ANALIZA STATISTICA A CONCENTRARII DIVERSIFICARII
Problematica concentrarii-diversificarii formulata pentru prima data de Corado Gini (1912) - o data cu analiza distributiei veniturilor unei populatii - este deosebit de importanta si prezinta interes in diverse domenii. In acest sens este suficient sa precizam urmatoarele: caracterizarea structurii pietelor; analiza inegalitatilor dintre repartitiile de structura;analiza repartitiilor regionale etc.
Prin concentrare se intelege, in general, aglomerarea unitatilor unei populatii statistice sau a valorilor globale ale unei distributii in jurul unei valori tipice a variabilei analizate X. In mod complementar se defineste notiunea de diversificare. Din definitia prezentata se constata, in mod evident, urmatoarele:
. Notiunea de concentrare se refera atat la aglomerarea unitatilor unei populatii statistice pe variante (sau in intervale de variatie), cat si la aglomerarea valorilor globale(de tipul xinj cu i = I,σ) sau a valorilor unui indicator de nivel pe aceleasi variante(sau intervale de variatie). Studiul concentrarii, presupune deci, analiza comparata a structurii efectivului unei populatii si a structurii valorilor globale pe aceleasi variante (sau intervale 353h78d de variatie) ale variabilei observate. In acest mod se pot evidentia atat inegalitatile dintre distributiile de structura comparate cat si compararea valorilor globale pe un numar limitat de unitati ale populatiei; cu cat sunt mai mari diferentele dintre cele doua distributii de structura cu atat mai mari sunt si disparitatile dintre grupele de unitati, ceea ce inseamna ca exista o concentrare care tinde sa creasca, si invers, cu cat diferentele dintre distributiilede structura sunt mai mici, cu atat concentrarea este mai slaba (diversificarea este mai mare), tinzand spre o echipartitie (distributie egalitara).
Studiul concentrarii solicita respectarea a doua cerinte esentiale: sa fie posibila si sa aiba sens aditivitatea valorilor individuale ale variabilei observate; sa fie posibila si sa aiba sens divizarea valorilor globale intre unitatile populatiei. Aceasta inseamna ca analiza concentrarii se poate efectua asupra variabilelor continue cu valori pozitive si doar in anumite cazuri variabilelor calitative (in mod deosebit, pentru stabilirea gradului de concentrare pe tipologii calitative).
Caracterizarea statistica a concentrarii/diversificarii se poate realiza prin mijloace grafice si prin procedee numerice (de calcul).
|
de concentrare de concentrare Curba de concentrare |
Curba de concentrare
Curba de concentrare (elaborata de italianul C. Gini si americanul Lorentz) numita si curba Lotentz-Gini - permite aprecierea si, totodata, sta la baza determinarii unei masuri a concentrarii (gradului de concentrare) numita indicele de concentrare Gini.
Curba de concentrare se traseaza pe baza punctelor de coordonate (Pi' qj)' Coordonatele acestor puncte sunt:
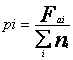
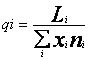
unde: i = 1,n; Fai = Fai-1 + n i - frecventa absoluta cumulata pana la nivelul "i"; Li = Li-1 + xini - valorile globale (xi' ni) cumulate pana la nivelul "i" al variabilei de grupare.
Metoda intervalelor de încredere
La organizarea unei cercetai prin sondaj una din problemele de rezolvat este dimensionarea lui rationala. Este adevarat ca marimea volumului n al sondajului - în virtutea legii numerelor mari - sporeste precizia rezultatelor, reduce eroarea medie probabila. Tinând seama de criterii de economicitate este necesar ca acest volum sa fie cât mai mic. Luând în considerare ambele apecte, se determina numarul minim de unitati de observat care sa satisfaca exigentele de precizie si siguranta formulate în raport cu cercetarea respectiva.
În teoria si practica sondajului se opereaza cu esantioane "mari" si esantioane de "volum redus" în functie de gradul de omogenitate al colectivitatii generale. Interpretarea erorii de reprezentativitate e face în mo diferit: pentru esantioanele de volum mare se foloseste functia Laplace, iar pentru cele de volum redus distributia Student.
Calculul volumului esantionului se relizeaza pornind de la eroare limita maxima admisa, care în cazul sondajului repetat se realizeaza pornind de la eroarea probabila.
În practica, de cele mai multe ori, situatiile cu care avem de-a face si întrebarile la care trebuie sa raspundem sunt de natura urmatore: cercetatorul sau analistul nu cunoaste valoarea reala, din populatie, a parametrului, ci încearca sa o estimeze. Pentru a ilustra o astfel de situatie sa presupunem ca un cercetator doreste sa estimeze nivelul de inteligenta al elevilor unei scoli. Pentru aceasta el extrage aleator un esantion format din 25 de elevi carora le aplica un test de inteligenta si obtine o valoare medie a coeficientului de inteligenta de 131. Bazându-se pe acest rezultat, ce poate el spune despre nivelul de inteligenta al elevilor scolii respective? Esantionul de 25 de elevi este evident doar unul din esantioanele care ar fi putut fi extrase, si prin urmare si media de 131 obtinuta la nivel de esantion este doar una din mediile posibile. Mai clar spus, 131 este doar una dintre mediile din distributia de medii care ar putea fi obtinuta extragând multe esantioane formate din 25 de elevi ai scolii respective. Se pune deci urmatoarea problema: care este valoarea medie a coeficientului de inteligenta pentru întreaga populatie de elevi vizata? - valoare evident necunoscuta pentru cercetator, altfel ce rost ar mai fi avut sa faca cercetarea!
Este destul de evident ca daca
dorim sa facem o inferenta despre media popultiei µ
pe baza lui ![]() (media unui esantion), si
daca vrem sa putem avea încredere ca aceasta
inferenta este corecta, nu putem pretinde ca µ =
(media unui esantion), si
daca vrem sa putem avea încredere ca aceasta
inferenta este corecta, nu putem pretinde ca µ = ![]() . Pare mult mai rezonabil sa
acceptam ca exista o oarecare eroare de esantionare cu
ajutorul careia sa construim o estimare de interval, sau, mai bine zis, un
interval de încredere:
. Pare mult mai rezonabil sa
acceptam ca exista o oarecare eroare de esantionare cu
ajutorul careia sa construim o estimare de interval, sau, mai bine zis, un
interval de încredere:
µ = ![]()
![]() o eroare de esantionare.
o eroare de esantionare.
Cât de mare ar trebui sa fie însa aceasta eroare?
Raspunsul depinde bineînteles de distributia de esantionare
a lui ![]() , sau mai bine zis de masura în care
acesta fluctueaza în jurul mediei din populatie.
, sau mai bine zis de masura în care
acesta fluctueaza în jurul mediei din populatie.
Aria de sub curba distributiei de
esantionare

Pentru orice distributie normala aria de sub curba aflata între µ - 1,96σ si µ + 1,96σ este întotdeauna 0,95. În cazul distributiei de esantionare, care este o distributie normala, vom spune deci ca aria de sub curba cuprinsa între µ - 1,96e si µ + 1,96e (unde e este eroarea standard) este egala de asemenea cu 0,95, de vreme ce eroarea standard este abaterea standard a distributiei de esantionare. Altfel spus, expresia
Pr(µ - 1,96e < ![]() < µ + 1,96e) = 0,95
< µ + 1,96e) = 0,95
este adevarata pentru orice distributie de esantionare. În cuvinte, probabilitatea ca media unui esantion simplu aleator de marime n sa se gaseasca între valorile µ - 1,96e si µ +1,96e, este egala cu 0,95 (Figura). Inegalitatile din paranteza expresiei de mai sus pot fi rezolvate pentru µ, obtinându-se astfel expresia echivalenta:
Pr(![]() - 1,96e
< µ <
- 1,96e
< µ < ![]() + 1,96e) = 0,95
+ 1,96e) = 0,95
Aceasta nu înseamna ca µ nu mai
e o constanta - parametrul cautat de noi în populatie. Expresia
de mai sus nu este nimic altceva decât o "propozitie"
probabilista despre variabila aleatoare ![]() . Media în populatie nu variaza.
. Media în populatie nu variaza.
Întorcându-ne la exemplul pivitor la estimarea coeficientului de inteligenta, sa presupunem ca în paralel cu cercetarea prin esantion a fost efectuata si o testare pe toata populatia de elevi din scoala respectiva. Rezultatul a fost o medie a coeficientului de inteligenta de 132, si o abatere standard de 12. Cercetatorului nostru nu i s-a comunicat însa decât abaterea standard, asa ca el a fost în continuare nevoit sa estimeze media în populatie pe baza valorii obtinute în esantion. În consecinta, el va lua expresia de mai sus, si, dupa calcularea erorii standard (e=2,4) va scrie:
Pr(131- 1,96 x 2,4 < µ < 131 + 1,96 x 2,4) = 0,95, adica
Pr(126,3 < µ < 135,7) = 0,95
În final deci, cercetatorul va afirma "cu un nivel de încredere" de 95% ca media în populatie, µ, se gaseste în intervalul 126 - 136. Acest interval se numeste interval de încredere.
Sa presupunem acum ca, asa cum e si firesc de altfel, cercetatorul nu e foarte multumit de precizia estimarii sale. El ar dori sa faca o afirmatie mai "exacta" în sensul unui interval mai restrâns. Propozitia probabilista prezentata anterior, însa în forma sa generala arata astfel:
Pr(![]() -
- ![]() < µ <
< µ < ![]() +
+ ![]() ) = 1-α
) = 1-α
unde 1-α este nivelul de încredere iar ![]() este valoarea din
tabelul z (calculata cu functia Laplace) corespunzatoare
respectivului nivel de încredere.
este valoarea din
tabelul z (calculata cu functia Laplace) corespunzatoare
respectivului nivel de încredere.
În conditiile în care cercetatorul doreste sa
obtina un interval de încredere mai mic (mai restrâns), el nu poate
face acest lucru decât printr-un compromis, si anume reducând valoarea
absoluta a lui z, sau altfel spus, reducând nivelul de încredere. Deoarece
cercetatorul nu poate modifica nici ![]() nici eroarea standard decât prin
efectuarea unei alte cercetari, lui nu îi ramâne decât sa
îsi aleaga un nivel de încredere mai mic decât 95%, ceea ce va duce
la o micsorare a intervalului. De exemplu, daca cercetatorul se
multumeste cu un nivel de încredere de 68% - caruia îi
corespunde
nici eroarea standard decât prin
efectuarea unei alte cercetari, lui nu îi ramâne decât sa
îsi aleaga un nivel de încredere mai mic decât 95%, ceea ce va duce
la o micsorare a intervalului. De exemplu, daca cercetatorul se
multumeste cu un nivel de încredere de 68% - caruia îi
corespunde ![]() , atunci el va
putea spune ca, pentru un nivel de încredere de 68%, µ va fi cuprins între
131 - 2,4 si 131 + 2,4, adica între 128,6 si 133,4.
, atunci el va
putea spune ca, pentru un nivel de încredere de 68%, µ va fi cuprins între
131 - 2,4 si 131 + 2,4, adica între 128,6 si 133,4.
Concluzia ca estimarea constituie întotdeauna un compromis între "exactitatea" si "siguranta" afirmatiei pe care dorim sa o facem despre parametrul în cauza. Mai riguros spus, daca vom încerca sa crestem nivelul de încredere al estimarii, marind astfel "siguranta", va trebui sa crestem si intervalul de încredere, pierzând astfel din "exactitate". si invers, daca dorim sa micsoram intervalul de încredere, vom fi nevoiti sa reducem si nivelul de încredere al estimarii. Este totusi legitim sa ne întrebam cum putem obtine estimari cât mai "sigure" si cât mai "exacte"? Raspunsul nu este foarte greu de dat: prin marirea volumului esantionului. Acest raspuns decurge firesc din formula erorii standard:
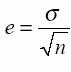
de unde reiese clar ca, cu cât vom avea un esantion mai mare cu atât vom avea o eroare standard mai mica, si deci intervale de încredere mai mici, pentru acelasi nivel de încredere.


Bibliografie: Isaic-Maniu Alexndru, Mitrut Constatin, Voineagu Vergil - "Statistica", ed. Universitara, Bucuresti 2003.
Lucian Pop, Cosmin Marian, Gabriel Badescu - "Statistica", Facultatea de Filosofie Bucuresti, 2001.
|
