curenta si doua - trei propozitii anterioare ([Mitkov 1998b]). Grupurile nominale definite pot referi entitati aflate la distante mai mari în text, si de aceea domeniul de cautare pentru acest tip de anafore este mai mare ([Kamayama 1997] - 10 propozitii). Aceste abordari de cautare a candidatilor sunt considerate lineare. Exista si modele de cautare ierarhice cum ar fi modelul bazat pe teoria nervurilor [Cristea et al. 1998, 2000] care considera candidati grupurile nominale din segmentul curent si din segmentul precedent ierarhic. Identificarea automata a segmentelor (necesare teoriei nervurilor) este dificila.
Selectia candidatului
Odata identificati anaforul si candidatii, programul va încerca sa determine anatecedentul din setul de candidati. Algoritmul de rezolutia a anaforei utilizeaza reguli bazate pe diferite surse de cunoastere. Acordul în numar si gen, restrictiile semantice, paralelismul sintactic si semantic sunt câteva din cele mai utilizate reguli. Unele reguli pot elimina diferite grupuri nominale din multimea de candidati posibili (constrângeri bazate pe acordul în gen sau numar) - reguli eliminatoare. Alte reguli specifica ca unii candidati au mai multe sanse sa fie antecedentul cautat decât alti candidati (reguli bazate pe focus, paralelism) - reguli cu scor. Mai exista si reguli confirmatoare, care gasesc antecedentul.
Aceste reguli lucreaza împreuna pentru identificarea antecedentului. Aplicarea unei singure reguli (eliminatoare, confirmatoare sau cu scor) nu conduce la gasirea antecedentului. Regulile interactionaza între ele ducând fie la îmbunatatirea fie la scaderea performantei algoritmului. Acest fenomen de dependenta nu a fost înca complet investigat, dar poate juca un rol important în procesul de rezolutie a anforei. Informatii despre gradul de dependenta sunt în special utile modelelor probabilistice si se spera sa ajute la îmbunatatirea rezultatelor.
Pentru alegerea antecedentului din setul de candidati sunt necesare diferite unelte si resurse: dictionare, analizatoare morfologice, marcatoare pentru partea de vorbire. O problema specifica limbii engleze este identificarea genului substantivelor (unele substantive au genul masculin sau feminin sau si feminin si masculin - pot aparea erori în interpretarea anaforei). Identificarea entitatilor animate ar putea ajuta la depistarea genului semantic. [Denber, 1998] si [Cardie & Wagstaff 1999] folosesc în acest sens WordNet-ul. [Evans & Orasan 2000] propun folosirea unui FDG - parser gramatical superficial, WordNet-ul si un set mic de reguli pentru identificarea entitatilor animate în limba engleza. Lucrarea lor arata ca recunoasterea entitatilor animate contribuie la marirea performantelor în rezolutia anaforei.
Informatiile semnatice pot fi oferite de WordNet, o ontologie folosita mult de cercetatorii NLP. WordNet-ul ofera o serie de relatii semantice (între cuvinte) cum ar fi sinonimia, antonimia, hipernimia (relatie de tipul "este un/o"), hiponimie, meronimie (relatie de tipul "parte - întreg"), familiaritate (rar, neobisnuit, obisnuit).
Evaluarea este esentiala pentru progresul în cercetare si pentru dezvoltare. Ea este esentiala pentru oricare sistem de prelucrare a limbajului. Evaluarea ofera o modalitate de apreciere a performantei individuale a unui sistem si de comparare cu alte aplicatii. Un sistem este evaluat prin supunerea sa la o proba practica, astfel ca acea proba sa poata fi folosita pentru a masura obiectiv performantele sistemului în raport cu performantele altui sistem. Este necesara diferentierea dintre evaluarea unui algoritm si evaluarea unui sistem pentru rezolutia anaforei. Prin sistem pentru rezolutia anaforei se întelege un sistem implementat complet care proceseaza un text de intrare pe mai multe nivele: morfologic, sintactic, semantic, al discursului si alimenteaza cu text procesat algoritmul pentru rezolutia anaforei.
O modalitate naturala de testare a unui algoritm de rezolutie a anaforei este rularea lui într-un mediu ideal fara a tine cont de erorile sau complicatiile posibile ce pot apare la diferite nivele de pre-procesare a textului. Când este evaluat un sistem de rezolutie a anaforei, apar scaderi în performanta datorate imposibilitatii analizarii limbajului natural cu acuratete absoluta. Un numar de sisteme pentru rezolutia anaforei lucreaza cu texte de intrare controlate de oameni (textul este pre-procesat manual sau este corectata adnotarea) sau sunt simulate manual, ceea ce sugereaza ca evaluarea raportata este de fapt a algoritmului de rezolutie. Pe de alta parte sunt sisteme care proceseaza complet textul înainte de a fi prelucrat de algoritmul de rezolutie a anaforei si evaluarea lor este a întregului sistem. Este preferabil ca evaluarea algoritmului de rezolutie a anaforei sa fie facuta alaturi de evaluarea sistemului din care face parte. Este posibil ca un sistem cu rezultate slabe sa fie bazat pe un algoritm eficient de rezolutie a anaforei.
3.1. Masuri utilizate pentru evaluarea în rezolutia anaforei
MUC (Message Understanding Conferences) a introdus pentru rezolutia coreferintei urmatoarele masuri: recall si precizia. Aceste masuri au fost adoptate de un numar mare de cercetatori în evaluarea algoritmilor sau sistemelor pentru rezolutia anaforei.
Exista mai multe definitii ale acestor masuri:
q [Aone & Bennett, 1995]:
|
Recall = |
Numarul de anafore rezolvate corect |
|
Numarul de anafore identificate de program |
|
|
Precizia = |
Numarul de anafore rezolvate corect |
|
Numarul de anafore propuse spre rezolvare |
q [Baldwin, 1997]:
|
Recall = |
Numarul de anafore rezolvate corect |
|
Numarul total de anafore |
|
|
Precizia = |
Numarul de anafore rezolvate corect |
|
Numarul de anafore propuse spre rezolvare |
Definitia preciziei este aceeasi, însa definitia lui Aone si al lui Bennett a recall-ului include doar anaforele identificate de program, si nu toate anaforele, împiedicând ca aceasta masura sa fie un indicator bun al succesului. Programul ar putea identifica numai un numar anume de anafore care sunt usor de rezolvat si recall-ul obtinut nu ar oferi o imagine realista a performantei. Mai mult, pentru algoritmi robusti, care propun un antecedent întotdeauna, definitia lui Aone nu ar face nici o diferenta între recall si precizie pentru ca numarul de anafore identificate de program ar fi egal cu numarul de anafore propuse spre rezolvare.
În definitia preciziei numarul de anafore propuse spre rezolvare face posibil ca anumiti algoritmi care lasa nerezolvate anumite pronume (de exemplu cele care nu pot fi rezolvate de programul respectiv), sistemele care rezolva doar pronumele cu un singur candidat sa obtina incorect precizie mare.
Mitkov propune pentru masurarea performantelor unui algoritm urmatoarele masuri: rata de succes (success rate), rata de succes critic (critical success rate) si rata de succes netrivial (non-trivial success rate).
Definitia ratei de succes pentru un algoritm de rezolutie a anaforei este:
|
Rata de succes = |
Numarul de anafore rezolvate corect |
|
Numarul total de anafore |
Rata de succes pune accent pe performanta algoritmului si nu a altor module de pre-procesare, va fi obtinuta o valoare corecta daca textul de intrare este adnotat manual sau este corectat.
Rata de succes netrivial se aplica doar pentru anaforele care au mai mult de un candidat pentru alegerea antecedentului, eliminându-le pe acelea precedate de un singur grup nominal în domeniul de cautare al algoritmului (prin urmare având un singur candidat) pentru ca rezolvarea lor ar fi triviala.
Rata de succes critic se aplica doar acelor anafore dificile care au mai mult de un candidat dupa filtrarea candidatilor dupa gen si numar. Aceasta masura este un indicator bun care descopera greselile generate de o evaluare care foloseste date ce contin doar anafore usor de rezolvat. Daca N este multimea de anafore împlicate întro evaluare, S multimea de anafore rezolvate corect, K multimea de anafore care au avut un singur candidat (si care au fost rezolvate corect într-un mod trivial), M multimea de anafore care au fost rezolvate pe baza acordului în gen si numar si n = |N|, s = |S|, k = |K|, si m = |M|. În mod evident s ≤ n, k ≤ s, k+m ≤ s, k ≥ 0, m ≥ 0, s ≥ 0.
Are loc urmatoarea relatie:
rata de succes ≥ rata de succes netrivial ≥ rata de succes critic
![]() pentru ca:
pentru ca:
q rata de succes = s / n,
q rata de succes netrivial = (s - k) / (n - k) =>
q rata de succes critic = (s - k - m) / (n - k - m)
|
s |
s - k |
s - k - m |
, k ≥ 0, m ≥ 0, s ≥ 0 |
||
|
n |
n - k |
n - k - m |
Rata de succes critic este un criteriu important pentru evaluarea eficientei factorilor utilizati în algoritmi de rezolutie a anaforei pentru cazurile critice când acordul în gen si numar nu sunt suficiente.
3.2. Evaluare comparativa
Performanta unui algoritm poate fi evaluata prin compararea cu algoritmi si modele reprezentative, indicând locul algoritmului respectiv în evolutia rezolutie anaforei.
Sunt prezentate trei clase de evaluari comparative:
q evaluare prin comparare cu modele de baza - acest tip de evaluare justifica utilitatea algoritmului dezvoltat.
Oricât de mare ar fi rata de succes, nu merita dezvoltarea algoritmului decât daca îti demonstreaza clar superioritatea fata de un model de baza
q evaluare prin comparare cu algoritmi care folosesc aceeasi "filozofie" - ajuta la descoperirea noutatilor aduse de algoritm în domeniul respectiv
q evaluare prin comparare cu un algoritm bine cotat / punct de referinta în domeniu - algoritmul lui Hobbs si algoritmul BFP (al lui Brennan) sunt de obicei folosite pentru acest tip de evaluare de multi cercetatori.
Este totusi dificila compararea directa între doi algoritmi de rezolutie a anforei folosind oricare din aceste trei metode. Chiar daca evaluarea este realizata pentru acelasi set de date, uneltele de pre-procesare utilizate de sistemele de rezolutie introduc suficienta variatie sau erori ce pot afecta procesul de comparare.
3.3 Evaluarea separata a componentelor unui algoritm de rezolutie a anaforei
Evaluarea separata a performantei componentelor unui algoritm pentru rezolutia anaforei este importanta pentru îmbunatatirea ulterioara. Evaluarea fiecarui factor inclus în algoritmul de rezolutie ne ofera o idee despre importanta sau contributia sa, permitând îmbunatatirea ulterioara a scorurilor asociate factorilor.
Puterea de decizie a unui factor (DPk) este masura influentei fiecarui factor în luarea deciziei:
|
DPk = |
Sk |
|
Ak |
unde Sk = nr. de cazuri în care candidatul, pentru care factorul k a fost aplicat, a fost ales ca antecedent , Ak = numarul de aplicari ale factorului.
Pentru factorii folositi pentru eliminarea candidatilor puterea de decizie se calcureaza astfel:
|
DPk = |
NonSk |
|
Ak |
unde NonSk = nr. de cazuri în care candidatul pentru care factorul k a fost aplicat si care nu a fost ales ca antecedent , Ak = numarul de aplicari ale factorului.
Importanta relativa arata cât de importanta este prezenta unui factor. Pentru un factor k ea este definita astfel:
|
RIk = |
SR - SR-k |
|
SR |
unde SR = rata de succes a tuturor factorilor, SR-k = rata de succes a tuturor factorilor mai putin factorul k. Aceasta marime exprima contributia relativa a unui factor, si cât de mult din performata se pierde daca factorul este eliminat.
3.4. Evaluarea unui sistem de rezolutie a anaforei
Rata de succes pentru un sistem de rezolutie a anforei este definita similar cu rate de succes a unui algoritm de rezolutie a anforei. Ea exprima, pe lânga rata de succes a algoritmului implementat, performanta globala a sistemului, performanta care este influentata de calitatea pre-procesarii. Determinarea corecta a grupurilor nominale, care vor deveni candidati, este o parte foarte importanta a pre-procesarii.
Rata de succes a unui sistem de rezolutie a anaforei se defineste astfel:
|
Rata de succes sistem = |
Numarul de anafore rezolvate corect |
|
Numarul total de anafore |
unde, numarul total de anafore este numarul de anafore din textul de evaluare care ar fi identificate de oameni. Aceasta definitie presupune ca identificarea anaforilor este responsabilitatea sistemului. Cum pre-procesarea se presupune a fi realizata automat, este probabil ca sistemul sa omita câtiva anafori sau candidati, fapt care duce la scaderea ratei de succes. Se recomanda si determinarea ratei de succes a algoritmului implementat de sistem prin rularea lui pe un text de intrare perfect pre-procesat, pentru a vedea limitele algoritmului.
[Mitkov, Evans & Orasan, 2001] considera ca aceasta definire a ratei de succes nu tine cont de cazurile în care programul încearca sa rezolve incorect anafore ne-nominale. Pentru programele de rezolutie a anaforei nominale, este importanta determinarea eficientei programului în eliminarea instantelor de anafora ne-nominala. Aceasta marime, numita eticheta rezolutiei (resolition etiquette) este definata astfel:
|
Eticheta rezolutiei sistem = |
A' + B' |
|
A + B |
unde A' = numarul de anafore nominale corect rezolvate; B' = numarul de pronume, descrieri definite sau nume proprii care sunt filtrare corect ca instante de anafore ne-nominale; A = numarul total de anafore nominale; B = numarul total de pronume, descrieri definite sau nume proprii. Aceasta marime exprima contributia modulelor de recunoastere a pronumelor ne-nominale si pleonastice si a modulului de rezolutie la performanta sistemului.
Pentru un sistem de rezolutie a anaforei pot fi determinate rata de succes netrivial si rata de succes critic, însa nu sunt indicate pentru ca sunt caracteristice evaluarii algoritmilor.
Fiabilitatea rezultatelor evaluarii
Majoritatea sitemelor pentru rezolutia anaforei raporteaza rezultate la teste de un singur tip. În plus calitatea evaluarii depinde de dimensiunea, semnificatia statisitica si de cât de reprezentativ este textul de intrare folosit. Rezultatele sunt mai semnificative daca textele folosite pentru evaluare sunt mari continând mii de anafore. Teoretic, rata de succes sau alta masura de evaluare este corect determinata doar daca testarea se face pe toate textele posibile, lucru imposibil de realizat. Aceasta afirmatie subliniaza importanta evaluarii automate. Evaluarea automata presupune un text mare adnotat la coreferinta, în raport cu care va fi comparat textul obtinut prin rularea sistemului de rezolutie a anforei.
O metoda alternativa este selectarea la întâmplare (random) a propozitiilor folosite la testare, în speranta ca astfel se vor obtine rezultate mai semnificative.
Cât de realiste sunt rezultatele obtinute în urma evaluarii depinde si de natura textelor folosite: daca textele contin anafore greu de rezolvat, anafore care au un numar mare de posibili candidati, anafore care au antecedentii la distanta mare în text sau texte care contin aprope doar anafore cu un singur candidat. Sunt necesare masuri pentru determinare mediei complexitatii rezolutiei anaforei pentru un text. Mitkov propune ca masuri pentru deteminarea gradului de dificultate a textului: numarul mediu de candidati ai unui anafor si distanta medie dintre un anafor si antecedentul sau.
Alte propuneri pentru evaluare
[Mitkov, 2000] propune un mediu (workbench) pentru compararea algoritmilor de rezolutie a anaforei bazati pe principii asemanatoare folosind nu doar acelasi text de intrare ci si aceleasi instrumente de pre-procesare. Aceasta dezvoltare este un proiect consumator de timp pentru ca presupune reimplementarea majoritatii algoritmilor, dar se asteapta sa ofere o imagine mai buna a avantajelor si dezavantajelor diferitilor algoritmi. Un alt avantaj este faptul ca algoritmii încorporati functioneaza în mod complet automat. Versiunea curenta foloseste parserul FDG ([Tapanainen, 1997]) pentru determinarea relatiilor de dependenta între cuvinte (folosite pentru determinarea grupurilor nominale), a informatiilor morfologice si sintactice. În viitor vor fi posibile doua modele de utilizare: unul folosind un parser superficial - pentru algoritmi ce folosesc o analiza partiala si altul folosind un parser complet - pentru algoritmi ce necesita o analiza completa. Versiunile viitoare vor include si accesul la informatii semantice cu ajutorul WordNet-ului pentru a putea fi inclusi si algoritmi ce necesita acest tip de informatii.
[Donna Byron, 2001] propune ca numarul de tipuri de informatii suplimentare folosite ar trebui inclus în evaluarea algoritmilor pentru rezolutia anaforei pronomiale. Este definita o noua masura numita rata de rezolutie (resolution rate) astfel:
|
Rata de rezolutie = |
Numarul de pronume rezolvate corect |
|
Numarul de pronume referentiale |
Este sugerat ca toate metodele de evaluare a algoritmilor pentru rezolutia pronumelor sa ofere informatii despre textul folosit pentru evaluare.
[Stuckardt, 2001] sugereaza ca evaluarea sistemelor pentru rezolutia anaforei ar trebui sa tina cont de mai multi factori în afara de acuratetea rezolutie (de exemplu cu cât se mareste performanta unei aplicatii NLP daca foloseste sistemul respectiv).
[Bagga, 1998] propune o metoda de evaluare a sistemelor pentru rezolutia coreferintei. Coreferinta este clasificata în functie de procesarea de care este nevoie pentru rezolutie. Este propusa o evaluare separata a claselor de coreferinta (apozitie, nume predicative, nume proprii, pronume).
Cele mai importante cercetari în domeniul rezolutiei anaforei din perioada 1960 - 1980 sunt: [Bobrow, 1964], [Winogad et al., 1972], [Hobbs, 1976, 1978], [Carter, 1968, 1987a], [Rich & LuperFoy, 1988], [Carbonnell & Brown, 1988]. Primele lucrari se bazeaza pe reguli eurisitice si nu exploateaza complet analiza lingvistica - sitemul STUDENT al lui Bobrow sau SHRDLU al lui Winograd. Abordarile ulterioare sunt mult mai complexe si folosesc euristici mai bune. Cercetatorii s-au implicat în dezvoltarea unor sisteme ce folosesc diferite surse de cunoastere. De exemplu algoritmul lui Hobbs (Hobbs' naive approach) din 1976 a folosit sintaxa în primul rând, iar algoritmul LUNAR si algoritmul lui Wilks semantica. Primele lucrari orientate discurs sunt ale lui [Sider, 1979] si [Webber, 1997]; lucrarile urmatoare mergând si mai departe folosind si informatii din lumea reala [Carter, 1986], [Carbonnell & Brown, 1988], [Rich & LuperFoy, 1988].
Majoritatea lucrarilor din aceasta perioada nu pot fi comparate cu metodele recente de rezolutie a anaforei pentru ca multe din ele nu au fost implementate sau evaluate, Cele evaluate au fost testate manual acordându-se atentie doar algoritmului: textele erau analizate sinatctic si semantic de oameni, oferind astfel algoritmului avantajul de-a lucra cu un text de intrare pre-procesat perfect.
În continuare sunt pezentate pe scurt câteva din cele mai semnificative proiecte de rezolutie a anaforei din perioada timpurie (anii 60 - 80).
STUDENT (Bobrow 1964)
Este una din primele încercari de rezolvare a anaforei de catre un program de calculator, fiind un sistem de rezolvare de probleme de algebra de liceu. STUDENT încearca sa gaseasca anaforii si antecedentii folosind pattern-matching.
Ex : The number of soldiers the Russians have is half the number of guns they have. The number of guns is 7000. What is the number of soldiers they have? (Numarul de soldati pe care rusii îl au este jumatate din numarul armelor pe care ei le au. Numarul de arme este 7000. Care este numarul de soldatii pe care ei îl au?)
Sistemul gaseste ca antecedent al lui they grupul nominal the Russians prin potrivirea dintre the number of soldiers the Russians have si the number of soldiers they have.
Sistemul lui Bobrow include o regula care specifica ca grupurile nominale ce contin cuvântul this refera grupuri nominale similare precedente.
De fapt STUDENT foloseste euristici limitate si în afara de tehnicile de potrivire propozitiile nu sunt parsate si nu are loc un proces real de rezolutie a anaforei.
SHRDLU (Winograd 1972)
Winograd este primul care dezvolta proceduri pentru rezolutia pronumelor în sistemul sau SHRDLU, care întretine un dialog despre o micro-lume de forme (blocuri si piramide). Euristicile sunt mult mai complexe lasând impresia unei abordari complexe a rezolutiei anaforei. SHRDLU gaseste referinte din parti anterioare ale conversatiei dintre utilizator si program. Algoritmul lui Winograd verifica grupurile nominale anterioare pentru a gasi antecedentul si nu considera doar primul candidat potrivit ci examineaza toate posibilitatile. Se tine cont de pozitia sintactica: subiectul este favorizat complementului si ambele sunt favorizate fata de un complement cu o prepozitie. Este folosit de asemenea si focusul, care este determinat din raspunsurile la întrebari si din întrebarile de tipul da/nu. Daca nici un candidat nu este gasit cu siguranta ca fiind antecedentul, utilizatorul este rugat sa ajute la selectarea celui mai bun candidat.
SHRDLU foloseste euristici practice care si astazi, dupa 30 ani, sunt înca relevante pentru sistemele de rezolutie a pronumelor.
LUNAR (Woods, Kaplan, Nash-Webber 1972)
Acest sistem foloseste un parser ATN ([Woods, 1970]) si un interpretor semantic bazat pe principiile semanticii procedurale ([Woods 1968]). Rezolutia anaforei este realizata în cadrul interpretorului semantic care distinge doua clase de anafori: partiali (care refera o parte dintr-un grup nominal precedent) si completi (refera un grup nominal precedent). Strategia de rezolvare a anaforilor partiali este cautarea unui antecedent ce se gaseste într-o structura sintactica (semanica) paralela cu cea a anaforului. Sistemul utilizeaza atât nivelul sintactic cât si cel semantic, dar sufera de aceasi limitare ca si STUDENT - poate rezolva doar anaforele pentru care antecedentii au o structura similara.
Sunt folosite trei metode diferite pentru a gasi referintele în functie de forma anaforului (pentru anafor de tipul pronume demontrativ + substantiv, pentru pronume si pentru anaforii precedati de one too si also ). Principala limitare a sistemului LUNAR este faptul ca nu gaseste referintele dintre propozitii.
Algoritmul lui Hobbs
Hobbs propune doua modalitati de rezolutie a anaforei pronomiale: una folosind arbori sintactici si alta folosind semantica ([Hobbs 1976, 1978]). Algoritmul ce foloseste sintaxa este cunoscuta ca Hoobs' naive approach si a atras atentia cercetatorilor fiind înca unul din cei mai de succes algoritmi.
Algoritmul lui Hobbs foloseste arbori sintactici de parsare, care sunt parcursi într-o anumita ordine cautând un grup nominal ce are numarul si genul corect. Hoobs adopta doua constrângeri sintactice propuse de Langacker: un pronume nereflexiv si antecedentul sau nu se pot afla în aceeasi propozitie si antecedentul unui pronume trebuie sa precede sau "comande" (relatie definita de Langacker) pronumele.
Rata de succes a acestul algoritm este între 81,8% si 92%. El este un algoritm "clasic" si ramâne un punct de referinta pentru evaluarea algoritmilor actuali.
Algoritmul BFP (Brennan et al, 1987; Walker 1989)
Este un algoritm pentru rezolutia anaforei pronomiale ce îsi are originea în modelul extins al teoriei centrelor al lui Brennan, Friedman si Pollard.
Primii algoritmi pentru rezolutia anaforei s-au bazat pe exploatarea cunostintelor lingvistice si cele despre domeniu, cunostinte greu de reprezentat sau procesat si care presupun prelucrarea manuala a textului. Printre acesti algoritmi se numara [Carbonell & Brown, 1988], [Carter, 1986, 1987a], [Rich & LuperFoy, 1988], [Sidner, 1997].
Cererile de sisteme NLP practice au încurajat cercetatorii sa treaca la strategii de rezolutie care presupun putine surse de cunoastere (knowledge-poor). Dezvoltarea algoritmilor robusti si cu putine surse de cunoastere a fost motivata si de aparitia unor unelte de prelucrare a limbajului bazate pe texte, unelte mai ieftine si mai performante, si de existenta textelor adnotate si a altor resurse (ontologii, dictionare).
Existenta textelor adnotate la relatiile coreferentiale a permis dezvoltarea algoritmilor de învatare si evaluare a rezolutiei anaforei. Textele, în special cele adnotate, sunt resurse nepretuite nu doar pentru cercetarea empirica ci si pentru metodele de învatare automata si pentru evaluarea algoritmilor implementati.
Performanta algoritmilor depinde de calitatea si cantitatea textelor folosite ca resurse. Algoritmul lui Dagan si Itai din 1999 foloseste reguli simple de învatare pe baza unor sabloane, Algoritmul lui Aone si Bennett din 1995 foloseste arbori de decizie pentru învatare în scopul identificarii perechilor anafor - antecedent, iar algoritmii lui Orasan din 2000 si al lui Mitkov din 2001 introduc algoritmii genetici pentru optimizarea procesului de rezolutie a anaforei.
Momente semnificative în cercetarea legata de rezolutia anaforei sunt:
q Trecerea spre strategii bazate pe surse de cunoastere putine în anii 90;
q Folosirea textelor în procesul de determinare a anaforei;
q Includerea rezolutie anaforei în sistemel MUC-6 si MUC-7;
q Dezvoltarea de proiecte pentru rezolutia anaforei pentru alte limbi decât engleza:
pentru limba franceza: [Popescu-belis & Robba, 1997];
pentru limba germana: [Dunker &Umbach, 1993],[Fischer et al., 1996], [Leass & Scwall, 1991], [Stuckadt, 1996, 1997];
pentru limba japoneza: [Mori et al., 1997], [Murata & Nagao, 2000], [Nakaiwa & Ikehara, 1992], [Nakaiwa & Ikehara, 1995], [Nakaiwa et al., 1995, 1996], [Wakao, 1994];
pentru limba portugheza: [Abraços & Lopes, 1994];
pentru limba turca: [Tin & Akman, 1994];
Rezolutia coreferintei si anaforei pentru mai multe limbi a câstigat mult teren în ultimii ani [Aone & McKee, 1993], [Azzam et al., 1998], [Harabagiu & Maiorano, 2000], [Mitkov, 1999], [Mitkov & Stys, 1997].
Alte tendinte în cercetare sunt:
q folosirea teoriei probabilitatilor si tehnicilor de învatare automata ([Aone & Bennett, 1995], [Ge et al., 1998], [Kehler, 1997], [Cardie & Wagstaff, 1999]);
q folosirea teoriei centrelor în forma originala sau revizuita ([Abraços & Lopes, 1994], [Hahn & Strube, 1997], [Strube & Hahn, 1996], [Tetranl, 1999]);
q dezvoltarea de metodologii pentru evaluarea algoritmilor de rezolutie a anaforei ([Mitkov 1998a, 2000, 2001b], [Byron, 2001]).
În continuare sunt prezentate pe scurt câteva din cele mai importante lucrari referitoare la rezolutia anaforei din ultimii ani.
Algoritmul [Dagan & Itai, 1990, 1991] - bazat pe frecventa de aparitie a sabloanelor
Este un algoritm pentru rezolutia anaforei pronomiale, pentru care anaforul este un pronume la persona a III-a.
Sunt utilizate sabloane pentru gasirea antecedentului, alternativa la implementarile costisitoare ce presupuneau o selectie restrictiva completa.
sabloanele sunt gasite automat într-un corpus (texte folosite ca sursa de cunoastere) si sunt folosite pentru filtrarea candidatilor nepotriviti. Selectia se face pornind de la ideea ca antecedentul trebuie sa satisfaca constrângerile impuse anaforului. În particular, daca anaforul se gaseste într-o anumita relatie sintactica (este subiect sau complement al unui verb) atunci substitutia anaforului cu antecedentul ar trebui sa fie posibila din moment ce antecedentul va satisface restrictiile cerute.
Anaforul este înlocuit cu fiecare candidat si candiadtul care produce cele mai multe aparitii ale sablonului este preferat.
Modelul are doua faze: prima în care corpus-ul este procesat si este construita baza de bate statistice si a doua faza, faza dezambiguizarii, în care baza de date statistice este folosita pentru gasirea antecedentilor pronumelor la persona a III-a.
Rata de succes a acestui algoritm este de 74%. Desi testat pe un set mic de date, modelul lui Dagan si Itai este o tehnica de rezolvare a anaforei utila, mai ales daca exista multe texte care pot fi folosite pentru colectarea de date statistice.
Algoritmul RAP al lui Lappin si Lears (1994) - foloseste parserul SGP pentru filtrarea candidatilor din interiorul propozitiilor
Shalom Lappin si Herbert Leass în 1994 descriu un algoritm pentru rezolvarea pronumelor la persoana a III-a (incluzând si pronumele reflexive) a caror antecedenti sunt grupuri nominale. Algoritmul, numit RAP (Resolution of Anaphora Preocedure) foloseste reprezentarile sintactice generate de parserul lui McCord (1990, 1993). Pentru a selecta antecedentul din lista de grupuri nominale candidate sunt folosite scoruri determinate folosind structuta sintactica si modelul dinamic al starilor atentionale. Nu foloseste infomatii semantice sau din lumea reala.
RAP contine mai multe componente: un filtru sintactic intrapropozitional, un filtru morfologic, o procedura pentru identificarea pronumelor pleonastice, un algoritm pentru identificarea candidatilor, o procedura care asigneaza valori unor parametri (cum ar fi rolul sintactic, frecventa), o procedura pentru identificarea grupurilor nominale legate printr-o relatie de referinta, o procedura de decizie pentru selectia antecedentului din lista de candidati.
RAP are o rata de succes de 86%, 72% pentru cazurile de referinta între propozitii si 89% pentru referintele în interiorul propozitiilor.
În 1995 Dagan a construit o procedura (numita RASPTAT) ce utilizeaza preferinta lexicala, pentru a îmbunatati performanta algoritmului RAP. RASPTAT are o rata de succes de 89%, adica cu 3% mai bun decât RAP
Algoritmul lui Lappin si Leass este una din cele mai importante contributii la rezolutia anaforei din anii 1990: a folosit ca baza pentru dezvoltarea altor aplicatii si este citat mult în literatura de specialitate.
Parserul lui Kennedy si Boguraev - versiune a algoritmului RAP.
Nu necesita parsare sintactica completa, ci functioneaza pe iesirea unui POS-tagger îmbogatita cu adnotarea la functia gramaticala. Sistemul foloseste o gramatica pentru identificarea constituientilor si, similar algoritmului lui Lappin si Leass, foloseste scoruri pentru candidati. Nu este o simpla adaptare cu mai putine surse de cunoastere a algoritmului RAP, ci mai degraba o extensie, pentru ca în acest nou sistem sunt folositi factori noi.
Pentru fiecare element din propozitie tagger-ul folosit (Lingsoft - realizat de [Voutilainen et al, 1992]) ofera un set de valori ce indica proprietatile morfologice, lexicale si gramaticale. Textul este examinat propozitie cu propozitie si referentii discursului sunt interpretati de la stânga la dreapta. Coreferinta este determinata astfel: întâi sunt eliminati acei referenti pe care un anafor nu-i poate referi, apoi se alege antecedentul din rândul candidatilor în functie de scor. Scorurile utilizate sunt un supraset a celor utilizate de algoritmul lui Lappin si Leass. La evaluarea algoritmului s-a obtinut o rata de succes de 75%, mai mica nu cu mult decât cea a algoritmului RAP.
CogNIAC - [Baldwin, 1997]
Este un program pentru rezolutia anaforei pronomiale.
Principala presupunere teoretica pe care se bazeaza strategia acestui algoritm este ca exista o subclasa de anafore care poate fi rezolvata cu ajutorului unei cantitati limitate de cunostinte si resurse. Ceea ce diferentiaza CogNIAC de alti algoritmi este faptul ca în cazul unei ambiguitati pronumele nu este rezolvat. Acest lucru conduce la obtinerea unei precizii mari, dar un recall nesatisfacator.
CogNIAC utilizeaza cunostinte si resurse putine. Foloseste sase reguli de baza (unicitate în discurs, reflexivitate, unicitate în propozitia anterioara si în cea curenta, pronume posesive, unicitatea propozitiei curente, subiect unic) si doua suplimentare. Pronumele sunt procesate de la stânga la dreapta si pentru fiecare regulile sunt aplicate într-o ordine specificata. Daca o regula gaseste un antecedent, nu mai sunt aplicate celelalte reguli. Daca nici o regula nu gaseste nici un antecedent atunci pronumele este lasat nerezolvat.
CogNIAC a fost evaluat în paralel cu algoritmul lui Hobbs obtinându-se rezultate aprope egale: 78,8% pentru algoritmul lui Hobbs si 77,9% pentru CogNIAC. Versiunea de înalta precizie a CogNIAC-ului are o precizie de 92% si un recall de 64%.
Proiectului lui Vieira si Poesio pentru expresii definite
S-a încercat dezvoltarea unui sistem de procesare care sa lucreze cu informatii structurale, informatii oferite de resurse lexicale existente cum este WordNet-ul, cu informatii minimale adnotate manual sau cu informatii care ar putea fi obtinute automat. Ca consecinta sistemul nu este echipat pentru rezolvarea grupurilor nominale care necesita procesare complexa. Pentru aceste tipuri de anafore sunt dezvoltate câteva euristici.
Sistemul lui Vieira si Poesio nu doar gaseste antecedentul anaforilor ci este capabil sa recunoasca entitatile noi de discurs. Sistemul ajunge la o precizie de 83% si de recall de 62% pentru anafora directa si o precizie de 72% si recall de 69% in cazul identificarii entitatilor de discurs noi.
Abordari bazate pe învatare automata
Ca alternativa la sistemele bazate de surse de cunoastere, metodele de învatare automata propun obtinerea de cunostinte / informatii din texte adnotate sau nu, prin învatarea folosind un set de exemple (sabloane). Termenul de învatare automata este folosit pentru a referi în special metodele care reprezinta cunostintele învatate într-o forma declarativa, simbolica, metode diferite de cele statistice sau care folosesc retelele neuronale. Intereseaza metodele care reprezinta cunostintele învatate sub forma unor arbori de decizie interpretabili, reguli logice si instante memorate. Arborii de decizie sunt de fapt functii de clasificare reprezentate sub forma unor arbori ca au drept noduri teste asupra atributelor, drept arce valori pentru atribute iar frunzele sunt etichete pentru clase.
[Aone si Bennet, 1995] descriu un sistem pentru rezolutia anaforei pentru limba japoneza care învata din texte adnotate cu informatii despre discurs - articole din ziare. Este continuarea proiectului de rezolutie a anaforei pentru mai multe limbi [Aone & McKee, 1993]. Modului de învatare automata (MLR) foloseste arbori de decizie C4,5. Arborele de decizie este construit pe baza unor vectori de caracteristici pentru un anafor si antecedentii posibili. Caracteristicile de învatare sunt fie unare, fiind legate de anafor sau de candidat (numar sau gen), fie binare, reprezentând o relatie dintre anafor si antecedent (distanta). Sunt folosite 66 de caracteristici (lexicale, sintactice, semantice si de pozitie). Metoda de învatare lucreaza cu trei parametri: lanturi anaforice, identificator de tip de anafora si factori de încredere. Precizia acestui algoritm se situeaza între 83,49% si 88,55%, iar recall-ul între 67,53% si 70,20%.
Sistemul RESOLVE al lui McCarthy si Lehnert utilizeaza arbori de decizie C4,5 pentru a învata sa clasifice grupuri nominale coreferentiale în domeniul întreprinderilor mixte de afaceri. Vectorii caracteristici utilizati sunt creati pe baza legaturilor coreferentiale si referentiale dintr-un text adnotat manual. La evaluarea sistemului s-a obtinut o precizie de 87,6% si un recall de 80,1%.
[Soon, Ng si Lim, 1999] descriu un algoritm de învatare pentru rezolutia anaforei substantivale într-un text nelimitat. Modulul de rezolutie a coreferintei este parte a unui sistem mai mare de rezolutie. Caracteristicile utilizate pentru perechi de grupuri nominale sunt: distanta, egalitate de siruri, acord în numar, acord de clasa semantica, acord în gen, nume proprii, aliasuri, iar pentru un grup nominal individual: pronume, grup nominal definit, grup nominal demonstrativ. Acest sistemul de rezolutie a coreferintei are o precizie de 68% si un recall de 52%.
[Ge et al., 1998] - algoritm probabilistic pentru rezolutia anaforei
Este propus un cadru statistic pentru rezolutia pronumelor la persona a III-a. Sunt combinati mai multi factori ai rezolutiei anaforei într-unul singur, probabilitatea, utilizat pentru gasirea antecedentului. Programul nu foloseste reguli, dar în schimb foloseste Penn Wall Street Journal Treebank pentru învatare.
Un prim factor utilizat de autori este distanta (Hobbs' distance - calculata în functie de gen, numar si animatie) dintre pronume si candidat. Cu cât distanta este mai mare cu atât probabilitatea este mai mica. Sunt folosite de asemenea sabloane pentru calcularea probabilitatii ca un candidat sa apara cu aceeasi funtie sintactica ca anaforul. Ultimul factor mentionat este numarul de aparitii. Un grup nominal mentionat mai frecvent are mai multe sanse sa fie antecedentul. Aceste patru propabilitati sunt înmultite pentru fiecare candidat; este ales candidatul cu probabilitatea cea mai mare. În urma evaluarii s-a obtinut o rata de succes de 82,9%.
[Cardie & Wagstaff, 1999] - propun rezolutia coreferintei ca algoritm de clustering (însumare)
Fiecare grup nominal este reprezentat ca un vector de unsprezece proprietati (constrângeri sau preferinte) si valorile lor. Algoritmul de clustering împarte multimea grupurilor nominale în partitii, reprezentând clase de echivalenta a lanturilor referentiale. Grupurile nominale sunt determinate folosind Empire NP finder [Cardie &Wagstaff, 1999]; pentru fiecare grup nominal sunt determinate valorile pentru cele 11 proprietati. Gradul de "apropiere de tip coreferinta" dintre fiecare doua grupuri nominale este determinat pe baza "distantei metrice". Cu cât sunt "mai apropiate", cu atât probabilitatea ca cele doua grupuri nominale sa fie coreferentiale este mai mare. Algoritmul începe de la sfârsitul textului si merge înapoi comparând fiecare grup nominal cu toate grupurile nominale precedente. Daca distanta dintre doua gurpuri nominale este mai mica decât raza de însumare r, atunci clasele lor sunt unite daca nu exista nici un grup nominal incompatibil în nici una din clase.
În urma evaluarilor algoritmul are o precizie de 54,6 - 57,4 % si un recall de 52,7 - 48,8 %. Acest algoritm nu necesita surse de cunoastere, nici adnotarea textelor folosite pentru învatare, în plus nu doar realizeaza rezolutia pronumelor ci si a grupurilor nominale. Limitarea este data de algoritmul de clustering care este un algoritm greedy, a acuratetei scazute a pre-procesarii, a faptului ca nu rezolva pronumele reflexive si pleonastice.
Algoritmul lui Mitkov - robust si cu putine surse de cunoastere
Dezvoltarea acestui algoritm, pentru rezolutia pronumelor ce au ca antecedenti grupuri nominale, demonstraza ca anafora poate fi rezolvata cu suficient succes fara cunostinte lingvistice sofisticate sau chiar fara parsare. Evaluarea algoritmului arata ca setul de factori utilizati poate fi folosit si pentru alte limbi decât engleza. Analiza sintactica, semantica si a discusului sunt eliminate folosindu-se în schimb o lista de preferinte - indicatorii antecedentului. Textul de intrare este adnotat la partea de vorbire. Algoritmul functioneaza astfel: localizeaza grupurile nominale care preced anaforul într-un interval de doua propozitii, verifica acordul cu anaforul în gen si numar si apoi aplica indicatorii candidatilor ramasi prin asignarea unui scor pozitiv sau negativ (2, 1, 0, -1). Grupul nominal cu scorul cel mai mare este propus ca antecedent. Algoritmul are o precizie de 77,9%.
Nimic nu este dat, totul este construit. (Bachelard)
Genframe este un sistem pentru rezolutia anaforei realizat de Dan Cristea, Oana-Diana Postolache, Gabriela-Eugenia Dima, si Catalina Barbu. Este prezentat în lucrarile Tough anaphora resolution problems Dan Cristea, Gabriela E. Dima, Oana-Diana Postolache, Ruslan Mitkov) si AR-Engine - a framework for unrestricted co-reference resolution (Dan Cristea, Oana-Diana Postolache, Gabriela-Eugenia Dima, Catalina Barbu)
Genframe-ul este un motor specializat pentru rezolutia anaforei (motor-AR) care funtioneaza pe baza unui model (model-AR) pe care îl primeste la intrare:
Fig 1. motorul-AR functioneaza pe baza modelelor-AR
El poate fi usor integrat în diverse aplicatii pentru prelucrare a limbajului ce necesita un modul de rezolutie a anaforei.
Structura Genframe-ului este:
Domeniu de acesibilitate
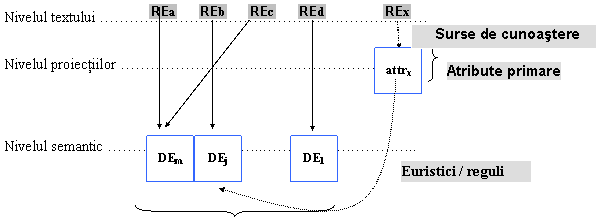
Fig 2. Motorul de rezolutie a anaforei
RE - expresii referentiale = grupuri nominale (din text )care pot referi entitati de discurs
Attr - structuri care memoreaza informatia pe nivelul proiectiilor
DE - entitati de discurs
Genframe foloseste este un model de reprezentare a anaforei care tine cont de relatiile morfologice si sintactice dintre elementele constitutive ale anaforei. Un set de restrictii morfologice, sintactice si semantice (specifice fiecarei limbi) este folosit pentru eliminarea candidatilor, fiind introdus un nivel nou în reprezentarea anaforei: nivelul restrictiilor morfo-sintactico-semantice (feature structures)
Interpretarea anaforei este privita ca un proces în doi pasi:
un prim proces de proiectare în care nivelul intermediar este populat cu informatii aduse din text,
un proces de evocare, care cu ajutorul regulilor (dependente de limba, de structura, de caracteristicile nivelului intermediar) evoca o entitate deja introdusa în discurs sau propune una noua.
Mecanismul de evocare este bazat pe nivelul intermediar, si nu pe textul propriu-zis, si este dependent de limba mai mult sau mai putin în functie de setul de reguli.
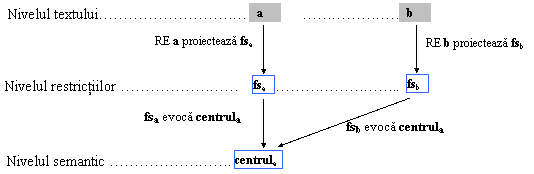
Fig. 2: Reprezentarea anaforei pe trei nivele
Introducerea nivelului intermediar este o rafinare a modelului clasic de reprezentare a anaforei pe doua nivele. Acest nivel este eliminat când procesul de rezolutie este încheiat.
S-a dorit crearea unui model care sa permita utilizarea tuturor ipotezelor formulate pâna în prezent despre rezolutia anaforei: acordul morfologic, sintactic sau semantic sub forma unor reguli dependente de limba, variatia entitatilor de discurs în timp, catafora, amânarea momentului rezolutie.
În cazul rezovarii automate a anaforelor procentul de indecizie poate fi mare datorita lipsei capacitatii de rezolutie, absentei sau limitarii cunoasterii. Amânarea rezolutie anaforei adauga un nou nivel semantic la model. Acest nivel este folosit în cazul unei indecizii si permite pastrarea unor structuri importante pentru identificarea referentului în discursul anterior în orice moment al ascultarii / citirii textului, simultan sau dupa momentul aparitiei expresiei referentiale.
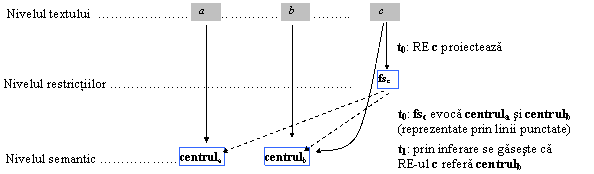
Fig. 3: Reprezentarea pe patru nivele impusa de amânarea rezolutiei
Figura 3 arata procesul de rezolutie pentru un caz care necesita amânarea rezolutiei. La momentul t0 are loc citirea RE-ului c. În acelasi timp, c proiecteaza structura morfo-sintactic-semantica pe nivelul restrictiilor. În acelasi moment cititorul devine constient de existenta unei ambiguitati. Pe nivelul temporal asociat, un atribut (numit candidati - reprezentat de o pereche de linii punctate) va contine lista posibilor antecedenti (în exemplul din figura 3 contine valorile centrula si centrulb). Elemetele din lista au asociate niste scoruri ce exprima gradul de fiabilitate. Apoi într-un moment t1, când exista suficienta informatie are loc procesul de dezambiguizare (în figura, centrulb este ales). Criterii de alegere a antecedentului sunt: un scor aflat sub un prag stabilit precum si o diferenta anume dintre primul si al doilea candidat.
Încheierea acestui proces implica transferul unei parti din datele memorate în reprezentarea de pe nivelul intermediar în reprezentarea semantica a candidatului ales, urmata de stergerea reprezentarilor de pe nivelul intermediar. La sfârsit este pastrata doar o legatura directa între nivelul textului si nivelul semantic. În toate referintele functionale, anaforul construieste întâi o entitate si apoi o pune într-o anumita relatie semantica (partitiva, proprietar-obiect posedat) cu antecedentul.
Framework-ul este capabil sa integreze sau sa gazduiasca o mare parte a algoritmilor existenti, fiind inclusi în motor sub forma unui model. Deci, notiunea principala este cea de model pentru rezolutia anaforei. Modelul reprezinta modalitatea prin care se rezolva anaforele
Un model este alcatuit din patru componente:
Componenta 1 este formata dintr-un set de atribute primare care completeaza nivelul intermediar (al proiectilor) si care sunt apoi raportate nivelului semantic. Fiecare atribut contribuie la stabilirea relatiei dintre anafor si antecedent.
Atributele, asa cum sunt mentionate în majoritatea abordarilor existente, pot fi clasificate în categoriile:
a) morfologice:
numar;
gen lexical;
persoana.
Toti algoritmi existenti utilizeaza criterii morfologice pentru filtrarea candidatilor. Eliminarea unei posibile legaturi referentiale pe baza unei nepotriviri morfologice poate duce la aparitia unor erori. Desi autorii nu sunt de acord cu parerea lui [Barlow, 1998] în aceasta privinta, si anume ca morfologia ar trebui ignorata, considera ca o abordare mai putin categorica este preferabila.
b) sintactice:
descrierea sintactica completa a RE-urilor ca constituenti ai arborelui sintactic:[Lappin & Leass, 1994];
rolul sintactic al RE-urilor fata de subiectului sau fata de verb. Exemplu: în abordarile bazate pe teoria centrelor [Grosz, Joshi & Weinstein, 1995], [Brennan, Friedman & Pollard, 1987], cele bazate pe domeniul sintactic: [Chomsky, 1981], [Reinhart, 1981], [Gordon & Hendricks, 1998], [Kennedy & Boguraev, 1996];
calitatea de a fi adjunct, inclus sau complement al unei prepozitii [Kennedy & Boguraev, 1996];
incluziunea sau nu într-o constructie [Kennedy and Boguraev, 1996];
sabloane sintactic în care este implicat RE-ul, care permit identificarea paralelismului sintactic [Kennedy & Boguraev, 1996], [Mitkov, 1997].
c) semantice:
pozitia head-ului RE-ului într-o ierarhie conceptuala (hiponimie, hipernimie): toate modele care folosesc WordNet-ul ([Poesio, Vieira & Teufel, 1997]). Proprietati ca animatia, sexul (genul natural) sau calitatea de a fi concret sau abstract pot fi considerate atribute simplificate derivate dintr-o ierarhie conceptuala;
apartenenta la o clasa de sinonimie, determinata din context;
rolul semantic ce permite verificarea legaturilor inferentiale, limitarilor pragmatice, paralelismului semantic, preferinta unui obiect;
d) pozitionale:
offsetul primului element al RE-ului (un grup nominal) în text ([Kennedy & Boguraev, 1996]);
incluziunea într-un segment, propozitie sau fraza, considerate ca unitati de discurs ([Azzam, Humphreys & Gaizauskas, 1998]). Aceasta proprietate permite calcularea gradului de apropiere dintre anafor si antecedent. Gradul de apropiere poate fi intra-unitate sau inter-unitate (multe modele stabilesc un maxim numar de unitati între RE-uri pentru stabilirea de accesibiliate din componenta 4).
e) realizare de suprafata
domeniu acestei proprietati este: elipse, pronume clitice, complete, reflexive, posesive, demonstrative, pronumele eliptiv "it", grupurile nominale nedefinite, definite, determinate sau nedeterminate, numerale, etc.
f) altele
incluziunea sau nu a RE-ului într-un câmp lexical anume, dominant în text (este numit "domain concept" în [Mitkov, 1997]);
frecventa termenului în text ([Mitkov, 1997]);
aparitia termenului în titlu ([Mitkov, 1997]).
Componenta 2 include un set de surse de cunoastere
Setul de surse de cunoastere gaseste valori pentru atribute în timpul procesarii imcrementale a textului (considerând textul în ordinea în care este citit).
O sursa de cunoastere este vazuta ca un procesor virtual capabil sa gaseasca valori pentru un singur atribut de pe nivelul proiectiilor (restrictiilor), de exemplu numar, gen, parte de vorbire, rol sintactic. Practic, un procesor actual gaseste valori pentru mai mult de un atribut. De aceea un marcator morfo-sintactic reprezinta mai multe surse de cunoastere pentru ca gaseste valori pentru mai multe atribute.
Cel putin doua surse de cunoastere sunt fundamentale pentru toate modele posibile de rezolutie a anforei: un marcator pentru partea de vorbire (POS tagger) - pentru a asocia tag-uri tuturor elemetelor din text si un parser superficial (shallow parser) capabil sa recunoasca RE-uri prin gruparea cuvintelor textului în grupuri nominale. Din moment ce exista grupuri nominale care nu pot fi RE-uri (ex: the bucket în afara grupului verbal to kick the bucket), un parser ar trebui sa respinga aceste grupuri nominale, prin folosirea unui set de expresii.
În afara de aceste procesoare, sisteme existente folosesc surse de cunoastere suplimentare. De exemplu Kennedy si Boguraev (1996) introduc un marcator pentru functia sintactica si un set de sabloane pentru recunoasterea eliptivului "it". Azzam, Humphreys si Gaizauskas (1998) folosesc un analizator sintactic, un analizator semantic si un descoperitor de eveniment elementare. Gordon si Hendrick (1998) utilizeaza un identificator de realizare de suprafata si un parser sintactic, iar Hobbs (1978) are nevoie , pentru algoritmul semantic , de un analizator sintactic, un identificator de realizare de suprafata si de un set de axiome pentru determinarea rolului semantic si a relatiilor dintre elementele lexicale.
Componenta 3 - un set de euristici sau reguli
Componenta 3 contine un set de euristici sau reguli care coopereaza pentru a gasi raspunsul la întrebarile:
(1) Un RE introduce o noua entitate de discurs?
(2) Daca nu, ce entitate de discurs existenta refera?
Euristicile si regulile realizaza faza de evocare dintre o structura existenta ce apartine nivelului restrictiilor si entitatile de discurs de pe nivelul sematic.
În concordanta cu majoritatea autorilor, pentru realizarea acestui proces sunt folosite trei tipuri de reguli:
Reguli demolatoare (aplicate primele) care elimina un posibil candidatat. Aceste reguli se aplica într-o faza de eliminare din rândul candidatilor a acelor entitati de discurs care nu pot fi referite de RE-ul ce se proceseaza
Reguli confirmatoare confirma daca un candidat anume este antecedentul cautat.
Reguli cu scor care maresc sau scad un factor asociat unui atribut. Aceste reguli se aplica într-o faza ulterioara, în care este ales cel mai bun candidat (este ales din rândul candidatilor ramasi dupa aplicarea regulilor demolatoare) sau este introdusa o noua entitate de discurs.
Multe reguli sunt bazate direct pe valorile atributelor gasite de sursele de cunoastere. Altele sunt aplicate cu ajutorul unor relatii binare, care sunt determinate pe baza atributelor primare.
De exmplu, pentru a elimina candidati [Kennedy & Boguraev, 1996] implementeaza reguli care împiedica un pronume sa refere un grup nominal ce îl contine. (în exemplul the child of his brother his nu refera nici child, nici brother, ci o entitate diferita). Pentru restul de candidati ei calculaza un scor prin evaluarea unui set de perechi de atribute. Aceste scoruri sunt justificate lingvistic si experimental (conform lui [Keenan & Comrie, 1977], [Lappin & Leass, 1994]).
[Gordon & Hendricks, 1998] calculeaza scorul pentru un anafor si un antecedent cu ajutorul unei clasificari a perechilor bazate pe realizarea de suprafata: substantiv-pronume > substantiv-substantiv > pronume-substantiv. Daca realizarea de suprafata a unui anafor este substantiv, atunci un candidat a carui realizare de suprafata este un substantiv va avea scor mai mare decât unul a carui realizare de suprafata este un pronume. Desi nu este specificat explicit, este probabil ca, daca realizarea de suprafata a unui anafor este un pronume, candidatul a carui realizare de suprafata este un substantiv sa aiba un scor mai bun decât cel a carui realizare de suprafata este un pronume.
Componenta 4 - un set de reguli care stabilesc domeniu de accesibilitate
Aceasta componenta are doua sarcini: sa determine entitatile de discurs care pot fi referite si sa le ordoneze potrivit unui criteriu.
Pentru ordonarea entitatilor pot fi adoptate diferite strategii: ordonarea liniara - aseaza toate entitatile de discurs gasite pâna în momentul respectiv descrescator momentului aparitiei RE-urilor din text pe care le refera. Daca se foloseste acest criteriu si exista doi candiati cu acelasi scor este ales candidatul cel mai apropiat textual de anafor. În algoritmul bazat pe teoria starilor atentionale [Grosz si Sidner, 1986] domeniul de accesibilitate este unitatea de discurs curenta iar entitatile sunt memorate într-o stiva a focusului. Abordarile bazate pe teoria centrelor cum ar fi [Sidner, 1981], [Azzam, Humphreys si Gaizauskas, 1998] folosesc registri pentru memorarea focusului curent si liste actualizate pentru fiecare propozitie si definesc o ordine de cautare a antecedentului. Teoria nervurilor [Cristea, Ide si Romary 1998] ordoneaza unitatile discursului potrivit unui domeniu extins de acesibilitate (E-DRA). In teoria nervurilor domeniul de acesibilitate efentiala a unei unitati de discurs este dat de structura discursului si identifica o secventa de unitati de discurs, numita nervura, în care se cauta antecedentul. Domeniul de acesibiliate extins (E-DRA) este domeniul de acesibilitate plus restul de unitati de discurs.
Textul este procesat secvential astfel:.
La nivelul textului sunt delimitate grupurile nominale prin contributia a doua surse de cunoastere (POS tagger si shallow parser).
La început pe nivelul proiectiilor nu se gaseste nici o structura intermediara (nici un attr) si nici pe nivelul semantic nu exista nici o entitate de discurs. La un moment dat se proceseaza un RE care apartine unui segment anume de discurs. Cum rolul nivelului proiectiilor este doar de a metine informatii despre RE-ului ce se proceseaza, dupa rezolvarea lui structura de pe acest nivel este stearsa. Nivelul semantic contine structuri ce corespund entitatilor de discurs gasite (DE1, . DEm), ordonate conform criteriului dat de Componenta 4. Aceste entitati de discurs definesc clase de echivalenta pentru expresiile referentiale (RE) aflate pe nivelul textului astfel ca expresiile coreferentiale refera acelasi DE.
Pentru fiecare RE din text (de la stânga la dreapta) se executa:
o faza de proiectie (RE-ul este transformat într-un Attr care contine setul de atribute împreuna cu valorile corespunzatoare); Momentul procesarii unui RE poate fi amânat daca unele surse de cunoastere necesita mai mult text. De exemplu unele proprietati semantice ale RE-urilor sunt identificate doar dupa prelucrarea verbului de care sunt legate.
o faza de propunere/evocare (Attr-ul obtinut este procesat, adica se încearca sa se gaseasca antecedentul aplicându-se regulile). Presupunem ca structura attrx de pe nivelul proiectiilor are urmatoarea lista de perechi atribut-valoare: ai = vi, i si DE1, . DEm este lista ordonata a entitatilor de discurs de la momentul respectiv, iar DE1 - cea mai importanta. Presupunem ca atributele si valorile acestora pentru DEj sunt: aji = vji, i . Atributul candidati al structurii attrx este un vector de lungime m ce contine perechi de valori numerice: primul numar este un indice corespunzator unui DE iar al doilea numar este un scor care exprima probabilitatea ca DE-ul corespunzator sa fie antecedentul anaforului curent. Notam cele doua valori ale unei perechi din lista candidati cu idx respectiv val. Faza de evocare se executa astfel:
Pentru fiecare entitate de discurs DEj executa
}
ordoneaza lista candidati în ordinea descrescatoare a valorilor
val si apoi a valorilor idx ;
daca candidati.val(0) < pragmin atunci copie attrx ca DEm+1 si
conecteaza anaforul curent REx) la el;
altfel daca abs(candidati.val(0) - candidati.val(1)) < pragdiff
atunci mentine doar candidati(0) si candidati(1) în attrx;
altfel alege drept antecedent al REx DE-ul dat de
candidati.idx(0), (primul candidat dupa ordonare) ,
uneste attrx cu DE-ul gasit si
sterge attrx de pe nivelul proiectiilor;
o faza de completare (se testeaza daca s-a gasit antecedent sau nu. Daca nu s-a gasit antecedentul, attr-ul se adauga la lista de attr-uri amânate); Pasul 7 descrie actiunile ce se executa când este propusa o noua entitate de discurs datorita potrivirii slabe dintre structurile proiectate si entitatile de discurs deja existente. Pasul 8 descrie actiunile ce se executa când exista o incertitudine în alegerea antecedentului (scorurile asociate primilor doi candidati sunt sub un prag stabilit) Pragurile utilizate în acesti doi pasi pragmin and pragdiff) sunt incluse în model printre alti parametri.
o faza de reevaluare (se reia reprocesarea attr-urilor amânate) Sunt situatii în care doua sau mai multe structuri attr sunt mentinute pe nivelul proiectiilor. Aceste situatii apar în cazul amânarii rezolutiei, datorita diferentei de scor prea mici între candiatii cei mai probabili.
Genframe este implementat în limbajul Java. Este un modul care poate fi inclus în alte aplicatii de prelucrare a limbajului.
La intrare: primeste un text, în format XML, adnotat la POS (partea de vorbire) si la NP (grupuri nominale) si un model ce reprezinta tocmai modalitatea prin care se rezolva anaforele (clase derivate din clasele GenFrame-ului scrise în Java);
La iesire: un text adnotat cu lanturile coreferentiale existente în text;
Clase importante
o Clasa RE clasa folosita pentru memorarea unui RE (grup nominal ce poate referi o entitate de discurs);
o Clasa DE clasa folosita pentru memorarea unui DE (entitati de discurs); contine o lista cu RE-urile ce au contribuit la entitatea respectiva; fiecare DE are asociat un vector cu atributele si valorile lor date de toate RE-urile care refera entitatea respectiva;
o Clasa Attr clasa folosita pentru memorarea unei structurii Attr, pe nivelul proiectiilor. Fiecare Attr memoreaza RE-ul caruia îi corespunde, un vector cu atributele si valorile corespunzatoare, DE-ul la care pointeaza si un vector cu candidatii valizi;
o Clasa Candidate clasa folosita pentru memorarea unui candidat; are asociat un DE, un scor si o pozitie;
o Clasa CandidateComparator clasa folosita pentru compararea candidatilor în vederea ordonarii lor;
o Clasa TagAttrNames clasa folosita pentru memorarea tag-uri folosite in adnotarea textului si a altor constante folosite ce depind de adnotare si de limba pentru care se face rezolutia anaforei;
o Clasa Rule - clasa abstracta ce trebuie derivata; este folosita pentru a descrie o regula; o regula are asociata un nume, o prioritate, un tip, un scor si o pondere. Regulile pot fi de doua tipuri:
certificatoare / demolatoare
regulile certificatoare returneaza -1 în cazul în care s-a gasit cu DE-ul la care refera attr-ul, altfel returneaza 0;
regulile demolatoare returneaza -2 în cazul în care DE-ul curent nu este cu siguranta antecedentul attr-ului si 0 altfel;
cu scor
regulile cu scor returneaza un anumit scor care se aduna la scorul candidatului (DE-ului) curent;
Metoda abstracta a acestei clase este:
public abstract int run(DE de, Attr attr)
o Clasa Model - clasa abstracta ce trebuie derivata si metodele ei abstracte implementate.
Metodele abstracte sunt:
public abstract void setFeatures(Attr attr);
- stabileste care sunt atributele care intereseaza din punctul de vedere al modelului si de asemenea ataseaza valorile corespunzatoare fiecarui atribut în parte pentru attr-ul curent. Pentru gasirea valorilor corespunzatoare se pot folosi sursele externe, fie care sunt deja exsistente, fie altele nou create special pentru acest scop. Pentru adaugarea de noi atribute se foloseste metoda public void addFeature(String f, Object v) din clasa Attr.
public abstract void sortDeList(Vector deList);
- sorteaza lista de DE-uri;
public abstract void applyHeuristics(Attr attr);
- Este posibil ca unui attr sa nu i se poata stabili antecedentul. Acest lucru se întâmpla atunci când doi (sau mai multi) candidati au acealasi scor sau diferenta scorurilor este foarte mica. În acest caz acesti candidati sunt memorati (clasa Attr are un membru validCandidati în care sunt stocati). Atunci când lista de RE-uri a fost parcursa în toatalitate dar un attr sau mai multi nu au putut fi rezolvati se aplica aceasta functie care trebuie sa aleaga un candidat din lista de candidati valizi (care se poate obtine folosind metoda getValidCandidati() din clasa Attr) folosindu-se de niste euristici.
public abstract void createRules()- modelul, pe lânga atribute, poate stabili si niste reguli care ajuta la determinarea antecedentului;
în aceasta metoda sunt adaugate regulile cu ajutorul metodei public void addRule(Rule r);
o Clasa Engine este clasa cea mai importanta; implementeaza algoritmul de rezolutie a anforei ce functioneaza pe baza unui model (o clasa derivata din clasa Model) prin metodele run, process si processAttr(); contine modelul, lista de RE-uri, de DE-uri si de Attr-uri, pragul sub care se construiesc noi DE-uri, pragul sub care este amanata decizia, multimea de tag-uri folosite in adnotarea textului (clasa derivata din TagAttr).
Lucrurile nu sunt grele de facut, ceea ce este greu este sa fim în stare sa le facem. (C-tin Brâncusi)
Mi-am propus (dezvoltarea unui model pentru) rezolvarea unor tipuri de anafora:
anafora functionala si coreferinta;
anafora substantivala
cazuri dificile de anafora:
subiect - nume predicativ;
subiect - apozitie;
grupuri nominale cu acelasi numar lexical dar leme diferite;
grupuri nominale cu numar lexical diferit si leme diferite.
Din punct de vedere computational cea mai multa atentie a primit anafora pronomiala existând multe lucari si multi algoritmi pentru rezolvarea acestui tip de anafora. Exista semnificativ mai putine lucrari despre anafora nominala, si mai putine despre anafora functionala. WordNet-ul este de obicei folosit pentru a rezolva anafora nominala si pe cea functionala, dar ar fi nevoie de o dezambiguizare a sensurilor cuvintelor pentru a obtine rezultate bune. De aceea am folosit în aplicatia mea si web-ul pentru rezolvarea acestor tipuri de anafore.
Aplicatia mea este de fapt un model folosit ca intrare pentru GenFrame - sistem pentru rezolutia anaforei (prezentat în capitolul III). Modelul reprezinta de fapt modul de rezolvare a anaforelor.
Base-model - modelul de baza
Setul de atribute:
Surse de cunoastere:
Reguli de potrivire:
Domeniu de accesibilitate: liniar; ordonare dupa pozitie
Acest model rezolva coreferintele pentru care anaforul este un pronume si antecedentul pronume sau substantiv propriu
WordNet-model = Base-model plus...(foloseste ierarhia WordNet)
Setul de atribute:
Surse de cunoastere:
Reguli de potrivire:
Domeniu de accesibilitate: liniar; ordonare dupa pozitie
Fata de modelul de baza acest model gaseste si unele referinte pentru care anaforul este un grup nominal, însa înca ramân anafore nominale nerezolvate pentru ca relatiile de hipernimie si sinonimie nu sunt suficiente si nici nu sunt complet implementate de catre WordNet
Centering-model = WordNet-model plus...(foloseste Teoria Centrelor)
Setul de atribute:
Surse de cunoastere:
Reguli de potrivire:
Domeniu de accesibilitate: liniar; ordonare dupa pozitie;
Centuring Model are performante mai bune decât modelul bazat pe WordNet, însa mai ramân cazuri mai complicate de anafora nerezolvate cum ar fi: subiect - nume predicativ, coreferinte dintre grupuri nominale cu acelasi numar lexical diferit, coreferinte dintre un substantiv comun si unul propriu, coreferinte pronume - antecedent splitat, coreferinte substantiv plural - antecedent splitat.
VT-model = Centering-model plus... (foloseste Teoria Nervurilor)
![]() Setul de atribute:
Setul de atribute:
Surse de cunoastere: ca la Centering Model
Reguli de potrivire:
Domeniu de accesibilitate: ierarhic conform teoriei nervurilor
Modelul bazat pe teoria nervurilor nu aduce îmbunatatiri modelului ce foloseste teoria centrelor decât în cazul unui text de dimensiuni mari.
Setul de atribute:
o POS = partea de vorbire;
o LNUM = numar lexical;
o LGEN = gen lexical;
o NGEN = genul natural;
o PERS = persona unui pronume;
o NAME = nume propriu;
o LEM = lema;
o SYNO = sinonimele;
o HYPER = hipernimele;
o MERO = meronimele (de fapt sunt de trei tipuri: part-of, substance-of si member-of);
o HOLO = holonime;
o DEF = definitia,
o DET = "determinantii" (cuvintele dintr-un grup nominal exceptând head-ul)
o ANIMACY = calitatea de a fi animat;
o APP = apozitie
o INCLUDE = gupul nominal în care este inclus
Sursele de cunoastere:
o POS-tagger, lematizator, WordNet-ul, Internetul, baza de date (fisier) pentru nume proprii;
Reguli:
o Reguli destructoare: match-DET, match-ANIMACY, IncludingRule,
o Reguli confirmatoare: match-NAME, match-APP, match-HOLO, match-MERO;
o Reguli cu scor: WebRule, LemmaRule, NumberRule, GenderRule, NaturalGenderRule, match-DEF;
Domeniu de accesibilitate:
o liniar
rezolva RE-urile "încuibarite" (se foloseste WordNet-ul si Web-ul pentru a seta un atribut de tipul PART-OF, SUBSTANCE-OF, MEMBER-OF) - adica anafora functionala.
Ex: a tree of the forest (tree = MEMBER-OF forest)
rezolva apozitiile: (se seteaza un atribut APPOSITION-OF)
Ex: Maria, my friend, . (my friend = SAME-AS Maria)
gaseste coreferintele subiect-nume predicativ: (se seteaza un atribut SAME-AS)
Ex: Dana is my sister. (Dana = SAME-AS my sister)
gaseste coreferinte dintre grupuri nominale cu acelasi numar lexical dar leme diferite (se foloseste WordNet-ul)
Ex: The queen . the woman.
gaseste coreferinte dintre NP-uri cu numere lexicale si leme diferite (se folosesc relatiile de meronimie, holonimie si hipernimie din WordNet si interogari web cu ajutorul motorului de cautare Google):
Ex: The patrol .... the soldiers
gaseste coreferinte dintre un substantiv comun si unul propriu (se foloseste o baza de cunostinte - de fapt o baza de date)
Ex: Maria ... the girl
gaseste coreferintele pronume - antecedent splitat: (se foloseste un atribut GROUP OF)
Ex: John meet Mary. They went to a movie. => they = GROUP-OF (Jhon & Mary);
gaseste coreferintele substantiv plural - antecedent splitat: (se foloseste un atribut GROUP-OF)
Ex: Dan, Chriss and Anne ... the kids => the kids= GROUP-OF (Dan, Chriss & Anne);
Aplicatia este un model ce este intrare pentru motorul GenFrame-ului (prezentat în capitolul III). Prin urmare este scrisa în limbajul Java si consta în clase derivate din clasele GenFrame-ului (lucru necesar), clase adaugate de mine, necesare pentru a rezolva cazurile mai dificile de anafora si clase folosite pentru accesul la WordNet (nu sunt scrise de mine, doar folosite si eventual modificate).
Precizez ca am
modificat si clasele GenFrame-ului deoarece am descoperit niste erori
de functionare. Este vorba de metoda public
static boolean process(Attr attr) a clasei Engine. De exemplu în urma
aplicarii unei reguli destructoare când era eliminat un candidat,
datorita modului în care era realizata o iteratie, era
sarit candidatul urmator, adica pentru acesta nu erau aplicate
regulile, prin urmare nu era luat în calcul la determinarea antecedentului. Am
modificat modul de iterare si eliminare a candidatilor. Pentru a
putea salva în fisierul de iesire si anafora functionala a
trebui sa modific si functia de salvare. De asemenea am
modificat modul de memorare a atributelor si valorilor asociate unui DE
pentru a permite gasirea tuturor atributelor si a valorilor
corespunzatoare unui RE ce refera DE-ul respectiv. De exemplu pentru
regulile HolomynRule, MeronymRule aveam nevoie sa de numarul lexical
corespunzator unei leme a DE-ului candidat.
Clase extinse
o Modelul : public class ModelLic extends Model - clasa care stabileste cum se face rezolutia anaforei: ce atribute se folosesc, ce reguli sau euristici se aplica;
Pragul minim (lowerBound) este 0.54f, iar pragul de diferentiere (epsilon) este 0.01f;
Metodele abstracte suprascrise sunt:
public void setFeatures(Attr attr) - stabileste care sunt atributele care intereseaza din punctul de vedere al modelului si de asemenea ataseaza valorile corespunzatoare fiecarui atribut în parte pentru attr-ul curent:
public void setFeatures(Attr attr)
// extragem tipul - comun, propriu
String type = TypeExtractor.extractType(headID,textFile,tags);
if (!type.equals(""))
if (pn.isFemale(lemma))
}
}
}
/* determinam genul semantic - este de fapt dat de trei valori
reale - procente ce exprima probabilitatea de a avea genul masculin, feminin si respectiv neutru
*/
if (lemma != null)
//extragem apozitiile
String app = AppositionExtractor.extractApposition("" + npID, textFile, tags);
if (app != null)
attr.addFeature(tags.APPOSITION, app);
//extragem "determinantii"
ArrayList det = DetExtractor.extractDet("" + npID, textFile, tags);
if (det != null && det.size() > 0)
attr.addFeature(tags.DET, det);
// extragem id-urile NP-urilor incluse in NP/ul curent
Vector included = IncludedNP.extractIncluded(npID, textFile, tags);
if (included.size() > 0)
attr.addFeature(tags.INCLUDED, included);
// conectare la wordnet ptr. a lua synonume,meronime,....
DictionaryDatabase dictionary = new FileBackedDictionary();
if (!lemma.equals("") && pos.equals(tags.N))
if (hp != null && hp.isEmpty() != true)
attr.addFeature(tags.HOLOP, hp);
if (hm != null && hm.isEmpty() != true)
attr.addFeature(tags.HOLOM, hm);
if (hs != null && hs.isEmpty() != true)
attr.addFeature(tags.HOLOP, hs);
if (mp != null && mp.isEmpty() != true)
attr.addFeature(tags.MEROP, mp);
if (mm != null && mm.isEmpty() != true)
attr.addFeature(tags.MEROM, mm);
if (ms != null && ms.isEmpty() != true)
attr.addFeature(tags.MEROS, ms);
vect = (Vector) dictionary.getSynonymSenses(lemma);
if (vect != null && vect.size() > 0)
attr.addFeature(tags.SYNO, vect);
}
}
public void sortDeList(Vector deList) - sorteaza lista de DE-uri în ordinea aparitiei în text (ultimile DE-uri referite sunt cele mai recente) apartinând ultimelor trei propozitii;
public void applyHeuristics(Attr attr) - modelul meu nu aplica nici o euristica
public void createRules()- stabileste regulile care ajuta la determinarea antecedentului, tipul lor, scorul si prioritarea asociata:
addRule(new IncludingRule(true, 15, 0));
addRule(new ProperNameRule(true, 14, 0));
addRule(new DetRule(true, 13, 0));
addRule(new AnimateRule(true, 12, 0));
addRule(new AppositionRule(true, 11, 0));
addRule(new GroupRule(true, 10, 0));
addRule(new RoleRule(true, 9, 0));
addRule(new HolonymRule(true, 8, 0));
addRule(new MeronymRule(true, 7, 0));
addRule(new LemmaRule(false, 6, 2));
addRule(new NumberRule(false, 5, 4));
addRule(new GenderRule(false, 4, 1));
addRule(new NaturalGenderRule(false, 3, 3));
addRule(new DefSRule(false, 2, 2));
addRule(new webRule(false, 1, 2));
addRule(new SynonymRule(false, 1, 1));
addRule(new HypernymRule(false, 1, 1));
addRule(new PosRule(false, 1, 1));
Regulile
o public class AnimateRule extends Rule - regula destructoare. Sunt eliminati candidatii care nu sunt la fel de "animati" ca antecedentul. Pentru fiecare candidat (de fapt un DE) si pentru attr sunt determinate (folosind WordNet-ul) procente de probabilitate ca entitatea corespunzatoare sa fie "animata". Daca diferenta dintre procentul candidatului si procentul attr-ului este mai mare ca un prag atunci candidatul este considerat nepotrivit.
o public class AppositionRule extends Rule - regula confirmatoare pentru rezolvarea referintelor de tipul substantiv - apozitie. Daca attr-ul are setat un atribut APPOSITION-OF si valoarea lui este ID-ul unui grup nominal ce refera entitatea descrisa de candidatul respectiv atunci candidatul cautat a fost gasit.
o public class DefSRule extends Rule - regula cu scor ce foloseste definitiile cuvintelor oferite de WordNet. Am adaugat aceasta regula deoarece relatiile de hipernimie, sinonimie, meronimie si holonimie nu sunt suficiente pentru rezolvarea anaforelor nominale. Întâi se testeaza daca exista un ancestor comun (în ontologia oferita de WordNet) între lema attr-ului si lemele grupurilor nominale ce au contribuit la crearea entitatii de discurs aflata pe post de candidat. Daca ancestorul exista si este ori lema attr-ului ori una din lemele candidatului atunci avem o relatie de coreferinta. Daca ancestorul exista si este nu este unul "general" (adica "life form", "something", "organism", etc) atunci este testat daca definitiile date de WordNet pentru lemele asociate candidatului contin lema attr-ului si daca definitiile date de WordNet pentru lema attr-ului contin una din lemele candidatului. Daca este îndeplinita una din aceste conditii atunci este considerat ca exista sanse sa fie coreferinta între attr si candidat.
o public class DetRule extends Rule - regula demolatoare referitoare la "determinatii" unui grup nominal. Eu spun "determinanti" cuvintelor dintr-un grup nominal ce nu sunt substantive. Folosind acesti "determinati" se testeaza daca un substantiv este articulat sau nu. Daca nu este articulat atunci el introduce o entitate noua de discurs, prin urmare nici un candidat nu este bun ca antecedent al sau. În plus mai sunt adaugate alte restrictii, de exemplu daca doar attr (sau doar candidatul) are "determinantul" some atunci nu poate exista o relatie de coreferinta.
o public class GenderRule extends Rule - regula cu scor. Daca attr-ul are acelasi gen ca un RE ce contribuie la definirea candidatului atunci candidatul are mai multe sanse sa fie antecedentul cautat.
o public class GroupRule extends Rule - regula destructoare. Daca candidatul face parte dintr-un grup (grupurile sunt determinate folosind un extractor si sunt memorate folosind o clasa Group) ce are acelasi "tip" cu attr-ul si attr-ul poate fi considerat un grup (adica ori este la plural ori este un substantiv colectiv) atunci avem o relatie de coreferinta între attr si grup, iar între candidat - membru al grupului si attr nu putem avea coreferinta, ci referinta functionala (de apartenenta).
o public class HolonymRule extends Rule - regula confirmatoare ce foloseste relatia de holonimie definita de WordNet. Daca attr este holonim al candidatului (lucru verificat cu ajutorul atributelor HOLOP, HOLOM, HOLOS si a WordNet-ului) atunci în unui testului asupra numarului attr-ului si candidatului se stabileste daca este relatie de coreferinta sau de referinta functionala. Analog pentru cazul când candidatul este holonim al attr-ului.
o public class IncludingRule extends Rule - regula demolatoare ce nu permite ca între un RE inclus în alt RE sa existe o relatie de coreferinta.
o public class LemaRule extends Rule - regula cu scor. Daca attr-ul are acelasi lema ca un RE ce contribuie la definirea DE-ului candidat atunci DE-ul are mai multe sanse sa fie antecedentul cautat.
o public class MeroniymRule extends Rule - regula confirmatoare asemanatoare cu HolonymRule diferenta fiind faptul ca foloseste relatia de meronimie si nu cea de holonimie.
o public class ProperNameRule extends Rule - regula certificatoare. Daca si attr-ul si DE-ul candidat sunt substantive proprii si au aceeasi lema atunci ele sunt coreferentiale.
o public class RoleRule extends Rule - regula destructoare. Daca attr-ul are pentru atributul ROLE valaorea nume predicativ si DE-ul are un pentru un atribut ROLE valoarea subiect si sunt din aceeasi propozitie atunci este setat un atribut SAME-AS;
o public class SemanticNumberRule extends Rule - regula cu scor ce foloseste atributele SHE, HE, IT - probabilitati ca entitatile respective sa fie de genul feminin, masculin sau neutru.
o public class webRule extends Rule - regula cu scor pentru anafora nominala ce foloseste interogari web pentru determinarea unei probabilitati de existenta a unei relatii de referinta între candidat si attr. Este trimisa o interogare unui motor de cautare (Google) printr-un socket, folosind protocolul HTTP si comanda GET. Interogarea este construita pe baza lemelor atrr-ului si DE-ului candidat si tinând cont de numarul lexical. Pagina primita drept rezultat este prelucrata pentru a determina numarul de pagini (ce contin sirul de interogare) gasite de motorul de cautare. Este cosiderat rezultatul cautarii semnificativ, daca se obtin mai mult de 50 de pagini.
Clase adaugate
Extractorii - clase care extrag din adnotare sau gasesc (pe baza adnotarii si a altor surse de cunostere) valori pentru un atribut al unui Atrr:
o public class AppositionExtractor extends DefaultHandler - parseaza textul de intrare (fisier XML) si pentru un NP (este trimis ca paramentru ID-ul sau) gaseste apozitiile;
o public class DetExtractor extends DefaultHandler - parseaza xml-ul si extrage informatii (partea de vorbire, lema, numar) despre "determinatii" unui grup nominal pe care le memoreaza folosind clasa DET;
o public class GenderExtractor extends DefaultHandler - parseaza xml-ul (trimis ca parametru) si pentru un NP (este trimis ca paramentru ID-ul sau) extrage genul lexical (este de fapt un atribut al tagului folosit pentru memorarea unui cuvânt);
o public class GroupParser extends DefaultHandler - parseaza xml-ul si determina grupurile posibile din care un grup nominal ar putea face parte. Pentru un cuvânt din propozitie este determinat tipul sau (person, being, object, concept, action) si numarul "propozitiei" (Am considerat propozitie toate cuvintele la început pâna la primul punct sau toate cuvintele dintre doua puncte). Numarul propozitiei este determinat practic numarând semnele de puctuatie "." din textul ce precede grupul nominal respectiv. Grupurile sunt determinate tinând cont de aceste informatii. La început sunt construite grupuri formate dintr-un singur element, apoi sunt unite grupurile care au acelasi tip si fac parte din aceeasi propoziti. Sunt pastrate doar grupurile cu mai mult de un membru, din care face parte si grupul nominal primit ca parametru.
o public class LemmaExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un NP (este trimis ca paramentru ID-ul sau) extrage lema (este de fapt un atribut al tagului folosit pentru memorarea unui cuvânt);
o public class NumberExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un NP (este trimis ca paramentru ID-ul sau) extrage numarul lexical (este de fapt un atribut al tagului folosit pentru memorarea unui cuvânt);
o public class PersonExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un pronume (este trimis ca paramentru ID-ul sau) extrage persona - categorie gramaticala folosita mai departe pentru determinarea genului;
o public class POSExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un NP (este trimis ca paramentru ID-ul sau) extrage partea de vorbire (substantiv, pronume, determinant, semn de punctuatie, etc.);
o public class RoleExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un NP (trimis prin ID-ul sau) extrage functia sintactica ;
o public class TypeExtractor extends DefaultHandler - parseaza textul de intrare (trimis ca parametru) si pentru un substantiv extrage tipul - propriu sau comun (este de fapt un atribut al tagului folosit pentru memorarea unui cuvânt);
o public class ProperNames - clasa folosita pentru gestionarea numelor proprii (citite si salvate într-un fisier serializate). Pentru fiecare nume propriu este instantiat un obiect NP (ce memoreaza lema, genul si tipul - pesoana, companie) ce este serializat si salvat într-un fisier. Pot fi adaugate, sterse, modificate numele proprii. Pot fi salvate în alt fisier sau poate fi încarcat un alt fisier cu nume proprii.
Alte clase folosite:
o public class DET - clasa folosita pentru memorarea unui "determinant";
o public class elem- clasa folosita pentru memorarea unui membru al unui grup;
o public class Group- clasa folosita pentru memorarea unui group; pentru un grup se memoreaza tipul, numarul propozitiei si membrii sai (într-un vector).
o public class PN implements Serializable - clasa folosita pentru memorarea unui nume propriu.
Am testat aplicatia pe un set de 35 de texte si am observat ca anafora pronomiala nu este rezolvata cu o precizie foarte mare, în schimb pentru anafora nominala si cea functionala rezultate destul de bune. În Anexa 1 sunt listate o parte din textele XML adnotate folosite pentru testare si textele cu rezultatele obtinute.
Nu am putut testa modelul meu pe acelasi text pe care au fost testate celelalte modele implementate si incluse în GenFrame datorita modului de acces la WordNet folosit. Pentru accesul la WordNet am folosit niste clase scrise în limbajul Java de Oliver Steele ([email protected]) speciale pentru acest lucru. Însa nu permit multe accese la WordNet, asa cum necesita modelul meu în cazul unui text mai mare.
Rezulatele evaluarii sunt:
|
Coreferinte nominale |
Anafore functionale |
Coreferinte pronomiale |
Total |
|
|
Numarul de anafore gasite corect de program | ||||
|
Numarul de anafore din text | ||||
|
Numarul de anafore gasite de program |
Pentru toate anaforele:
q precizia = 85 / 98 = 86,73%;
q recall = 85 / 97 = 97,70%
Pentru coreferinta nominala :
q precizia = 38 / 42 = 90,47%;
q recall
Pentru anafora functionala :
q precizia = 24 / 25 = 96%;
q recall
Pentru coreferinta pronominala :
q precizia = 23 / 31 = 74,19%;
q recall
Aplicatia mea gaseste si anafore care nu exista în realitate în textul respectiv (gaseste referite între elemente din text între care nu exista nici o legatura referentiala). Ca o consecinta a acestui lucru recall-ul obtinut este mai mare decât precizia.
Folosirea interogarilor web îmbunatateste rata de suces în cazul anaforei nominale si functionale pentru ca exista anafore care nu pot fi rezolvate folosind doar WordNet-ul.
Modelul propus de mine are rezultate mai bune în cazul rezolvarii unor cazuri dificile de anafora, si în cazul anaforei functionale. Anafora pronomiala nu este rezolvata cu o precizie foarte mare. Exista multi algoritmi specializati pentru rezolutia anaforei pronomiale cu rata de succes mai buna.
Pentru marirea performantei ar trebui dezvoltate regulile pentru rezolvarea anaforelor pronomiale pentru care antecedentul este un grup nominal. De asemenea ar trebui modificate regulile ce folosesc WordNet-ul, pentru a nu mai gasi anafore ce nu exista de fapt. De exemplu regula cu scor ce foloseste definitiile cuvintelor oferite de WordNet ar trebui sa fie mai restrictiva.
Rezultatele obtinute în urma evaluarii arata ca algoritmul propus este eficient.
Din greutati se ivesc minunile. (La Bruyere)
Rezolutia anaforei are un rol vital în multe aplicatii de prelucrare a limbajului natural cum ar fi traducerea automata, abstractizarea automata, rezumarea automata.
Rezolutia automata a anaforei este o sarcina complexa care necesita diferite surse de cunoastere si care poate fi privita ca un proces în trei etape: identificarea anforilor, gasirea candidatilor si selectia antecedentului cu ajutorul unui algoritm de rezolutie (bazat pe reguli).
Primii algoritmi de rezolutie a anaforei folosesc euristici simple cum ar fi potrivirea ([Bobrow, 1964]), sau euristici mai complexe ([Winograd, 1972]) obtinând rezultate remarcabile pentru timpul respectiv. Algoritmii de mai târziu au evoluat pe masura ce mai multe elemente teoretice despre diferite tipuri de anafora au fost stabilite. Sunt folosite in mod extensiv informatile lingvistice si ne-ligvistice ([Carter, 1986], [Carbonnell & Brown, 1988], [Rich & LuperFoy, 1988], [Sider, 1979], [Wilks, 1973]), si din aceasta cauza lucrarile au o valoare practica mai mica, implementarile fiind limitate sau inexistente. Ca urmare, evaluarea (în conditii actuale) este dificila. Oricum, proiectele despre rezolutia anforei din anii 70 si 80 sunt remarcabile pentru ca prezinta câteva probleme fundamentale si modele sofisticate. Unele abordari dezvoltate (de exemplu [Hobbs 1976, 1978], [Brennan et al., 1987]) sunt puncte de referinta si sunt citate în literatura de specialitate acctuala.
Cele mai recente cercetari în rezolutia anaforei sunt orientate spre solutii robuste si bazate pe putine surse de cunoastere ce ofera suport pentru aplicatii practice cum ar fi extragerea de informatii si rezumarea textelor. În plus, acum dezvoltatorii beneficiaza de existenta unui corpus si sunt constienti de necesitatea evaluarii pentru a vedea unde se situeaza o anume abordare. Daca cercetatorii din anii 1970 sau 1980 abia îsi punea problema evaluarii, astazi nici un proiect nu va fi luat în serios daca nu sunt reportate rezultatele evaluarii. Oricum compararea diferitelor abordari într-un mod corect si consistent ramâne dificila pentru ca, de obicei, evaluarea se face pe texte (date de intrare) diferite deoarece fiecare abordare necesita un alt grad de pre-procesare a textului.
Textele adnotate cu legaturile anaforice si coreferentiale sunt importante pentru cercetarea în domeniu rezolutiei anaforei. Ele constituie o sursa valoroasa de a obtine date si reguli empirice pentru realizarea unor noi algoritmi de rezolutie a anaforei, pentru învatare, optimizare si evaluare a algoritmilor existenti.
Evaluarea algoritmilor pentru rezolutia anaforei si a sistemelor de rezolutie a anaforei ar trebui facute separat. Exista o serie de marimi de evaluare. Compararea corecta a metodelor presupune nu doar ca evaluarea sa se realizeze pentru aceleasi date, dar si pentru aceleasi unelte de pre-procesare.
Genframe este un model incremental pentru rezolutia relatiilor anaforice complexe. Acest model suporta diferite tipuri de amânare a rezolutiei Este posibila o rafinare mai mare a algoritmului. Mecanismul actual de identificare a antecedentului nu este suficient detaliat. Autorii cred ca abordarea corecta este o combinatie între procesarea incrementala si alte criterii de identificare a antecedentului.
GenFrame permite:
o definirea si rafinarea modelelor usor;
o comparare usoara între modele:
o posibilitatea de a integra diferite abordari;
o amânarea rezolutiei în caz de incertitudine;
Modelul propus si implementat trateaza:
anafora nominala cu ajutorul interogarilor web si a WordNet-ului
RE-urile "încuibarite" prin folosirea atributul belongs-to
anaforele cu antecedenti splitati prin gasirea grupurilor posibile clasificând RE-urile în clase (persoana, obiect, actiune, etc) cu ajutorul WordNetului.
Modelul propus si implementat nu gaseste anaforele pronomiale pentru care antecedentul este un grup nominal
Algoritmul de rezolutie a anaforei descris de modelul meu a obtinut în urma evaluarii pe 35 de texte o precizie de 86,73% si un recall de 97,70%. Pentru anafora nominala si pentru cea functionala se obtine o precizie mai mare de 90,47%, respectiv de 96%. Precizia pentru anafora nominala este mai mica din cauza folosirii WordNet-ului. Anafora pronomiala nu este suficient tratata de model.
Algoritmul meu este indicat pentru anafora nominala si cea functionala.
rezolvarea anaforelor pronomiale mai eficient;
îmbunatatirea modului de acces la WordNet si folosirea pentru testare a unui text mai mare;
rafinarea interogarilor Web folosite pentru rezolvarea anaforei nominale;
includerea unui modului de învatare pentru rafinarea scorurilor regulilor si pragurilor;
folosirea informatiilor aduse de adjective si prepozitii.
Bunescu, Razvan - Associative
anaphora Resolution: A Web-Based Approach,
Cristea, Dan - Lingvisitca computationala - curs, Universitatea "A. I. Cuza",
Facultatea de Informatica,
Cristea, Dan; Dima Gabriela - An Integrating Framework for Anaphora Resolution, Universitatea "Al. I. Cuza";
Cristea, Dan; Postolache, Oana-Diana; Dima, Gabriela-Eugenia; Barbu,Catalina - AR-Engine - a framework for unrestricted co-reference resolution, Universitatea "Al. I. Cuza , 2002;
Davies, S.; Poessio, M. - Coding Schemas for Co-reference, 2000
Dennett, Daniel C. - The Role of
Language in Intelligence,
Fogel, David B. - Blondie24, Playing at the Edge of AI, Morgan Kaufmann Publishers, 2002;
Grosz, Barbara J; Joshi, Aravind K. & Weinstein, Scott, Centering: A framework for modelling the local coherence of discourse, Computational Linguistics, 1995
Kennedy, C., Boguraev, B. 1996. Anaphora for Everyone: Pronominal Anaphora Resolution without a Parser, 16th International Conference on Computational Linguistics, vol. 1;
Lust, Barbara - Introducere la Studies in the Acquisition of Anaphora, D. Reidel, 1986
Markert, Katja; Nissi, Malvina; Modjeska,
Natalia N. - Using the Web for Nominal
Anaphora Resolution, University of
Meyer, Josef; Dale, Robert - Using the WordNet
Hierarchy for Associative Anaphora Resolution, Centre for
Mitkov Ruslan - Anaphora Resolution, Longman, 2002
Mitkov, Ruslan - Evaluation in anafora resolution, University of
Poesio, Massimo - What is 'coreference'?
|
